



پیاده سازی نگاشت کاهش (MapReduce) در پایتون – به زبان ساده
«نگاشت کاهش» (MapReduce)، یک مدل بینظیر است که پردازش مجموعه دادههای دارای نمونههای زیاد (مجموعه دادههای بزرگ) را آسانتر کرده است. این مدل، کاربردهای متعددی در مسائل تحلیل داده دارد و در مسائل جهان واقعی متعددی مورد استفاده قرار میگیرد. از این رو، در این مطلب روش پیاده سازی نگاشت کاهش در زبان برنامهنویسی پایتون شرح داده شده است. همچنین، مدل در یک پروژه عملی مورد بررسی قرار گرفته است. در این پروژه، تعداد کلمات کتاب رمان «Unveiling a Parallel» شمارش خواهد شد. در ادامه، برخی از پیشنیازهای لازم و موجود برای پیادهسازی این کد بیان شده است.
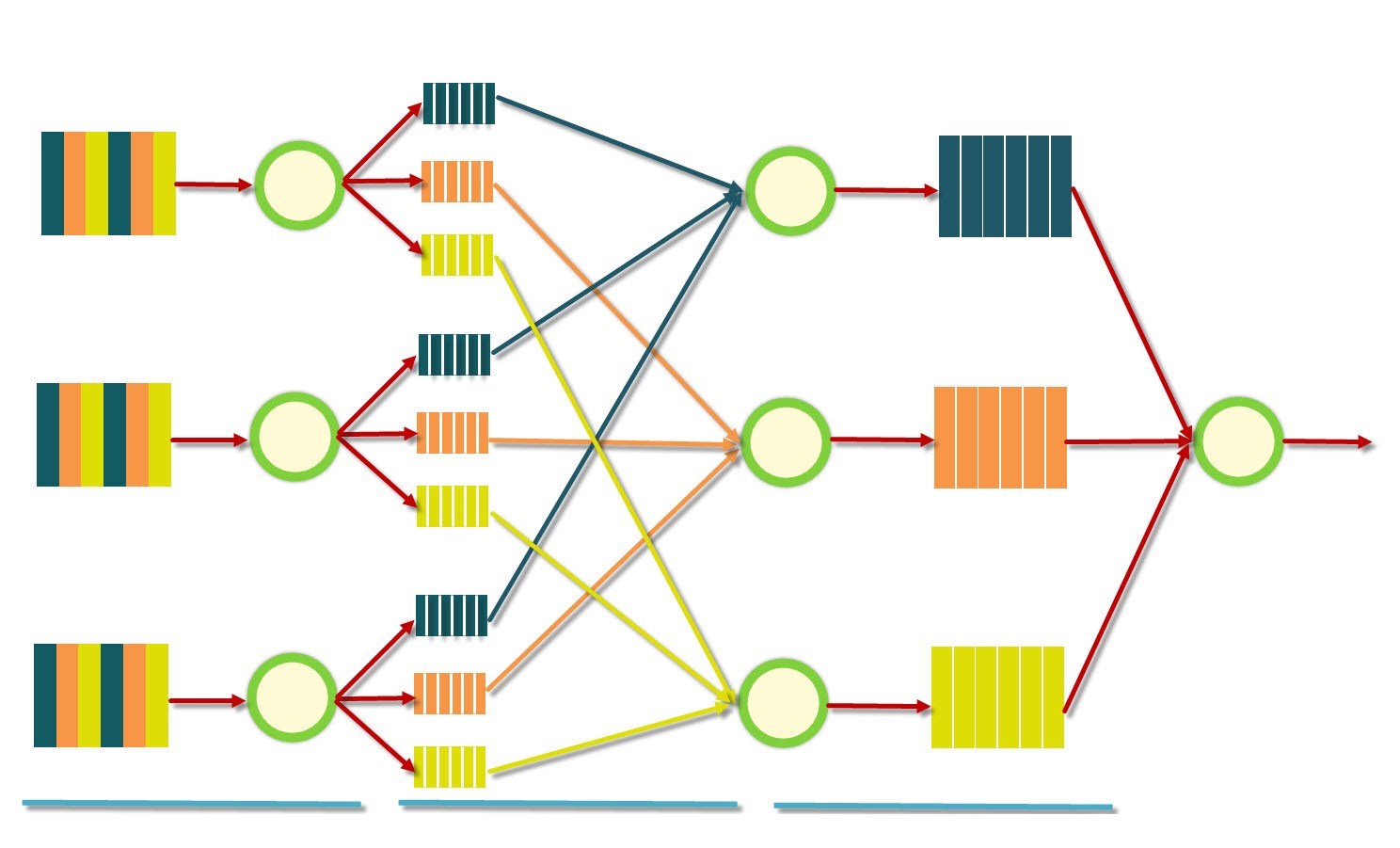


- ماژول «چندپردازشی» (multiprocessing) برای پخش کردن پردازشها، که با فراخوانی متد ()start روی شی Process ساخته شده مورد استفاده قرار میگیرد.
- یک فایل خروجی متناظر با هر «رشته اجرایی» (thread) «کاهش» (Reduce) وجود دارد.
- خروجیها را میتوان در پایان در یک فایل یکتا ادغام کرد.
- نتایج گام نگاشت (map)، با استفاده از «نشانهگذاری شی جاوا اسکریپت» (نشانهگذاری شی جاوا اسکریپت | JSON) ذخیره میشوند (مانند فایلهای خروجی برای هر رشته اجرایی خروجی).
کاربر در پایان ممکن است تصمیم بگیرد که این فایلها را حذف و یا رها کند.
پیاده سازی نگاشت کاهش (MapReduce)
ابتدا، اولین کاری که باید انجام شود نوشتن کلاس MapReduce است که نقش رابط را برای پیادهسازی شدن توسط کاربر، دارد. این کلاس دارای دو متد است: mapper و reducer که بعدا پیادهسازی خواهند شد (مثالی از پیادهسازی یک شمارنده لغات با استفاده از MapReduce در ادامه و در بخش مثال شمارنده کلمات، ارائه شده است).
بنابراین، کار نوشتن الگوریتم، با نوشتن کد زیر آغاز میشود:
برای بررسی تنظیمات گوناگون، باید ماژول «تنظیمات» (settings) را بررسی کرد. سپس، نیاز به افزودن متد ()run برای کلاس MapReduce است که عملیات map و reduce را اجرا میکند. بدین منظور، نیاز به تعریف یک متد (run_mapper(index است (که در آن، index به رشته اجرایی کنونی ارجاع دارد) که از mapper استفاده میکند و نتایج را روی دیسک ذخیره میکند و (run_reducer(index که reducer را روی نتایج map اعمال و نتایج رار وی دیسک ذخیره میکند.
متد ()run تعداد دلخواهی از نگاشتکنندهها (mappers) و سپس، تعداد لازم از کاهشدهندهها (reducers) را پخش میکند. شی Process از ماژول multiprocessing به صورت زیر مورد استفاده قرار میگیرد.
اکنون، باید متدهای run_mapper و run_reducer را تکمیل کرد. اما، از آنجا که این متدها نیازمند خواندن و ذخیره دادهها از یک فایل ورودی هستند، ابتدا باید یک کلاس FileHandler ساخت. این کلاس، فایل ورودی را با استفاده از متد split_file (همان number_of_splits) (که در آن تعداد تقسیمات یا همان number of splits، تعداد کل بخشهایی است که به عنوان نتیجه تقسیمبندی مورد نیاز هستند) تقسیمبندی میکند. کلاس FileHandler نیز با استفاده از متد join_files (داریم number_of_files ,clean ,sort ,decreasing) به خروجیها میپیوندد (که در آن number_of_files تعداد کل فایلها برای join است.
clean ،sort و decreasing مجموعه همه آرگومانهای بولی دلخواه هستند که در این مثال، همه به طور پیشفرض در حالت True قرار دارند). clean بیان میکند که کاربر کجا میخواهد فایلهای موقتی را بعد از join حذف کند، sort نشان میدهد که آیا نتایج مرتب شده یا نه و decreasing نشان میدهد که کاربر میخواهد مرتبسازی را به ترتیب معکوس انجام دهد یا خیر. باید این موضوع را به خاطر داشت که کار با نوشتن شی FileHandler به صورت زیر، آغاز شده است:
سپس، نوشتن متدهای split و join کامل میشود.
اکنون، میتوان متدهای run_mapper و run_reducer را مانند زیر کامل کرد:
در نهایت، متد run اندکی ویرایش میشود تا کاربر قادر به تعیین این باشد که خروجیها متصل شوند یا خیر. متد run به صورت زیر میشود:
کد نهایی الگوریتم نگاشت کاهش (Map Reduce)، در زبان برنامهنویسی پایتون، به صورت زیر خواهد بود:
ماژول Settings
این ماژول حاوی تنظیمات و تابعهای مفید پیشفرض برای ساخت نامهای مسیر برای ورودی، خروجی و فایلهای موقت است.
این متدهای کارآمد در قسمت «توضیحات» (comment) قطعه کد زیر شرح داده شدهاند.
مثال شمارنده کلمات
در این مثال، فرض میشود که یک سند وجود دارد و هدف، شمردن تعداد وقوع هر کلمه در آن است. برای انجام این کار، نیاز به تعریف عملیات نگاشت و کاهش است تا بتوان متدهای mapper و reducer از کلاس MapReduce را پیادهسازی کرد.

راهکار برای شمارش کلمات، خیلی ساده است:
map: متن تقسیم میشود، سپس کلماتی که فقط حاوی کاراکترهای ascii و حروف کوچک هستند شمارش میشوند. پس از آن، هر کلمه به عنوان کلیدی با شمار ۱ ارسال میشود.
reduce: به سادگی میتوان همه مقادیر پیشین برای هر کلمه را جمع کرد.
بنابراین، کلاس MapReduce به صورت زیر پیادهسازی میشود.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزش های داده کاوی یا Data Mining در متلب
- مجموعه آموزشهای آمار و احتمالات
- مفاهیم کلان داده (Big Data) و انواع تحلیل داده — راهنمای جامع
- کلان داده یا مِه داده (Big Data) — از صفر تا صد
- تحلیل کلان داده (Big Data)، چالش ها و فناوری های مرتبط — راهنما به زبان ساده
^^







