



متغیر تصادفی و توزیع دریکله (Dirichlet Distribution) – به زبان ساده
در آمار و تئوری احتمالات، متغیر تصادفی و «توزیع دریکله» (Dirichlet Distribution) جزء توابع توزیع با اهمیت محسوب میشود زیرا در استنباط بیزی میتواند به عنوان توزیع مزدوج دوجملهای (Binomial Distribution) قرار گیرد. بنابراین آگاهی از خصوصیات آن میتواند در حل بسیاری از مسائل استنباط آماری موثر باشد. این توربع به صورت چند متغیره تک پارامتری بوده و به صورت نشان داده میشود.



از آنجایی که این توزیع در حالت چند متغیره میتواند تعمیم برای توزیع بتا در نظر گرفته شود، گاهی به آن توزیع بتای چند متغیره (Multivaraite Beta Distribution - MBD) نیز گفته میشود. نام این توزیع از نام ریاضیدان بزرگ آلمانی «پیتر دریکله» (Peter Gutav Lejeune Dirikhlet) گرفته شده است. این توزیع را گاهی «دیریکله» نیز مینامند.
برای درک مفاهیم به کار رفته در این نوشتار مطالعه مطالب توزیع های آماری گاما و بتا — مفاهیم و کاربردها و متغیر تصادفی و توزیع چند جمله ای (Multinomial Distribution) — به زبان ساده ضروری به نظر میرسد. همچنین خواندن مطلب احتمال پسین (Posterior Probability) و احتمال پیشین (Prior Probability) — به زبان ساده خالی از لطف نیست.
متغیر تصادفی و توزیع دریکله
این توزیع به صورت چند متغیره است. بنابراین تکیهگاه آن نیز به صورت یک بردار نمایش داده میشود. فرض کنید متغیر تصادفی دارای بعد باشد.
در این صورت تکیهگاه متغیر تصادفی دریکله به صورت زیر نوشته میشود.
این روابط نشان میدهند که متغیر تصادفی دریکله بعدی بوده و مجموع مقادیر مولفههای آن برابر با یک است. از طرفی مشخص است که مقادیر بردار متغیر تصادفی دریکله در بازه صفر تا یک تغییر میکند. به این ترتیب متغیر تصادفی با این خصوصیات را با منتغیر تصادفی با توزیع دریکله از مرتبه مینامیم.
نکته: مشخص است که مقدار از مجموعه اعداد طبیعی است. معمولا مقدار را بزرگتر یا مساوی با ۲ در نظر میگیرند. در ادامه مشخص میشود که به ازاء این توزیع با توزیع بتا یکسان خواهد شد.
متغیر تصادفی را دارای توزیع دریکله گویند اگر تابع احتمال (تابع چگالی احتمال) آن به صورت زیر باشد. در این صورت میگوییم متغیر تصادفی دارای توزیع دریکله مرتبه با پارامتر است و این عبارت را به صورت نماد ریاضی نشان میدهیم.
در اینجا منظور از تابع بتای چند متغیره است که به شکل نسبت توابع گاما و مطابق با رابطه زیر محاسبه میشود.
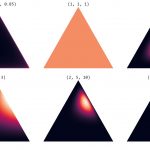
همانطور که مشخص است این توزیع دارای یک پارامتر چند متغیره است که براساس آن مختصات مرکز (امید ریاضی و نما) توزیع تعیین میشود. نمودار تابع چگالی این متغیر تصادفی در سه بُعد برای چهار شکل مختلف از پارامتر در تصویر زیر دیده میشود.

حالت خاص توزیع دریکله
یکی از حالتهای خاص برای توزیع دریکله، زمانی است که بردار پارامتر این توزیع مقادیر یکسانی داشته باشد. در چنین حالتی، توزیع دریکله را «متقارن» (Symmetric) مینامند. به این ترتیب میتوان تابع چگالی این متغیر تصادفی را با تنها یک پارامتر عددی () مشخص کرد. در این حالت پارامتر را با نام «پارامتر تراکم» (Concentration) میشناسند. رابطه محاسباتی برای تابع چگالی متغیر تصادفی «دریکله متقارن مرتبه » به صورت زیر نوشته میشود.
اگر پارامتر باشد، توزیع دریکله متقارن به توزیع یکنواخت استاندارد تبدیل خواهد شد. به این معنی که این توزیع در هر بعد به صورت یک توزیع گسسته یکنواخت تک متغیره خواهد بود. چنین توزیعی را گاهی به نام Flat Dirichlet Distribution نیز میشناسند.
اگر بردار دارای توزیع دریکله با پارامتر باشد و را به صورت در نظر بگیریم، آنگاه هر یک از ابعاد متغیر تصادفی یعنی دارای توزیع بتا هستند. به این ترتیب رابطه زیر برقرار است.
همچنین اگر در نظر گرفته شود، توزیع دریکله به توزیع بتا تبدیل خواهد شد. به این ترتیب خواهیم داشت:
خصوصیات متغیر تصادفی دریکله
با توجه به مفهوم امید ریاضی و واریانس متغیر تصادفی، میتوان برای متغیر تصادفی دریکله، این خصوصیات را محاسبه کرد. به این ترتیب خواهیم داشت:
از طرفی واریانس نیز در هر بعد مطابق با رابطه زیر بدست میآید.
همیچنین کوواریانس بین متغیرهای تصادفی به صورت زیر است.
نکته: توجه داشته باشید که ماتریس حاصل از کوواریانس برای متغیر تصادفی دریکله، منفرد، یعنی معکوسپذیر است.
از طرفی «نما» (Mode) این توزیع به ازاء برابر است با .
توزیع دریکله به صورت توزیع مزدوج پیشین توزیع چندجملهای است. به این ترتیب اگر متغیر تصادفی دارای توزیع چندجملهای (Multinomial- MN) با احتمالات و توزیع پیشین پارامتر آن (یعنی بردار ) دارای توزیع دریکله با مرتبه باشد، آنگاه توزیع پسین برای بردار پارامتر نیز باز توزیع دریکله خواهد بود. این موضوع را به کمک روابط زیر نشان میدهیم.
به این ترتیب با توجه به روابط بالا، خواهیم داشت:
از این رابطهها در حوزه استنباط بیزی بخصوص برای پارامتر احتمال توزیع چندجملهای استفاده میشود.
ارتباط با توزیعهای دیگر
فرض کنید متغیرهای تصادفی مستقل با توزیع گاما باشند. یعنی داشته باشیم:
میدانیم که مجموع این متغیرهای تصادفی نیز دارای توزیع گاما (Gamma Distribution) است. یعنی رابطه زیر برقرار است.
حال متغیر تصادفی که به صورت نسبت ها بر تعریف میشود، دارای توزیع دریکله است. یعنی میتوان توزیع متغیر تصادفی را به صورت زیر در نظر گرفت.
از این خاصیت برای شبیهسازی یا تولید اعداد تصادفی با توزیع دریکله استفاده میشود. بنابراین کافی است مقادیری از متغیر تصادفی گاما تولید کرده و حاصل جمع آنها را محاسبه کنیم، نسبت هر یک از این مقدارها بر حاصل جمع، بردار مقادیر توزیع دریکله خواهد بود.
نکته: با توجه به کوواریانس متغیر تصادفی دریکله، مشخص است که این متغیرهای تصادفی ها مستقل نیستند ولی از طریق نسبت متغیرهای تصادفی مستقل گاما تولید شدهاند.
کد پایتون که در زیر قابل مشاهده است، شیوه شبیهسازی و تولید اعداد تصادفی با توزیع دریکله را مورد بررسی قرار داده است. خروجی این دستورات، یک اعداد تصادفی بعدی با توزیع دریکله است.
تفسیر شهودی از پارامتر توزیع دریکله
همانطور که قبلا اشاره شد، توزیعهای خانواده دریکله اغلب به عنوان توزیع پیشین در استباط بیزی به کار میروند. سادهترین و شاید رایجترین توزیع دریکله، نوع متقارن آن است که در این حالت تمام مقدار بردار پارامترها با یکدیگر برابر هستند. به این ترتیب مشخص است که هیچ یک از مولفههای این توزیع نسبت به دیگری دارای اهمیت یا اولویت بیشتری نیست. بنابراین زمانی که هیچ اطلاعات پیشینی از پارامترها نداریم، استفاده از این توزیع مناسب به نظر میرسد.

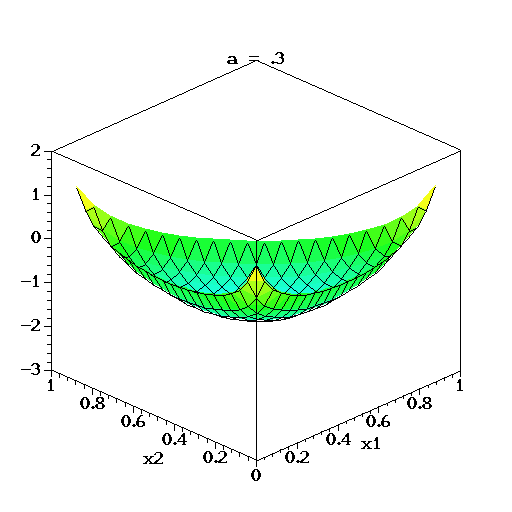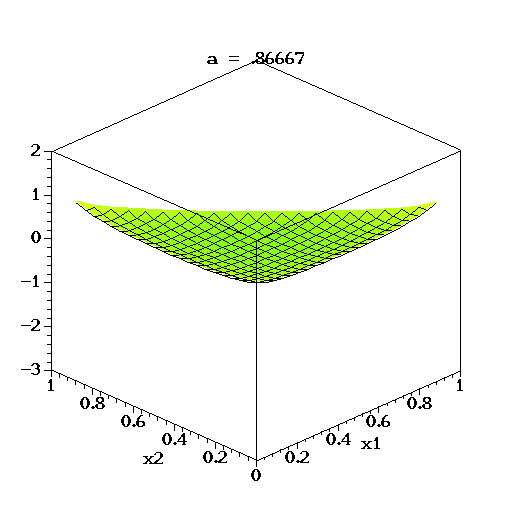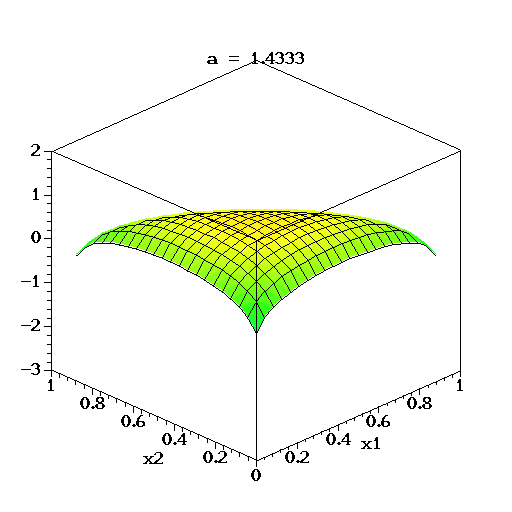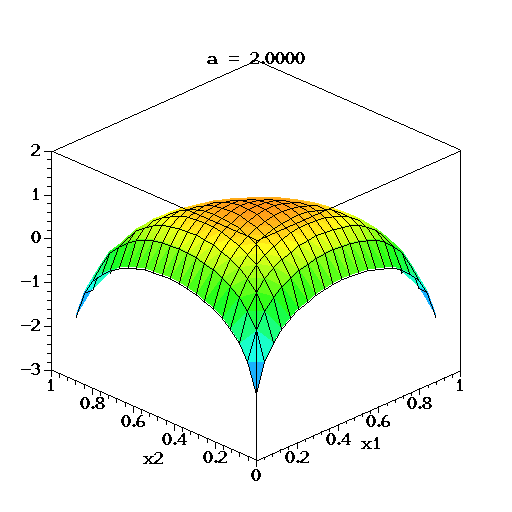
در این حالت، همانطور که در قسمتهای قبل گفته شد، پارامتر ، پارامتر تراکم (Concentration) نامیده می شود. اگر فضای نمونه متغیر تصادفی دریکله، به صورت گسسته در نظر گرفته شود و تابع احتمال را به صورت میزان احتمال در هر نقطه محسوب کنیم، میتوان پارامتر تراکم را به عنوان میزان چگالی یا تراکم (Concentration) احتمال در هر بعد در نظر گرفت. اگر مقدار این پارامتر بسیار کمتر از ۱ باشد، بیشترین جرم احتمال روی تعداد مولفههای کمتری متمرکز شده است. همچنین اگر مقدار پارامترها بسیار بزرگتر از ۱ باشند، به نظر میرسد که جرم احتمال روی همه مولفهها بطور یکسان پخش شده است و توزیع حاصل، مشابه توزیع یکنواخت خواهد شد.
در تصویر متحرک زیر نیز برای متغیر تصادفی سه بُعدی دریکله، لگاریتم تابع چگالی برای مقدارهای مختلف پارامتر تا ترسیم شده است. البته توجه داشته باشید که تغییرات بردار پارامترها در این ترسیمها همگی یکسان است.
اگر مطلب بالا برایتان مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- آموزش آمار و احتمال مهندسی
- تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده
- توزیع های آماری گاما و بتا — مفاهیم و کاربردها
- احتمال پسین (Posterior Probability) و احتمال پیشین (Prior Probability) — به زبان ساده
^^










