



درخت تصمیم در یادگیری ماشین – به زبان ساده + نمونه کد
«درخت تصمیم» (Decision Tree) یک روش رایج برای نشان دادن فرآیند تصمیمگیری به وسیله ساختاری درختمانند و شاخهدار است. این روش یکی از رویکردهای «دستهبندی» (Classification) و «رگرسیون» (Regression) در «یادگیری ماشین» (Machine Learning) به حساب میآید. از آنجایی که روشهای «هوش مصنوعی» (Artificial Intelligence) و یادگیری ماشین در پروژههای امروزی استفاده بسیاری دارند، بنابراین یادگیری روشهای دستهبندی آنها ازجمله درخت تصمیم در یادگیری ماشین میتواند کمک بسیاری در روند حل این مسائل داشته باشد. در این نوشتار سعی شده است به طور جامع به تعریف و شرح مفاهیم درخت تصمیم در یادگیری ماشین پرداخته شود و همچنین انواع آن مورد بررسی قرار بگیرند.



درخت تصمیم معمولاً برای برنامهریزی و ترسیم تصمیمهای عملیاتی در کسب و کارها به عنوان «نمودار» یا همان «فلوچارت بصری» (Visual Flowchart) نیز استفاده میشود. این روش، شاخهای از تصمیمها را نشان میدهد که انتهای هر شاخه نتیجه نهایی آن بهدست میآید. این شاخهها باعث ایجاد یک ساختار یا نمایش درختی میشوند. اولین بخش از این مقاله به بررسی درخت تصمیم در یادگیری ماشین اختصاص دارد.
درخت تصمیم در یادگیری ماشین چیست ؟
درخت تصمیم، روشی در یادگیری ماشین برای ساختاربندی (یا شکلدهی یا سازماندهی) به الگوریتم است. یک الگوریتم درخت تصمیم برای تقسیم ویژگیهای «مجموعه داده» (Data Set) از طریق «تابع هزینه» (Cost Function) مورد استفاده قرار میگیرد. این الگوریتم قبل از انجام بهینهسازی و حذف شاخههای اضافه، به گونهای رشد میکند که دارای ویژگیهای نامرتبط با مسئله است؛ به همین دلیل، عملیات «هرس کردن» (Pruning) برای حذف این شاخههای اضافه در آن انجام میشود. در الگوریتم درخت تصمیم، پارامترهایی ازجمله عمق درخت تصمیم را نیز میتوان تنظیم کرد تا از «بیشبرازش» (Overfitting) یا «پیچیدگی بیش از حد درخت» (Overly Complex Tree) تا جای امکان جلوگیری شود.
انواع بسیاری از درختهای تصمیم در یادگیری ماشین برای مسئلههای دستهبندی و گروهبندی (Classification) اشیا بر اساس ویژگیهای آموزش داده شده، استفاده میشوند. همچنین این روش میتواند در مسائل رگرسیون (Regression) یا روشی برای پیشبینی نتایج پیوسته دادههای دیده نشده، مورد استفاده قرار بگیرد. مزیت اصلی استفاده از یادگیری ماشین در پروژهها، سادگی آن است؛ زیرا با استفاده از آن، فرآیند تصمیمگیری به راحتی قابل تجسم و درک خواهد شد. با این حال، در مسائل یادگیری ماشین با افزایش تعداد شاخههای درخت تصمیم، ممکن است درک و استفاده از آن به دلیل پیچیدگی بیش از حد درخت، چالش برانگیز شود؛ بنابراین، هرس کردن درخت در چنین شرایطی بسیار ضروری بهنظر میرسد.
به طور کلی درخت تصمیم روشی برای مدلسازی تصمیمها، خروجی آنها و همچنین نگاشت تصمیمها در ساختاری درختی است. این الگوریتم روشی برای محاسبه پتانسیل موفقیت دنبالهای مختلف تصمیمگیری در دستیابی به یک هدف خاص به حساب میآید. مفهوم درخت تصمیم به تنهایی و قبل از ورود آن به یادگیری ماشین نیز وجود داشته است؛ زیرا میتوان از آن برای تصمیمهای عملیاتی مدلها به صورت دستی، مانند یک فلوچارت، استفاده کرد. آنها معمولاً در بخشهای کسب و کار، اقتصاد و مدیریت عملیات در نقش رویکردی برای تجزیه و تحلیل تصمیمگیریهای سازمانی استفاده میشوند.
درخت تصمیم در قالب مدلسازی پیشبینی کننده، به نگاشت تصمیمها یا راهحلهای مختلف برای به دست آوردن خروجی کمک میکند. درخت تصمیم از «گرههای» (Node) مختلفی ایجاد شده است. «گره ریشه» (Root Node) محل شروع درخت تصمیم به حساب میآید که معمولاً تمام مجموعه داده مسئله را شامل میشود. «گرههای برگ» (Leaf Node) نقطه پایانی هر شاخه درخت یا خروجی نهایی مجموعهای از تصمیمها هستند. هر شاخه درخت تصمیم در یادگیری ماشین فقط دارای یک گره برگ است.
در درخت تصمیم یادگیری ماشین ، ویژگی دادهها در گرههای داخلی شاخهها و نتیجه آنها در برگ هر شاخه نشان داده میشود. به دلیل اینکه درخت تصمیم در یادگیری ماشین ، ساختار سادهای در نشان دادن یک مدل دارد، در این حوزه بسیار محبوب شده است. ساختار درختمانند این الگوریتم باعث ساده شدن درک فرآیند تصمیمگیری در پردازشها میشود.
«توضیحپذیری» در یادگیری ماشین به عنوان فرآیندی جهت توضیح خروجی یک مدل برای انسانها، بخش مهمی از پروژهها به حساب میآید و این فرایند را میتوان در درخت تصمیم به خوبی پیادهسازی کرد. یکی از بخشهایی که یادگیری ماشین را قدرتمند میکنند، بهینهسازی وظایف، بدون دخالت و کنترل مستقیم انسان است؛ اما اغلب توضیح خروجی مدل دشوار میشود. دلیل استفاده از فرآیند تصمیمگیری زمانی مشخص میشود که مدل از ساختار درختی استفاده کند؛ زیرا هر تصمیم را میتوان در قالب یک شاخه نشان داد. در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به طور خلاصه برخی از اصطلاحات مهم مرتبط با درخت تصمیم شرح داده شدهاند.
اصطلاح های مهم درخت تصمیم کدامند؟
در بخش قبلی به طور پراکنده و ضمنی به برخی از اصطلاحهای درخت تصمیم اشاره شد؛ اما در این بخش هر کدام از اصطلاحهای مهم درخت تصمیم فهرست شدهاند و شرح مختصری برای هر یک ارائه شده است تا همه این اصطلاحها بهطور یکجا و بهصورت سازمانیافتهتر در دسترس باشند:
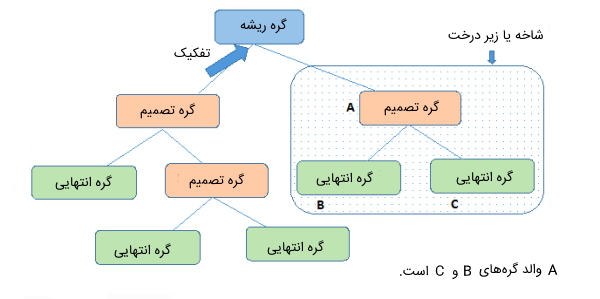
- «گره ریشه» (Root Node): این گره نشاندهنده تمام مجموعه داده مسئله است و میتواند به دو یا چند مجموعه «همگن» (Homogeneous) تقسیم شود. گره ریشه اولین و بالاترین گره درخت تصمیم به حساب میآید.
- «تفکیک» (Splitting): تفکیک یا همان تقسیمبندی به پردازشی برای تقسیم کردن گرهها به دو یا چند «زیر گره» (Sub-Node) دیگر گفته میشود.
- «گره تصمیم» (Decision Node): هنگامی که یک زیر گره به چند زیر گره دیگر تقسیم میشود، به آن گره تصمیم میگویند.
- «گره برگ یا گره انتهایی» (Leaf | Terminal Node): گرههای انتهایی هر شاخه که دیگر قابلیت تفکیک ندارند، گره برگ یا گره انتهایی نامیده میشوند.
- «هرس کردن» (Pruning): گاهی نیاز است که بخشهایی از درخت حذف شوند. زمانی هرس کردن انجام میشود که لازم باشد زیرگرههایی از گره تصمیم نیاز به حذف داشته باشند. به عبارتی، میتوان گفت هرس کردن عملیاتی مخالف عملیات تفکیک است.
- «شاخه یا زیر درخت» (Branch | Sub-Tree): به تمام زیربخشهای درخت تصمیم، شاخه یا زیر درخت گفته میشود.
- «گره والد و فرزند» (Parent and Child Node): گرهای که به زیر گرههای دیگر تقسیم میشود، گره والد زیر گرهها نام دارد و این زیر گرههای ایجاد شده فرزند، گره والد نامیده میشوند.
در تصویر زیر، مفاهیم و اصطلاحات فهرست شده در بالا پیرامون درخت تصمیم نشان داده شدهاند:
در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی مراحل و روش عملکرد درخت تصمیم پرداخته شده است.
درخت تصمیم چگونه کار می کند؟
در درخت تصمیم برای پیشبینی کلاسهای مورد نظر مجموعه داده مسئله، رویکرد الگوریتم از گره ریشه درخت آغاز میشود. این الگوریتم، مقادیر ویژگیهای ریشه را با ویژگیهای دادهها مقایسه و بر اساس این مقایسه، شاخهها را دنبال میکند و به گره بعدی میرود. برای گره بعدی، الگوریتم دوباره مقدار ویژگی دادهها را با زیر گرههای دیگر مقایسه میکند و روند ایجاد درخت را پیش میبرد. این رویکرد تا رسیدن به گره برگ یا گره انتهایی درخت ادامه پیدا میکند. فرآیند کامل روش کار کردن درخت تصمیم را میتوان با ارائه آن به صورت الگوریتم زیر بهتر درک کرد:
- مرحله اول: شروع روند کار الگوریتم درخت تصمیم از گره ریشه آغاز میشود که شامل مجموعه داده کامل مسئله است.
- مرحله دوم: با استفاده از روش «سنجیدن انتخاب ویژگی» (Attribute Selection Measure | ASM) بهترین ویژگی در مجموعه داده انتخاب میشود.
- مرحله سوم: تقسیم کردن گره ریشه به زیرمجموعههایی که شامل مقادیر مناسب و ممکن برای بهترین ویژگیها باشند.
- مرحله چهارم: تولید گره درخت تصمیمی که شامل بهترین ویژگیها باشد.
- مرحله پنجم: با استفاده از زیرمجموعههای ایجاد شده از مجموعه داده در مرحله سوم این رویکرد، درختهای تصمیم جدید به صورت بازگشتی ایجاد میشوند. این روند تا جایی ادامه دارد که دیگر نمیتوان گرهها را بیشتر طبقهبندی کرد و گره نهایی به عنوان گره برگ یا انتهایی به دست میآید.
در ادامه این بخش از مقاله «درخت تصمیم در یادگیری ماشین»، مثالی برای درک بهتر نحوه عملکرد درخت تصمیم ارائه شده است.
مثالی برای نحوه عملکرد درخت تصمیم
در این مثال فرض میشود فردی وجود دارد که یک پیشنهاد شغلی دارد و قصد انجام بررسیهای لازم را برای انتخاب یا عدم انتخاب این موقعیت شغلی دارد. بنابراین برای حل این مسئله، رویکرد الگوریتم درخت تصمیم با گره ریشه آغاز و ویژگی «حقوق» با استفاده از روش سنجیدن انتخاب ویژگی در آن مشخص میشود. برای حل مسئله و پیش رفتن بیشتر آن، گره ریشه به گره تصمیم بعدی یعنی همان گره مربوط به ویژگی «فاصله از شرکت» و یک گره برگ بر اساس برچسبهای مربوطه برای رد درخواست پیشنهاد شغلی تقسیم میشود.
گره تصمیم بعدی به یک گره تصمیم برای امکانات سازمان و یک گره برگ دیگر برای رد درخواست پیشنهاد شغلی تقسیم شده است. در نهایت، گره تصمیم به دو گره برگ یعنی «پذیرش پیشنهاد شغلی» و «رد پیشنهاد شغلی» تقسیم میشود. دیاگرام زیر نشاندهنده این توضیحات در رابطه با مثال انتخاب شغل پیشنهادی با استفاده از درخت تصمیم است:
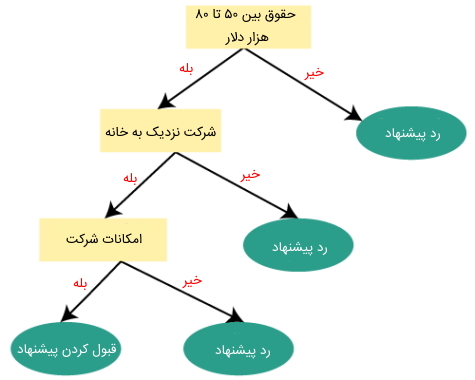
در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی روش سنجش انتخاب ویژگی پرداخته شده است.
روش سنجش انتخاب ویژگی درخت تصمیم در یادگیری ماشین چیست؟
در زمان پیادهسازی درخت تصمیم ، یکی از مهمترین و اساسیترین مسائلی که پیش میآید این است که بهترین ویژگی برای گره ریشه و گرههای فرعی دیگر چگونه انتخاب شود؟ بنابراین برای حل چنین مسائلی، روشی وجود دارد که به آن «معیار یا سنجش انتخاب ویژگی» (Attribute Selection Measure) یا «ASM» گفته میشود. با این روش میتوان به راحتی بهترین ویژگی را برای گره ریشه و دیگر گرههای درخت انتخاب کرد. روش سنجش انتخاب ویژگی دارای دو رویکرد رایج به نامهای زیر است:
- «بهره اطلاعاتی» (Information Gain)
- «شاخص جینی» (Gini Index)
در ادامه به بررسی هر کدام از این دو مورد فوق پرداخته شده است.
بهره اطلاعاتی در درخت تصمیم چیست؟
بهره اطلاعاتی به وسیله سنجش تغییرات آنتروپی پس از تقسیمبندی یک مجموعه داده بر اساس ویژگیها انجام میشود. در این روش محاسبه میشود که یک ویژگی چه مقدار اطلاعات درباره یک کلاس میدهد؟ طبق مقادیر اطلاعات به دست آمده، گرهها تقسیم میشوند و درخت تصمیم ساخته خواهد شد. الگوریتم درخت تصمیم همیشه تا حد امکان سعی خود را در به حداکثر رساندن اطلاعات به دست آمده میکند و سپس، ابتدا آن گره ویژگی را تقسیم میکند که بیشترین اطلاعات را دارد. رابطه این روش یعنی فرمول بهدست آوردن اطلاعات در ادامه نمایش داده شده است:
آنتروپی معیاری برای اندازهگیری ناخالصی در یک ویژگی مشخص است. همچنین تصادفی بودن دادهها را نیز مشخص میکند. این معیار با استفاده از رابطه زیر برای مثال فوق محاسبه میشود:
در رابطه فوق، S تعداد همه نمونهها را در مسئله نشان میدهد. (yes)P نشاندهنده احتمال وقوع «بله» و (no)P نشاندهنده احتمال وقوع «خیر» است. در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی و شرح شاخص جینی پرداخته میشود.
شاخص جینی در درخت تصمیم چیست؟
شاخص جینی معیاری از ناخالصی به خلوص ویژگیها است که هنگام ایجاد درخت تصمیم در الگوریتم CART یا همان «درخت دستهبندی و رگرسیون» (Classification and Regression Tree) استفاده میشود. ویژگی با میزان شاخص جینی پایین در مقایسه با شاخص جینی بالا در درخت تصمیم ترجیح داده و انتخاب خواهد شد. از این شاخص فقط برای ایجاد دسته و گروههای باینری استفاده میشود، همچنین الگوریتم CART نیز از شاخص جینی برای ایجاد دستههای باینری استفاده میکند. شاخص جینی به وسیله رابطه زیر محاسبه میشود:
در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به روش چگونگی نمایش یک الگوریتم به صورت درخت پرداخته شده است.
چگونه یک الگوریتم مانند درخت نمایش داده می شود؟
برای توصیف اینکه چگونه یک الگوریتم را میتوان به وسیله درخت نمایش داد، در این بخش مثال سادهای در نظر گرفته شده است. در این مثال از مجموعه داده مسافران کشتی تایتانیک برای پیشبینی اینکه آیا فردی زنده میماند یا خیر، استفاده میشود. در مدل زیر از سه «ویژگی» (Feature | Attribute) یا «ستون» (Column) مجموعه داده با نامهای جنسیت، سن، تعداد همسر و فرزندان استفاده شده است.
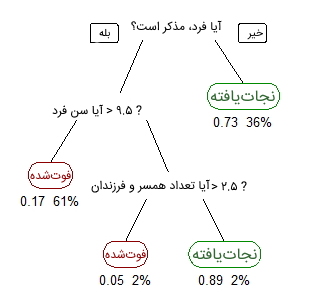
تصویر فوق، نشاندهنده یک درخت تصمیم همراه با ریشه و چندین شاخه است. در بالای تصویر، متن نوشته شده با رنگ مشکی، یک شرط یا گره داخلی را نشان میدهد و بر اساس آن، درخت به شاخههای مختلف تقسیم میشود. انتهای شاخهای که دیگر تقسیم نمیشود، تصمیم یا برگ وجود دارد. در این مثال، فوتشده یا زنده ماندن مسافر، به ترتیب با رنگهای قرمز و سبز نوشته شدهاند. اگرچه، یک مجموعه داده واقعی دارای تعداد بالایی ویژگی (Feature) است و ترسیم درخت تصمیم آن باعث ایجاد درختی بزرگ همراه با تعداد زیادی شاخه میشود، با این حال نمیتوان از سادگی و قابل فهم بودن الگوریتم درخت تصمیم چشمپوشی کرد.
در این درخت تصمیم، اهمیت ویژگیها در مجموعه دادهها قابل درک است و رابطه بین ویژگیها به راحتی مشخص میشود. این روش بیشتر به عنوان درخت تصمیم یادگیری دادهها شناخته شده است. درخت تصویر فوق یک درخت دستهبندی به حساب میآید؛ زیرا هدف این مسئله، دستهبندی مسافرها در دو گروه مرده و زنده است. درخت رگرسیون نیز با همین روش فوق نشان داده میشود، با این تفاوت که مقادیر پیوسته ازجمله قیمت مسکن را نشان میدهد. به طور کلی میتوان گفت که درختهای تصمیم در یادگیری ماشین به عنوان الگوریتمهای «CART» شناخته میشوند. CART سرنامی برای عبارت «Classification and Regression Tree» به معنی «درخت دستهبندی و رگرسیون» است.
از آنجایی که گاهی برخی از درختان به اندازه زیادی بزرگ میشوند؛ با روشهای رایجی باید آنها را به بخشهای کوچکتری تعدیل کرد. در ادامه به بررسی برخی از این روشها پرداخته شده است. ابتدا بخش بعدی به تقسیم باینری بازگشتی اختصاص دارد.
تقسیم باینری بازگشت درخت تصمیم چیست؟
در این روش برای تقسیم بخشهای گوناگون درخت جهت کاهش ابعاد آن، تمام ویژگیهای در نظر گرفته شده و نقاط تقسیم مختلف با استفاده از تابع هزینه بررسی میشوند. تقسیم با بهترین هزینه یا همان کمترین هزینه در این روش انتخاب شده است. با توجه به مثالی که در بخش قبلی برای مجموعه داده مسافران ارائه شد، در «انشعاب» (Split) اول یا همان ریشه درخت، همه ویژگیها در نظر گرفته شدهاند و دادههای آموزشی براساس این ریشه به گروههایی تقسیم میشوند. در این مثال سه ویژگی وجود دارد، بنابراین سه کاندید برای ایجاد انشعاب و تقسیمبندی جدید میتوان در نظر گرفت. حال با استفاده از یک تابع، محاسبه میشود که دقت به دست آمده برای هر بخش چقدر است.
سپس، کمهزینهترین بخش انتخاب میشود که در این مثال، بخش جنسیت مسافران است. همچنین میتوان گفت که این الگوریتم ماهیتی بازگشتی دارد؛ زیرا گروههای تشکیل شده را میتوان با استفاده از یک استراتژی ساده به گروههای کوچکتر تقسیم کرد. با این تفسیرها، این روش به عنوان «الگوریتم حریصانه» (Greedy Algorithm) نیز شناخته میشود، زیرا در این الگوریتم تمایل زیادی برای کاهش هزینهها وجود دارد. این موارد باعث میشود که گره ریشه به عنوان بهترین پیشبینی کننده یا «دسته بند» (Classifier) در نظر گرفته شود. در بخش بعدی به بررسی هزینه تقسیم در درخت تصمیم پرداخته شده است.
هزینه تقسیم برای درخت تصمیم چقدر است؟
در این بخش به صورت عمیقتری به بررسی «تابع هزینهای» (Cost Function) پرداخته میشود که برای مسائل دستهبندی و رگرسیون مورد استفاده قرار میگیرد. در هر دو نوع این مسائل، تابع هزینه سعی دارد تا شاخههای «همگن» یا شاخههایی با گروههایی از ویژگیها با نتایج مشابه را پیدا کند. رابطه تابع هزینه برای مسائل رگرسیون به صورت زیر است:
برای مثال، در اینجا هم مسئله پیشبینی قیمت مسکن در نظر گرفته شده است. حال در این بخش، درخت تصمیم براساس در نظر گرفتن هر ویژگی در دادههای آموزشی شروع به تقسیم میکند. میانگین نتایج ورودی دادههای آموزشی یک گروه خاص به عنوان پیشبینی برای آن گروه در نظر گرفته میشود. تابع فوق برای همه نقاط داده اعمال خواهد شد و با استفاده از آن هزینه برای همه کاندیدهای تقسیمبندی محاسبه میشود. مجدداً در این بخش نیز آن انشعابی انتخاب شده است که کمترین هزینه را دارد. در مسائل دستهبندی، رابطه زیر مورد استفاده قرار میگیرد:
یک «نمره جینی» (Gini Score) ایدهای از میزان خوب و مناسب بودن یک تقسیم را توسط ترکیب پاسخ و نتایج کلاسها در گروههای ایجاد شده با تقسیمبندی ارائه میدهد. در این رابطه، پارامتر pk نشاندهنده مقدار ورودیهای کلاس یکسان موجود است. یک کلاس عالی زمانی ایجاد میشود که یک گروه شامل همه ورودیهای کلاس باشد. در این حالت، مقدار pk یا صفر یا یک و G = 0 است.
در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی روش چگونگی متوقف کردن تقسیم شدن انشعابهای درخت پرداخته میشود.

چه زمانی تقسیم شدن انشعاب های درخت تصمیم متوقف می شوند؟
از آنجایی که معمولاً یک مسئله دارای مجموعه داده بزرگی است و این حجم بالای دادهها باعث ایجاد تعداد تقسیمبندی و انشعابهای بالایی میشود، درخت بزرگ و پیچیدهای به وجود میآید. چنین درختانی باعث ایجاد بیشبرازش خواهند شد، بنابراین زمان توقف تقسیم شاخههای درخت باید بررسی و مشخص شود. روشهای جلوگیری از بیشبرازش در این حالت و زمان توقف تقسیمبندی شاخههای درخت تصمیم در ادامه ارائه شدهاند:
- یکی از روشهای انجام این کار، تنظیم حداقل تعداد ورودیهای آموزشی برای استفاده در هر برگ است. برای مثال فقط میتوان ۱۰ مسافر برای تصمیمگیری در مسئله زنده یا مرده بودن استفاده کرد و هر برگی با کمتر از ۱۰ مسافر را نادیده گرفت.
- روش دیگر، تنظیم حداکثر عمق مدل است. حداکثر عمق به طول طولانیترین مسیر از یک رشته تا یک برگ اشاره دارد.
هرس کردن درخت تصمیم چیست؟
کارایی درخت تصمیم در یادگیری ماشین میتواند با استفاده از روشهای هرس کردن افزایش پیدا کند. هرس کردن به معنی حذف شاخههایی است که دارای ویژگیهایی با اهمیت کمتر در هدف مسئله هستند. با استفاده از این روش میتوان پیچیدگی درخت را کاهش داد و سپس قدرت و دقت پیشبینی الگوریتم با کاهش بیشبرازش افزایش پیدا خواهد کرد. هرس کردن میتواند از ریشه یا برگها آغاز شود. در ادامه به بررسی برخی از روشهای هرس کردن درخت تصمیم پرداخته شده است:
- «هرس خطای کاهش یافته» (Reduced Error Pruning): این روش سادهترین نوع هرس کردن درخت تصمیم به حساب میآید و به این صورت است که از برگها شروع میشود و هر گره با محبوبترین کلاس را در برگ حذف میکند و این رویکرد تا زمانی ادامه دارد که دقت مسئله کاهش پیدا نکند.
- «هرس پیچیدگی هزینه» (Cost Complexity Pruning): هرس پیچیدگی هزینه، روش پیچیدهتری به حساب میآید که در آن میتوان از یک پارامتر یادگیری به نام «آلفا» برای سنجش چگونگی حذف گرهها بر اساس اندازه «زیر درختها» (Sub-Tree) استفاده کرد. این روش به عنوان «هرس ضعیفترین پیوند» (Weakest Link Pruning) نیز شناخته میشود.
در بخش بعدی این مقاله، پس از معرفی مجموعه دورههای آموزش داده کاوی و یادگیری ماشین، به بررسی انواع درخت تصمیم در یادگیری ماشین پرداخته شده است.
معرفی فیلم های آموزش داده کاوی و یادگیری ماشین فرادرس

دورههای آموزشی ویدیویی وب سایت فرادرس بر اساس موضوع به صورت مجموعههای آموزشی متفاوتی دستهبندی شدهاند. یکی از این مجموعههای جامع مربوط به دورههای آموزش داده کاوی و یادگیری ماشین است. علاقهمندان میتوانند از این مجموعه آموزشی برای مطالعه بیشتر یادگیری ماشین با انواع روشهای مختلف استفاده کنند. در زمان تدوین این مقاله، مجموعه دورههای داده کاوی و یادگیری ماشین فرادرس حاوی بیش از ۳۱۵ ساعت محتوای ویدیویی و حدود ۳۹ عنوان آموزشی مختلف بوده است. در ادامه این بخش، برخی از دورههای این مجموعه به طور خلاصه معرفی شدهاند:
- فیلم آموزش یادگیری ماشین Machine Learning با پایتون Python (طول مدت: ۱۰ ساعت، مدرس: مهندس سعید مظلومی راد): در این فرادرس سعی شده است، ابتدا بستههای شناخته شده پایتون معرفی و سپس کار با توابع آنها آموزش داده شوند. در انتها نیز مباحث یادگیری ماشین همراه با مثالهای متعدد در پایتون مورد بررسی قرار گرفتهاند. برای مشاهده فیلم آموزش یادگیری ماشین Machine Learning با پایتون Python + کلیک کنید.
- فیلم آموزش یادگیری عمیق با پایتون - تنسورفلو و کراس TensorFlow و Keras (طول مدت: ۲ ساعت و ۵۷ دقیقه، مدرس: دکتر سعید محققی): در این دوره آموزشی، تمرکز بر روی محبوبترین بسترهای نرم افزاری، پرکاربردترین کتابخانه کدنویسی ازجمله تنسورفلو و کراس و رایجترین مدلها و دادهها در زمینه یادگیری عمیق است. برای مشاهده فیلم آموزش یادگیری عمیق با پایتون - تنسورفلو و کراس TensorFlow و Keras + کلیک کنید.
- فیلم آموزش یادگیری عمیق - شبکه های GAN با پایتون (طول مدت: ۵ ساعت و ۶ دقیقه، مدرس: دکتر عادل قاضی خانی): در این دوره آموزشی شبکههای GAN معمولی، شبکههای Deep Convolutional GAN ،Semi-Supervised GAN ،Conditional GAN و CycleGAN بررسی میشوند. علاوه بر این، قبل از ورود به موضوع شبکههای GAN، مفاهیم مقدماتی مورد نیاز یادگیری ماشین و شبکههای عصبی بیان میشود. در این آموزش از زبان پایتون برای آموزش برنامه نویسی شبکههای GAN استفاده شده است. برای مشاهده فیلم آموزش یادگیری عمیق - شبکه های GAN با پایتون + کلیک کنید.
- فیلم آموزش پردازش زبان های طبیعی NLP در پایتون Python با پلتفرم NLTK (طول مدت: ۷ ساعت و ۱۲ دقیقه، مدرس: مهندس احسان یزدانی): در این فرادرس، زبان برنامه نویسی پایتون برای پردازش زبان طبیعی و مهمترین ابزار آن، یعنی NLTK آموزش داده شده است. برای مشاهده فیلم آموزش پردازش زبان های طبیعی NLP در پایتون Python با پلتفرم NLTK + کلیک کنید.
- فیلم آموزش کتابخانه scikit-learn در پایتون - الگوریتم های یادگیری ماشین (طول مدت: ۳ ساعت و ۵۷ دقیقه، مدرس: سید علی کلامی هریس): هدف این دوره آموزشی ویدویی، آموزش بخشی از الگوریتمهای یادگیری ماشین موجود در کتابخانه scikit-learn پایتون است. برای مشاهده فیلم آموزش کتابخانه scikit-learn در پایتون - الگوریتم های یادگیری ماشین + کلیک کنید.
- آموزش شبکه های عصبی پیچشی CNN - مقدماتی (طول مدت: ۲ ساعت و ۱۲ دقیقه، مدرس: سایه کارگری): از آنجایی که شبکههای عصبی پیچشی یکی از نیازهای اصلی علاقهمندان به پردازش تصویر و بینایی ماشین به حساب میآید، فراگیری مفاهیم این شبکهها از اهمیت بالایی برخوردار است و در این فرادرس به آنها پرداخته میشود. برای مشاهده آموزش شبکههای عصبی پیچشی CNN - مقدماتی + کلیک کنید.
حال پس از معرفی مجموعه دورههای آموزش داده کاوی و یادگیری ماشین فرادرس، بخش بعدی مقاله «درخت تصمیم در یادگیری ماشین» به بررسی انواع درخت تصمیم در یادگیری ماشین، اختصاص داده شده است.
انواع درخت تصمیم در یادگیری ماشین
دو نوع درخت تصمیم اصلی زیر در یادگیری ماشین وجود دارند که بر اساس هدف و رویکرد متغیرها ایجاد شدهاند:
- «درخت تصمیم متغیر گسسته» (Categorical Variable Decision Tree)
- «درخت تصمیم متغیر پیوسته» (Continuous Variable Decision Tree)
در ادامه این بخش از مقاله «درخت تصمیم در یادگیری ماشین» به شرح و بررسی هر یک از این موارد فوق پرداخته شده است. ابتدا بخش بعدی به توصیف درخت تصمیم متغیر گسسته اختصاص دارد.
درخت تصمیم متغیر گسسته چیست؟
همانطور که از نام این الگوریتم مشخص است، درخت تصمیم متغیر گسسته دارای متغیرهای گسستهای است که به گروههای مختلف دستهبندی میشوند. برای مثال، میتوان گروههایی را نام برد که با استفاده از پاسخ بله یا خیر از هم جدا و دستهبندی شدهاند. به عبارت دیگر میتوان گفت که هر بخش از فرآیند درخت تصمیم باید متعلق به یک گروه یا دسته باشد و هیچ گروه میانی وجود ندارد. در بخش بعدی از این مقاله به بررسی و شرح درخت تصمیم متغیر پیوسته پرداخته شده است.
درخت تصمیم متغیر پیوسته چیست؟
این درخت تصمیم دارای متغیرهای پیوسته است. برای مثال، اگر قصد مسئلهای به دست آوردن درآمد افراد باشد، میتوان درآمد را با استفاده از اطلاعات در دسترس دیگری ازجمله شغل، سن و سایر متغیرهای پیوسته دیگر پیشبینی کرد. بخش بعدی از این مقاله به بررسی انواع رویکردهای درخت تصمیم در یادگیری ماشین اختصاص دارد.

انواع رویکردهای درخت تصمیم در یادگیری ماشین کدامند؟
اکثر مدلهای یادگیری ماشین بخشی از دو رویکرد اصلی آن، یعنی «یادگیری نظارت شده» (Supervised Learning) و «یادگیری نظارت نشده» (Unsupervised Learning) هستند. تفاوت اصلی بین این دو رویکرد در شرایط دادههای آموزشی و مسئلهای است که مدل برای حل آن استفاده میشود. البته چند نوع یادگیری دیگر نیز وجود دارند که از محبوبیت کمتری نسبت به این دو نوع اصلی برخوردار هستند. در ادامه به برخی دیگر از تفاوتهای این دو نوع یادگیری همراه با مثال پرداخته شده است:
- یادگیری نظارت شده: مدلهای این نوع از یادگیری معمولاً با استفاده از مجموعه داده مشخصی که به الگوریتم هوش مصنوعی داده میشود، برای ارائه نتایج مورد نیاز، آموزش میبینند. به عبارت دیگر، یادگیری نظارت شده نوعی از یادگیری به حساب میآید که دارای مجموعه دادههای برچسبدار است. یادگیری نظارت شده به طور کلی برای دستهبندی اشیا یا دادهها در نرم افزاری با اهدافی مانند تشخیص چهره یا پیشبینی نتایج متوالی سهام استفاده میشوند.
- یادگیری نظارت نشده: در این نوع از الگوریتمها از مجموعه دادههایی استفاده میشود که برچسب ندارند. روش طبقهبندی دادهها در این الگوریتمها به صورت «خوشهبندی» (Clustering) است. این الگوریتمها با پیدا کردن شباهت بین اشیا یا کشف قوانین ارتباط بین متغیرها، آنها را طبقهبندی میکنند. در «سیستمهای توصیهگر» (Recommendation System) خودکار از این نوع یادگیری استفاده شده است.
درخت تصمیم در مدلهای نظارت شده یادگیری ماشین مورد استفاده قرار میگیرد. این رویکرد میتواند مسائل رگرسیون و دستهبندی را حل کند. بنابراین دو نوع اصلی از درخت تصمیم در یادگیری ماشین بر اساس نوع عملکرد آنها در ادامه فهرست شدهاند:
- «درخت دستهبندی» (Classification Tree)
- «درخت رگرسیون» (Regression Tree)
به طور کلی میتوان گفت که درختهای دستهبندی به میزان بیشتری در روشهای درخت تصمیم یادگیری ماشین کاربرد دارند، ولی میتوان از این رویکرد برای حل مسائل رگرسیون نیز استفاده کرد. تفاوت اصلی این دو روش در نوع مسئله و دادهها است. درختهای دستهبندی در مسائلی که دارای پاسخ بله یا خیر هستند با متغیر تصمیمگیری طبقهبندی استفاده میشوند. درختهای تصمیم رگرسیون برای متغیرهای خروجی متوالی مانند اعداد مورد استفاده قرار میگیرند. در ادامه به طور کامل به بررسی بیشتر این درختهای تصمیم در یادگیری ماشین پرداخته شده است.
دستهبندی در درخت تصمیم یادگیری ماشین چیست؟
رایجترین نوع استفاده از درخت تصمیم در یادگیری ماشین، کاربرد آن در مسائل دستهبندی است. این روش، یک مدل یادگیری ماشین نظارت شده به حساب میآید. مدلها نسب به برچسبهای کلاس برای پردازش دادهها آموزش داده شدهاند. کلاسها توسط مدل و با دادههای آموزشی برچسبدار در بخش آموزش مدل یادگیری ماشین آموزش داده میشوند. برای حل مسائل دستهبندی، مدلها باید ویژگیها و «گروهبندی» (Category) کلاسهای مختلف را برحسب برچسبها درک کنند. یک مسئله دستهبندی میتواند در طیف گستردهای از تنظیمات مختلف برحسب برچسبها انجام شود.
ازجمله این مسائل میتوان به دستهبندی اسناد، نرم افزار «تشخیص تصویر» (Image Recognition) یا «تشخیص هرزنامه ایمیل» (Email Spam Detection) اشاره کرد. درخت دستهبندی روشی برای ساختاربندی یک مدل برای دستهبندی اشیا یا دادهها است. برگها یا انتهای شاخهها در درخت دستهبندی، برچسب کلاسها هستند. درخت تصمیم دستهبندی به صورت تدریجی ایجاد میشود و در آن مجموعه داده اصلی به زیر مجموعههای کوچکتر تقسیم میشوند. این روش زمانی استفاده میشود که متغیرهای هدف به صورت گسسته یا گروهبندی شده باشند و معمولاً به وسیله تقسیمبندی باینری (دودویی) شاخهها انجام میشوند.

برای مثال، ممکن است هر گره دارای یک پاسخ بله یا خیر روی شاخههای خود باشد. بهطور کلی میتوان گفت درخت تصمیم دستهبندی زمانی مورد استفاده قرار میگیرد که متغیر هدف آن به صورت گروهی تعریف شده باشد یا بتوان آن را به صورت گروههایی با بله و خیر دستهبندی کرد. نقطه پایانی هر شاخه یک گروه است. حال در بخش بعدی به بررسی کدهای روش دستهبندی در درخت تصمیم با استفاده از زبان برنامه نویسی پایتون پرداخته میشود.
برنامه نویسی روش دستهبندی درخت تصمیم در یادگیری ماشین
برای انجام برنامه نویسیهای مرتبط با درخت تصمیم در یادگیری ماشین، میتوان از کتابخانه و ابزارهای پایتون استفاده کرد.DecisionTreeClassifier کلاسی است که توانایی انجام «دستهبندیهای چند کلاسه» (Multi-Class Classification) را با استفاده از درخت تصمیم در مجموعه دادهها دارد. همانند دیگر دستهبندی کنندههای داده در پایتون،DecisionTreeClassifier نیز دو آرایه به عنوان ورودی دریافت میکند که در ادامه شرح داده شدهاند:
- آرایه X: این آرایه به صورت «پراکنده» (Sparse) یعنی نمونهها یا «متراکم» (Dense) به معنی ویژگیها و با فرم (n_samples, n_features) ، نمونههای آموزشی را در برمیگیرد.
- آرایه Y: این آرایه دارای مقادیر «عدد صحیح» (Integer) است و در فرم(n_samples,) نوشته میشود.
حال برنامه نویسی این الگوریتم آغاز خواهد شد، نگهداری برچسبهای کلاس برای نمونههای آموزشی با کدهای زیر انجام میشود:
پس از پیادهسازی کدهای فوق، مدل میتواند برای پیشبینی کلاس نمونهها به صورت زیر مورد استفاده قرار بگیرد:
در مواردی که در مسئله مورد نظر چندین کلاس با احتمال یکسان و بالا وجود دارند، الگوریتم دستهبندی کننده باید دستهبندی کلاسها را با کمترین شاخص در میان آنها پیشبینی کند. به عنوان جایگزینی برای خروجی یک کلاس خاص، احتمال وقوع هر کلاس پیشبینی میشود. این احتمال بخشی از نمونههای آموزشی کلاس در یک برگ از درخت تصمیم است. با کدهای زیر این احتمال به دست میآید:
DecisionTreeClassifier قابلیت دو نوع دستهبندی زیر را دارد:
- «دستهبندی دودویی» (Binary Classification) که در آن برچسبها به صورت[-1, 1] نمایش داده میشوند.
- دستهبندی چند کلاسه که در آن برچسبها به صورت[0, …, K-1] نشان داده میشوند.
در ادامه، با استفاده از مجموعه داده «Iris» و کدهای زیر یک درخت تصمیم ایجاد میشود:
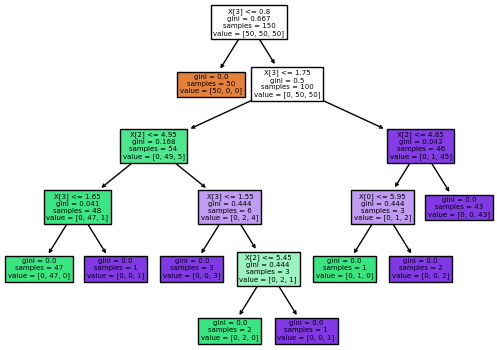
زمانی که کدهای فوق پیادهسازی و آموزش داده شدند، میتوان با استفاده از تابع زیر درخت تصمیم در یادگیری ماشین را ترسیم کرد:
درخت تصمیم آموزش داده شده با استفاده از دادههای مجموعه داده Iris همراه با ایجاد و مشاهده ویژگیهای آن در ادامه نشان داده شده است:
همچنین میتوان درخت تصمیم را در فرمت گرافیکی یا همانGraphviz با استفاده از ابزارexport_graphviz نشان داد. برای استفاده از این کتابخانه اگر بسته مدیریتconda روی سیستم مورد نظر نصب باشد، میتوان کتابخانهgraphviz را با استفاده از آن و به وسیله نوشتن عبارت زیر در خط فرمان، روی سیستم نصب کرد:
conda install python-graphvizهمچنین روشهای دیگری نیز برای نصب این کتابخانه وجود دارند. میتوان آن را از صفحه اصلی وب سایتgraphviz دانلود و نصب کرد یا با استفاده از PIP که ابزاری برای نصب بستهها، کتابخانهها، فریمورکها و سایر موارد این چنینی در پایتون است، به وسیله نوشتن عبارت زیر در ترمینال خط فرمان آن را نصب کرد:
pip install graphvizدر کدهای زیر، برای ترسیم درخت فوق در مجموعه داده Iris از ابزارgraphviz استفاده شده است و خروجی آن به صورت یک فایلiris.pdf ذخیره میشود:
این ابزار دارای گزینههای زیبایی شناختی مختلفی است، ازجمله برخی از این گزینهها میتوان به رنگآمیزی گرهها بر اساس کلاس آنها یا مقدار آنها در مسائل رگرسیون، رنگآمیزی نام متغیرها و کلاسها اشاره کرد. «جوپیتر نوت بوک» (Jupyter Notebook) یکی از ابزارهای برنامه نویسی است که از این نمودارها به صورت پیشفرض و داخلی پشتیبانی میکند. در ادامه تصویر مربوط به ترسیم درخت تصمیم با استفاده ازexport_graphviz ارائه شده است:
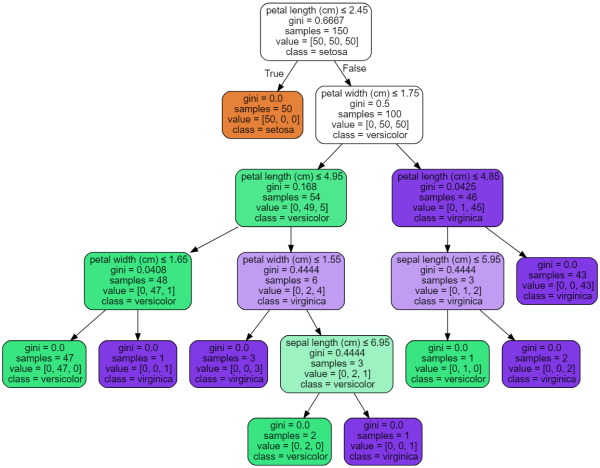
همچنین، درخت تصمیم را میتوان با تابعexport_text به صورت متنی نیز ایجاد کرد. این روش نیازی به نصب کتابخانههای دیگر ندارد و به صورت فشرده انجام میشود. کدهای نشاندهنده این روش در ادامه ارائه شدهاند:
بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی درخت رگرسیون پرداخته میشود.

رگرسیون در درخت تصمیم یادگیری ماشین چیست؟
مدلهای رگرسیون زمانی مورد استفاده قرار میگیرند که در مسائل نیاز است نوعی پیشبینی یا همان پیشبینی متوالی انجام شوند. برای مثال میتوان به پیشبینی قیمت مسکن یا تغییر قیمت سهام اشاره کرد. رگرسیون روشی برای آموزش مدلها جهت درک رابطه بین متغیرهای مستقل و خروجی مدل به حساب میآید. مدلهای رگرسیون با دادههای آموزشی برچسبدار آموزش میبینند، بنابراین، نوعی از الگوریتمهای نظارت شده یادگیری ماشین به شمار میروند. مدلهای رگرسیون یادگیری ماشین برای یادگیری رابطه بین دادههای خروجی و ورودی آموزش داده شدهاند.
زمانی که این رابطه درک شد، میتوان از مدل برای پیشبینی نتایج با دادههای جدیدی که قبلاً توسط مدل دیده نشدهاند، استفاده کرد. معمولاً این روشها برای پیشبینی وقایع در آینده برای گستره وسیعی از تنظیمات کاربرد دارند. درختهای تصمیم یادگیری ماشینی که با خروجیهای متوالی یا مقادیر پیوسته سر و کار دارند، معمولاً درختهای تصمیم رگرسیون خواهند بود. این نوع درخت نیز مانند درخت تصمیم دستهبندی، مجموعه داده را به صورت تدریجی به زیرمجموعههای کوچکتر تقسیم میکند.
درخت رگرسیون، خوشههای متراکم یا پراکندهای از دادهها را ایجاد میکند که میتوان دادههای دیده نشده و جدیدی را به آنها اضافه کرد. به این نکته نیز باید توجه شود که درخت تصمیم رگرسیون نسبت به سایر روشهای پیشبینی دارای خروجی عددی پیوسته از دقت کمتری برخوردار است. در بخش بعدی این مقاله به بررسی روش برنامه نویسی رویکرد رگرسیون درخت تصمیم در یادگیری ماشین پرداخته شده است.
برنامه نویسی روش رگرسیون درخت تصمیم در یادگیری ماشین
همانطور که در بخشهای پیشین نیز به آن اشاره شد، درخت تصمیم میتواند مسائل مرتبط با رگرسیون را نیز حل کند. برای انجام این کار باید از کلاسDecisionTreeRegressor زبان برنامه نویسی پایتون استفاده شود. پیادهسازی این رویکرد بسیار شبیه به روش دستهبندی است و تفاوتهای اندکی دارد. نمودار زیر نشاندهنده نمودار یک درخت تصمیم در یادگیری ماشین با هدف و رویکرد رگرسیون است.
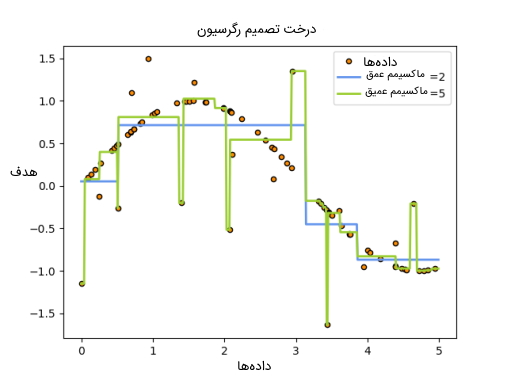
همانطور که در بخش دستهبندی بررسی شد، مدل درخت تصمیم دارای آرگومانهای ورودی آرایهای X و Y هستند. تنها تفاوت در وروردیها بین روش دستهبندی و رگرسیون این است که انتظار میرود Y به جای مقادیر عدد صحیح، دارای مقادیر اعشاری باشد. کدهای درخت تصمیم رگرسیون در ادامه ارائه شدهاند:
از کدها و روشهای دیگری که در بخش برنامه نویسی دستهبندی درخت تصمیم ارائه شدند نیز میتوان برای برنامه نویسی رگرسیون درخت تصمیم استفاده کرد. در بخش بعدی از این مقاله، به بررسی مسائلی که دارای چندین خروجی هستند با استفاده از درخت تصمیم پرداخته شده است.

برنامه نویسی مسائل با چند خروجی به وسیله درخت تصمیم در یادگیری ماشین
«مسئلهها با چند خروجی» (Multi-Output Problem) به عنوان مسائل یادگیری نظارت شده در نظر گرفته میشوند. این مسائل دارای چندین خروجی برای پیشبینی هستند، به عبارت دیگر میتوان گفت زمانی که Y دارای یک آرایه دو بعدی به صورت(n_samples, n_outputs) است، مسئله چندین خروجی دارد. زمانی که در مسئلهای هیچ ارتباطی بین خروجیها وجود ندارد، سادهترین راه برای حل آنها، ساختن n عدد مدل مستقل برای هر کدام از مسائل است. یعنی برای هر خروجی میتوان یک مدل جداگانه ساخت و سپس آنها را به صورت مستقل پیشبینی کرد.
با این حال، از آنجایی که این احتمال وجود دارد که مقادیر خروجی هر ورودی، با ورودی همبستگی داشته باشند، در اغلب موارد، بهترین روش برای حل چنین مسائلی استفاده از نوعی مسئله است که بتواند همه خروجیها را به طور همزمان پیشبینی کند. ابتدا در این روشها به زمان کمتری برای آموزش دادهها نیاز است، زیرا فقط باید یک «تخمینگر» (Estimator) ساخته شود، در مرحله دوم، دقت تولید شده برای نتایج تخمینگر ممکن است افزایش یابد. با توجه به ویژگیهای درخت تصمیم، این روش به راحتی میتواند برای حل مسائل با چندین خروجی مورد استفاده قرار بگیرد. برای استفاده از درخت تصمیم در چنین مسائلی باید تغییرات زیر روی آن اعمال شوند:
- ذخیره n عدد مقدار خروجی به جای یک عدد در برگها انجام میشود.
- استفاده از معیارهای تقسیم یا همان تفکیک تا میانگین کاهش یافته در همه n خروجی محاسبه شوند.
میتوان برای حل مسائل این چنینی و پشتیبانی از وجود چند خروجی با استفاده از ابزارهایDecisionTreeClassifier وDecisionTreeRegressor پیادهسازی این برنامهها را انجام داد. اگر درخت تصمیم دارای آرایه خروجی Y به شکل(n_samples, n_outputs) باشد، نتایج تخمینگر به صورت زیر نمایش داده میشوند:
- خروجیn_output مقادیری بر اساس تابعpredict هستند.
- خروجی مسئله فهرستی از آرایههایn_output و احتمالات کلاس بر اساس تابعpredict_proba است.
کاربرد درخت در مسائلی با چندین خروجی برای رگرسیون نشاندهنده «درخت تصمیم رگرسیون چند خروجی» (Multi-output Decision Tree Regression) است. در این مثال، ورودی X یک مقدار یکتا واقعی و خروجیهای Y به صورت سینوس و کسینوسی از X هستند. نمودار این درخت تصمیم در تصویر زیر نشان داده شده است.
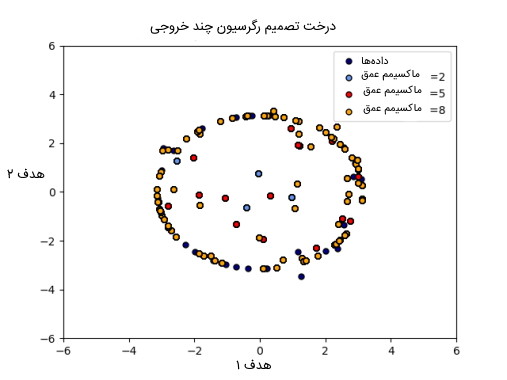
کاربرد درخت در مسائلی با چندین خروجی برای دستهبندی نشاندهنده «تکمیل چهره با تخمینگر چند خروجی» (Face Completion With A Multi-Output Estimator) است. در این مثال، ورودی X پیکسلهای بخش بالایی تصویر چهره فرد را نشان میدهد و خروجیهای Y پیکسلهای تصویر بخش پایینی چهره فرد را نشان میدهند که چندین بار و در چند مرحله این خروجیها ارائه میشوند. در تصویر زیر روند ساخت و تکمیل چهره افراد نمایش داده شده است.

در بخش بعدی از این مقاله به بررسی «پیچیدگی زمانی» (Time Complexity) درخت تصمیم در یادگیری ماشین پرداخته شده است.
پیچیدگی زمانی درخت تصمیم در یادگیری ماشین
به طور کلی، هزینه زمان اجرا برای ساخت یک درخت باینری متعادل برابر است با و زمان «پرس و جو» (Query) آن با مشخص میشود. با اینکه الگوریتم ساخت درخت همیشه سعی دارد تا الگوریتم متعادلی تولید کند، با این حال همیشه درختان تولید شده این الگوریتم متعادل نیستند. با فرض اینکه زیردرختهای ساخته شده تقریبا متعادل هستند، برای پیدا کردن ویژگی که بیشترین کاهش را در معیار ناخالصی میدهد هزینه هر گره برابر با است.
برای مثال، از دست دادن گزارشها یا همان log که باعث بدست آمدن بهره اطلاعاتی جدید میشود. هزینه را در هر گره نشان میدهد و هزینه ساخت کل یک درخت با جمع هزینه تمام گرهها، است. در بخش بعدی از این مقاله، نکاتی درباره استفاده عملی از درخت تصمیم در یادگیری ماشین ارائه شدهاند.
نکاتی درباره استفاده عملی از درخت تصمیم در یادگیری ماشین
در این بخش از مقاله به برخی از نکات کلیدی پرداخته شده است که در طراحی درخت تصمیم در یادگیری ماشین حیاتی هستند و رعایت کردن آنها میتواند تاثیر خوبی در روند طراحی درخت مورد نظر بگذارد. این نکات در ادامه فهرست شدهاند:
- درختهای تصمیم معمولاً روی دادههایی که دارای تعداد زیادی ویژگی هستند، دچار بیشبرازش میشوند. برای طراحی این درختان به دست آوردن نسبت صحیحی از نمونهها به تعداد ویژگیها اهمیت بالایی دارد؛ زیرا درختی با تعداد نمونههای پایین و فضایی با ابعاد بزرگ نیز امکان دارد که دچار بیشبرازش شود.
- کاهش ابعاد با انواع روشهای «PCA» ،«ICA» و انتخاب ویژگی میتواند از قبل انجام شود تا درخت مورد نظر شانس بیشتری برای استخراج ویژگیهای متمایز داشته باشد.

- درک ساختمان درخت تصمیم برای دستیابی به اطلاعات بیشتر درباره چگونگی انجام پیشبینی جهت درک ویژگیهای مهم در دادهها کمک میکند.
- میتوان درخت تصمیم را با استفاده از تابعexport در حال آموزش مصورسازی کرد. همچنین ازmax_depth=3 به عنوان عمق اولیه درخت استفاده میشود و سپس به مرور عمق را میتوان افزایش داد.
- باید به این نکته توجه شود که تعداد نمونههایی که در هر سطح اضافی درخت ایجاد خواهند شد، نسبت به سطح قبلی خود دو برابر میشوند. از تابعmax_depth برای کنترل سایز درخت و جلوگیری از بیشبرازش استفاده میشود.
- از تابعmin_samples_split یاmin_samples_leaf برای اطمینان از این استفاده میشود که بررسی شود چند نمونه در هر درخت از هر تصمیمی وجود دارند. به وسیله کنترل تقسیمهای در نظر گرفته شده، این کار انجام خواهد شد. تعداد بسیار پایین نمونهها معمولاً منجر به بیشبرازش خواهد شد، در حالی که تعداد بالای دادهها نیز باعث جلوگیری از یادگرفتن درخت میشود. بهتر است از مقدارmin_samples_leaf=5 به عنوان مقدار اولیه استفاده شود. اگر حجم نمونهها بسیار متفاوت باشد، یک عدد اعشاری به عنوان درصد در این دو پارامتر مورد استفاده قرار میگیرد.

در حالی که،min_samples_split میتواند برگهای کوچکی ایجاد کند،min_samples_leaf تضمین میکند که هر برگ دارای حداقل سایز خود است و از ایجاد گرههای برگ با واریانس کم و بیشبرازش در مسائل رگرسیونی جلوگیری میکند. برای دستهبندی مسائلی که دارای کلاسهای کمی هستند، معمولاًmin_samples_leaf=1 بهترین انتخاب است. باید به این نکته نیز توجه داشت کهmin_samples_split نمونهها را به صورت مستقیم و مستقل ازsample_weight در صورت ارائه در درخت در نظر میگیرد، برای مثال گرههایی با m نمونه وزنی هنوز دقیقا m نمونه دارند. اگر محاسبه وزن نمونهها در تقسیمات مورد نیاز باشد، برای انجام این محاسبه ازmin_weight_fraction_leaf یاmin_impurity_decrease استفاده میشود.
- قبل از آموزش مجموعه داده، بهتر است که دادهها متعادل شوند تا از ایجاد بایاس در درخت نسبت به کلاسهای اصلی جلوگیری شود. متعادلسازی کلاسها و نمونهها را میتوان با استفاده از روش در نظر گرفتن تعداد نمونههای یکسان برای هر کلاس یا نرمال کردن مجموع وزنهای نمونهها برای هر کلاس با استفاده از تابعsample_weight برای مقادیر یکسان انجام داد. همچنین باید به این موضوع نیز توجه شود که معیارهای «پیش از هرس» (Pre-Pruning) درخت مبتنی بر وزن نمونه، ازجملهmin_weight_fraction_leaf نسبت به معیارهایی ازجملهmin_samples_leaf که از وزن نمونهها آگاه نیستند، در کلاسهای اصلی دارای بایاس کمتری هستند.
- اگر نمونهها دارای وزن باشند، بهینهسازی ساختار درخت با استفاده از معیارهای پیش از هرس مبتنی بر وزن ازجملهmin_weight_fraction_leaf آسانتر خواهد بود و تضمین میکند که حداقل بخشی از مجموع وزن نمونهها را شامل میشود.
- همه درختهای تصمیم از آرایهnp.float32 به صورت داخلی استفاده میکنند. اگر دادههای آموزشی مجموعه داده مسئله در این فرمت نباشند، یک کپی از مجموعه داده با این فرمت ایجاد خواهد شد.
- اگر ماتریس ورودی X خیلی پراکنده باشد، توصیه میشود که این ماتریس قبل از فراخوانیfit و شروع پیادهسازی الگوریتم، بهcsc_matrix پراکنده و قبل از فراخوانیpredict بهcsr_matrix پراکنده تبدیل شود. زمان آموزش دادههای درخت، هنگامی که ویژگیها در اکثر نمونهها دارای مقادیر صفر هستند، میتواند برای ورودیهایی با ماتریس پراکنده نسب به ورودیها با ماتریس متراکم سریعتر باشد.
در بخش بعدی از این مقاله به شرح و بررسی الگوریتمهای درخت تصمیم در یادگیری ماشین پرداخته میشود.
الگوریتم های درخت تصمیم در یادگیری ماشین
درخت تصمیم دارای الگوریتمهای گوناگونی است که با یکدیگر در روشهای پیادهسازی دارای تفاوتهایی هستند و به شرح همه آنها در این بخش پرداخته میشود. نامهای این الگوریتمها در ادامه فهرست شدهاند:
- الگوریتم درخت تصمیم «ID3» یا همان «Iterative Dichotomiser 3»
- الگوریتم درخت تصمیم «C4.5»
- الگوریتم درخت تصمیم «C5.0»
- الگوریتم درخت تصمیم «CART» یا همان «درختهای دستهبندی و رگرسیون» (Classification and Regression Trees)
در ادامه این بخش از مقاله «درخت تصمیم در یادگیری ماشین»، ابتدا به بررسی الگورتیم درخت تصمیم «ID3» پرداخته شده است.
الگوریتم درخت تصمیم ID3 چیست؟
الگوریتم ID3 در سال ۱۳۶۵ شمسی (۱۹۸۶ میلادی) توسط «Ross Quinlan» توسعه یافته است. این الگوریتم یک درخت «چند مسیره» (Multiway) ایجاد میکند و برای هر گره مانند الگوریتمهای حریصانه ویژگی گسسته و گروهی پیدا خواهد کرد. این نوع از الگوریتمهای درخت تصمیم در یادگیری ماشین بیشترین اطلاعات را در مسائلی با اهداف گسسته به دست میآورند. معمولاً درختها به بزرگترین اندازه ممکن خود در مسائل رشد پیدا میکنند، سپس یک مرحله هرس برای بهبود عملکرد و توانایی درخت روی دادههای درخت انجام میشود. در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی الگوریتم C4.5 پرداخته شده است.
الگوریتم درخت تصمیم C4.5 چیست؟
الگوریتم C4.5، جانشینی برای الگوریتم ID3 به حساب میآید و با تعریف پویا یک ویژگی گسسته بر اساس متغیرهای عددی که مقادیر ویژگی پیوسته را به مجموعهای از بخشهای گسسته تقسیم میکنند، محدودیت را از ویژگیهایی حذف خواهد کرد که باید گسسته باشند. این الگوریتم درختهای آموزش دیده را (مثلاً همان خروجی الگوریتم ID3) به مجموعهای از قوانینif-then تبدیل میکند. سپس دقت هر قانون برای تعیین ترتیبی خاص ارزیابی میشود که باید اعمال شود. اگر دقت قانون بدون هرس کردن بهبود یابد، با حذف قانون، پیششرط انجام میشود. در بخش بعدی از این مقاله به بررسی الگوریتم درخت تصمیم در یادگیری ماشین C5.0 پرداخته شده است.
الگوریتم درخت تصمیم C5.0 چیست؟
الگوریتم درخت تصمیم C5.0 آخرین نسخه ارائه شده توسط Quinlan تحت مجوز اختصاصی است. این الگوریتم از حافظه کمتری استفاده میکند و مجموعه قوانین کوچکتری نسب به الگوریتم C4.5 میسازد. در حالی که الگوریتم درخت تصمیم C5.0 دقیقتر هم است. بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی الگوریتم CART اختصاص دارد.
الگوریتم درخت تصمیم CART چیست؟
این الگوریتم شباهت بسیاری با الگوریتم C4.5 دارد. تفاوتی که این دو الگوریتم با یکدیگر دارند، در این است که الگوریتم CART از متغیرهای هدف پیوسته و عددی یا همان مسائل رگرسیون نیز پشتیبانی میکند و مجموعه قوانین را محاسبه نمیکند. این الگوریتم با استفاده از ویژگی و آستانهای که بیشترین اطلاعات را در هر گره ایجاد میکند، درختهای دودویی را میسازد. کتابخانهscikit-learn از نسخه بهینه شده الگوریتم CART استفاده میکند. با این حال، در حال حاضر پیادهسازیscikit-learn از متغیرهای گسسته پشتیبانی نمیکند. بخش بعدی از این مقاله به بررسی انواع مثالهای درخت تصمیم در یادگیری ماشین اختصاص داده میشود.
مثال های درخت تصمیم در یادگیری ماشین
در این بخش از مقاله به بررسی برخی از کاربردهای درخت تصمیم در مثالهایی از زندگی روزمره پرداخته شده است. برای مثال یکی از این کاربردهای درخت تصمیم در ارزیابی فرصتهای رشد کسب و کارها در آینده به حساب میآید و در بخش بعدی بررسی میشود.

ارزیابی فرصت های رشد کسب و کارها در آینده
یکی از کاربردهای درخت تصمیم، ارزیابی فرصتهای رشد در آینده برای کسب و کارها بر اساس دادههایی است که در طول مدت زمان زیادی در رابطه با کسب و کارها جمعآوری شدهاند. برای مثال، دادههای فروش یک سازمان را میتوان با استفاده از درخت تصمیم استفاده کرد و فرصتهای رشد فروش آن را برای آینده مورد بررسی قرار داد. این روند ممکن است منجر به ایجاد تغییرات اساسی در رویکرد یک کسب و کار برای کمک به گسترش و رشد آن شود. در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی استفاده از دادههای جمعیتشناسی برای یافتن مشتریهای احتمالی پرداخته شده است.
استفاده از داده های جمعیت شناسی برای یافتن مشتری های احتمالی
یکی دیگر از مثالهای کاربردی در استفاده از درخت تصمیم یادگیری ماشین در دادههای جمعیتشناسی برای پیدا کردن مشتریهای احتمالی است. این دادهها میتوانند به کارآمد کردن بودجه بازاریابی و تصمیمگیری آگاهانه متناسب با آن درمورد بازار هدف کسب و کار مورد نظر کمک کنند. بدون استفاده از درختان تصمیم، ممکن است کسب و کارها با در نظر نگرفتن بازار بازاریابی و دادههای جمعیتشناسی پیش بروند و از مسائلی چشمپوشی کنند که بر درآمد کلی سازمان تاًثیر مثبت خواهند گذاشت. در بخش بعدی از این مقاله به بررسی درخت تصمیم به عنوان یک ابزار پشتیبانی در چندین زمینه پرداخته شده است.
درخت تصمیم به عنوان یک ابزار پشتیبانی در چندین زمینه
درخت تصمیم به عنوان یک ابزار پشتیبانی در چندین زمینه به کار گرفته میشود. برای مثال، وامدهندگان در یک سازمان از درختهای تصمیم برای پیشبینی پرداخت یا عدم پرداخت وام توسط مشتری و دادههای اطلاعات گذشته مشتری استفاده میکنند. استفاده از ابزارهای پشتیبانی درخت تصمیم میتواند به وامدهندگان کمک کند تا اعتبار مشتری را برای جلوگیری از ضرر و عدم پرداخت وام ارزیابی کنند.
همچنین درخت تصمیم در رویکردهای تحقیقاتی و پژوهشی در برنامهریزی «جزئیات کار» (Logistic) و مدیریت استراتژیک استفاده میشود. آنها میتوانند در تعیین روشهای مناسب در رسیدن سازمان به اهداف مورد نظر خود کمک کنند. علاوه بر موارد ذکر شده، در برخی از زمینههای دیگر ازجمله مهندسی، آموزش، حقوق، کسب و کار، مراقبتهای درمانی و حوزههای مالی نیز میتوان از درخت تصمیم در یادگیری ماشین استفاده کرد. بخش بعدی از این مقاله به بررسی مزایای درخت تصمیم در یادگیری ماشین اختصاص دارد.
مزایای درخت تصمیم در یادگیری ماشین چیست؟
درخت تصمیم به دلیل داشتن مزایای بسیار، یکی از رویکردهای خوب و مناسب در یادگیری ماشین به حساب میآید. درک درخت تصمیم نهایی ایجاد شده فرآیندها، به دلیل مصور بودن آن، بسیار ساده است. همچنین، این روش توضیح خروجی مدل را برای افراد و ذینفعانی که در زمینه یادگیری ماشین و «تجزیه و تحلیل دادهها» (Data Analytics) تخصصی ندارند، ساده میکند. این ذینفعان غیرمتخصص میتوانند به درخت دیداری و مصور دادهها دسترسی داشته باشند و آن را به راحتی درک کنند، بنابراین این دادهها برای تیمهای کسب و کار مختلف قابل دسترسی هستند و منطق مدل را با استفاده از درخت تصمیم میتوان به راحتی درک کرد.
عدم توضیحپذیری یکی از مواردی است که میتواند مانعی برای پذیرش روشهای یادگیری ماشین از سمت سازمانها باشد، اما درخت تصمیم در یادگیری ماشین دارای مزیت توضیحپذیری است و همه موارد را به طور واضح و مصور در اختیار افراد قرار میدهد و این مانع را از بین میبرد. مزیت دیگر درخت تصمیم در یادگیری ماشین در مرحله «آمادهسازی و پیشپردازش دادهها» (Data Preparation) برای مدل است. مدلهای درخت تصمیم در مقایسه با سایر روشهای یادگیری ماشین به «پاکسازی داده» (Data Cleaning) کمتری احتیاج دارند.
به عبارت دیگر، درختهای تصمیم در مراحل اولیه پردازشهای یادگیری ماشین خود نیازی به «نرمالسازی دادهها» (Data Normalization) ندارند. مدلهای درختهای تصمیم میتوانند هم دادههای عددی و هم دادههای گروهی را پردازش کنند، بنابراین، متغیرهای کیفی مانند سایر روشهای یادگیری ماشین نیازی به تبدیل شدن ندارند. مزیتهای اصلی درخت تصمیم در یادگیری ماشین به طور خلاصه در ادامه فهرست شدهاند:
- درک مسائل مربوط به درخت تصمیم برای کسانی نیز ساده است که در این حوزه متخصص نیستند و دانشی درباره دادهها ندارند.
- این الگوریتم تا حد زیادی دارای ویژگی توضیحپذیری است. هر تصمیمی در مدل را میتوان با استفاده از درخت تصمیم توضیح داد، این برخلاف الگوریتمهای جعبه سیاه است که در آنها توضیحپذیری دشوار به حساب میآید.
- دادههای درخت تصمیم در یادگیری ماشین نیازی به نرمالسازی ندارند؛ زیرا این روش میتواند متغیرهای عددی و گروهی را پردازش کند.
- از درخت تصمیم در یادگیری ماشین میتوان برای به تصویر کشیدن سلسله مراتب ویژگیها در یک مجموعه داده استفاده کرد و این درخت تصمیم میتواند در مدلسازیهای بعدی هرس و اصلاح شود.
- درخت تصمیم به طور غیر مستقیم سنجش متغیر و انتخاب ویژگی را انجام میدهد.
- الگوریتم درخت تصمیم میتواند هم دادههای گروهی و هم دادههای عددی را مدیریت کند. همچنین توانایی مدیریت مسائل با چند خروجی را نیز دارد.
- درخت تصمیم به تلاش نسبتاً کمی از طرف کاربران برای آمادهسازی دادهها نیاز دارند.
- روابط غیر خطی بین پارامترها روی عملکرد درخت تصمیم یادگیری ماشین تاًثیری نمیگذارند.
- این الگوریتم نسب به روشهای دیگر به پاکسازی داده کمتری نیاز دارد.
در بخش بعدی از این مقاله، به بررسی انواع معایب درخت تصمیم در یادگیری ماشین پرداخته شده است.

معایب درخت تصمیم در یادگیری ماشین چیست؟
یکی از اصلیترین معایب درخت تصمیم در یادگیری ماشین، مسئله «بیشبرازش» (Overfitting) به حساب میآید. هدف مدلهای یادگیری ماشین، دسترسی به درجه خوبی از دقت و تعمیم است که مدل بتواند پس از استقرار، دادههای دیده نشده را با دقت پردازش کند. بیشبرازش زمانی رخ میدهد که مدل فقط برای دادههای آموزشی دقت خوبی را نشان دهد و برای دادههای تست و آن دادههایی که تا به حال توسط مدل دیده نشدهاند، دقت پایینی ارائه شود. به عبارت دیگر، میتوان کفت که مدل شرطی میشود و فقط برای تعدادی داده خاص عملکرد خوبی را نشان میدهد. بیشبرازش یک مشکل عمده در درختهای تصمیم است که اغلب میتواند بسیار بزرگ و پیچیده شود.
یکی از روشهایی که برای از بین بردن این مسئله در درخت تصمیم یادگیری ماشین انجام میشود، استفاده از هرس کردن است. هرس درخت تصمیم، آن شاخهها و گرههایی در درخت را حذف میکند که به هدف مسئله ارتباطی ندارند یا اطلاعات اضافی برای رسیدن به هدف برای مسئله اضافه نمیکنند. هر هرس در درخت تصمیم، از طریق فرآیند «اعتبارسنجی متقابل» (Cross Validation) در یادگیری ماشین اندازهگیری میشود و میتواند توانایی مدل برای عملکرد و دقت آن را در یک محیط زنده محاسبه کند. برخی از معایب اصلی درخت تصمیم در یادگیری ماشین در ادامه به صورت خلاصه فهرست شدهاند:
- درختهای تصمیم میتوانند در حالتهای بسیار پیچیدهای رشد کنند، بنابراین نیاز به هرس کردن و بهینهسازی دارند.
- بیشبرازش یا همان Overfitting یکی از مشکلات بسیار رایج در درخت تصمیم یادگیری ماشین است. این مورد با استفاده از هرس کردن، بهینهسازی «فرا پارامترها» (Hyperparameter) و روش الگوریتم «جنگل تصادفی» (Random Forest) حل میشود.
- تغییرهای کوچک در دادههای آموزشی میتوانند تأثیر زیادی روی درخت تصمیم داشته باشند و اغلب باعث ایجاد درختهای تصمیم متفاوت میشوند.
- درخت تصمیم در هنگام استفاده با مسائل رگرسیون نسبت به سایر روشهای یادگیری ماشین، به ویژه مسائلی که دارای خروجیهای عددی پیوسته هستند، ممکن است دقت کمتری داشته باشد.
- اگر مجموعه داده آموزشی متعادل یا مشخص نباشد، باعث ایجاد «بایاس» (Bias) در مدلهای یادگیری ماشین میشود.
- درختهای تصمیم امکان دارد که ناپایدار باشند؛ زیرا حتی تغییرات کوچک در دادهها ممکن است درخت کاملاً متفاوتی را ایجاد کنند. این موضوع «واریانس» (Variance) نامیده میشود که با استفاده از روشهای «Bagging» و «Boosting» میتوان آن را کاهش داد.
- زمانی که در درخت تصمیم تعداد برچسب کلاسها افزایش پیدا میکند، پیچیدگی محاسباتی درخت تصمیم نیز افزایش مییابد.
حال پس از بررسی تئوری انواع مفاهیم و موارد مرتبط با درخت تصمیم در یادگیری ماشین، در بخش بعدی به پیادهسازی درخت تصمیم با استفاده از زبان پایتون پرداخته شده است.
- مقالههای پیشنهادی:
پیاده سازی درخت تصمیم در یادگیری ماشین با استفاده از مثال زبان برنامه نویسی پایتون
در این بخش یک درخت تصمیم با استفاده از زبان برنامه نویسی پایتون پیادهسازی شده است. در پیادهسازی این الگوریتم از مجموعه دادهای با نامuser_data.csv استفاده خواهد شد. در این کدها مثال مرتبط با انتخاب شغل یک کاربر پیادهسازی خواهد شد که یک مثال دستهبندی به حساب میآید. ابتدا مراحل پیادهسازی این درخت تصمیم در یادگیری ماشین در ادامه فهرست شدهاند:
- مرحله «پیش پردازش دادهها» (Data Preprocessing)
- ایجاد الگوریتم درخت تصمیم برای مجموعه داده آموزشی
- پیشبینی نتایج تست
- استخراج دقت تست نتایج و ایجاد «ماتریس درهمریختگی» (Confusion Matrix)
- مصورسازی نتایج دادههای مجموعه آموزش
- مصورسازی نتایج دادههای مجموعه تست
در ادامه به ترتیب همه مراحل فوق همراه با کدهای آنها مورد بررسی قرار گرفتهاند. ابتدا بخش بعدی به بررسی مرحله پیش پردازش دادهها اختصاص داده شده است.
پیش پردازش داده ها برای پیاده سازی درخت تصمیم در یادگیری ماشین
در این بخش با استفاده از کدهای زیر پیش پردازش دادهها برای الگوریتم درخت تصمیم در یادگیری ماشین انجام شده است:
در کدهای فوق، دادهها پردازش و سپس بارگذاری شدهاند، در ادامه خروجی این کدها نمایش داده شده است و مجموعه داده را نشان میدهد.
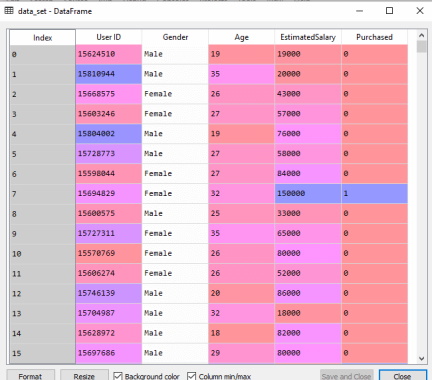
در بخش بعدی به روش ایجاد الگوریتم درخت تصمیم در یادگیری ماشین برای مجموعه داده آموزشی با استفاده از کدهای برنامه پرداخته شده است.
ایجاد الگوریتم درخت تصمیم در یادگیری ماشین برای مجموعه داده آموزشی
حال در این بخش و پس از پیش پردازش دادهها، مجموعه داده آموزشی ایجاد میشود. برای این کار نیاز است که کلاسDecisionTreeClassifier از کتابخانهsklearn.tree در ابتدای کدهای برنامه «وارد» یا همانimport شود. در ادامه کدهای این بخش مشاهده میشوند:
با استفاده از کدهای فوق، یک «شی دستهبندی» (Classifier Object) ایجاد شده است که دو پارامتر اصلی زیر را دارد:
- criterion='entropy' : این معیار برای اندازهگیری کیفیت گروههایی استفاده میشود که بر اساس اطلاعات به دست آمده و توسط آنتروپی محاسبه شدهاند.
- random_state=0 : این معیار برای تولید حالتهای تصادفی ایجاد میشود.
پس از اجرا و پیادهسازی برنامه فوق، در ادامه خروجی این کدها نمایش داده شدهاند:
Out[8]:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=0, splitter='best')در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» پیشبینی نتایج دادههای مجموعه تست نشان داده شده است.
پیش بینی نتایج داده های مجموعه تست الگوریتم درخت تصمیم در یادگیری ماشین
حال در این بخش با استفاده از کدهای زیر نتایج مجموعه داده پیشبینی میشوند. در این کدها یک بردار پیشیبینی جدید به نامy_pred ایجاد شده است.
خروجی کدهای پیشبینی مجموعه تست فوق در ادامه نشان داده شدهاند. در تصویر خروجی زیر، خروجی پیشبینی شده و خروجی تست واقعی در کنار یکدیگر آورده شده است. به وضوح مشاهده میشود، مقادیری که در بردار پیشبینی تست وجود دارند با مقادیر بردار واقعی تفاوت دارند. به این تفاوتها خطاهای پیشبینی گفته میشود.
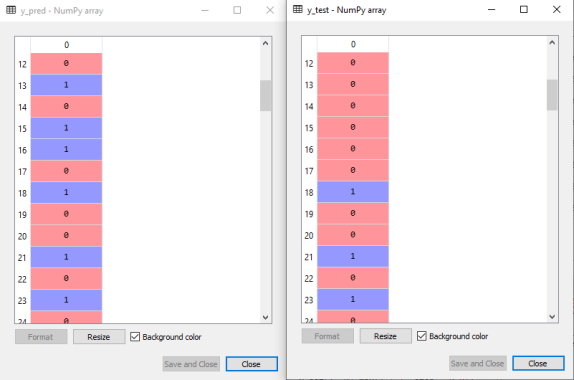
در ادامه این بخش از مقاله «درخت تصمیم در یادگیری ماشین» به بررسی و شرح استخراج دقت تست نتایج و ایجاد ماتریس درهمریختگی در درخت تصمیم پرداخته شده است.
استخراج دقت تست نتایج و ایجاد ماتریس درهم ریختگی در درخت تصمیم
در خروجی کدهای مرحله قبل مشاهده شد که برخی از پیشبینیهای ارائه شده مسئله نادرست هستند. بنابراین، در این بخش به بررسی این مورد پرداخته میشود که تعداد پیشبینیهای صحیح و نادرست چقدر است. برای این منظور باید از ماتریس درهمریختگی یا همان Confusion Matrix استفاده کرد. کدهایی این ماتریس در ادامه نمایش داده شدهاند:
پس از پیادهسازی کدهای فوق، خروجی زیر نمایش داده میشود:
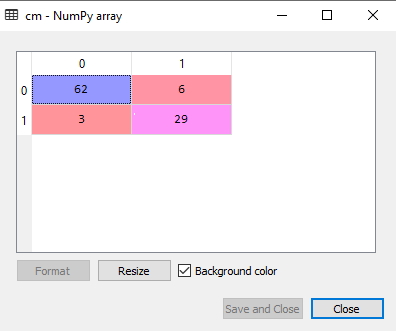
در تصویر فوق یک ماتریس درهمریختگی نشان داده شده است که پیشبینی نادرست و پیشبینی صحیح دارد. بنابراین، میتوان گفت که در مقایسه با سایر روشها و الگوریتمهای پیشبینی، درخت تصمیم در یادگیری ماشین پیشبینی خوبی داشته است. بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به مصورسازی نتایج دادههای مجموعه آموزش در الگوریتم درخت تصمیم اختصاص دارد.
مصورسازی نتایج داده های مجموعه آموزش در الگوریتم درخت تصمیم
در این بخش از مقاله به مصورسازی مجموعه آموزش پرداخته شده است. برای این مصورسازی، یک «گراف» (Graph) دستهبندی درخت تصمیم ترسیم میشود. دستهبند پاسخهای بله یا خیر را برای کاربری پیشبینی میکند که قصد استخدام در یک شرکت را دارد و مثال آن در بخشهای پیشین مورد بررسی قرار گرفته بود. در ادامه، کدهای مرتبط با این برنامه نمایش داده شده است:
خروجی کدهای فوق به صورت زیر است:
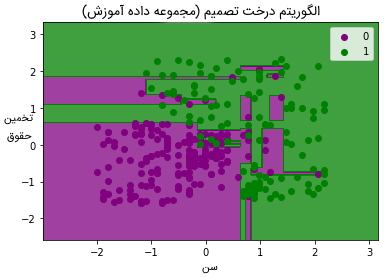
خروجی فوق نسبت به دیگر مدلهای دستهبندی موجود متفاوت است. در تصویر فوق، خطهای عمودی و افقی مشاهده میشوند که مجموعه داده را براساس سن و تخمین متغیر حقوق، تقسیم میکنند. همانطور که مشاهده میشود، درخت تصمیم سعی کرده است تا حد امکان هر مجموعه داده را در بربگیرد و باعث ایجاد بیشبرازش نشود. در بخش بعدی از مقاله «درخت تصمیم در یادگیری ماشین» به شرح روش مصورسازی نتایج دادههای مجموعه تست در الگوریتم درخت تصمیم همراه با کدهای آن پرداخته شده است.
مصورسازی نتایج داده های مجموعه تست در الگوریتم درخت تصمیم
کدهای مصورسازی نتایج مجموعه داده تست، شباهت بسیاری با کدهای مصورسازی مجموعه داده آموزش دارند، با این تفاوت که در این کدها به جای استفاده از دادههای آموزش از دادههای تست استفاده میشود.
پس از پیادهسازی کدهای فوق، خروجی زیر نمایش داده میشود:
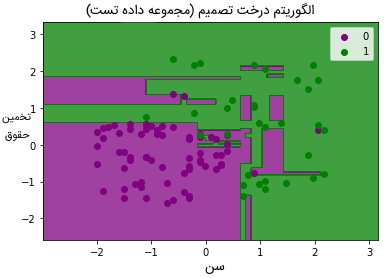
همانطور که در تصویر فوق مشاهده میشود، تعدادی داده سبز در ناحیه بنفش و همچنین تعدادی داده بنفش در ناحیه سبز وجود دارند. این موارد، پیشبینیهای نادرستی هستند که در ماتریس درهمریختگی نیز مشاهده میشدند.
جمعبندی
در مقاله «درخت تصمیم در یادگیری ماشین» الگوریتم دستهبندی و رگرسیون درخت تصمیم به طور کامل معرفی و از جهتهای مختلف مورد بررسی قرار گرفت. در این مقاله سعی شد پس از تعریف و معرفی درخت تصمیم در یادگیری ماشین به بررسی روش عملکرد و همچنین مراحل گوناگون عملکرد آن پرداخته شود. در اواسط مقاله به بررسی کدهای درخت تصمیم با استفاده از زبان برنامه نویسی پایتون نیز پرداخته شد.
معمولاً برای پیادهسازی درخت تصمیم از کتابخانهscikit-learn استفاده میشود و با استفاده از این کتابخانه، کدها و مثالی برای یادگیری بیشتر درخت تصمیم در یادگیری ماشین ارائه شد. همچنین مزایا و معایب درخت تصمیم در یادگیری ماشین نیز مورد بررسی قرار گرفتند. در نهایت میتوان به این موضوع نیز اشاره کرد که برای درک و یادگیری بیشتر این نوع از الگوریتمها توسط علاقهمندان و دانشجویان، آموزش برخی از مباحث مرتبط با یادگیری ماشین و هوش مصنوعی نیز در این مقاله برای آنها معرفی شدهاند.








بسیار عالی
سلام کمی بیشتر در مورد پیچیدگی زمانی درخت تصمیم توضیح دهید.
متاسفانه دسترسی به user_data.csv واسه پیاده سازی نداریم. لطفا لینک دانلودش رو هم قرار بدید
به نظر من بهتر است کلمه Information Gain رو “بهره اطلاعاتی” معنا کنید تا “به دست آوردن اطلاعات”
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
سپاس بیکران بابت پیشنهاد شما، این مورد اصلاح شد.
برای شما آرزوی سلامتی و موفقیت داریم.