



امید ریاضی (Mathematical Expectation) – مفاهیم و کاربردها
در تئوری آمار و احتمال، «متغیر تصادفی» (Random Variable) و تابع توزیع آن بسیار به کار میرود. هر چند که بسیاری از ویژگیها و خصوصیات متغیر تصادفی بوسیله تابع توزیع آن مشخص میشوند ولی به عنوان شاخصی که قابلیت مقایسه بین مقدارهای متغیرهای تصادفی مختلف را داشته باشد، احتیاج به معیاری سادهتر از تابع توزیع احتمال داریم. بنابراین اگر «تابع توزیع احتمال» (Probability Distribution Function) برای متغیر تصادفی همان نقش «جدول فراوانی» (Frequency Table) برای دادهها را داشته باشد، نیاز است مانند میانگین که اطلاعات جدول فراوانی را خلاصه میکند از شاخص یا معیاری برای خلاصه کردن اطلاعات تابع توزیع احتمال کمک گرفت. این شاخص میتواند «امید ریاضی» (Expectation Value) باشد که گاهی به آن «مقدار مورد انتظار» (Expected Value) نیز میگویند. در این مطلب امید ریاضی و خصوصیات آن معرفی و کاربرد آن را در محاسبه شاخصهای دیگر مانند واریانس، کوواریانس و ضریب همبستگی، بررسی میکنیم. در انتها نیز به چند قضیه مهم در رابطه با امید ریاضی که از اهمیت بیشتری برخوردارند، اشاره خواهیم کرد.
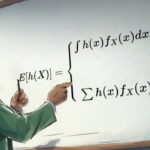
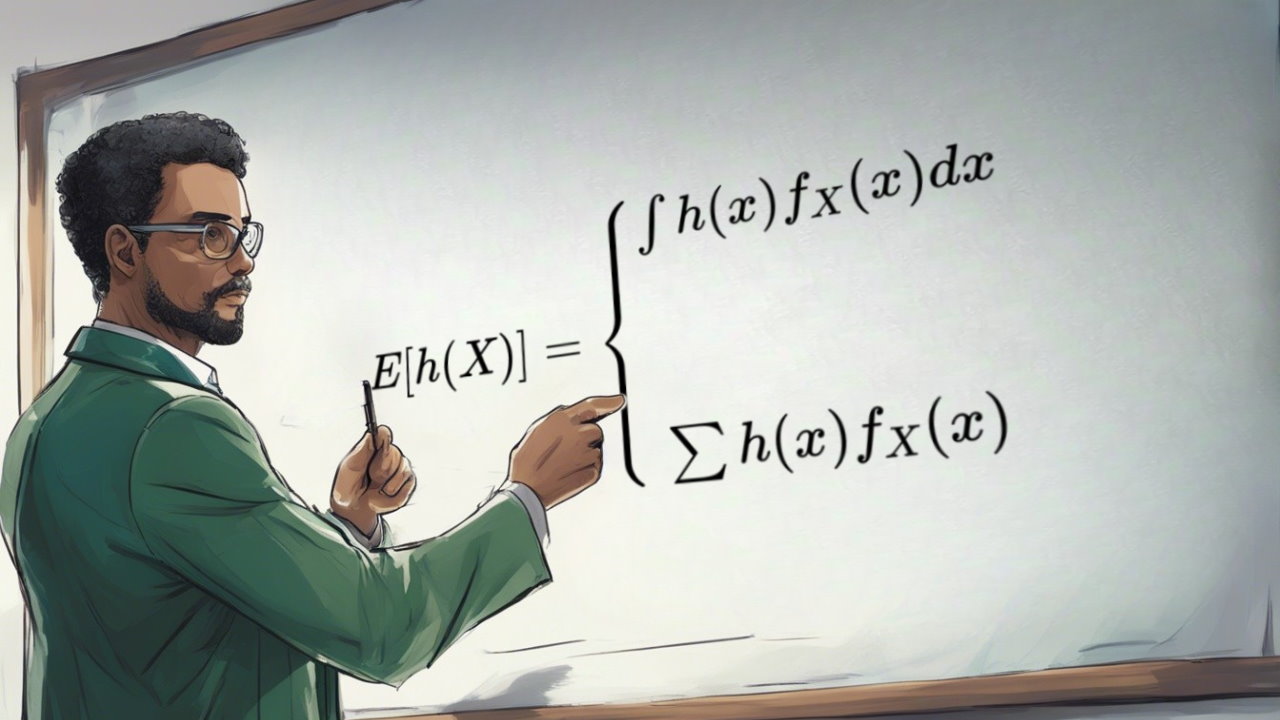


برای استفاده بیشتر از این مطلب بهتر است ابتدا مطلبهای متغیر تصادفی، تابع احتمال و تابع توزیع احتمال، آزمایش تصادفی، پیشامد و تابع احتمال و میانگین وزنی — به زبان ساده را مطالعه کرده باشید.
امید ریاضی
ایده اصلی مطرح شده در مورد امید ریاضی به سالهای دور بر میگردد. زمانی که «بلز پاسکال» (Blaise Pascal) دانشمند و ریاضیدان فرانسوی در سال ۱۶۵۴ به مسئلهای با موضوع بازیهای شانسی برخورد کرد. او میخواست متوسط درآمد فردی که در چنین بازی شرکت میکند را محاسبه کرده و مشخص کند در صورتی که فرد در تعداد زیادی از این بازی شرکت کند آیا سود نصیبش خواهد شد و یا زیان هنگفتی خواهد کرد. او همچنین به میزان دارایی که بازیکن در هر مرحله صرف کرده توجه داشت و آن را به عنوان پارامتری در حل این مسئله در نظر گرفت.
از آنجایی که بازی به صورت شانسی برنده یا بازنده را مشخص میکند، او اجبار به دخیل کردن احتمال در چنین محاسباتی داشت در نتیجه با همکار خود «پیر دو فرما» (Pierre de Fermat) دیگر دانشمند فرانسوی در این زمینه مشورت کرد و هر یک با دو شیوه مختلف به نتیجه یکسانی رسیدند. آنها یافته خود را منتشر نکردند و نامی نیز برای نتیجه محاسبات خود انتخاب نکردند.

سالها بعد «پیر لاپلاس» (Pierre Laplace) در ۱۸۱۴ طی مقالهای به مفهوم کامل و روشنی از امید ریاضی پرداخت. همچنین انتخاب علامت برای این شاخص که به صورت حرف E نمایش داده میشود نیز از ابتکارات «ویتورت» (Whitworth) ریاضیدان انگلیسی است. حال بهتر است که برای درک مفهوم امید ریاضی به بررسی یک مثال بپردازیم.
مثال ۱
فرض کنید فردی در یک بازی شانسی شرکت کرده است؛ احتمال برد او 0٫2 است و در نتیجه احتمال اینکه ببازد نیز برابر با 0٫8 است. همچنین فرض کنید که در صورت برنده شدن به وی مقدار ۱۰۰ تومان داده میشود. ضمناً اگر بازی را ببازد، باید مبلغ ۱۰ تومان جریمه پرداخت کند. به نظر شما او در این بازی نفع خواهد برد یا ضرر خواهد کرد؟

برای پاسخ به این سوال باید متوسط دریافت یا پرداختهای او را محاسبه کنیم. این کار را به واسطه محاسبات زیر انجام میدهیم. از آنجایی که 0٫2 احتمال دارد که 100 تومان برنده شود، به نظر میرسد اگر وارد بازی شود 0٫2×100=۲۰ تومان درآمد خواهد داشت. از طرفی در چنین وضعیتی نیز ممکن است 0٫8×10=8 تومان جریمه شود. بنابراین به طور متوسط در هر بار بازی، احتمال دارد 12 تومان درآمد کسب کند.
حال فرض کنید که X متغیر تصادفی باشد که مقدار a را به عنوان مبلغ جایزه و (b-) را به عنوان جریمه دریافت میکند. احتمال کسب جایزه برابر با p و احتمال جریمه نیز برابر با است. در نتیجه مقدار متوسط به صورت زیر محاسبه میشود:
بنابراین اگر X را با تکیهگاه در نظر بگیریم و احتمال مشاهده هر یک از مقدارهای تکیهگاه نیز توسط تابع احتمال p معرفی شده باشد، متوسط مقدار متغیر تصادفی X که آن را با نشان میدهیم برابر خواهد بود با:
مثال ۲
فرض کنید X یک متغیر تصادفی با تابع احتمال به صورت زیر باشد. آنگاه میانگین این متغیر تصادفی براساس تکیهگاهش، همان میانگین وزنی براساس وزنیهایی است که احتمال رخداد هر مقدار را نشان میدهند.
| مقدار متغیر تصادفی X | 1 | 2 | 3 | 4 |
| احتمال رخداد چنین مقداری |
همانطور که دیده میشود، احتمال مشاهده مقدار ۱ بیشتر از بقیه است، پس اهمیت بیشتری در محاسبه میانگین خواهد داشت. از طرف دیگر مقدار ۴ نیز با احتمال کمتری رخ داده، پس باید اهمیت کمتری در محاسبه میانگین داشته باشد. با توجه به تعریف میانگین وزنی، میتوان اهمیت حضور هر یک از مقدارها را همان احتمال رخداد هر یک از آنها، در نظر گرفت. باید توجه داشت که مقدار فراوانی درصدی، همان نقش احتمال را در جدول فراوانی دارد.
بنابراین مقدار مورد انتظار برای X به صورت زیر قابل محاسبه است:
به این ترتیب انتظار داریم اگر چندین بار مقدارهایی از متغیر تصادفی X را مشاهده کنیم، متوسط آنها برابر با 2٫25 باشد.
تعریف امید ریاضی متغیر تصادفی گسسته X
اگر X یک متغیر تصادفی گسسته با تکیهگاه S باشد، آنگاه امید ریاضی آن به صورت زیر تعریف میشود:
به این ترتیب میتوان برای مثال امید ریاضی متغیر تصادفی برنولی را محاسبه کرد.
همچنین برای متغیر تصادفی هندسی نیز محاسبات مربوط به امید ریاضی در زیر دیده میشود:
تعریف امید ریاضی متغیر تصادفی پیوسته X
اگر X یک متغیر تصادفی پیوسته با تکیهگاه و تابع چگالی احتمال باشد، آنگاه امید ریاضی آن به صورت زیر تعریف میشود:
به این ترتیب میتوان امید ریاضی متغیر تصادفی نرمال را به صورت زیر نوشت.

خواص امید ریاضی
در ادامه به بررسی خصوصیات اولیه برای امید ریاضی میپردازیم. این خصوصیات در توسعه مفهوم امید ریاضی متغیر تصادفی نقش مهمی دارند.
با توجه به مفهوم «متغیر تصادفی تباهیده» (Degenerate Random Variable) میتوان نشان داد امید ریاضی برای هر مقدار ثابت برابر است با خود آن مقدار. در این حالت تابع احتمال برای چنین متغیر تصادفی برابر است با:
بنابراین میتوان نوشت:
همچنین میتوان انتظار داشت که اگر تکیهگاه متغیر تصادفی X نامنفی باشد، امید ریاضی آن نیز مقداری نامنفی بدست آید. یعنی اگر آنگاه .
حال فرض کنید متغیرهای تصادفی باشند. آنگاه برای امید ریاضی مجموع این متغیرهای تصادفی میتوان رابطه زیر را نوشت:
از طرفی اگر این متغیرهای تصادفی، هم توزیع نیز باشند به رابطه زیر خواهیم رسید.
به این ترتیب برای متغیر تصادفی توزیع دو جملهای که از جمع متغیرهای تصادفی همتوزیع برنولی ساخته میشود، میتوان نشان داد که امید ریاضی برابر با است. البته، امید ریاضی برای مجموع متغیرهای تصادفی نرمال با میانگین برابر است با زیرا متغیرهای تصادفی یاد شده، همتوزیع نیستند.
به طور کلی میتوان برای ترکیب خطی از متغیرهای تصادفی، رابطه زیر را در نظر گرفت.
یکی از خصوصیات جالب امید ریاضی یکنوا بودن آن است. دو متغیر تصادفی X و Y با شرط را در نظر بگیرید. میخواهیم نشان دهیم که . به این ترتیب اگر Z متغیر تصادفی باشد که از تفاضل بین X و Y حاصل شده است، مشخص است که مقدارهای آن همیشه منفی خواهد بود. در نتیجه امید ریاضی برای چنین متغیری نیز منفی بدست میآید. بنابراین خواهیم داشت:
همچنین اگر X و Y دو متغیر تصادفی مستقل باشند میتوان رابطه زیر را برایشان برحسب امید ریاضی نوشت:
این تساوی نشان میدهد که در صورت استقلال، متوسط حاصلضرب دو متغیر تصادفی برابر با حاصلضرب متوسط آنها است. از عکس این حالت زمانی که متغیرهای تصادفی X و Y دارای توزیع نرمال و همچنین حاصلضرب آنها نیز دارای توزیع توام نرمال دو متغیره باشد، میتوان مستقل بودن را نتیجه گرفت. به این معنی که با توجه به شرایط گفته شده اگر امید ریاضی حاصلضرب آنها برابر با حاصلضرب امیدهایشان باشد میتوان استقلال متغیر X و Y را استنباط کرد.
اگر متغیر تصادفی X دارای تکیهگاهی نامنفی باشد، میتوان با توجه به تعریف امید ریاضی، رابطهای بین آن و تابع توزیع احتمال نوشت. فرض کنید تابع توزیع متغیر تصادفی X و نیز امید ریاضی آن باشد. در نتیجه میتوان رابطه زیر را بین این دو برای حالت گسسته و پیوسته اثبات کرد:

قانون (ضعیف و قوی) اعداد بزرگ
قانون اعداد بزرگ از مهمترین قضایای مطرح شده در تئوری آمار و احتمال است. این قانون با توجه به مفهوم امید ریاضی تعریف شده است. قانون اعداد بزرگ بیان میکند که میانگین متغیرهای تصادفی هم توزیع و مستقل به سمت امید ریاضی آنها میل میکند. فرض کنید دنبالهای از متغیرهای تصادفی هم توزیع و مستقل با امید ریاضی برابر با باشند. آنگاه امید ریاضی میانگین آنها زمانی که تعدادشان زیاد باشد، با امید ریاضی هر یک از آنها برابر است. این موضوع در رابطه زیر مشخص شده است:
این قانون آخرین بار توسط «الکساندر کینچین» (Aleksandr Khinchin) دانشمند آمار اهل روسیه در سال 1929 برای هر متغیر تصادفی دلخواه اثبات شد. البته ممکن است با دو شیوه از این قانون مواجه شده باشید. «قانون ضعیف اعداد بزرگ» (Weak Law of Large Numbers) و «قانون قوی اعداد بزرگ» (Stronge Law of Large Numbers). قانون اول و دوم هر دو یک چیز را مشخص میکنند ولی فضایی که در آن حد گرفته میشود متفاوت است. این قوانین هر چند دو عنوان مختلف دارند ولی مفهوم اصلی آنها این است که با افزایش تعداد نمونه دقت برآورد میانگین جامعه افزایش مییابد.
واریانس متغیر تصادفی
میدانیم که واریانس برای دادهها به معنی میانگین مربعات فاصله مقدارها از میانگینشان است. همین تعریف را نیز میتوان در مفهوم متغیر تصادفی تعمیم داد.
بنابراین اگر میانگین را با تعریف امید ریاضی جایگزین کنیم، شیوه محاسبه واریانس برای متغیر تصادفی X مشخص میشود.
در صورتی که این رابطه را بسط دهید و عمل توان رساندن را به انجام برسانید، خواهید دید که رابطه سادهتری برای محاسبه واریانس بدست خواهد آمد که کار محاسبات را آسانتر میکند.
این تساوی نشان میدهد که برای محاسبه واریانس متغیر تصادفی X کافی است تفاضل امید ریاضی مربعات X را از مربع امید ریاضی X بدست آورد. ولی چگونه امید ریاضی را برای محاسبه کنیم. راه حل مشخص آن است که براساس تابع احتمال متغیر تصادفی X، تابع احتمال متغیر تصادفی را بدست آورده و سپس برحسب تعریف امید ریاضی عمل کنیم. ولی قضیه زیر در انجام این محاسبه به ما یاری میرساند و عملیات را بسیار سادهتر میکند.
قضیه امید ریاضی برای تابعی از متغیر تصادفی
اگر X یک متغیر تصادفی و نیز تابعی از X باشد که امید ریاضی آن موجود است، آنگاه میتوان را به صورت زیر در دو حالت گسسته و پیوسته نوشت:
بنابراین با استفاده از این قضیه به راحتی محاسبه و در نتیجه واریانس متغیر تصادفی امکانپذیر است. همچنین به کمک این قضیه میتوان نشان داد که امید ریاضی ترکیب خطی از یک متغیر تصادفی برابر با همان ترکیب خطی از امید ریاضی آن است.
کوواریانس دو متغیر تصادفی
بر طبق تعریف امید ریاضی متغیر تصادفی، کوواریانس بین دو متغیر تصادفی مثلا X و Y که به صورت نوشته میشود به شکل زیر قابل محاسبه است.
این مقدار میزان وابستگی بین دو متغیر تصادفی را نشان میدهد. چنانچه جهت تغییرات دو متغیر عکس یکدیگر باشند، مقدار آن منفی و اگر تغییرات در یک جهت باشند، مقدار کوواریانس مثبت خواهد شد. از نظر مقایسه وابستگی بین X و Y نسبت به X و W، اگر قدر مطلق بزرگتر از قدرمطلق باشد رای به وابستگی بیشتر بین X و Y میدهیم.
نامساوی کوشی-شوارتز (Cauchy–Schwarz Inequality)
اگر X و Y دو متغیر تصادفی باشند، آنگاه نامساوی زیر در موردشان صدق میکند.
این نامساوی اولین بار توسط «آگوستین کوشی» (Augustin Cauchy) دانشمند و ریاضیدان فرانسوی در سال 1821 معرفی گردید و به عنوان ابزاری موثر در بیشتر شاخههای ریاضی به کار گرفته شد.

در اینجا این نامساوی کمک میکند برای کوواریانس دو متغیر تصادفی، یک کران بالا در نظر گرفته شود. به این ترتیب میتوان برای «ضریب همبستگی» (Correlation) نیز کرانهایی در نظر گرفت. میدانیم ضریب همبستگی توسط رابطه زیر قابل محاسبه است.
در نتیجه با توجه به نامساوی کوشی-شوارتز، کرانهای کوواریانس توسط رابطه زیر بدست میآیند:
که با در نظر گرفتن این کرانها در رابطه بالا خواهیم داشت:
از همین رو برای سنجش بزرگی وابستگی بین دو متغیر بدون در نظر گرفتن واحد اندازهگیری آنها از ضریب همبستگی استفاده میشود، زیرا این ضریب شاخصی بدون واحد است و برای مقایسه نسبت به کوواریانس مناسبتر است.
نامساوی کوشی، بعدها توسط «آمادئوس شوارتز» (Amandus Schwarz) دانشمند ریاضیدان آلمانی در سال ۱۸۸۸، به وسیله محاسبات انتگرالی اثبات شد و توسعه یافت.
نامساوی مارکف (Markov Inequality)
اگر متغیر تصادفی X نامنفی باشد، میتوان بوسیله امید ریاضی X یک کران بالا برای احتمال بدست آورد. در این حالت مینویسیم:
نامساوی مارکف و نامساویهای مشابه آن، یک کران (هر چند نادقیق) برای تابع توزیع احتمال برحسب امید ریاضی میسازند.
مثال ۳
فرض کنید X درآمد افراد باشد (درآمد در این حالت متغیر تصادفی نامنفی است) و داشته باشیم . آنگاه میتوان گفت حداکثر 25٪ افراد، درآمدی بیش از ۴ برابر میانگین دارند.
نامساوی چبیشف (Chebyshev Inequality)
فرض کنید X یک متغیر تصادفی با امید ریاضی و واریانس متناهی باشد. آنگاه برای هر عدد حقیقی مثبت مثل k داریم:
این نامساوی نیز با توجه به واریانس و امید ریاضی یک کران بالا برای تابع احتمال متغیر تصادفی X در دمهای سمت راست ایجاد میکند. اگر در نامساوی مارکف مقدار a را برابر با در نظر بگیریم و باشد، قضیه چبیشف به راحتی اثبات میشود.

نامساوی جنسن (Jensen's Inequality)
فرض کنید X یک متغیر تصادفی و نیز یک تابع «محدب» (Convex) باشد. در این حالت میتوان رابطه زیر را بین امید ریاضی تابع X با تابعی از امید ریاضی X نوشت. یعنی در این شکل خواهیم داشت:
برای مثال با توجه به اینکه یک تابع محدب است (زیرا مشتق دوم آن مثبت است)، نامساوی زیر برای آن صدق میکند.
با توجه به این موضوع مشخص است که واریانس مقداری نامنفی خواهد بود زیرا:
مثال ۴
اگر باشد با توجه به محدب بودن تابع قدر مطلق میتوان نتیجه گرفت که در نتیجه اگر امید ریاضی برای قدرمطلق X وجود داشته باشد (امید ریاضی متناهی باشد)، بطور قطع نیز امید ریاضی متغیر تصادفی X وجود دارد. زیرا کرانهای مربوط به امید ریاضی متغیر تصادفی X برحسب امید ریاضی |X| نوشته میشوند.








سلام و عرض ادب می خواستم اگر زحمتی نیست اثبات رابطه برای امید ریاضی حاصلضرب توان دو دو متغیر تصادفی تواما نرمال را برای من بفرستید رابطه اش بدین صورت است
E[X^2.Y^2]=E[X^2]E[Y^2]-2(E[XY]) ^2
با سلام و عرض ادب. ممنون بابت نشر این مطالب. بسیار مفید بود برام
سلام وقت بخیر من ی سوال داشتم اگر میشه لطفا جواب بدید
اگر F سیگما میدان باشه و aعضوش باشه و احتمال aی بار 0و ی بار 1بشه اگر X نسبت به این سیگما میدان متغیر تصادفی باشع Xتباهیده هس. مبشه لطفا ثابت کنید چرااا؟؟؟؟
سلام خسته نباشید ممنون بخاطر اموزش خوبتون . یک سوال داشتم , معنی تکیه گاه چیه اگر ی توضیحی بدید ممنون میشم
سلام.
«تکیهگاه» (Support) مجموعه مقدارهایی است که متغیر تصادفی با احتمال مثبت اختیار میکند. برای آشنایی بیشتر به مطلب «متغیر تصادفی، تابع احتمال و تابع توزیع احتمال (+ دانلود فیلم آموزش رایگان)» مراجعه کنید.
سپاس از همراهیتان با مجله فرادرس.
سلام
سپاس از زحمات شما
تفاوت تابع توزیع احتمال با تابع چگالی احتمال چیست؟
جهت پیش بینی یک مقدار بر اساس مقادیر قبلی از چه قضیه یا روش های آماری تصادفی باید استفاده کرد؟
سلام خواننده گرامی،
همانطور که از اسم تابع توزیع احتمال و چگالی احتمال دریافت میکنیم، هر دو میزان یا جرم احتمال را در نقاط تکیهگاه متغیر تصادفی مشخص میکنند ولی برای اینکه متغیر تصادفی به دو صورت پیوسته و گسسته شناخته میشود، در مواقعی که متغیر تصادفی گسسته باشد، از تابع توزیع احتمال استفاده می کنیم که دقیقا در هر نقطه، میزان احتمال را مشخص میکند. ولی در حالت پیوسته، تابع مورد نظر، جرم (نه میزان احتمال) را تعیین مینماید. در توزیعهای پیوسته، میزان احتمال در هر نقطه برابر با صفر است ولی تابع چگالی احتمال، جرم احتمال و چگونگی توزیع احتمال را در تکیهگاه تعیین میکند که نمیتوان از آن به عنوان مقدار احتمال استفاده کرد.
در مورد سوال دوم شما باید گفت که چندین روش برای انجام این کار وجود دارد. سری زمانی (Time Series) یک روش پیشبینی است که برای دادههای وابسته به زمان مناسب است. در حالی که رگرسیون و مدل آنها به شرط استقلال مشاهدات مورد استفاده قرار میگیرد. البته تکنیکهای میانگین گیری و امید ریاضی (مارتینگل) نیز به کار میروند.
پیروز و پایدار باشید.
درراستا سوال قبلم اگر ممکنه جواب رو کامل به ایمیلم بفرستین
سلام ببخشید من یه سوالی داشتم لطفا خیلی سریع اگرمیشه راهنمایی کنید اگه متغیر های تصادفی مثبت داشته باشین و امید x1متناهی باشی اونموقع حد a.sحاصل ضرب xi ها به توان یک ان ام چی میشه
سلام
فکر میکنم در قسمت خواص امیدریاضی، که تاکید شده امیدریاضی مجموع متغیری تصادفی «مستقل» برابر مجموع امیدریاضی آنهاست و بعد مثال از مجموع تعدادی توزیع برنولی و نیز مجموع تعدادی نمایی زده شده، مستقل بودن شرط لازمی نیست. در واقع امیدریاضی همواره خطی است و این نیازی به استقلال متغیرها ندارد. و این برای هر تعداد متغیری برقرار است. درست نمیگویم؟
درود به شما همراه دقیق و کنجکاو مجله فرادرس؛
کاملا حق با شما است. متن مورد نظر با توجه به تذکر سازنده شما اصلاح شد و رابطه خطی در امید ریاضی به متن افزوده شد.
از اینکه به مطالب مجله فرادرس توجه دارید و کاستی و لغزشهای ما را گوشزد میکنید، سپاسگزاریم.
تندرست و پایدار باشید.
سلام. در مثال شماره یک مقدار امید ریاضی 2.25 هست که 2.5 تایپ شده لطفا اصلاحش کنین. ممنون بابت این مطالب مفید
با سلام و تشکر از توجه شما به مطالب مجله فرادرس
بابت اشتباه محاسباتی در این نوشتار از شما عذرخواهی میکنم. مطلب اصلاح شد.
شاد و موفق و تندرست باشید.
با سپاس فراوان از مطلب مفیدتون،
سوالم اینه که ایا امکان داره در خصوص قانون اعداد بزرگ، متغیرهای تصادفی مستقل باشند ولی هم توزیع نباشند؟در این حالت قانون اعداد بزرگ صادق هست یا خیر؟
سلام و درود
در قضیه یا قانون اعداد بزرگ فرض استقلال و هم توزیعی وجود دارد. در شرایطی که توزیعها یکسان نباشد. برای اطلاع از نحوه ارائه این قضیه در حالت کلیتر بهتر است مقاله Chen را مطالعه فرمایید.
R. Chen, “A remark on the strong law of large numbers,” Proc. Am. Math. Soc.,61, No. 1, 112–116 (1976).
باز هم از اینکه همراه فرادرس هستید سپاسگزاریم.
با سلام و تشکر از توجه شما به مطالب فرادرس
در قضیه یا قانون اعداد بزرگ شرکت استقلال و هم توزیعی وجود دارد. در صورتی که شرط هم توزیعی وجود نداشته باشد اثباتهایی برای این قضیه ارائه شده است. بهتر است برای آشنایی با این حالت به مقاله زیر مراجعه کنید.
https://link.springer.com/article/10.1007/BF01240002
باز هم از اینکه همراه فرادرس هستید متشکریم.