



کدهای پایتون آماده کاربردی و ضروری برای برنامه نویسان مبتدی تا حرفه ای
گاهی اوقات برنامهنویسی میتواند برای افراد تازهکار دلهرهآور باشد. با این حال بهترین کار برای یادگرفتن برنامهنویسی شروع مستقیم و کدنویسی است. بررسی و نوشتن نمونه کدهای آسان بهترین روش شروع کردن و آموختن برای افرادی است که بهتازگی وارد دنیای برنامهنویسی شدهاند و میخواهند با اصول پایه برنامهنویسی آشنا شوند. در این مطلب از مجله فرادرس تلاش کردیم تا مجموعه کاملی از نمونه کدهای پایتون آماده را فراهم کنیم. مطالعه و استفاده این کدها هم برای افراد تازهکار بسیار آموزنده خواهد بود و هم برای حرفهایها حاوی نکات ارزشمندی است. برنامهنویسان در هر سطحی میتوانند با مطالعه این کدها از تجربیات دیگران و روشهای متفاوت حل مسئله مطلع شوند. مطالعه کدهای از پیش پیادهسازی شده این مطلب در نهایت باعث افزایش مهارت برای توسعهدهندگان برنامههای پایتونی خواهد شد.
- با اهمیت انجام تمرینهای عملی برای پیشرفت آشنا خواهید شد.
- روشهای مختلف حل یک مسئله ساده پایتون را یاد میگیرید.
- میآموزید که ساختمان دادههایی مانند لیست و دیکشنری چگونه استفاده میشوند.
- کدهای آماده را بررسی کرده و ایدههای جدیدی را پرورش میدهید.
- راهبردهای تست و اجرای کد در محیط اختصاصی را یاد میگیرید.
- خواهید توانست مزایا و تفاوت رویکردهای مختلف کدنویسی را تحلیل کنید.




این نمونه کدها محدوده گستردهای از مفاهیم برنامهنویسی را پوشش میدهند و کمک میکنند که مهارت برنامهنویسی خود را با زیربنای محکمی پایهگزاری کنیم. چه اینکه به تازگی کار با پایتون را شروع کردهاید یا برنامهنویس با تجربهای هستید که میخواهد مهارتهای خود را مرور کند، این نمونه کدها گزینه بسیار مناسبی برای شروع کار و مرور آموختههای پیشین است.
نمونه کدهای پایتون آماده
تمرین کردن با نمونه کدها انتخاب بسیار خوبی برای تقویت ادراکات منطقی مغز و مهارتهای برنامهنویسی است. بنابراین سعی کردیم که در این مطلب بهترین مجموعه را از نمونه کدهای پایتون آماده کنیم. در این بخش مجموعه گستردهای از نمونه کدهای پایتون آماده را بررسی خواهیم کرد که شامل مفاهیم پایهای زبان برنامهنویسی پایتون مانند «لیست» (List)، String، دیکشنری، تاپل، Set و غیره میشوند. در هر نمونه هم تلاش میکنیم که درصورت امکان چند روش متفاوت را برای حل مسئله بررسی کنیم.
نمونه کد برنامه های ساده
در این بخش به برنامههای ساده و ابتدایی پایتون خواهیم پرداخت. تلاش کنید که کدها را درک یا در محیط کدنویسی خودتان وارد کرده و آزمایش کنید. این بخش بیشتر برای کسانی مناسب است که بهتازهگی با زبان برنامهنویسی پایتون آشنا شدهاند.

اضافه کردن دو عدد مختلف به یکدیگر در پایتون
تکنیکها و کدهای آسان عمل جمع را در پایتون بهخوبی یاد بگیرید. جمع کردن اعداد با یکدیگر در پایتون از کارهای بسیار آسان است. در این مبحث، سه روش مختلف را برای اجرای این عمل پیادهسازی کردهایم. اما با کمی تحقیق میتوانید باروشهای دیگری نیز برای انجام این کار آشنا شوید.
دو عدد num1 و num2 داده شدهاند. وظیفه ما این است کدی بنویسیم که این دو عدد را با هم جمع ببندد و نتیجه را به کاربر نمایش دهد. روشهای متفاوتی برای اجرای عمل جمع در پایتون وجود دارد. در این مطلب از روشهای زیر برای انجام این کار کمک میگیریم.
- استفاده از عملگر +
- تعریف کردن تابعی برای جمع کردن ۲ عدد
- بهکار گرفتن متد operator.add

در ادامه هر کدام از این متدها را همراه با توضیح بهطور کامل کدنویسی کردهایم.
جمع کردن دو عدد با استفاده از عملگر «+»
در این مسئله num1 و num2 متغیرهای مسئله هستند و میخواهیم این متغیرها را با استفاده از عملگر + جمع ببندیم. به کد زیر نگاه کنید.
خروجی کد بالا به صورت زیر است.
Sum of 15 and 12 is 27فرایند جمع کردن و انجام عملهای ریاضی با استفاده از عملگرهای مرتبط به همین سادگی است که دیدیم. روش گرفتن داده از کاربر و ذخیره کردن دادهها در متغیرها را در تمرینهای بعدی بیشتر خواهیم دید.
اضافه کردن دو عدد در پایتون به کمک تعریف تابع سفارشی
در برنامه نوشته شده روش انجام عمل جمع را با تابع سفارشی خودمان پیادهسازی کردهایم. بسیار ساده میتوان تابعی تعریف کرد که دو «عدد صحیح» (Integer) بپذیرد و نتیجه جمع این دو عدد را برگرداند. به کد آورده شده در زیر توجه کنید.
خروجی کد بالا به صورت زیر است.
Sum of 10 and 5 is 15;جمع بستن دو عدد با استفاده از متد operator.add
در این کد ابتدا دو متغیر num1 و num2 را مقداردهی کردهایم. سپس کتابخانه برنامهنویسی operator را «وارد» (Import) محیط کدنویسی خود کرده و متد add() را از این کتابخانه فراخوانی کردیم. سپس متغیرها را به عنوان پارامتر به این متد ارسال کردیم و بعد از آن نتیجه عمل جمع را به متغیر su تخصیص میدهیم.
خروجی کد بالا به صورت زیر است.
Sum of 15 and 12 is 27در نهایت هم با کمک تابع print() نتیجه را به کاربر نمایش میدهیم.
پیداکردن بیشترین مقدار بین دو عدد Maximum
یکی از نمونه مسائل مهم در کدهای پایتون آماده پیداکردن بیشترین مقدار در بین دو عدد است. این مسئله بهظاهر ساده ممکن است در خیلی از برنامههای پیچیده و حرفهای پایتون پیش بیاید. برای حل این مساله به سه روش مختلف زیر اقدام میکنیم. توجه کنید روشهای بیشتری نیز برای حل این مسئله وجود دارند.
- استفاده از عبارت شرطی if-else
- استفاده از تابع max()
- استفاده از «عملگر سهتایی» (Ternary Operator)

کار خود را با اولین روش یعنی عبارت شرطی if-elseشروع میکنیم.
پیداکردن بیشترین مقدار با کمک عبارت شرطی if-else
استفاده از عبارت شرطی if-else برای مقایسه بین دو عدد یکی از رویکردهای بسیار ساده در پایتون است. با کمک عبارت شرطی if-else به راحتی میتوان دو عدد را مقایسه کرد و نتیجه نهایی را به کاربر نمایش داد. به کدی که در ادامه آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
4استفاده از تابع max برای پیدا کردن بیشترین مقدار
تابع max() بیشترین مقدار را بین مقادیری که به عنوان پارامتر دریافت کرده پیدا میکند. به کدی که در ادامه پیادهسازی شده توجه کنید.
خروجی کد بالا به صورت زیر است.
4استفاده از عملگر سه تایی برای پیدا کردن بیشترین مقدار
عملگر سهتایی نوعی از عبارتهای شرطی if-else است. به این صورت که در این نوع از عبارت شرطی، چیزی را بر اساس شرطی ارزیابی میکنند که دو حالت True یا False دارد. این تکنیک شرط نویسی کمک میکند که بهسادگی عبارتی را در یک خط کد بسنجیم. به مثال زیر توجه کنید.
خروجی کد بالا به صورت زیر است.
4محاسبه مقدار فاکتوریل یک عدد
فاکتوریل برای عدد صحیح مثبت غیر صِفر، برابر است با حاصل ضرب همه اعداد کوچکتر مساوی همان عدد در یکدیگر. این اعداد از یک شروع میشوند و صِفر جزو این اعداد نیست. برای مثال فاکتوریل عدد 6 برابر با 6*5*4*3*2*1 است که مساوی با عدد 720 میشود.
برای این مسئله هم سه روش را پیادهسازی کردهایم.
- محاسبه فاکتوریل با رویکرد توابع بازگشتی
- محاسبه فاکتوریل با رویکرد اشیای پیمایشی
- محاسبه فاکتوریل با استفاده از عملگر سهتایی
بررسی کدهای پایتون آماده برای روشهای مختلف محاسبه فاکتوریل یک عدد میتواند بسیار مفید باشد، بهخصوص برای دانشجویان و دانشآموزانی که با محاسبات ریاضی کار میکنند. بررسی خود را از روش اول شروع میکنیم.
محاسبه فاکتوریل با رویکرد توابع بازگشتی
این برنامه پایتون از تابع بازگشتی برای محاسبه مقدار فاکتوریل عدد داده شده استفاده میکند. تابع بازگشتی به تابعی میگویند که قادر است از خودش استفاده کند یا در زمان انجام فعالیت خود را فراخوانی میکند. کدی که نوشتهایم میزان فاکتوریل هر عدد را به کمک ضرب همان عدد در میزان فاکتوریل عدد قبل از خودش محاسبه میکند. به نمونه کد زیر دقت کنید.
خروجی کد بالا به صورت زیر است.
Factorial of 5 is 120محاسبه فاکتوریل با رویکرد اشیای پیمایشی
به هر شی در پایتون که شمارندهای بتواند بر روی محتوی آن شی پیمایش کند، شی پیمایشی یا پیمایشپذیر میگویند. به عنوان چند نمونه از اشیا پیمایشپذیر میتوان به ساختارهای دادهای مانند لیست، رشته و دیکشنری در پایتون اشاره کرد.

برای حل این مسئله به روش گفته شده تابعی به نام factorial تعریف خواهیم کرد و درون تابع به کمک شمارنده حلقه while از آرگومان تابع یک شی پیمایشی مجازی میسازیم. پیمایش روی این مقدار را تا زمان رسیدن شمارنده به عدد یک ادامه میدهیم و پارامتر دریافتی تابع را به کمک عبارت شرطی if-else اعتبار سنجی میکنیم. اعتبار سنجی پارامتر دریافتی تابع الزامی است اما روش اینکار بسته به دلخواه برنامهنویس است.
خروجی کد بالا به صورت زیر است.
Factorial of 5 is 120محاسبه فاکتوریل با استفاده از عملگر سه تایی
همانطور که قبلا اشاره کردیم منظور از «عملگر سهتایی» (Ternary Operator) عبارت شرطی یکخطی است که انجام رفتار بسته به شرطی است که بین دو حالت True یاFalse قرار میگیرد. برای این حالت نیز تابعی به نام factorial تعریف میکنیم. به کد زیر نگاه کنید.
خروجی کد بالا به صورت زیر است.
Factorial of 5 is 120بررسی عدد آرمسترانگ
در این مسئله از کدهای پایتون آماده، عدد x داده شده است. باید بررسی کنیم که آیا x عدد آرمسترانگ است یا نه. قبل از شروع به کار لازم است تعریفی از عدد آرمسترانگ داشته باشیم. عدد آرمسترانگ به عدد صحیح مثبتی میگویند که اگر همه ارقام آن را به صورت جداجدا به توان تعداد رقم آن عدد برسانیم و نتیجهها را باهم جمع کنیم این عدد بدست میآید.
فرمول این عدد به صورت زیر است.
abcd... = pow(a,n) + pow(b,n) + pow(c,n) + pow(d,n) + ....برای مثال عدد 153 یک عدد آرمسترانگ است. محاسبه زیر را نگاه کنید.
1*1*1 + 5*5*5 + 3*3*3 = 153اگر برنامه ما عدد 153 را به عنوان ورودی دریافت کند باید در خروجی مقدار Yes را چاپ کند اما عدد 120 عدد آرمسترانگ نیست. به محاسبه زیر توجه کنید.
1*1*1 + 2*2*2 + 0*0*0 = 9اگر برنامه ما عدد 120 را به عنوان ورودی دریافت کند باید در خروجی مقدار No را چاپ کند.
برای حل این مسئله هم از سه روش مختلف استفاده خواهیم کرد. ولی روشهای دیگری نیز برای حل این مسئله وجود دارند.
- بررسی عدد آرمسترانگ با کمک تابع سفارشی power
- بررسی عدد آرمسترانگ بدون استفاده از تابع power
- بررسی عدد آرمسترانگ با تبدیل عدد به رشته
از شماره اول شروع میکنیم.
بررسی عدد آرمسترانگ با کمک تابع سفارشی power
در این روش که یکی از ابتداییترین و سادهترین روشها است، سه تابع جداگانه تعریف میکنیم. تابع power() برای به توان رساندن اعداد این تابع به صورت بازگشتی عمل میکند. سپس تابعی تعریف میکنیم که تعداد رقمهای هر عدد دریافت شده در ورودی را محاسبه کند و در آخر نیز تابعی برای بررسی آرمسترانگ بودن تعریف میکنیم.
در کد زیر توابع توصیف شده بالا به ترتیب تعریف شدهاند.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
True
Falseبررسی عدد آرمسترانگ بدون استفاده از تابع power
عدد آرمسترانگ سه رقمی به عددی میگویند که مجموع مکعب همه رقمهایش برابر با خود عدد باشد. همانطور که اشاره کردیم عدد 153 نمونهای از اعداد آرمسترانگ است.
1*1*1 + 5*5*5 + 3*3*3 = 153بررسی آرمسترانگ بودن این روش بر روی عددی مثل شماره 153 به صورت نوشته شده انجام میگیرد. حلقه while روی عدد دریافتی پیمایش میکند. این حلقه بررسی میکند که آیا عدد برابر صِفر است یا نه. اگر عدد برابر صِفر باشد از حلقه خارج میشود وگرنه وارد حلقه شده و محاسبات درون حلقه روی عدد انجام میگیرد.

درون حلقه اول از همه یکان عدد را به صورت باقیمانده تقسیم عدد بر 10 بدست میآوریم. حاصل عبارت 153%10 برابر با عدد 3 است. در مرحله بعد مکعب رقم یکان «3» را به متغیر sum1 اختصاص میدهیم. سپس در مرحله بعد رقم یکان را از عدد اصلی خارج میکنیم. بهاین صورت که با اجرای تقسیم صحیح بر 10 روی عدد اصلی رقم یکان حذف میشود 153//10=15 . این دو رقم را دوباره در حلقه while به گردش در میآوریم. حلقهwhile تا وقتی که عدد دریافتی برابر با صِفر شود به گردش ادامه میدهد.
کدی که در پایین آمده روند اجرای این پردازش را نمایش میدهد.
خروجی کد بالا به صورت زیر است.
The given number 153 is armstrong numberبررسی عدد آرمسترانگ با تبدیل عدد به رشته
این رویکرد حل مسئله شامل دریافت داده ورودی، تبدیل آن به رشته و پیمایش بر روی هر رقم در رشته برای محاسبه مقدار نهایی است. هر رقم را به توان تعداد کاراکترهای رشتهای میرسانیم که از تبدیل داده ورودی بهدست آمده است و نتایج را با یکدیگر جمع میبندیم. اگر نتیجه نهایی جمع حاصل توانها برابر با عدد ورودی بود در نتیجه داده ورودی از نوع اعداد آرمسترانگ است.
الگوریتمی که در بالا توضیح دادیم را به صورت مرحله به مرحله باید اجرا کنیم. پیادهسازی که ما انجام دادیم شامل 8 مرحله زیر میشود.
- با استفاده از تکه کد str(num) عدد ورودی را به رشته تبدیل میکنیم.
- با کمک تکه کد len(num_str) طول رشته را بدست میآوریم و در متغیر n ذخیره میکنیم.
- متغیری به نام اختیاری sum ایجاد میکنیم و با مقدار صِفر مقداردهی میکنیم.
- با استفاده از حلقه forبر روی هر کارکتر رقمی در رشته پیمایش میکنیم و با کمک تابع int(digit) هر رقم را به عدد صحیح تبدیل میکنیم.
- با بهکار بردن تکه کد int(digit)**n هر رقم را به توان n میرسانیم و نتیجه توان را با مقدار متغیر sum جمع میبندیم.
- بعد از اینکه فرایند حلقه کامل شد بررسی میکنیم که آیا مقدار sum با مقدار عدد ورودی num برابر است یا نه.
- اگر sum برابر با num باشد بنابراین مقدار True یا Yes را برمیگردانیم. این مقدار برگشتی به معنی این است که عدد دریافتی برنامه از نوع اعداد آرمسترانگ است.
- اگر sum برابر با num نباشد باید مقدار False یا No را برگردانیم. این مقدار برگشتی به معنی این است که عدد دریافتی برنامه از نوع اعداد آرمسترانگ نیست.
فرایند پیادهسازی این مراحل به صورت زیر است.
خروجی کد بالا با عدد فرضی دریافتی 153 به صورت زیر است.
Trueمحاسبه مساحت دایره
حداقل چند مورد برای محاسبه مساحت اشکال هندسی در کدهای پایتون آماده باید وجود داشته باشد. یکی از بهترین مثالها برای این نوع از مسائل محاسبه مساحت دایره است.
مساحت دایره را میتوان بهسادگی با کمک فرمول Area = pi * r2 بدست آورد. در این فرمول «r» نمایانگر شعاع دایره و «pi» نمایانگر همان عدد پی معروف 3.14 است.
در ادامه این مطلب درباره کدهای پایتون آماده، مسئله محاسبه مساحت دایره را به دو روش حل کردهایم.
- نوشتن تابع سفارشی خودمان برای محاسبه مساحت دایره
- استفاده از کتابخانه math در پایتون
نوشتن تابع سفارشی برای محاسبه مساحت دایره
برای این کار کافی است که یک تابع بسیار ساده و قابل درک طراحی کنیم تا در همهجای برنامه خود و هر وقت که خواستیم مورد استفاده قرار دهیم. به کد زیر نگاه کنید.
خروجی کد بالا به صورت زیر است.
Area is 78.550000استفاده از کتابخانه math در پایتون
کتابخانه math در پایتون یکی از قویترین و کاربردیترین کتابخانههای پایتون است که برای کمک به حل محاسبات ریاضی بهکار میرود. میتوانیم از این کتابخانه برای دسترسی به عدد پی با دقت بالا هم استفاده کنیم.
خروجی کد بالا به صورت زیر است.
Area of circle is: 50.26548245743669یافتن همه اعداد اول در یک محدوده خاص
فرض کنیم که دو عدد صحیح مثبت به عنوان نقاط شروع و پایان یک محدوده عددی داده شدهاند. مسئله این است که برنامه پایتون بنویسیم که تمام اعداد اول داخل این محدوده را برای ما پیدا و در نهایت بر روی صفحه نمایش کاربر چاپ کند.

اول از همه به تعریف عدد اول توجه کنید: عدد اول به عددی میگویند که صحیح، مثبت و بزرگتر از ۱ باشد، همچنین به هیچ عددی بهجز خودش و ۱ بخشپذیر نباشد. برای مثال میتوان از مجموعه اعداد {2, 3, 5, 7, 11, ….} به عنوان چند عدد اول نام برد.
در این بخش از مطلب کدهای پایتون آماده، برای یافتن عدد اول چهار روش کلی را پیادهسازی کردیم. نام این روشها را در فهرست زیر میبینید.
- روش عادی و ساده برای پیدا کردن عدد اول
- روش بهینهسازی شده
- روش «الک اراتوستن» (Sieve of Eratosthene)
- روش بهینه الک اراتوستن یا «الک بیتی» (Bitwise Sieve)
توضیحات و پیادهسازی الگوریتمهای بالا را از روش ساده و ابتدایی اول فهرست شروع میکنیم.
روش عادی پیدا کردن عدد اول با پیاده سازی آسان
سادهترین ایدهای که برای حل این مسئله به ذهن میرسد پیمایش محدوده مورد نظر از اول تا انتها با استفاده از حلقههای پایتونی است. هر عدد n که بزرگتر از 1 باشد را بررسی میکنیم که آیا بر اعداد کوچکتر از نصف خودش بخشپذیر است یا نه. هر عددی که بر اعداد کوچکتر از نصف خودش بهجز عدد یک بخشپذیر نبود را در لیست اعداد اول وارد میکنیم.
روند توصیف شده بالا را میتوانید در کد پیادهسازی شده زیر مشاهده کنید.
خروجی کد بالا به صورت زیر است.
The prime numbers in this range are: [2, 3, 5]
روش بهینه سازی شده از روش معمول پایتونی
ایده اصلی برای حل این مسئله این است که مثل روش اول کل محدوده را از ابتدا تا انتها با استفاده از حلقه for پیمایش کنیم. سپس برای هر عددی که به اعدادی به غیر از خودش و یک بخشپذیر است – همانطور که در تعریف اعداد اول آمده- متغیر تعریف شده به عنوان «پرچم» (flag) را برابر با مقدار یک قرار میدهیم. در بلاک بعدی هر عددی که پرچم متناظرش برابر با صِفر باشد به لیست اعداد اول اضافه میشود.
مراحل پیادهسازی این کد را قدم به قدم در 5 بخش پایین شرح دادیم.
- مرحله اول: متغیری برای پرچم و لیست به صورت جداگانه تعریف میکنیم.
- مرحله دوم: بخشپذیری هر عنصر داخل محدوده را بر اعداد کوچکتر میسنجیم. در این مرحله در واقع اول بودن هر عدد را بررسی میکنیم.
- مرحله سوم: اگر هر عنصر مورد بررسی به عددی بخشپذیر بود بلافاصله پرچم برابر یک میشود. سپس دستور break را اجرا میکنیم که دور بعدی حلقه شروع شود. در غیر اینصورت مقدار پرچم متناظر این عنصر مقدار صِفر میگیرد.
- مرحله چهارم: برای هر عنصر اگر مقدار پرچم صِفر باشد، عنصر را با استفاده از متد append به لیست اعداد اول اضافه میشود.
- مرحله پنجم: لیست را برمیگردانیم.
در ادامه کد پیادهسازی شده مراحل بالا را میبینید.
خروجی کد بالا به صورت زیر است.
The prime numbers in this range are: [2, 3, 5]روش الک اراتوستن
روش «الک اراتوستن» (The Sieve Of Eratosthene) یکی از کارآمدترین روشها برای پیدا کردن همه اعداد اول کوچکتر از N است وقتی که N برابر با 10 میلیون یا حتی بیشتر باشد.

مراحل مورد استفاده در این روش به شرح زیر توصیف شده است.
- یک آرایه از نوع داده بولین به صورت prime[srt to n] ایجاد میکنیم. سپس همه محتویات داخل آن را با True مقداردهی اولیه میکنیم.
- عناصر prime[0] و prime[1] را برابر False قرار میدهیم. زیرا این عناصر عدد اول نیستند.
- برای هر عدد اول p که کوچکتر یا مساوی جزر n باشد از p = srt شروع میکنیم و همه مضارب عدد p را که بزرگتر یا مساوی p*p باشند را به عنوان عدد غیر اول علامتگزاری میکنیم. این علامتگزاری با اختصاص دادن مقدار False به prime[i] انجام میگیرد.
- در نهایت هم همه اعداد اول بین str و n را با تابع print() نمایش میدهیم.
پیادهسازی این مراحل را میتوانید در کد زیر ببینید.
اعداد اول حاصل از اجرای کد بالا را در پایین میبینید.
2 3 5 7پیچیدگی زمانی: «پیچیدگی زمانی» (Time Complexity) الک اراتوستن برابر با است. چون که این الگوریتم روی همه اعداد از 2 تا n پیمایش میکند و مضارب هر عدد اولی را که میبیند حذف میکند.
در این کد الگوریتم را فقط بر روی محدوده [srt, n] اعمال کردهایم که باعث میشود پیچیدگی زمانی در محدوده [srt, n] به میزان کاهش یابد. حلقهای که قرار است پرچم همه مضارب هر عدد اول را علامتگذاری کند از p*p تا n پیمایش میکند. این پیمایش به اندازه زمان میبرد. بنابراین کل پیچیدگی زمانی این کد برابر با است.
الک اراتوستن بهینه سازی شده یا الک بیتی
یکی از تکنیکهای بهینهسازی شده روشی که در مرحله قبل مشاهد کردیم به این شکل است که از اجرای عملیات روی همه اعداد زوج به صورت یکجا صرف نظر کنیم. با این کار اندازه آرایه prime را به نصف کاهش میدهیم. ضمنا زمان مورد نیاز برای هر پیمایش را بهنصف کاهش میدهیم. به این روش «الک بیتی» (Bitwise Sieve) هم میگویند.
میتوانید در پایین شکل کدهای پایتون آماده برای این الگوریتم را ببینید.
خروجی کد بالا به صورت زیر است.
2 3 5 7 «پیچیدگی زمانی» (Time Complexity) این الگوریت برابر با است. در این فرمول n برابر با فاصله بین محدوده اعداد است.
بررسی اول بودن عدد مشخص شده
در فرض این مسئله N را به عنوان یک عدد صحیح مثبت داده شده فرض میکنیم. مسئله این است که برنامه پایتون بنویسیم که اول بودن عدد N را بررسی کند.
توجه کنید که عدد اول، عددی صحیح، مثبت و بزرگتر از یک است که به هیچ عددی بهجز ۱ و خودش بخشپذیر نیست. برای حل کردن این مسئله از دو روش استفاده میکنیم ولی بازهم روشهای بیشتری برای حل این مسئله در دسترس هستند.
- برنامه ساده پایتونی برای بررسی اول بودن هر عدد
- بررسی اول بود اعداد با استفاده از تابع بازگشتی

برنامه ساده پایتونی برای بررسی اول بودن هر عدد
ایده اصلی این روش برای حل مسئله در بررسی عدد N بر پایه پیمایش همه اعداد از 2 تا « N/2» با استفاده از حلقه forبنا شده است. به این صورت بررسی میکنیم که آیا N بر اعداد پیمایش شده بخشپذیر است یا نه. اگر در این بررسی عددی پیدا کردیم که N بر آن بخشپذیر بود مقدار False را برگشت میدهیم. در غیر اینصورت اگر هیچ عددی از 2 تا « N/2» پیدا نکردیم که N بر آن بخشپذیر باشد، این به معنای اول بودن عدد N است. پس مقدار True را برمیگردانیم.
فرایند ساده حل این مسئله را در کد پایین پیاده کردهایم.
خروجی کد بالا به صورت زیر است.
11 is a prime numberبررسی اول بودن اعداد با استفاده از تابع بازگشتی
یکی از روشهای بسیار جالبی که در کدهای پایتون آماده کردهایم استفاده از روش تابع بازگشتی است. میتوانیم بهجای اینکه اعداد را تا n پیمایش کنیم تا مجذور n پیمایش کنیم. زیرا هر فاکتور بزرگتر از n باید مضربی از فاکتور کوچتری باشد که قبلا بررسی شده است. کد پایین شکل بازگشتی از تابعی است که این فرایند را پیادهسازی میکند.
خروجی کد بالا برای عدد فرضی 13 به صورت زیر است.
Trueپیدا کردن عدد فیبوناچی شماره n
در ریاضیات دنباله Fn فیبوناچی با رابطهای بازگشتی تعریف میشود. این رابطه بازگشتی بیان میکند مقدار هر جایگاه در دنباله برابر با مجموع اعداد جایگاه قبلی خود با عدد قبل از آن در دنباله است. فرمول رابطه فیبوناچی به صورت Fn = Fn-1 + Fn-2 است. در این فرمول به صورت قراردادی مقدار جایگاه F0 برابر با 0 و مقدار جایگاه F1 برابر با 1 است. چند عنصر اول این دنباله به صورت زیر هستند.
۰، ۱، ۱، ۲، ۳، ۵، ۸، و ...
در این مسئله باید برنامهای بنویسیم که شماره جایگاه را به صورت n دریافت کند و مقدار عددی n-اُمین جایگاه را در دنباله فیبوناچی پیدا کند. این مسئله را به 4 روش مختلف حل میکنیم.
- پیداکردن n-اُمین عدد فیبوناچی با استفاده از تابع بازگشتی
- پیداکردن n-اُمین عدد فیبوناچی با استفاده از «برنامهنویسی پویا» (Dynamic Programming)
- پیداکردن n-اُمین عدد فیبوناچی با استفاده از برنامهنویسی پویا به همراه «بهینهسازی فضا» (Space Optimization)
- پیداکردن n-اُمین عدد با استفاده از فرمول اصلی دنباله فیبوناچی
این سری از کدهای پایتون آماده را با پیادهسازی اولین روش شروع میکنیم.
استفاده از تابع بازگشتی
در این روش حل مسئله از تابع بازگشتی استفاده میکنیم. در کد تابعی به نام Fibonacci(n) تعریف میشود که n-اُمین عنصر فیبوناچی را به صورت بازگشتی محاسبه میکند. کد نوشته شده، در ابتدا مقدار ورودی را اعتبارسنجی میکند. سپس با توجه به اعداد اول سری که 0 و 1 هستند عدد فیبوناچی مورد نظر را محاسبه میکند. در نهایت مقدار صحیح جواب را برمیگرداند یا مقدار سری اول را از عدد n کم میکند و دوباره خود را فراخوانی میکند. کدی که در ادامه نوشتهایم مقدار 10-اُمین عدد فیبوناچی را برمیگرداند.
خروجی کد بالا برابر با عدد 34 است.
استفاده از برنامه نویسی پویا
در این روش در کد، تابعی به نام fibonacci(n) را برای محاسبه اعداد فیبوناچی با استفاده از تکنیک برنامهنویسی پویا تعریف کردهایم. سپس لیستی به نام FibArray را با دو عدد اول سری فیبوناچی -0 و1- مقداردهی کردیم.

تابع بررسی میکند که آیا مقدار عدد فیبوناچی که به دنبال آن میگردیم از قبل در لیست موجود بوده یا نه. در صورت وجود عدد مورد نظر در لیست، آن را برمیگرداند و در غیر اینصورت عدد فیبوناچی را به صورت بازگشتی محاسبه میکند و در لیست FibArray برای استفاده در آینده ذخیره میکند و سپس مقدار محاسبه شده را برمیگرداند. برنامه نوشته شدهای که در زیر میبینید مقدار نهمین عدد فیبوناچی را با استفاده از این روش محاسبه میکند.
خروجی کد بالا به صورت زیر است.
21استفاده از برنامه نویسی پویا به همراه بهینه سازی فضا
این روش همانند روش قبلی است با این تفاوت که لیستی برای نگهداری مقادیر فیبوناچی وجود ندارد و در نتیجه هیچ فضای حافظهای برای نگهداری لیستی استفاده نمیشود. لیستی که بهمرور زمان اندازهاش بزرگتر نیز میشود.
این فرایند در کد زیر پیادهسازی شده است.
خروجی کد بالا نیز برابر با عدد 21 است.
استفاده از فرمول اصلی دنباله فیبوناچی
این کد، تابعی به نام fibonacci(n)تعریف میکند. تابع fibonacci(n) به وسیله ساخت آرایهای که شامل سری فیبوناچی تا n-اُمین عدد است، n-اُمین عدد سری فیبوناچی را محاسبه میکند. این تابع، دادههای آرایه مورد نظر را با اولین اعداد سری فیبوناچی یعنی 0 و 1 مقداردهی اولیه میکند و سپس به صورت پیمایشی اعداد بعدی زنجیره را محاسبه میکند. برنامهای که در ادامه میبینید 9-اُمین مقدار فیبوناچی را با استفاده از این روش محاسبه میکند.
خروجی کد بالا هم برابر با عدد 144 است.
برنامه ای که بررسی می کند آیا عدد داده شده فیبوناچی هست یا نه؟
در این مسئله عدد n داده شده است. باید بررسی کنیم که آیا n جزو اعداد فیبوناچی است یا نه. در پایین چند عدد از زنجیره اعداد فیبوناچی را نمایش دادهایم.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ..قانون جالبی درباره اعداد فیبوناچی وجود دارد که از آن میتوان برای بررسی فیبوناچی بودن اعداد نیز استفاده کرد. این قانون بیان میکند، عددی فیبوناچی است که اگر و تنها اگر یکی یا هر دو فرمول یا &&(n^{2}-4\times5)&& مربع کامل باشند.
کد زیر برای بررسی اعداد با کمک این قانون پیادهسازی شده است.
خروجی کد بالا به صورت زیر است.
1 is a Fibonacci Number
2 is a Fibonacci Number
3 is a Fibonacci Number
4 is a not Fibonacci Number
5 is a Fibonacci Number
6 is a not Fibonacci Number
7 is a not Fibonacci Number
8 is a Fibonacci Number
9 is a not Fibonacci Number
10 is a not Fibonacci Number نمایش مقدار کد ASCII هر کاراکتر
در این بخش از کدهای پایتون، آماده نوشتن برنامهای میشویم که هر کاراکتری بگیرد مقدار کد ASCII آن را نمایش میدهد.
برای پیدا کردن مقدار کد ASCII کاراکتر داده شده در پایتون از تابع ord() استفاده میکنیم. این تابع رشته داده شده به طول یک کاراکتر را به عنوان پارامتر تبدیل به کد ASCII میکند و عدد صحیح متناظر با کاراتر مورد نظر را برمیگرداند. برای مثال ord(‘a’) مقدار عدد صحیح 97 را برمیگرداند.
کد زیر برای نمایش پیادهسازی این برنامه نوشته شده است.
خروجی حاصل از کد بالا به صورت زیر است.
("The ASCII value of 'g' is", 103)محاسبه مجموع مربعات اعدد طبیعی از 1 تا N
در این مسئله عدد صحیح مثبتی داده میشود و سوال این است که مجموع مربعات همه اعداد کوچکتر مساوی N را بدست بیاورید. رفتار برنامه باید مانند مثال آمده در پایین باشد.
Input : N = 4
Output : 30
= 1 + 4 + 9 + 16
= 30
Input : N = 5
Output : 55این برنامه را به سه روش مختلف پیادهسازی خواهیم کرد. این روشها را در ادامه فهرست کردهایم.
- روش اول یک برنامه ساده پایتونی
- روش دوم استفاده از تکنیک List Comprehension
- روش سوم استفاده از ساختار داده پیمایشی
این سری از کدهای پایتون آماده را با بررسی از روش اول یعنی یک برنامه ساده پایتونی شروع میکنیم.
برنامه ساده پایتونی
ایده این روش به این صورت است که برای هر iبه شرطی که 1 <= i <= n باشد مقدار i<sup>2</sup> را پیدا میکنیم و با متغیر sm جمع میبندیم. این کار را با کمک یک حلقه انجام میدهیم. متغیر sm را در ابتدای عملیات با مقدار 0 مقداردهی میکنیم.
به کد زیر نگاه کنید. کد زیر شکل پیادهسازی شده الگوریتم بالا به زبان پایتون است.
خروجی کد بالا برابر با عدد 30 است.
تکنیک List Comprehension
در این روش میخواهیم از تکنیک «Comprehension» برای لیستها استفاده کنیم. در ابتدای کار لیستی از همه مربعات اعداد طبیعی مشخص شده ایجاد میکنیم. سپس عناصر لیست را با کمک تابع sum() جمع میبندیم. مراحل انجام این کار را در ادامه فهرست کردهایم.
- با استفاده از تابع input عددی را از کاربر به عنوان ورودی دریافت کنید و بررسی کنید که صحیح و مثبت باشد.
- رشته ورودی را با استفاده از تابع int() به نوع داده «عدد صحیح» (Integer) تبدیل کنید و در متغیر N ذخیره کنید.
- از روش Comprehension برای ساخت لیستی استفاده کنید که عناصر آن شامل مربع اعداد از 1 تا N میشود. این Comprehension باید شبیه به [i*i for i in range(1, N+1)] باشد. این تکه کد لیستی از مربعهای همه اعداد از 1 تا N را تشکیل میدهد.
- از تابع sum() برای محاسبه مجموع همه عناصر لیست جدید ساخته شده استفاده کنید و نتیجه را در متغیر sum_of_squares ذخیره کنید.
- نتیجه را با استفاده از تابع print() در خروجی نمایش دهید.

کد پیادهسازی شده مربوط به مراحل بالا را در پایین میبینید.
خروجی ناشی از کد بالا به صورت زیر است.
Sum of squares of first 5 natural numbers is 55
استفاده از ساختار داده پیمایشی
میتوانیم از حلقه برای پیمایش روی اعداد طبیعی نیز استفاده کنیم. با کمک حلقه، تمام اعداد کوچکتر از N را به توان دو میرسانیم و در نهایت مجموع اعداد را باهم جمع میبندیم. این روش کدنویسی خیلی کوتاه و خلاصهای دارد. توضیح لازم برای کدهای پایتون آماده این روش را در زیر فهرست کردهایم.
- متغیری به نام sum را با مقدار صِفر مقداردهی اولیه میکنیم.
- از حلقهای برای پیمایش بر روی اعداد طبیعی از 1 تا n استفاده میکنیم.
- درون حلقه هر عدد را به توان دو میرسانیم و با مقدار متغیر sum جمع میبندیم.
- بعد از اینکه پیمایش حلقه کامل شد مقدار متغیر sum را بر روی خروجی نمایش میدهیم.
در پایین کدهای پایتون آماده مربوط به الگوریتم بالا را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The sum of squares of first 4 natural numbers is 30
برنامه نویسی حرفه ای پایتون با فرادرس
برای ارتقای مهارت در کار با زبان برنامهنویسی پایتون، استفاده از فیلمهای آموزشی مربوط به پایتون را در فرادرس به شما مخاطبین عزیز پیشنهاد میدهیم. این فیلمها به صورت تخصصی، توسط اساتید حرفهای، با محتوای منظم و با کیفیت بسیار خوبی از لحاظ بصری و صوتی تهیه شدهاند. اگر در اولین مراحل آشنایی با زبان برنامهنویسی پایتون هستید میتوانید از فیلمهای مربوط به سطح مقدماتی پایتون استفاده ببرید. چند مورد از این فیلمها را در ادامه فهرست کردهایم.
- فیلم آموزش رایگان پایتون در ۱۴۰ دقیقه با فرادرس
- فیلم آموزش برنامه نویسی پایتون Python مقدماتی فرادرس
- فیلم آموزش برنامه نویسی پایتون همراه با مثال های عملی در فرادرس
- فیلم آموزش کتابخانه Datetime در پایتون برای مدیریت زمان (رایگان) فرادرس

در صورتی که نسبت به زبان برنامهنویسی پایتون آشنا هستید و به دنبال افزایش مهارتها و تسلط خود بر این زبان قدرتمند هستید پیشنهاد میکنیم که از فیلمهای آموزشی پیشرفتهتر وبسایت فرادرس استفاده کنید. این فیلمها بهصورت تخصصی به جنبه های مختلف این زبان برنامهنویسی میپردازند. با کمی جستوجو میتوانید رشته مورد علاقه خود را در میان این فیلمها پیدا کنید. برای راحتی کار شما چند مورد از فیلمهای تخصصی و پرطرفدار را در ادامه فهرست کردهایم.
- فیلم آموزش رایگان تبدیل متن به گفتار در Python با کتابخانه pyttsx3 فرادرس
- فیلم آموزشی مربوط به یادگیری ماشین با پایتون در فرادرس
- فیلم آموزش برنامه نویسی پیشرفته ترفندهای Python از فرادرس
- فیلم آموزش پایتون گرافیکی در ارتباط با رابط های گرافیکی پایتون فرادرس
برنامه های مربوط ساختارهای داده پیمایش پذیر
برای تقویت کردن مهارت کار با آرایهها باید کدهای پایتون آماده در ارتباط با مفهوم آرایه را نیز بررسی کنیم. در این بخش تلاش کردیم همه مثالهای مهم مرتبط با مفهوم آرایه یا انواع ساختارهای داده پیمایشپذیر در پایتون را کدنویسی کنیم.
محاسبه مجموع عناصر آرایه
در مسئله فعلی، آرایهای از اعداد صحیح داده شده و باید مجموع عناصر آرایه را بدست بیاوریم. در این برنامه باید جمع کل عناصر را با پیمایش همه اعضای آرایه محاسبه کنیم و به هر عنصر که میرسیم آن را به مجموع کل اضافه کنیم. چند مثال کاربردی را برای نمایش جمع همه عناصر آرایه در ادامه فهرست کردهایم.
- محاسبه مجموع عناصر آرایه با کدنویسی ساده پایتونی
- محاسبه مجموع عناصر آرایه با استفاده از تابع sum()
- محاسبه مجموع عناصر آرایه با استفاده از متد reduce()
- محاسبه مجموع عناصر آرایه با استفاده از تابع enumerate()
کدنویسی ساده پایتونی
در این روش کل آرایه را پیمایش میکنیم و یک به یک عناصر را به مقدار متغیر sum اضافه میکنیم و در نهایت مقدار متغیر sum را نمایش میدهیم.
خروجی کد بالا به صورت زیر است.
Sum of the array is 34استفاده از تابع sum
در این روش از تابع درونی sum()استفاده میکنیم. پایتون تابع «درونی» (Built-In) به نام sum() فراهم کرده که برای محاسبه مجموع عناصر درون لیست بهکار میرود.
خروجی کد بالا به صورت زیر است.
Sum of the array is 34استفاده از متد reduce
در این روش از متد کتابخانهای reduce() استفاده میکنیم. متد Array.reduce() برای پیمایش آرایهها و خلاصهسازی همه عناصر آرایهها بهکار میرود. این متد را باید در ابتدا از کتابخانه functools به محیط کدنویسی وارد کرد. سپس متد reduce() تمام عناصر آرایه را با توجه به خواست و کدنویسی برنامهنویس، به یک مقدار تبدیل میکند. در کد زیر روش استفاده از این متد را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
('Sum of the array is ', 34)استفاده از تابع enumerate
در این کد مجموع عناصر لیست list1 را با استفاده از حلقه محاسبه میکنیم. حلقه بر روی تک به تک عناصر پیمایش میکند و عنصر را به متغیر تعریف شده s اضافه میکند و در نهایت هم مقدار مجموع عناصر را در متغیر s به کاربر نمایش میدهد. این روش کدنویسی مختصری دارد که میتوانید در ادامه به پیادهسازی آن نگاه کنید.
خروجی کد بالا هم عدد 34 را نمایش میدهد.
پیدا کردن بزرگترین عنصر درون آرایه
برای پیدا کردن بزرگترین عنصر درون آرایه، باید روی همه عناصر پیمایش کنیم و هر عنصر را با بزرگترین عنصر موجود مقایسه کنیم. در ابتدای پیمایش اولین عنصر را به عنوان بزرگترین عنصر فعلی در نظر میگیریم و در متغیری ذخیره می کنیم. اگر هر مقداری از عنصر فعلی، به عنوان بزرگترین عنصر، بزرگتر بود بهجای آن در متغیر مربوطه قرار میگیرد وگرنه به سراغ عنصر بعدی موجود در لیست میرویم. با این روش در پایان پیمایش، بزرگترین عنصر درون آرایه را پیدا کردهایم. در تصویر خروجی پایین مثالی نمایش دادیم از دادههای فرضی که برنامه گرفته و خروجی متناسب با مسئله را برگردانده است.
Input : arr[] = {10, 20, 4}
Output : 20
Input : arr[] = {20, 10, 20, 4, 100}
Output : 100این مسئله را به سه روش مختلف حل میکنیم. این روشها را در فهرست زیر نام بردهایم.
- روش عادی کدنویسی بدون استفاده از ابزار اختصاصی پایتون
- پیدا کردن بزرگترین عنصر آرایه با کمک تابع درونیmax()
- پیدا کردن بزرگترین عنصر آرایه با کمک تابع درونی sort()
بررسی روشهای حل مسئله را بهترتیب از روش اول شروع میکنیم.
روش عادی کدنویسی بدون استفاده از ابزار اختصاصی پایتون
اولین روش از کدهای پایتون آماده برای حل این مسئله روشی است که تماما توسط برنامهنویس طراحی و اجرا شده است. این روش بدون استفاده از توابع درونی اختصاصی پایتون کار میکند. به کدی که در ادامه نوشتهایم توجه کنید.
خروجی حاصل از کد بالا بهشکل زیر است.
Largest in given array 9808پیدا کردن بزرگترین عنصر آرایه با کمک تابع درونی max
در این روش از تابع درونی max() استفاده خواهیم کرد تا بیشترین عنصر آرایه را پیدا کنیم. در کد آمده پایین این رویکرد حل مسئله را پیادهسازی کردهایم.
خروجی کد بالا بهشکل زیر است.
Largest in given array 9808پیدا کردن بزرگترین عنصر آرایه با کمک تابع درونی sort
در این روش اولین کار این است که با استفاده از تابع sort() آرایه را تنظیم کنیم. پس بهطور طبیعی بزرگترین عنصر آرایه، آخرین عنصر آرایه تنظیم شده خواهد بود. میتوانید در کد پایین پیادهسازی این روش را مشاهده کنید.
خروجی کد بالا به صورت زیر است.
Largest in given array 9808این مسئله را با روشهای دیگری مانند استفاده از تابع reduce()یا تکنیک تعریف تابع Lambda نیز میتوان حل کرد.
اجرای عملیات چرخش آرایه ها
در تصویر زیر نمایشی از چرخش آرایهها را میبینید.
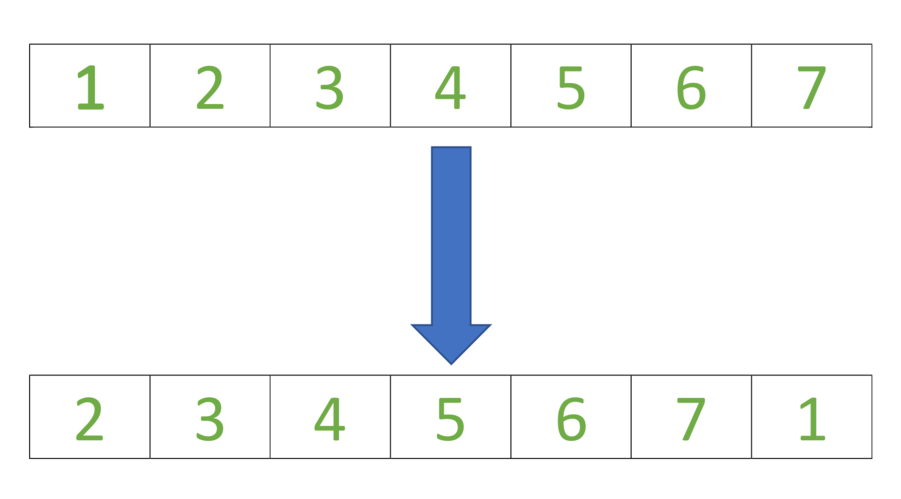
در این روش، هدف چرخاندن عناصر داخل آرایهها به صورت پیشفرض از از راست به چپ است. همانطور که در تصویر بالا دیدید.
برای حل این مسئله از چهار روش مختلف فهرست شده در زیر استفاده کردهایم.
- روش عادی کدنویسی برای حل مسئله
- چرخاندن عناصر آرایه با استفاده از لیست temp
- چرخش عناصر آرایه به صورت یک به یک
- چرخش آرایه با استفاده از الگوریتم چهارگانه Juggling
ارائه کدهای پایتون آماده برای حل این مسئله را از روش اول شروع میکنیم.
روش عادی کدنویسی برای حل مسئله
در این روش از عملیات قطعهبندی آرایه اصلی به زیرمجموعههای کوچک و معکوس کردن آنها استفاده میکنیم. فرایند حل مسئله به صورت مرحله بندیشده زیر است. برای شروع فرض کنید آرایه arr[] = [1, 2, 3, 4, 5, 6, 7, 8] را در اختیار داریم.
- در ابتدا کل لیست را با جابهجا کردن اعداد اول و آخر لیست معکوس میکنیم.
- سپس اولین زیر مجموعه را انتخاب میکنیم. اولین زیر مجموعه، از خانه اول لیست تا خانه یکی مانده به آخر لیست را شامل میشود.
- بعد از آن دوباره زیر مجموعه شماره یک را معکوس میکنیم.
- دفعه بعد زیر مجموعه شماره دو را انتخاب میکنیم و آن را معکوس میکنیم.
- و این کار را میتوانیم تا آخر انجام بدهیم تا لیست بهطور کامل یک بار بچرخد.
برای درک بهتر الگوریتم بالا به تصویر زیر نگاه کنید.
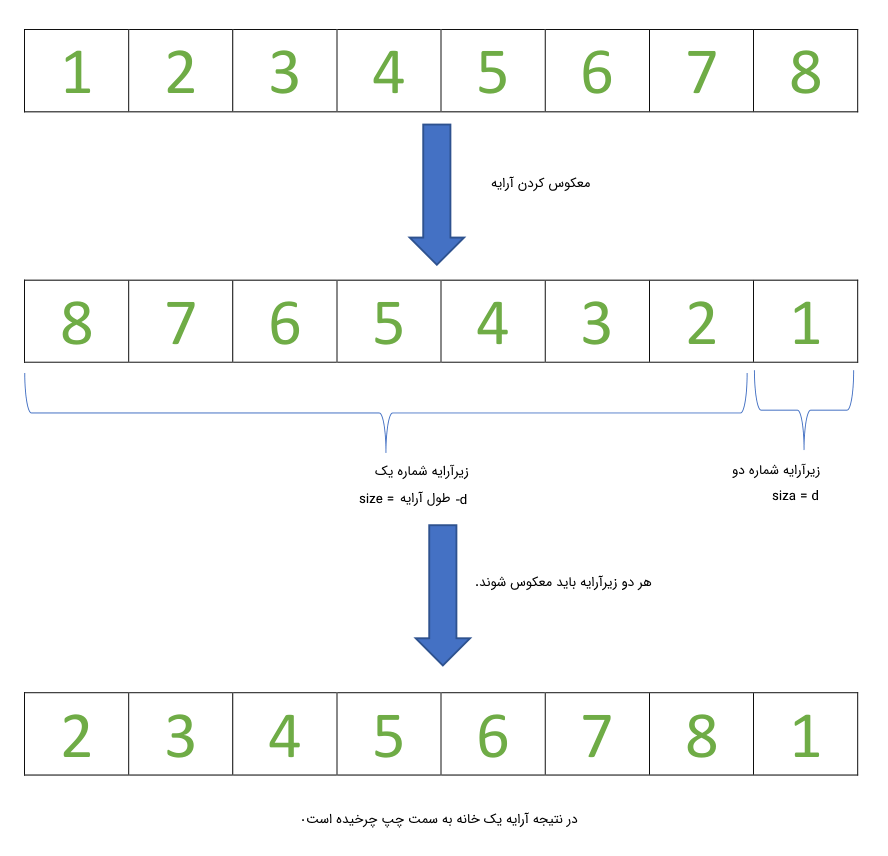
کد آمده در پایین فرایند ذکر شده بالا را به صورت یک برنامه پایتون پیادهسازی کرده است.
خروجی کد بالا به صورت زیر است.
Original array: [1, 2, 3, 4, 5, 6, 7, 8]
Rotated array: [2, 3, 4, 5, 6, 7, 8, 1]چرخاندن عناصر آرایه با استفاده از لیست temp
در این روش تابع rotate(ar[], d, n) را تعریف میکنیم که آرایه arr[] با اندازه n را به تعداد d عنصر میچرخاند.

چرخاندن آرایهای که در بالا میبینید به اندازه ۲ خانه آرایه را به شکل زیر میسازد.

فرایند حل مسئله با این روش به صورت زیر است.
- در ابتدا برنامه، آرایه ورودی را به همراه اندازه و تعداد خانهای که باید بچرخد، دریافت میکند. مانند arr[] = [1, 2, 3, 4, 5, 6, 7] و d = 2 و n =7
- عناصر مربوط به d را که همان عناصری اند که باید بچرخند و از انتهای آرایه وارد شوند را در لیست temp ذخیره میکند. temp[] = [1, 2]
- بقیه عناصر آرایه را به سمت راست حرکت میدهد. arr[] = [3, 4, 5, 6, 7, 6, 7]
- عناصر d را در انتهای آرایه دوباره وارد میکند. arr[] = [3, 4, 5, 6, 7, 1, 2]
در ادامه کدهای پایتون آماده مربوط به فرایند بالا را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
Array after left rotation is: [3, 4, 5, 6, 7, 1, 2]چرخش عناصر آرایه به صورت یک به یک
برای اینکه بتوانیم عناصر آرایه را به صورت یک به یک بچرخانیم باید مقدار خانه arr[0] را در متغیر موقتی temp ذخیره کنیم. سپس مقدار موجود در خانه arr[1] را به خانه arr[0] انتقال دهیم و مقدار موجود در خانه arr[2] را به خانه arr[1] انتقال دهیم. این رفتار را ادامه میدهیم تا آخر که مقدار درون متغیر temp را به خانه arr[n-1] انتقال بدهیم.

به عنوان مثال اگر آرایه arr[] = [1, 2, 3, 4, 5, 6, 7] به همراه d = 2 بابت اندازه چرخش آرایه در متن سوال آمده باشد. d = 2به معنای چرخش آرایه به اندازه دو خانه است. در ابتدا که آرایه را به صورت یک به یک میچرخانیم، بعد از حرکت اول آرایه به شکل [2, 3, 4, 5, 6, 7, 1] در میآید و بعد از حرکت دوم آرایه بهشکل [ 3, 4, 5, 6, 7, 1, 2] در میآید.
میتوانید کدهای مربوط به پیادهسازی این روش حل مسئله را در پایین ببینید.
خروجی کد بالا به صورت زیر است.
3 4 5 6 7 1 2
چرخش آرایه با استفاده از الگوریتم چهارگانه Juggling
این روش حالت گسترشداده شدهای از روش دوم است. بهجای اینکه یک به یک خانهها را حرکت بدهیم آرایه را به مجموعههای جداگانهای تقسیم میکنیم. تعداد مجموعهها برابر با «بزرگترین مقسوم علیه مشترک» (GCD) است و باید عناصر را درون مجموعهها جابهجا کنیم. اگر بزرگترین مقسوم علیه مشترک یا GCD برابر 1 باشد، همانطور که برای مثال بالا بود -GCD بین n = 7 وd =2 برابر 1 است- پس عناصر فقط درون یک مجموعه جابهجا میشوند. ما فقط کافی است که با temp = arr[0] شروع کنیم و به جابهجا کردن مقادیر از خانهarr[I+d] به خانه arr[I] بپردازیم و در نهایت مقدار متغیر temp را در جایگاه درست آن جایگذاری کنیم.
برای مثال فرض کنید که آرایهای به شکل زیر در اختیار داریم. در این آرایه مقدار nبرابر با ۱۲ و مقدار d برابر با ۳ است. پس GCD نیز برابر با ۳ است.
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}در مرحله اول عناصر را در مجموعه اول جابهجا میکنیم. به دیاگرام زیر درباره این حرکت توجه کنید.

آرایه arr[] بعد از مرحله بالا به شکل زیر در میآید.
{4 2 3 7 5 6 10 8 9 1 11 12} بعد همین کار را در مرحله دوم تکرار میکنیم و آرایه به شکل زیر در میآید.
{4 5 3 7 8 6 10 11 9 1 2 12}در نهایت در مرحله سوم آرایه به شکل پایین میشود.
{4 5 6 7 8 9 10 11 12 1 2 3}فرایند بالا را به صورت زیر در کدهای پایتون آماده کردهایم.
خروجی کد بالا به صورت زیر است.
3 4 5 6 7 1 2الگوریتم واژگون سازی برای چرخش آرایه
در این بخش از مطلب، الگوریتم Reversal را برای چرخاندن آرایهها بررسی و کدهای مربوط به این فرایند را پیادهسازی میکنیم. در مسئله استفاده از «الگوریتم واژگونسازی» (Reversal Algorithm) برای چرخش آرایه ابتدا باید تابعی برای چرخش آرایه بهشکل rotate(arr[], d, n) تعریف کنیم. این تابع باید آرایه arr[] را با تعداد n عنصر به اندازه d بچرخاند.
فرض کنید آرایهای بهشکل زیر در اختیار داریم.
arr[] = [1, 2, 3, 4, 5, 6, 7]بعد از اینکه آرایه بالا را به اندازی ۲ واحد بچرخانیم آرایه زیر بدست میآید.
arr[] = [3, 4, 5, 6, 7, 1, 2] برای پیادهسازی الگوریتم واژگونسازی چرخش آرایه کدهای زیر را نوشتهایم.
خروجی کد بالا به صورت زیر است.
[3, 4, 5, 6, 7, 1, 2]جدا کردن ابتدای آرایه و اتصال آن به انتهای آرایه
به تصویر زیر نگاه کنید. در بخش بالای این تصویر آرایهای را میبینید که قسمت ابتدای آرایه از آن باید جدا شود و طبق بخش پایینی تصویر به قسمت انتهای آرایه بچسبد.

این مسئله را به سه روش مختلف فهرست شده در زیر، حل خواهیم کرد اما روشهای بیشتری نیز برای حل این مسئله میتوان پیدا کرد.
- روش اول: استفاده از تکنیکهای عادی کدنویسی پایتون
- روش دوم: استفاده از روش List Comprehension
- روش سوم: استفاده از ماژول deque موجود در کتابخانه collections
نمایش کدهای پایتون آماده برای حل این مسئله را از روش اول شروع میکنیم.
استفاده از تکنیک های عادی کدنویسی پایتون
در این روش برای جدا کردن قسمتی از ابتدای آرایه و انتقال آن به انتهای آرایه از روش «برش زدن» (Slicing) لیستها استفاده میکنیم. به کد نوشته شده در زیر دقت کنید.
خروجی کد بالا به صورت زیر است.
5 6 52 36 12 10
استفاده از روش List Comprehension
یکی از رویکردهای مورد استفاده برای حل این مسئله، تقسیم آرایه به دو بخش و اتصال بخش اول به انتهای بخش دوم است. این عملیات بهطور متداولی در برنامهنویسی مورد استفاده قرار میگیرد و برای استفاده در انواع گستردهای از برنامهها مانند چرخاندن عناصر آرایهها یا پیادهسازی بافرهای حلقهای، میتواند مفید باشد.

فرایند حل این مسئله را در چهار مرحله به صورت قدم به قدم توصیف میکنیم.
- تابعی به شکل split_and_add(arr, n) تعریف میکنیم که در آن پرامتر arr نمایانگر آرایهای است که میپذیرد. پارامتر n نیز نمایانگر عدد صحیحی است که از ورودی میگیرد.
- اندازه طول آرایه ورودی را با استفاده از تابع len در پایتون محاسبه میکنیم و درون متغیری به نام arr_len ذخیره میکنیم.
- از روش «List Comprehension» استفاده میکنیم تا لیستی تعریف کنیم که به اندازه آرایه ورودی باشد. هر عنصر لیست جدید با استفاده از فرمول (i + n) % arr_len محاسبه میشود. در این فرمول i شماره ایندکس عنصر موجود در آرایه ورودی است. لیست جدید را به عنوان خروجی تابع برمیگردانیم.
- خروجی تابع را در متغیری به نام result قرار داده و در نهایت بر بروی خروجی به کاربر نمایش میدهیم.
کد لازم برای پیادهسازی مراحل بالا به صورت زیر است.
خروجی کد بالا به صورت زیر است.
5 6 52 36 12 10استفاده از ماژول deque موجود در کتابخانه collections
در این سری از کدهای پایتون آماده از ماژول deque استفاده میکنیم. ماژول deque یکی از ابزارهای خاص پایتون است که برای ساخت لیست استفاده میشود. این الگوریتم را در پنج مرحله پیادهسازی میکنیم. مراحل اجرای این الگوریتم به صورت زیر است.
- ماژول deque را از کتابخانه collections به محیط کدنویسی خود Import میکنیم.
- تابعی به نام splitArr() تعریف میکنیم که پارامترهای آرایه a را به همراه طول آرایهn و عدد صحیحی با علامتk به عنوان ورودی میپذیرد.
- با استفاده از متد سازنده deque() یک شی از کلاس deque با نام q تعریف میکنیم.
- شی q از کلاس deque را به اندازه k موقعیت با استفاده از تابع rotate() میچرخانیم. این عملیات بهطور کارآمدی تعداد Kعدد از عناصر آرایه را به انتهای deque حرکت میدهد عناصر باقی مانده را به ابتدای آرایه انتقال میدهد.
- با استفاده از متد سازنده list()شی deque به نام q را دوباره به لیست تبدیل میکنیم و نتیجه را برمیگردانیم.
در برنامه اصلی آرایه arr را مقداردهی میکنیم. طول این آرایه به مقدار n خواهد بود. همچنین متغیری برای موقعیت به نام Kتعریف میکنیم. تابع splitArr() را به همراه پارامترهای ورودی arrبه عنوان آرایه، n به عنوان طول آرایه و Kبه عنوان موقعیت درون آرایه که باید تغییر کند، فراخوانی میکنیم.
در نهایت بر روی آرایه نتیجه گرفته شده از عملیات بالا پیمایش میکنیم و همه عناصر را نمایش میدهیم. در ادامه به کدی که از الگوریتم بالا پیادهسازی شده توجه کنید.
خروجی کد بالا به صورت زیر است.
5 6 52 36 12 10پیدا کردن باقی مانده تقسیم حاصل ضرب همه اعضای آرایه در یکدیگر بر n
در این مسئله آرایهای از اعداد به همراه عدد n داده شده است. مسئله این است که اول همه اعضای آرایه را در یکدیگر ضرب کنیم. سپس حاصل ضرب را بر عدد n تقسیم کنیم و باقیمانده را برگردانیم.
به عنوان مثال فرض کنیم که آرایه arr[] = {100, 10, 5, 25, 35, 14} به همراه n=11 داده شده است. فرایند راه حل محاسبه جواب به صورت زیر است.
Explanation: 100 x 10 x 5 x 25 x 35 x 14 = 61250000 % 11 = 9
Output: 9مثال بعدی را برای آرایه arr[] = {100, 10} به همراه n = 5 ببینید.
Explanation: 100 x 10 = 1000 % 5 = 0
Output : 0
این مسئله را به سه روش مختلف حل خواهیم کرد. روشهای مورد نظر را در فهرست زیر نامبردهایم.
- پیدا کردن باقیمانده تقسیم n بر حاصل ضرب اعضای آرایه با رویکرد ساده
- استفاده از رویکرد ساده با جلوگیری از «سرریز» (Overflow) برای اعداد بزرگ
- حل مسئله با استفاده از متد «functools.reduce»

برای ادامه مطلب، از سادهترین روش که همان اولین روش است به حل مسئله خواهیم پرداخت.
پیدا کردن باقیمانده تقسیم n بر حاصل ضرب اعضای آرایه با رویکرد ساده
در این روش کافی است که بهسادگی در ابتدای کار همه اعضای آرایه را در یکدیگر ضرب کنیم، سپس با کمک عملگر ٪ باقیمانده مقدار حاصل ضرب را در عدد n بدست میآوریم. اما نقطه ضعف این روش این است که برای اعداد بزرگتر از 2^64 جواب اشتباه میدهد.
در پایین کدهای آماده پایتون را برای این روش نمایش دادهایم.
خروجی کد بالا برابر با عدد 9 است.
استفاده از رویکرد ساده با جلوگیری از سرریز برای اعداد بزرگ
در این روش برای اینکه از سرریز جلوگیری کنیم در ابتدا باقیمانده همه اعضای آرایه را بر عدد n محاسبه میکنیم. سپس باقیماندهها را در یکدیگر ضرب میکنیم و در نهایت از نتیجه این ضرب دوباره مقدار باقیمانده تقسیم بر n را بدست میآوریم. به کمک این روش از سرریز بهطور کامل جلوگیری میشود. از آنجا که در ریاضیات عبارتها خواصیت ماژولار دارند این روش به خوبی کار میکند. در واقع ما طبق فرمول زیر جواب را محاسبه میکنیم.
( a * b) % c = ( ( a % c ) * ( b % c ) ) % cدر ادامه کدهای آماده پایتون را برای این روش ارائه دادهایم.
خروجی کد بالا برابر با عدد 9 است.
حل مسئله با استفاده از متد functools.reduce
در این روش ما از تابع reduce در کتابخانه functoolsاستفاده میکنیم تا همه عناصر درون آرایه دریافت شده را در یکدیگر ضرب کنیم. بعد از هر عمل ضرب باقیمانده تقسیم را بر عدد n بدست میآوریم. کدنویسی این روش را در کد پایین میبینید.
خروجی این کد به صورت زیر است.
9
0
بررسی یکنواخت بودن آرایه
در این مسئله فرض بر این است که آرایه A شامل n تعداد عدد صحیح داده شده است. سوال اینجاست که باید بررسی کنیم آیا این آرایه «یکنواخت» (Monotonic) است یا نه. آرایهای «یکنواخت» (Monotonic) است که عناصر آن آرایه با آهنگ دائم و بهطور یکنواختی کم یا زیاد شوند.

یا به این صورت میتوان تعریف کرد که: آرایه A یکنواخت افزایشی است اگر برای همه i-های کوچکتر مساوی j i <= j رابطه A[i] <= A[j] برقرار باشد و آرایه A یکنواخت کاهشی است اگر برای همه i-های کوچکتر مساوی j i <= j رابطه A[i] >= A[j] برقرار باشد.
نوع داده برگشتی برنامه حل این مسئله از نوع Boolean است. اگر آرایه داده شده Monotonic باشد مقدار True و اگر آرایه داده شده Monotonic نباشد مقدار False برمیگردد. بهعنوان مثالی از آرایهها و خروجی برنامه به نمونه زیر نگاه کنید.
Input : 6 5 4 4
Output : true
Input : 5 15 20 10
Output : falseبرای حل این مسئله از سه نمونه پیادهسازی شده متفاوت کدهای پایتون آماده استفاده کردهایم.
- استفاده از توابع sort و extend
- کدنویسی تعریف Monotonic
- به وسیله بررسی طول آرایه
نمایش این نمونه کدهای پایتون آماده را از روش اول شروع میکنیم.
استفاده از توابع sort و extend
برای حل مسئله به این روش کل فرایند را در ۴ بخش کلی دستهبندی کردهایم.
- در ابتدا با استفاده از تابع extend() آرایه گرفته شده را در دو آرایه متفاوت کپی میکنیم.
- آرایه اول را با استفاده از تابع sort() به ترتیب افزایشی یا «صعودی» (Ascending) منظم میکنیم.
- آرایه دوم را با استفاده از تابع sort(reverse=True) به ترتیب کاهشی یا «نزولی» (Descending) منظم میکنیم.
- اگر آرایه گرفته شده با یکی از دو آرایه برابر بود نتیجه میگیریم که آرایه «یکنواخت» (Monotonic) است.
در پایین میتوانید شکل کدنویسی شده این مراحل چهارگانه را ببینید.
خروجی کد بالا برابر با مقدار True است.
کدنویسی تعریف Monotonic
آرایهای «یکنواخت» (Monotonic) است اگر و تنها اگر که به صورت متناوبی کاهشی یا به صورت متناوبی افزایشی باشد. از آنجا که اگر p <= q باشد و q <= r باشد میتوان نتیجه گرفت که p <= r است. بنابراین تنها کاری که باید بکنیم این است که عناصر مجاور یکدیگر را بررسی کنیم تا بفهمیم که آیا آرایهای یکنواخت -افزایشی یا کاهشی- است یا نه. میتوان هر دوی این ویژگیها را به صورت همزمان در یک پیمایش بررسی کرد.
برای اینکه بررسی کنیم آیا آرایه A به صورت «یکنواختی افزایشی» (Monotonic Increasing) است باید رابطه A[i] <= A[i+1] را برای همه i-ها از ایندکس 0 تا len(A)-2 بررسی کنیم. به همینصورت میتوانیم «یکنواختی کاهشی» (Monotonic Decreasing) را با بررسی رابطه A[i] >= A[i+1] برای همه i-ها از ایندکس 0 تا len(A)-2بررسی کنیم.
توجه کنید: آرایهای که فقط یک عضو دارد به صورت همزمان هم یکنواخت کاهشی و هم یکنواخت افزایشی است. بنابراین مقدار True برمیگرداند.
رویکرد بالا را برای حل مسئله در کدهای پایین پیادهسازی کردهایم.
خروجی کد بالا برابر با مقدار True است.
بررسی یک نواختی به وسیله اندازه گیری طول آرایه
در این روش اول از همه بررسی میکنیم که ایا طول آرایه کوچکتر یا مساوی ۲ است یا نه. در صورتی که طول آرایه کوچکتر یا مساوی ۲ باشد برنامه مقدار True برمیگرداند. بعد از آن متغیر direction را به اندازه اختلاف بین دو عنصر اول آرایه مقداردهی میکند. سپس در طول بقیه آرایه شروع به پیمایش میکند و به هر عنصر که میرسد بررسی میکند که با توجه به مسیر پیمایش نسبت به عنصر قبلی بزرگتر است یا کوچکتر. اگر عنصری وجود داشت که با روال حرکت پیمایش آرایه نسبت به عنصر قبلی همخوانی نداشت، برنامه مقدار False برمیگرداند. اگر تابع حلقه را به اتمام رساند بدون اینکه مقدار Falseبرگرداند، پس باید مقدار Trueرا به خروجی گرداند.

به کدی که در ادامه از پیادهسازی این روش بدست آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
True
True
True
False
به این نکته توجه کنید که این برنامه فرض را بر این میگذارد که آرایه داده شده لیستی از اعداد «صحیح» (Integer) است. اگر آرایه داده شده شامل نوع دادههای دیگری باشد بهطوری که مورد انتظار است کار نخواهد کرد.
در ادامه بررسی کدهای پایتون آماده به دیدن و تمرین بر روی برنامههای مربوط به لیستها خواهیم پرداخت.
کدهای پایتون آماده برای کار با لیست ها
در این بخش تلاش کردیم انواع کدهای مربوط به کار با لیستها را جمعآوری و بررسی کنیم. لیستها از ساختارهای بنیادین ذخیره داده در پایتون هستند که میتوان گفت شاید حتی پرکاربردترین ساختار ذخیره داده در پایتون باشند. محدودیت اندازه ندارند، ناهمگون هستند، قابل تغییر و اصلاحاند و میتوانند موارد تکراری نیز بپذیرند.

جابه جا کردن عناصر اول و انتهای لیست با هم
در این مسئله لیستی داده شده و باید برنامهای بنویسیم که عناصر ابتدا و انتهای لیست را با یکدیگر جابهجا کند. به مثال زیر توجه کنید.
Input : [12, 35, 9, 56, 24]
Output : [24, 35, 9, 56, 12]
Input : [1, 2, 3]
Output : [3, 2, 1]روشهای بسیار زیادی برای انجام این عملیات بر روی لیست وجود دارد ولی از آنجا که تقریبا مثالهایی شبیه به این مسئله را در بخش آرایهها حل کردیم فقط به ذکر سادهترین روش با استفاده از کدهای معمولی پایتون میپردازیم. برای این کار طول لیست را پیدا میکنیم و به سادگی عنصر اول را با عنصر «n-1» در لیست جابهجا میکنیم.
به کدی توجه کنید که از روی روش توضیح داده شده بالا پیادهسازی کردیم.
خروجی کد بالا به صورت زیر است.
[24, 35, 9, 56, 12]جابه جا کردن دو عنصر مختلف در جایگاه های مختلف در لیست
در این مسئله لیستی در پایتون داده شده است به همراه دو عدد که نماد جایگاه برای دو عنصر مختلف هستند. این دو عدد به شماره ایندکس اشاره نمیکنند. باید برنامهای بنویسیم که این دو عنصر را در لیست با یکدیگر جابهجا کند. فرض کنید لیست [23, 65, 19, 90] داده شده است به همراه موقیعتهایpos2 = 3 و pos1 = 1 خروجی این برنامه باید لیستی بهشکل[19, 65, 23, 90] باشد.

این مسئله را به چهار روش مختلف حل خواهیم کرد و کدهای پایتون آماده برای این روشها را نمایش میدهیم.
- جابهجایی دو عنصر مختلف با استفاده از عملگر کاما و تخصیص یا کاما-مساوی
- استفاده از تابع درونی list.pop() برای جابهجایی عناصر مختلف
- جابهجایی دو عنصر مختلف با استفاده از متغیر Tuple
- جابهجایی دو عنصر مختلف با استفاده از تابع enumerate()

بررسی کدهای پایتون آماده را برای این مسئله از روش اول شروع میکنیم.
جابه جایی دو عنصر مختلف با استفاده از عملگر کاما و تخصیص
از آنجا که موقعیت عناصر شناخته شده است میتوانیم به آسانی موقعیت این عناصر را جابهجا کنیم. برای انجام این عملیات از یکی از میانبرهای ارائه شده توسط پایتون استفاده میکنیم. به کدی که در ادامه آمده دقت کنید.
خروجی کد بالا به صورت زیر است.
[19, 65, 23, 90]جابه جایی دو عنصر مختلف با استفاده از تابع درونی list.pop
برای حل مسئله با کمک تابع pop() فقط کافی است که عنصری که در موقعیت pos1 قرار دارد را بیرون بکشیم و در متغیری ذخیره کنیم به همین صورت، عنصری که در موقعیت pos2 قرار دارد را نیز بیرون بکشیم و در متغیر دیگری ذخیره کنیم. الان میتوانیم هر دو عنصر را در مکان مرتبط با دیگری وارد کنیم. به کدی که درپایین از این فرایند پیادهسازی شده نگاه کنید.
خروجی کد بالا به صورت زیر است.
[19, 65, 23, 90]جابه جایی دو عنصر مختلف با استفاده از متغیر Tuple
برای این کار مقادیر موجود در جایگاههای pos1 وpos2 را به عنوان یک جفت داده در متغیر Tuple پایتون ذخیره کنید. نام این متغیر را به صورت دلخواه get گذاشتیم. سپس هر دو عنصر را از متغیر خارج کرده و با جایگاههای مختلف در لیست وارد کنید. اکنون جایگاه این دو مقدار در لیست تغییر کرده است.
به کدی پیادهسازی شده در پایین توجه کنید.
خروجی کد بالا به صورت زیر است.
[19, 65, 23, 90]جابه جایی دو عنصر مختلف با استفاده از تابع enumerate
روش دیگری که برای جابهجای عناصر مختلف در لیست وجود دارد استفاده از تابع enumerate() است که به صورت همزمان ایندکس و مقدار هر عنصر را در لیست استخراج میکند. در این متد از حلقهای برای پیدا کردن عناصری که باید جابهجا شوند استفاده میکنیم و آنها را باهم جابهجا میکنیم.
به کدی که در ادامه از روی این روش حل مسئله نوشته شده نگاه کنید.
خروجی کد بالا به صورت زیر است.
[19, 65, 23, 90]روش های مختلف پیدا کردن طول لیست
لیستها قسمتی جداییناپذیر از برنامهنویسی پایتون هستند. بناربراین، هرکسی که با پایتون کار میکند باید روش کار با لیستها را نیز بیاموزد. داشتن دانش کافی درباره استفاده و عملیات مرتبط با لیست بسیار ضروری و مفید است.
عملیات زیادی برای اجرا با لیستها ارائه شدهاند اما در این مطلب درباره طول لیستها بحث خواهیم کرد. طول لیست به معنی تعداد عناصر تشکیلدهنده لیست است. در این مطلب سه روش مختلف را برای پیدا کردن طول لیستها بررسی خواهیم کرد. اما در نظر داشته باشید برای اینکار روشهای دیگری هم قابل طراحی و اجرا هستند.

روشهایی که در این بخش از کدهای پایتون آماده برای پیدا کردن طول لیست پیادهسازی شده شامل موارد زیر هستند.
- استفاده از تابع len()
- استفاده از روش ساده
- استفاده از تابع length_hint()
بررسی تکنیکهای پیدا کردن طول لیست را از روش اول یعنی تابع len()شروع میکنیم.
استفاده از تابع len برای پیدا کردن طول لیست
تابع len() یکی از توابع درونی پایتون است. از این تابع میتوان برای پیدا کردن طول هر شی استفاده کرد. شی مورد نظر را باید به عنوان پارامتر به این تابع ارسال کرد. استفاده از این تابع کدنویسی بسیار سادهای نیز دارد. به کد آمده در پایین توجه کنید.
خروجی کد بالا بهصورت زیر است.
The length of list is: 3استفاده از روش ساده برای پیدا کردن طول لیست
به سادگی فقط کافی است که لیست را به کمک حلقهای مورد پیمایش قرار دهیم و شمارندهای تعریف کنیم که با هربار چرخیدن حلقه یک شماره اضافه شود. وقتی که حلقه به پایان برسد و به آخرین عنصر لیست برسیم مقدار شمارنده برابر با اندازه لیست خواهد بود. این روش پایهایترین راهبردی است که در صورت عدم حضور سایر تکنیکهای ممکن احتمالا بهکار میرود. در پایین این روش را کدنویسی کردهایم.
خروجی حاصل از کد بالا به صورت زیر است.
The list is : [1, 4, 5, 7, 8]
Length of list using naive method is : 5استفاده از تابع length_hint برای پیدا کردن طول لیست
این روش یکی از روشهای کمتر شناخته شده برای شناسایی طول لیستها است. این متد خاص در کلاس operator تعریف شده است و میتواند تعداد عناصر حاضر در لیست را نیز محاسبه کند. در این بخش ما با استفاده از توابع len() و length_hint() طول لیست را پیدا خواهیم کرد.
به کدی که در ادامه آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
The list is : [1, 4, 5, 7, 8]
Length of list using len() is : 5
Length of list using length_hint() is : 5جست وجو به دنبال عنصر خاصی در لیست
لیستها یکی از مهمترین ساختارهای ذخیره داده در پایتون هستند که میتوانند عناصر هر نوع دادهی دیگری را در خود نگهداری کنند. داشتن دانش درباره عملیات مشخص و رایجی که توسط لیستها قابل انجام است برای برنامهنویسی روزانه ضروری است.

در این بخش از کدهای پایتون آماده، چهار روش از سریعترین روشها را برای بررسی وجود داشتن عنصر مشخصی در لیستها پیادهسازی کرده و توضیح میدهیم. این روشها را در ادامه فهرست کردهایم.
- استفاده از عبارت in
- استفاده از حلقه برای بررسی لیست
- استفاده از تابع any()
- استفاده از تابع count()
برای انجام این عملیات روشهای دیگری مانند استفاده از تابع sort() ، find() و غیره هم وجود دارند که البته میتوانید با کمی خلاقیت یا جستوجو در اینترنت از این روشها هم استفاده کنید. این بخش را با استفاده از عبارت inشروع میکنیم.
استفاده از عبارت in
در این روش فقط کافی است که از عبارت in استفاده کنیم. البته در این بخش از عبارت inدرون یک بلاک شرطی استفاده کردهایم که این کار اجباری نیست. این روش آسانترین روش برای بررسی وجود آیتم مشخص شدهای در لیست است. استفاده از این روش در زبان برنامهنویسی پایتون مرسومترین روش برای بررسی لیستها و محتویات درونی آنها است.
در صورتی که عنصر مورد جستوجو در لیست وجود داشته باشد این برنامه مقدار Trueو اگر عنصر در لیست وجود نداشته باشد مقدار False برمیگرداند. برای کار کردن با این روش بررسی، نیازی نیست که لیست را منظم کنیم. به کد پیادهسازی شده این برنامه در ادامه توجه کنید.
خروجی کد بالا به صورت زیر است.
not existاستفاده از حلقه برای بررسی وجود آیتم خاصی در لیست
کد پایتونی که در این مثال داده شده در ابتدا لیستی به نام test_list را با چند «عدد صحیح» (Integer) مقداردهی میکند. سپس با کمک حلقه forبر روی همه عناصر درون لیست پیمایش میکند. بر روی هر عنصر با بهکار بردن عبارت شرطی if چک میکند که آیا محتوای عنصر iبا مقدار 4 برابر است یا نه. عدد 4 اینجا فقط گزینهای فرضی و آزمایشی است که در لیست به دنبالش میگردیم. اگر که شرط برقرار بود و عنصری پیدا شد که مقدار برابر 4 داشت برنامه جمله «Element Exists» را در خروجی نمایش میدهد. فقط بهشرط موجود بودن آیتمی که به دنبال آن میگردیم در لیست، برنامه این خروجی را نمایش میدهد. در لیست آزمایشی ما [1, 6, 3, 5, 3, 4] این جمله بر روی خروجی نمایش داده خواهد شد.
در ادامه به کد زیر توجه کنید. کد زیر را از روی برنامه توصیف شده در بالا نوشتهایم.
چون به دنبال عدد 4 میگشتیم و این عدد هم در لیست موجود بود، خروجی کد بالا به صورت زیر است.
Element Existsاستفاده از تابع any برای بررسی وجود داشتن آیتم در لیست
در این روش با استفاده از تابع any() همراه با عبارت «مولد» (Generator) به بررسی عناصر درون لیست برای پیدا کردن جواب میپردازیم. عبارت Generator بر روی همه اعضای لیست test_listپیمایش و بررسی میکند که آیا این عنصر بیشتر از یکبار در لیست ظاهر شده است یا نه. نتایج این بررسی لیست در متغیری به نام result ذخیره میشود. در نهایت، کد پیامی را نمایش میدهد که به وضعیت تکرار عنصرها درون لیست اشاره میکند. اگر عنصر خاصی درون لیست تکرار شده باشد پیام « Does string contain any list element: True» را نمایش میدهد و اگر عنصر تکراری درون لیست پیدا نکند پیام «Does string contain any list element: False» را نمایش میدهد.

به کدی که در ادامه از روی توصیف عملیات بالا پیادهسازی شده است توجه کنید.
خروجی کد بالا به صورت زیر است.
Does string contain any list element : Trueبررسی وجود داشتن عنصر خاص در لیست با استفاده از تابع count
میتوانیم برای بررسی اینکه آیا عنصر ارسال شده در لیست موجود است یا نه از متدهای دورنی مخصوص لیستها در پایتون استفاده کنیم.
اگر عنصری که به برنامه داده شده در لیست موجود بود متد count() تعداد کل دفعاتی را که این عنصر در تمام لیست تکرار شده را نمایش میدهد. اگر خروجی متد count()عدد صحیح بزرگتر از صِفر بود به این معنی است که این عنصر در لیست وجود دارد.
در کد پایین روش استفاده از متد count() را برای بررسی وجود داشتن عنصر مشخص شده در لیست، پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
Checking if 15 exists in list
Yes, 15 exists in listروش های مختلف حذف عناصر داخل لیست یا خالی کردن لیست
در این مسئله باید لیستی را که در اختیار داریم بهطور کامل خالی کنیم. پس چند مدل از روشهای موجود برای حذف عناصر داخل لیست را باهم میبینیم. بهواسطه ساختارهای متنوعی که زبان برنامهنویسی پایتون ارائه میدهد، روشهای مختلفی نیز برای پاکسازی درون لیستها وجود دارد. در این بخش از مطلب به بررسی سه نوع مختلف از کدهای پایتون آماده این روشها میپردازیم.
- استفاده از متد clear()
- روش مقداردهی دوباره لیست
- روش استفاده از *= 0
حذف داده های درون لیست با استفاده از متد clear
در این روش از متد clear() برای حذف دادههای درون لیست استفاده میکنیم. این متد به صورت اختصاصی برای این کار تولید شده است و با کمترین کدنویسی این عملیات را انجام میدهد. در کد زیر استفاده از این متد را نمایش دادهایم.
خروجی کد بالا به صورت زیر است.
lst_test before clear: [6, 0, 4, 1]
lst_test after clear: []حذف داده های درون لیست با مقداردهی دوباره
در روش مقداردهی دوباره لیست، اینبار لیست را با مقدار هیچی initialize میکنیم. در واقع لیستی با اندازه 0 را مقداردهی میکنیم. کد آمده در پایین این روش را نشان میدهد.
خروجی کد بالا به صورت زیر است.
List1 before deleting is : [1, 2, 3]
List1 after clearing using reinitialization : []پاک کردن اعضای لیست با استفاده از عبارت 0=*
استفاده از عبارت *= 0 برای پاک کردن اعضای لیست روشی کمتر شناخته شده است. این روش همه اعضای داخل لیست را حذف میکند و باعث میشود لیست کاملا خالی شود. در واقع در این روش از عبارت تخصیص مرکب استفاده میکنیم. به این صورت که لیست را ضرب در 0 میکنیم و در خودش جایگذاری میکنیم. به کدی که در ادامه از پیادهسازی این روش بدست آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
List1 before clearing is : [1, 2, 3]
List1 after clearing using *=0 : []روش های معکوس کردن لیست
پایتون برای معکوس کردن لیستها روشهای متفاوتی را ارائه میدهد. در این بخش به چند روش مختلف از بین تعداد زیاد روشهای ممکن پرداختهایم. تکنیکهای معرفی شده در این مطلب را در ادامه فهرست کردهایم.
- استفاده از تکنیک «برش زدن» (Slicing)
- معکوس کردن لیست از طریق جابهجا کردن اعداد ابتدا و انتهای لیست
- استفاده از توابع درونی revese() و reversed() در پایتون
- معکوس کردن لیست با استفاده از ابزار کتابخانه Numpy

با بررسی روش اول این مبحث را شروع میکنیم.
معکوس کردن لیست با استفاده از روش Slicing
در این روش درحالی که لیست اصلی در جای خود دست نخورده باقیمانده است، کپی معکوسی از لیست اصلی ساخته میشود. ساخت کپی از لیست به فضای بیشتری برای نگهداری همه اعضای موجود در لیست احتیاج دارد. این تکنیک فشار بیشتری به حافظه میآورد. در کد پایتونی پایین روش استفاده از این تکنیک را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
[15, 14, 13, 12, 11, 10]در این روش با کمک خط کد new_lst = lst[::-1] لیست جدید به صورت معکوس از لیست قبلی ساخته میشود. از مزایای این روش میتوان به مقدار کد بسیار کوتاه اشاره کرد.
معکوس کردن لیست از طریق جابه جا کردن اعداد ابتدا و انتهای لیست
این رویکرد حل مسئله به این صورت است که اگر در لیست arr[] طول لیست برابر با یک واحد باشد، برنامه خود arrرا برمیگرداند و اگر طول لیست برابر با 2 واحد باشد برنامه عناصر اول و آخر لیست arrرا جابهجا میکند و لیست arrرا برمیگرداند. در غیر از این حالتها متغیر iرا با مقدار 0 مقداردهی میکنیم و در حلقه forبا محدوده size//2 شروع به پیمایش بر روی لیست میکنیم و اعضای اول و آخر محدوده را به شرط اینکه ایندکس اعداد اول و انتها برابر نباشند با یکدیگر جابهجا میکنیم. در حرکت بعد، ایندکسهای بعدی و قبل از آخری را با هم جابهجا میکنیم و مقدار iرا دو واحد افزایش میدهیم. در نهایت بعد از پیمایش حلقه، لیست arrرا برمیگردانیم.
به کد نوشته شده زیر نگاه کنید. کد زیر، پیادهسازی از الگوریتم توصیف شده بالا است.
نتیجه حاصل از کد بالا به صورت زیر است.
Original list: [1, 2, 3, 4, 5]
Reversed list: [5, 4, 3, 2, 1]استفاده از توابع درونی revese و reversed در پایتون
میتوانیم با استفاده از تابع reversed() لیستها را معکوس کنیم. از این تابع شی list_reverseiterator برمیگردد. با استفاده از تابع list() میتوان یک لیست جدید از شی list_reverseiterator ساخت. این لیست جدید شکل معکوس شده لیست قبلی است که به عنوان پارامتر به این تابع ارسال شده بود.

میتوان در پایتون از تابع revese() نیز استفاده کرد. این تابع هر لیستی را که بر روی آن اعمال شود معکوس میکند. فرق بین تابع revese() و تابع reversed() این است که تابع اول خود لیست را معکوس میکند ولی تابع دوم لیست اصلی را تغییر نمیدهد. در عوض، تابع reversed() شی جدیدی میسازد که قابل تبدیل به لیست معکوس شدهای طبق لیست اصلی است.
کدی که در پایین میبینید از هر دو تابع برای معکوس کردن لیست lst استفاده میکند.
خروجی کد بالا به صورت زیر است.
Using reverse() [15, 14, 13, 12, 11, 10]
Using reversed() [10, 11, 12, 13, 14, 15]معکوس کردن لیست با استفاده از کتابخانه Numpy
در این بخش از ابزار موجود در کتابخانه Numpy استفاده خواهیم کرد. کدهای پایتون آماده مربوط به برنامهای که در پایین میبینید مراحل اجرای کد پیادهسازی شده زیر را توضیح میدهند.
- در ابتدای کار لیست ورودی را با نام my_list مقداردهی کردهایم.
- با استفاده از تابع np.array(my_list) لیست my_list را به آرایهای یک بعدی از جنس آرایههای numpy تبدیل میکنیم و به متغیر my_array تخصیص میدهیم.
- با استفاده از تکه کد my_array[::-1] ترتیب چیدمان آرایه را برعکس میکنیم.
- آرایهی numpyمعکوس شده را با استفاده از متد .tolist() دوباره به لیست تبدیل میکنیم.
- در نهایت نیز لیست معکوس شده را برای نمایش در خروجی به تابع print() ارسال میکنیم.
به کدی که در ادامه آوردهایم دقت کنید.
خروجی کد بالا به صورت زیر است.
[9, 8, 7, 6, 5, 4]برنامه پایتون برای پیدا کردن مجموع عناصر لیست
در این مسئله فرض میکنیم که لیستی داده شده است. مسئله این است که: باید برنامهای طراحی کنیم که همه عنصر لیست را با یکدیگر جمع بسته و حاصل جمع را برگرداند.
برنامه طراحی شده، برای لیست فرضی [12, 15, 3, 10] باید خروجی برابر با 40 برگرداند. برای این مسئله دو راه حل را در این بخش از کدهای پایتون آماده کردهایم.
- روش برنامهنویسی عادی
- روش استفاده از تابع بازگشتی
روش برنامه نویسی عادی بدون استفاده از ابزار درونی پایتون
در این روش بسیار ساده، برنامه را با استفاده از حلقه forو متغیری به نام دلخواه total مینویسیم. متغیر totalبرای نگهداری مقدار حاصل جمع اعضای لیست بهکار میرود. به کد آمده در پایین دقت کنید.
خروجی کد بالا به صورت زیر است.
Sum of all elements in given list: 74استفاده از توابع بازگشتی
در این روش برای محاسبه حاصل جمع اعضای داخل لیست از توابع بازگشتی استفاده میشود. به کدی توجه کنید که از بابت پیادهسازی این روش در پایین آمده است.
خروجی کد بالا به صورت زیر است.
Sum of all elements in given list: 74ضرب همه اعضای لیست در یکدیگر
در این مسئله لیستی داده شده و باید مقدار بدست آمده از ضرب همه اعضای لیست در یکدیگر را بر روی خروجی نمایش دهیم. به عنوان نمونه، اگر لیست داده شده برابر با [1, 2, 3] باشد، در خروجی باید عدد 6 نمایشداده شود.

در پایتون برای حل چنین مسئلهای درباره ضرب اعضای داخل لیست رویکردهای متفاوتی وجود دارد. در این بخش ما چهار سبک متفاوت از کدهای پایتون آماده مربوط به متداولترین روشهای حل چنین مسئلهای را پیادهسازی کردهایم.
- استفاده از روش پیمایش
- استفاده از تابع numpy.prod()
- استفاده از تابع lambda
- استفاده از کتابخانه Math
نمایش روشهای مختلف حل مسئله ضرب اعضا در لیست را با روش اول شروع میکنیم.
استفاده از روش پیمایش
در این روش برای حل مسئله گفته شده بالا، ابتدا متغیری به نام دلخواه –در اینجا result - برای نگهداری حاصل ضرب با مقدار 1 تعریف میشود. توجه کنید که نباید متغیر مقدار صِفر داشته باشد زیرا حاصل ضرب صِفر در هر عددی برابر با صِفر است. سپس تا آخر لیست را پیمایش میکند و همه عناصر را در متغیر result ضرب میکند. در انتهای پیمایش لیست، مقداری که در متغیر result باقیمانده جواب اصلی سوال است.
در مثالی که برای این روش کدنویسی کردهایم درون تابع سفارشی multiplyList ، کد از رویکرد پیمایشی با استفاده از حلقه forاستفاده میکند. این پیمایش در محدوده خود لیست انجام میشود. به کمک پیمایش لیستها حاصل ضرب همه اعضای لیستهای [1, 2, 3] و [3, 2, 4] را بدست میآوریم و به ترتیب در خروجی نمایش میدهیم. به کد زیر نگاه کنید. کد زیر از پیادهسازی فرایند بالا ایجاد شده است.
خروجی کد بالا به ترتیب برابر با اعداد 6 و 24 است.
ضرب همه اعضای لیست در یکدیگر با استفاده از numpy.prod
میتوانیم بعد از import کردن کتابخانه Numpy از تابع numpy.prod() برای بدست آوردن حاصل ضرب همه اعداد درون لیست در یکدیگر استفاده کنیم. این تابع با توجه به نتیجهای که بدست میآورد میتواند مقدار عدد صحیح یا Float برگرداند.
در مثال پیادهسازی شده پایین، این کد با استفاده از تابع numpy.prod() اقدام به محاسبه حاصل ضرب عناصر درون لیستهای [1, 2, 3] و [3, 2, 4] میکند و به ترتیب جوابها را در خروجی نمایش میدهد. به کد پایین نگاه کنید.
خروجی کد بالا به ترتیب برابر با اعداد 6 و 24 است.
ضرب همه اعضای لیست در یکدیگر با استفاده از تابع lambda
تعریف تابع lambda به شکلی انجام شده که شامل عبارت return نمیشود. این تابع همیشه شامل عبارتی میشود که قرار است برگشت داده شود. میتوانیم از تابع lambda هرجایی که نیاز به حضور تابع است استفاده کنیم و هیچ نیازی هم به تخصیص دادن این تابع به متغیری وجود ندارد. این عوامل باعث سادگی کار با تابع lambda هستند. در صورتی که نسبت به تابع lambda نا آشنا هستید، مطلب تابعهای (Lambda) در پایتون از مجله فرادرس به صورت کاملا پایهای این تابع بسیار پرکاربرد و رایج در پایتون را توضیح داده است.
تابع reduce() در پایتون به عنوان آرگومان، لیستی را به همراه تابعی میپذیرد. در این روش حل مسئله تابع reduce() به عنوان ورودی، تابع lambda را به همراه یک لیست میپذیرد و نتیجه را به متغیرresult برمیگرداند. این رفتار به صورت تکراری بر روی هر دو لیست انجام میگیرد.

در نمونهای که برای حل مسئله به این روش از کدهای پایتون آماده کردهایم از تابع functools.reduce() به همراه تابع lambda برای ضرب کردن همه اعضای لیست درون یکدیگر استفاده میکنیم. در مثال زیر از لیستهای دلخواه [1, 2, 3] و [3, 2, 4] استفاده کردهایم.
خروجی کد بالا به ترتیب برابر با اعداد 6 و 24 است.
ضرب همه اعضای لیست در یکدیگر با استفاده از تابع prod از کتابخانه Math
اگر از پایتون 3.8 به بالا استفاده کنید تابع prod در ماژول math تعبیه شده است، پس نیازی به نصب کتابخانههای خارجی ندارید.
در این مثال، کد آمده پایین، تابع math.prod در پایتون را بهکار میبرد تا حاصل ضرب همه مقادیر لیستهای دلخواه [1, 2, 3] و[3, 2, 4] را در یکدیگر محاسبه کند. به کدی که در پایین آمده توجه کنید.
خروجی کد بالا به ترتیب برابر با اعداد 6 و 24 است.
پیدا کردن کوچکترین عدد لیست
در این مسئله لیستی از اعداد داده میشود و وظیفه ما این است که برنامه پایتون بنویسیم که کوچکترین عنصر لیست داده شده را پیدا کند.
برای حل این مسئله میتوانیم از روشهای گوناگونی استفاده کنیم. در این مطلب، کدهای پایتون آماده مربوط به سه روش متفاوت را برای پیدا کردن کوچکترین عدد لیست ارائه دادهایم. این روشها را در زیر فهرست کردیم.
- پیدا کردن کوچکترین عدد با کمک منظم کردن لیست
- استفاده از تابع min() برای پیدا کردن کوچکترین عدد در لیست
- مقایسه همه عناصر لیست با یکدیگر

این بخش از کدهای پایتون آماده درباره پیدا کردن کوچکترین عدد را با کمک منظم کردن لیست شروع میکنیم.
پیدا کردن کوچکترین عدد با کمک منظم کردن لیست
این روش را میتوان با منظم کردن لیست به ترتیب صعودی یا نزولی انجام داد. فقط باید توجه کرد که اگر به ترتیب صعودی لیست را منظم کنیم کوچکترین عنصر لیست همان اولین عنصر خواهد بود و اگر لیست را به ترتیب نزولی منظم کردیم، اینبار کوچکترین عنصر لیست عنصر آخر خواهد بود.
کد زیر مربوط به چیدن لیست بهصورت صعودی است.
خروجی کد بالا به صورت زیر است.
smallest element is: 4کد زیر هم مربوط به چیدن لیست بهصورت نزولی است.
خروجی کد بالا به صورت زیر است.
smallest element is: 4استفاده از تابع min برای پیدا کردن کوچکترین عدد در لیست
تابع min() یکی از توابع درونی پایتون است. این تابع برای پیدا کردن کوچکترین عضو ساختارهای داده پیمایشپذیر استفاده میشود. در کد زیر از این تابع برای پیدا کردن کوچکترین عنصر لیست استفاده کردیم.
خروجی کد بالا به صورت زیر است.
smallest element is: 1مقایسه همه عناصر لیست با یکدیگر
در این روش با کمک حلقه forبر روی همه اعضای لیست پیمایش میکنیم و یک به یک آنها را با یکدیگر مقایسه میکنیم. متغیری را با نام دلخواه min1 در این کد پیادهسازی کردهایم که از اولین عنصر لیست شروع به نگهداری میکند. در طول پیمایش لیست همه عنصرها را با متغیر min1مقایسه میکنیم. مقدار هر عنصری که از مقداری متغیر min1کوچکتر بود به متغیر min1اختصاص میدهیم.
به کدی که در پایین آمده نگاه کنید.
ورودی دلخواهی که به این برنامه میدهیم بهصورت زیر است.
List: 23,-1,45,22.6,78,100,-5خروجی حاصل از کد بالا به همراه ورودی داده شده بهشکل آمده در پایین تولید میشود.
The list is ['23', '-1', '45', '22.6', '78', '100','-5']
The smallest element in the list is -5پیدا کردن بزرگترین عدد در لیست
در این مسئله لیستی از اعداد داده میشود و وظیفه ما این است که برنامه پایتون بنویسیم که بزرگترین عنصر لیست داده شده را پیدا کند. برای حل این مسئله میتوانیم از روشهای گوناگونی استفاده کنیم. در این مطلب کدهای پایتون آماده مربوط به سه روش متفاوت را برای پیدا کردن بزرگترین عدد لیست ارائه دادهایم. این روشها را در زیر فهرست کردیم.
- سادهترین صورت حل مسئله با کمک تابع sort()
- استفاده از تابع max()
- پیدا کردن بزرگترین عدد در لیست بدون استفاده از توابع درونی

در ادامه، اول از همه به سادهترین صورت حل مسئله با کمک تابع sort()خواهیم پرداخت.
ساده ترین صورت حل مسئله با کمک تابع sort
برای این کار کافی است که فقط لیست را با کمک تابع sort منظم کنیم. در این حالت عناصر لیست به صورت پیشفرض در حالت صعودی چیده خواهند شد. پس آخرین عنصر لیست برابر با بزرگترین عنصر لیست هم خواهد بود.
به کدی که در ادامه از پیادهسازی این فرایند بدست آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
Largest element is: 99استفاده از تابع max
تابع max() هم یکی از توابع پایتون است که به صورت اختصاصی برای پیداکردن بزرگترین عنصر در ساختارهای داده پیمایشپذیر ارائه شده است. در مثال زیر از تابع max() برای پیدا کردن بیشترین عنصر در لیست list1استفاده میکنیم. این روش هم یکی از سادهترین روشها به همراه کوتاهترین کدنویسیها است.
خروجی کد بالا به صورت زیر است.
Largest element is: 99پیدا کردن بزرگترین عدد در لیست بدون استفاده از توابع درونی
در این روش متغیری به نام دلخواه max تعریف میکنیم که مقدار اولین عنصر لیست را نگهداری میکند. با کمک پیمایشگری بر روی لیست حرکت میکنیم. به هر عنصر که میرسیم مقدار آن را با مقدار ذخیره شده در متغیر maxمقایسه میکنیم. در صورتی که مقدار این عنصر از مقدار متغیر maxبزرگتر بود، مقدار عنصر را به متغیر maxاختصاص میدهیم، در غیر اینصورت به سراغ عنصر بعدی میرویم. این پیمایش را تا آخر لیست ادامه میدهیم و در نهایت محتوی متغیر maxشامل بزرگترین عنصر لیست خواهد بود.
روش گفته شده در بالا را میتوان به صورت ساده یا به صورت تابع کدنویسی کرد. در مثال نمایش داده شده پایین این روش را به صورت تابع کدنویسی کردهایم.
خروجی کد بالا به صورت زیر است.
Largest element is: 99پیدا کردن دومین عدد بزرگ در لیست
در این مسئله لیستی داده شده است و درخواست مسئله این است که برنامهای برای پیدا کردن دومین عدد بزرگ در لیست بنویسیم.
بر فرض مثال اگر لیست داده شده list1 = [10, 20, 4] است، برنامه باید مقدار 10 را به عنوان خروجی نمایش دهد و اگر لیست داده شده برابر با list2 = [70, 11, 20, 4, 100] است برنامه باید مقدار 70 را به عنوان خروجی نمایش دهد.

برای این برنامه سه روش متفاوت از کدهای پایتون آماده کردهایم که در زیر فهرست شدهاند.
- منظم کردن صعودی لیست
- حالت بهینه منظم کردن لیست به حالت صعودی و انتخاب عنصر یکی مانده به آخر
- حذف بزرگترین عنصر لیست
نمایش کدهای پایتون آماده برای این مسئله را از اولین روش شروع کردهایم.
منظم کردن صعودی لیست
منظم کردن لیستها آسانترین روش حل برای این نوع از مسائل است. اما در صورت عدم دقت در پیادهسازی کد بهرهوری کمتری نسبت به سایر روشها پیدا میکنند، مانند مثالی که در پایین نشان دادهایم.
خروجی کد بالا به صورت زیر است.
Second highest number is : 45در این الگوریتم، پیچیدگی زمانی به اندازه O(n) است. زیرا این الگوریتم برای پیدا کردن دومین عنصر بزرگ لیست، فرایند بررسی خطی را به صورت مجزا بر روی هر عنصر انجام میدهد. عملیات انجام شده در هر پیمایش پیچیدگی زمانی ثابتی دارد، در نتیجه پیچیدگی زمانی کل عملیات برابر O(n) است.
حالت بهینه منظم کردن لیست به حالت صعودی و انتخاب عنصر یکی مانده به آخر
در این روش متغیری به نام list2تعریف میکنیم و مقدار این متغیر را برابر با list(set(list1)) قرار میدهیم. در واقع، ابتدا لیست list1را به مجموعه تبدیل میکنیم تا مقادیر تکراری از لیست حذف شوند. سپس دوباره مجموعه را به لیست تبدیل میکنیم. بعد از مقداردهی متغیر list2به روش گفته شده فقط کافی است که لیست list2را به صورت صعودی مرتب کنیم و عنصر یکی مانده به آخر را از لیست برگردانیم.
این روش هم کدنویسی خیلی کمتری نسبت به روش قبلی دارد و هم بهرهوری زمانی خیلی بهتری مخصوصا در لیستهای بزرگ دارد. به کد پیادهسازی شده از روی این روش در پایین توجه کنید.
خروجی کد بالا به صورت زیر است.
Second highest number is : 45پیچیدگی زمانی این الگوریتم برابر با است.
حذف بزرگترین عنصر لیست
در این روش همانند روش قبلی باید در ابتدا لیست را به مجموعه تبدیل کرد و در متغیر جداگانهای که در اینجا با نام داخواه new_list مشخص شده ذخیره کنیم. این کار باعث میشود که عناصر تکراری لیست حذف شوند. سپس با کمک خط کد new_list.remove(max(new_list)) ابتدا بزرگترین عنصر مجموعه را استخراج میکنیم. سپس این عنصر شناخته شده را از مجموعه حذف میکنیم و در آخر با استفاده دوباره از تابع درونی max() بزرگترین عنصر مجموعه را که میشود دومین عنصر بزرگ لیست اصلی پیدا میکنیم و به کاربر برمیگردانیم.

به کدی که در پایین طبق الگوریتم بالا پیادهسازی شده است توجه کنید.
خروجی کد بالا برابر با عدد ۴۵ است.
پیدا کردن N عنصر بزرگتر در لیست
در این مسئله لیستی از اعداد داده شده است. سوال این است، با فرض اینکه اگر طول لیست بزرگتر یا مساوی N باشد، N عنصر بزرگتر در لیست را پیدا کنید.
فرض کنیم که لیست [4, 5, 1, 2, 9] را به همراه N = 2 به برنامه میدهیم. برنامه باید در خروجی مقدار [9, 5] را نمایش دهد یا اگر به برنامه لیست [81, 52, 45, 10, 3, 2, 96] را به همراهN = 3 بدهیم، برنامه باید در خروجی مقدار [81, 96, 52] را نمایش بدهد.
این مسئله را به سه روش متفاوت حل کردهایم که هر روش را با کدنویسی مربوط به آن در ادامه نمایش دادهایم.
- روش ساده و معمولی کدنویسی در پایتون بدون استفاده از ابزار خاص
- استفاده از تابع sort()به همراه حلقه
- استفاده از کتابخانه heapq
این بخش از کدهای پایتون آماده را با معرفی روش اول شروع میکنیم.
روش ساده و معمولی کدنویسی در پایتون بدون استفاده از ابزار خاص
روش ساده حل مسئله، این است که لیست داده شده را N بار پیمایش کنیم. در هر پیمایش بیشترین مقدار لیست را پیدا کنیم و به لیستی که برای نگهداری نتایج استفاده میکنیم اضافه کنیم. لیست مخصوص نگهداری نتایج را در اینجا به نام دلخواه final_list نامگزاری کردیم. در نهایت این مقدار را با کمک تابع remove() از لیست حذف کنیم. کدی که در پاییین میبینید پیادهسازی این الگوریتم را نمایش میدهد.
خروجی کد بالا به صورت [85, 41] است.

استفاده از تابع sort به همراه حلقه
فرایند این الگوریتم را در سه مرحله به شرح زیر میتوان توضیح داد.
- در ابتدای کار باید لیست گرفته شده را مرتب کنیم.
- لیست را به اندازه N واحد پیمایش میکنیم و عناصر را به آرایه جدید arrاضافه میکنیم.
- در نهایت هم آرایه arrرا بر روی خروجی نمایش میدهیم.
به کدی که در زیر پیادهسازی شده توجه کنید. برنامه زیر شکل پیادهسازی شده کدهای پایتون الگوریتم بالا است.
خروجی کد بالا به صورت زیر است.
[298, 900, 1000, 3579]توجه کنید که کد بالا همه مقادیر بزرگ لیست را در نظر میگیرد. در صورتی که بخواهید N تعداد مقادیر بزرگ غیر تکراری را ببینید میتوانید بعد از منتظم کردن لیست آن را به ساختار ذخیره داده از نوع مجموعه تبدیل کنید.
استفاده از کتابخانه heapq
در این روش باید با استفاده از لیست ورودی یک صف هیپ ایجاد کنیم. سپس از تابع heapq.nlargest() استفاده میکنیم تا N عدد از بزرگترین عناصر درون صف هیپ را پیدا کنیم. در نهایت هم باید مقدار نتیجه را برگردانیم. میتوان فرایند کار این الگوریتم را در سه مرحله توصیف کرد.
- با استفاده از لیست ورودی، صف هیپی را مقداردهی اولیه میکنیم.
- از تابع heapq.nlargest() استفاده میکنیم تا N عدد از بزرگترین عناصر درون صف هیپ را پیدا کنیم.
- نتیجه نهایی را برمیگردانیم.
در کدهای پایتون آماده پایین فرایند الگوریتم توصیف شده در بالا را پیادهسازی کردهایم و برای مثال دو لیست مجزای [4, 5, 1, 2, 9] و [81, 52, 45, 10, 3, 2, 96] را بهترتیب به برنامه ارسال کردهایم.
خروجی کد بالا به صورت زیر است.
[9, 5]
[96, 81, 52]پیدا کردن اعداد زوج در لیست
در این مسئله لیستی داده شده است و سوال این است که اعداد زوج درون لیست را پیدا کنید. به عنوان مثال اگر لیست [2, 7, 5, 64, 14] ارسال شود خروجی باید برابر با [2, 64, 14] باشد.
این برنامه را به روشهای گوناگونی میتوان نوشت اما در اینجا فقط از دو روش مختلف برای حل این مسئله استفاده خواهیم کرد.
- استفاده از حلقههای پایتون برای پیدا کردن اعداد زوج در لیست
- استفاده از روش تعریف لیست به سبک Comprehension

استفاده از حلقه های پایتون برای پیدا کردن اعداد زوج در لیست
در بیان این روش، کدهای پایتون آماده برای حل مسئله را با کمک هر دو حلقه forو while ارائه دادهایم. در این روش حل مسئله باید بر روی هر عنصر در لیست پیمایش کنیم و با کمک عبارت شرطی if num % 2 == 0 بخشپذیری عنصر بر ۲ را بررسی کنیم. اگر شرط برآورده شود فقط باید عنصر مورد نظر را در خروجی چاپ کرد و گرنه به سراغ عنصر بعدی میرویم.
در پیادهسازی اول این الگوریتم از حلقه forاستفاده کردهایم. به کد زیر نگاه کنید.
خروجی کد بالا به صورت زیر است.
10 4 66 در کد نمایش داده شده پایین همان الگوریتم را با کمک حلقه while پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
10 24 4 66 استفاده از روش تعریف لیست به سبک Comprehension
در این روش از List Comprehension استفاده میکنیم که از عناصر زوج موجود در لیست داده شده به برنامه لیست جدیدی بسازیم. و در نهایت این لیست جدید را بر روی خروجی نمایش دهیم. به کدی که در پایین آمده است دقت کنید.
خروجی کد بالا به صورت زیر است.
Even numbers in the list: [10, 4, 66]پیدا کردن اعداد فرد در لیست
در این مسئله لیستی از اعداد داده شده و سوال این است که اعداد فرد داخل لیست را در خروجی نمایش دهیم. بر فرض مثال اگر لیست list1 = [2, 7, 5, 64, 14] به عنوان ورودی به برنامه داده شده باشد برنامه باید خروجی [7, 5] را نمایش دهد.
این برنامه را نیز همانند برنامه مورد نیاز برای پیدا کردن اعداد زوج به روشهای مختلفی میتوان نوشت. اما در اینجا فقط از دو روش مجزا برای حل این مسئله استفاده کردهایم.
- استفاده از حلقههای پایتون برای پیدا کردن اعداد فرد در لیست
- استفاده از روش تعریف لیست به سبک Comprehension
استفاده از حلقه های پایتون برای پیدا کردن اعداد فرد در لیست
در این قسمت از کدهای پایتون آماده مسئله را با کمک هر دو حلقه forو while حل خواهیم کرد. در این روش حل مسئله بر روی هر عنصر در لیست پیمایش میکنیم و با کمک عبارت شرطی if num % 2 != 0 برسی میکنیم که اگر باقیمانده تقسیم عنصر بر دو مساوی صِفر نیست باید عنصر مورد نظر را در خروجی چاپ کرد و اگر باقیمانده تقسیم عنصر بر دو مساوی صِفر شود به سراغ عنصر بعدی میرویم.

در پیادهسازی اول این الگوریتم از حلقه forاستفاده خواهیم کرد. به کد زیر نگاه کنید.
خروجی کد بالا به صورت زیر است.
21 45 93 در کد نمایش داده شده پایین همان الگوریتم را با کمک حلقه while پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
21 45 93 استفاده از روش List Comprehension
برای حل مسئله در این روش از تکنیک Comprehension برای تعریف لیستها استفاده میکنیم. به کمک تکنیک Comprehension از عناصر فرد موجود در لیست اصلی، لیست جدیدی میسازیم. و در نهایت این لیست جدید را بر روی خروجی نمایش میدهیم. به کدی که در پایین آمده است دقت کنید.
خروجی کد بالا به صورت زیر است.
[21, 45, 93]چاپ کردن همه اعداد زوج موجود در محدوده مشخص شده
در این مسئله نقاط ابتدا و انتهای محدوده، مشخص شدهاند. سوال این است که برنامهای بنویسیم که تمام اعداد زوج داخل این محدوده را نمایش دهد. بر فرض مثال اگر نقاطstart = 4 و end = 15 را به برنامه بدهیم باید خروجی را به صورت 4, 6, 8, 10, 12, 14 به کاربر نمایش دهد.
برای حل این مسئله ساده تکنیکهای بسیار زیادی قابل استفاده هستند که در این جا به سه مورد از این تکنیکها اشاره میکنیم.
- استفاده از حلقه forبه همراه عبارت شرطی - کدنویسی ساده پایتونی
- استفاده از کدنویسی عبارات پایتونی ساده در یک خط
- استفاده از تابع بازگشتی
این بخش از کدهای پایتون آماده را با توضیح و نمایش کدهای روش اول شروع میکنیم.
استفاده از حلقه for به همراه عبارت شرطی - کدنویسی ساده پایتونی
در این روش محدودههای ورودی را از کاربر گرفتیم تا نحوه استفاده از تابع input() را هم ببینیم. سپس بر روی یک به یک اعضای محدوده مورد نظر -نقاط ابتدا و انتها را نیز جزو محدوده در نظر میگیریم- پیمایش میکنیم. زوج بودن هر عضو محدوده را با استفاده از کد شرطی if num % 2 == 0 بررسی میکنیم. در صورتی که عبارت شرطی برنامه برقرار باشد عدد مورد نظر را بر روی خروجی نمایش میدهیم.
به کدی که در پایین آمده توجه کنید.
خروجی حاصل از اجرای کد بالا با محدودههای دلخواه 4 و 10 به صورت زیر است.
Enter the start of range: 4
Enter the end of range: 10
4 6 8 10 استفاده از کدنویسی عبارات پایتونی ساده در یک خط
در این روش با کمک خط کد start+1 if start&1 else start نقطه شروع را به عدد زوج تبدیل میکنیم و سپس قدم به قدم به صورت یکی در میان اعضا را رد میکنیم و عضو بعدی را نمایش میدهیم.
به کدی که در پایین از پیادهسازی این گوریتم بدست آمده است توجه کنید.
خروجی حاصل از اجرای کد بالا با محدودههای دلخواه 4 و 10 به صورت زیر است.
Enter the start of range: 4
Enter the end of range: 10
4 6 8 10 استفاده از تابع بازگشتی
در این روش تابعی با نام دلخواه even تعریف میکنیم که دو پارامتر برای ابتدا و انتهای محدوده دریافت میکند. سپس بررسی میکند اگر که ابتدای محدوده کوچکتر از انتهای آن باشد اولین عنصر محدوده را چاپ میکند. بعد از آن به ابتدای محدوده دو واحد اضافه میکند و دوباره خود را فراخوانی میکند. در فراخوانی خود ابتدای جدید محدوده را به همراه انتهای آن به عنوان پارامتر به خودش ارسال میکند. به کدی که در ادامه آمده توجه کنید.
خروجی کد بالا به صورت 4 6 8 10 12 14 است. توجه کنید که این متد فقط اعداد را به صورت یکی در میان از محل شروع محدوده تعیین شده نمایش میدهد و زوج یا فرد بودن را بررسی نمیکند. در صورتی که میخواهیم حتما اعداد زوج را نمایش دهد. برای اینکار میتوانید با افزودن عبارت شرطی if num1 % 2 == 0 به ابتدای تابع بررسی کنید که اگر مقدار متغیر num1 زوج بود تابع وارد عمل شود و در غیر اینصورت با افزودن یک واحد به متغیر num1، مقدار جدید را به عنوان محدوده شروع به تابع ارسال کنید.

برای چاپ اعداد فرد درون محدوده مشخص شده نیز میتوان از تکنیکهای بالا با کمی تغییر استفاده کرد.
چاپ اعداد مثبت درون لیست
در فرض این مسئله لیستی از اعداد داده شده است و سوال این است که باید برنامهای بنویسیم تا تمام اعداد مثبت داده شده در لیست را در خروجی نمایش دهیم. برای مثال اگر لیستی بهشکل list1 = [12, -7, 5, 64, -14] به برنامه داده شد، برنامه باید خروجی بهشکل 12, 5, 64 را برگرداند.
برای حل این برنامه روشهای متفاوتی وجود دارند. در این بخش کدهای پایتون آماده مربوط به دو مدل از این روشها را بررسی خواهیم کرد.
- استفاده از حلقهwhile
- استفاده از List Comprehension
با بررسی روش اول کار خود را شروع میکنیم.
استفاده از حلقه while
در این روش برای حلقه while باید محدودیت چرخش تعیین کنیم. این کار را به کمک کد num < len(list1) انجام میدهیم. این کد به حلقه while میگوید تا زمانی که مقدار متغیر num کوچکتر از اندازه لیست باشد به چرخش خود ادامه دهد. توجه کنید که در این برنامه مقدار متغیر num را برابر با 0 قرار دادیم تا از ابتدای لیست عمل پیمایش انجام گیرد. حلقه هر بار به هر عنصر که میرسد با کمک عبارت شرطی list1[num] >= 0 در مقابل if بررسی میکند که آیا این عنصر مثبت است یا نه در صورت مثبت بودن عنصر در خروجی نمایش داده میشود و در غیر این صورت مقدار متغیر num یک واحد افزایش مییابد و حلقه دوباره میچرخد.
به کدی که در پایین از روی الگوریتم توصیف شده بالا پیادهسازی شده است توجه کنید.
خروجی این کد اعداد 21,93 را نمایش میدهد.
استفاده از List Comprehension
در این روش با استفاده از تکنیک Comprehension برای تعریف لیستها، از روی عناصر موجود در لیست اصلی، لیستی از اعداد مثبت میسازیم. به کدی که در پایین آمده دقت کنید.
خروجی کد بالا به صورت زیر است.
Positive numbers in the list: 45 93برای چاپ اعداد منفی درون لیست داده شده نیز میتوانید از تکنیکهای بالا با انجام اصلاحات کوچکی استفاده کنید.
حذف چندین عنصر به صورت همزمان از لیست
در این مسئله، فرض کنیم که لیستی از اعداد داده شده است. باید برنامهای بنویسیم که بتواند به صورت همزمان چند عنصر مختلف را از لیست با توجه به شرایط مشخص شده حذف کند. بر فرض مثال لیستی مانند [12, 15, 3, 10] داده شده، همراه با آن لیست دیگری که محتویاتش باید حذف شوند به صورت Remove = [12, 3] نیز ارائه شده است. خروجی برنامه باید برابر با New_List = [15, 10] شود.
اکنون میتوانیم با توجه به دانشی که درباره دادهها داریم چندین عنصر مختلف را به صورت همزمان از لیست در پایتون حذف کنیم. بر فرض مثال درباره عنصرهایی که قرار است حذف شوند دو نوع اطلاعات میتوانیم داشته باشیم. مقدار این عنصرها یا ایندکس هر کدام از عنصرها اطلاعاتی هستند که درباره هر داده در لیست میتوان مورد استفاده قرار داد. در ادامه مثالهای مختلفی از کدهای پایتون آماده بر مبنای سناریوهای مختلف برای حل این مسئله را بررسی کردهایم.
سناریوهای مورد بررسی در این بخش موارد فهرست شده زیر هستند.
- حذف عناصر بخشپذیر بر ۲
- حذف عناصر موجود در یک محدوده ایندکس مشخص شده
- حذف عناصر موجود در یک مجموعه پایتونی از لیست با استفاده از تکنیک Comprehension
در این بخش، کدهای پایتون آماده را با حذف عناصر بخشپذیر بر ۲ شروع میکنیم.

حذف عناصر بخش پذیر بر ۲
فرض کنیم که باید همه اعداد بخشپذیر بر ۲، یا در واقع تمام اعداد زوج را از لیست حذف کنیم. به کدی که در پایین نمایش داده شده توجه کنید.
خروجی کد بالا به صورت زیر است.
New list after removing all even numbers: [11, 5, 17, 23]برای حذف اعداد زوج در لیست میتوان از روشهای دیگری هم استفاده کرد. یکی از این روشها این است که لیست جدیدی از عناصر لیست قبلی ایجاد کنیم که همه اعداد غیر زوج را شامل شود.
به کدی که در پایین از روی الگوریتم توصیف شده بالا شبیهسازی شده نگاه کنید.
خروجی کد بالا به صورت زیر است.
11 5 17 23حذف عناصر درون محدوده مشخص شده
برای حذف کردن عناصر درون محدوده ایندکسهایی که از قبل مشخص شدهاند میتوانید از عملیات Slicing استفاده کنید. کد پایتونی که در پایین میبینید مقادیر بین ایندکس 1 تا 4 را حذف میکند.
خروجی کد بالا برابر با اعداد 11 و 50 است.
استفاده از تکنیک Comprehension برای تعریف لیست
درباره عناصری که قرار است حذف شوند، فرض کنیم بهجای مشخص شدن شماره ایندکسهای عناصر، خود عناصر صراحتا مشخص شدهاند. در چنین مواردی میتوانیم بدون توجه به ایندکسها، بهطور مستقیم خود عناصر را محدود کنیم. در کدهای پایتون آماده زیر، فرایند الگوریتم توصیف شده در بالا پیادهسازی شده است. در مجموعه unwanted به عناصری که باید حذف شوند بهطور مستقیم اشاره شده است.
خروجی کد بالا به صورت زیر است.
New list after removing unwanted numbers: [17, 18, 23, 50]حذف لیست های خالی از لیست
بعضی وقتها که با پایتون کار میکنیم وضعیتی پیش میآید که دادههای خالی درون سایر لیستها بهوجود میآیند. برای اینکه بتوانیم با دادههای خود بهخوبی کار کنیم باید این دادههای خالی را از درون لیست اصلی حذف کنیم. این دادههای پوچ میتوانند شامل رشتههای خالی، None، لیستهای خالی و غیره شوند.
در این بخش از مطلب کدهای پایتون آماده به بحث درباره حذف این نوع از دادهها از لیستها خواهیم پرداخت.

بهطور کل در دنیای برنامهنویسی برای هر مسئلهای بسته به خلاقیت برنامهنویسها میتوان تعداد زیادی راه حل ایجاد کرد. این مسئله هم از این قضیه مستثنا نیست. در این مطلب به بررسی و پیادهسازی کدهای پایتون آماده سه روش متفاوت برای اجرای این عملیات پرداختهایم.
- استفاده از تکنیک List Comprehension
- استفاده از متد filter()
- تعریف تابع اختصاصی برای حذف عناصر خالی درون لیست.
بررسی روشهای بالا را به ترتیب از گزینه اول شروع میکنیم.
استفاده از تکنیک List Comprehension
استفاده از تکنیک List Comprehension یکی از راهکارهای ارائه شده برای حل این مسئله است. در این روش لیست جدیدی میسازیم. به این صورت که در ابتدا بر روی لیست اصلی پیمایش میکنیم. در این پیمایش عناصر با مقدار لیستهای خالی را برای عضویت در لیست جدید انتخاب نمیکنیم.
در کدهای پایتون آماده پیادهسازی شده پایین، این رویکرد حل مسئله دیده میشود.
خروجی کد بالا به صورت زیر است.
The original list is : [5, 6, [], 3, [], [], 9]
List after empty list removal : [5, 6, 3, 9]استفاده از متد filter
استفاده از متد filter() روش دیگری است که برای حل این مسئله پیشنهاد داده میشود. در این روش مقادیر Noneاز لیست اصلی فیلتر میشوند. مقادیر Noneشامل لیستهای خالی نیز میشود، بنابراین با این کار لیستهای خالی هم از لیست اصلی حذف میشوند.
در کد زیر رویکرد بالا برای حل مسئله را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The original list is : [5, 6, [], 3, [], [], 9]
List after empty list removal : [5, 6, 3, 9]تعریف تابع اختصاصی برای حذف عناصر خالی درون لیست
در این روش تابعی تعریف میکنیم که به عنوان پارامتر لیست دریافت میکند. در این تابع، لیستی خالی تعریف کردهایم. با پیمایش بر روی لیست اصلی و وارد کردن دادههای غیر پوچ لیست اصلی به لیست خالی، لیست جدیدی تولید میشود که شامل همه دادههای لیست اصلی به غیر از مقادیر خالی است. در نهایت لیست جدید را به عنوان خروجی از تابع برمیگردانیم.

در کد پایین روش حل مسئله تعریف شده در بالا را شبیهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The original list is : [5, 6, [], 3, [], [], 9]
List after empty list removal : [5, 6, 3, 9]روش بالا برای تعریف تابع سفارشی بهینهترین روش در بین هر سه روشی است که بررسی کردیم.
شبیه سازی یا کپی کردن لیست ها
در این مطلب به بررسی کدهای پایتون آماده مربوط به روشهای گوناگون، برای کپی کردن لیستها در پایتون خواهیم پرداخت. هر کدام از این روشهای کپی کردن لیستها زمان اجرای متفاوت و کدهای مخصوص به خود را دارند. در ادامه به بررسی چهار روش مختلف تکثیر لیستها خواهیم پرداخت که در پایین فهرست کردهایم. توجه کنید که البته روشهای بیشتری هم به غیر از موارد فهرست شده، قابل طراحی و پیادهسازی هستند.
- استفاده از تکنیک «تکهتکه کردن» (Slicing)
- استفاده از متد extend()
- کپی کردن لیست با استفاده از عملگر تخصیص یا مساوی =
- استفاده از روش «کپی کمعمق» (Shallow Copy)
مطلب را با بررسی روش استفاده از تکنیک Slicing ادامه میدهیم.
تکثیر لیست با استفاده از تکنیک Slicing
این روش سادهترین و سریعترین راه کپی کردن لیستها است. از این روش بیشتر برای زمانهایی استفاده میشود که باید اطالاعات موجود در لیستی را دستکاری کنیم و در عین حال اطلاعات همان لیست را هم بدون تغییر نگهداریم. در روش Slicing یک کپی از لیست در کنار لیست مرجع ایجاد میکنیم. به این فرایند شبیهسازی نیز میگویند. این تکنیک حدودا 0.039 ثانیه زمان میبرد و میتوان گفت که سریعترین روش است.
در مثال آمده پایین، استفاده از روش Slicing برای «تکثیر» (Copy) یا «شبیهسازی» (Cloning) لیستها پیادهسازی شده است.
خروجی کد بالا به صورت زیر است.
Original List: [4, 8, 2, 10, 15, 18]
After Cloning: [4, 8, 2, 10, 15, 18] تکثیر لیست با استفاده از متد extend
لیستها را میتوان با استفاده از متد extend() درون لیست جدیدی کپی کرد. این متد تمام عنصرهای شی پیمایشپذیری را که به عنوان پارامتر دریافت کند به انتهای لیستی که بر روی آن اعمال میشود اضافه میکند. در این موقعیت اگر لیستی که این متد بر روی آن اعمال شده است خالی باشد، میتوان گفت در واقع متدextend() کپی از لیستی که به عنوان پارامتر دریافت کرده میسازد. سرعت اجرای عملیات در این متد حدود 0.053 ثانیه است.
در مثال آمده پایین میتوانید استفاده از متد extend() را برای ساخت کپی از لیست ببینید. در این روش تابعی سفارشی برای انجام عملیات کپی کدنویسی کردهایم.
خروجی کد بالا به صورت زیر است.
Original List: [4, 8, 2, 10, 15, 18]
After Cloning: [4, 8, 2, 10, 15, 18] کپی کردن لیست با استفاده از عملگر تخصیص یا مساوی =
روش استفاده از عملگر = آسانترین روش برای کپی کردن لیستها است. در این عملیات لیست قدیمی با استفاده از عملگرهای پایتون به لیست جدیدی اختصاص داده میشود. عملیات به این صورت است که در ابتدا لیستی را ایجاد میکنیم. سپس با استفاده از عملگر مساوی لیست قدیمی را در لیست جدید کپی میکنیم.

به این نکته توجه کنید که این نوع از کپی را نمیتوان یک کپی واقعی در نظر گرفت. در واقع چیزی که به عملوند سمت چپ مساوی تخصیص داده میشود آدرس لیست در حافظه سیستم است. یعنی هر تغییری در متغیر سمت چپ مساوی باعث تغییر محتویات لیست مرجع نیز میشود.
در مثال آمده پایین میتوانید استفاده از این عملگر را برای کپی کردن لیستها ببینید.
خروجی کد بالا به صورت زیر است.
Original List: [4, 8, 2, 10, 15, 18]
After Cloning: [4, 8, 2, 10, 15, 18] استفاده از روش Shallow Copy
برای بهکار بردن این روش کپی کردن لیستها باید از ماژول copy استفاده کنیم. زمان اجرای این عملیات تقریبا برابر با 0.186 ثانیه طول میکشد. به این دلیل به این عملیات کپی سطحی میگویند که اطلاعات منتقل شده به لیست دوم برعکس مورد بالا است. در مورد بالا یا استفاده از عملگر مساوی، اطلاعات مرتبط با مکان قرارگیری لیست اصلی در حافظه منتقل میشود. اما در این روش تمام محتویات لیست قدیمی به لیست جدید با همان ساختار و نظم منتقل میشود. بر خلاف لیستی که با استفاده از عملگر مساوی ایجاد شده است، اعمال تغییرات در دادههای لیست جدید باعث بروز هیچ اتفاقی در لیست قدیمی نمیشود.
در کدهای پایتون آماده پایین میتوانید فرایند استفاده از این ماژول را برای ساخت کپی جدید از لیست مرجع ببینید.
خروجی کد بالا به صورت زیر است.
[1, 2, [3, 5], 4]شمارش تعداد تکرار عناصر در لیست
در این مسئله فرض میکنیم که لیستی به همراه عدد «x» داده شده است. باید برنامهای بنویسیم که تعداد تکرار عنصر x را در لیست داده شده محاسبه کند. به عنوان مثال فرض کنید که لیست زیر به همراه متغیر x به صورت زیر به برنامه داده شده است.
Input: lst = [15, 6, 7, 10, 12, 20, 10, 28, 10], x = 10
Output: 3 همانطور که میبینید خروجی عدد 3 را نمایش میدهد. این خروجی بیان میکند که عنصر با مقدار 10 به تعداد سه دفعه در لیست تکرار شده است.
روشهای متفاوتی برای بررسی تکرار اعضا یا حتی عناصر ناموجود در لیست ارائه شدهاند. در این مطلب کدهای پایتون آماده درباره چهار روش متفاوت را ارائه دادهایم. این تکنیکها را در ادامه فهرست کردیم.
- استفاده از حلقه در پایتون
- استفاده از تکنیک List Comprehension
- استفاده از تابعenumerate()
- استفاده از تابع count()
بررسی این روشها را به ترتیب از روش استفاده از حلقههای پایتون شروع میکنیم.

شمارش تکرار وقوع هر عنصر در لیست با استفاده از حلقه در پایتون
در این روش با کمک حلقهای به بررسی لیست میپردازیم و از متغیری به عنوان شمارنده استفاده میکنیم. با هر بار مشاهده عنصر مورد نظر در لیست، مقدار شمارنده را یک واحد افزایش میدهیم. فرایند کدنویسی این روش را در کد پیادهسازی شده پایین میتوانید مشاهده کنید.
خروجی کد بالا به صورت زیر است.
8 has occurred 5 timesشمارش تکرار وقوع هر عنصر در لیست با استفاده از List Comprehension
در این روش که چندان روش بهینهای نیست از تکنیک List Comprehension برای شمارش تعداد رخداد آیتم مشخص شده در لیست، استفاده میکنیم. فرایند اجرای این عملیات به این صورت است که لیست جدیدی با استفاده از تکنیک List Comprehension از روی لیست اصلی میسازیم و فقط عناصری را به لیست جدید وارد میکنیم که برابر با عنصر مورد جستوجو باشند. سپس اندازه طول لیست جدید را محاسبه میکنیم. این اندازه برابر با تعداد تکرار عنصر مورد نظر در لیست اصلی است.
در کد پایین میتوانید پیادهسازی این فرایند را در زبان برنامهنویسی پایتون مشاهده کنید.
خروجی کد بالا به صورت زیر است.
the element 1 occurs 2 timesشمارش تکرار وقوع هر عنصر در لیست با استفاده از تابع enumerate
در این روش از حل مسئله از تابع enumerate() استفاده خواهیم کرد. این تابع وقتی بر روی لیست اعمال شود، شی پیمایشپذیری از همه عناصر و ایندکسهای مرتبط با آنها را به صورت جفتی در تاپل برمیگرداند. با استفاده از تابع enumerate()در این عملیات، لیست جدیدی از روی لیست قبلی میسازیم و فقط عناصری را در لیست جدید وارد میکنیم که همسان با عنصر مورد نظر باشند.
این روش منطقی شبیه به عملیات با List Comprehension دارد. در کد آمده پایین فرایند این عملیات را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
the element 1 occurs 2 timesشمارش تکرار وقوع هر عنصر در لیست با استفاده از تابع count
در این روش حل مسئله از تابع درونی count() در پایتون برای شمارش تعداد تکرار عنصر مورد نظر در لیست استفاده میکنیم. این روش یکی از کوتاهترین کدنویسیها را دارد. تابعی برای اجرای عملیات شمارش بر روی لیست پیادهسازی کردهایم که برای کوتاهتر شدن کدنویسی قابل نادیده گرفته شدن است.
به فرایند پیادهسازی این روش دقت کنید.
خروجی کد بالا به صورت زیر است.
8 has occurred 5 timesحذف تاپل های خالی از لیست
در این مسئله، روش حذف تاپلهای خالی از لیست داده شده را بررسی میکنیم. برای اجرای این عملیات روشهای گوناگونی قابل پیادهسازی هستند که ما به بیان سه مورد از این روشها خواهیم پرداخت. برای شروع فرض کنید که لیستی مانند مورد زیر داده شده است.
tuples = [(), (‘ram’,’15’,’8′), (), (‘laxman’, ‘sita’), (‘krishna’, ‘akbar’, ’45’), (”,”),()]برنامه ما باید خروجی برابر با گزینه نشان داده شده پایین را برگرداند.
Output : [(‘ram’, ’15’, ‘8’), (‘laxman’, ‘sita’), (‘krishna’, ‘akbar’, ’45’), (”, ”)]کدهای پایتون آماده روشهایی که برای حل این مسئله خواهیم دید در ادامه فهرست شدهاند.
- استفاده از مفهوم List Comprehension
- استفاده از متد filter()
- استفاده از متد len()

بررسی روشهای بالا را به ترتیب از گزینه اول یعنی استفاده از مفهوم List Comprehension شروع میکنیم.
استفاده از مفهوم List Comprehension
در پیادهسازی این روش تابعی به نام Remove() تعریف کردهایم. تابع Remove() با کمک مفهوم List Comprehension لیست جدیدی از روی لیست اصلی میسازد که تاپلهای خالی موجود در لیست اصلی از آن حذف شدهاند. به کدی که در ادامه آمده دقت کنید.
خروجی کد بالا به صورت زیر است.
[('ram', '15', '8'), ('laxman', 'sita'), ('krishna', 'akbar', '45'), ('', '')]استفاده از متد filter
میتوانیم با استفاده از متد درونی filter() در پایتون، عناصر خالی را حذف کنیم. برای این کار باید مقدار Noneبه عنوان پارامتر به متد filter() ارسال شود. این متد در پایتون2، پایتون3 و نسخههای جدیدتر پایتون کار میکند. اما بهترین خروجی مورد انتظار را فقط میتوان در پایتون2 دید. زیرا متد درونی filter() در پایتون3، شی جنریتور -شی پیمایشپذیر از نوع filter- برمیگرداند.
متد درونی filter() از تکنیک List Comprehension سریعتر عمل میکند. کد پایین، مخصوص پایتون3 نوشته شده است. درصورتی که میخواهید شی ساخته شده توسط متد filter() را ببینید از خط آخر کد، سازنده list() را حذف کنید.
خروجی کد بالا به صورت زیر است.
[('ram', '15', '8'), ('laxman', 'sita'), ('krishna', 'akbar', '45'), ('', '')]استفاده از متد len
برای این کار تابعی به نام Remove()تعریف کردهایم. این تابع بهعنوان پارامتر ورودی، لیست دریافت میکند. با بهکار بردن حلقهای بر روی لیستی که به عنوان آرگومان ورودی در تابع کار میکند داخل تابع پیمایش میکنیم. با کمک کد خط if(len(i) == 0) هر عنصری که در لیست، طول صِفر داشته باشد را شناسایی کرده و از لیست حذف میکنیم و در نهایت لیست جدید را برمیگردانیم.
با استفاده از این تابع، لیست مرجع تغییر میکند. به کد پایین نگاه کنید تا روش پیادهسازی الگوریتم وصف شده در بالا را ببینید.
خروجی کد بالا به صورت زیر است.
[('ram', '15', '8'), ('laxman', 'sita'), ('krishna', 'akbar', '45'), ('', '')]برنامه ای برای چاپ عناصر تکراری در لیست اعداد صحیح
فرض کنیم که لیستی از اعداد صحیح داده شده و باید برنامهای بنویسیم که لیست جدیدی تولید کند. لیست جدید فقط باید شامل عناصری باشد که در لیست اصلی بیشتر از یکبار ظاهر شدهاند. بر فرض مثال اگر لیست داده شده مانند گزینه آمده در پایین است.
Input : list = [10, 20, 30, 20, 20, 30, 40, 50, -20, 60, 60, -20, -20]خروجی برنامه باید مانند گزینه زیر نشان داده شود.
Output : output_list = [20, 30, -20, 60]برای حل این مسئله روشهای مختلفی ارائه شدهاند که در این بخش، کدهای پایتون آماده چهار روش مختلف را بررسی خواهیم کرد.
- استفاده از «رویکرد برنامهنویسی پُر قدرت» (Brute Force approach)
- استفاده فقط از یک حلقه
- استفاده از تابع Counter() از کتابخانه collections
- استفاده از متدcount()
ادامه مطلب را به بررسی روشهای فهرست شده در بالا -بهترتیب از روش اول- خواهیم پرداخت.

استفاده از رویکرد برنامه نویسی پرقدرت | Brute Force Approach
در این روش حل مسئله، تابعی تعریف کردهایم که پارامتر x را از ورودی میگیرد. پارامتر x باید شی پیمایشپذیر باشد. به کمک دو حلقه تو در تو forبر روی یک به یک عناصر این پارامتر پیمایش میکند و هر عنصری را که تکرار شده در لیست تکرار شدههاrepeated = [] وارد میکند، به شرطی که از قبل در لیست تکرار شدههاrepeated = [] وارد نشده باشد. این شرط با عبارت if x[i] == x[j] and x[i] not in repeated بررسی میشود.
به کدی که در ادامه پیادهسازی شده توجه کنید.
خروجی کد بالا به صورت زیر است.
[20, 30, -20, 60]حل مسئله فقط با کمک یک حلقه
در این روش با کمک حلقه forبر روی لیست مرجع شروع به پیمایش میکنیم. دو لیست خالی به نامهای uniqueList و duplicateList داریم. این لیستها به ترتیب برای نگهداری همه اعضای لیست به صورت غیر تکراری و همه اعضای تکرار شده لیست به صورت یکتا استفاده میشوند. با کمک حلقه forیک نمونه از هر عضوی که در لیست مرجع قرار دارد را به لیست uniqueList وارد میکنیم و بررسی میکنیم تا یک نمونه از هر عضوی که تکرار شده نیز در لیست duplicateList قرار داده شود.
به کدهای پایتون آماده پایین توجه کنید. این کدها را از روی الگوریتم توضیح داده شده در بالا پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
[1, 2, 5, 9]استفاده از تابع Counter در کتابخانه collections
در این روش از تابع درونی Counter() که در کتابخانه collections پایتون تعریف شده استفاده میکنیم. این تابع همه اعضای لیست را میشمارد و شی اختصاصی از جنس Counter میسازد. شی اختصاصی Counter، ظاهری بهشکل دیکشنری از همه اعضای لیست به عنوان کلید و تعداد تکرار آنها به عنوان مقدار هر کلید دراد. سپس از روی ساختار دادهای که توسط تابعCounter() برگردانده شده لیستی از همه کلیدهایی میسازیم که مقدار بیشتر از یک دارند. در واقع اعضایی در لیست اصلی که تکرار شدهاند.
به مثال پیادهسازی شده پایین توجه کنید. کدهای پایتون آماده پایین از روی روش نوشته شده در بالا کدنویسی شدهاند.
خروجی کد بالا به صورت زیر است.
Counter({1: 4, 2: 3, 5: 2, 9: 2, 3: 1, 4: 1, 6: 1, 7: 1, 8: 1})
[1, 2, 5, 9]استفاده از متد count
این روش بسیار ساده و متداول است. در پیادهسازی این الگوریتم برای حل مسئله، لیستی خالی بهنام new میسازیم. با کمک حلقه بر روی لیست مرجع پیمایش میکنیم و با کمک متد count() تعداد تکرار هر عنصر را میشماریم. اگر تعداد تکرار هر عنصر در لیست مرجع بیش از ۱ بار بود و اگر تعداد تکرار این عنصر در لیست new برابر صِفر بود آنگاه عنصر مورد بررسی به لیست new وارد میشودnew.append(a) . در غیر این صورت به سراغ عنصر بعدی موجود در لیست میرویم.

در کدهای پایتون آماده زیر، روش پیادهسازی این الگوریتم را نمایش دادهایم.
خروجی کد بالا به صورت زیر است.
[1, 2, 5, 9]محاسبه حاصل جمع Cumulative عناصر در لیست
چنین فرض کنیم که لیستی از اعداد داده شده است. باید برنامهای بنویسیم که لیست جدیدی از روی لیست داده شده بسازد با این خصوصیت که هر عضو در لیست جدید برابر باشد با مجموع اعضای قبل از خود با خودش در لیست اصلی.
فرض کنیم که لیست list = [10, 20, 30, 40, 50] به عنوان ورودی به برنامه داده شده است. برنامه باید بتوان در خروجی لیست [10, 30, 60, 100, 150] را نمایش دهد.
در این بخش، سه نوع مختلف از کدهای پایتون آماده را برای حل این مسئله، ارائه و توضیح دادهایم. این روشها در ادامه فهرست شدهاند. البته روشهای دیگری، مخصوصا بدون استفاده از ابزار درونی پایتون برای حل این مسئله ارائه شدهاند که در این بخش به آنها نمیپردازیم.
- استفاده از مفاهیم Comprehension و عملیات Slicing بر روی لیستها
- استفاده از ماژول یا کتابخانه itertools
- استفاده از تابع numpy.cumsum()
توضیح روشهای بالا را از روش اول شروع میکنیم.
استفاده از مفاهیم Comprehension و عملیات Slicing بر روی لیست ها
در این روش از مفاهیم Comprehension و عملیات Slicing بر روی لیستها استفاده میکنیم تا حاصل جمع «انباشت تدریجی» (Cumulative) عناصر را در لیست داده شده بدست بیاوریم. از مفهوم Comprehension برای دسترسی به عناصر لیست به صورت یک به یک استفاده میکنیم و از مفهوم Slicing برای دسترسی به عناصر از شروع لیست تا ایندکس i+1 استفاده میکنیم. همچنین از متد sum() استفاده میکنیم تا عناصر داخل لیست را از ابتدا تا جایگاه i+1جمع ببندیم.
به کدهای پایتون آماده پایین نگاه کنید. میتوانید در این کدها ساختار پیادهسازی شده الگوریتم بالا را ببینید.
خروجی کد بالا به صورت زیر است.
[10, 30, 60, 100, 150]استفاده از ماژول یا کتابخانه itertools
یکی از روشهایی که معمولا در راه حلهای ارائه شده برای حل این مسئله مورد اشاره قرار نمیگیرد استفاده از تابع درونی accumulate() است. این تابع در کتابخانه «itertools» به صورت آماده قرار دارد. این تابع کمک میکند که حاصل جمع «انباشت تدریجی» (Cumulative) عناصر هر شی پیمایشپذیری را محاسبه کنید. همچنین این تابع شی پیمایشپذیری را برمیگرداند که حاصل جمع عناصر را در هر مرحله بهترتیب نگهداری میکند.
برای استفاده از این تابع باید لیست را به عنوان آرگومان اول و تابع operator.add را به عنوان آرگومان دوم ارسال کنیم. آرگومان دوم نشان میدهد که میخواهیم حاصل جمع انباشت تدریجی عناصر لیست ارسال شده را محاسبه کنیم. در کد پایین، مثالی از روش پیادهسازی حل مسئله با استفاده از این تابع را نمایش دادهایم.
خروجی کد بالا به صورت زیر است.
[10, 30, 60, 100, 150]استفاده از تابع numpy.cumsum
توجه کنید که برای استفاده از این روش در ابتدا باید کتابخانه Numpy را با استفاده از فرمان زیر در خط فرمان بر روی سیستم خود 0نصب کنید.
pip install numpyکتابخانه Numpy دارای توابع ریاضی بسیار زیادی است. یکی از این توابع، تابع cumsum() نام دارد. این تابع با توجه به محور مشخص شده حاصل جمع Cumulative عناصر هر آرایهای را محاسبه میکند.

برای اینکه از این تابع استفاده کنیم اول از همه نیاز داریم که لیست خود را با استفاده از تابع numpy.array() به آرایه مخصوص Numpy تبدیل کنیم. سپس میتوانیم بر روی آرایه بدست آمده تابع cumsum() را فراخوانی کنیم تا حاصل جمع Cumulative عناصر آرایه را محاسبه کند. در نهایت میتوانیم با استفاده از متد tolist() آرایه Numpy نتیجه گرفته شده را به لیست معمولی پایتونی تبدیل کنیم.
در کد پایین روش استفاده از تابع cumsum()را برای حل مسئله مورد نظر با دادههای دلخواه پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
[10, 30, 60, 100, 150]پیدا کردن مجموع ارقام عددهای موجود در لیست
مسئله پیدا کردن مجموع ارقام عددهای موجود در ساختارهای داده بسیار رایج و پُر برخورد است. این مسئله میتواند بعضی وقتها در زمان کار با لیست هم پیش بیاید. در نهایت باید با روشهای حل کردن این مسئله آشنا شویم. دانش لازم برای حل این مسئله در طیف گستردهای از برنامهها، از تمرینات مدرسه گرفته تا «توسعه برنامههای اینترنتی» (Web Development) کاربرد دارد.
در ادامه مطلب به بحث درباره روشهای مشخص ارائه شده برای حل این مسئله، خواهیم پرداخت.
فهرست زیر روشهایی را نشان میدهد که در این مبحث به آنها پرداختهایم.
- استفاده از حلقه به همراه تابع str()
- استفاده از تابع sum() همراه با تکنیک List Comprehension
- استفاده از توابعsum() همراه با reduce()
استفاده از حلقه به همراه تابع str
استفاده از این روش برای حل این مسئله بخصوص، «روش برنامهنویسی پُر قدرت» (Brute Force Method) محسوب میشود. در این روش با استفاده از حلقهای بر روی همه عنصرها پیمایش میکنیم. به هر عنصر که میرسیم، عنصر مورد نظر را با کمک تابع str() به رشته تبدیل میکنیم و عمل جمع کردن را بروی تک تک ارقام آن انجام میدهیم.
در بخش پایین به کدهای پایتون آماده توجه کنید. این کدها از روی توضیح بالا پیادهسازی شدهاند.
نتیجه اجرای کد بالا بهشکل زیر است.
The original list is : [12, 67, 98, 34]
List Integer Summation : [3, 13, 17, 7]استفاده از تابع sum همراه با تکنیک List Comprehension
میتوان این مسئله را با روشهای کوتاهتری نیز حل کرد. به این منظور میتوانیم از توابعی که در بخشهای قبل معرفی شده استفاده کنیم. تابع sum()برای محاسبه حاصل جمع و تکنیک List Comprehension برای محاسبه عملیات همراه با پیمایش مورد استفاده قرار میگیرند. به کدی که در پایین با استفاده از این مفاهیم برای حل مسئله پیادهسازی شده توجه کنید.
نتیجه اجرای کد بالا بهشکل زیر است.
The original list is : [12, 67, 98, 34]
List Integer Summation : [3, 13, 17, 7]استفاده از تابع sum همراه با reduce
این تکنیک هم برای مختصرنویسی عالی است. در واقع از توابعی استفاده میکنیم که برای اجرای عملیات پیچیده در یک خط کد طراحی شدهاند. برای محاسبه حاصل جمع بر روی اعضای هر شی پیمایشپذیر استفاده از تابع sum()به همراه تابع reduce()نیز روش بسیار موثری است. تابع reduce() در کتابخانه functoolsتعریف شده است.

در کدهای پایتون آماده زیر از این توابع در کنار هم برای حل مسئله جمع ارقام عناصر لیست استفاده کردهایم. به کدهای پایین توجه کنید.
نتیجه اجرای کد بالا بهشکل زیر است.
The original list is : [12, 67, 98, 34]
List Integer Summation : [3, 13, 17, 7]قطعه بندی کردن لیست به لیست هایی با بیشترین اندازه N
در این بخش از مطلب به بررسی کدهای پایتون آماده برای برنامههایی میپردازیم که لیستها را به لیستهای کوچکتری با بیشترین اندازه N تقسیم میکنند.
در ادامه سه روش فهرست شده زیر را برای حل این مسئله بررسی خواهیم کرد.
- استفاده از کلمه کلیدی yield در پایتون
- استفاده از حلقه for
- استفاده از ابزار درونی کتابخانه Numpy
بررسی کدها را از اولین مطلب شروع میکنیم.
استفاده از کلمه کلیدی yield در پایتون
کلمه کلیدی yieldدر پایتون این امکان را برای توابع فراهم میکند که از کار بهایستند و محل توقف خود را به یاد داشته باشند. هر تابعی که با کلمه کلیدی yieldهمراه شده بود اگر دوباره فراخوانی شود میتواند به ادامه کار خود از محل توقف قبلی بپردازد. این خواصیت تفاوت بسیار حساسی است که تابع معمولی با تابعی فراخوانی شده همراه با کلمه کلیدی yieldدارد. توابع معمولی نمیتوانند کار خود را از جایی که قبلا رها کردهاند دوباره شروع کنند.
کلمه کلیدی yieldبه توابع کمک میکند که حالت خود را طی اجرای عملیات در حافظه ثبت کنند. کلمه کلیدی yieldمیتواند کمک کند که تابعی در وسط فرایند اجرا متوقف شده و مقداری را برگرداند. سپس فرایند اجرای خود را از محل توقف دوباره از سر بگیرد و از همان حالت به کار ادامه دهد.
به کدی که در ادامه آمده توجه کنید. این کد را درباره نحوه استفاده از کلمه کلیدی yield برای حل این مسئله پیادهسازی کردهایم.
خروجی کد بالا بهشکل زیر است.
[['geeks', 'for', 'geeks', 'like', 'geeky'],
['nerdy', 'geek', 'love', 'questions', 'words'],
['life']]استفاده از حلقه for
در این قسمت، برای حل این مسئله از حلقه for در پایتون به همراه عملیات Slicing بر روی لیست استفاده میشود. به کمک ترکیب این مفاهیم برنامهنویسی میتوانیم لیست را به تکههایی با اندازه مورد نظرمان تقسیم کنیم. به کدهای پایتون آماده در پایین توجه کنید. این کدها با کمک این مفاهیم به حل مسئله پرداختهاند.
خروجی کد بالا به صورت زیر است.
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]استفاده از ابزار درونی کتابخانه Numpy
در این قسمت برای حل مسئله تکهتکه کردن لیستها به لیستهای کوچکتر از تابع Numpy.array_split() استفاده خواهیم کرد. این تابع به صورت اختصاصی برای تقسیم آرایهها به تکههای مساوی تعریف شده است. کدی که در ادامه میبینید مثالی ساده است. در صورتی که بخواهید از تابع Numpy.array_split() بر روی لیستها استفاده کنید باید فرایند مخصوصی طراحی کنید. این فرایند خاص باید در ابتدا لیستها را به آرایههای مخصوص Numpy تبدیل کند و بعد از آن میتوانید به اجرای عملیات تکهسازی بپردازید. در نهایت لازم است همه آرایههای کوچک ساخته شده را دوباره بهسادگی با استفاده از توابع درونی پایتون بهلیست تبدیل کنید.

در صورتی که تمایل به مطالعه بیشتر درباره کتابخانه Numpy پایتون دارید میتوانید از مطالب آماده شده درباره این کتابخانه در مجله فرادرس استفاده کنید.
به مثال ساده زیر درباره استفاده از تابعNumpy.array_split() توجه کنید.
خروجی حاصل از اجرای کد بالا بهشکل زیر است.
[array([0, 1, 2, 3, 4]),
array([5, 6, 7, 8, 9]),
array([10, 11, 12, 13, 14]),
array([15, 16, 17, 18, 19]),
array([20, 21, 22, 23, 24]),
array([25, 26, 27, 28, 29])]مرتب سازی لیست بر اساس داده های لیست دیگر
در فرض این مسئله چنین آمده است که دو لیست مختلف ارائه شدهاند. دادههای این دو لیست با هم متناظر هستند. پس مسئله این است: برنامهای بنویسید که وقتی دادههای لیست list2 را مرتب کردیم، لیست جدید از دادههای مرتب شده لیست list1 بر اساس list2 بهوجود بیاید.
در واقع فرض کنید که لیستهای داده شده به صورت زیر هستند.
Input : list1 = [“a”, “b”, “c”, “d”, “e”, “f”, “g”, “h”, “i”]
list2 = [ 0, 1, 1, 0, 1, 2, 2, 0, 1]خروجی که برنامه نوشته شده تولید میکند باید به صورت زیر باشد.
Output : [‘a’, ‘d’, ‘h’, ‘b’, ‘c’, ‘e’, ‘i’, ‘f’, ‘g’]برای حل این مسئله از سه روش متفاوت فهرست شده در زیر استفاده کردهایم.
- استفاده از تابع zip()
- استفاده از مفاهیم تابع lambda و List Comprehension و دیکشنری
- استفاده از توابع sort() و list() و set()
توضیح روشهای بالا را با بررسی روش اول شروع میکنیم.
استفاده از تابع zip
توجه کنید که تابع zip()برای جفت کردن ایندکسهای متناظر با هم در چند لیست مختلف استفاده میشود. در نتیجه میتوان از چندین ساختار ذخیره داده مختلف در کنار یکدیگر همانند موجودیت یکسانی استفاده کرد. برای استفاده از این تابع فرایند حل مسئله را به ۳ قسمت مهم تقسیم میکنیم.
- هر دو لیست را با هم zip میکنیم.
- با استفاده از تابع sorted() لیست منظم شده جدیدی بر پایه شی zip شده ایجاد میکنیم.
- با استفاده از تکنیک List Comprehension عنصر اول از هر جفت داده درون لیست zip منظم شده را استخراج میکنیم.
برای درک بهتر مراحل بالا به کدی توجه کنید که در پایین از روی مراحل تعریف شده الگوریتم پیادهسازی شده است.
خروجی کد بالا به صورت زیر است.
['a', 'd', 'h', 'b', 'c', 'e', 'i', 'f', 'g']
['g', 'k', 'r', 'e', 'e', 'g', 's', 'f', 'o']استفاده از مفاهیم تابع lambda و List Comprehension و دیکشنری
در کد پایین برای منظم کردن دادههای لیست list1بر حسب دادههای لیست list2تابعی تعریف شده که دو پارامتر میپذیرد. این پارامترها در واقع لیستهای فرض مسئله هستند. در این کد با استفاده از مفهوم دیکشنری دادههای دو لیست مجزا را در ابتدا در یک دیکشنری به صورت کلید و مقدار جمع کردهایم. سپس با استفاده از مفاهیم تابع lambda و List Comprehension دیکشنری را منظم کردیم. در نهایت با استفاده از حلقه forمقادیر مرتب شده لیست list1را بر حسب دادههای لیست list2استخراج کردیم.

به کدهای پایتون آماده شده در پایین نگاه کنید. این کدها از پیادهسازی این فرایند بدست آمدهاند.
خروجی کد بالا بهشکل زیر است.
['a', 'd', 'h', 'b', 'c', 'e', 'i', 'f', 'g']استفاده از توابع sort و list و set
در این الگوریتم اول از همه مقادیر تکراری لیست شماره ۲ list2را حذف میکنیم. سپس این لیست را منظم میکنیم. در نهایت با استفاده از ۲ حلقه forبه صورت تو در تو به ازای هر عضو در list2یکبار list1را پیمایش میکنیم. در هر مرحله پیمایش دادهها را متناظر با عناصر مرتب شده در list2به لیست جدید res = [] اضافه میکنیم. در نهایت لیست res را که حاوی دادههای منظم شده list1بر حسب list2است به عنوان خروجی نمایش میدهیم.
به کدی که در پایین از پیادهسازی این عملیات بدست آمده دقت کنید.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
['a', 'd', 'h', 'b', 'c', 'e', 'i', 'f', 'g']برنامه های مربوط به اجرای عملیات بر روی ماتریس ها
ماتریسها آرایههای دو بعدی هستند که برای ذخیره دادهها در سطر و ستون استفاده میشوند. در پایتون اغلب از لیستهای تو در تو برای نمایش ماتریسها استفاده میشود. در این بخش کدهای پایتون آماده مربوط به اجرای انواع عملیات بر روی ماتریسها را بررسی میکنیم.
برنامه پایتون برای جمع دو ماتریس با یکدیگر
در این مسئله فرض میکنیم که دو ماتریس X و Y داده شدهاند. مسئله این است که حاصل جمع دو ماتریس را محاسبه کنیم و در نهایت در خروجی پایتون نمایش دهیم.

به عنوان مثال ماتریسهای زیر داده شدهاند.
Input :
X= [[1,2,3],
[4 ,5,6],
[7 ,8,9]]
Y = [[9,8,7],
[6,5,4],
[3,2,1]]خروجی باید برابر با مقدار صحیح زیر باشد.
Output :
result= [[10,10,10],
[10,10,10],
[10,10,10]]برای حل این مسئله روشهای مختلفی قابل طراحی و اجرا هستند. در این بخش کدهای پایتون آماده مربوط به چهار روش گوناگون را برای بررسی قرار دادهایم.
- جمع دو ماتریس با استفاده از حلقه for
- جمع دو ماتریس با استفاده از تکنیک List Comprehension
- جمع دو ماتریس با استفاده از تابعzip()
- جمع دو ماتریس با استفاده از ابزار کتابخانه Numpy
ادامه این بخش از مطلب را با بحث درباره جمع دو ماتریس با استفاده از حلقه forشروع میکنیم.
جمع دو ماتریس با استفاده از حلقه for
در این بخش برای محاسبه حاصل جمع دو ماتریس بدون استفاده از ابزارهای اختصاصی پایتون به سراغ حلقه forمیرویم. برای حل این مسئله با کمک حلقه forدر ابتدا یک ماتریس خالی با نام دلخواه result و مقدار اولیه صِفر برای هر عنصر تعریف میکنیم. ماتریس result قرار است حاصل جمع عناصر ماتریسها را در خود نگهدارد. سپس با کمک دو عدد، forبه صورت تو در تو سطر به سطر بر روی ماتریسها حرکت میکنیم و ستون به ستون دادههای هر سطر را باهم جمع میبندیم.
به کدهای پایتون آماده زیر توجه کنید. این کدها از روی الگوریتم توضیح داده شده بالا پیادهسازی شدهاند.
خروجی کد بالا به صورت زیر است.
[10, 10, 10]
[10, 10, 10]
[10, 10, 10]جمع دو ماتریس با استفاده از تکنیک List Comprehension
در این روش هم از دو حلقه forاستفاده میکنیم تا بر روی سطرها و ردیفها حرکت کنیم. در هر قدم پیمایش، عناصر متناظر با هم را در دو ماتریس داده شده جمع میبندیم و در جایگاه صحیح خودشان داخل ماتریس result قرار میدهیم. در واقع این روش را به عنوان تکنیک List Comprehension تو در تو نیز میتوان نامگزاری کرد. زیرا در پایتون میتوان ماتریسها را به صورت لیستهای تو در تو نمایش داد. در واقع با هر عنصر لیست بیرونی به عنوان سطری در ماتریس رفتار میشود.

به کدی که در ادامه آمده توجه کنید.
خروجی کد بالا به صورت زیر است.
[10, 10, 10]
[10, 10, 10]
[10, 10, 10]جمع دو ماتریس با استفاده از تابع zip
در این قسمت نیز هدف جمع کردن دو ماتریس و برگرداندن خروجی است. برای اجرای این عملیات از تکنیک List Comprehension تو در تو استفاده کردهایم. به کمک این روش بر روی هر عنصر ماتریس پیمایش میکنیم و عمل جمع را بر روی عناصر متناظر با هم انجام میدهیم. تکنیک List Comprehension به برنامهنویسان کمک میکند که کدها را به صورت بسیار مختصر و مفید بنویسند. بنابراین باید تلاش کنیم برای تسلط بر تکنیک List Comprehension به صورت متداول از آن استفاده کنیم. مختصرنویسی کدها کاری بسیار پُر فایده با ظاهری بسیار حرفهای است.
کدی که در پایین میبینید، برای حل مسئله به روش توضیح داده شده بالا پیادهسازی شده است.
خروجی کد بالا به صورت زیر است.
[[10, 10, 10], [10, 10, 10], [10, 10, 10]]استفاده از ابزار کتابخانه Numpy برای جمع ماتریس ها
کتابخانه Numpy برای جمع ماتریسها عملگر + را به صورت «درونی» (Built-In) «سربارگزاری» (Overload) کرده است. البته بازنویسی عملگر +در کتابخانه Numpy دلایل و نتایج زیادی داشته که یکی از آنها توانایی جمع بین ماتریسها است. برای استفاده از این کتابخانه در ابتدا باید با کمک تابع np.array() ماتریسها را به آرایههای مخصوص Numpy تبدیل کنیم.
استفاده از این ابزار، کدنویسی را به مقدار بسیار زیادی کاهش میدهد. به مثال آمده در پایین توجه کنید. پیادهسازی این مثال، در رابطه با ابزار Numpy است.
خروجی کد بالا به صورت زیر است.
[10, 10, 10]
[10, 10, 10]
[10, 10, 10]برنامه پایتون برای ضرب دو ماتریس در یکدیگر
در این مسئله فرض میکنیم که دو ماتریس مجزا از هم داده شده است. باید برنامهای بنویسیم که حاصل ضرب این دو ماتریس را در یکدیگر محاسبه کند و نتیجه را در خروجی نمایش دهد.
به عنوان مثال اگر ماتریسهای زیر داده شده باشند.
Input : X = [[1, 7, 3],
[3, 5, 6],
[6, 8, 9]]
Y = [[1, 1, 1, 2],
[6, 7, 3, 0],
[4, 5, 9, 1]]خروجی برنامه باید چیزی شبیه به مورد پایین باشد.
Output : [55, 65, 49, 5]
[57, 68, 72, 12]
[90, 107, 111, 21]برای حل این مسئله سه روش متفاوت را همراه با کدهای پایتون آماده مربوط به هر کدام بررسی خواهیم کرد. هر کدام از این روشها از تکنیکهای کاملا مجزایی استفاده میکنند. تسلط به استفاده از این تکنیکها مهارت برنامهنویسان را در حل مسائل پیچیده افزایش میدهد.
- استفاده از لیستهای تو در تو به همراه تابعzip()
- استفاده از ابزار کتابخانه Numpy
- استفاده از توابع بازگشتی برای محاسبه حاصل ضرب دو ماتریس

نمایش و بررسی کدهای پایتون آماده برای روشهای حل مسئله را به ترتیب از روش اول شروع میکنیم.
استفاده از لیست های تو در تو به همراه تابع zip
در این روش از لیستهای تو در تو برای پیمایش بر روی عناصر ماتریسها استفاده کردهایم. به کد آمده در پایین توجه کنید. این کد در یک خط تمام محاسبات را انجام داده است.
خروجی کد بالا به صورت زیر است.
[114, 160, 60, 27]
[74, 97, 73, 14]
[119, 157, 112, 23]استفاده از ابزار کتابخانه Numpy
در این روش از تابع dot() استفاده شده است. این تابع جزو توابع تعریف شده کتابخانه Numpy است که برای ضرب ماتریسها استفاده میشود. توجه کنید که مقداردهی اولیه برای متغیر result به صورت یک ماتریس ۳ در ۴ و با عناصر صِفر الزامی نیست و جزوی از فرایند حل مسئله نیست.
به کد زیر توجه کنید. این کد فرایند توضیح داده شده بالا را پیادهسازی کرده است.
خروجی کد بالا به صورت زیر است.
[114, 160, 60, 27]
[74, 97, 73, 14]
[119, 157, 112, 23]استفاده از توابع بازگشتی برای محاسبه حاصل ضرب دو ماتریس
در این الگوریتم از سادهترین و رایج ترین توابع درونی پایتون برای حل مسئله استفاده شده است. البته این کد، کدنویسی طولانیتری نسبت به روشهای توصیف شده قبلی دارد. الگوریتم پیادهسازی شده پایین را میتوان در ۶ مرحله توضیح داد.
- در ابتدای کار باید بررسی کنیم که آیا ابعاد ماتریسهای ورودی برای انجام عمل ضرب معتبر هستند یا نه. طبق قوانین ضرب در ماتریسها اگر تعداد ستونهای ماتریس اول با تعداد سطرهای ماتریس دوم برابر نباشد، بنابراین نمیتوان این دو ماتریس را در یکدیگر ضرب کرد. در این مسئله باید برای این شرایط در ماتریسها اعتبار سنجی کرد. در صورت مغایرت تعداد سطر و ستونهای ماتریسها با شرط گفته شده بالا یا باید پیغام خطای مناسبی برگردانیم یا مقدار None را به عنوان نتیجه ضرب در خروجی نمایش دهیم.
- سپس باید اندازه ماتریسها را بررسی کنیم. اگر اندازه ماتریسها 1*1 بود فقط کافی است که عناصر آنها را در یکدیگر ضرب کنیم. بعد باید مقدار جواب را برگردانیم.
- اگر اندازه ماتریسها 1*1 نبود هر ماتریس را باید به چهار زیر مجموعه ماتریسی با اندازه مساوی تقسیم کنیم.
- به صورت بازگشتی زیرمجموعههای ماتریسی را به صورتی که گفته شد در یکدیگر ضرب کنید تا وقتی که اندازه هر زیرمجموعه ماتریسی برابر با 1*1 شود.
- حاصل ضرب زیرمجموعههای ماتریسی را محاسبه کنید. برای محاسبه این ضرب از فرمولی که در پایین آمده استفاده کنید.
- result = [A11B11 + A12B21, A11B12 + A12B22, A21B11 + A22B21, A21B12 + A22B22]
- در آخر ماتریس نتیجه را از تابع برگردانید.

به کد زیر نگاه کنید. الگوریتمی را که در مراحل بالا توضیح دادیم در کد زیر پیادهسازی کردهایم .
خروجی کد بالا به صورت زیر است.
[114, 160, 60, 27]
[74, 97, 73, 14]
[119, 157, 112, 23]محاسبه حاصل ضرب همه عناصر ماتریس در یکدیگر
انجام عملیات برای محاسبه حاصل ضرب همه عناصر لیستها در یکدیگر بسیار عادی است. بارها با این مسئله روبهرو شدهایم. همچنین در این مطلب هم چند روش مختلف را برای حل این مسئله بررسی کردهایم. اما بعضی وقتها لازم میشود که حاصل ضرب همه عناصر ماتریسها یا لیستهای تو در تو را نیز محاسبه کنیم. در این مطلب درباره روشهای محاسبهحاصل ضرب لیستهای تو در تو بحث کردهایم و انواع کدهای پایتون آماده را برای روشهای مختلف نمایش دادهایم. برای تمرین در این بخش، سه روش کلی برای انجام این عمیات در پایتون را مورد بحث قرار دادیم.
- استفاده از حلقههای پایتون همراه با تابع chain()
- استفاده از متد extend()
- استفاده از کدهای ساده پایتونی برای پیمایش بر روی عناصر لیستهای تو در تو
در ادامه مطلب هر سه روش بالا را به ترتیب مورد بحث قرار میدهیم.
استفاده از حلقه های پایتون همراه با تابع chain
برای حل این مسئله خاص میتوان هم از تکنیک List Comprehension و هم از تابع chain() استفاده کرد. در این روش برای حل مسئله از تابع chain() بهجای تکنیک List Comprehension و توابع مرسوم پایتون استفاده کردهایم.
به کد زیر دقت کنید. کد زیر مثال سادهای درباره نحوه استفاده از تابع chain()را پیادهسازی کرده است.
خروجی کد بالا به صورت زیر است.
The original list : [[1, 4, 5], [7, 3], [4], [46, 7, 3]]
The total element product in lists is : 1622880استفاده از متد extend
متد extend() یکی از متدهای درونی پایتون است. در این روش ابتدا لیستی خالی تعریف کردهایم. سپس با کمک آن لیست و متدextend() کل دادههای لیست تو در تو را به صورت عادی درون لیست یک بعدی وارد کردیم. بعد از آن همه عناصر لیست را به صورت کاملا کارآمد و سادهای با یکدیگر ضرب میکنیم. در نهایت باید نتیجه حاصل ضرب را نمایش دهیم.
به کد پایین توجه کنید. کد پایین نسخه پیادهسازی شده الگوریتم توضیح داده شده بالا است.
خروجی کد بالا به صورت زیر است.
The original list : [[1, 4, 5], [7, 3], [4], [46, 7, 3]]
The total element product in lists is : 1622880استفاده از توابع بازگشتی برای پیمایش لیست های تو در تو
در این روش تلاش داریم که مسئله را تا حد امکان از طریق توابع مرسوم و ساده پایتون و با تکنیک تابع بازگشتی حل کنیم. مراحل پیادهسازی این روش حل مسئله، شامل الگوریتم به همراه کدهای لازم برای بررسی و تست برنامه و نمایش نتیجه نهایی میشود. تمام این مراحل را در ۱۱ گام میتوان به شرح زیر توضیح داد.
- در ابتدای کار تابعی با نام دلخواه multiply_nested_list تعریف میکنیم که به عنوان پارامتر یک لیست تو در تو را دریافت میکند.
- داخل این تابع متغیری به نام دلخواه res با مقدار 1 تعریف میکنیم. توجه کنید که مقدار این متغیر باید حتما 1 باشد نه 0.
- با کمک حلقه forبر روی هر عنصر iدر لیست ورودی پیمایش میکنیم.
- برای هر عنصری که در طی انجام عمل پیمایش بر روی لیست به آن برخورد میکنیم، باید لیست بودن را بررسی کنیم. این بررسی را با استفاده از تابع isinstance() انجام میدهیم.
- اگر که عنصر در حال بررسی i، لیست بود به صورت بازگشتی تابع multiply_nested_list() را فراخوانی میکنیم و عنصر iرا به عنوان پارامتر به تابع ارسال میکنیم. سپس نتیجه را در متغیر res ضرب میکنیم.
- اگر عنصر مورد بررسی در پیمایش، یعنی عنصر iلیست نبود، پس مقدار iرا در متغیر res ضرب میکنیم.
- سپس مقدار نهایی ذخیره شده در متغیر res را برمیگردانیم.
- در کد پایین بعد از پیادهسازی الگوریتم لیست آزمایشی را به نام دلخواه test_list با عناصری از جنس لیست تعریف کردهایم. لیست test_list در واقع یک لیست تو در تو است.
- در خط بعد لیست آزمایشی اصلی test_list را بر روی خروجی پایتون چاپ کردهایم.
- بعد از آن تابعmultiply_nested_list() را فراخوانی میکنیم. این تابع بر اساس الگوریتم توضیح داده شده بالا توسط خودمان کدنویسی شده است. لیست test_list را به عنوان پارامتر ورودی به این تابع ارسال میکنیم و مقدار خروجی تابع را به متغیری به نام res تخصیص میدهیم.
- در نهایت مقدار کل حاصل ضرب همه عناصر لیست را در یکدیگر نمایش میدهیم. این کار را با تبدیل کردن مقدار متغیر res به رشته و چسباندن آن به پیغام اختصاصی برای نمایش به کاربر انجام دادهایم.

به کدهای پایتون آماده زیر توجه کنید. این کدها از پیادهسازی گام به گام مراحل بالا حاصل شدهاند.
خروجی کد بالا به صورت زیر است.
The original list : [[1, 4, 5], [7, 3], [4], [46, 7, 3]]
The total element product in lists is : 1622880تغییر جای سطرها و ستون های ماتریس در پایتون
تغییردادن جای سطرها و ستونهای ماتریسها در پایتون مسئله آسانی است که همه میتوانیم با کمک حلقهای تو در تو در پایتون به حل آن بپردازیم. اما روشهای جالبی برای انجام این کار وجود دارند که میتوانند بهسادگی در یک خط مسئله را حل کنند. در پایتون میتوان ماتریسها را با استفاده از لیستهای تو در تو نمایش داد. در لیست اول هر عنصر نقش یک سطر را در ماتریس بازی میکند. برای مثال لیست m = [[1, 2], [4, 5], [3, 6]] در پایتون نمایانگر ماتریسی است که از ۳ سطر و ۲ ستون تشکیل شده است. اولین عنصر این ماتریس m[0][0] است. ایندکس m[0] نمایانگر اولین سطر ماتریس است و عنصر m[0][0] نمایانگر نقطه تلاقی اولین سطر و اولین ستون است.
فرض کنیم که ماتریس ورودی ما به صورت لیست [[1,2],[3,4],[5,6]] داده شده است. این لیست نشاندهنده شکل ماتریس زیر است.
[[1, 2],<br> [3, 4],<br> [5, 6]]ماتریس خروجی باید بهشکل زیر باشد.
[[1, 3, 5],
[2, 4, 6]]روشهای متفاوتی وجود دارند که میتوانند شکل ترانهاده ماتریسها را به کمک یک خط کد محاسبه کنند. در این بخش به چهار رویکرد بسیار کارآمد مورد استفاده برای تغییر جای سطر و ستون در ماتریس خواهیم پرداخت.
- استفاده از از تکنیک List Comprehension برای تعریف ماتریسها
- استفاده از تابع zip()
- استفاده از ابزار کتابخانه Numpy
- استفاده از ابزار کتابخانه itertools
بررسی روشهای فهرست شده بالا را به ترتیب از روش اول شروع میکنیم.
تکنیک List Comprehension برای تعریف ماتریس ها
از تکنیک List Comprehension برای پیمایش بر روی هر عنصر ماتریس استفاده میشود. در مثال داده شده بر روی هر عنصر در ماتریس m پیمایش خواهیم کرد. این پیمایش به صورت ستونی انجام میگیرد و نتایج را در ماتریس rez وارد میکنیم. ماتریس rezدر نهایت شکل ترانهاده ماتریس m شده است.
به کد زیر توجه کنید. در کد زیر عملیات توضیح داده شده بالا را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر نمایش داده میشود.
[1, 2]
[3, 4]
[5, 6]
[1, 3, 5]
[2, 4, 6]استفاده از تابع zip
تابع zip() در پایتون به عنوان خروجی، شی پیمایشپذیری برمیگرداند. عناصر این شی پیمایشپذیر از نوع ساختار ذخیره داده تاپل هستند. این تابع به این صورت کار میکند که به عنوان ورودی میتواند چند شی پیمایشپذیر دریافت کند. سپس عناصر متناظر این اشیا را با یکدیگر در یک تاپل قرار میدهد. یعنی در واقع خروجی شی Zip، به عنوان مثال عنصر اول، تاپلی است که از عناصر اول اشیا پیمایشپذیری تشکیل شده که که تابع zip() به عنوان پارامتر دریافت کرده است.
در مثال پایین با استفاده از عملگر * قبل از نام آرایه، آرایه خود را Unzip میکنیم. یعنی تاپلها را از درون لیست خارج میکنیم. در نتیجه ساختار داده از این به بعد در عوض اینکه در شکل لیستی با چهار عنصر از جنس تاپل باشد، به چهار تاپل مجزا از هم تبدیل میشود. سپس با استفاده از تابع zip() شکل ترانهاده ماتریس را بدست میآوریم. به کدی پایین توجه کنید. در کد پایین مطابق توضیح بالا، فرایند حل مسئله را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
(1, 2, 3)
(4, 5, 6)
(7, 8, 9)
(10, 11, 12)
(1, 4, 7, 10)
(2, 5, 8, 11)
(3, 6, 9, 12)استفاده از ابزار کتابخانه Numpy
کتابخانه Numpy ماژول تخصصی پایتونی است که با هدف کلی کار بر روی آرایهها ارائه شده است. این کتابخانه به صورت بسیار موثری برای اجرای فعالیتهای حرفهای در رابطه با آرایههای چندبعدی بزرگ طراحی شده است.

متد transpose() ساختار ترانهاده شده ماتریس چندبعدی را که به عنوان پارامتر دریافت کرده به عنوان خروجی برمیگرداند.
خروجی کد بالا بهشکل زیر است.
[[1, 2, 3], [4, 5, 6]]
[[1 4]
[2 5]
[3 6]]ابزار بعدی در کتابخانه Numpy عبارت .T است. این عبارت به صورت تخصصی برای تغییر جای سطرها و ستونها در آرایههای Numpy استفاده میشود. به کدی که در ادامه آمده توجه کنید.
خروجی کد بالا بهشکل زیر است.
[[1, 2, 3], [4, 5, 6]]
[[1 4]
[2 5]
[3 6]]سریع ترین روش ترانهادن ماتریس با استفاده از ابزار کتابخانه itertools
کتابخانه itertoolsیکی از ماژولهای تخصصی پایتون است. این ماژول شامل توابع گسترده و متنوعی برای کار با اشیا پیمایشپذیر است و میتواند عملیات پیمایش پیچیده را نیز مدیریت کند. تابع chain() یکی از ابزار این کتابخانه است. این تابع مجموعهای از اشیا پیمایشپذیر را دریافت میکند و یک شی پیمایشپذیر را به عنوان خروجی برمیگرداند.
در مثال پایین، از تابع chain() استفاده میکنیم تا همه مقادیر درون ماتریس را دریافت کنیم و به لیست سادهای تبدیل کنیم. سپس در ماتریس جای سطرها و ستونها را تغییر دهیم. این روش از روشهای دیگر گفتهشده بسیار سریعتر عمل میکند. به کد پایین نگاه کنید. میتوانید در این کد فرایند کدنویسی الگوریتم ساده بالا را ببینید.
خروجی که از اجرای کد بالا به دست میآید بهشکل زیر است.
[[1, 4], [2, 5], [3, 6]]
Time taken 108570 nsساخت ماتریس n*n
در «علم داده» (Data Science) تقریبا همیشه با اعداد کار میکنیم. یکی از مسائل، هنگام کار در علم داده این است که بعضی وقتها لازم میشود عددی را به ماتریسی از اعداد متوالی تبدیل کنیم. این مسئله یکی از مسائل رایج کار در علم داه است که حتما بارها با آن روبهرو خواهید شد. حالا که به اهمیت این مسئله پِی بردیم باید با انواع روشهای حل این مسئله نیز آشنا شویم.
در این بخش، کدهای پایتون آماده برای سه روش مختلف ساخت ماتریس را بررسی خواهیم کرد. توجه کنید این روشها به صورت اختصاصی برای این مسئله خاص کاربرد دارند.
- استفاده از تکنیک List Comprehension
- استفاده از توابع next() و itertools.count() در تعامل با یکدیگر
- استفاده از تکنیک List Comprehension به همراه تابع enumerate()
در ادامه مطلب، هر سه روش بالا را به ترتیب از گزینه اول، مورد بحث قرار دادهایم.
استفاده از تکنیک List Comprehension
با استفاده از تکنیک List Comprehension میتوان این مسئله خاص را حل کرد. بهمنظور انجام این کار باید برای هر لیست که قرار است به صورت متوالی ساخته شود از تابع range() استفاده کنیم. به کد زیر دقت کنید. کل فرایند توضیح داده شده را در کد زیر پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The dimension : 4
The created matrix of N * N: [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]استفاده از توابع next و itertools.count در تعامل با یکدیگر
در این روش از تابع count() برای شروع عملیات شمارش اعداد استفاده میشود و تابعnext() وظیفه ایجاد زیرلیستها را به صورت پشت سر هم دارد. تکنیک List Comprehension هم برای مدیریت فرایند بهکار برده شده است. به شکل پیادهسازی شده این الگوریتم در کد پایین توجه کنید.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The dimension : 4
The created matrix of N * N: [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]استفاده از تکنیک List Comprehension به همراه تابع enumerate
در این کد با کمک تکنیک List Comprehension بر روی سطرهای ماتریس پیمایش انجام میدهیم. برای پیدا کردن شماره ایندکس هر سطر از تابع enumerate() استفاده میکنیم. در نهایت با استفاده از List Comprehension به صورت تو در تو عناصر هر سطر را تولید میکنیم. Comprehension درونی که برای تولید عناصر متوالی بهکار میرود از فرمول i * n + j استفاده میکند. این Comprehension بر روی ستونهای ماتریس پیمایش میکند. در این الگوریتم شمارنده i نمایانگر شماره ایندکسهای سطرها و شمارنده j نمایانگر شماره ایندکسهای ستونها است.

در کد زیر الگوریتم توصیف شده بالا را پیادهسازی کردهایم. به کد زیر دقت کنید.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The dimension : 4
The created matrix of N * N: [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]استخراج داده های ستون شماره K از ماتریس
بعضی وقتا که در حال کار بر روی ماتریسها در پایتون هستیم ممکن به مشکل خاصی برخورد کنیم. برای حل این مشکل باید دادههای ستون مشخصی -مثلا ستون شماره K - را از ماتریس استخراج کنیم. این مسئله یکی از مشکلات متداول در حوزه «یادگیری ماشین» (Machine Learning) است. پس داشتن راه حل آماده برای این مسئله میتواند بسیار مفید باشد.
برای حل این مسئله روشهای مختلفی توسط برنامهنویسان ابداع شده است. در ادامه این مطلب کدهای پایتون آماده از چهار روش مختلف برای حل این مسئله را بررسی خواهیم کرد.
- استفاده از تکنیک List Comprehension برای تعریف لیستها
- استفاده از ابزار کتابخانه Numpy
- استفاده از حلقه for
- استفاده از تکنیک Slicing در لیستها
بررسی این سری از کدهای پایتون آماده را از گزینه اول یعنی روش استفاده از تکنیک List Comprehension برای استخراج دادههای ستون شماره Kاز ماتریس شروع میکنیم.
تکنیک List Comprehension برای استخراج داده های ستون شماره K از ماتریس
یکی از بهترین روشهای حل این مسئله استفاده از تکنیک List Comprehension است. زیرا در این تکنیک میتوانیم بر روی همه سطرهای ماتریس پیمایش کنیم. در طول این پیمایش به صورت گزینشی همه عناصر منطبق با ایندکس شماره Kرا جمعآوری میکنیم.
به کد زیر نگاه کنید. در کد پایین الگوریتم توضیح داده شده بالا را پیادهسازی کردهایم.
خروجی کد بالا بهشکل زیر است.
The original list is : [[4, 5, 6], [8, 1, 10], [7, 12, 5]]
The Kth column of matrix is : [6, 10, 5]استفاده از ابزار کتابخانه Numpy
اگر میخواهیم با کتابخانه Numpy کار کنید در ابتدا باید این کتابخانه را با اجرای دستور زیر در خط فرمان نصب کنید.
pip install numpyاین مسئله با ابزار تعبیه شده در کتابخانه Numpy هم قابل حل است. کتابخانه Numpy روش بسیار کارآمد و سادهای را برای بدست آوردن دادههای ستون شماره Kدر ماتریس ارائه میدهد. تمام این کد بسیار ساده است. فقط باید به سینتکس عبارت np.array(test_list)[:,K] دقت کنید. به کد زیر نگاه کنید. در کد پایین روش استفاده از این عبارت را پیادهسازی کردهایم.
خروجی کد بالا بهشکل زیر است.
The original list is : [[4, 5, 6], [8, 1, 10], [7, 12, 5]]
The Kth column of matrix is : [6, 10, 5]استفاده از حلقه for
در این روش با استفاده از حلقه forبر روی سطرهای ماتریس قدم به قدم پیمایش میکنیم. در هر سطر عنصر شماره Kرا استخراج میکنیم. برای استخراج عنصر Kاز ایندکسها استفاده میکنیم. سپس عناصری که استخراج شدهاند را به لیست جدید با نام دلخواه res اضافه میکنیم. خروجی نهایی این الگوریتم، لیست res است که شامل دادههای ستون Kاز ماتریس مرجع است.
در کد زیر فرایند الگوریتم بالا پیادهسازی شده است. به کد زیر توجه کنید.
خروجی کد بالا بهشکل زیر است.
The Kth column of matrix is : [6, 10, 5]استفاده از تکنیک Slicing در لیست ها
در این روش حل مسئله از روش Slicing در لیستها برای حل سوال استفاده میکنیم. این الگوریتم چهار مرحله اساسی دارد که به صورت یک به یک در فهرست زیر توضیح دادهایم.
- لیستی را برای ذخیره ستون K-ام ماتریس تعریف میکنیم. در اینجا از نام دلخواه res استفاده کردهایم.
- بر روی هر سطر ماتریس با کمک حلقه شروع به گردش میکنیم.
- تمام عناصر درون ایندکس شماره Kاز هر سطر را به لیست res اضافه میکنیم. لیست res در مرحله اول تعریف کردهایم.
- لیست res را به عنوان ستون شماره Kماتریس برمیگردانیم.

به کد زیر توجه کنید. کد زیر شکل کدنویسی الگوریتم توضیح داده شده در بالا است.
خروجی کد بالا بهشکل زیر است.
The original list is : [[4, 5, 6], [8, 1, 10], [7, 12, 5]]
The Kth column of matrix is : [6, 10, 5]الحاق عناصر ماتریس به صورت عمودی
در این مسئله فرض میکنیم که ماتریسی با عناصری از جنس نوع داده «رشته» (String) داریم. سوال این است: باید برنامهای بنویسیم که عناصر هر ستون را در ماتریس به یکدیگر الحاق کند. توجه کنید که طول رشتهها ممکن است با هم فرق کند. پس برنامهای که طراحی میکنیم باید بتواند این تفاوت اندازه رشتهها را مدیریت کند.
فرض کنید که ماتریس زیر را به عنوان ورودی به برنامه دادهایم.
Input : [[“Gfg”, “good”], [“is”, “for”]] برنامه ما با توجه به وظیفهاش برای الحاق عناصر هر ستون باید خروجی مطابق لیست زیر تولید کند.
Output : [‘Gfgis’, ‘goodfor’] برای حل این مسئله کدهای پایتون آماده مربوط به سه روش مختلف را پیادهسازی کردیم. این روشها را در فهرست زیر نام بردهایم.
- روش ساده پایتونی با استفاده از حلقه
- استفاده از توابع join() و zip_longest() به همراه تکنیک List Comprehension
- استفاده از ابزارهای numpy.transpose() و numpy.ravel() از کتابخانه Numpy
بررسی کدهای پایتون آماده را برای حل این مسئله به ترتیب از روش اول شروع میکنیم.
روش ساده پایتونی با استفاده از حلقه
روش ساده پایتونی با استفاده از حلقه، روشی قوی و ساده برای حل این مسئله است. در این روش، بر روی همه ستونها پیمایش میکنیم و عملیات چسباندن رشتهها را انجام میدهیم. به کد زیر نگاه کنید. از حلقه while درون حلقه forاستفاده کردهایم. همچنین برای اعتبار سنجی ستونها نیز از بلاک try/except استفاده کردهایم.
خروجی کد بالا بهشکل زیر است.
The original list : [['Gfg', 'good'], ['is', 'for'], ['Best']]
List after column Concatenation : ['GfgisBest', 'goodfor']استفاده از توابع join و zip_longest به همراه تکنیک List Comprehension
با ترکیب توابع join() و zip_longest() نیز میتوان این مسئله را حل کرد. در این روش مقادیر ایندکسهای خالی را با استفاده از تابع zip_longest() مدیریت میکنیم. از تابع join() نیز برای انجام عملیات چسباندن رشتهها استفاده میکنیم. در نهایت هم با تکنیک List Comprehension، منطقی یک خطی را برای ساخت عناصر لیست res پیادهسازی کردهایم.
به کد زیر دقت کنید. تمام فرایند بالا در یک خط کد پیادهسازی شده است.
خروجی کد بالا بهشکل زیر است.
The original list : [['Gfg', 'good'], ['is', 'for'], ['Best']]
List after column Concatenation : ['GfgisBest', 'goodfor']استفاده از ابزارهای transpose و ravel در کتابخانه Numpy
کتابخانه Numpy به صورت تخصصی برای کار با آرایههای چندبعدی پیادهسازی شده است. پس تعجبی ندارد اگر برای حل همه مسائل مربوط به ماتریسها توابع اختصاصی ارائه دهد. برای حل این مسئله هم میتوان از توابع کتابخانه Numpy استفاده کرد.
روش کار این الگوریتم را قدم به قدم در مراحل زیر توضیح دادهایم.
- در ابتدا باید کتابخانه numpy را Import کنیم.
- سپس لیستtest_list را مقداردهی میکنیم. تصمیم داریم الگوریتم خود را بر روی این لیست آزمایش کنیم.
- با استفاده از تکنیک List Comprehension به همراه تابع max() بیشترین طول عناصر لیستtest_lisرا پیدا میکنیم.
- برای اینکه مطمئن شویم همه «زیرلیستها» (Sublists) طول یکسانی دارند- به لیستهایی که عضوی لیست دیگری هستند زیر لیست میگویند- میتوانیم یکبار دیگر از تکنیک List Comprehension استفاده کنیم. در این عملیات Comprehension به بقیه زیر لیستهایی که کوتاهتر هستند رشتههای خالی اضافه میکنیم.
- لیست پر شده را با استفاده از تابع np.array() به آرایه مخصوص Numpy تبدیل میکنیم.
- از ابزار مخصوص «ترانهادن» (Transpose) T برای جابهجا کردن سطرها و ستونها استفاده میکنیم.
- یکبار دیگر از عملیات List Comprehension به همراه تابع join() استفاده میکنیم تا همه رشتهها را در هر سطر از آرایه ترانهاده شده بهیکدیگر بچسبانیم.
- در نهایت باید نتیجه را بر روی خروجی نمایش دهیم.

به کد زیر نگاه کنید. تمام مراحل توضیح داده شده در بالا را در کد زیر پیادهسازی کردهایم.
خروجی حاصل از اجرای برنامه بالا به صورت زیر است.
List after column concatenation: ['GfgisBest', 'goodfor']کدهای پایتون آماده برای کار با رشته ها
اگر بهدنبال نمونه کدهای پایتون آماده، درباره کار با مفهوم «رشته» (String) در پایتون میگردید، در این بخش از مطلب، اطلاعات بسیار خوبی همراه با نمونه کدهای متنوع برای هر مبحث پیادهسازی کردهایم. رشتهها نوع داده مربوط به کاراکترهای نوشتاری در پایتون هستند. این اشیا پیمایشپذیراند و از کلیدیترین انواع داده برای انتقال اطلاعات محسوب میشوند.

بررسی پالیندروم بودن کلمات
در فرض این سوال رشتهای داده شده است. باید برنامهای بنویسیم که بررسی کند، آیا این رشته داده شده «واروخوانه» (Palindrome) هست یا نیست. واروخوانه یا پالیندروم به رشتههایی میگویند که شکل معکوس شده این کلمه نیز برابر با شکل اصلی آن باشد. لازم نیست که این رشتهها حتما کاراکتر الفبا باشند. اعداد یا حتی رشتههای ترکیبی نیز میتوانند پالیندروم باشند. برای مثال کلمه «radar» پالیندروم است اما کلمه «radix» پالیندروم نیست. اگر به برنامه رشتهای مانند «malayalam» را بدهیم باید برنامه مقدار Yes را برگرداند و اگر مقدار «Faradars» را ارسال کنیم باید No را برگرداند.
روشهای بسیاری برای بررسی پالیندروم بودن رشتهها وجود دارند. ما در این بخش سه روش کلی و ساده را برای اجرای این عملیات بررسی کردهایم که در فهرست زیر نامبرده شدهاند.
- استفاده از رویکرد ساده کدنویسی پایتونی
- استفاده از روش پیمایشی
- استفاده از تابع درونی برای معکوس کردن رشتهها

بررسی روشهای بالا را بهترتیب از اولین روش شروع میکنیم.
استفاده از رویکرد ساده کدنویسی پایتونی
در این روش با کمک تکنیکهای ساده پایتونی اول از همه شکل معکوس رشته را محاسبه میکنیم. بعد از آن با کمک عبارت شرطی if بررسی میکنیم که آیا این دو رشته با هم برابر هستند یا نه.
به کد زیر نگاه کنید. مخصوصا به ترفند بسیار ساده و اختصاصی پایتون برای معکوس کردن لیستها توجه کنید.
خروجی کد بالا برابر با عبارت Yesاست.
استفاده از روش پیمایشی
روش پیمایشی به این شکل است که باید از ابتدا تا وسط رشته را پیمایش کنیم. البته از عملگر تقسیم برای تعیین محدوده پیمایش استفاده میکنیم length/2. سپس در هر محله از پیمایش اولین عنصر رشته را با آخرین عنصر، عنصر دوم رشته را با عنصر یکی مانده به آخر و به همین ترتیب تمام عناصر رشته را تا وسط بررسی میکنیم. اگر بین هیچ دو کاراکتری ناهماهنگی وجود نداشت در نتیجه رشته مورد نظر پالیندروم است.
کد زیر، شکل کدنویسی شدهای از الگوریتم بالا است. به کد زیر توجه کنید.
خروجی کد بالا برابر با عبارت Yes است.
استفاده از تابع درونی برای معکوس کردن رشتهها
در این روش از تابع از پیش تعریف شده join(reversed(string)) برای معکوس کردن رشتهها استفاده میکنیم. قسمت مرکزی این تکه کد تابع درونی reversed() است که برای معکوس کردن نوع دادههای پیمایشپذیر استفاده میشود.
به کد زیر توجه کنید. در کد زیر یکی از روشهای استفاده از تابع درونی reversed() را برای حل این مسئله پیادهسازی کردهایم.
کد خروجی کد بالا برابر با عبارت Yes است.
برنامه پایتون برای بررسی Symmetrical و Palindrome بودن رشته
فرض مسئله این است که رشتهای در اختیار ما قرار گرفته است. در این مسئله باید برنامهای بنویسیم که «متقارن بودن» (Symmetrical) و پالیندروم بودن رشتهها را بررسی کند.
رشتهای متقارن شمرده میشود که در آن هر دو نیمه رشته با هم برابر باشد و به رشتهای پالیندروم میگویند که هر نیمه رشته به صورت مکوس نیمه دیگر باشد یا به عبارت دیگر رشته با معکوس شده خودش برابر باشد. بر فرض مثال اگر رشته ورودی به برنامه برابر با khokho باشد، خروجی برنامه باید مشابه خروجی نمایش داده شده در زیر شود.
Output:
The entered string is symmetrical
The entered string is not palindrome
یا اگر به برنامه رشته «amaama» ورودی را به عنوان ورودی بدهیم. خروجی برنامه باید مشابه خروجی نمایشداده شده زیر باشد.
Output:
The entered string is symmetrical
The entered string is palindromeبرای حل این مسئله روشهای متنوعی ارائه شدهاند. با توجه به مسئله قبل تلاش میکنیم از روشهایی استفاده کنیم که غیرتکراری، نو آورانه و کارآمد باشند.
- استفاده از تکنیکی بسیار ساده مبتنی بر ابزار رایج پایتونی
- استفاده از تکنیک «قطعهسازی» (Slicing)
- استفاده از ماژول یا کتابخانه re

در ادامه این بخش به توضیح کدهای پایتون آماده برای حل مسئله بررسی متقارن بودن و پالیندروم بودن رشتهها میپردازیم. این بررسی را به ترتیب از روش اول شروع میکنیم.
استفاده از تکنیکی بسیار ساده مبتنی بر ابزار رایج پایتونی
این روش، رویکردی بسیار ساده برای حل مسئله ارائه میدهد. برای بررسی پالیندروم بودن با کمک حلقهای تا وسط رشته را پیمایش میکنیم. سازگار بودن اولین عنصر رشته را با آخرین عنصر رشته و دومین عنصر رشته را با عنصر یکی مانده به آخر رشته و به همین ترتیب تا وسط رشته بررسی میکنیم. به محض اینکه کاراکترهایی ناهمگون پیدا کردیم حلقه را با دستور break به پایان میرسانیم و پیغام مربوط به پالیندروم نبودن «The entered string is not palindrome» را بر روی خروجی نمایش میدهیم. در غیر این صورت هم که رشته مورد بررسی پالیندروم است و پیغام «The entered string is palindrome» باید چاپ شود.
برای بررسی متقارن بودن رشته، اگر طول رشته زوج باشد، باید رشته را به دو نیمه مساوی تقسیم و از حلقهای برای پیمایش استفاده کنیم. حلقه در هر مرحله پیمایش، کاراکترهای هر دو نیمه رشته را بررسی میکند. اگر کاراکترها شبیه به هم نباشند، پیمایش حلقه به پایان میرسد و به این نتیجه میرسیم که رشته متقارن نیست. سپس پیغام «The entered string is not Symmetrical» را بر روی خروجی نمایش میدهیم. در غیر این صورت رشته متقارن است و باید پیغام «The entered string is Symmetrical» را در خروجی پایتون نمایش داد. اگر طول رشته فرد باشد بازهم باید رشته را به دو نیم تقسیم کنیم با این تفاوت که کاراکتر وسطی اصلا بررسی نمیشود. سپس مراحل ذکر شده بالا تکرار میشود.
به کد زیر توجه کنید. در برنامه پایین، کدهای پایتون آماده مربوط به الگوریتمهای توصیف شده در بالا پیادهسازی شدهاند.
خروجی کد بالا با دادههای فرضی داده شده، به صورت زیر است.
The entered string is palindrome
The entered string is symmetricalاستفاده از تکنیک قطعه سازی | Slicing
در این روش ابتدا با کد int(len(string) / 2) اندازه وسط رشته را بدست میآوریم. سپس رشته را با استفاده از تکنیک Slicing به دو نیم مساوی تقسیم میکنیم. بعد از آن باید با استفاده از عملگر برابری == متقارن بودن رشته را بررسی کنیم. در نهایت با استفاده از تکنیک Slicing برای معکوس کردن لیستها [::-1] پالیندروم بودن رشته را مشخص میکنیم.
به کد زیر توجه کنید. در کد زیر فرایند ساده و مختصر الگوریتم بالا را پیادهسازی کردهایم.
خروجی کد بالا با دادههای فرضی داده شده، به صورت زیر است.
amaama string is symmetrical
amaama string is palindromeاستفاده از ماژول یا کتابخانه re
در کد پایین اول از همه با استفاده از تکنیک Slicing متقارن بودن رشته را بررسی کردیم. سپس با استفاده از تابع re.match() به وسیله عبارت منظمی که سازگاری کاراکترهای رشته را چک میکند الگوی رشته را میسنجیم. این عبارت منظم محل انتهای رشته را نیز تعیین میکند. در نهایت هم بررسی میکنیم که آیا رشته اصلی با شکل معکوس شده خود همخوانی دارد یا نه. در واقع با این کار پالیندروم بودن رشته را نیز بررسی کردیم.

مراحل پیادهسازی این الگوریتم را در ادامه به صورت کامل توضیح دادهایم.
- رشتهای به نام input_str تعریف میکنیم که متقارن بودن و پالیندروم بودن آن را بررسی کنیم.
- رشته input_str را با تکنیک Slicing معکوس میکنیم و در متغیر reversed_str ذخیره میکنیم.
- بررسی میکنیم که آیا رشتههای reversed_str و input_str با هم برابر هستند یا نه. اگر برابر بودند نتیجه میگیریم رشته ورودی پالیندروم است.
- مرحله بالا را به این صورت هم میتوان بررسی کرد که از حلقهای استفاده کنیم. به کمک حلقه بر روی رشته input_str پیمایش میکنیم و هر کاراکتر از این رشته را با کاراکتر متناظر آن در رشته reversed_str تطبیق میدهیم. اگر کاراکتری با کاراکتری متناظرش سازگار نبود نتیجه میگیریم این رشته پالیندروم نیست.
- برای بررسی متقارن بودن میتوان از توابع بازگشتی نیز استفاده کرد. تابعی تعریف میکنیم که رشته را به عنوان ورودی دریافت کند.
- اگر طول رشته از دو کاراکتر کمتر بود یا کارکتر اول و آخر رشته برابر نبودند، مقدار False را برمیگردانیم.
- در غیر این صورت تابع را به صورت بازگشتی فراخوانی میکنیم و بهعنوان پارامتر ورودی زیر رشتهای از رشتهاصلی را به تابع ارسال میکنیم که کارکتر اول و انتهای رشته اصلی را از آن حذف کرده باشیم.
- از توابع «درونی» (Built-In) و «عبارات منظم» (Regular Expressions) نیز میتوان برای بررسی پالیندروم بودن رشته input_str استفاده کرد.
- تابع re.match() برای بررسی الگوری رشته با عبارت منظمی بکار میرود که تعداد یک یا بیشتری کاراکتر را بررسی میکند. همچنین تابع re.match() به پایان رسیدن رشته را در همینجا تضمین میکند.
به کد نوشته شده زیر توجه کنید.
خروجی کد بالا به همین صورت است.
The entered string is symmetrical
The entered string is palindromeمعکوس کردن چیدمان کلمات در متن داده شده
در این مسئله فرض میکنیم که رشتهی طولانی متشکل از زیر رشتههای مجزایی داده شده است. وظیفه ما این است که برنامهای بنویسیم تا زیر رشتههای رشته اصلی را به صورت معکوس کنار هم قرار دهد.
برای روشنتر شدن مسئله به این مثال توجه کنید. اگر رشته «geeks quiz practice code» به برنامه داده شود، خروجی برنامه باید به شکل رشته «code practice quiz geeks» باشد و اگر به عنوان ورودی برنامه رشته «my name is Mostafa» را دریافت کرده باشیم، برنامه تولید شده باید خروجی به شکل « Mostafa is name my» را برگرداند.
در ادامه این بخش کدهای پایتون آماده مربوط به سه روش متفاوت را بررسی کردهایم.
- روش ساده پایتونی با استفاده از متدهای split() و join()
- معکوس کردن چیدمان کلمات با استفاده از پیمایش معکوس
- معکوس کردن کلمات با استفاده از «پشته» (Stack)
راه حلهای این مسئله را با روشهای بالا به ترتیب از روش اول شروع میکنیم.
روش ساده پایتونی با استفاده از متدهای split و join
در این الگوریتم از تکنیکها و ابزار رایج پایتونی استفاده میکنیم. مراحل پیادهسازی این الگورتیم را در سه مرحله اصلی طراحی کردهایم.
- متد split()مخصوص نوع داده رشته در پایتون طراحی شده است. با استفاده از این متد کلمات درون رشته داده شده را از یکدیگر جدا میکنیم و کلمات از هم جدا شده را در لیستی به نام داخواه words جمعآوری میکنیم.
- لیستی words را با کمک تکه کد r.reversed(words) معکوس میکنیم.
- تمام کلمات درون لیست را با استفاده از متد join() در پایتون به یکدیگر متصل میکنیم.
- در نهایت رشته جدید ساخته شده را در خروجی نمایش میدهیم.
خروجی برنامه بالا با جمله دلخواه داده شده در متن کد به صورت زیر است.
code practice quiz geeksمعکوس کردن چیدمان کلمات با استفاده از پیمایش معکوس
این روش هم تقریبا همان فرایند حل مسئله را طی میکند با این تفاوت که از روشهای متفاوتی برای معکوس کردن کلمات درون رشته اصلی استفاده میکنیم. در این روش همراه با عبارات منظم یا همان رجکسها از پیمایش معکوس هم استفاده میکنیم. مراحل پیادهسازی این الگوریتم شامل بخشهای زیر هستند.
- با استفاده از تابع re.findall() همه کلمات درون رشته را پیدا میکنیم.
- به شکل معکوس بر روی لیست پیمایش میکنیم.
- برای ساخت رشته خروجی نهایی، کلمات درون رشته را با استفاده از تابع join() به یکدیگر متصل میکنیم.
به کدهای پایتون آماده زیر توجه کنید. کدهای پایین شکل پیادهسازی شده الگوریتم بالا هستند.
خروجی کد بالا به صورت زیر است.
code practice quiz geeksمعکوس کردن کلمات با استفاده از پشته | Stack
در این بخش از کدهای پایتون آماده درباره استفاده از پشتهها برای حل مسئله صحبت میکنیم. روش دیگری که برای معکوس کردن چیدمان کلمات درون یک رشته بزرگتر وجود دارد استفاده از پشتهها است.

پشته به ساختار ذخیره دادهای میگویند که عملیات pop و push را پشتیبانی میکند. با استفاده از push کردن کلمات درون پشتهها هم میتوان از پشته برای معکوس کردن چیدمان کلمات استفاده کرد. برای این کار باید کلمات را از ابتدای رشته یکی یکی درون به پشته وارد کنید. سپس به صورت یکی یکی کلمات را از پشته خارج میکنیم تا رشته اصلی را به صورت معکوس بازنویسی کنیم.
به کد زیر دقت کنید. در این کد فرایند توصیف شده بالا را برای حل این مسئله پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا با رشته دلخواه داده شده در برنامه بهشکل زیر است. میتوانید کارکرد این برنامه را با رشتههای مورد نظر خودتان هم امتحان کنید.
code practice quiz geeksروش حذف حروف از درون کلمات در پایتون
رشته به نوع دادهای میگویند که برای نشان دادن متن یا کاراکتر مورد استفاده قرار میگیرد. سوال این است که: باید برنامهای برای حذف کردن کاراکترهای معین شده از درون رشتهها بنویسیم.
در این بخش، کدهای پایتون آماده متفاوتی را برای راهحلهای این مسئله ارائه دادهایم. برای حل این مسئله، سه راهحل متفاوت نمایش دادهایم. برای هر راه حل نیز الگوریتم و کدنویسی مخصوص به آن را پیادهسازی کردهایم.
- استفاده از تابع str.replace()
- استفاده از تابع translate()
- استفاده از توابع بازگشتی برای حذف کاراکترهای مشخص از درون رشته
در ادامه به بررسی هر سه روش پرداختهایم. به ترتیب از روش اول شروع میکنیم.
استفاده از تابع str.replace
از تابع str.replace() برای جایگذاری همه مظاهر کاراکتر مشخص شده استفاده میکنند. به همچنین از این تابع میتوان برای حذف کاراکتر مشخص شده نیز استفاده کرد. فقط کافی است که ایندکس مربوط به کاراکتر مورد نظر را در رشته با استفاده از این تابع با فضای خالی جایگزین کنیم. بنابراین این مسئله به سادگی قابل حل است.
به کد زیر نگاه کنید. کد زیر در نتیجه پیادهسازی الگوریتم فوق ایجاد شده است.
خروجی کد بالا به صورت زیر است.
The string after removal of i'th character( doesn't work) : GksForGks
The string after removal of i'th character(works) : GeekForGeeksاشکال: از تابع replace() برای جایگذاری همه مظاهر کاراکتر تعیین شده استفاده میشود. اگر در آیتمهای درون رشته اصلی کاراکترهای تکراری وجود داشته باشند که با کاراکتر تعیین شده در موقعیت iتطبیق پیدا کنند، تابع replace() میتواند پاسخ غلط برگرداند.
این تابع همه رخدادهای کاراکتر مشخص شده را در رشته اصلی جایگزین میکند. در نتیجه همه کاراکترهایی که در موقعیت iقرار دارند نیز جایگزین میشوند. البته هنوز میتوانیم از این تابع برای جایگزین کردن کاراکترهای داخل رشته اقدام کنیم. فقط باید برای کاراکترهایی از این تابع استفاده کنیم که یکبار در رشته ظاهر شدهاند.
استفاده از تابع translate
این روش، مکانیزمی بسیار قوی برای حذف کاراکترهای مورد نظر درون رشتهها ارائه میدهد. در کد زیر میبینید که بهسادگی با استفاده از تابع translate() عبارت «123» را از رشته «Geeks123For123Geeks» حذف کردهایم.
خروجی کد بالا به صورت زیر است.
GeeksForGeeksاستفاده از توابع بازگشتی برای حذف کاراکترهای مشخص از درون رشته
با استفاده از توابع بازگشتی نیز میتوان کاراکتر مشخصی را از درون هر رشتهی دلخواه حذف کرد. برای این کار میتوانیم تابعی تعریف کنیم که رشتهای را به همراه ایندکس مورد نظر به عنوان پارامتر دریافت کند و کاراکتر درون ایندکس مشخص شده را از داخل رشته حذف کند. تابع بررسی میکند که آیا مقدار ایندکس برابر با 0 هست یا نه. اگر برابر بود رشته را بعد از حذف اولین کاراکتر برمیگرداند. اما اگر مقدار ایندکس برابر صِفر نبود تابع، اولین کاراکتر رشته را همراه با نتیجه فراخوانی خودش بر روی رشته برمیگرداند. تابع هر بار در فراخوانی خودش مقدار ایندکس را یک واحد کم میکند و به همین صورت تابع در فراخوانی جدیدش بررسی رشته را از کاراکتر بعدی شروع میکند.

به کدهای پایتون آماده زیر دقت کنید. کدهای زیر از پیادهسازی الگوریتم بالا بدست آمدهاند.
خروجی کد بالا به صورت زیر است.
The string after removal of ith character: GeksForGeeksبررسی موجود بودن زیررشته خاصی در رشته داده شده
در این بخش کدهای پایتون آماده را برای مسئلهای بررسی خواهیم کرد که در آن خواسته شده وجود زیر رشتهای را در رشتهی دیگری بررسی کنیم. فرض کنید که رشته «geeks for geeks» به همراه زیر رشته «geek» داده شدهاند. برنامه باید خروجی Yes را برگرداند.
در واقع در این مسئله بررسی میکنیم که آیا رشته اصلی شامل زیر رشته داده شده میشود یا نه. بررسی زیر رشتهها یکی از رایجترین کارها در برنامههای تخصصی پایتون است. پایتون از متدهای زیادی برای این کار استفاده میکند. برای مثال متدهای درونی مانند find() و index() و count()و غیره برای بررسی رشتهها استفاده میشوند. کارآمدترین و سریعترین روش استفاده از عملگر in است. عملگر in به عنوان عملگر مقایسهای استفاده میشود. برای حل این مسئله، کدهای پایتون آماده مربوط به چهار روش متفاوت زیر را بررسی خواهیم کرد.
- استفاده از عبارت شرطی if-else
- استفاده از عملگر in
- بررسی رشته با استفاده از متد split()
- بررسی رشته با استفاده از متد find()
در ادامه مطلب، روشهای بالا را برای حل مسئله به ترتیب از روش اول، یکی به یک بررسی خواهیم کرد.
استفاده از عبارت شرطی If-Else
در پایتون میتوان با استفاده از عبارت شرطی if-else وجود زیر رشتهها را در رشتههای بزرگتر بررسی کرد. عبارت if-else به برنامهنویسان کمک میکند که به صورت مشروط بلاکهای متفاوتی از کدها را اجرا کنند. بسته به اینکه کدام شرط درست یا غلط میشود، کد میتواند رفتار متفاوتی را بُروز دهد.
به کد زیر توجه کنید. در کد زیر یکی از موارد استفاده از عبارت شرطی if-else را برای بررسی رشتهها پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر خواهد بود.
Yes! it is present in the stringاستفاده از عملگر in
در پایتون با استفاده از عملگر in به سادگی میتوانید وجود هر عنصری را در اشیا پیمایشپذیر بررسی کنید. به همین ترتیب میتوان با استفاده از عملگر in وجود داشتن مقدار خاصی را –در اینجا منظور زیر رشته است- در صف داده بررسی کرد.
می توانید در کدهای پایتون آماده زیر روش استفاده از عملگر in را ببینید.
خروجی حاصل از کد بالا با دادههای فرضی داده شده در متن کد به صورت زیر است.
Substring found!
Substring not found!بررسی رشته با استفاده از متد split
در این بخش از کدهای پایتون آماده برای بررسی وجود زیررشتهها در رشته بزرگتر از متد split() استفاده خواهیم کرد. در ابتدا رشته داده شده را به کلمات تشکیل دهنده آن تجزیه میکنیم و این کلمات را در متغیر s ذخیره میکنیم. با این کار متغیری که به نام s تشکیل دادیم به لیست تبدیل میشود. اختصاص این کد string.split() متغیر را به لیست تبدیل میکند و نیازی نیست که از ابتدا لیست بودن را برای متغیر تعیین کنیم. در نهایت با استفاده از عبارت شرطی if-else بررسی میکنیم که آیا زیر رشته داده شده در لیست کلمات رشته اصلی، وجود دارد یا نه.

به کد زیر توجه کنید. کد زیر فرایند توضیح داده شده در بالا را پیادهسازی کرده است.
خروجی کد بالا عبارت Yes است.
بررسی رشته با استفاده از متد find
با کمک ابزارهای پیمایشگر موجود میتوانیم بر روی هر نوع ساختار دادهی پیمایشپذیری پیمایش کنیم. به همین ترتیب میتوانیم داخل متنهای بزرگ نیز به دنبال هر کلمهای بگردیم. اما پایتون برای برنامهنویسان، تابعی «درونی» (Built-In) مخصوص جستوجو درون لیستها فراهم کرده است. نام تابع مخصوص جستوجو در ساختارهای ذخیره داده پیمایشپذیر find() است. با کمک این تابع هم میتوان بررسی کرد که آیا زیر رشتهای در رشته مرجع وجود دارد یا نه. استفاده از این تابع کل فرایند جستوجو را در یک خط کد ممکن میکند. در صورتی که زیر رشته مورد جستوجو پیدا نشود تابع find() مقدار -1 برمیگرداند. در غیر این صورت اولین رخداد گزینه مورد جستوجو را برمیگرداند. پس با استفاده از تابع find() هم میتوان این مسئله را حل کرد.
به کد زیر توجه کنید. کد زیر، مثال سادهای از استفاده تابع find() را پیادهسازی کرده است.
خروجی کد بالا هم عبارت Yes است.
شمارش فراوانی کلمات در متن
بعضی وقتها که در حال کار با رشتهها در پایتون هستیم، لازم میشود که فراوانی همه کلمات درون رشته یا متن را بدست بیاوریم. قبلا درباره روشهای پیدا کردن کلمات درون رشتهها صحبت کردهایم. در این بخش میخواهیم درباره روشهایی صحبت کنیم که به صورت سریعتر و با کدنویسی کمتری این مسئله را حل میکنند. در این بخش از مطلب، کدهای پایتون آماده مربوط به چند رویکرد مختلف را برای حل این مسئله بررسی خواهیم کرد. این روشها در زمینههای مختلفی از توسعه برنامههای اینترنتی گرفته تا «برنامهنویسی رقابتی» (Competitive Programming) کاربرد دارند.
فرض کنیم که رشته'Gfg is best' را به برنامه میدهیم. برنامه باید خروجی بهشکل زیر تولید کند.
Output : {'Gfg': 1, 'is': 1, 'best': 1} برای بررسی فرایند حل این مسئله، کدهای پایتون آماده چهار روش مختلف را بررسی خواهیم کرد. این روشها را به ترتیب بررسی در پایین فهرست کردهایم.
- استفاده از تکنیک Dictionary Comprehension به همراه توابعcount() وsplit()
- استفاده از توابع Counter() و split()
- استفاده از توابع operator.countOf() و split() به همراه تکنیک Comprehension برای دیکشنری
- استفاده از تابع set() به همراه تکنیک List Comprehension
تکنیک Dictionary Comprehension به همراه توابع count و split
با ترکیب توابع بالا و تکنیک Dictionary Comprehension میتوان این مسئله را حل کرد. برای حل مسئله در ابتدا باید همه کلمات درون رشته را با کمک تابع split() از یکدیگر تجزیه کنیم. سپس با استفاده از تابع count() تعداد ظهور هر کلمه را در رشته مرجع -لیستی که از تجزیه کلمات تشکیل شده است- میشماریم. در نهایت با بهکار گرفتن تکنیک Comprehension برای دیکشنریها همه این کلمات را به صورت مجزا همراه با تعداد تکرارشان در یک دیکشنری جمع میکنیم و به کاربر در خروجی نمایش میدهیم.
به کد زیر توجه کنید. در کد زیر الگوریتم توصیف شده بالا را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The original string is : Gfg is best . Geeks are good and Geeks like Gfg The words frequency : {‘Gfg’: 2, ‘is’: 1, ‘best’: 1, ‘.’: 1, ‘Geeks’: 2, ‘are’: 1, ‘good’: 1, ‘and’: 1, ‘like’: 1}استفاده از توابع Counter و split
از ترکیب توابع Counter() و split() نیز میتوان برای حل این مسئله استفاده کرد. در این روش نیز در ابتدا باید با استفاده از تابع split() رشته را به کلمات تشکیل دهندهاش تجزیه کنیم. سپس برای شماردن کلمات تشکیل دهنده رشته از تابع Counter() استفاده میکنیم. نکته این روش، اینجا است که تابع Counter() را باید از داخل کتابخانه collections در پایتون Import کرد.

توجه کنید خروجی تابع Counter() شی نوع Counter است که شامل یک دیکشنری میشود. برای اینکه خروجی این تابع بهطور کامل به دیکشنری تبدیل شود باید از تابع dict() استفاده کنیم. به کد زیر نگاه کنید. در کد زیر روش ساده استفاده از از ترکیب توابع Counter() و split() را پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The original string is : Gfg is best . Geeks are good and Geeks like Gfg The words frequency : {‘Gfg’: 2, ‘is’: 1, ‘best’: 1, ‘.’: 1, ‘Geeks’: 2, ‘are’: 1, ‘good’: 1, ‘and’: 1, ‘like’: 1}توابع operator.countOf و split به همراه تکنیک Dictionary Comprehension
برای پیادهسازی این روش هم در ابتدا باید کتابخانه operator را به محیط کدنویسی پایتون Import کنیم. تابع countOf() درون این کتابخانه تعریف شده است. در ابتدا مانند روشهای قبلی با استفاده از تابع split() رشته اصلی را به کلمات تشکیل دهندهاش تجزیه میکنیم. سپس با استفاده از تابع countOf() تعداد ظهور تمام کلمات را در رشته میشماریم. نکته اینجاست که این تابع دو ورودی دریافت میکند. رشتهای که باید درون آن بگردد و رشتهای که باید به دنبال آن بگردد. برای همین با استفاده از تکنیک Dictionary Comprehension، از نتایج تابع countOf() برای ساخت دیکشنری استفاده میکنیم. تمام کلمات درون رشته به عنوان کلید و تعداد تکرار هر کلمه در رشته مقدارهای دیکشنری را تشکیل میدهند.
به کد زیر توجه کنید. در کد زیر تکنیک حل مسئله توضیح داده شده در بالا را پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The original string is : Gfg is best . Geeks are good and Geeks like Gfg
The words frequency : {'Gfg': 2, 'is': 1, 'best': 1, '.': 1, 'Geeks': 2, 'are': 1, 'good': 1, 'and': 1, 'like': 1}استفاده از تابع set به همراه تکنیک List Comprehension
در این روش برای اینکه همزمان با شمارش کلمات، کلیدهای تکراری را حذف کنیم از تابعset() استفاده میکنیم. در ادامه، الگوریتم حل مسئله را به صورت قدم به قدم شرح دادهایم.
- همانند الگوریتمهای پیشین در ابتدای کار باید رشته اصلی را به لیستی از کلمات تشکیل دهنده رشته تبدیل کنیم. این کار را با بهرهگیری از تابع split() انجام میدهیم.
- از تابع set()استفاده میکنیم که مجموعهای از کلمات یکتای موجود در لیست مرحله قبل را بدست بیاوریم.
- سپس از تکنیک List Comprehension استفاده میکنیم تا تعداد تکرار هر کلمه را در لیست اصلی محاسبه کنیم.
- نتایج بدست آمده را با استفاده از تکنیک Dictionary Comprehension در یک دیکشنری ذخیره میکنیم.
- در نهایت دیکشنری نتیجه گرفته شده را باید برای نمایش به کاربر در خروجی چاپ کنیم.
به کدهای پایتون آماده شده زیر توجه کنید. در این کدها مراحل الگوریتم توضیح داده شده بالا را پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The original string is : Gfg is best . Geeks are good and Geeks like Gfg
The words frequency : {'are': 1, 'good': 1, 'and': 1, 'like': 1, 'best': 1, 'Gfg': 2, 'is': 1, 'Geeks': 2, '.': 1}تبدیل عبارت های Snake case به Pascal case
گاهی ممکن است هنگام کار با نوع داده رشته در پایتون با مشکلی در رابطه با تغییر وضعیت رشتهها روبهرو شوید. فرض کنیم که رشتهای به شکل «teamـblogـFaradars» داریم. باید برنامهای بنویسیم که رشته را به شکل «FaradarsBlogTeam» در بیاورد. یا مثلا برنامه نوشته شده باید بتواند رشتهای به شکل «left_index» را تحویل بگیرد و در خروجی رشته «LeftIndex» را برگرداند.

این یکی از مسائل بسیار رایج در برنامهنویسی است. این مسئله در حوزههای مختلفی مانند توسعه برنامههای اینترنتی کاربرد دارد. در این بخش به بررسی کدهای پایتون آماده چند عدد از راه حلهای متنوعی میپردازیم که برای این مسئله ارائه شدهاند.
- روش اول: استفاده از توابع title() و replace()
- روش دوم: استفاده از تابع capwords()
- روش سوم: استفاده از تکنیک capitalize برای تغییر اندازه حروف
- روش چهارم: استفاده از متد split()
- روش پنجم: استفاده از کدهای ساده پایتونی بدون ابزار خاص
- روش ششم: استفاده از عبارتهای منظم

بررسی کدهای پایتون آماده روشهای نامبرده شده بالا را از روش اول یعنی استفاده از توابع title() و replace() شروع میکنیم.
استفاده از توابع title و replace
این مسئله را میتوان به کمک بهکار گرفتن ترکیبی از توابع title() و replace() حل کرد. در این روش برای شروع کار باید «خطوط زیر» (Underscores) را به رشته خالی تبدیل کنیم و سپس حرف اول هر کلمه را به حرف بزرگ تبدیل کنیم.
در کدهای زیر روش توضیح داده شده در بالا را برای حل مسئله پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
The original string is : faradarsblog_is_best
The String after changing case : FaradarsblogIsBestاستفاده از تابع capwords
در این روش با استفاده از تابع capwords() به حل مسئله پرداختهایم. این تابع درون کتابخانه string قرار دارد. کتابخانه string بهطور اختصاصی برای کار با رشتهها تعریف شده است.
به کد زیر نگاه کنید. در کد زیر برای شروع «خطوط زیر» (Underscores) را به فضای خالی تبدیل کریم و بعد از آن این فضاهای خالی را نیز حذف کردیم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The original string is : faradarsblog_is_best
The String after changing case : FaradarsblogIsBestاستفاده از تکنیک capitalize برای تغییر اندازه حروف
در این تکنیک برای حل مسئله تابعی تعریف کردهایم. در این تابع اول از همه رشته ورودی را با استفاده از تکه کد split("_") از محل علامتهای Underscores به رشتههای کوچکتر تجزیه میکنیم. در نتیجه کلمات رشته را پیدا میکنیم. حرف اول هر کلمه را بزرگ میکنیم. بعد از آن کلمات را بهشکل عبارتهای PascalCase به یکدیگر میچسبانیم.
فرایند این الگوریتم را در سه مرحله به صورت کلی میتوان توصیف کرد.
- با استفاده از تابع split("_") رشته داده شده از محل علامتهای Underscores به صورت کلمه به کلمه جدا میکنیم و درون یک لیست وارد میکنیم.
- با استفاده از متد capitalize() حرف اول هر کلمه را بزرگ میکنیم و بعد از آن به کمک متد join() کلمات را به یکدیگر میچسبانیم.
- رشته نهایی را که به شکل عبارت PascalCase درآمده برای نمایش در خروجی به تابع print() ارسال میکنیم.
کدهای پایتون آماده مربوط به الگوریتم بالا در پایین قرار داده شدهاند.
خروجی کد بالا به صورت زیر است.
FaradarsblogIsBestاستفاده از متد split
در این روش حل مسئله، با استفاده از تابع split() و علامت خط زیر ـ کلمات تشکیل دهنده رشته را از یکدیگر جدا میکنیم. برای این کار باید از کد string.split('_') استفاده کنیم. با استفاده از متد title() حروف اول همه کلمات را بزرگ میکنیم و در نهایت کلمات را با استفاده از متد join() به یکدیگر میچسبانیم. مراحل اجرای این الگوریتم را به صورت قدم به قدم در پایین توضیح دادهایم.
- با ارسال کارکتر Underscore ـ به تابع split() و اعمال تابع split() بر روی رشته، کلمات رشته را از یکدیگر جدا میکنیم.
- با استفاده از متد title() حروف اول همه کلمات جدا شده را بزرگ میکنیم.
- تمام کلمات جدا شده را دوباره با استفاده از متد join() به یکدیگر متصل میکنیم.
- رشته نهایی را برای نمایش در خروجی برمیگردانیم.
به کد زیر نگاه کنید. تمام مراحل بالا را در کد زیر پیادهسازی کردهایم.
خروجی کد بالا به صورت زیر است.
FaradarsblogIsBestاستفاده از کدهای ساده پایتونی بدون ابزار خاص
الگوریتمی که برای نمایش در این بخش ارائه دادهایم از توابع اختصاصی و حرفهای پایتون استفاده نمیکند. البته که در این روش هم از تابعهای پایتون استفاده کردهایم. همچنین تابع سفارشی خودمان را نیز برای استفاده در راه حل این مسئله پیادهسازی کردهایم. به مراحل زیر توجه کنید.
- در تابعی که به صورت سفارشی پیادهسازی میکنیم اول از همه باید رشته خالی به نام result ایجاد کنیم.
- متغیری را به عنوان پرچم با نوع داده بولین به نام دلخواه capitalize_next_word با مقدار اولیه True تعریف میکنیم.
- با کمک حلقه for ، بر روی هر کاراکتر در رشته ورودی پیمایش میکنیم.
- اگر کاراکتر از نوع Underscore بود مقدار پرچم capitalize_next_word را بر روی True تنظیم میکنیم.
- اگر کاراکتر مورد پیمایش از نوع Underscore نبود و مقدار پرچم capitalize_next_wordبرابر با True بود، نسخه بزرگ شده این کاراکتر را وارد متغیر result میکنیم. سپس مقدار پرچم capitalize_next_word را هم برابر با False قرار میدهیم.
- اگر کاراکتر مورد پیمایش از نوع Underscore نبود و مقدار پرچم capitalize_next_wordبرابر با False بود، کاراکتر را به همین شکلی که هست وارد متغیر result میکنیم.
- در نهایت باید رشته result را در خروجی برگردانیم.

به کدهای پایتون آماده زیر توجه کنید. در کدهای پایین تمام مراحل توصیف شده بالا پیادهسازی شدهاند.
خروجی کدهای بالا به صورت زیر است.
FaradarsBlogTeam
LeftIndexاستفاده از عبارات منظم | RegEx
برای حل مسئله به این روش در ابتدا باید ماژول مربوط به RegEx را Import کنیم. نام این کتابخانه re است. بعد از آن تابعی تعریف میکنیم که به عنوان ورودی، رشتهای از نوع Snake_Case را دریافت کند. از متد sub() در کتابخانه مربوط به RegEx استفاده میکنیم تا در رشته ورودی، کاراکتر Underscore را با رشته خالی به طول یک کاراکتر، جابهجا کند. سپس حرف اول هر کلمه را به حرف بزرگ تبدیل میکنیم و در نهایت بعد از چسباندن کلمات به یکدیگر، نتیجه نهایی را برمیگردانیم.
به کد زیر توجه کنید تا روش پیادهسازی این الگوریتم را ببینید.
خروجی کد بالا به صورت زیر است.
FaradarsblogIsBestروش های پیدا کردن طول رشته در پایتون
رشتهها در پایتون صف «تغییرناپذیری» (Immutable) از نقاط داده منحصر به فرد هستند. در این بخش از کدهای پایتون آماده، فرض میکنیم رشتهای داده شده است. بهمنظور حل مسئله، باید برنامهای برای پیدا کردن طول رشته بنویسیم.
بر فرض مثال، اگر رشته 'hello world !' داده شده باشد، برنامه طراحی شده باید خروجی 13 را برگرداند و اگر رشتهای بهشکل 'abc' داده شده باشد برنامه باید خروجی را برابر با عدد 3 برگرداند. توجه کنید که در رشتهها، فضاهای خالی نیز جزو کاراکترها محاسبه میشوند.
برای حل این مسئله در پایتون با کمک ابزارهای مختلف، روشهای گوناگونی میتوان طراحی کرد. در این بخش سه روش متنوع را مورد بررسی قرار دادهایم.
- استفاده از تابع «درونی» (Built-In) len()
- استفاده از حلقه for به همراه عملگر in
- استفاده از حلقه while به همراه تکنیک Slicing
با بررسی روش اول به ادامه مطلب میپردازیم.
استفاده از تابع درونی len
تابع درونی len() بهطور اختصاصی، برای شمارش طول ساختارهای داده پیمایشپذیر طراحی و پیادهسازی شده است. این تابع تعداد آیتمهای درون هر ظرف ساختار دادهای را برمیگرداند. به کد زیر نگاه کنید تا مثالی واضح و مختصر از روش استفاده از این تابع را ببنید.
کد بالا در خروجی عدد 5 را نمایش میدهد.
استفاده از حلقه for به همراه عملگر in
رشتهها را به صورت مستقیم میتوان با کمک حلقه for مورد پیمایش قرار داد. ذخیره تعداد پیمایشی که بر روی رشتهای انجام میشود در نهایت طول آن رشته را مشخص میکند. برای مثال، به کد زیر توجه کنید. در کد زیر، نمایشی از پیمایش بر روی رشته با کمک حلقه for را مشاهده میکنید. شمارندهای تعداد پیمایش حلقه را میشمارد. بعد از خروج از حلقه، مقداری که توسط شمارنده شمرده شده برابر با طول رشته است.
کد بالا در خروجی عدد 5 را نمایش میدهد.
استفاده از حلقه while به همراه تکنیک Slicing
برای استفاده از تکنیک Slicing، در ابتدا باید با استفاده از حلقه while رشته را مورد پیمایش قرار دهیم. در هر مرحله، تکهای از رشته جدا میکنیم که اندازهای برابر با یک واحد کمتر از رشته مرحله قبل داشته باشد. در نهایت طول رشته برابر با تهی یا صِفر خواهد شد. در این مرحله، حلقه پیمایش را متوقف میکند. برای بدست آوردن طول رشته با کمک شمارندهای باید تعداد پیمایشهای حلقه را بشماریم. مقدار نهایی شمارنده برابر با طول رشته خواهد بود.
به کد زیر توجه کنید. در کد پایین روش استفاده از تکنیک Slicing را در حلقه while پیادهسازی کردهایم.
کد بالا در خروجی عدد 5را نمایش میدهد.
چاپ کلمات با طول زوج از درون رشته بزرگتر
این مثال، برای تمرین کار با رشتهها در پایتون بسیار عالی است. فرض کنید رشتهای داده شده و باید برنامهای بنویسیم که همه کلمات درون رشته را چاپ کند، با این شرط که مقدار طولشان برابر با عددی زوج باشد.
به عنوان مثال، فرض کنیم رشتهای به شکل زیر به برنامه ارسال شده است.
Input: s = "This is a python language"خروجی برنامه باید بهشکل زیر شود.
Output: This is python languageولی اگر رشتهای به شکل "I am a boy" به برنامه ارسال کنیم. برنامه نوشته شده باید خروجی برابر با am را به کاربر برگرداند.

برای حل این مسئله، میتوان روشهای متفاوتی را در پایتون پیادهسازی کرد. در این بخش، کدهای پایتون آماده مربوط به پنج روش مختلف را نمایش دادهایم.
- روش اول: استفاده از حلقه for به همراه عبارت شرطی if
- روش دوم: استفاده از تکنیک تعریف تابع lambda
- روش سوم: استفاده از تابع enumerate() درون تکنیک List Comprehension
- روش چهرم: پیمایش تک به تک کاراکترها برای تجزیه و تحلیل
- روش پنجم: استفاده از تابع itertools.compress()
بررسی روشهای بالا را به ترتیب از روش اول شروع کردهایم.
استفاده از حلقه for به همراه عبارت شرطی if
این روش یکی از سادهترین سینتکسها را دارد. در روش پایین، بدون تعریف تابعی جدید، به صورت شفاف برنامهای برای حل مسئله نوشته شده است. در ابتدا با استفاده از تابع split() رشته را به کلمات تشکیل دهنده آن تجزیه میکنیم. سپس برنامه با کمک حلقه for بر روی رشته اصلی پیمایش میکند. این برنامه با عبارت شرطی ifطول همه کلمات را با استفاده از تابع len() یک به یک میسنجد. اگر طول کلمهای زوج باشد، برنامه نوشته شده کلمه را در خروجی چاپ میکند.
به کد زیر توجه کنید. در کد زیر فرایند توضیح داده شده بالا را پیادهسازی کردهایم.
خروجی کد بالا با توجه به عبارت دلخواه داده شده برای آزمایش برنامه، به صورت زیر خواهد شد.
This
is
python
languageاستفاده از تکنیک تعریف تابع lambda
در این سری از کدهای پایتون آماده، برای حل مسئله دو حرکت اصلی انجام میدهیم. حرکت اول تجزیه رشته مرجع داده شده با کمک تکه کد n.split(" ") به کلمات تشکیل دهنده رشته است و در حرکت دوم با کمک تابع لامبدایی که به تابع filter() ارسال شده، کلمات با طول زوج را از درون آرگومان s جدا میکنیم. آرگومان s، متغیر حاوی کلمات تشکلیل دهنده رشته مرجع است.
به کد زیر توجه کنید.
خروجی کد بالا با توجه به عبارت دلخواه داده شده به صورت زیر است.
['geek']
استفاده از تابع enumerate درون تکنیک List Comprehension
این سری از کدهای پایتون آماده نیز مانند روشهای بالا، رشته مرجع داده شده را با کمک تکه کد n.split(" ") به کلمات تشکیل دهنده آن، تجزیه میکند. تفاوت اصلی در حرکت بعدی است. در این بخش با استفاده از تابع enumerate() به دادههای درون متغیر s دسترسی پیدا میکنیم.
به کدی که در ادامه آمده توجه کنید. در این کد از تکنیک List Comprehension نیز استفاده شده است.
خروجی کد بالا با توجه به عبارت دلخواه داده شده به صورت زیر است.
['geek']
پیمایش تک به تک کاراکترها برای تجزیه و تحلیل
حل مسئله با روش «پیمایش تک به تک کاراکترها برای تجزیه و تحلیل» سه مرحله کلی را در بر میگیرد. در نهایت هم باید همه کلماتی که طول رشته زوج دارند را چاپ کنیم. در فهرست زیر، این سه مرحله را توضیح دادهایم.
- در اولین مرحله متغیر رشتهای با مقدار خالی، تعریف میکنیم. از این متغیر برای ذخیره کلمهای استفاده میکنیم که اکنون در حال تجزیه و تحلیل است. این متغیر را با نام دلخواه word نامگذاری کردهایم.
- برای هر کاراکتر درون رشته ورودی به صورت مجزا پیمایش میکنیم.
- اگر کاراکتر «فضای خالی» (Space) بود، به این معنا است که کلمهای که درحال بررسی آن بودیم به پایان رسیده است. پس باید بررسی کنیم که آیا طول کلمهی بررسی شده زوج و بزرگتر از صِفر هست یا نه. اگر جواب مثبت بود باید کلمه بررسی شده را برای نمایش در خروجی چاپ کرد.
- اگر کاراکتر مورد بررسی «فضای خالی» (Space) نبود، به این معنا است که کلمهی مورد بررسی، هنوز در حال شکلگیری است. پس باید کاراکتر را به محتوی فعلی متغیر word اضافه کرد.
- بعد از اینکه پیمایش حلقه به پایان رسید باید بررسی کنیم که طول آخرین کلمه، زوج و بزرگتر از صِفر است یا نه. درصورتی که طول این کلمه هم بزرگتر از صِفر باشد باید آخرین کلمه را نیز چاپ کنیم.
به کد زیر دقت کنید. در کد زیر فرایند توصیف شده بالا را پیادهسازی کردهایم.
خروجی کد بالا با توجه به عبارت دلخواه داده شده به صورت زیر است.
This is python language
استفاده از تابع itertools.compress
برای این روش حل مسئله از تابع compress() استفاده کردهایم. این تابع را باید از درون کتابخانه itertools فراخوانی کنیم. در ادامه، کدهای پایتون آماده الگوریتم حل این مسئله را در ۶ مرحله کلی توضیح دادهایم.
- متغیر رشتهای با نام دلخواه n و محتوای دلخواه را برای ارزیابی برنامه تعریف کردهایم. توجه کنید که برای این کار بهتر است متغیر nشامل جملهای شود که حاوی کلمات با طول متنوع است.
- با استفاده از متد split() جمله اصلی تعریف شده در بالا را به لیستی از کلمات تشکیل دهنده آن تجزیه میکنیم. این لیست را در متغیری به نام دلخواه s ذخیره میکنیم.
- از تکنیک Comprehension برای تعریف لیستها استفاده میکنیم تا لیستی با محتوای «بولین» (Boolean) بر حسب زوج یا فرد بودن طول کلمات درون لیست sتشکیل دهیم. لیست جدید را با نام دلخواه even_len_bool نامگذاری میکنیم. اگر طول کلمه متناظر با ایندکس در لیست sزوج بود، درون لیست even_len_bool هم مقدار True قرار میگیرد. در غیر این صورت مقدار False درون ایندکس متناظر با هر کلمه در لیست sقرار خواهد گرفت.
- در این مرحله از تابع compress() که از ماژول itertools Import شده استفاده میکنیم. از این تابع برای فیلتر کردن کلمات درون لیست sبه کمک لیست بولینی که در مرحله ۳ ساخته شده -به نام even_len_bool - استفاده میکنیم.
- کلمات فیلتر شده را درون لیستی به نام even_len_words ذخیره میکنیم.
- در نهایت هم لیست کلمات با طول زوج even_len_words را برای نمایش در خروجی چاپ میکنیم.

به کد زیر نگاه کنید. در کد زیر فرایند توصیف شده بالا را پیادهسازی کردهایم.
خروجی کد بالا با توجه به عبارت دلخواه داده شده به صورت زیر است.
['This', 'is', 'python', 'language']برنامه ای برای تشخصی رشته های شامل تمام حروف صدادار
در این مسئله فرض میکنیم که رشتهای داده شده است. باید برنامهای بنویسیم که وجود همه حروف «صدادار» (Vowels) را در رشته مورد نظر بررسی کند. در بررسی حروف صدادار، شکل بزرگ یا کوچک حروف تاثیری نخواهد داشت. حروف صدادار انگلیسی شامل موارد «A» ,«E» ,«I» ,«O» و «U» یا «a» ,«e» ,«i» ،«o» و «u» میشوند.
به عنوان مثال اگر رشته faradarsblogteam را به عنوان ورودی به برنامه بدهیم، برنامه باید خروجی به شکل زیر برگرداند.
Output : Not Accepted
All vowels except 'i','u' are presentو اگر رشتهای به شکل ABeeIghiObhkUul را به عنوان داده ورودی به برنامه بدهیم، برنامه نوشته شده باید خروجی بهشکل زیر را برگرداند.
Output : Accepted
All vowels are presentبرای حل این مسئله کدهای پایتون آماده مربوط به چهار روش مختلف زیر را بررسی خواهیم کرد.
- بررسی وجود حروف صدادار با استفاده از مجموعهها
- بررسی وجود حروف صدادار با استفاده از توابع درونی
- بررسی وجود حروف صدادار با استفاده از عبارات منظم
- بررسی وجود حروف صدادار با استفاده از ساختارهای داده
بررسی همه روشهای بالا را به ترتیب از روش اول شروع کردهایم.
بررسی وجود حروف صدادار با استفاده از مجموعه ها
در مرحله اول با استفاده از تابع set() مجموعهای از حروف صدادار تشکیل میدهیم. سپس همه کاراکترهای رشته را بررسی میکنیم که آیا «صدادار» (Vowel) هستند یا نه. اگر صدادار بودند باید به مجموعه s اضافه شوند. بعد از اینکه حلقه به پایان رسید، باید طول مجموعه s را اندازه بگیریم. اگر طول مجموعه s برابر با طول مجموعه حروف صدادار بود، در نتیجه رشته تایید خواهد شد. در غیر این صورت، باید پیغام عدم تایید بر روی خروجی چاپ شود.
به کدی که در ادامه آمده توجه کنید.
با توجه به رشته دلخواه داده شده در کدهای پایتون آماده بالا، خروجی برنامه برابر با Accepted خواهد بود. میتوانید برای بررسی و آزمایش کارکرد برنامه رشته ورودی را تغییر دهید.
بررسی وجود حروف صدادار با استفاده از توابع درونی
الگوریتمی که در این روش برای حل مسئله طراحی کردهایم را میتوان در چند مرحله زیر توضیح داد. البته توجه کنید که در این روش هم تابعی اختصاصی برای بررسی همه رشتههای ممکن طراحی میکنیم. مراحل زیر وظایف اجرایی این تابع را توضیح میدهند.
- در ابتدا تمام فضاهای خالی درون رشته را حذف میکنیم تا تمام کاراکترها به یکدیگر بچسبند.
- سپس با استفاده از تابع lower() ، همه کاراکترهای الفبای موجود در رشته را به حروف کوچک تبدیل میکنیم.
- در قسمت بعدی لیستی از تعداد تکرار همه حروف صدا دار تشکیل میدهیم.
- در نهایت هم با کمک عبارت شرطی if بررسی میکنیم که آیا مقدار 0 درون لیست تشکیل شده مرحله سه وجود دارد یا نه. اگر مقدار 0 وجود داشت، یعنی حداقل یک حرف صدادار وجود دارد که در رشته اصلی نیامده. در غیر این صورت رشته اصلی شامل تمام حروف صدادار است.
به کد زیر توجه کنید. در کدهای پایتون آماده زیر تمام مراحل توضیح داده شده بالا پیادهسازی شدهاند.
با توجه به رشته دلخواه داده شده در کدهای پایتون آماده بالا، خروجی برنامه برابر با accepted خواهد بود. میتوانید با تغییر رشته ورودی به بررسی و آزمایش کارکرد برنامه بپردازید.

کد بالا را به صورت بهینهتری نیز میتوان نوشت. به کد زیر توجه کنید.
با توجه به رشته دلخواه داده شده در کدهای پایتون آماده بالا خروجی برنامه برابر با not accepted خواهد بود.
بررسی وجود حروف صدادار با استفاده از عبارات منظم
برای شرط اینکه کاراکتر جزو حروف صدادار «a» و «e» و «i» و «o» و «u» نباشد با استفاده از تابع compile() عبارت منظمی تعریف میکنیم. سپس از تابع re.findall() برای فراخوانی رشتههایی استفاده میکنیم که با عبارت منظم تعریف شده همخوانی دارند. در نهایت هم با توجه به نتیجهای که برنامه بدست آورده خروجی مرتبط را برمیگردانیم.
به کد زیر توجه کنید. در کد زیر نحوه پیادهسازی الگوریتم بالا قابل مشاهده است.
با توجه به رشته دلخواه داده شده در کدهای پایتون آماده بالا، خروجی برنامه برابر با accepted است.
بررسی وجود حروف صدادار با استفاده از ساختارهای داده
در این روش برای حل مسئله، تابع سفارشی خود را طراحی کردهایم. روند کار الگوریتم طراحی شده برای حل مسئله را میتوان در چند مرحله زیر توصیف کرد.
- در ابتدا لیستی از همه حروف صدادار موجود، در رشته دریاف شده را با استفاده از تکنیک List Comprehension ایجاد میکنیم.
- سپس دیکشنری ایجاد میکنیم که حروف صدادار، کلیدهای آن و تعداد تکرار این حروف در لیست مرحله قبل مقادیر این کلیدها شدهاند.
- در نهایت با استفاده از حلقه for و عبارت شرطی ifبررسی میکنیم که آیا در دیکشنری ساخته شده کلیدی وجود دارد که مقدار آن برابر صفر باشد یا نه.
- با توجه به نتیجه بررسی مرحله بالا خروجی مورد نظر را به کاربر نمایش میدهیم.
به کد زیر توجه کنید. برنامه زیر شکل کدنویسی شده الگوریتم بالا است.
خروجی حاصل از اجرای کد بالا بهصورت زیر است.
All vowels except a,i,u are not present
All vowels are presentشماردن تعداد کاراکترهای مشترک میان دو رشته متمایز
تصور کنید یک جفت رشته غیر خالی داده شده است. در سوال، خواسته شده که برنامهای برای شمارش تعداد کاراکترهای مشترک میان این دو رشته بنویسیم. برای نوشتن این برنامه باید توجه کنیم که وجود کاراکتر تکراری در یک رشته بر جواب نهایی نباید تاثیر داشته باشد.
فرض کنیم برای مثال رشتههای 'abcdef' و'defghia' داده شدهاند. خروجی برنامه باید به صورت زیر باشد.
Output : 4
(i.e. matching characters : a, d, e, f)یا برای مثال اگر رشتههای 'aabcddekll12@' و'bb22ll@55k' به عنوان دادههای ورودی به برنامه داده شون، برنامه باید خروجی به شکل زیر تولید کند.
Output : 5
(i.e. matching characters : b, 1, 2, @, k)روشهای متفاوتی برای حل این مسئله وجود دارند. در این بخش، کدهای پایتون آماده دو روش متمایز در حل این مسئله را نمایش دادهایم.
- استفاده از توابع set() و len()
- بدون استفاده از ابزار اختصاصی و توابع درونی پایتون
در ادامه مطلب به بررسی روشهای بالا پرداختهایم.
استفاده از توابع set و len
در این رویکرد حل مسئله از تابع set() برای حذف کاراکترهای تکراری رشته دریافت شده استفاده میکنیم. بعد از آن مفهوم اشتراک مجموعهها بر روی رشته داده شده استفاده میکنیم. در آخر طول رشته را با استفاده از تابع len() بدست میآوریم.
به کد آمده زیر توجه کنید. در این کد، روش پیادهسازی الگوریتم بالا را مشاهده میکنید.
خروجی کد بالا به صورت زیر است.
NO. OF COMMON CHRACTERS ARE : 5بدون استفاده از ابزار اختصاصی و توابع درونی پایتون
کدهای پایتون آماده الگوریتمی که برای حل مسئله در این بخش بررسی میکنیم فقط از حلقه for و عبارت شرطی if-esle استفاده میکنند. فرایند اجرای این الگوریتم را میتوان در پنج مرحله زیر، توصیف کرد.
- در ابتدای کار، متغیری از جنس دیکشنری را با نام دلخواه به صورت خالی مقداردهی میکنیم. بعدا از این متغیر برای ذخیره تعداد تکرار هر کاراکتر موجود در رشته اول استفاده خواهیم کرد.
- بر روی اولین رشته پیمایش میکنیم. تمام کاراکترهای تشکیل دهنده آن را به همراه تکرار ظهور هر کاراکتر در رشته، درون دیکشنری که در مرحله قبل تعریف شده ذخیره میکنیم.
- سپس متغیری را به عنوان شمارنده تعریف میکنیم. این متغیر را با 0 مقداردهی اولیه میکنیم.
- بر روی رشته دوم پیمایش میکنیم. در این پیمایش بررسی میکنیم که آیا کاراکترهای رشته دوم در دیکشنری که در مرحله دو مقداردهی کردیم وجود دارند یا نه و آیا اینکه مقدار آنها بیشتر از صفر است یا نه. اگر جواب مثبت بود مقدار شمارنده را یک واحد افزایش میدهیم و تعداد شمارش کاراکتر درون دیکشنری را یک واحد کاهش میدهیم.
- در نهایت مقدار نهایی متغیر شمارنده را نمایش میدهیم.
به کد زیر توجه کنید. در کد پایین ساختار توصیف شده الگوریتم بالا پیادهسازی شده است.
خروجی کد بالا به صورت زیر است.
No. of matching characters are: 5برنامه پایتون برای حذف تمام کاراکترهای تکراری در رشته داده شده
در این مسئله رشتهای داده شده است. صورت سوال به این شکل است که باید برای حذف کاراکترهای تکراری در رشته برنامهای بنویسید. توجه کنید در برنامه نوشته شده باید اولین کاراکتر حفظ شود و باقی کاراکترهای تکراری آن از رشته حذف شوند. فرض کنید به عنوان مثال رشته faradarsblogteam داده شده است. برنامه نوشته شده باید خروجی به صورت رشته fardsblogtem را برگرداند.
برای حل این مسئله روشهای مختلفی وجود دارند. در این بخش کدهای پایتون آماده دو روش مختلف را بررسی کردهایم.
- استفاده از تابعset()
- استفاده از متد operator.countOf()
بررسی کدهای پایتون آماده مربوط به هر کدام از روشهای بالا را بهترتیب از روش اول شروع میکنیم.
استفاده از تابع set
در این روش تابعی سفارشی برای انجام این کار تعریف میکنیم. با کمک تابع set() عناصر تکراری درون رشته را حذف میکنیم. این تابع، ساختار داده رشته را به کاراکترهای تشکیل دهنده تجزیه میکند و به ساختار ذخیره داده تکرارناپذیر Set تبدیل میکند. در نهایت همه کاراکترهای باقیمانده را دوباره به یکدیگر میچسبانیم.
به کد پایین توجه کنید. در کد پایین فرایند حل مسئله بالا پیادهسازی شده است.
خروجی حاصل از کد بالا به صورت زیر است.
Without Order: rstfdgelmoab
With Order: f
With Order: fa
With Order: far
With Order: far
With Order: fard
With Order: fard
With Order: fard
With Order: fards
With Order: fardsb
With Order: fardsbl
With Order: fardsblo
With Order: fardsblog
With Order: fardsblogt
With Order: fardsblogte
With Order: fardsblogte
With Order: fardsblogtemاستفاده از متد operator.countOf
در این روش از متد countOf() استفاده میکنیم. این متد درون کتابخانه operator تعریف شده است و باید از طریق آن کتابخانه، فراخوانی شود. در این روش هم میتوان با کمک تابع set() اعضای تکراری رشته را حذف کرد. اما از تابع countOf() استفاده میکنیم. در ابتدا با کمک حلقه for بر روی رشته دریافتی پیمایش میکنیم. سپس به کمک تابع countOf() وجود هر کاراکتر را که در متغیر t وجود نداشته باشد در رشته اصلی بررسی میکنیم. همه کاراکترهای تکراری را ندیده میگیریم و اگر به کاراکتر جدیدی رسیدیم به متغیر tاضافه میکنیم.

به کد زیر توجه کنید. در کد زیر فرایند حل مسئله بالا پیادهسازی شده است.
خروجی حاصل از کد بالا به صورت زیر است.
Without Order: rstfdgelmoab
With Order: f
With Order: fa
With Order: far
With Order: far
With Order: fard
With Order: fard
With Order: fard
With Order: fards
With Order: fardsb
With Order: fardsbl
With Order: fardsblo
With Order: fardsblog
With Order: fardsblogt
With Order: fardsblogte
With Order: fardsblogte
With Order: fardsblogtemپیداکردن کاراکتری که کمترین مقدار را در رشته دارد
در این مسئله به دنبال کاراکتری میگردیم که کمترین تکرار را در رشته به همراه کمترین مقدار داشته باشد. یعنی اگر دو کاراکتر بودن که فقط یک بار در رشته ظاهر شده بودند، کاراکتری انتخاب میشود که جایگاه کوچکتری نیز نسبت به سایر کاراکترها دارد. در حال حاضر این مسئله یکی از مسائل پر کاربرد برنامهنویسی است و آشنایی با روشهای حل این سوال میتواند بسیار مفید واقع شود.
برای حل این مسئله کدهای پایتون آماده سه روش مختلف را بررسی خواهیم کرد.
- متد ساده با استفاده از تابع min()
- استفاده از تابع collections.Counter() همراه با تابع min()
- استفاده از تابع defaultdict() به همراه تکنیک List Comprehension
بررسی روشهای بالا را به ترتیب از روش اول شروع میکنیم.
متد ساده با استفاده از تابع min
در این روش به سادگی بر روی رشته پیمایش میکنیم. در طی پیمایش رشته، هر دفعه که با کارکتر جدیدی روبهرو میشویم این کاراکتر را به دیکشنری اضافه میکنیم. اگر به کاراکتری بر بخوریم که از قبل در دیکشنری موجود باشد، مقدار شمارش آن کاراکتر را یک واحد افزایش میدهیم. در نهایت هم میتوان کاراکتری که کمترین مقدار شمارش را دارد با اعمال تابع min() بر روی مقادیر value-های دیکشنری بدست آورد.
به کد زیر توجه کنید. این کد از روی پروسه حل مسئله توضیح داده شده در بالا بهدست میآید.
خروجی کد بالا به صورت زیر است.
The original string is : FaradarsBlogTeam
The minimum of all characters in FaradarsBlogTeam is : fاستفاده از تابع collections.Counter همراه با تابع min
این روش بیشترین استفاده را برای پیدا کردن تعداد تکرارهای همه کاراکترهای درون رشته دارد. در واقع با کمک این روش میزان فراوانی همه عناصر موجود در رشته بدست میآید. پس در صورت نیاز هر عنصر را با توجه به فراوانی تعیین شده میتوان در خروجی نمایش داد. برنامهای که طراحی کردیم برای پیدا کردن جواب کمترین مقدار کاراکترها از تابع min() بر روی مقدار تکرار کاراکترها استفاده میکند.
به کد زیر توجه کنید. در کد زیر فرایند استفاده از تابع Counter() را پیادهسازی کردهایم. این تابع درون کتابخانه collections تعریف شده است و باید از این کتابخانه فراخوانی یا Import شود.
خروجی کد بالا به صورت زیر است.
The original string is : GeeksforGeeks
The minimum of all characters in GeeksforGeeks is : fاستفاده از تابع defaultdict به همراه تکنیک List Comprehension
در این روش کاراکتری را که کمترین مقدار تکرار را داشته باشد درون رشته داده شده بدست میآوریم. این کار را با شمارش تکرار هر کاراکتر به وسیله تابع defaultdict() انجام میدهیم. این روش کمترین تکرار شمارش کاراکترها را محاسبه میکند و کاراکتر با کمترین تکرار را برمیگرداند. برای این کار کلیدهای دیکشنری را بر حسب مقدار آنها فیلتر میکند. کاراکترهایی که به عنوان نتیجه استخراج شدهاند در نهایت منظم میشوند. اولین کاراکتر از میان کاراکترهای نتیجه منظم شده را برنامه به خروجی برمیگرداند.

تابع defaultdict() یک تابع از پیش تعریف شده پایتونی است که درون کتابخانه collections قرار دارد و باید از آنجا به محیط کدنویسی Import شود. به کد زیر توجه کنید. در کد پایین فرایند توضیح داده شده بالا را پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
The least frequent character in 'FaradarsBlogTeam' is: fبرنامه ای برای بررسی وجود کاراکترهای خاص در رشته
در این مسئله فرض میکنیم رشتهای داده شده است. باید برنامهای بنویسیم که وجود کاراکترهای خاص را درون این رشته بررسی کند. برنامه نوشته شده اگر کاراکتر خاصی پیدا کرد رشته مورد پذیرش قرار نخواهد گرفت در غیر این صورت رشته معتبر است و مورد پذیرش قرار میگیرد. فرض کنیم که به برنامه رشته فرضی Faradars$Blog$Team را ارسال میکنیم. برنامهای که نوشتهایم باید خروجی به صورت پیام String is not accepted. برگرداند اما اگر به برنامه رشتهFaradars Blog Team را ارسال کنیم، برنامه باید خروجی به صورت String is accepted را برگرداند.
توجه کنید مجموعه کاراکترهای خاص شامل کاراکترهای زیر میشود.
'[@_!#$%^&*()<>?/\|}{~:]'برای حل این مسئله میتوان راه حلهای متفاوتی را در نظر گرفت. در این بخش کدهای پایتون آماده مربوط به چهار روش مختلف زیر را بررسی خواهیم کرد.
- استفاده از عبارات منظم
- استفاده از راه حل ساده پایتونی
- استفاده از متدهای درونی خود پایتون
- استفاده از الگوریتم string.punctuation
- استفاده از مقادیر کد ASCII
هر کدام از راه حلهای بالا برای حل مسئله روش منحصر بهفردی را در پیش گرفتهاند که الزاما بهترین روش نیستند. اما آشنایی با این روشها و تمرین و تسلط بر روی کار با همه کدهای پایتون آمادهای که ارائه دادهایم در نهایت باعث تقویت مهارت حل مسئله در هر برنامهنویسی خواهد شد. بررسی روشهای بالا را بهترتیب از روش اول شروع میکنیم.
استفاده از عبارات منظم
بهترین روش کار با عبارات منظم در پایتون، استفاده از کتابخانه مخصوص رجکسها یا همان کتابخانه re است. درون این کتابخانه ابزار گوناگونی وجود دارد. در این روش حل مسئله از متد compile() استفاده میکنیم. الگوریتمی که برای این برنامه در نظر گرفته شده را میتوان در ۴ مرحله کلی زیر توضیح داد.
- در ابتدا از همه کاراکترهای خاصی که نمیخواهیم در رشته باشند شی «عبارت منظمی» (RegEx | Regular Expression) تولید میکنیم.
- سپس رشته را به متد مخصوص جستوجو ارسال میکنیم.
- اگر هر کاراکتری در رشته پیدا کردیم که با رجکس نوشته شده سازگار بود
- پیغام مربوط به عدم پذیرش رشته و در غیر این صورت پیغام مربوط به پذیرفته شدن رشته را چاپ میکنیم.
به کد زیر توجه کنید. در کد زیر فرایند الگوریتم بالا را پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
String is not accepted.استفاده از راه حل ساده پایتونی
روند حل مسئله در این الگوریتم به این صورت است که در ابتدای کار برای بررسی اینکه آیا کاراکتر خاصی درون رشتهای موجود است یا نه، همه کاراکترهای خاص را درون یک مجموعه دستهبندی میکنیم. سپس با استفاده از حلقه for و عبارت شرطی if رشته دریافت شده را برای پیدا کردن کاراکترهای خاص، مورد جستوجو قرار میدهیم. اگر کاراکتر خاصی درون رشته پیدا شد، مقدار متغیر c را یک واحد افزایش میدهیم. در نهایت اگر مقدار متغیر c بزرگتر از صِفر بود بر روی خروجی سیستم به کاربر پیام string is not accepted را نمایش میدهیم. این پیام به معنای عدم پذیرش رشته دریافت شده است. در غیر این صورت رشته مورد پذیرش قرار میگیرد و پیام string is accepted. به کاربر نمایش داده میشود.

به کد زیر نگاه کنید تا شکل پیادهسازی شده فرایند بالا را در زبان برنامهنویسی پایتون درک کنید.
خروجی حاصل از اجرای کد بالا با رشته داده شده فرضی به صورت زیر است. میتوانید با سایر رشتههای مورد نظر خود این کد را آزمایش کنید.
String is not accepted.استفاده از متدهای درونی خود پایتون
در ادامه رویکرد دیگری را برای حل این مسئله مشاهده میکنید. کدهای پایتون آماده زیر بدون استفاده از عبارات منظم و فقط بر پایه توابع درونی خود پایتون به حل این مسئله میپردازند. نکته بسیار کلیدی این روش حل مسئله استفاده از توابع اختصاصی پایتون isdigit() و isalpha() است.
در کد زیر به روش استفاده از این توابع برای حل مسئله توجه کنید.
خروجی کد بالا به صورت زیر است.
The string does not contain special characters.
The string contains special characters.در رویکرد حل مسئله بالا تابع isdigit() برای بررسی رقم بودن و تابع isalpha() برای بررسی الفبا بودن کاراکترها استفاده میشود. اگر برنامه کاراکتری پیدا کند که نه جزو کاراکترهای الفبا باشد و نه جزو ارقام، نتیجه میگیرد که کاراکتر مورد نظر از نوع کاراکترهای خاص است.
استفاده از رشته string.punctuation
در این الگوریتم برای حل مسئله از شی رشتهای punctuation استفاده میکنیم. این شی punctuationدر واقع الگوریتمی است که درون کتابخانه string تعریف شده است. شی punctuationاز جنس رشته است. این شی شامل همه کاراکترهای خاص میشود. مراحل حل مسئله را در کدهای پایتون آماده زیر، به صورت کلی در چهار بخش میتوان توضیح داد.
- ماژول مربوط به string را در پایتون Import میکنیم. شی رشتهای به نام punctuationدرون این ماژول تعریف شده، این نیز حاوی همه کاراکترهای خاص است.
- بر روی همه کاراکترهای درون رشته پیمایش میکنیم.
- به هر کاراکتری که میرسیم، وجودش را درون رشته punctuationبررسی میکنیم.
- در صورت پیدا شدن کاراکتری خاص در طول پیمایش، رشته را مورد پذیرش قرار نمیدهیم و پیغام String is not accepted را بر روی خروجی به کاربر نمایش میدهیم. در غیر این صورت رشته مورد پذیرش برنامه قرار میگیرد و پیغام String is accepted در خروجی نمایش داده میشود.
به کد زیر توجه کنید. در کد زیر رویکرد حل مسئله بالا را به زبان برنامهنویسی پایتون پیادهسازی کردهایم.
خروجی حاصل از اجرای برنامه بالا به صورت زیر است.
String is not accepted
String is accepted
استفاده از مقادیر کد ASCII
در این روش حل مسئله تابع سفارشی با نام دلخواه check_special_char_ascii() تعریف کردهایم. در این تابع از مقادیر کدهای ASCII استفاده میکنیم. با کمک مقادیر کدهای ASCII وجود کاراکترهای خاص را درون رشتههای دریافت شده بررسی میکنیم. تابع سفارشی که طراحی کردیم بر روی هر کاراکتر درون رشته پیمایش میکند. در طول پیمایش قرارگیری این کاراکتر را درون محدوده کاراکترهای الفبایی و رقمی بررسی میکند. اگر کاراکتری پیدا کرد که مقدار کد ASCII آن در خارج از این محدودهها قرار داشت در نتیجه آن کاراکتر از نوع کاراکترهای خاص است. طبق روشهای بالا اگر درون رشته کاراکتری از نوع خاص پیدا شود پیغام String is not accepted و اگر کاراکتر خاص درون رشته دریافی پیدا نشود، پیغام String is accepted. باید در خروجی نمایش داده شود.

عملیات توصیف شده بالا را در چهار مرحله میتوان پیادهسازی کرد.
- حلقه for برای پیمایش بر روی هر کاراکتر از رشته ورودی تعریف میکنیم.
- با استفاده از تابع ord() برای هر کاراکتر، مقدار کد ASCII آن را محاسبه میکنیم.
- اگر مقدار کد ASCII به خارج از محدوده مقادیر مربوط به کاراکترهای رقمی و الفبایی تعلق داشت پیغام String is not accepted را در خروجی برنامه نمایش میدهیم.
- اگر پیمایش حلقه بهطور کامل بدون پیدا کردن هر شکل از کاراکتر خاصی به اتمام رسید پیغام String is accepted. را در خروجی برنامه نمایش میدهیم.
به کد زیر توجه کنید. در کد زیر روش پیادهسازی الگوریتم بالا را نمایش دادهایم.
خروجی اجرای کد بالا به صورت زیر است.
String is not accepted.تولید تصادفی رشته برای بدست آوردن رشته ای مانند رشته داده شده
در این مسئله فرض میکنیم که رشتهای داده شده است. باید برنامهای بنویسیم که به صورت رندم رشته تولید کند. رشته تولید شده به صورت تصادفی باید شامل همه کاراکترها باشد. فرایند تولید تا زمان دستیابی به جواب باید داعما تکرار شود. هر وقت که رشته تولید شده توسط برنامه دقیقا برابر با رشته دریافت شده بود وظیفه برنامه پایان یافته است.
پیشنیاز: در زبان برنامهنویسی پایتون از ثابتهای string.ascii_lowercase و string.digits و string.ascii_uppercase برای تولید «شناسههای» (IDs) تصادفی استفاده میشود. این ثابتهای به ترتیب شامل حروف الفبای کوچک، ارقام و حروف الفبای بزرگ انگلیسی میشوند. در این قسمت از کدهای پایتون آماده به عنوان دیکشنری برای ساخت شناسههای تصادفی مورد استفاده قرار میگیرند. همه این ثابتهای رشتهای با کاراکترهای اختصاصی دیگری مانند ., !?;: ترکیب و در متغیری ذخیره میشوند.
حل مسئله: برای حل این مسئله کافی است که از دو حلقه و تابع درونیrandom() پایتون برای تولید داده تصادفی استفاده کنیم. این فرایند همه ترکیبات ممکنی که توسط تابع random() تولید میشوند را نمایش میدهد. حلقههای مخصوص رمزگشایی نیز تقریبا همچنین فرایندی را طی میکنند. در پایان، این برنامه متنی را به کاربر نمایش میدهد که از کاربر خواسته شده بود به صورت دلخواه وارد کند. این برنامه همه رشتههای تصادفی تولید شده را با رشته وارد شده توسط کاربر تطبیق میدهد. بر روی هر کاراکتر به صورت جداگانه عمل بررسی انجام میگیرد. اگر کاراکترهایی پیدا کرد که با یکدیگر همسان بودند آن کاراکتر را در جایگاه شناسایی شده رشته تصادفی تثبیت میکند و برای بررسی باقی کاراکترها به پیمایش میپردازد.
به کدهای پایتون آماده زیر توجه کنید. در کدهای زیر فرایند توصیف شده الگوریتم بالا پیادهسازی شده است.
خروجی کد بالا با داده ورودی فرضی برنامه به صورت زیر است. میتوانید این برنامه را با دادههای مورد نظر خود نیز آزمایش کنید.
FyFJ
.:YZ
aubo
.
.
.
g56G
gk6R
g7Se
gT o
gD d
gXek
g0ek
g ek
.
.
gUek
giek
geek
Target matched after 168 iterationsپیدا کردن کلماتی که بزرگتر از طول مشخص شده K هستند
در این مسئله فرض میکنیم که رشتهای -مثل متن طولانی- داده شده است. باید برنامهای بنویسیم که همه کلمات بزرگتر از اندازه تعیین شده K را مشخص کند. توجه کنید که در واقع به دنبال زیر رشتههایی میگردیم که از یکدیگر با فضای خالی جدا شدهاند.

فرض کنید که رشته زیر به عنوان ورودی به برنامه داده میشود.
Input : str = "hello geeks for geeks
is computer science portal" <br> k = 4<br>خروجی برنامه باید تقریبا به شکل زیر باشد.
Output : hello geeks geeks computer
science portal<br>توجه کنید که در خروجی لیستی از همه کلماتی که اندازه بزرگتر از K دارند نمایش داده شده است. یا به مثال بعدی توجه کنید. در این مثال داده ورودی بهشکل زیر است.
Input : str = "string is fun in python"<br> k = 3خروجی برنامه باید به شکل زیر باشد.
Output : string python برای حل این مسئله کدهای پایتون آماده سه روش مختلف زیر را بررسی خواهیم کرد.
- با استفاده از کدهای ساده پایتون
- استفاده از تکنیک List Comprehension
- استفاده از تابع lambda

در ادامه مطلب، روشهای بالا را به ترتیب از اولین روش یعنی استفاده از کدهای ساده پایتون بررسی کردهایم.
استفاده از کدهای ساده پایتون
در این روش رویکرد اصلی برای حل مسئله بر اساس تجزیه با کمک تابع split() و پیمایش رشته طراحی شده است. به این شکل که در ابتدای کار رشته داده شده را با توجه به فضاهای خالی موجود در رشته به زیر رشتههای تشکیل دهنده آن تجزیه کردهایم. سپس بر روی همه کلمات پیمایش میکنیم. به هر کلمه که میرسیم اندازه آن کلمه را با مقدار K مقایسه میکنیم. کلمات بزرگتر از مقدار K در خروجی چاپ میشوند.
به کد زیر توجه کنید. فرایند ساده حل مسئله بالا را در کد زیر پیادهسازی کردهایم.
خروجی حاصل از اجرای کد بالا به صورت زیر است.
geek geeks استفاده از تکنیک List Comprehension
در این روش با استفاده از تکنیک List Comprehension عملیات مربوط به تجزیه رشته دریافت شده، پیمایش بر روی کلمات، عمل مقایسه و تشکیل لیست نهایی همگی بسیار ساده فقط در یک خط پیادهسازی شدهاند. به کد زیر توجه کنید.
خروجی حاصل از اجرای کد بالا بهشکل زیر است.
['hello', 'geeks', 'geeks', 'computer', 'science', 'portal']استفاده از تابع lambda
در این روش از توابع درونی lambdaو len() و filter() و list() در کنار هم در یک خط استفاده کردهایم. برای جداسازی کلمات تشکیل دهنده رشته هنوز بهترین روش استفاده از تکه کد .split(" ") است. به کد زیر توجه کنید تا روش استفاده از تابع lambda را برای جداسازی کلمات ببینید.
خروجی حاصل از اجرای کد بالا بهشکل زیر است.
['hello', 'geeks', 'geeks', 'computer', 'science', 'portal']برنامه پایتون برای تجزیه و اتصال واحدهای رشته به یکدیگر
در این بخش باید برنامه پایتون بنویسیم که رشتهها را بر اساس حائلی که مشخص شده از یکدیگر جدا کند و رشتههای جدا شده را با استفاده از حائلی که تعیین شده به یکدیگر بچسباند. تجزیه رشتهها بعضی وقتها میتواند بسیار مفید و ضروری باشد، مخصوصا زمانهایی که فقط به قسمتهای خاصی از رشته نیاز داشته باشیم. به عنوان یک مثال ساده و موثر میتوان به تجزیه نام و نامخانوادگی اشخاص اشاره کرد.
کاربرد دیگر این روش در فایلهای CSV است. حروف CSV علامت اختصاصی «مقادیر جدا شده به وسیله کاما» (Comma Separated Values) است. برنامهنویسان از عمل تجزیه دادهها برای گرفتن اطلاعات از فایلهای CSV و از عمل اتصال دادهها برای نوشتن اطلاعات در فایلهای CSV استفاده میکنند.
در پایتون میتوانیم با استفاده از تابع split() رشتهها را تجزیه کنیم. همچنین با استفاده از تابع join() نیز میتوانیم رشتههای تجزیه شده را به یکدیگر بچسبانیم. به عنوان مثال اگر رشته Faradars Blog Team را به برنامه بدهیم با استفاده از تابع split() و مشخص کردن جداساز فضای خالی پایتون خروجی زیر را به صورت لیست به کاربر برمیگرداند.
Output : ['Faradars', 'Blog', 'Team']و اگر لیست فرضی ['Faradars', 'Blog', 'Team'] را به برنامه ارسال کنیم، با استفاده از تابع join() و مشخص کردن حائل ('-') پایتون خروجی زیر را به کاربر برمیگرداند.
Output : Faradars-Blog-Teamبرای حل این مسئله، کدهای پایتون آماده دو روش مختلف زیر را بررسی خواهیم کرد.
- جداسازی و اتصال زیر رشتهها به یکدیگر بر اساس حائل مشخص شده
- استفاده از توابع join() و split()
با بررسی مورد اول مطلب را ادامه میدهیم.
جداسازی و اتصال زیر رشته ها به یکدیگر بر اساس حائل مشخص شده
در این روش، با کمک حائلی که برای برنامه مشخص شده اجزای تشکیل دهنده رشته را از یکدیگر جدا میکنیم یا با استفاده از این حائل رشتههای جدا از هم را به یکدیگر متصل میکنیم.
به کد زیر توجه کنید.
خروجی اجرای کد بالا به صورت زیر است.
['Faradars', 'Blog', 'Team']
Faradars-Blog-Teamاستفاده از توابع join و split
در پایتون با استفاده از تابع split() میتوانیم رشتهها را به اجزای کوچکتری تجزیه کنیم. این تابع بعد از اعمال شدن بر روی رشته، با توجه به جدا کنندهای که برای تابع مشخص شده همه زیر رشتههای ممکن را از هم تجزیه میکند. سپس این زیر رشتهها در لیستی جمعآوری میشوند. به همچنین در پایتون با استفاده از تابع join() میتوانیم رشتههای مجزا از هم را به یکدیگر متصل کنیم. به صورت دلخواه برای اتصال بین رشتهها میتوان حائل مورد نظر خود را -فضای خالی، کاراکتر خاص یا اصلا هیچ حائلی- تعیین کرد.

به کد زیر نگاه کنید. در کد زیر یکی از سادهترین و مختصرترین کدنویسیهای ممکن را برای حل این مسئله ارائه دادهايم.
خروجی اجرای کد بالا به صورت زیر است.
['Geeks', 'for', 'Geeks']
Geeks-for-Geeksبرنامه پایتون برای پیدا کردن کلمات غیر مشترک بین دو رشته مختلف
فرض کنیم که دو جمله متفاوت به عنوان رشته A و رشته B داده شدهاند. مسئله این است که برنامهای برای برگرداندن لیستی از کلمات غیر مشترک این دو رشته بنویسیم. منظور از کلمات غیر مشترک، کلماتی هستند که فقط در یکی از این دو لیست وجود دارند و در لیست دیگر وجود ندارند.
توجه کنید: در مبحث زبانهای برنامهنویسی، به رشتهای که اجزای تشکیل دهنده آن توسط یک فضای خالی از یکدیگر قابل تفکیک باشند، جلمه میگویند.
برای مثال فرض کنیم که جملات زیر را به برنامه ارسال کردهایم.
Input : A = “apple banana mango” , B = “banana fruits mango”این برنامه باید خروجی به شکل [‘apple’, ‘fruits’] را برگرداند.
برای حل این مسئله، کدهای پایتون آماده مربوط به چهار روش مختلف زیر را بررسی کردهایم.
- تعریف تابع و استفاده از تکنیکهای ساده پایتونی
- استفاده از توابع split() و list() و set() به همراه عملگرهای in و not
- استفاده از تابع Counter()
- استفاده از توابع difference() و set() برای پیدا کردن اختلاف دو مجموعه
تعریف تابع و استفاده از تکنیک های ساده پایتونی
برای حل مسئله باید به این نکته توجه کنیم که هر کلمه غیر مشترکی بین رشتهها فقط در یکی از رشتهها ظاهر میشود و در رشته دیگر وجود نخواهد داشت. بنابراین تکه کدی به صورت جدول هش برای شماردن تعداد ظهور هر کلمه در جملات پیادهسازی میکنیم. سپس لیستی از کلمات که دقیقا یک بار ظاهر شدهاند را برمیگردانیم.
در کد زیر میتوان کدهای پایتون آماده پیادهسازی شده راه حل بالا را مشاهده کرد.
خروجی کد بالا برابر با لیست ['Learning', 'from'] است.
استفاده از توابع split و list و set به همراه عملگرهای in و not
در این روش اولین کاری که انجام میشود تجزیه کلمات هر دو رشته و تشکیل دادن لیستی از کلمات آنها است. تکه کد A=A.split() همه کلمات رشته A را تجزیه کرده و به لیستی از کلمات تبدیل میکند. سپس لیست خالی به نام دلخواه x تعریف میکنیم. سپس با کمک حلقه for بر روی هر دو لیست پیمایش میکنیم. هر کلمهای را که فقط در یکی از لیستها موجود بود را با تکه کد x.append(i) وارد لیست x میکنیم. در نهایت با استفاده از خط کد x=list(set(x)) کلمات تکراری را از لیست x حذف میکنیم. این کار را به وسیله تبدیل لیست به مجموعه انجام میدهیم. سپس مجموعه را دوباره به لیست تبدیل میکنیم و لیست نهایی را برای استفاده کاربر توسط تابع برمیگردانیم.
به کد زیر توجه کنید. در این کد فرایند توصیف شده بالا را پیادهسازی کردهایم.
خروجی کد بالا برابر با لیست ['Learning', 'from'] است.
استفاده از تابع Counter
تابع Counter درون کتابخانه collections قرار دارد. تابع Counter برای شمارش اعضای درون ساختارهای ذخیره داده پیمایشپذیر استفاده میشود. خروجی این تابع دیکشنری است که تعداد همه اعضای داخل لیست دریافتی را شمارش کرده است. نام هر عنصر برابر با کلید و تعداد ظهور آن عنصر بیانگر مقدار کلید آن عنصر است.
به کدی که در پایین آمده توجه کنید.
خروجی کد بالا برابر با لیست ['Learning', 'from'] است.
استفاده از توابع difference و set برای پیدا کردن اختلاف دو مجموعه
از تابع set() برای تبدیل ساختارهای ذخیره داده پیمایشپذیر به مجموعه استفاده میشود و تابع difference() برای محاسبه تفاوت بین دو مجموعه بهکار گرفته میشود. مراحل این الگوریتم را برای حل مسئله میتوان در ۶ گام زیر دستهبندی کرد.
- با تجزیه رشتههای A و B به زیر رشتههای تشکیل دهنده آنها توسط تابع split()، لیستی از کلمات این دو رشته تشکیل میدهیم. سپس دو مجموعه setA و setB را از این لیستها ایجاد میکنیم.
- از متد difference() برای پیدا کردن لغات غیر مشترک بین مجموعه setB و setA استفاده میکنیم.
- با استفاده از متد union() کلمات نامشترک هر دو مجموعه را ترکیب میکنیم.
- مجموعه ترکیب شده را با بهکارگیری تابع list() به لیست تبدیل میکنیم و لیست ایجاد شده را از تابع برمیگردانیم.
- تابع UncommonWords را به همراه مقادیر A و B فراخوانی میکنیم.
- در نهایت مقدار خروجی تابع را برای نمایش در خروجی چاپ میکنیم.
به کد زیر نگاه کنید. تمام فرایند توصیف شده بالا را در کد زیر پیادهسازی کردهایم.
خروجی کد بالا برابر با لیست ['Learning', 'from'] است.
جایگزین کردن رخدادهای تکراری یک مقدار در رشته
شاید بعضی وقتها که در حال کار با رشتهها در پایتون هستیم، نیاز بهجایگذاری کلمههای تکراری داشته باشیم. یعنی بخواهیم یک کلمه را در سراسر متن با کلمه دیگری جایگزین کنیم. این رفتار در زمان کار با رشتهها و متنها کاملا رایج است که به دفعات درباره آن صحبت شده و راهکارهای متفاوتی نیز برای انجام آن ارائه شده است. اما گاهی اوقات نیاز داریم که فقط تکرارهای کلمه اول را جایگزین کنیم. در واقع از رخداد دوم به بعد عنصر مورد نظر در رشته را باید جابهجا کرد. این رفتار هم در حوزههای متنوعی کاربرد دارد.
در این بخش به بررسی چند روش مختلفی که برای حل این مسئله ارائه شدهاند خواهیم پرداخت.
- استفاده از توابع split() و enumerate() به همراه حلقه
- استفاده از توابع keys() و index() به همراه تکنیک List Comprehension
- استفاده از تکنیک List Comprehension به همراه set و keys
- استفاده از «عبارات منظم» (Regular Expressions)
استفاده از توابع split و enumerate به همراه حلقه
با ترکیب توابع split() و enumerate() به همراه حلقه میتوان برنامهای نوشت که این مسئله را حل کند. در این روش با استفاده از تابع split() کلمات رشته را از یکدیگر جدا میکنیم. سپس اولین رخداد از هر عنصر یا کلمه را درون مجموعهای ذخیره میکنیم.
بعد از آن بررسی میکنیم که آیا قبلا با این مقدار روبهرو شده بودیم یا نه. اگر قبلا با این مقدار روبهرو شده باشیم، مقدار تکراری را با مقدار مورد نظر جایگذین میکنیم. به کد زیر توجه کنید. در کد زیر از تابع enumerate() برای ساخت شمارنده حلقه استفاده کردهایم. به همچنین عناصر مورد پیمایش را نیز با کمک این تابع مورد بررسی قرار میدهیم.
خروجی حاصل از اجرای کد بالا با استفاده از دادههای دلخواه برای آزمایش روند اجرای تابع به صورت زیر است.
The original string is : Gfg is best . Gfg also has Classes now. Classes help understand better.<br>The string after replacing : Gfg is best . It also has Classes now. They help understand better.استفاده از توابع keys و index به همراه تکنیک List Comprehension
این روشهم يكی از روشهای خلاقانه دیگری است که در زبان برنامه نویسی پایتون برای حل این مسئله ارائه شده است. در این رویکرد حل مسئله نیازی برای استفاده از تکنیک «بخاطرسپاری» (Memorization) وجود ندارد. در این رویکرد اصلیترین قسمت فرایند حل مسئله را در کد جامع تکنیک List Comprehension پیادهسازی کردهایم. به این کد دقت کنید.
خروجی حاصل از اجرای کد بالا با استفاده از دادههای دلخواه برای آزمایش روند اجرای تابع به صورت زیر است.
The original string is : Gfg is best . Gfg also has Classes now. Classes help understand better.<br>The string after replacing : Gfg is best . It also has Classes now. They help understand better.استفاده از تکنیک List Comprehension به همراه set و keys
در ادامه، پیادهسازی کامل کدهای پایتون آماده این الگوریتم را به همراه توضیحات لازم برای درک هر بخش از کدها آوردهایم.
- در کدهای پایین، اولین کاری که انجام میدهیم تعریف متغیر رشتهای به نام test_str با محتوای متن «.Gfg is best . Gfg also has Classes now. Classes help understand better» است.
- در خط بعدی کد با استفاده از تکنیک الحاق رشتهها درون تابع print() ، رشته اصلی را برای نمایش به کاربر در خروجی چاپ میکند.
- کد، متغیر دیکشنری به نام repl_dict را مقداردهی میکند. جفتهای «کلید و مقدار» (key-value) این دیکشنری به این صورت مقداردهی میشوند که هر کلید رشتهای است که باید جایگزین شود و مقدار آن کلید همان مقداری است که باید با این رشته جایگزین شود.
- در ادامه کد با استفاده از متد split() رشته test_str را به لیستی از کلمات تشکیل دهنده آن تجزیه میکند. سپس مجموعه خالی به نام seenرا برای نگهداری رد کلمات جایگزین شده تعریف میکنیم.
- برای جایگزین کردن رخدادهای تکراری درون لیست کلماتی که در مرحله قبل تولید کردیم این کد از تکنیک List Comprehension استفاده میکند. در عملیات Comprehension بر روی همه کلمات درون لیست پیمایش میکنیم و وجود داشتن هر کلمه را درون دیکشنری repl_dict به همراه عدم حضور هر کلمه، درون مجموعه seen را بررسی میکنیم. اگر کلمهای پیدا کردیم که درون دیکشنری مورد اشاره قرار گرفته وجود داشت ولی درون مجموعه seenوجود نداشت پس کلمه مذکور را با مقدار value متناظر خودش درون دیکشنری جایگزین و به مجموعه seenاضافه میکنیم. در غیر این صورت از کلمه به همان صورت که هست استفاده میکنیم.
- در حرکت بعدی کد، برای ساخت رشته نهایی، لیستی از کلمات را که در مرحله قبل تولید کرده را با استفاده از تابع join() به یکدیگر متصل میکند. در زمان اتصال کلمات از فضای خالی به اندازه یک کاراکتر به عنوان جداکننده بین کلمات استفاده میکند. و نتیجه نهایی را به متغیری با نام دلخواه res تخصیص میدهد.
- در نهایت هم کد رشته نهایی تولید شده را با استفاده از تکنیک الحاق رشتهها درون تابع print() برای نمایش به کاربر در خروجی چاپ میکند.

به کدهای پایتون آماده زیر توجه کنید. در کدهای زیر الگوریتم توصیف شده بالا پیادهسازی شده است.
خروجی حاصل از اجرای کد بالا با استفاده از دادههای دلخواه برای آزمایش روند اجرای تابع به صورت زیر است.
The original string is : Gfg is best . Gfg also has Classes now. Classes help understand better .
The string after replacing : It is best . Gfg also has They now. Classes help understand better .استفاده از عبارات منظم
در پایتون برای کار با «عبارات منظم» (Regular Expressions) کتابخانه اختصاصی تعریف شده است. این کتابخانه ابزارهایی را برای کار سریعتر، راحتتر و امنتر با رجکسها ارائه میدهد. در این روش حل مسئله از کتابخانه اختصاصی پایتون برای کار با رجکسها استفاده خواهیم کرد. نام این کتابخانه re است. در این روش برای اینکه بهدنبال رخدادهای تکراری کلمات درون رشته دریافت شده بگردیم و کلمات تکراری را با مقادیر متناظر آنها جابهجا کنیم از کتابخانه «re» استفاده میکنیم. مقادیر متناظر کلماتی که باید جایگزین شوند در دیکشنری repl_dict ذخیره شدهاند.
روند اجرای عملیات این الگوریتم را میتوان به صورت خلاصه در ۵ مرحله زیر بیان کرد.
- ماژول re را Import میکنیم.
- متغیرهای test_str و repl_dict را تعریف و مقداردهی اولیه میکنیم.
- برای اینکه رجکس با رخدادهای تکراری کلمات درون repl_dict مطابقت داشته باشد، الگوی مخصوصی برای عبارت منظم تعریف میکنیم.
- برای اینکه کلمات تطبیق داده شده با الگوی رجکس را با مقادیر متناظرشان در repl_dict جایگزین کنیم، از متد re.sub() استفاده میکنیم.
- در نهایت رشته اصلی دریافت شده را به همراه رشته خروجی برنامه که کلماتش جایگزین شده برای نمایش در خروجی چاپ میکنیم.
به کد زیر توجه کنید. در کد زیر تمام فرایند توضیح داده شده در بالا پیادهسازی شده است.
خروجی حاصل از اجرای کد بالا با استفاده از دادههای دلخواه برای آزمایش روند اجرای تابع به صورت زیر است.
The original string is : Gfg is best . Gfg also has Classes now. Classes help understand better .
The string after replacing : It is best . Gfg also has They now. Classes help understand better .محاسبه جایگشت های رشته داده شده با استفاده از توابع درونی پایتون
به «جایگشت» (Permutation)، «عدد چیدمان» (Arrangement Number) یا ترتیب هم میگویند. جایگشت در واقع به تمام چیدمانهای مختلف عناصر لیست S میگویند که میتوان به صورت منظم و به تعداد عناصر در کنار یکدیگر مرتب کرد. قانون کلی این است که رشتهای با طول n به تعداد !n جایگشت مختلف دارد. در این مسئله فرض سوال این است که رشتهای داده شده است. باید برنامهای بنویسیم که تمام جایگشتها ممکن کاراکترهای تشکیل دهنده رشته را نمایش دهد.
فرض کنیم که اگر به عنوان ورودی برنامه، رشتهای بهشکل str = 'ABC' داده شود. برنامهای که طراحی شده باید خروجی بهشکل زیر تولید کند.
ABC
ACB
BAC
BCA
CAB
CBAبرای حل این مسئله در پایتون تابع درونی به نام permutations() وجود دارد. این تابع به صورت اختصاصی برای محاسبه جایگشتهای ممکن به وجود آمده است و درون کتابخانه itertools تعریف شده است. در این بخش سه سری متفاوت از کدهای پایتون آماده زیر را برای حل این مسئله پیادهسازی کردهایم.
- شکل اول استفاده از تابع permutations()
- شکل دوم استفاده از تابع permutations()
- استفاده از توابع بازگشتی برای محاسبه جایگشت
شکل اول استفاده از تابع permutations
همانطور که در متن بالا اشاره کردیم تابع permutations()را باید از کتابخانه itertools به محیط کدنویسی Import کرد. در این روش حل مسئله بعد از Import کردن تابع permutations()تابع سفارشی برای نمایش جایگشتهای مختلف رشته مشخص شده تعریف میکنیم.
به کد زیر توجه کنید.
خروجی کد بالا با توجه به رشته دلخواه داده شده ABC به شکل زیر است.
ABC
ACB
BAC
BCA
CAB
CBAشکل دوم استفاده از تابع permutations
در این روش، شکل دیگری از نحوه پیادهسازی استفاده از تابع permutations()برای محاسبه جایگشت را مشاهده میکنید. این روش، نسبت به روش بالا خلاصهتر کدنویسی شده است.
خروجی کد بالا با توجه به رشته دلخواه داده شده GEEK به شکل زیر است.
GEEK
GEKE
GKEE
EGEK
EGKE
EEGK
EEKG
EKGE
EKEG
KGEE
KEGE
KEEGاستفاده از توابع بازگشتی برای محاسبه جایگشت
در این روش برعکس روشهای بالا از تابع permutations()استفاده نمیکنیم. بلکه خودمان با استفاده از تکنیک کدنویسی توابع بازگشتی، تابعی را به صورت اختصاصی برای این کار مینويسيم. توجه کنید: لیستی که به نام permutations تعریف کردهایم ارتباطی به تابع permutations()از کتابخانه itertools ندارد.

کل فرایند الگوریتم طراحی شده به این منظور را میتوان در ۶ مرحله زیر توضیح داد.
- رشته ورودی را از کاربر میگیریم.
- تابع بازگشتی تعریف میکنیم تا تمام جایگشتهای قابل ساخت ممکن با کاراکترهای رشته ارسال شده کاربر را محاسبه کنیم.
- تعریف مورد پایه: اگر طول رشته دریافت شده برابر با یک باشد، خود رشته باید برگردانده شود.
- تعریف مورد بازگشتی: برای هر کاراکتر درون رشته جایگاهش را تثبیت میکنیم و برای کاراکترهای باقی مانده به صورت بازگشتی جایگشتهای ممکن محاسبه میشود.
- هر کاراکتر تثبیت شده را با تمام جایگشتهای ناشی از فراخوانی بازگشت تابع ترکیب میکنیم و به لیست جایگشتها به نام permutations اضافه میکنیم.
- لیست جایگشتها permutationsرا در خروجی برمیگردانیم.
به کدهای پایتون آماده زیر توجه کنید. تمام فرایند بالا را در کدهای پایین پیادهسازی کردهایم.
خروجی کد بالا با توجه به رشته دلخواه داده شده GEEK به شکل زیر است.
GEEK
GEKE
GKEE
EGEK
EGKE
EEGK
EEKG
EKGE
EKEG
KGEE
KEGE
KEEGبررسی وجود URL در رشته ها
توجه کنید که داشتن آشنایی با تطبیق الگو برای «عبارات منظم» (Regular Expression)پیش شرط لازم برای درک راه حلهای این مسئله است. در فرض این مسئله رشته بزرگی داده شده است. باید برنامهای بنویسیم که درون رشته را برای یافتن URL بررسی کند. در صورت وجود داشتن URL در رشته، آن را از رشته استخراج کند و در خروجی برگرداند.
در اولین روش، برای حل این مسئله از مفهوم Regular Expression در پایتون استفاده خواهیم کرد. فرض کنیم که رشته زیر به عنوان ورودی به برنامه داده شده است.
Input : string = 'My Profile: https://blog.faradars.org/author/m-rashidi/ in the portal of https://blog.faradars.org/'خروجی برنامه باید لیستی بهشکل زیر باشد.
['https://blog.faradars.org/author/m-rashidi/', 'https://blog.faradars.org/']برای حل این مسئله، کدهای پایتون آماده روش استفاده از تابع re.findall() را بررسی خواهیم کرد.
استفاده از تابع re.findall
در این روش برای اینکه بتوانیم URL-ها را درون رشته دریافت شده پیدا کنیم از تابع findall() استفاده کردهایم. این تابع درون ماژول اختصاصی پایتون برای کار کردن با عبارات منظم یعنی ماژول re تعریف شده است. این تابع تمام تطابقهای «غیر همپوشانه» (Non-Overlapping) با الگوی تعریف شده را از درون رشته برمیگرداند. در واقع آیتمهایی که توسط این تابع از درون رشته شناسایی میشوند کاراکتر مشترک درون رشته ندارند. تابع findall() رشته را از چپ به راست بررسی میکند و با همان ترتیبی که پیدا میشوند موارد مطابق با الگو برگردانده خواهند شد.
به کد زیر توجه کنید. در این کد فرایند استفاده از این تابع به همراه الگوی رجکس برای کشف URL-ها نمایش داده شده است.
خروجی حاصل از کد بالا با رشته داده شده دلخواه به صورت زیر است.
Urls: ['https://blog.faradars.org/author/m-rashidi/', 'https://blog.faradars.org/']آموزش های تکمیلی مرتبط با پایتون در فراردس
بعد از تمرین و بررسی کدهای پایتون آماده متنوعی که در این مطلب یا مطالب مشابه آمدهاند، کار مهمی که باید انجام دهیم آماده شدن و استفاده از دانش مربوط به زبان برنامهنویسی پایتون برای انجام پروژههای واقعی متناسب با بازار کار است. به این منظور در وبسایت فرادرس فیلمهای آموزشی مربوط به دورههای حرفهای طراحی شده که بهطور اختصاصی آموزش پایتون را به صورت پروژه محور دنبال میکنند. پروژههایی که در بازار کار قابل ارائه دادن و درآمدزایی هستند.

این فیلمهای آموزشی در انواع فیلدهای مختلف کاربردی پایتون آماده شدهاند که برای راحتی دسترسی شما، چند مورد را در ادامه فهرست کردهایم.
- فیلم آموزش برنامه نویسی Raspberry Pi با Python از فرادرس
- فیلم آموزش پروژه محور پایتون در ارتباط با ساخت برنامه هواشناسی آنلاین فرادرس
- فیلم آموزش پیش بینی با الگوریتم های یادگیری ماشین در پایتون با پروژه پیش بینی نارسایی قلبی در فرادرس
- فیلم آموزش پروژه محور طراحی سایت و وب اپلیکیشن با فریمورک Django در پایتون از فرادرس
- فیلم آموزش پیاده سازی ربات معامله گر با مدل SVM در پایتون فرادرس
جمع بندی
همه پروژهها و نمونه کدهای پایتون آمادهای که در این مطلب از مجله فرادرس نمایش داده شدهاند بسیار ساده قابل پیادهسازی و درک هستند. اگر تمایل به ارتقای سطح مهارتهای خود در پایتون دارید پیشنهاد میکنیم که نمونه کدهای بالا را در سیستم خودتان پیادهسازی و بررسی کنید. بسیاری از این مثالهای ساده در برنامههای پیچیده و بزرگ قابل پیادهسازی و استفاده هستند.

در این مطلب مثالهای سادهای از کدهای پایتونی درباره آرایهها، لیستها، ماتریسها و رشتهها دیدیم و با مفاهیمی از قبیل دیکشنریها، کتابخانههای پایتون، تکنیکهای تعریف لیست، عبارتهای منظم و غیره کار کردیم. بهتر است در هر مسئلهای که بررسی میکنید برای کسب مهارتهای متنوع با انواع راه حلهای تعریف شده آشنا شوید.









