



تفاوت طبقه بندی و خوشه بندی در یادگیری ماشین چیست؟ – ۳ فرق کلیدی
در صورتیکه با حجم بالایی از دادههای بدون ساختار سر و کار داشته باشید، پیش از هر چیز ابتدا باید دادهها را در گروههای مجزا دستهبندی کنید. الگوریتمهای یادگیری ماشین بر اساس نوع مسئله و مقادیر هدف، به چند گروه مختلف تقسیم میشوند. از جمله مهمترین و رایجترین این تکنیکها میتوان به «طبقهبندی» (Classification) و «خوشهبندی» (Clustering) اشاره کرد. اغلب، درک تفاوت طبقه بندی و خوشه بندی برای افراد مبتنی در این حوزه دشوار است. در ظاهر شاید طبقهبندی و خوشهبندی شبیه بهنظر برسند؛ چرا که هر دو الگوریتم از ویژگیهای مجموعهداده برای کشف الگوها و جداسازی نمونهها استفاده میکنند. اما از دیدگاه کاربردی، تفاوتهای عمدهای باهم دارند. در این مطلب از مجله فرادرس، با بررسی انواع روشها و کاربردها، به تفاوت طبقه بندی و خوشه بندی در یادگیری ماشین پیمیبریم.
- خواهید آموخت که تفاوت بنیادین طبقهبندی و خوشهبندی چیست.
- میآموزید چگونه نوع داده در تعیین و انتخاب روش مناسب تأثیر دارد.
- یاد میگیرید که چه زمانی باید از الگوریتمهای مهم طبقهبندی استفاده کنید.
- خواهید توانست دادههای برچسبدار و بدون برچسب را تشخیص دهید.
- با ساختار و منطق اصلی الگوریتمهای خوشهبندی آشنا میشوید.
- یاد خواهید گرفت مزیتهای هر مدل را در پروژه بسنجید.




در این مطلب، ابتدا تعریفی از دو رویکرد طبقهبندی و خوشهبندی ارائه داده و به معرفی انواع الگوریتمهای رایج هر کدام میپردازیم. سپس یاد میگیریم تفاوت طبقه بندی و خوشه بندی در چیست و در نهایت نیز به چند مورد از سوالات متداول و مرتبط پاسخ میدهیم.
طبقه بندی چیست؟
بهطور کلی، کاربردهای طبقهبندی در دستهای از مسائل بهنام «یادگیری نظارت شده» (Supervised Learning) قرار میگیرند. مسائلی که با توسعه مدلهای یادگیری ماشین از طریق دادههای جمعآوری شده، نتایج رویدادهای جدید را پیشبینی میکنند. مطابق تعریف، یادگیری نظارت شده شامل کاربردهایی میشود که در آن، تابعی بر اساس جفت ورودی-خروجیهای نمونه، نحوه نگاشت کردن دادههای ورودی جدید را به خروجیهای متناظر یاد میگیرد. اگر پیشزمینه ریاضیاتی داشته باشید، میدانید که از این مسئله با عنوان «تقریب تابع» (Function Approximation) نیز یاد میشود.

یادگیری نظارت شده انواع مختلفی همچون «رگرسیون» (Regression) و طبقهبندی دارد. هدفِ الگوریتمهای یادگیری در مسائل طبقهبندی، رسیدن به تابعی است که با بررسی مجموعهای از ویژگیها، قادر به پیشبینی خروجی از نوع «گسسته» (Discrete) باشد. الگوریتمهای طبقهبندی در کاربردهای متنوعی از جمله مسائل زیر مورد استفاده قرار میگیرند:
- «پالایش اسپم» (Spam Filtering): طبقهبندی ایمیلهای مخرب و اسپم؛ در جهت جلوگیری از رسیدن چنین نمونههای بهدست کاربر.
- «بازشناسی چهره» (Face Recognition): شناسایی و تایید هویت افراد بر اساس ویژگیهای چهره در تصویر، ویدئو و یا بهصورت بلادرنگ و در لحظه.
- پیشبینی «ریزش مشتری» (Customer Churn): میتوان از طبقهبندی برای پیشبینی مشتریانی که احتمال دارد لغو عضویت کرده یا سرویس شما را ترک کنند بهره برد و با بهکارگیری راهکارهای جدید مانند کمپینهای تبلیغاتی، برای حفظ و ماندگاری آنها تلاش کرد.
- «پذیرش وام» (Loan Approval): تشخیص دادن واجد شرایط بودن یا نبودن یک مراجعهکننده برای دریافت وام، فرایندی تکراری و یکنواخت است. از همینرو، الگوریتمهای طبقهبندی با در نظر گرفتن معیارهایی همچون سابقه مالی فرد، پیشبینی میکنند که آیا وام به او تعلق میگیرد یا خیر.
انواع الگوریتم های طبقه بندی
در فهرست زیر، برخی از رایجترین و مورد استفادهترین الگوریتمهای طبقهبندی را ملاحظه میکنید:

- «رگرسیون لجستیک» (Logistic Regression)
- «K-نزدیکترین همسایه» (K-Nearest Neighbors | KNN)
- «درخت تصمیم» (Decision Tree)
- «جنگل تصادفی» (Random Forest)
- «بیز ساده» (Naive Bayes)
نحوه کارکرد هر کدام از الگوریتمهای عنوان شده متفاوت است و در ادامه بیشتر با هر کدام آشنا میشویم.

الگوریتم رگرسیون لجستیک
اغلب، «رگرسیون لجستیک» (Logistic Regression) را در دسته الگوریتمهای رگرسیون قرار میدهند. در واقع چندان هم اشتباه نیست؛ چرا که الگوریتم رگرسیون لجستیک هیچگونه عمل طبقهبندی آماری انجام نمیدهد و تنها پارامترهای یک مدل لجستیک را تخمین میزند. تنها دلیلی که به ما اجازه میدهد از الگوریتم رگرسیون لجستیک در مسائل طبقهبندی استفاده کنیم، «مرز تصمیمی» (Decision Boundary) است که وظیفه آن جداسازی کلاسها از یکدیگر است. از همین جهت و در سادهترین حالت، رگرسیون لجستیک از تابعی لجستیک برای مدلسازی متغیرهای وابسته دودویی استفاده میکند.


الگوریتم K-نزدیکترین همسایه
الگوریتم «K-نزدیکترین همسایه» (K-Nearest Neighbors | KNN) یکی از سادهترین الگوریتمهای یادگیری ماشین است و برخلاف رگرسیون لجستیک، هم در مسائل طبقهبندی و هم رگرسیون کاربرد دارد. روشی «ناپارامتری» (Non-parametric) که در گروه الگوریتمهای «یادگیری تنبل» (Lazy Learning) قرار میگیرد. تنبل به این معنی که پیشفرضی نسبت به ویژگیها یا کمی و کیفی بودن نمونهها نداشته و تمامی محاسبات لازم را تا زمان ارزیابی به تعویق میاندازد.

الگوریتم درخت تصمیم
الگوریتم ناپارامتری و محبوب دیگری که در مسائل رگرسیون و طبقهبندی بهکار گرفته میشود. از جمله مهمترین دلایل محبوبیت الگوریتم «درخت تصمیم» (Decision Tree)، میتوان به قابل فهم بودن و سادگی آن اشاره کرد. در مقایسه با سایر روشها، تفسیر و مصورسازی این الگوریتم به مراتب راحتتر است. درخت تصمیم، ساختاری درختی است که از موقعیت یا گرهای بهنام «ریشه» (Root) شروع شده و به گرههای دیگری با عنوان «برگ» (Leaf) ختم میشود. هر مسیر از ریشه تا برگ، معرف نوعی قاعده تصمیمگیری است که بر اساس ویژگیها اتخاذ شده است.


الگوریتم جنگل تصادفی
الگوریتم «جنگل تصادفی» (Random Forest)، در واقع مدلی ترکیبی است که از یک یا چند درخت تصمیم تشکیل شده است. این تکنیک از روشهایی همچون «تجمیع بوتاسترپ» (Bootstrap Aggregation) و «زیرفضای تصادفی» (Random Subspace) برای بسط دادن درختها و دستیابی به یک مدل تجمعی که قادر به حل مسائل طبقهبندی و رگرسیون باشد، استفاده میکند. توجه داشته باشید که روشهای Bootstrap و Bagging، تکنیکهایی هستند که از نسخههای مختلف یک مدل، در ساخت مدلی تجمعی بهره میبرند. با کاهش همبستگی میان مدلهای پیشبینی کننده، عملکرد مدل تجمعی نسبت به نمونههای جدید بهبود مییابد. در این الگوریتم، ابتدا بهصورت تصادفی از دادههای هر مدل نمونهگیری شده و سپس از آنها در فرایند آموزش استفاده میشود.

روش زیرفضای تصادفی وظیفه کاهش همبستگی میان چند مدل را در «یادگیری جمعی» (Ensemble Learning) بر عهده دارد.
الگوریتم بیز ساده
دستهبند «بیز ساده» (Naive Bayes) نوعی «الگوریتم احتمالاتی» (Probabilistic Algorithm) بر اساس نظریه بیز است که از قواعد ریاضی برای بهروزرسانی مقادیر استفاده میکند. عبارت «ساده» در نام این الگوریتم، بیانگر فرضیهای است که هنگام پیشبینی خروجی، تمامی ویژگیها یا متغیرهای مجموعهداده را مستقل از یکدیگر در نظر میگیرد. این فرضیه نوعی سادهسازی است؛ چرا که در حقیقت ممکن است ویژگیها به هم وابسته باشند. با این حال، الگوریتم بیز ساده در اغلب کاربردهای طبقهبندی عملکرد مناسبی دارد. در نتیجه، نظریه بیز نقشی در فرضیه مستقل بودن متغیرها ندارد. بلکه این دستهبند بیز ساده است که بهمنظور سادگی و کارآمدی محاسبات، چنین پیشفرضی را مطرح و از قاعده زیر پیروی میکند:
خوشه بندی چیست؟
در این بخش از مطلب مجله فرادرس، برای درک تفاوت طبقه بندی و خوشه بندی، یاد میگیریم خوشهبندی چیست و با انواع الگوریتمهای آن آشنا میشویم. برای درک خوشهبندی، ابتدا باید با تعریف «یادگیری نظارت نشده» (Unsupervised Learning) شروع کنیم. یادگیری نظارت نشده راهی برای کشف ساختار دادهها، بدون نگاشت نمونههای ورودی به خروجی متناظر است.


برخلاف یادگیری نظارت شده، در یادگیری نظارت نشده برای گروهبندی و پیدا کردن الگوهای داده، نیازی به برچسب نیست. بلکه اینطور در نظر گرفته میشود که نمونههای همگروه، ویژگیهای مشابهی نیز دارند. از همین جهت، خوشهبندی نوعی تکنیک یادگیری نظارت نشده است که دادههای بدون برچسب را بر اساس شباهتها و تفاوتهایشان گروهبندی میکند. از جمله کاربردهای خوشهبندی میتوان به موارد زیر اشاره کرد:
- «بخشبندی بازار» (Market Segmentation): بهطور معمول، تیمهای بازاریابی علاقه دارند تا خریداران احتمالی را بر اساس نیازهای مشترک در گروههای مختلف طبقهبندی کنند. به این شکل و با درک ویژگیهای مشترک، کسبوکارها محصولات خود را در راستای نیاز مشتری قرار داده و برنامهریزی دقیقتری ارائه میدهند.
- «تحلیل شبکههای اجتماعی» (Social Network Analysis): کسبوکارها با پیادهسازی الگوریتمهای خوشهبندی بر روی دادههای حاصل از شبکههای اجتماعی، اهداف و تصمیمات تجاری آینده خود را شناسایی میکنند.
- «بخشبندی تصاویر» (Image Segmentation): بخشبندی تصاویر دیجیتال، با هدف سادهسازی و راحتتر شدن فرایند تجزیه و تحلیل انجام میشود.
- «موتورهای توصیهگر» (Recommendation Engines): الگوریتمهای خوشهبندی ارتباط میان رفتار گذشته کاربر را با گرایشهای نو پیدا کرده و به استراتژیهای فروش بهینهتری منجر میشوند.
چگونه فرق خوشه بندی و طبقه بندی را یاد بگیریم؟

برای شروع، ابتدا باید تفاوت اساسی بین طبقهبندی و خوشهبندی در یادگیری ماشین را درک کنید. در طبقهبندی، هدف تخمین کلاس یا برچسب دستهای برای یک نمونه داده است، در حالی که در خوشهبندی، دادهها به گروههای مشابه بدون اطلاع از برچسبها تقسیم میشوند. پس از درک تفاوتها، به مفاهیم پایه یادگیری ماشین بپردازید. از جمله این موارد میتوان به درخت تصمیم و الگوریتمهای خوشهبندی مانند K-Means اشاره کرد.. سپس، با مطالعه موارد کاربردی هر روش در مسائل واقعی، آشنایی بیشتری با آنها پیدا کنید.
در مرحله بعدی، با مطالعه مفاهیم پیشرفتهتر و الگوریتمهای متنوعتر در هر دو حوزه، مانند روشهای تقویت شده طبقهبندی یا الگوریتمهای خوشهبندی سلسلهمراتبی، توانمندیهای بیشتر ماشین یادگیری را یاد بگیرید. در نهایت، با استفاده از فیلمهای آموزشی مرتبط با یادگیری ماشین در فرادرس، میتوانید مفاهیم را به طور کامل درک کنید و به کاربردهای عملی آنها در زمینههای مختلف پی ببرید.
میتوانید فیلم های آموزشی مرتبط با طبقهبندی و خوشهبندی در یادگیری ماشین را از لینکهای زیر در فرادرس بررسی کنید.
- آموزش یادگیری ماشین
- آموزش کاربردی شبکه های عصبی مصنوعی – طبقه بندی، پیش بینی و ترکیب با الگوریتم های تکاملی
- آموزش طبقه بندی و بازشناسی الگو با شبکه های عصبی LVQ در متلب MATLAB
- آموزش تخمین خطای طبقه بندی یا کلاسیفایر در داده کاوی
- آموزش خوشه بندی با الگوریتم های تکاملی و فراابتکاری
- آموزش خوشه بندی سلسله مراتبی در آر R
- آموزش خوشه بندی K میانگین K-Means با اس پی اس اس SPSS
- آموزش داده کاوی Data Mining در متلب MATLAB
انواع الگوریتم های خوشه بندی
پس از معرفی الگوریتمهای طبقهبندی و پیش از آنکه به تفاوت طبقه بندی و خوشه بندی بپردازیم، بهتر است ابتدا با انواع الگوریتمهای خوشهبندی نیز آشنا شویم. در این بخش، به بررسی چند مورد از کاربردیترین الگوریتمهای خوشهبندی میپردازیم.

الگوریتم خوشه بندی K میانگین
از الگوریتم «K میانگین» (K-Means) به عنوان یکی از محبوبترین و مورد استفادهترین روشها در مسائل خوشهبندی یاد میشود. الگوریتمی «مبتنیبر مرکز» (Centroid-based) و تکرارپذیر که به خوشههایی غیر همپوشان ختم میشود.
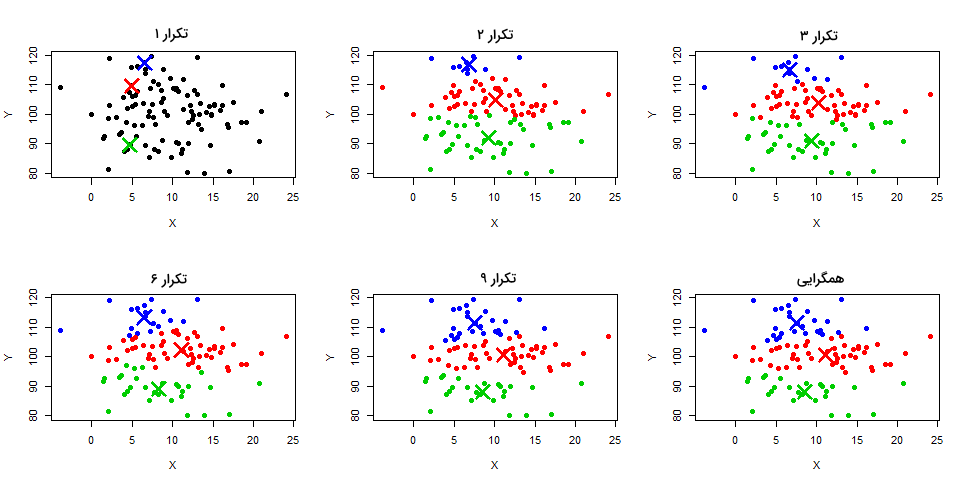
الگوریتم خوشه بندی سلسله مراتبی
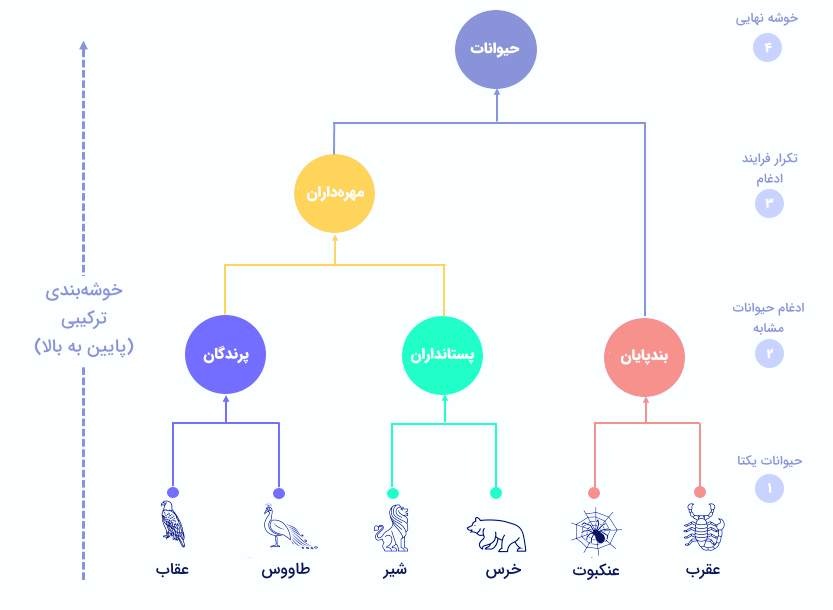
ساخت سلسلهای از خوشهها، راهی دیگر برای انجام عمل خوشهبندی است. الگوریتم «خوشهبندی سلسله مراتبی» (Hierarchical Clustering) که پیشتر نیز در مجله فرادرس توضیح داده شد، از دو نوع «ترکیبی» (Agglomerative) و «تقسیمی» (Divisive) تشکیل میشود.
روش ترکیبی
رویکردی پایین به بالا که در مرحله شروع، هر نمونه به عنوان یک خوشه مجزا در نظر گرفته میشود. همزمان با تکمیل شدن ساختار سلسله مراتبی از پایین به بالا، نمونهها با یکدیگر ادغام شده و در نهایت، جفت نمونهها به یک خوشه تبدیل میشوند.
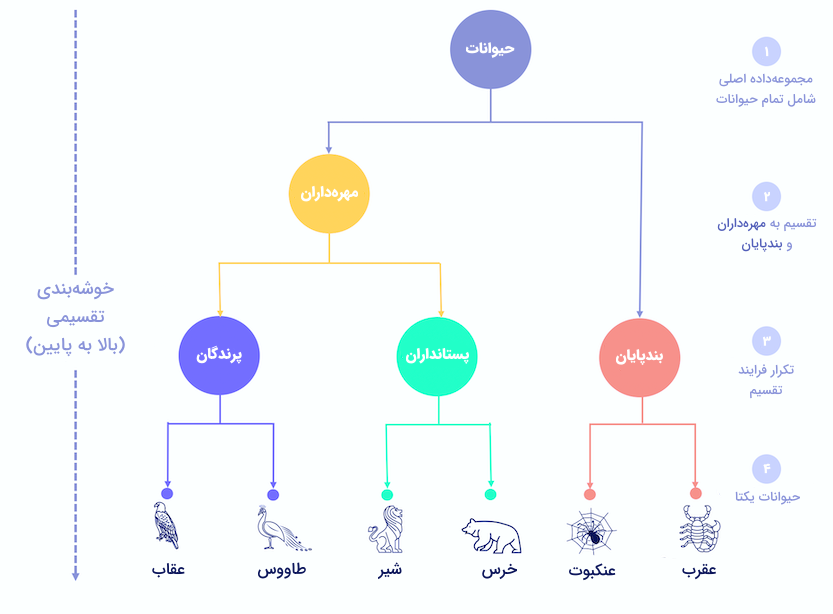
روش تقسیمی
خوشهبندی تقسیمی، نوعی روش بالا به پایین است که ابتدا تمامی نمونهها در یک خوشه قرار دارند و سپس در هر مرحله بهصورت بازگشتی، خوشهها تقسیم شده و ساختار سلسله مراتبی از بالا به پایین شکل میگیرد.
الگوریتم DBSCAN
در واقع، DBSCAN مخفف عبارت (Density Based Spatial Clustering of Applications with Noise) و به معنی خوشهبندی فضایی مبتنیبر چگالی برای کاربردهایی است که با دادههای نویزی سر و کار دارند. پایداری و مقاومت الگوریتم DBSCAN نسبت به دادههای پَرت یا Outliers از جمله مزیتهای کلیدی آن محسوب میشود. روشی که در دسته الگوریتمهای خوشهبندی «مبتنیبر چگالی» (Density-based) قرار میگیرد. نحوه کار الگوریتم DBSCAN به این صورت است که هر ناحیه متراکم را خوشهای در نظر میگیرد که بهوسیله نواحی با چگالی پایین، از دیگر خوشهها جدا شده است. برخلاف K-Means، در الگوریتم DBSCAN، تعداد خوشهها از دادهها استنباط شده و محدودیتی نیز برای شکل خوشهها وجود ندارد. در نتیجه، نیازی به مشخص کردن تعداد خوشهها به عنوان یک پارامتر نیست.

الگوریتم OPTICS
نام الگوریتم OPTICS مخفف عبارت (Ordering Points to Identify the Clustering Structure) به معنی مرتبسازی نقاط داده برای شناسایی ساختار خوشهبندی است. مانند DBSCAN، روش OPTICS نیز الگوریتمی مبتنیبر چگالی است که توسط همان تیم تحقیقاتی توسعه داده شده است. هدف الگوریتم OPTICS، برطرف کردن مهمترین چالش DBSCAN، یعنی شناسایی خوشهها صرفنظر از میزان تراکم و فرضیه ثابت بودن چگالی دادهها میباشد.

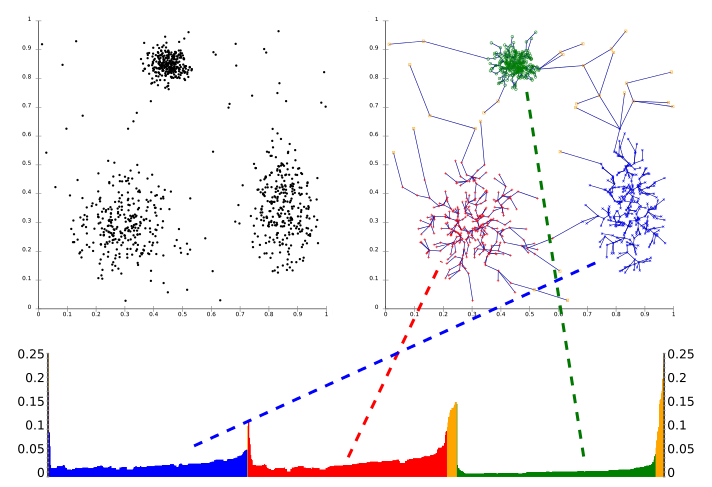
توجه داشته باشید که «نمودار دسترسپذیری» (Reachability Plot) در تصویر بالا نشانگر فاصله هر نمونه تا مرکز خوشه است.
تفاوت طبقه بندی و خوشه بندی
بررسی تفاوت طبقه بندی و خوشه بندی نیازمند آشنایی و بهدست آوردن درک اولیه از انواع الگوریتمهای این دو روش است که در بخشهای قبلی این مطلب به آنها پرداختیم. در ادامه، به شرح تفاوت طبقه بندی و خوشه بندی از سه جنبه مهم میپردازیم.
۱. یادگیری نظارت شده و نظارت نشده
طبقهبندی، نوعی روش یادگیری نظارت شده است. یادگیری نظارت شده شامل یادگیری تابعی است که بر اساس آموختههای قبلی، یک ورودی را به خروجی متناظر نگاشت میکند. در مقابل، یادگیری نظارت نشده از تکنیکهایی همچون خوشهبندی، برای کشف الگوهای پنهان در دادههای بدون برچسب بهره میبرد.
۲. نیاز به داده های آموزشی و آزمایشی
هم طبقهبندی و هم خوشهبندی برای یادگیری روابط میان دادهها به مجموعه آموزشی نیاز دارند. با این حال، بهتر است برای ارزیابی عملکرد مدل یادگیری ماشین در مسائل طبقهبندی، از مجموعهداده آزمایشی نیز استفاده شود.

۳. تفاوت های الگوریتمی
الگوریتمهای خوشهبندی برای بهدست آوردن اطلاعات، به دادههای ورودی مدل یادگیری ماشین وابسته هستند. به بیان سادهتر، معلمی وجود ندارد که پاسخهای درست را به الگوریتم برساند؛ بلکه یادگیری توسط الگوریتم صورت میگیرد. اما الگوریتمهای طبقهبندی برای بهدست آوردن مدل یادگیری و در ادامه پیشبینی خروجی نمونههای جدید، به جفت دادههای ورودی و خروجی نیاز دارند. در جدول زیر، خلاصهای از تفاوت طبقه بندی و خوشه بندی را مشاهده میکنید:
| طبقهبندی | خوشهبندی | |
| نوع یادگیری | نظارت شده | نظارت نشده |
| نوع دادهها | برچسبگذاری شده | بدون برچسب |
| هدف | تخمین تابعی که با یادگیری مجموعهای از ورودیها با خروجی گسسته، در پیشبینی خروجی نمونههای جدید مورد استفاده قرار میگیرد. | یادگیری الگوهای پنهان ورودی، بهمنظور گروهبندی دادههای مختلف. |
| الگوریتمها | رگرسیون لجستیک، KNN، درخت تصمیم، جنگل تصادفی، بیز ساده | K-Means، خوشهبندی ترکیبی، خوشهبندی تقسیمی، DBSCAN، OPTICS |
| کاربردها | پیشبینی نرخ ریزش مشتری، پذیرش وام، پالایش اسپم، تشخیص چهره | بخشبندی بازار، بخشبندی تصاویر، تحلیل شبکههای اجتماعی، موتورهای توصیهگر |
سوالات متداول پیرامون تفاوت طبقه بندی و خوشه بندی
پس از آشنایی با انواع الگوریتمها و تفاوت طبقه بندی و خوشه بندی، حال زمان خوبی است تا در این بخش، به چند مورد از پرسشهای متداول در این زمینه پاسخ دهیم.

چه زمان باید به جای خوشه بندی از طبقه بندی استفاده شود؟
از طبقهبندی زمانی استفاده میشود که گروه یا کلاسهایی برای دستهبندی دادهها از پیش تعریف شده باشند. این در حالی است که هدف خوشهبندی در شناسایی الگو یا گروهبندی دادهها خلاصه میشود.
کدام یک در تحلیل داده دقیق تر عمل می کند؛ طبقه بندی یا خوشه بندی؟
بهطور پیشفرض، هیچکدام از این دو روش از دیگری دقیقتر نبوده و انتخاب تکنیک مناسب، به نوع مسئله و مجموعهداده بستگی دارد. همچنین کیفیت دادهها، نقش مهمی در دقت نتایج نهایی ایفا میکند.
در چه مسائلی از الگوریتم های طبقه بندی و خوشه بندی استفاده میشود؟
بخشبندی مشتریان، بازشناسی تصویر، تشخیص کلاهبرداری و طبقهبندی متن، از جمله رایجترین کاربردهای الگوریتمهای طبقهبندی و خوشهبندی به حساب میآیند.
جمعبندی
با وجود یکسان بودن هدف نهایی، دو رویکرد طبقهبندی و خوشهبندی روش منحصربهفرد خود را برای جداسازی نمونه دادهها در گروههای مجزا دارند. همانطور که در این مطلب از مجله فرادرس خواندیم، الگوریتمهای طبقهبندی برای مورد استفاده قرار گرفتن در کاربردهایی همچون پالایش ایمیلهای اسپم و پیشبینی نرخ ریزش مشتری، به دادههای برچسبگذاری شده نیاز دارند. از طرفی دیگر، خوشهبندی نیازی به چنین راهنماییهایی نداشته و به شیوهای اکتشافی، کاربرد خود را در مسائلی مانند بخشبندی بازار یا سیستمهای توصیهگر پیدا میکند. داشتن درکی مناسب از تفاوت طبقه بندی و خوشه بندی، تاثیر بهسزایی بر کارآمدی پروژههای یادگیری شما خواهد گذاشت.







