



الگوریتم کد گذاری هافمن (Huffman Coding) – به زبان ساده
در این مطلب، الگوریتم هافمن (Huffman Algorithm) مورد بررسی قرار خواهد گرفت. همچنین، پیادهسازی آن در زبانهای برنامهنویسی گوناگون شامل ++C و «جاوا» (Java) ارائه شده است. «کد هافمن» (Huffman Code) نوع خاصی از «کدهای پیشوندی» (Prefix Codes) بهینه است که اغلب برای فشردهسازی بیاتلاف اطلاعات مورد استفاده قرار میگیرد. فرایند پیدا کردن یا استفاده از این کد به وسیله کدگذاری هافمن (Huffman coding)، با بهرهگیری از الگوریتمی انجام میشود که توسط «دیوید آ هافمن» (David A. Huffman) توسعه داده شده است.
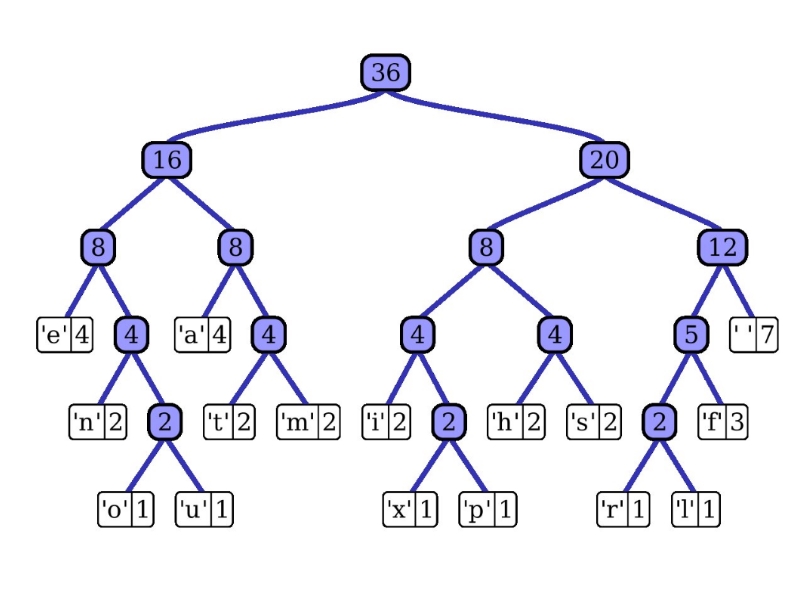


کدهای پیشوندی نوعی از کدها (توالی بیتها) هستند که در آنها کد اختصاص داده شده به یک کاراکتر پیشوند کد تخصیص داده شده به هیچ کاراکتر دیگری نیست. این، روشی است که کدگذاری هافمن با استفاده از آن اطمینان حاصل میکند که هیچ ابهامی هنگام رمزگشایی توالی بیتهای (جریان بیت) تولید شده وجود نخواهد داشت. در ادامه، برای درک بهتر موضوع، مثالی ارائه شده است. فرض میشود که چهار کاراکتر c ،b ،a و d موجود هستند و کدهای طول متغیر متناظر با آنها به ترتیب ۰۰، ۰۱، ۰ و ۱ است. این کدگذاری موجب ابهام میشود زیرا کد تخصیص یافته به c، پیشوند کدهای تخصیص یافته به a و b است. اگر جریان رشته فشرده شده ۰۰۰۱ است، خروجی که از حالت فشرده خارج شود امکان دارد cccd یا ccb یا acd یا ab باشد. دو بخش اصلی مهم در کدگذاری هافمن وجود دارد:
- ساخت درخت هافمن از کاراکترهای ورودی
- پیمایش درخت هافمن و تخصیص کد به کاراکترها
مراحل ساخت درخت هافمن
در اینجا، ورودی آرایهای از کاراکترهای یکتا با تکرار وقوع هر یک و خروجی یک «درخت هافمن» (درخت هافمن) است:
- یک گره برگ برای هر کاراکتر یکتا بساز و همچنین، «هرم کمینه» (Min Heap) از همه گرههای برگ را بساز (هرم کمینه به عنوان صف اولویت استفاده میشود. مقدار فیلد تکرار برای مقایسه دو گره در هرم کمینه مورد استفاده قرار میگیرد. به طور اولیه، کاراکتری با کمترین تکرار در ریشه است).
- دو گره با حداقل تکرار از هرم کمینه را استخراج کن.
- یک گره داخلی با فرکانسی برابر با مجموع تکرارهای دو گره را بساز. اولین گره استخراج شده را به عنوان فرزند سمت چپ و دیگر گره استخراج شده را به عنوان گره سمت راست قرار بده. این گره را به هرم کمینه اضافه کن.
- گامهای ۲ و ۳ را تا هنگامی که هرم تنها حاوی یک گره باشد تکرار کن. گره باقیمانده، گره ریشه و درخت کامل است.
در ادامه، برای درک بهتر موضوع، یک مثال بیان شده است.
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45
گام ۱: یک هرم کمینه بساز که شامل ۶ گره است و هر گره، نشانگر ریشه درخت با یک گره یکتا است.
گام ۲: دو گره با کمترین تکرار را از درخت کمینه استخراج کن. گره داخلی جدید با تکرار ۱۴ = ۹ + ۵ را اضافه کن.

اکنون، هرم کمینه حاوی ۵ گره است که ۴ گره، هر یک با یک عنصر مجرد، ریشههای درختها هستند و یک گره هرم نیز ریشه درخت با ۳ عنصر است.
character Frequency
c 12
d 13
Internal Node 14
e 16
f 45
گام ۳: دو گره کمینه را از هرم استخراج کن. یک گره داخلی جدید با تکرار ۲۵ = ۱۲ + ۱۳ را اضافه کن.

اکنون، هرم کمینه حاوی ۴ گره است که دو گره هر یک با تنها یک عنصر ریشههای درختها هستند و دو گره هرم با بیش از یک گره، ریشه درخت هستند.
character Frequency
Internal Node 14
e 16
Internal Node 25
f 45
گام ۴: دو گره با کمترین تکرار را از هرم استخراج کن. یک گره داخلی جدید با تکرار ۳۰ = ۱۶ + ۱۴ اضافه کن.

اکنون، هرم اصلی حاوی ۳ گره است.
character Frequency
Internal Node 25
Internal Node 30
f 45
گام ۵: دو گره با تکرار کمتر را استخراج کن. یک گره داخلی با تکرار ۵۵ = ۳۰ + ۲۵ را اضافه کن.

اکنون، هرم اصلی حاوی دو گره است.
character Frequency
f 45
Internal Node 55
گام ۶: دو گره با کمترین تکرار را استخراج کن. یک گره داخلی جدید با تکرار ۱۰۰ = ۵۵ + ۴۵ را اضافه کن.

اکنون، هرم کمینه تنها حاوی یک گره است.
character Frequency Internal Node 100
به دلیل آنکه هرم تنها حاوی یک گره است، الگوریتم در این مرحله متوقف میشود.
چاپ کدها از درخت هافمن
پیمایش درخت ساخته شده، از ریشه آغاز میشود. برای این کار، باید از یک آرایه کمکی استفاده شود. در این راستا، هنگامی که به فرزند سمت چپ حرکت میشود، ۰ باید در آرایه نوشته شود و در حالیکه به سمت فرزند سمت راست حرکت میشود، ۱ را باید در آرایه نوشت.
آرایه را هنگامی که یک گره برگ مشاهده شد، چاپ کن.

کدها به صورت زیر هستند:
character code-word
f 0
c 100
d 101
a 1100
b 1101
e 111
در ادامه، پیادهسازی رویکرد بالا انجام شده است.
پیادهسازی الگوریتم هافمن در C
پیادهسازی الگوریتم هافمن در ++C
پیادهسازی الگوریتم هافمن در ++C با استفاده از STL
پیادهسازی الگوریتم هافمن در جاوا
خروجی قطعه کدهای بالا به صورت زیر است.
f: 0 c: 100 d: 101 a: 1100 b: 1101 e: 111
پیچیدگی زمانی روش ارائه شده از درجه (O(nlogn است که در آن، n تعداد کاراکترهای یکتا محسوب میشود. اگر n گره وجود داشته باشد، ()extractMin به تعداد مرتبه فراخوانی میشود.
()extractMin از درجه (O(logn است، زیرا ()minHeapify را فراخوانی میکند. بنابراین، پیچیدگی کلی از درجه (O(nlogn خواهد بود. اگر آرایه ورودی مرتب شده باشد، الگوریتم دارای پیچیدگی زمانی خطی میشود.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامه نویسی
- آموزش ساختمان دادهها
- مجموعه آموزشهای ساختمان داده و طراحی الگوریتم
- رنگآمیزی گراف به روش حریصانه — به زبان ساده
- الگوریتم دایجسترا (Dijkstra) — از صفر تا صد
- الگوریتم پریم — به زبان ساده
- برنامه تجزیه عدد به عوامل اول آن — به زبان ساده
^^











عالی ممنونم
سلام. ممنون از زحمتی که برای ترجمه کشیدید؛ ولی اگر از منبعی استفاده میکنید، خوبه که اون رو هم ذکر کنید.
با سلام؛
منبع تمامی مطالب مجله فرادرس اگر ترجمه باشند در انتهای مطلب و پیش از نام نویسنده آورده شدهاند.
با تشکر از همراهی شما با مجله فرادرس
با تشکر از شما . نکته ی حائز اهمین این که کد C رو اگر صرفا به جای printf از cout استفاده کنن تبدیل به کد C++ نمی شه . و تقاوت های ماهوی این دو کد بسیار بیشتر از این حرفاست .ممنون از این که این کد رو در سایت قرار دادید
سلام… آیا الگوریتم کدگشایی هم جزو این برنامه هست؟؟؟
سلام
می خواستم بدونم این کد های بالا برای کد گذاری فایل های باینری می باشد؟؟ با الگوریتم هافمن
اگه نیستش لطفا بگید چه تغییراتی باید تو کد بدم؟
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزارم. قطعه کدهای ارائه شده در این مطلب، پیادهسازی الگوریتم کدگذاری هافمن هستند و در آن، به عنوان نمونه، یک آرایه از کاراکترها به عنوان ورودی به برنامه داده شده است تا کاربر بتواند با اجرای کد، نمونه خروجی را مشاهده کند. برای کدگذاری هافمن محتوای یک فایل، کافی است این کد را به گونهای تغییر دهید که فایل را به عنوان ورودی دریافت، محتوای آن را کدگذاری و خروجی را در همان فایل یا فایل دیگری، بازگرداند.