



کدون چیست؟ – مختصر و مفید
نوکلئوتیدها واحدهای ساختاری ژنوم هستند و از طریق تولید پروتئینها، کلیه فعالیتهای سلول را هدایت میکنند. برای این کار، نوکلئوتیدها باید در یک الگوی منظم، خوانده شوند و رونوشتی را پدید آورند. این رونوشت، در گام بعد، در قالب کدهای سهتایی که کدون نام دارند، به پروتئین، ترجمه میشود. کار ترجمه در ماشین پروتئینسازی سلول، یعنی ریبوزوم انجام میشود. اما ریبوزوم، از کجا نقطه آغاز و پایان ترجمه را تشخیص میدهد؟ از کجا میداند رشته mRNA باید در کدام قالب، ترجمه شود؟ اسیدهای آمینه، چطور در جای صحیح خود درون پروتئین، قرار میگیرند؟ اینها و پرسشهای دیگری از این دست، مطالبی هستند که در این نوشتار، به آنها پاسخ خواهیم داد.


کدون چیست؟
کدونها، مجموعههای سهتایی از نوکلئوتیدهای رشته mRNA هستند که هریک، اتصال اسید آمینه خاصی را در فرایند ترجمه، هدایت میکنند. به عنوان مثال، کدون AUG، رمزکننده اسید آمینه متیونین است و UUU فنیل آلانین را رمز میکند. اتصال صحیح تعداد مشخصی از اسیدهای آمینه، در نهایت، یک زنجیره پروتئینی را ایجاد میکند که در مراحل بعد، با ایجاد انواع پیوندهای شیمیایی، به صورت سه بعدی درمیآید و عملکرد خود را در سلول، آغاز میکند.

افزونگی (انحطاط) کدونی
همانطور که مشخص است، ترجمه DNA، اطلاعات را از زبان ۴ حرفی نوکلئوتیدی به زبان ۲۰ حرفی اسید آمینهای تبدیل میکند. اگر هر کدون، تنها از یک نوکلئوتید تشکیل شده بود، امکان ایجاد رمز، تنها برای ۴ اسید آمینه فراهم میشد. کدونهای دو حرفی نیز تنها رمزگشایی از ۱۶ اسید آمینه را امکانپذیر میکردند. با ایجاد جایگاههای سه حرفی، ۶۴ کدون ایجاد میشود که بسیار بیشتر از تعداد انواع اسیدهای آمینه است. سلول، از این ویژگی، استفاده هوشمندانهای کرده است؛ برخی از اسیدهای آمینه، با بیش از یک کدون، فراخوانی میشوند. این ویژگی، «انحطاط کدون»، «هرز بودن کدون» یا «افزونگی کدون» (Codon Degeneracy) نام دارد.
میدانیم، tRNAها مسئول انتقال اسیدهای آمینه به ریبوزوم هستند تا در آنجا طبق الگوی mRNA در کنارهم چیده شوند. بنابراین، هر مولکول tRNA دارای دو جایگاه مهم است:
- جایگاه اتصال به اسید آمینه (A-site)
- جایگاه اتصال به کدون (آنتی کدون)
اگر اسید آمینهای دارای بیش از یک کدون باشد، به این معنی است که tRNAهای مختلفی در سلول وجود دارند که همگی، دارای جایگاه اتصال یکسان برای آن اسید آمینه هستند. اما توالی آنها در جایگاه آنتی کدون، متفاوت است و هرکدام میتوانند به یک کدون خاص، متصل شوند. به این ترتیب، مجموعه این کدونهای مختلف، اسید آمینه واحدی را رمز خواهد کرد.
این ویژگی، وقتی جذابتر میشود که بدانیم، غلظت همه tRNAها در سلول، یکسان نیست. برخی از آنها فراوانتر و گروهی دیگر، «کمیاب» (Rare) هستند. بنابراین، اسید آمینه هدف را کندتر در اختیار ریبوزوم قرار میدهند. وجود کدونهای موسوم به Rare در یک توالی ژنی، ترجمه آن را به کندی و با تاخیر به پیش خواهد برد. در حالی که وجود کدونهای «پُریاب» در آن، ترجمه را سرعت میبخشد. سلول، از این ویژگی، برای تنظیم بیان ژنها استفاده میکند.
جالب است بدانید غلظت tRNAها در سلولهای مختلف نیز با هم متفاوت است. به این ترتیب، ممکن است tRNA خاصی در سلول انسان، پُریاب و در سلول ای. کولی، کمیاب باشد. پژوهشگران علم ژنتیک، از این ویژگی برای تنظیم بیان ژنهای بیگانه، در سلولهای میزبان استفاده میکنند. در هر موجود زنده، فراوانی نسبی کدونهای رمزکننده آمینو اسیدهای مختلف، در جدولی به نام «جدول ارجحیت کدونی» (Codon Usage Table) جمعآوری میشود که نمونهای از آن در ادامه آورده شده است.

فرضیه باز لغزان چیست؟
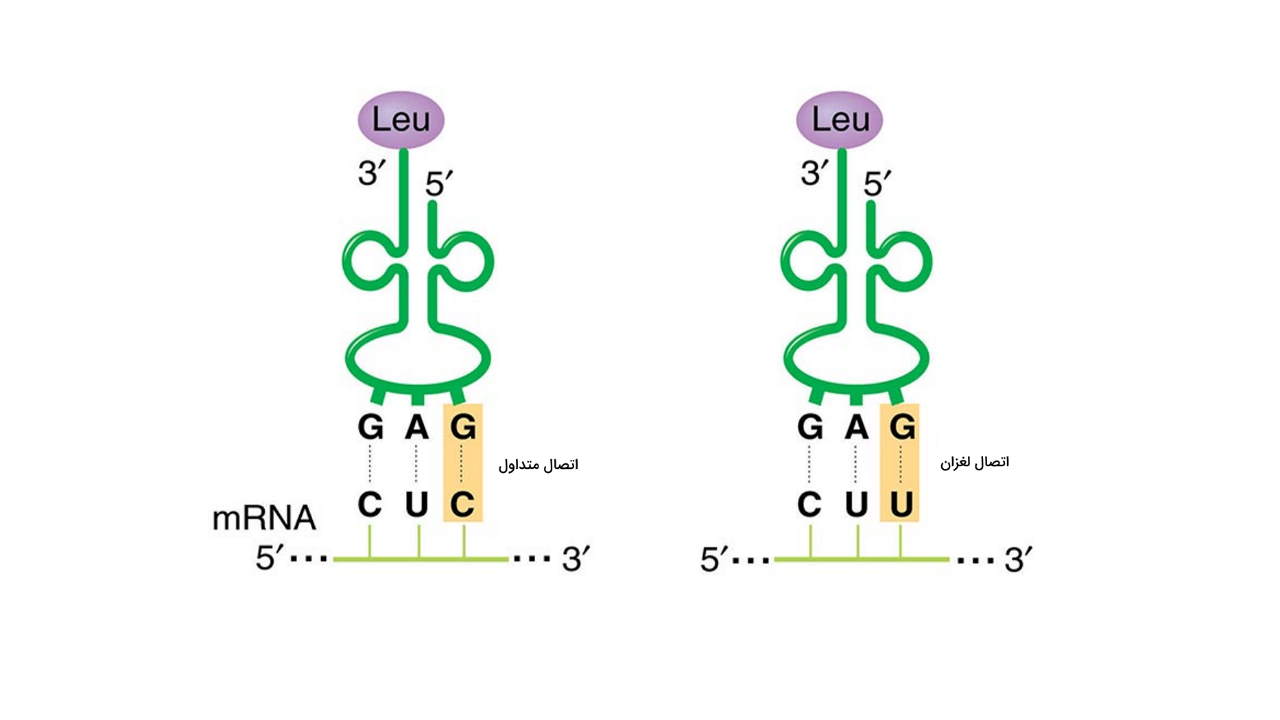
واژه «لغزان» در این اصطلاح، به معنی تلوتلوخوردن یا حرکت ناپایدار است. «فرضیه باز لغزان» (Wobble Hypothesis)، که نخستین بار، در سال 1966، توسط فرانسیس کریک، برای توجیح هرز بودن کدونها مطرح شد، بیان میکند که باز سوم در کدون mRNA ممکن است با یک الگوی غیر واتسون-کریکی، با باز اول آنتی کدون tRNA جفت شود. به عنوان مثال، اگر باز سوم کدون باشد، امکان اتصال به هریک از را داراست. این پدیده به یک tRNA واحد اجازه میدهد تا بیش از یک کدون را تشخیص دهد.
دو باز اول کدون mRNA، به روش معمول واتسون-کریک، پیوندهای هیدروژنی را با بازهای مکمل خود، بر روی آنتی کدون tRNA تشکیل میدهند. همانطور که میدانیم، در این الگوی جفتشدگی، آدنین فقط با تیمین و گوانین، فقط با سیتوزین، جفت باز تشکیل میدهند. اما تشکیل پیوندهای هیدروژنی بین باز سوم در کدون و باز اول در آنتیکدون، به طور بالقوه میتواند به روشی غیر از واتسون-کریک رخ دهد. بنابراین گاهی، جفت بازهای متفاوتی در این موقعیت ایجاد خواهند شد.

قوانین فرضیه باز لغزان
طبق فرضیه باز لغزان، باز اول آنتیکدون، بر خلاف دو باز دیگر، از نظر فضایی، محدودیتی ندارد و بنابراین میتواند با بازهای مختلفی، جفت شود و پیوندهای هیدروژنی برقرار کند. نتیجه این جفت شدنهای غیر متداول، به صورتهای زیر نمود مییابد:
- اگر A در موقعیت سوم کدون باشد، میتواند با U یا I در جایگاه اول آنتیکدون، جفت شود.
- اگر U در موقعیت سوم کدون باشد، میتواند با A ،G یا I در جایگاه اول آنتیکدون، جفت شود.
- اگر G در موقعیت سوم کدون باشد، میتواند با C یا U در جایگاه اول آنتیکدون، جفت شود.
- اگر C در موقعیت سوم کدون باشد، میتواند با G یا I در جایگاه اول آنتیکدون، جفت شود.
«I» نوکلئوزید اینوزین است که با حذف یک گروه آمینه از آدنوزین در tRNA تشکیل میشود. این فرایند، توسط آنزیمی به نام آنتی کدون دآمیناز انجام میشود.

به طور کلی، آنالیز توالیهای نوکلئوتیدی و پروتئینی، گام مهمی در مسیر دستورزیهای ژنتیکی به شمار می رود. برخی از این بررسیها در سطح اسیدهای نوکلئیک، مواردی مانند شناسایی ORFها و جایگاههای برش و در مورد پروتئینها مواردی مانند فراوانی هر یک از اسیدهای آمینه و برخی ویژگیهای بیوشیمیایی را در بر میگیرد. نرم افزارهای مختلفی در این زمینه تولید شدهاند که یکی از قدرتمندترین آنها CLC Main Workbrench است.

کدونهای آغاز و پایان
گفتیم فرایند ترجمه در ماشینهای ترجمه سلولی، یعنی ریبوزومها انجام میشود. فرض کنید یک رشته mRNA به طول 1800 نوکلئوتید، وارد ماشین ترجمه شود. با یک حساب ساده، انتظار داریم رشتهای به طول 600 اسید آمینه به دست آید. اما، در عمل، رشته پروتئینی حاصل، تنها 200 اسیدآمینه، طول دارد. چرا؟ بخشی از پاسخ این پرسش، به وجود اینترون و اگزونها برمیگردد. اما بخش دیگر، در کدونهای تنظیمی، نهفته است که مشخص میکنند ترجمه در کجا باید آغاز شود و در کدام نقطه به پایان برسد. به این نکته، بسیار مهم، دقت کنید:
mRNA یوکاریوتی، در تمام طول خود، ترجمه نمیشود. بلکه ترجمه، در جایی، پایین دست نقطه آغاز رونویسی، شروع میشود و در جایی، بالادست نقطه پایان آن، به اتمام میرسد.
تقریبا در همه موجودات زنده، کدون AUG به عنوان کدون آغاز و کدونهای UAG، UGA و UAA به عنوان کدونهای پایان، شناخته میشوند. کدون AUG، علاوه بر اینکه با همکاری اجزای دیگری روی mRNA، نقطه آغاز ترجمه را به ریبوزوم، نشان میدهد، در سلولهای یوکاریوتی و آرکی باکترها، tRNA حامل متیونین و در میتوکندری، کلروپلاست و باکتریها، tRNA حامل فرمیل-متیونین (fMet) را نیز، فراخوانی میکند. به همین دلیل، اگر سری به پایگاههای اطلاعاتی بزنید، خواهید دید که توالی خام پروتئینها در بیشتر موارد، با یکی از این دو اسید آمینه، آغاز شده است.
کدونهای آغاز جایگزین
با این وجود، علاوه بر AUG، کدونهای آغاز دیگری، هم در یوکاریوتها و هم در پروکاریوتها یافت میشوند. این «کدونهای آغاز جایگزین» (Alternate START Codons)، اگر در جایگاه دیگری در طول زنجیره mRNA باشند، اسیدهای آمینهای غیر از متیونین را کد میکنند، اما وقتی به عنوان کدونهای آغاز، در جایگاه ترجمه قرار میگیرند، tRNA دیگری را فراخوانی میکنند که حامل متیونین است.
گروهی از کدونهای آغاز جایگزین، «کدونهای غیر AUG» (یا Non-AUG Codons) هستند، که به ندرت در ژنومهای یوکاریوتی یافت میشوند. اما مواردی از آنها در سلولهای مختلف، گزارش شده است. به عنوان مثال، سلولهای پستانداران، علاوه بر مسیر متداول متیونین، میتوانند ترجمه را با آمینو اسید لوسین شروع کنند. در این حالت، کدون CUG در به جای AUG در جایگاه آغاز ترجمه قرار میگیرد و با کمک یک لوسیل-tRNA (tRNA حاوی لوسین) ترجمه آغاز میشود. ژنومهای میتوکندریایی از AUA و AUU در انسان و GUG و UUG در پروکاریوتها (آرکی باکترها) به عنوان کدونهای جایگزین START استفاده میکنند.
فراوانی کدونهای آغاز، در موجودات مختلف، بررسی شده است. به عنوان مثال، در بین پروکاریوتها، فراوانی هریک از کدونهای آغاز در باکتری اشرشیا کولی (E. coli) در جدول زیر نشان داده شده است.
| کدون آغاز | AUG | GUG | UUG |
| فراوانی | ٪83 | ٪14 | ٪3 |
یکی از اپرانهای پرکابرد در ای. کولی، اپران lac است که متابولیسم لاکتوز را بر عهده دارد. نواحی کدکننده lacA و lacI در این اپران، کدون آغاز AUG ندارند و در عوض، به ترتیب، از کدونهای UUG و GUG به عنوان کدونهای شروع، استفاده میکنند.
تفاوت کدون با کد ژنتیکی
تا اینجا، به خوبی با مفهوم «کدون» آشنا شدیم. حالا میتوانیم اصطلاح «کد ژنتیکی» (Genetic Code) را معرفی و درباره اختلاف ظریف آن با کدون، بحث کنیم. کدون، یک توالی سه نوکلئوتیدی است که یک اسید آمینه خاص را رمز میکند. اما کد ژنتیکی، مفهومی است که بیان میکند چه ارتباطی بین نوکلئوتیدهای موجود در توالی DNA یک ژن خاص، و اسیدهای آمینه موجود در توالی پروتئینی حاصل از آن، وجود دارد. در واقع، کد ژنتیکی، از کدونها برای ایجاد این ارتباط، کمک میگیرد.
مجموعه کدونها و اسیدهای آمینه رمزشده توسط آنها، معمولا در جدولی مرتب میشوند که «جدول کد ژنتیکی» (Genetic Code Table) نام دارد و نمونهای از آن در ادامه آورده شده است. همانطور که مشخص است، در این روش، بازها، به ترتیب، از چپ به راست، در سه ضلع جدول، نوشته میشوند و مثل جدول ضرب، خانههای جدول، پر خواهد شد.

نوع دیگری از نمایش کدهای ژنتیکی نیز وجود دارد که به نمایش دایرهای، معروف است. در این شیوه، بازهای موجود در کدون، به ترتیب، حلقههای بزرگتر دایره را پر میکنند و سرانجام، کدونهای سهتایی، در آخرین حلقه نوشته میشوند.
همانطور که از این شیوه نمایش پیداست، افزونگی کدونی، در بیشتر موارد، به سومین باز موجود در کدون، برمیگردد. یعنی بیشترین میزان جهشهای (نسبتا) بیاثر، در این جایگاه رخ داده است.

قالب خواندن باز چیست؟
یک «قالب خواندن باز» (Open Reading Frame) بخشی از یک مولکول DNA است که وقتی به اسیدهای آمینه تبدیل شود، عاری از کدون توقف باشد. کد ژنتیکی، توالی DNA را در کدونهای سهتایی میخواند. این بدان معناست که یک مولکول DNA دو رشتهای میتواند در هر یک از شش قالب ممکن خواندن - سهتا در جهت جلو و سهتا در جهت عکس - خوانده شود. یک قالب خواندن باز و طولانی، احتمالاً بخشی از یک ژن است.





دمت گرم واقعا نیازش داشتم برای مرور خیلی محشر بود مرسی❤️❤️❤️
عالی و جامع توضیح دادید
سپاس