



بوت استرپ در پایتون – راهنمای کاربردی
یکی از روشهای قدرتمند رایانهای در حوزه استنباط آماری، «بوت استرپ» (Bootstrap) است. این روش بدون در نظر گرفتن شرایط پیچیده، سعی در تخمین خطای برآوردگرها دارد. برای مثال برای ایجاد «فاصلههای اطمینان» (Confidence Interval)، «مدلهای رگرسیونی» (Regression Models) و همچنین در حوزه «یادگیری ماشین» (Machine Learning) برای تخمین خطای مدل، میتوان از روش بوتاسترپ استفاده کرد. در این نوشتار به منظور پیادهسازی الگوریتم بوت استرپ از زبان برنامهنویسی پایتون استفاده خواهیم کرد. بوت استرپ در لغت به معنی تسمهای است که بر روی چکمه قرار داشته و پوشیدن آن را سادهتر میکند. در مباحث آماری نیز به منظور برآورد راحتتر و سادهتر پارامترهای جامعه آماری، از تکنیک بوتاسترپ استفاده میشود.


در این نوشتار به بررسی شیوه عملکرد بوت استرپ پرداخته و بوسیله کدهایی از پایتون آن را پیادهسازی خواهیم کرد. در دیگر نوشتارهای فرادرس با عنوان جک نایف و بوت استرپ (Jackknife and Bootstrap) روش های بازنمونه گیری — به زبان ساده با مفهوم این شیوه تخمین آشنا شدهاید. از طرفی مطالعه متن نمونه گیری و بازنمونه گیری آماری (Sampling and Resampling) — به زبان ساده نیز خالی از لطف نیست.
بوت استرپ در پایتون
هر چند روش بوتاسترپ شامل مبانی عمیق آماری است ولی در این نوشتار به بررسی سادهای از این مفهوم خواهیم پرداخت. البته برای پیاده سازی محاسبات مربوط به این تکنیک، از زبان برنامهنویسی «پایتون» (Python) کمک خواهیم گرفت.
به هر حال برای درک روش بوت استرپ باید با مفاهیمی آماری که در فهرست زیر قابل مشاهده است، آشنا باشید.
- مفاهیم اولیه ریاضیات و توابع
- میانگین و واریانس
- توابع توزیع آماری و تابع احتمال
- توزیع نمونهای
- قضیه حد مرکزی، قانون اعداد بزرگ و همگرایی در احتمال
- تابع توزیع تجربی و تابعکهای آماری
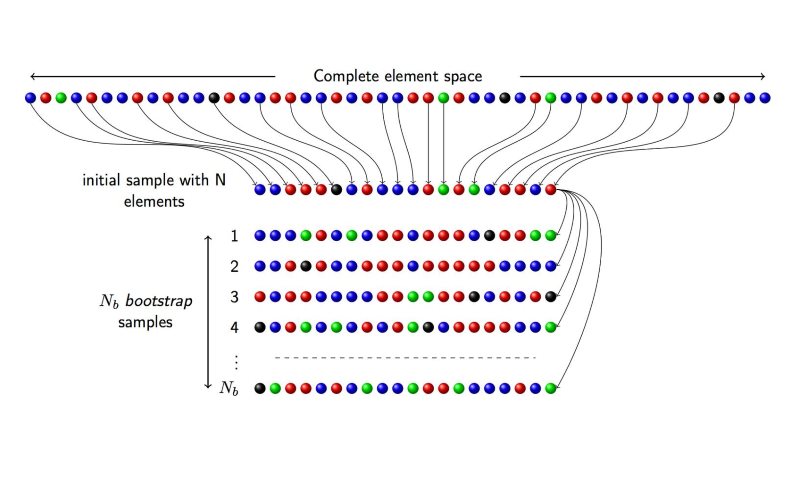
همانطور که گفته شد، هدف از روش به کارگیری بوت استرپ، استنباطی در مورد برآوردگر پارامتر جامعه آماری است. روش بوت استرپ به کمک تکنیک نمونهگیری با جایگذاری (بازنمونهگیری) سعی میکند که بهترین برآورد را برای خطای برآوردگرها با توجه به حجم نمونه محدود، بدست آورد. البته نمونههای حاصل از بازنمونهگیری، مستقل از یکدیگر هستند. مراحل مربوط به تکنیک بوتاسترپ را میتوان به صورت نمادین در زیر مشاهده کرد.

این گامها به صورت زیر هستند.
- گام ۱: استخراج یک نمونه از جامعه آماری با حجم .
- گام ۲: تهیه یک زیرنمونه از نمونه حاصل از گام ۱ با جایگذاری با حجم و تکرار این عمل به تعداد بار. به این زیرنمونهها به اصطلاح نمونههای بوتاسترپ (Bootstrap Sample) گفته میشود. به این ترتیب به تعداد نمونه بوتاسترپی خواهیم داشت.
- گام ۳: برآوردگر پارامتر جامعه آماری () را براساس هر یک از نمونههای حاصل از نمونههای بوتاسترپ، محاسبه و در مجموع به تعداد برآوردگر مختلف برای پارامتر بدست خواهد آمد.
- گام ۴: به کمک این برآوردگرها، و تعیین توزیع نمونهای آنها، خطای برآورد یا فاصله اطمینان برای برآوردگر پارامتر قابل محاسبه است.
در این نوشتار میخواهیم نحوه کار روش بوتاسترپ را بررسی کنیم. به منظور این کار بهتر است برای سه سوال زیر به دنبال پاسخ بگردیم.
- علت معرفی روش بوتاسترپ توسط دانشمند آمار «بردلی افرون» (Bradley Efron) چیست؟ انگیزه او از این کار چه بوده است؟
- چرا روشهای شبیهسازی در بوت استرپ به کار میرود؟ چگونه بوسیله بازنمونهگیری برآورد واریانس برای یک آماره محاسبه میشود؟
- ایده بازنمونهگیری با جایگذاری به چه علت در بوتاسترپ استفاده میشود؟
۱. انگیزه اصلی برای معرفی روش بوتاسترپ: برآورد خطای برآوردگر
ریشه و انگیزه اصلی استفاده از تکنیک بوتاسترپ، استفاده از سرعت رایانههای مدرن به منظور انجام استنباط آماری است. «افرن» این روش را برای تعیین میزان دقت برآوردگرها در مسائل تحلیل آماری ابداع کرد. به عنوان یک اصل، بعد از تخمین پارامتر توسط برآوردگر باید میزان خطای تخمین نیز که همان دقت برآوردگر است، تعیین شود. برای روش شدن این موضوع به بررسی یک مثال میپردازیم.
مثال
فرض کنید قرار است مشخص کنید در یک روز، هر دانشآموز چند بار از تلفن هوشمند استفاده میکند. مدرسه مورد نظر، شامل ۱۰۰ دانشآموز است. از آنجایی که بررسی همه دانشآموزان و محاسبه این متغیر به سختی میسر است، براساس پرسشنامه آنلاین از دانشآموزان میخواهید در این تحقیق مشارکت کنند. در پایان دوره تحقیق، ۳۰ دانشآموز پرسشنامه را تکمیل کردهاند و براساس این دادهها، میانگین تعداد دفعاتی که از تلفن هوشمند استفاده میکنند برابر با 228.06 بار است. این مسئله را به کمک کدهای پایتون شبیهسازی کردهایم. ابتدا کتابخانهها را بارگذاری میکنیم.
سپس نمونه تصادفی با حجم ۱۰۰ تولید و آن را در متغیر pickups قرار میدهیم.
نتیجه خروجی میتواند به صورت زیر در آید. این اعداد تعداد دفعات استفاده از گوشی همراه را نشان میدهد.
همانطور که مشاهده میشود، ۱۰۰ مقدار شبیهسازی شده است. میانگین این مقدارها نیز برابر با 252.7 است که میتوان آن را میانگین جامعه آماری در نظر گرفت.
از طرفی انحراف استاندارد برای این مقدارها را نیز محاسبه میکنیم تا نشان دهیم چه میزان پراکندگی در بین دادهها وجود دارد.
نتیجه اجرای این دستور، انحراف استاندارد را 144.25342 نشان میدهد. در ادامه یک نمونه ۳۰ تایی از این جامعه تهیه میکنیم و محاسبات مربوط به میانگین و انحراف استاندارد را برای این نمونه بدست میآوریم.
براساس نمونهای که تهیه شده، میانگین برابر با 228.0666 و انحراف استاندارد نیز 166.96890 محاسبه میشود.
خطا یا انحراف استاندارد برای میانگین محاسبه شده توسط رابطه زیر بدست میآید.
بنابراین انحراف استاندار یا خطای برآورد میانگین با استفاده از کد زیر محاسبه میشود.
در مباحث آمار استنباطی، محاسبات و کارهایی که برای این مثال صورت گرفت، «برآورد نقطهای» (Point Estimation) نامیده میشود. در برآورد نقطهای، به کمک مشاهدات حاصل از نمونه، سعی میکنیم پارامتر جامعه را تخمین بزنیم. به این ترتیب دو واژه در درک این مسئله دخیل هستند.
- برآوردگر/ آماره: تابعی از نمونه تصادفی که به منظور برآورد پارامتر جامعه به کار میرود، مانند میانگین نمونهای ().
- پارامتر جامعه: مقداری عددی که به عنوان یک شاخص به منظور شناسایی بهتر جامعه آماری به کار میرود، مانند میانگین جامعه ().
با توجه به این مفاهیم، سوالی که بوسیله روش بوتاسترپ پاسخ خواهیم داد، میزان دقت یا خطای برآوردگرها است.
از آنجایی که تفاوت در مقدار نمونهها وجود دارد، نمیتوان همیشه مقدار پارامتر را با مقدار برآورد آن یکسان در نظر گرفت. میانگین نمونهای از نمونهای به نمونه دیگر متفاوت خواهد بود در حالیکه پارامتر جامعه (میانگین جامعه آماری) همیشه ثابت و یکسان است. بنابراین با توجه به مقدارهای مختلف برآوردگر برای نمونههای متفاوت میتوان این سوال را مطرح کرد که دقت برآوردگر چقدر است؟
خطای استاندارد
خطای استاندارد برای یک برآوردگر، همان انحراف استاندارد آن است. این شاخص نشان میدهد که مقدار برآورد چه میزان از مقدار واقعی دور است. مطابق با آنچه در تئوری آمار برای محاسبه خطای استاندارد میانگین داریم، لازم است که انحراف استاندارد جامعه معلوم باشد تا بتوان خطای استاندارد را محاسبه کرد.
در اینجا خطای استاندارد میانگین را با و انحراف استاندارد جامعه آماری را با نشان دادهایم. مشخص است که منظور از نیز اندازه نمونه است.
متاسفانه در اکثر مواقع، انحراف استاندارد جامعه آماری نامشخص است. بنابراین ابتدا باید برای آن یک برآورد مشخص کنیم. به نظر میرسد که انحراف استاندارد نمونهای میتواند برآورد خوبی برای انحراف استاندارد جامعه آماری باشد. بنابراین رابطه بالا را به صورت زیر بازنویسی میکنیم.
نکته: برآوردگر نااریب برای انحراف استاندارد جامعه آماری مطابق با رابطه زیر بدست میآید.
به همین علت در محاسباتی که در پایتون دیده میشود، برآورد برای انحراف استاندارد (خطای برآورد) برآوردگر برابر با 30.48 شده است.
تفسیر خطای برآورد
حال که میزان خطای برآوردگر محاسبه شد، باید از آن در استنباط آماری مربوط به میانگین استفاده کنیم. بهتر است این موضوع را بیشتر مورد بررسی قرار دهیم.
از آنجایی که برآوردگر، تابعی از نمونه تصادفی است، دارای مقدارهای تصادفی نیز خواهد بود و از نمونهای به نمونه دیگر، تغییر خواهد کرد. فرض کنید یک برآوردگر دارای توزیع نرمال یا تقریبا نرمال است. با توجه به توزیع احتمالی نرمال، برای برآوردگر مورد نظر، انتظار داریم که در فاصله یک انحراف استاندارد از میانگین، ۶۸٪ مقدارهای برآوردگر را ببینیم. همچنین به نظر میرسد که با توجه به توزیع نرمال، در فاصله دو انحراف استاندارد از میانگین، تقریبا ۹۵٪ از مقدارهای برآوردگر قرار داشته باشد.
به یاد دارید که اندازه نمونه برای مثال ما برابر با ۳۰ است. با توجه به «قضیه حد مرکزی» (Central Limit Theorem) میتوانیم توزیع میانگین نمونهای را نرمال فرض کنیم و برای برآوردگر، یک فاصله اطمینان ۹۵٪ تشکیل دهیم.
نکته: ضریب ۲ در محاسبه این فاصله اطمینان براساس دو انحراف استاندارد نوشته شده است. البته میدانیم که مقدار دقیق برای این ضریب 1.96 است که همان صدک توزیع نرمال استاندارد است زیرا باید بالایی و 2.5٪ پایین این توزیع حذف شود تا ناحیه میانی شامل ۹۵٪ دادهها باشد.
به منظور استفاده از قوانین و قواعد استنباط آماری باید شرایط زیر برقرار باشد.
- خطای استاندارد میانگین نمونه، براساس انحراف استاندارد جامعه (یا برآورد آن) قابل محاسبه باشد.
- توزیع برآوردگر نرمال یا تقریبا نرمال باشد.
متاسفانه در اکثر مواقع، از توزیع واقعی جامعه آماری مطلع نیستیم و نمیتوانیم وجود شرایط بالا را بررسی کنیم. از طرفی امکان تشخیص توزیع برآوردگر و یا محاسبه انحراف استاندارد آن به راحتی میسر نیست. برای مثال تشخیص توزیع میانه (Median) در بسیاری از مواقع امکان پذیر نیست و نمیتوانیم انحراف استاندارد آن را مشخص کنیم.

یکی از روشهای تعیین خطای برآورد در چنین حالتهایی استفاده از تکنیک بوتاسترپ است. بنابراین هرگاه یک یا هر دو شرط بالا محقق نشده باشد، بوتاسترپ میتواند برآورد نسبتا دقیقی از خطای برآوردگر در اختیار ما قرار دهد.
۲. چرا روشهای شبیهسازی در بوت استرپ به کار میروند؟
برای آنکه بتوانیم نحوه عملکرد روش بوتاسترپ را درک کنیم، ابتدا چند مفهوم مهم آماری را مرور میکنیم. فرض کنید قرار است که انحراف استاندارد یک آماره را برآورد کنیم تا بتوانیم در مورد این آماره به یک استنباط آماری (مانند آزمون فرض یا فاصله اطمینان) برسیم. شرایطی که با آن روبرو هستیم در زیر فهرست شدهاند.
- هیچ اطلاعی از توزیع احتمالی جامعه آماری نداریم.
- روش مشخص و تحلیلی برای تعیین توزیع یا انحراف استاندارد برآوردگر در اختیار ما نیست.
متغیرهای تصادفی را یک نمونه آماری از جامعه با تابع توزیع در نظر بگیرید. فرض کنید که آماره برای پارامتر مورد نظر ما باشد. قرار است واریانس را محاسبه کنیم. از آنجایی که هیچ اطلاعی از توزیع جامعه آماری نداریم، مقدار واریانس برآوردگر یعنی (Var(M را نمیتوانیم مشخص کنیم. بنابراین لازم است که واریانس را برآورد کنیم. این برآورد را با مشخص میکنیم.
از آنجایی که در دنیای واقعی هستیم، به سادگی و با روش تحلیلی محاسبه این واریانس کار دشوار و سختی است. بنابراین باید به صورت تقریبی این واریانس را برآورد کنیم. به روش شبیهسازی (Simulation) میتوان با تقریب مناسب، واریانس برآوردگر را بدست آورد. در این قسمت از شبیهسازی فرض بر این است که جامعه آماری () را میشناسیم.
شبیهسازی (Simulation) با پایتون
شبیهسازی، تکنیکی مفید برای بدست آوردن توزیع آماری نمونه به کمک رایانه است. البته شبیهسازی دارای یک شرط مهم و قوی است که آن هم آگاه بودن از مشخصات و ویژگیهای جامعه آماری است. به منظور شبیهسازی و محاسبه واریانس برآوردگر، مراحل زیر را طی میکنیم.
- یک نمونه تصادفی با اندازه از جامعه تهیه (شبیهسازی) میکنیم.
- آماره مورد نظر () را براساس این نمونه محاسبه میکنیم.
- مراحل ۱ و ۲ را به تعداد مشخصی (مثلا ) بار تکرار میکنیم تا (مقدار برآوردگر مورد نظر) حاصل شود.
- میانگین (Mean) و واریانس (Variance) را برای ها (مقدارهایی که از مرحله ۳ حاصل شده) را بدست میآوریم.

با توجه به قانون اعداد بزرگ (Law of Large Numbers) میدانیم که میانگین حاصل از این فرآیند به میانگین جامعه آماری نزدیک خواهد شد. به این ترتیب تقریبا مطمئن هستیم که با بزرگ شدن مقدار ، میانگین برآوردگرهای به سمت پارامتر واقعی جامعه میل میکند. همچنین با افزایش مقدار میانگین حاصل از واریانسها نیز به واریانس واقعی برآوردگر نزدیک و نزدیکتر خواهد شد.

به این ترتیب با استفاده از رایانهها، میتوانیم این محاسبات تکراری را بارها و بارها انجام دهیم تا به برآوردی به دقت بالا (واریانس کوچک) برسیم.
در ادامه با استفاده از کد پایتون به بررسی مثال مربوط به گوشیهای هوشمند پرداختهایم. در این جا تعداد تکرارها بار است و خواهیم دید که میانگین و انحراف استاندارد برآوردگر حاصل از نمونهها به مقدار واقعی بسیار نزدیک خواهد شد.
ورودی ۱:
ورودی ۲:
خروجی 2:
ورودی 3:
خروجی 3:
ورودی 4:
خروجی ۴؛
ورودی ۵:
خروجی ۵:
ورودی ۶:
خروجی ۶:
ورودی ۷:
خروجی ۷:
ورودی ۸:
خروجی ۸:
ورودی ۹:
خروجی ۹:
ورودی ۱۰:
ورودی ۱۱:
ورودی ۱۲:
ورودی ۱۳:
خروجی ۱۳:

ورودی ۱۴:
خروجی ۱۴:
ورودی ۱۵:
خروجی ۱۵: مقایسه انحراف استاندارد برآوردگر با انحراف استاندار حاصل از شبیهسازی
تابع توزیع تجربی (Empirical Distribution Function)
در قسمت قبل، ایده مربوط به استفاده از شبیهسازی را در تکنیک بوتاسترپ مورد بررسی قرار دادیم. حال باید تقریبی برای واریانس برآوردگر یعنی ایجاد کنیم. متاسفانه برای انجام شبیهسازی احتیاج به اطلاعاتی در مورد توزیع جامعه آماری داشتیم در حالیکه، این اطلاعات همیشه در دسترس نیست. خوشبختانه یکی از بخشهای مهم در بوت استرپ تشخیص یا تعیین توزیع جامعه به کمک تابع توزیع تجربی است.
«تابع توزیع تجربی» (Empirical Distribution Function) یا با اختصار EDF به عنوان تقریبی برای تابع توزیع تجمعی (Cumulative Distribution Function- CDF) به کار میرود. این تقریب برای اندازه نمونههای بزرگ به خوبی عمل میکند. تابع توزیع تجربی، یک توزیع گسسته است که وزنهای یکسانی به هر مشاهده میدهد. برای مثال اگر تعداد نقاط مشاهده شده در نمونه برابر با باشد (یک نمونه تای موجود باشد) مقدار احتمال براساس تابع توزیع تجربی برای مشاهده هر یک از نقاط برابر با خواهد بود.
به این ترتیب تابع توزیع تجربی را میتوان به صورت یک «تابع پلهای» (Step Function) در نظر گرفت.
تابعکهای آماری (Statistical Functional)
در مباحث آماری، به توابعی که برحسب تابع توزیع تجمعی (CDF) نوشته میشوند، «تابعک آماری» (Statistical Functional) گفته میشود. بنابراین با توجه به روابط زیر میتوان امید ریاضی (Mathematical Expectation) و واریانس (Variance) را به عنوان تابعکهای آماری در نظر گرفت.
همینطور، بسیاری از شاخصهای جامعه آماری، مانند «میانه» (Median) و «چندکها» (Quantiles)، تابعک آماری محسوب میشوند. به این ترتیب اگر را تابع توزیع تجمعی متغیر تصادفی در نظر بگیریم، آماره را میتوان به صورت تابعی مثل از در نظر گرفت. بنابراین خواهیم داشت:
حال به بحث مربوط به بوتاسترپ باز میگردیم. همانطور که به یاد دارید باید به کمک نمونهگیری و یا بازنمونهگیری برای برآوردگر، خطا یا میزان دقت را اندازهگیری کنیم. از آنجایی که دقت یا خطا را با واریانس مرتبط میدانیم، مشخص است که باید از تابعکهای آماری و تابع توزیع تجربی استفاده کنیم. فرض کنید که پارامتر مورد نظر باشد، یعنی برحسب تابع توزیع و تابع داریم . به این ترتیب اگر برآورد پارامتر مورد نظر را با و تابع توزیع تجربی را با نشان دهیم، خواهیم داشت:
نکته: از آنجایی که «برآوردگر حداکثر درستنمایی» (Maximum Likelihood Estmator- MLE) برای است، برای برآورد هم میتوان از استفاده کرد. به این ترتیب در چنین مواردی، رابطه زیر برقرار است.
برای مثال اگر پارامتر مورد نظر، میانگین جامعه آماری () باشد میتوان براساس تصویر زیر نحوه برآورد آن را به کمک تابعکها و تابع توزیع تجمعی تجربی مشخص کرد. از طرفی با توجه به خاصیت برآوردگرهای نااریب، میدانیم با افزایش حجم نمونه، متوسط برآوردگرها به مقدار واقعی پارامتر میل خواهد کرد.

به این ترتیب از آنجایی که به کمک روش بوتاسترپ، تابع توزیع تجربی (EDF) را به عنوان برآوردی برای تابع توزیع تجمعی (CDF) در نظر میگیریم، میتوانیم تابعی مثل از تابع توزیع تجمعی را به کمک همان تابع از تابع توزیع تجربی، برآورد کنیم. فرض کنید برآوردگر ما باشد. مراحل انجام این کار به صورت زیر خواهد بود.
- براساس نمونه تصادفی، برآوردگر تابع توزیع تجربی (EDF) را محاسبه میکنیم.
- به کمک تابع برآوردگر را بدست میآوریم. یعنی
فرض کنید منظور برآورد میانگین جامعه () باشد. از آنجایی که تابع توزیع تجربی، تابعی گسسته است، مراحل بالا، به کمک رابطههای زیر پیادهسازی میشود.
برآورد تابع توزیع تجربی -EDF
برآورد واریانس به روش بوت استرپ
همانطور که به یاد دارید، هدف از اجرای روش بوتاسترپ، برآورد واریانس یک برآوردگر بود. بر این مبنا، موارد زیر را باید در این روش در نظر بگیریم.
- توزیع واقعی جامعه آماری مشخص نیست، بنابراین در روش بوتاسترپ باید از تابع توزیع تجربی (EDF) استفاده کرد.
- برای محاسبه تابع توزیع تجربی از نمونه تصادفی که از جامعه آماری تهیه شده است، کمک میگیریم.
- برای بدست آوردن برآورد از تابع توزیع تجربی و بهره خواهیم برد.
- از شبیهسازی برای تعیین واریانس برآوردگر استفاده خواهیم کرد.
همانطور که به یاد دارید، در شبیهسازی باید توزیع جامعه آماری مشخص باشد. ولی از آنجایی که در روش بوتاسترپ، چنین اطلاعاتی در دسترس نیست، لازم است که از برآورد تابع توزیع تجمعی، یعنی تابع توزیع تجربی استفاده کنیم. به این ترتیب برآورد را به کمک بار تکرار عمل نمونهگیری و محاسبه برآوردگر، بدست میآوریم. واریانس مقدارهای حاصل از تکرارها نیز واریانس برآوردگر را مشخص میکند. به این ترتیب براساس چهار گام، محاسبات را انجام میدهیم.
- یک نمونه از تابع توزیع تجربی (EDF) استخراج میکنیم.
- برآوردگر را بدست میآوریم.
- مراحل ۱ و ۲ را به تعداد بار تکرار میکنیم.
- برای بدست آوردن دقت (واریانس) برآوردگر ، واریانس مقدارهای حاصل از مرحله ۳ را محاسبه میکنیم.
ایده باز نمونهگیری با جایگذاری به چه علت در بوت استرپ استفاده میشود؟
از آنجایی که تابع توزیع تجربی، برای هر مشاهده وزن ثابت و یکسانی در احتمال در نظر میگیرد، میتوان آن را یک نمونهگیری با جایگذاری در نظر گرفت. به این ترتیب داریم:
به همین علت بازنمونهگیری را در روش بوتاسترپ به صورت با جایگذاری در نظر میگیرند پس هنگام شبیهسازی نیز باید این نکته رعایت شود. به این ترتیب یک نمونه تصادفی از مشاهدات با جایگذاری انتخاب میشود. فرض کنید نمونه اولیه به صورت و نتیجه بازنمونهگیری به شکل باشند.

همانطور که در بخش شبیهسازی گفته شد، با توجه به مشخص بودن توزیع در جامعه آماری میتوانیم شبیهسازی را مبنای محاسبه واریانس برآوردگر در نظر بگیریم. به تصویر زیر که برآورد پارامتر و واریانس آن را به کمک شبیهسازی نشان میدهد، توجه کنید.
نمونههای گرفته شده در این شبیهسازی از جامعهای با توزیع مشخص و ثابت تهیه شدهاند. از آنجایی که در روش بوتاسترپ، مشخصات و ویژگیهای جامعه آماری مشخص نیست، از برآورد تابع توزیع تجمعی استفاده خواهیم کرد. به تصویر زیر در این زمینه توجه کنید.

پیاده سازی الگوریتم بوت استرپ با پایتون
در ادامه کد پایتون، به منظور پیادهسازی الگوریتم بوتاسترپ دیده میشود. در هر مرحله، ورودی و خروجی مشخص شدهاند. در این کد فرض بر این است که میانگین و واریانس آن باید براساس یک نمونه تصادفی برآورد شود.
Bootstrap Simulation
Statistic: Mean
ورودی ۱۷:
خروجی ۱۷:
ورودی ۱۸:
ورودی ۱۹:
ورودی ۲۰:
# simulated standard deviation of mean
bootmean_std = np.std(boot_means)
ورودی ۲۱:
خروجی 21:
ورودی ۲۲:
خروجی ۲۲:
همانطور که میبینید مقدار پیشبینی شده انحراف استاندارد (جذر واریانس) براساس روش بوتاسترپ (26.850034) به مقدار انحراف استاندارد میانگین نمونهای براساس دادهها ۱۰۰ تایی (26.580034) بسیار نزدیک است.
نتیجهگیری
همانطور که مشخص شد، تفاوتهای مهمی بین روش شیبهسازی و بوتاسترپ وجود دارد. تصویر زیر این دو روش را به خوبی مقایسه کرده است.

در این نوشتار، سعی کردیم که برای درک عملکرد روش بوت استرپ به اصطلاحات آماری پیچیده نپردازیم و براساس مثالهای عددی و تصویرهای مختلف، با این تکنیک آماری آشنا شویم. امروزه با توجه به قدرت پردازش زیاد رایانهها و امکانات شبیهسازی میتوانیم برآوردهای با دقت مناسب را به کمک روش بوت استرپ ایجاد کنیم.
اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزش های SPSS
- مجموعه آموزش های Minitab
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش روش های نمونه برداری و بازرسی در کنترل کیفیت
- نمونهگیری و بازنمونهگیری آماری (Sampling and Re-sampling) — به زبان ساده
- جامعه آماری — انواع داده و مقیاسهای آنها
- جک نایف و بوت استرپ (Jackknife and Bootstrap) روش های باز نمونهگیری — به زبان ساده
^^









