شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
در آموزشهای قبلی مجله فرادرس، با کنترل بهینه آشنا شدیم. حل معادلاتی که در رگولاتورهای مرتبه دوم خطی به دست آوردیم، تحت شرایط غیر از حالت ماندگار کار دشواری است. در این موارد میتوان از روشهای عددی استفاده کرد. یکی از این روشها، برنامه ریزی پویا (Dynamic Programming) است که میتوان به راحتی آن را به مسئله گسسته رگولاتور مرتبه دوم خطی (LQR) اعمال کرد. برنامهریزی پویا یک روش کارآمد برای حل انواع خاصی از مسائل بهینهسازی است و اولین بار، «ریچارد بلمن» (Richard Bellman) آن را ارائه کرد.
روش برنامه ریزی پویا انعطافپذیری بالایی دارد و میتوان از آن برای حل مسائل متنوعی استفاده کرد. از این مسائل میتوان به مسیریابی، صرف کمترین هزینه در جابهجایی بین دو شهر، برنامهریزی موجودی، کنترل بهینه و... اشاره کرد. هدف اصلی در برنامه ریزی پویا محاسبه یک تابع هزینه در هر حالت است. وقتی نقشه این تابع هزینه به دست آید، قانون کنترل بهینه را میتوان از یک حالت به حالت دیگر که هزینه را کمینه میکند به دست آورد. مسئله عمومی برنامهریزی پویا را میتوان به صورت زیر نمایش داد:
J(x[k])=u[k]min[L(x[k],u[k],x[k+1])+J(x[k+1])]
در بسیاری از موارد، عبارت بالا به صورت زیر اصلاح میشود:
J(x[k])=u[k]min[L(x[k],u[k],x[k+1])+γJ(x[k+1])]
عامل γ مقادیر آینده هزینه رو به جلو را کاهش میدهد. اگر γ=0، آنگاه در الگوریتم، از مقدار هزینه رو به جلو کاملاً چشمپوشی میشود، در حالی که اگر γ بزرگ باشد، مقادیر آینده مورد توجه بیشتری قرار میگیرند. وجود γ در آن دسته از روشهای عددی نیز مفید است که در آنها مقدار هزینه رو به جلو را برای شروع نمیدانیم و آن را به صورت بازگشتی تخمین میزنیم. ضریب γ اثرات مفروضات اشتباه اولیه را کاهش میدهد.
بنابراین، با استفاده از برنامه ریزی پویا حل مسئله کنترل بهینه به یافتن تابع هزینه رو به جلو تقلیل مییابد. این کار را میتوان با حل رو به عقب از حالت مطلوب تا به همه مقادیر اولیه ممکن انجام داد. وقتی این تابع هزینه رو به جلو را یافتیم، قانون کنترل بهینه به یافتن مسیری میانجامد که تابع هزینه را از وضعیت فعلی به یک وضعیت آینده کمینه میکند. روش برنامه ریزی پویا یک الگوریتم بسیار عمومی است و میتوان آن را به مسائل بهینهسازی اعمال کرد که در آنها هزینه رو به جلو و هزینه جابهجایی از یک حالت به حالت دیگر، جمع شونده است. قبل از پرداختن به جزئیات الگوریتم، یک مثال ساده را بیان میکنیم.
مثالی از برنامه ریزی پویا
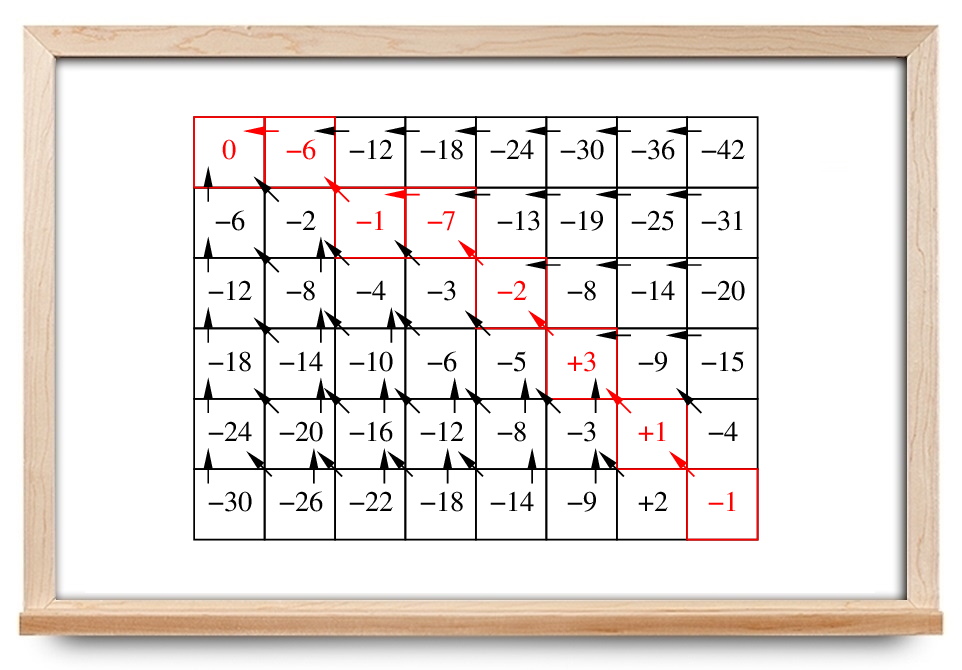
مسئله یافتن کوتاهترین مسیر بین یک هدف و هر نقطه شروع را روی شبکه شکل زیر در نظر بگیرید. فرض میکنیم فقط به سمت چپ، راست، بالا و پایین میتوانیم حرکت کنیم و هر حرکت یک واحد هزینه دارد.
شکل ۱: تشکیل برنامهریزی پویا
در مثال بالا، محاسبه مسیر بهینه با شروع از شرایط اولیه دشوار است. کار سادهتر، محاسبه هزینه رو به جلو با شروع از یک هدف (GOAL) و بازگشت به عقب است. بعد از گام اول، خانه بالا و پایین هدف، هزینه رو به جلویی برابر با ۱ خواهد داشت.
شکل ۲: هزینه رو به جلو بعد از یک گام برگشت به عقب
میتوانیم این گام را برای چهار چرخه بعدی انجام دهیم که در آن، هزینه رو به جلوی متناظر با هر خانه در شکل زیر مشخص شده است. توجه کنید که سلولهای بالا و سمت راستِ خانه متناظر با ۵ امتیاز، هر دو امتیاز ۶ دارند.
شکل ۳: هزینه رو به جلو بعد از یک مرحله بازگشت به عقب
نقشه هزینه رو به جلو برای موقعیت هدف مطابق شکل زیر است.
شکل ۴: هزینه رو به جلو بعد از دو گام برگشت به عقب
پس از صرف هزینه لازم برای پیکربندی شبکه هدف، میتوانیم از هر نقطهای از شبکه شروع کرده و با دنبال کردن مسیری که مجموع عمل (۱) و هزینه رو به جلو را کمینه میکند، به هدف برسیم. این الگوریتم، همان برنامه ریزی پویا است.
برنامه ریزی پویا برای کنترل رگولاتور خطی درجه دوم
در این بخش روند بالا برای محاسبه کنترل بهینه را برای یک سیستم خطی به فرم زیر بیان میکنیم:
X[k]=AX[k−1]+Bu[k−1]
میخواهیم کنترلکنندهای برای تابع هزینه زیر طراحی کنیم:
توجه کنید که x[N−1] به u[N−1] وابسته نیست. بنابراین، هزینه رو به جلوی بهینه را میتوان با استفاده از مشتقات ماتریسی و مشتقگیری نسبت به u[N−1] محاسبه کرد:
اگر J(x[N−1]) را به صورت 21X[N−1]TSN−1X[N−1] بنویسیم، آنگاه:
SN−1=Q+KN−1TRKN−1+(A−BKN−1)TSN(A−BKN−1)
عبارت بالا همان معادله ریکاتی است که قبلاً درباره آن صحبت کردیم و در آن S به جای P قرار گرفته است. اکنون عبارت هزینه رو به جلو بین (N−2) و (N−1) برابر است با:
برنامهریزی پویا برای سیستمهای پیوسته شامل گسستهسازی هزینه رو به جلو با محاسبه هزینه بین یک بازه و بازه بعدی به عنوان انتگرال هزینه کنترل است.
مثال برنامه ریزی پویا برای LQR
سیستمی با معادله x¨=u را در نظر بگیرید. میخواهیم کنترلی را پیدا کنیم که تابع هزینه زیر را کمینه کند:
J=21∫u=01u2dt
که هزینه نهایی برای کمینه شدن برابر است با:
Jf=21(10x2+10x˙2)
با گسستهسازی سیستم، مسئله را به برنامهریزی پویا تبدیل میکنیم:
dtd[x1x2]=[10dt1][x1x2]+[0dt]u
اکنون، پارامترهای متناظر با هزینه رو به جلو، SN=10I، Q=0 و R=dt هستند. از معادلات زیر برای محاسبه بازگشتی SN استفاده میکنیم و از حالتها رو به جلو انتگرال میگیریم برای محاسبه کنترل بهینه. در عمل، Q=0 نتایج عددی را ارائه میدهد که ناپایدار هستند، بنابراین، از Q=0.001dtI استفاده میکنیم.
KN−1=(R+BTSNB)−1BTSNAX[N−1]
SN−1=Q+KN−1TRKN−1+(A−BKN−1)TSN(A−BKN−1)
شکل ۵: نتایج مثال LQR
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
سید سراج حمیدی دانشآموخته مهندسی برق است و به ریاضیات و زبان و ادبیات فارسی علاقه دارد. او آموزشهای مهندسی برق، ریاضیات و ادبیات مجله فرادرس را مینویسد.
سلام برنامه ریزی پویا با چه نرم افزاری انجام میشه؟؟
پوریا نوید
با سلام و احترام؛
تکنیک برنامهریزی پویا را میتوانید با زبانهای برنامهنویسی رایج مانند پایتون یا نرمافزارهایی مانند متلب پیادهسازی کنید.
دورههای رایگان معرفی شده در زیر میتوانند راهنمای خوبی برای استفاده از این زبانها باشند.
سلام خسته نباشید
ببخشید برنامه ریزی تولید با روش برنامه ریزی پویا قابل حل می باشد ؟
مثال چند کالا داریم ولی تابع هدف که ماکس کردن سود هست ترکیبی از همه کالا ها هست و محدودیت ها هم وابسته یکدیگر هستند.
حقیقت
روش برنامه ریزی پویا به نسبت کنترل تمامی ترکیب های متغیر های تصمیم ، چگونه حجم محاسبات را کاهش می دهد؟
حقیقت
ممنون از سایت خیلی خوب و متلب کامل شما
می شه لطفا زود تر جواب سوال من را بدین
چون جواب این سوال را تا آخر هفته لازم دارم
باز هم ممنون از شما
حسین
با سلام و تشکر از آموزش تون.
در خط 25 ام از کد متلب تون از دستور dare استفاده شده است، اما توی قسمت help نرم افزار متلب، پیشنهاد داده است که به جای استفاده از دستور dare از دستور idare استفاده بشه. علت اینکه از این دستور استفاده شده چی هست؟
با تشکر
سید سراج حمیدی
سلام.
در راهنمای متلب توصیه شده بعد از نسخه R2019a از دستور “idare” به جای “dare” استفاده شود. در برنامه، دستور “dare” مربوط به نسخی قدیمیتر متلب به کار رفته بود که تصحیح شد و به “idare” تغییر یافت. البته استفاده از دستور “dare” تغییری در نتیجه نهایی ایجاد نمیکند، اما بهتر است آنچه را که راهنمای متلب پیشنهاد داده به کار ببرید.
از بازخورد دقیق و سازنده شما بسیار سپاسگزاریم.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.






















سلام برنامه ریزی پویا با چه نرم افزاری انجام میشه؟؟
با سلام و احترام؛
تکنیک برنامهریزی پویا را میتوانید با زبانهای برنامهنویسی رایج مانند پایتون یا نرمافزارهایی مانند متلب پیادهسازی کنید.
دورههای رایگان معرفی شده در زیر میتوانند راهنمای خوبی برای استفاده از این زبانها باشند.
برای شما آروزی موفقیت داریم.
سلام خسته نباشید
ببخشید برنامه ریزی تولید با روش برنامه ریزی پویا قابل حل می باشد ؟
مثال چند کالا داریم ولی تابع هدف که ماکس کردن سود هست ترکیبی از همه کالا ها هست و محدودیت ها هم وابسته یکدیگر هستند.
روش برنامه ریزی پویا به نسبت کنترل تمامی ترکیب های متغیر های تصمیم ، چگونه حجم محاسبات را کاهش می دهد؟
ممنون از سایت خیلی خوب و متلب کامل شما
می شه لطفا زود تر جواب سوال من را بدین
چون جواب این سوال را تا آخر هفته لازم دارم
باز هم ممنون از شما
با سلام و تشکر از آموزش تون.
در خط 25 ام از کد متلب تون از دستور dare استفاده شده است، اما توی قسمت help نرم افزار متلب، پیشنهاد داده است که به جای استفاده از دستور dare از دستور idare استفاده بشه. علت اینکه از این دستور استفاده شده چی هست؟
با تشکر
سلام.
در راهنمای متلب توصیه شده بعد از نسخه R2019a از دستور “idare” به جای “dare” استفاده شود. در برنامه، دستور “dare” مربوط به نسخی قدیمیتر متلب به کار رفته بود که تصحیح شد و به “idare” تغییر یافت. البته استفاده از دستور “dare” تغییری در نتیجه نهایی ایجاد نمیکند، اما بهتر است آنچه را که راهنمای متلب پیشنهاد داده به کار ببرید.
از بازخورد دقیق و سازنده شما بسیار سپاسگزاریم.