



انواع ایندکس در SQL – معرفی ۸ نوع Index
استفاده از انواع ایندکس در SQL یکی از سادهترین روشها برای ارتقا کلی عملکرد پایگاه داده و به طور خاص، عملکرد کوئریها است. اما به شرطی که نوع درست ایندکس را انتخاب کرده باشیم. ایندکس پایگاه داده، ساختار داده اضافی است که در سطحی بالاتر از دادههای درون جدول ایجاد میشود. شناخت انواع ایندکس در SQL بسیار مهم است. زیرا ایندکسهای مختلف، کاربردها و مزایایی مختلفی را نیز ارائه میدهند. در این مطلب از مجله فرادرس، رایجترین ایندکسهای مورد استفاده در SQL در بین مشهورترین سامانههای مدیریت پایگاههای داده رابطهای (RDBMS) را مورد بررسی قرار داده و بهترین زمان روش استفاده از هر کدام را توضیح دادهایم.
- با تأثیر انتخاب Index مناسب در بهبود عملکرد دیتابیس آشنا خواهید شد.
- فرق ساختاری و کاربردی انواع Index را میآموزید.
- خواهید توانست برای هر سناریو، بهترین نوع Index را انتخاب کنید.
- با ساختارهای دادهای درختی و Hash مرتبط با Index-ها آشنا میشوید.
- کاربرد Index-های اختصاصی مانند Bitmap و Function-based را فرا میگیرید.
- خواهید آموخت چگونه Index مناسب را برای پروژه خود طراحی کنید.




برنامه نویسان برای جدول مورد نظر خود ایندکس ایجاد کرده و ستون یا ستونهایی را به عنوان ایندکس تعریف میکنند. این ایندکسها به افزایش سرعت واکشی دادهها کمک میکنند. ایندکسها با کمک ستونهای مشخص شده، ساختارهایی برای جستوجوی سریعتر ایجاد میکنند. در این مطلب توضیح میدهیم که ایندکس چیست، انواع ایندکس در SQL را معرفی میکنیم و روش ایجاد ایندکس را نشان میدهیم. سپس انواع اندیکسها موجود را به طور کامل توضیح داده و به زمان استفاده از آنها نیز اشاره میکنیم.
انواع ایندکس در SQL کدام هستند؟
ایندکس در SQL Server ساختاری است که در حافظه ذخیره شده و با جدول یا «نما» (View) تجمیع میشود. ایندکسها برای پیدا کردن سریع و منظم ردیف یا مجموعهای از ردیفهای داده بهکار برده میشوند.
انواع مختلفی از ایندکسها در SQL وجود دارد که در این بخش به معرفی مهمترین آنها میپردازیم.
- «ایندکس خوشهای» (Clustered Index)
- «ایندکس بیتنگاشت» (Bitmap Index)
- «ایندکس معکوس» (Reverse Index)
- «ایندکس غیر خوشهای» (Non-Clustered Index)
- «ایندکس ذخیره ستونی» (Column Store Index)
- «ایندکس فیلتر شده» (Filtered Index)
- «ایندکس هش شده» (Hash Index)
- «ایندکس یکتا» (Unique Index)
در ادامه ایندکسهای معرفی شده بالا را با توضیح بیشتری تعریف خواهیم کرد.
دلیل اصلی ایجاد انواع ایندکس در SQL چیست؟
هدف اصلی از تعریف ایندکسهای پایگاه داده این است که با سریعتر کردن زمان واکشی دادهها، کارایی کوئریها را ارتقا بدهیم. این مسئله با استفاده از فضای ذخیرهسازی اضافی برای نگهداری ساختمانهای داده بدست میآید. منظور از ساختمانهای ذخیرهسازی داده مواردی مانند «درخت دودویی» (Binary Tree) است که به دادههای واقعی اشاره میکند.
ایندکسها به پایگاه داده کمک میکنند، در هر زمان که کوئری اجرا میشود، بدون نگاهکردن به همه سطرهای جدول در SQL با سرعت زیادی دادهها را در مکانهای مشخص شده ثبت یا از آن مکانها بخواند. ایندکسها روش کارآمدی را برای دستیابی به دادههای مرتب شده ارائه میدهند.
آموزش کامل SQL Server
SQL یا «زبان پرس و جوی ساختاریافته» (Structured Query Language)، زبانی است که برای مدیریت و ارتباط با پایگاههای داده رابطهای استفاده میشود. در حال حاضر SQL یکی از پرکاربردترین زبانها برای مدیریت پایگاههای داده رابطهای در سراسر جهان و در صنایع و سیستمهای تجاری فعال دنیا است. آموزش کار با این پایگاه داده قدرتمند باعث باز شدن موقعیتهای شغلی زیادی برای برنامهنویسان میشود.

وبسایت فرادرس به عنوان بزرگترین تولیدکننده محتوی آموزشی فارسی، تلاش کرده که همه زبانهای برنامهنویسی و تکنولوژیهای مربوط به مدیریت پایگاه داده را نیز پوشش دهد. به همین جهت فیلمهای آموزشی بسیار مناسبی را برای آموزش SQL Server تهیه کرده است. برای آموزش این پایگاه داده لازم است که زبان SQL را به شکل خوبی یاد بگیریم. با مشاهده منظم این فیلمها و تمرین هر روزه میتوانید، بر روی کار با پایگاههای دادهای که با زبان SQL کار میکنند، به طرز بسیار خوبی مسلط شوید. در ادامه چند مورد از این فیلمهای آموزشی را معرفی کردهایم.
- فیلم آموزش اس کیو ال سرور سطح مقدماتی با فرادرس
- فیلم آموزش SQL Server سطح تکمیلی با فرادرس
- فیلم آموزش کوئری نویسی پیشرفته در SQL Server با فرادرس
- فیلم آموزش پروژه محور ساخت دیکشنری برای دیتابیس با SQL Server در فرادرس
- فیلم آموزش SQL Server سطح پیشرفته فرادرس
معرفی انواع ایندکس در SQL با جزئیات
تا اینجای مطلب دلیل اصلی استفاده از ایندکسها را بیان کردهایم. در این بخش به بازبینی انواع اصلی ایندکسهای پایگاه های داده رابطهای میپردازیم. این ایندکسها میتوانند کیفیت و عملکرد کوئریهای نوشته شده را ارتقا دهند. شاید بعضی از این ایندکسها فقط بر روی نوع خاصی از موتورهای پایگاه داده در دسترس باشند، اما جای نگرانی نیست. زیرا در این بخش محل استفاده هر کدام از ایندکس را به طور کامل مشخص کردهایم.
همه ایندکسها از درخت جستوجویی برای ذخیرهسازی نشانگرهای ردیفهای داده استفاده میکنند. این درختهای جستوجو به شکلی طراحی شدهاند که عملیات خود را به صورت بهینهشدهای اجرا کنند. در واقع درختهای جستوجو مانند ستون فقرات ایندکسها عمل میکنند. رفتار درختهای جستوجو مانند رفتار درختهای جست و جوی دودویی است، تنها با این تفاوت که کمی پیچیدگی بیشتری دارند.
انواع مختلفی از ایندکسها وجود دارند که هر کدام از آنها ساختارهای داده داخلی متفاوتی را نیز شامل شده و برای استفاده در سناریو خاصی بهترین عملکرد را نشان میدهند. در ادامه مطلب به بررسی جزئیات بیشتری در این باره پرداختهایم. انواع ایندکسهای در دسترس را فقط به صورت خلاصه در فهرست زیر نامبردهایم.
دیدگاه ویژگی های صفات ایندکس ها
در این دیدگاه ایندکسها را بر اساس صفات ساختاری آنان تقسیم بندی میکنند. از دیدگاه ویژگیهای صفات ایندکسها میتوان آنها را به سه دسته اصلی زیر تقسیم کرد.
- «ایندکسهای اولیه» (Primary Index)
- «ایندکسهای خوشهای» (Clustered Index)
- «ایندکسهای ثانویه» (Secondary Index)
ایندکس های ارجاع داده شده
از دیدگاه تعداد ایندکسهای ارجاع داده شده به فایل داده، میتوان آنها را به دو دسته اصلی زیر تقسیم کرد.
- «ایندکس متراکم» (Dense Index)
- «ایندکس خلوت» (Sparse Index)
ایندکس های اختصاصی سازی شده
این نوع از ایندکسها به منظور انجام وظایف خاصی تعریف میشوند. ایندکسهای اختصاصیسازی شده برای استفاده در سناریوهای بسیار خاص را هم میتوان به صورت فهرست زیر، دستهبندی کرد.
- ایندکس Bitmap
- «ایندکس معکوس» (Reverse Index)
- ایندکس Hash
- «ایندکس فیلتر شده» (Filtered Index)
- «ایندکس بر پایه عملکرد» (Function-based Index)
- «ایندکس فضایی یا هندسی» (Spatial Index)
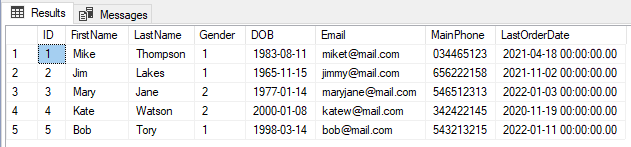
برای معرفی ایندکسهای بالا به همراه مثال از جدول مربوط به مشتریان Customer استفاده میکنیم. این جدول با توجه به فیلدهای زیر و دادههای فرضی ایجاد میشود. برای اینکه ببینیم دادههای نمونه شبیه به چه هستند، کوئری سادهای با کمک دستور SELECT در SQL نوشته و همه چیز را از جدول برمیگردانیم.
| نوع داده | نام ستون |
| int | ID |
| varchar(50) | FirstName |
| varchar(50) | LastName |
| int | Gender |
| date | DOB |
| varchar(100) | |
| varchar(50) | MainPhone |
| datetime2(2) | LastOrderDate |
دادههای جدول بالا به شکل زیر در خروجی نمایش داده میشوند.
۱. Clustered Index
یکی از رایجترین ایندکسها در سیستمهای پایگاه داده رابطهای مدرن و کارآزموده، «ایندکسهای خوشهای» یا «خوشهبندی شده» (Clustered Index) است. Clustered Index نظم فیزیکی دادهها را بر روی دیسک تعیین میکند. در واقع به طور ضمنی نظم ذخیره شدن دادهها در جدول را تعریف کند.
در بخش پایین درباره این مسئله مثالی را نمایش دادهایم. فرض کنیم همینطور که در پایین نمایش داده شده، دو ردیف اول جدول در صفحه ۱ قرار دارند، ردیفهای سوم و چهارم در صفحه ۲ و ردیف آخر در صفحه ۳ قرار میگیرد.

هدف اصلی ایندکسگذاری Clustered این است که ساختار فیزیکی دادههای ردیفها را بر اساس ستون انتخاب شده به شکل صعودی یا نزولی ذخیره کند. دلیل ایجاد چنین ایندکسی این است که همیشه دادهها را به صورت ذخیره شده داشته باشیم. این کار کمک بسیار زیادی در جستوجو به دنبال یک یا چند مقدار در محدوده مشخص شده میکند. اگرچه، ایندکس Clustered در زمان جستوجو در محدودههای مشخص شده بهترین عملکرد خود را نشان میدهد.
فرض کنیم که داشبورد گزارشات برنامه، همیشه مشخصات مشتریها را بر اساس حروف الفبای نام و نام خانوادگی آنها مرتب کرده و نمایش میدهد. بنابراین میخواهیم دادهها هم برای ذخیره شدن به صورت فیزیکی از ترتیب الفبایی نام FirstName و نام خانوادگی LastName استفاده کنند. برای اینکه ایندکس Clustered را برای رسیدن به این هدف، طراحی کنیم، باید کوئری را مانند مورد زیر بنویسیم.
ساخت ایندکس خوشهبندی شده با ترتیب صعودی بر روی ستونهای نام FirstName و نام خانوادگی LastName ، دادههای قرار گرفته در صفحات مختلف را برای همساز شدن با این ترتیب، بازچینی میکند. در نتیجه، وقتی که به صفحات داده نگاه میکنیم، دادهها با ترتیب الفبایی ظاهر خواهند شد. این مسئله میتواند بازدهی کوئریها را ارتقا دهد، بهخصوص در اجرای عملیاتی که نیاز به دادههای مرتبشده دارند. برای مثال میتوان به عملیات جمعاوری گزارشات اشاره کرد.

همینطور که در تصویر بالا مشاهده میشود، دادهها در ابتدا بر اساس نام FirstName و بعد از آن بر اساس نام خانوادگی LastName - اولویت حروف الفبا در نامها بالاتر از اولویت حروف الفبا در نام خانوادگی است - چیده شدهاند. اگر میخواستیم که ردیفها را بر اساس الفبا مرتب کنیم، این روش بهترین نتیجه را تولید میکرد. زیرا ردیفها از قبل به صورت مرتب شده ذخیره شدهاند. این مسئله به دوری کردن از اجرای عملیات مرتبسازی در کوئری کمک میکند.
اگر بخواهیم که ۱۰ مشتری اول را با ترتیب حروف الفبا نمایش دهیم، دیگر نیازی به جستوجوی کل جدول برای پیدا و انتخاب کردن مشتریها نیست. پایگاه داده فقط صفحات دادهای را برمیگرداند که شامل اطلاعات ۱۰ مشتری اول هستند. زیرا مشتریها از قبل بر اساس حروف الفبا به صورت مرتب و صعودی چیده شدهاند.
۲. Bitmap Index
این نوع از ایندکس را نمیتوان به عنوان یکی از اعضای ثابت انواع ایندکس در SQL در نظر گرفت، زیرا فعلا فقط بر روی پایگاه داده اوراکل در دسترس است و در سناریوهای بسیار خاصی کاربرد دارد، اما در جایگاه خودش جزو مهمترین و کاربردیترین ایندکسها است. برای مثال این ایندکس، وقتی که میخواهیم کوئری بنویسیم که با آن کوئری، کل ردیفهای جدولی را بر اساس ستون خاصی فیلتر کنیم. این ستون خاص، شامل اعداد کوچک و با مقادیر مجزا از هم است. در این شرایط استفاده از ایندکس Bitmap یکی از بهترین گزینههای ممکن است. این نوع ایندکس، به طور موثری چنین کوئریهایی را مدیریت میکند. Bitmap Index برای این کار از نگاشتهای بیتی برای نمایش حضور یا غیبت مقادیر استفاده میکند.
برای درک بهتر این مطلب، سناریویی را در نظر گرفتهایم که شامل دادههای نمونه ابتدای این مطلب است. در این سناریو میخواهیم از ایندکس Bitmap استفاده کنیم. تصور کنید که جدول مشتریان Customer این بار بیش از ۵ ردیف دارد. برای مثال، چیزی در حدود ۱۰ میلیون ردیف اطلاعات در این جدول ذخیره شده است. فرض کنیم که باید کوئری خود را برای پیدا کردن مشتریان خانمی فیلتر کنیم که نام فامیلی آنها «Watson » است.

برای حل این مسئله میتوان کوئری مانند کادر زیر نوشت.
در چنین مسائلی استفاده از ایندکس Bitmap عالی است. زیرا برای ویژگی جنسیت، مقادیر مجزای بسیار کمی - ۰ و ۱ یا مرد و زن - وجود دارند که عملیات مقایسه در طول ۱۰ میلیون ردیف را در کل جدول ممکن میکنند. برای اینکه اجرای کوئری بالا را با استفاده از ایندکس Bitmap سریعتر کنیم، با استفاده از سینتکس زیر ایندکس Bitmap را بر روی این جدول ایجاد میکنیم.
اکنون میتوانیم مشخصات خانم «Kate Watson» و ایمیل ایشان را - همینطور که در تصویر زیر نمایش داده شده- همراه با همه ردیفهایی که توسط کوئری مورد نظرمان از درون جدول استخراج شدهاند، به سادگی انتخاب کنیم.

ایندکس Bitmap، به خصوص وقتی که در بند JOIN درSQL تعریف شود، حتی میتوان عملکرد قدرتمندتری را نیز از خود نشان دهد. برای مثال، اگر جدول Customer را به جدول Sales الحاق کرده و دادههای کل را بر اساس جنسیت مشتریها فیلتر کنیم. ایندکس Bitmap در چنین سناریویی، شبیه به مورد پیادهسازی شده در پایین خواهد شد.
هر وقت که کوئری داشته باشیم که این دو جدول را به یکدیگر متصل کرده و دادهها را بر اساس جنسیت فیلتر کند، میتوان به بیشترین عملکرد این ایندکس دست پیدا کرد.
۳. Reverse Index
ایندکسهای Reverse شبیه به ایندکسهای معمولی هستند. با این تفاوت که این ایندکسها بهینهسازی شدهاند تا بهجای انجام دادن عملیات جستوجوی دادهها به صورت صعودی، آن را در جهت برعکس و به صورت نزولی انجام بدهند. در حالی که ایندکسهای معمولی در جستوجوهای صعودی از درخت جستوجوی دودویی برای رسیدن به حالت بهینه استفاده میکنند، ایندکسهای معکوس برای جستوجوهای سریعی طراحی شدهاند که در طی آنها دادهها را باید در حالت نزولی پیمایش کرد. سینتکس مورد استفاده برای ایجاد ایندکسهای معکوس شبیه به سینتکس ایندکسهای «غیرخوشهای» (Non-Clustered) است، اما به صورت واضح باید حالت معکوس یا نزولی را مشخص کرد.
فرض کنیم که قرار است مشتریهایی را پیدا کنیم که ۳ سفارش اخیر را ثبت کردهاند. باید این عملیات به صورت بهینهسازی شدهای انجام شود.
کلمه ضروری در سینتکس بالا DESC است. این کلمه به موتور پایگاه داده میگوید که ایندکسها را با ترتیب معکوس ایجاد کند. با کمک کد بالا هر وقت که در جدول Customer برای پیدا کردن ۳ سفارش اخیر کوئری بنویسیم، کوئری نوشته شده با بهترین عملکرد اجرا خواهد شد.
۴. Non-Clustered Index
این نوع از ایندکس، ساختاری را ارائه میدهد که به صورت مجزایی از ردیفهای داده تعریف میشود. این نوع از ایندکس در SQL server مقادیر کلیدی غیرخوشهبندی شده را پوشش میدهد. هر کلید به نشانگری متصل است که به ردیف دادههای حاوی اطلاعات مهم اشاره میکند.
در ایندکس «Non-Clustered» میتوانیم ستونهای غیر کلیدی بیشتری را در سطح برگ به پایگاه داده اضافه کنیم. این کار از طریق دور زدن محدودیتهای ایندکس و کمک به پوشش کامل همه کوئریها توسط ایندکس انجام میگیرد. ایندکسهای Non-Clustered برای افزایش کارایی کوئریهایی طراحی شدهاند که توسط ایندکسهای Clustered پوشش داده نمیشوند.
تفاوت اصلی بین ایندکسهای Clustered و Non-Clustered در SQL Server این است که ایندکس Non-Clustered دادهها را در یک مکان و ایندکسها را در مکان دیگری ذخیره میکند. در مقابل، ایندکسهای Clustered ردیفهای داده را در جدول بر اساس مقادیر کلیدی آنها ذخیره میکند.
۵. Column store Index
ایندکس Column یکی از انواع ایندکس در SQL Server است که برای ذخیرهسازی و اجرای کوئریها بر روی جدولهای «انبار داده» (Data Warehouse) بزرگ طراحی شده است. این ایندکس کارایی کوئریهایی را ارتقا میدهد که با مقدار بسیار زیاد داده کار میکنند.

این ایندکس دادهها را در قالب فشردهای ذخیره میکند. در نتیجه فرایند اجرای کوئریها با سرعت بیشتری انجام میگیرد. در مقایسه با ذخیرهسازی دادهها بر اساس ردیف، استفاده از ذخیرهسازی دادهها بر اساس ستون میتواند به اجرای سریعتر کوئریها کمک کند. همچنین با کمک این ایندکس عملیات مقایسه دادهها به صورت بهتری انجام میشود. زیرا معمولا دادههای موجود در ستون یکسان از ماهیت یکسانی نیز برخوردار هستند. با استفاده از این ایندکس در مصرف فضا هم برای ذخیرهسازی دادهها صرفهجویی میشود.
۶. Filtered Index
فرض کنیم که کوئری دلخواهی بر روی مجموعهای از دادهها اعمال شده است. ایندکس فیلتر شده در SQL Server، زمانی تولید میشود که تعداد کمی از ردیفهای ستون خاصی به کوئری مربوط شوند. وقتی جدولی شامل انواع مختلفی از داده است، ایندکس فیلتر شده میتواند برای کار بر روی تعداد یکی یا بیشتر از انواع دادههای خاص ساخته شود. این ایندکس فقط بر روی ردیفهای مرتبط باهم تمرکز میکند و به این صورت، اجرای کوئریها به صورت کارآمدتر و سریعتری انجام میشود.
۷. Hash Index
«Hash Index» یکی از انواع ایندکس در SQL server است که از تابع هش برای نگاشت کلیدها بر روی «ظرفهای» (Buckets) محتوی داده استفاده میکند. به فضاهای شبیه به آرایهای که برای نگهداری داده استفاده میشوند، ظرفهای محتوی داده گفته میشود. هر ظرف شامل ۸ بایت است که آدرس هر ردیف از داده در حافظه را نگهداری میکند. تابع هش به صورت F(K, N) است و مشخص میکند که هر ظرف به کدام کلید خاص تعلق دارد. این نوع از ایندکس از طریق پیدا کردن سریع ظرف درست برای هر کلید به واکشی سریعتر دادهها کمک میکند و در نتیجه در اجرای سریعتر عملیات جستوجو بسیار موثر است.
توجه: «تابع هش» (Hash Function)، تابعی است که مقداری را از ورودی دریافت کرده و با استفاده از آن، مقدار خروجی قطعی متناظر با مقدار ورودی را ایجاد میکند. برای آشنا شدن با تابع هش، پیشنهاد میکنیم که مطلب تابع هش یا درهم سازی (Hash Function) چیست؟ به زبان ساده را از مجله فرادرس مطالعه کنید.
۸. Unique Index
ایندکس یکتا در SQL Server تضمین میکند که کلیدهای ایندکس فقط شامل موارد یکتا باشند. به این معنا که هیچ مقدار تکراری برای استفاده در ایندکسها مجاز نیست. با کمک این ایندکس میتوان مطمئن شد که تقریبا هر ردیف در جدول به نوعی یکتا و مجزا از سایر ردیفها است. ایندکسهای یکتا بهویژه، زمانی مفید هستند که باید یکتایی دادههای ستون خاص یا ترکیبی از ستونها را حفظ کنیم. در نتیجه یکپارچگی دادهها نیز حفظ میشود.
علاوه بر موارد بیان شده، از طریق فراهم کردن اطلاعات اضافی درباره ساختار داده به بهینهسازی کوئری هم کمک میکند. بر اثر این کار، کارایی کوئریها از قبیل عملیات جستوجو و مرتبسازی دادهها بر اساس مقادیر یکتا، ارتقا مییابد.
انواع ایندکس در SQL را چگونه ایجاد کنیم؟
سامانههای مختلف «مدیریت پایگاههای داده رابطهای» (Relational Database Management Systems | RDBMS) برای ساخت ایندکسها تفاوت کمی در سینتکس با هم دارند. علاوه بر این، هر موتور پایگاه دادهای نیز ممکن است که گزینههای مختلفی را در زمان ساخت ایندکسها به کاربران ارائه دهد. اگرچه، برای ساخت ایندکسها سینتکس کلی وجود دارد. با کمک آن سینتکس میتوان در موتورهای پایگاه داده مختلف ایندکس ساخت.
سینتکسی که در ادامه نمایش داده شده، روش ساخت ایندکس را به صورت خام نشان میدهد.
اکنون باید این سینتکس را بر روی جدول واقعی اعمال کنیم. فرض کنید که جدولی به نام Customer مانند جدول نمایش داده شده زیر در اختیار داریم. اکنون برای افزایش دادن سرعت جستوجوی دادهها را بر اساس نام مشتریان، میخواهیم ایندکس خاصی را ایجاد کنیم.
| نوع داده | نام ستون |
| int | ID |
| varchar(50) | FirstName |
| varchar(50) | LastName |
| int | Gender |
| date | DOB |
| varchar(100) | |
| varchar(50) | MainPhone |
| datetime2(2) | LastOrderDate |
به کمک کدهای پایین در جدول بالا بر روی ستونهای FirstName و LastName ایندکسی تعریف میکنیم.
وقتی که کد بالا اجرا شود، این سینتکس، ایندکسی به نام IX_CustomerName را بر روی جدول Customer ایجاد میکند. با کمک ایندکس ایجاد شده، میتوانیم با سرعت بسیار بیشتری به جستوجوی دادههای درون ستونهای FirstName و LastName بپردازیم.
ایندکسی که ایجاد شده در پشت صحنه خود دارای نوع داده خاصی است. این سینتکس میتواند از نوع Non-Clustered یا ایندکس جستوجوی باینری باشد. این نوع از ایندکسها به کاربران پایگاه داده کمک میکنند تا کوئریهای بهینهسازی شدهتری را در سناریوهایی مانند کوئری نوشته شده در پایین، اجرا کنند.
در زمان بهینهسازی کوئریها، رویکرد عمومی این است که وجود ایندکس را در ستونهای استفاده شده عبارتهای فیلترکننده مانند WHERE و JOIN و ORDER BY در SQL بررسی کنیم. اگر ستونهای نامبرده شده در بند SELECT بسیار شبیه به ستونهای فیلتر کننده - ستونهایی که در عبارتهای فیلتر کننده نامبرده شدهاند - باشند، در نتیجه کوئری بهینهسازی شده است و زمان اجرای آن سریع خواهد بود. اگرچه معمولا اضافه کردن ایندکس به این سادگی کافی نیست.
ایندکس ها از چه ساختار داده ای استفاده می کنند؟
همینطور که قبلا اشاره کردیم، ایندکسها در بالای همه ساختارهای داده پیادهسازی شدهاند تا عملیات جستوجو را بهینهسازی کنند. در این بخش میبینیم که این ساختارهای داده چه هستند.
Balanced Tree
رایجترین ایندکسها در پشت صحنه خود از ساختار «درخت متوازن» (Balanced Tree) برای سرعت بخشیدن به عملکرد کوئریها استفاده میکنند. بیشتر موتورهای پایگاههای داده یا از درخت متوازن استفاده میکنند یا از نوع خاصی از درختهای متوازن مانند «درخت بی» (B Tree). در تصویر زیر ساختار «درخت متوازن عادی» (General Balanced Tree) نمایش داده شده است.
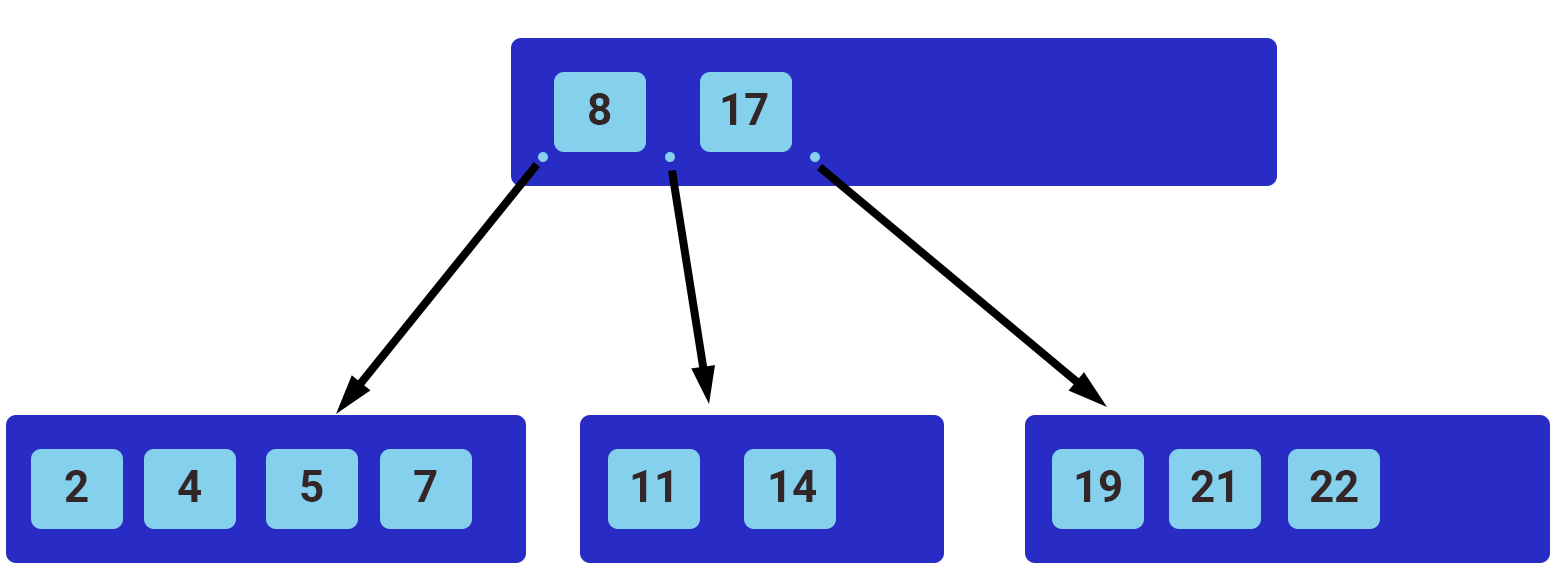
در درخت جستوجو، «بالاترین گره» (Top Node) به نام «ریشه» (Root) شناخته میشود. به همین صورت گرههایی که زیر آن قرار دارند نیز به عنوان «گره فرزند» (Child Node) یا «گره برگ» (Leaf Node) شناخته میشوند. برای پیداکردن مقدار خاصی، باید از گره ریشه شروع کنیم. سپس مقداری را که در حال جستوجو به دنبال آن هستیم را با مقدار موجود درون هر گره مقایسه میکنیم.
- اگر مقداری که در حال جستوجو به دنبال آن هستیم از مقدار موجود در گره کمتر بود، به سمت چپ آن گره در درخت حرکت میکنیم.
- اگر مقداری که در حال جستوجو به دنبال آن هستیم از مقدار موجود در گره بیشتر بود، به سمت راست آن گره در درخت حرکت میکنیم.
در مثال بالا، همه مقادیر کمتر از عدد ۸ جستوجو را به سمت چپ و همه مقادیر بیشتر از ۸ جستوجو را به سمت راست منتقل میکنند.
ساختار Hash
ایندکسهای Hash از «تابع هش» (Hash Function) استفاده میکنند. این ساختار داده یکی از سریعترین عملیات جستوجو را ارائه میدهد. هشها به ایندکس کمک میکنند که با سرعت بسیار زیادی بر روی دادههای ذخیره شده در جدول پیمایش کرده و عملیات جستوجو را انجام دهند.
ایده اصلی در پشت Hash این است در عوض اینکه به دنبال ایندکس خاصی بگردیم یا کل جدول را جستوجو کنیم، کلید جستوجو را از طریق تابع Hash بدست بیاوریم. عملیات «هش کردن» (Hashing) کلید جستوجو را به مقدار Hash تبدیل میکند. مقدار Hash هم اشاره به ظرف خاصی دارد که داده مورد نظر در آن ذخیره شده است. این رویکرد در دستیابی به زمان واکشی دادهها به میزان بسیار سریعتری کمک میکند. بهخصوص در اجرای عملیات «جستوجوهای برابری» (Equality Searche).
برای مثال اگر کلمه «Mike» کلید جستوجو باشد، تابع هش مقدار Hash شدهای از Mike ایجاد میکند. این مقدار Hash تعیین میکند که کدام ظرف درون «جدول هش» (Hash Table) آدرس رکورد متناظر با آن را ذخیره کرده است. این متد، دسترسی به دادهها را به میزان سریع و کارآمدی ارتقا میدهد.
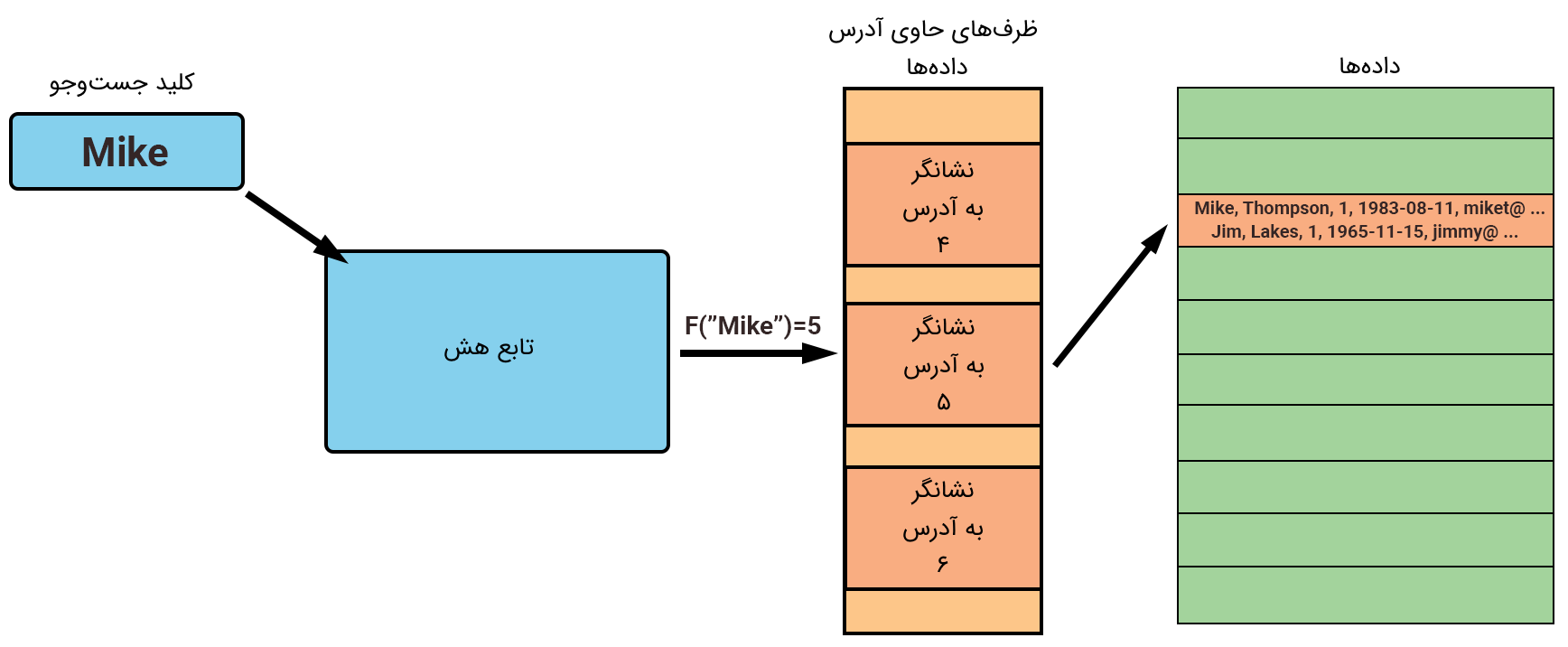
هر ظرفی در آرایه ظرفها شامل تعداد یکسانی از رکوردها است. مهم نیست که چه تعداد، مقدار مجزا در ستونی وجود داشته باشد، هر ردیفی بر ظرف مجزایی نگاشت شده است. بنابراین داده سازگار با جواب انتخاب شده و از ظرف به بیرون برگشت داده میشود.
ایندکس های موجود در انواع پایگاه های داده رابطه ای
همینطور که میبینیم، چندین نوع مختلف از ایندکسها در پایگاههای داده رابطهای وجود دارند. هر موتور پایگاه دادهای روش پیادهسازی ایندکس مخصوص به خود را دارد. در این بخش از مطلب به بررسی مشهورترین موتورهای پایگاه داده پرداخته و ایندکسهای در دسترس را برای هر کدام فهرست کردهایم. در نهایت هم به زمان استفاده از هر کدام اشاره کردیم.
ایندکس های پایگاه داده PostgreSQL
PostgreSQL، سامانهای برای مدیریت پایگاه دادههای شی-رابطهای است که در روی سکوهای مختلفی از جمله لینوکس، FreeBSD، ویندوز و macOS در دسترس است. برای آموزش کار با این پایگاه داده میتوانید فیلم آموزش مقدماتی PostgreSQL برای مدیریت پایگاه داده را از فرادرس مشاهده کنید. لینک مربوط به این فیلم را در پایین نیز قرار دادهایم.

پایگاه داده PostgreSQL فهرست طولانی از ایندکسها را برای استفاده ارائه میدهد. هر کدام از این ایندکسها در سناریوهای مختلفی بهکار برده میشوند.
- B-Tree: ایندکس «درخت بی» (B-Tree) رایجترین نوع ایندکسها است. این ایندکس برای جستوجوی برابری و مقایسههای درون محدوده مشخص شده، در ستونهایی انجام میشود که حاوی دادههای قابل مرتبسازی هستند.
- Hash Index: ایندکس هش، کد هش ۳۲ بیتی را ذخیره میکند که از مقادیر ستونهای ایندکسگذاری شده استخراج میشود. از این ایندکس زمانی استفاده میشود که مقایسه برابری ساده، مورد نیاز باشد.
- GiST :GiST ایندکسی ساده و مجزا نیست. بلکه ساختار منطقی است که درون آن چندین استراتژی مختلف ایندکسگذاری قابل پیادهسازیاند. از این ساختار ایندکسدهی اغلب در پیدا کردن نزدیکترین همسایگی بر روی نوع دادههای هندسی استفاده میشود.
- SP-GiST :SP-GiST هم مانند GiST نوعی از ایندکسدهی است که میتواند چندین استراتژی ایندکسگذاری مختلف را به صورت همزمان پیادهسازی کند. این ساختار ایندکس بر اساس ساختارهای داده مختلف مانند «درخت چهارتایی» (QuadTree)، «درختان کی دی» (k-d Trees) و «درخت مبنا» (Radix Tree) پایهگذاری شده است. همچنین در سناریوهایی مانند موارد استفاده از ایندکس GiST بهکار برده میشود.
- GIN: ایندکس GIN به نام «ایندکس معکوس» (Inverted Index) نیز شناخته میشود. این نوع ایندکس در سناریوهایی بهکار برده میشود که دادهها توسط آرایهای قالب دهی شدهاند. ایندکس معکوس یا GIN شامل ورودی جدایی به ازای هر مقدار در عناصر آرایه است.
- BRIN: کالمه BRIN مخفف عبارت «Block Range Index» و به معنای «ایندکس محدوده بلوک» است. این ایندکس برای ذخیرهسازی خلاصهای از مقادیر در صفحات پشت سر هم و به صورت داده فیزیکی درون جدول بهکار برده میشود. وقتی که مقادیر درون ردیفهای جدول پایگاه داده با نظم فیزیکی به یکدیگر مرتبط باشند، این ایندکسها مناسبترین گزینه برای استفادهاند.

ایندکس های پایگاه داده Oracle
شرکت «اوراکل» (Oracle) در زمینه تولید نرمافزارهای مدیریت داده، پایگاه داده و سیستمهای اطلاعاتی فعالیت میکند. اوراکل تقریبا نوعهای ایندکس کمتری نسبت به PostgreSQL دارد. اما به هرحال ایندکسهای Oracle در بحث کاربردی مستحکمتر هستند.
- B-Tree: ایندکس «درخت بی» (B-Tree) نوع ایندکس استاندار است. هرچند توسط سایر نوعهای پایگاه داده نیز استفاده میشود. این ایندکس برای استفاده در کلید اصلی و ستونهایی مناسب است که در مقایسه با تعداد کل ردیفها، تعداد بسیار زیادی دادههای مجزا دارند.
- Bitmap: ایندکسهای Bitmap برای سناریوهای مخالف موراد استفاده B-Tree بهکار برده میشود. بهویژه وقتی از این ایندکس استفاده میکنیم که تعداد مقادیر یکتا یا مجزا در ستونی نسبت به تعداد کل ردیفهای جدول بسیار کمتر باشد.
- Function-Based Index: ایندکس «مبتنی بر تابع» ( Function-Based Index) نوعی از ایندکس است که در آن مقدار ذخیره شده در درخت جستوجو توسط تابعی تعریف شده است. زمانی که تابعی در بندهای WHERE وجود داشته باشد، این ایندکس عملکرد بسیار عالی را ارائه میدهد.
انواع ایندکس در SQL Server
SQL Server به عنوان «سامانه مدیریت پایگاه داده» (DBMS) با ویژگیهایی همچون مدیریت داده، انجام عملیات CRUD، پرسوجوی پیشرفته و امنیت داده، شناخته میشود.

SQL Server تعداد کمی ایندکس دارد، اما این ایندکسها در عملکردی که ارائه میدهند بسیار قدرتمند و پایدار ظاهر شدهاند.
- Clustered Index: ایندکسهای Clustered Index در موتور پایگاه داده، فقط روشی برای جستوجو در بین کوئریها نیست. بلکه به صورت فیزیکی ردیفهای درون صفحات داده را نیز سازماندهی میکند. بنابراین، همه این ردیفها به صورت مرتب شده - صعودی یا نزولی - در میآیند.
- The nonClustered Index: این ایندکس معادل ایندکس استاندارد «درخت بی» در سایر موتورهای پایگاه داده است. این گزینه به طور کلی برای جستوجو در بین دادههایی خوب است که شامل تعداد بسیار زیادی از مقادیر مجزا از همدیگراند.
- Filtered Indexes: ایندکسهای فیلتر شده برای مشخص کردن زیرمجموعههای داده، ایجاد شدهاند. این ایندکسها را میتوان برای بهینهسازی عملیات جستوجو به دنبال داده با معیار مشخص شدهای استفاده کرد. مخصوصا زمانی که دادههای ذخیره شده دارای توازن نباشند. برای مثال، مقدار ۵۵ از ستون عددی ممکن است به طور متناوبی مورد جستوجو قرار گیرد. اما فقط در چند ردیف محدود از کل ردیفهای موجود در جدول پایگاه داده قابل پیدا کردن است. برای حل این مسئله میتوانیم ایندکس فیلترشدهای ایجاد کنیم که شبیه به ایندکسهای Non-Clustered باشد. فقط باید در کوئری مورد نظر برای تعریف ایندکس از تکه کد WHERE column = 55 به عنوان شرط استفاده کنیم.

ایندکس های پایگاه داده MySQL
نرم افزار MySQL «سیستم مدیریت پایگاه داده رابطهای« (RDBMS) است که امکان ذخیرهسازی، جستجو، مرتب کردن و بازیابی دادهها را از طریق وب فراهم میکند. برای آموزش کار با MySQL میتوانید فیلم آموزش پایگاه داده MySQL را از فرادرس مشاهده کنید. لینک مربوط به این فیلم را در پایین نیز قرار دادهایم.
همینطور که انواع ایندکس در SQL را معرفی میکنیم، باید به انواع ایندکسهای اختصاصی MySQL هم بپردازیم. این پایگاه داده نیز دارای ایندکسهایی است که با کمک آنها میتوان سرعت اجرای کوئریها را ارتقا داد.
- کلید اصلی: کلید اصلی در پایگاه داده، ایندکس یکتایی را ایجاد میکند. این ایندکس در اجرای عملیات جستوجو به دنبال مقادیر یکتا هم عملکرد پایگاه داده را ارتقا داده و هم زمان جستوجو را به میزان زیادی کاهش میدهد. همچنین ایندکس کلید اصلی نمیتواند مقادیر NULL را بپذیرد. در نتیجه کارایی کلی پایگاه داده و این ایندکس در جستوجو به میزان قابل توجهی ارتقا پیدا میکند. وقتی که کلید اصلی تعریف میشود، این ایندکس نیز به صورت خودکار ایجاد میشود.
- ایندکس یکتا: ایندکس یکتا شبیه به کلید اصلی است. اما مانعی در برابر وجود داشتن چندین مقدار NULL ایجاد نمیکند. از این ایندکس میتوان برای تضمین یکتا بودن مقادیر با تاکید بیشتری استفاده کرد، مخصوصا در زمانی که کلید اصلی از قبل وجود دارد.
آموزش پایگاه های داده مختلف در فرادرس
زبان کوئری نویسی SQL مورد استفاده پایگاههای داده مختلفی است. در همه این پایگاههای داده اکثر توابع SQL با سینتکس شبیه هم استفاده میشوند. اما هر کدام بسته به هدفی که از تولیدشان وجود دارد برای کار در سناریوهای مختلف و با سختافزارهای مختلفی طراحی شدهاند. در این بخش، فیلمهای آموزشی مربوط به چند مورد از این پایگاههای داده را معرفی کردیم. با توجه به نیاز و هدف خود از برنامهنویسی میتوانید پایگاه داده مناسب را انتخاب کنید.
- فیلم آموزش پایگاه داده MySQL در فرادرس
- فیلم آموزش تکمیلی مدیریت بانک اطلاعاتی با Oracle فرادرس
- فیلم آموزش مقدماتی «آپاچی کاساندرا» Apache Cassandra در فرادرس
- فیلم آموزش پایگاه داده SQLite در پایتون با فرادرس
- فیلم آموزش کار با بانک اطلاعاتی «اکسس» Access در C# با فرادرس

جمعبندی
با مطالعه مطلب حاضر به صورت دقیق به اهمیت توانایی کار با انواع ایندکس در SQL پی برده میشود. دانستن اینکه چه ایندکسهایی در موتورهای پایگاه داده خاص در دسترس هستند به کاربران کمک میکند که در زمان گیرکردن کار کوئریها، عملکرد خود را ارتقا داده و مسائل را حل کنند. بعضی از اوقات ایندکس «درخت بی» که به صورت ایندکس عمومی نیز شناخته میشود، کافی نیست. شاید این ایندکس با طرح یا دادههای در نظر گرفته شده برای پروژه به خوبی کار نکند. شناخت همه انواع ایندکس در SQL مانند ابزار همهکارهای در جعبه ابزار شخصی برنامهنویس است.

در این مطلب از مجله فرادرس درباره انواع ایندکس در SQL صحبت کردهایم و مهمترین آنها را با بیان توضیحات کاملی معرفی کردیم. سپس درباره روش ساخت ایندکس و ساختارهای پشت صحنه ایندکسها مطالب مهمی را نوشتیم. در نهایت هم چند مورد از مهمترین پایگاههای داده را همراه با ایندکسهای اختصاصی هر کدام معرفی کردیم.










