



نامساوی کانتلی و باتاچاریا – به زبان ساده
در نوشتارهای دیگر مجله فرادرس با نامساویهای احتمال نظیر نامساوی مارکف (Markov Inequality) و نامساوی چبیشف (Chebyshev Inequality) آشنا شدید. در این نوشتار به بررسی نامساوی کانتلی و باتاچاریا خواهیم پرداخت که با توجه به مقدار پارامتر آن، یک کران بالا یا پایین برای احتمال تجمعی یا تابع بقا متغیر تصادفی ایجاد میکند.

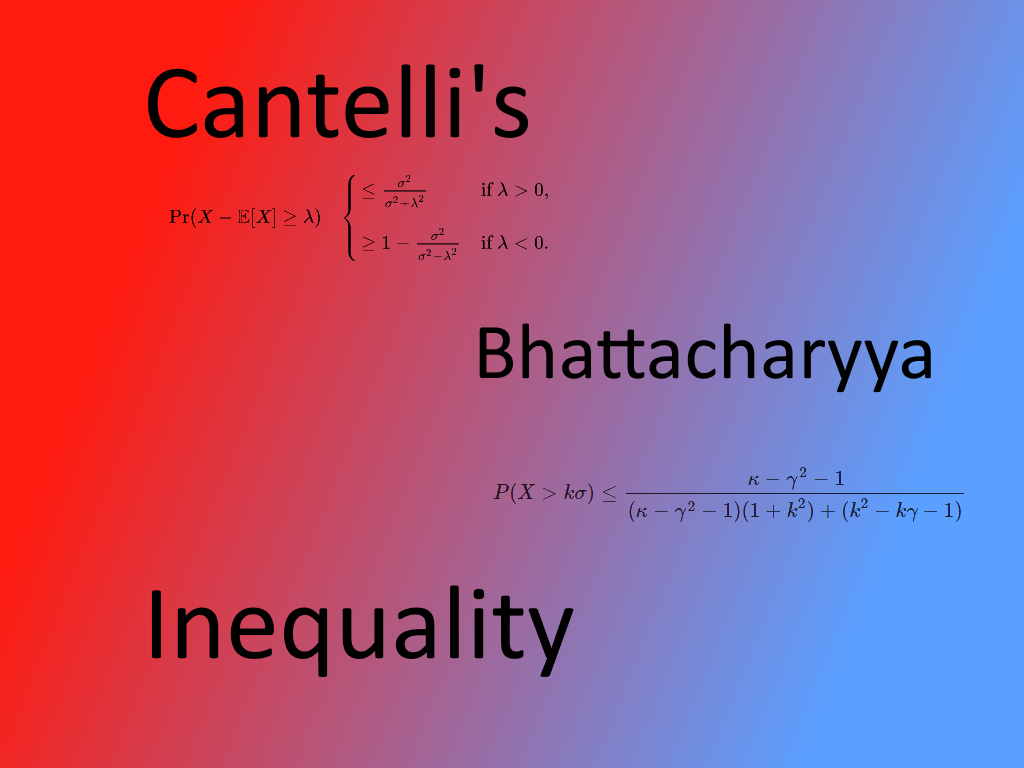


برای درک و آشنایی با اصطلاحات به کار رفته در این نوشتار بهتر است مطالب متغیر تصادفی، تابع احتمال و تابع توزیع احتمال و امید ریاضی (Mathematical Expectation) — مفاهیم و کاربردها را مطالعه کنید. همچنین خواندن نوشتار توزیع تجمعی — به زبان ساده نیز خالی از لطف نیست.
نامساوی کانتلی و باتاچاریا
فرض کنید متغیر تصادفی با تابع احتمال مشخص شده است. امید ریاضی و واریانس این متغیر تصادفی نیز متناهی و مشخص بوده و به ترتیب با نمادهای و نشان داده میشود. نامساوی مارکف و چبیشف به منظور پیدا کردن کران بالا برای تابع احتمال (تابع بقاء) متغیر تصادفی به کار میروند. البته نامساوی کانتلی و باتاچاریا نسبت به دو نامساوی قبلی بهتر عمل کرده و برای کران بالای احتمال، مقادیر تیزتری دارند.
نامساوی کانتلی (Cantelli's Inequality)، حالت عمومیتری برای نامساوی چبیشف را ارائه میکند. به همین علت برای یادآوری ابتدا نامساوی چبیشف را در نظر میگیریم.
نامساوی چبیشف: متغیر تصادفی با شرایط بالا را در نظر بگیرید. در این صورت برای هر خواهیم داشت:
همانطور که مشاهده میکنید این نامساوی برای قدر مطلق فاصله متغیر تصادفی از میانگین و همچنین مقادیر مثبت نوشته شده است. ولی در نامساوی کانتلی این محدودیتها برداشته شده است.
این نامساوی به افتخار «فرانچسکو کانتلی» (Francesco Paolo Cantelli) که در سال ۱۹۲۸ این نامساوی را معرفی کرد، نامگذاری شده است. او ایده و محاسبات خود را براساس نامساوی چبیشف بنا نهاد.
نامساوی چبیشف بیان میکند که احتمال فاصله متغیر تصادفی از میانگین آن (قدر مطلق فاصله) چه رابطهای با مضارب واریانس آن متغیر تصادفی دارد. در حالیکه در نامساوی کانتلی (که گاهی آن را نامساوی چبیشف-کانتلی هم مینامند) احتمال بزرگتر یا کوچکتر بودن متغیر تصادفی از میانگینش محاسبه میشود.
نامساوی کانتلی و اثبات آن
صورت نامساوی کانتلی به شکل زیر است:
رابطه ۱
که در آن متغیر تصادفی با اندازه احتمال و امید ریاضی و واریانس است.
البته میتوان با ترکیب دو حالت با از رابطه ۱ به رابطه زیر رسید.
رابطه ۲
نکته: فرض بر این است که واریانس متغیر تصادفی از صفر بزرگتر است. یعنی داریم .
اثبات
دو حالت و را بطور جداگانه در نظر میگیریم. در نتیجه اثبات را به دو بخش تقسیم میکنیم. ابتدا متغیر تصادفی را در نظر بگیرید. واضح است که در این حالت داریم:
حالت
برای هر میتوان نوشت:
بوسیله نامساوی مارکف رابطه بالا را به صورت نامساوی مینویسیم.
رابطه ۳
از آنجایی که نامساوی بالا به ازاء همه مقادیر برقرار است، مقداری از را پیدا میکنیم که طرف راست نامساوی را کمینه کند.
با مشتقگیری از طرف راست نامساوی برحسب داریم:
پس
که با صفر قرار دادن صورت خواهیم داشت:
پس مقداری است که رابطه ۱ را کمینه میسازد پس را در آن قرار میدهیم.
رابطه ۴
به این ترتیب حکم یعنی نامساوی کانتلی ثابت میشود.
حالت
در این حالت در نظر گرفته شده و برای مینویسیم:
رابطه ۵
مشخص است که با در نظر گرفتن به کمک نامساوی مربوط به رابطه ۴، نامساوی رابطه ۵ نوشته شده است. با در نظر گرفتن متمم پیشامد (طرف چپ نامساوی رابطه ۵) میتوان نوشت:
به این ترتیب نامساوی کانتلی برای هر دو حالت، اثبات شد.
کاربرد نامساوی کانتلی
یکی از نکات جالبی که از نامساوی کانتلی میتوان نتیجه گرفت فاصله بین میانگین و میانه یک توزیع است. نامساوی کانتلی نشان میدهد که فاصله بین میانگین و میانه در هر توزیع، هرگز از یک انحراف معیار بزرگتر نخواهد بود.
برای روشنتر شدن موضوع متغیر تصادفی با میانگین و میانه و انحراف معیار را در نظر بگیرید. باید نشان دهیم که رابطه زیر برای این سه پارامتر برای هر متغیر تصادفی، برقرار است.
برای اثبات این قضیه، فرض میکنیم که در نامساوی کانتلی باشد.
نکته: اگر نامتناهی باشد که قضیه به راحتی اثبات میشود. پس فرض میکنیم که انحراف معیار متناهی است.
برای شروع، نامساوی کانتلی را به صورت زیر بازنویسی میکنیم.
حال، علامت متغیر تصادفی را تغییر میدهیم. واضح است که میانگین آن هم تغییر علامت خواهد داد، زیرا . پس خواهیم داشت:
از طرفی با توجه به مفهوم میانه متغیر تصادفی، میتوانیم نامساویهای زیر را برای بنویسیم:
پس نتیجه خواهیم گرفت، تعداد نقاطی که یک انحراف معیار از میانگین فاصله دارند از تعداد نقطههایی که از میانه کوچکترند، کمتر هستند. در نتیجه:
در نوشتارهای قبلی در مورد نامساویهای آماری، مقایسهای بین مقدار واقعی احتمال و کران بالای آن با استفاده از زبان برنامهنویسی برای توزیعهای دوجملهای و نرمال ارائه کردیم. این کار را هم برای نامساوی کانتلی در ادامه تکرار خواهیم کرد.
مقایسه نامساوی کانتلی برای توزیع دو جملهای
فرض کنید متغیر تصادفی دو جملهای (Binomial Distribution) با پارامترهای n=15 و p=۰٫5 داریم. به ازاء مقادیر مختلف نمودار مربوط به احتمال و کرانهای بالای نامساویهای کانتلی را رسم میکنیم. کد زیر به این منظور نوشته شده است.
حاصل اجرای این برنامه، نموداری است که در تصویر زیر دیده میشود. همانطور که مشخص است نامساوی کانتلی بسیار به مقدار واقعی احتمال نزدیک است.

مقایسه نامساوی کانتلی برای توزیع نرمال
متغیر تصادفی با توزیع نرمال با پارامترهای میانگین و واریانس را در نظر بگیرید. به ازاء مقادیر مختلف به کمک برنامه و کدهای زیر، نمودار مربوط به احتمال و کرانهای بالای نامساویهای کانتلی را رسم میکنیم.
نتیجه اجرای این برنامه توسط یک نمودار مطابق با تصویر زیر دیده میشود. باز هم مشخص است که طرف راست نامساوی کانتلی به مقدار واقعی احتمال بسیار نزدیک است.

نامساوی باتاچاریا (Bhattacharyya Inequality)
یک نامساوی دیگر که به صورت تعمیم یافته نامساوی کانتلی است، نامساوی باتاچاریا (Bhattacharyya Inequality) نام دارد که در سال ۱۹۸۷ طی مقالهای برای تعمیم نامساوی چبیشف و کانتلی توسط دانشمند هندی «برید باران باتاچاریا» (Barid Baran Bhattacharya) معرفی شد.

در این نامساوی از گشتاورهای مرتبه سوم و چهارم متغیر تصادفی استفاده میشود.
فرض کنید که و واریانس هم مثبت باشد. در این صورت اگر و باشد، آنگاه برای تابع احتمال متغیر تصادفی خواهیم داشت:
به شرطی که باشد. البته اگر مقدار به حد کافی بزرگ باشد، رابطه قبل محقق خواهد شد.
نکته: گشتاور سوم و چهارم در اینجا به مانند میزان چولگی (Skewness) و کشیدگی (Kurtosis) توزیع متغیر تصادفی عمل میکنند. در نتیجه زمانی نامساوی باتاچاریا موثر است که میزان کشیدگی متغیر تصادفی زیاد باشد.
خلاصه و جمعبندی
در این نوشتار به بررسی و مقایسه نامساویها کانتلی و باتاچاریا پرداختیم. همچنین اثبات نامساوی کانتلی را در دو حالت مرور کردیم. هر چند این نامساویها نسبت به نامساوی چبیشف و مارکف، تیز تر هستند ولی به علت سهولت، نامساوی مارکف و چبیشف بیشتر به کار میروند.
در صورت علاقهمندی به مباحث مرتبط در زمینه ریاضی و آمار، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار و احتمالات
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای ریاضیات
- توزیعهای آماری — مجموعه مقالات جامع وبلاگ فرادرس
- متغیر تصادفی و توزیع برنولی — به زبان ساده
- توزیع نرمال یک و چند متغیره — مفاهیم و کاربردها
^^










