



آنالیز کلان داده و ساختار شبکه اجتماعی – آشنایی با اصطلاحات و مثال عملی
با انفجار اطلاعات و افزایش دادههایی که روزانه از منابع مختلف تولید میشود، با پدیده جدیدی به نام «کلان داده» (Big Data) یا «مِه داده» مواجه شدهایم. لازم است که ابزارهای مناسب برای ثبت و نگهداری و همچنین تحلیل چنین حجم عظیمی از دادهها را داشته باشیم. پیشرفت دستگاههای محاسباتی و بوجود آمدن «رایانش ابری» (Cloud Computing) دسترسی به این دادهها و پردازش آنها را در زمان کوتاه میسر ساخته است. بنابراین مسائلی مانند نمونهگیری که در آمار برای جلوگیری از بررسی همه جامعه آماری به وجود آمده، دیگر لزومی نداشته باشد. به همین جهت در این نوشتار از مجله فرادرس به بررسی روش آنالیز کلان داده و ساختار شبکه پرداختهایم. در این بین به تکنیک شبکهای کردن و ارتباط گرهها اشاره کرده و مثالهای عینی نتایج را مورد بررسی قرار دادهایم.
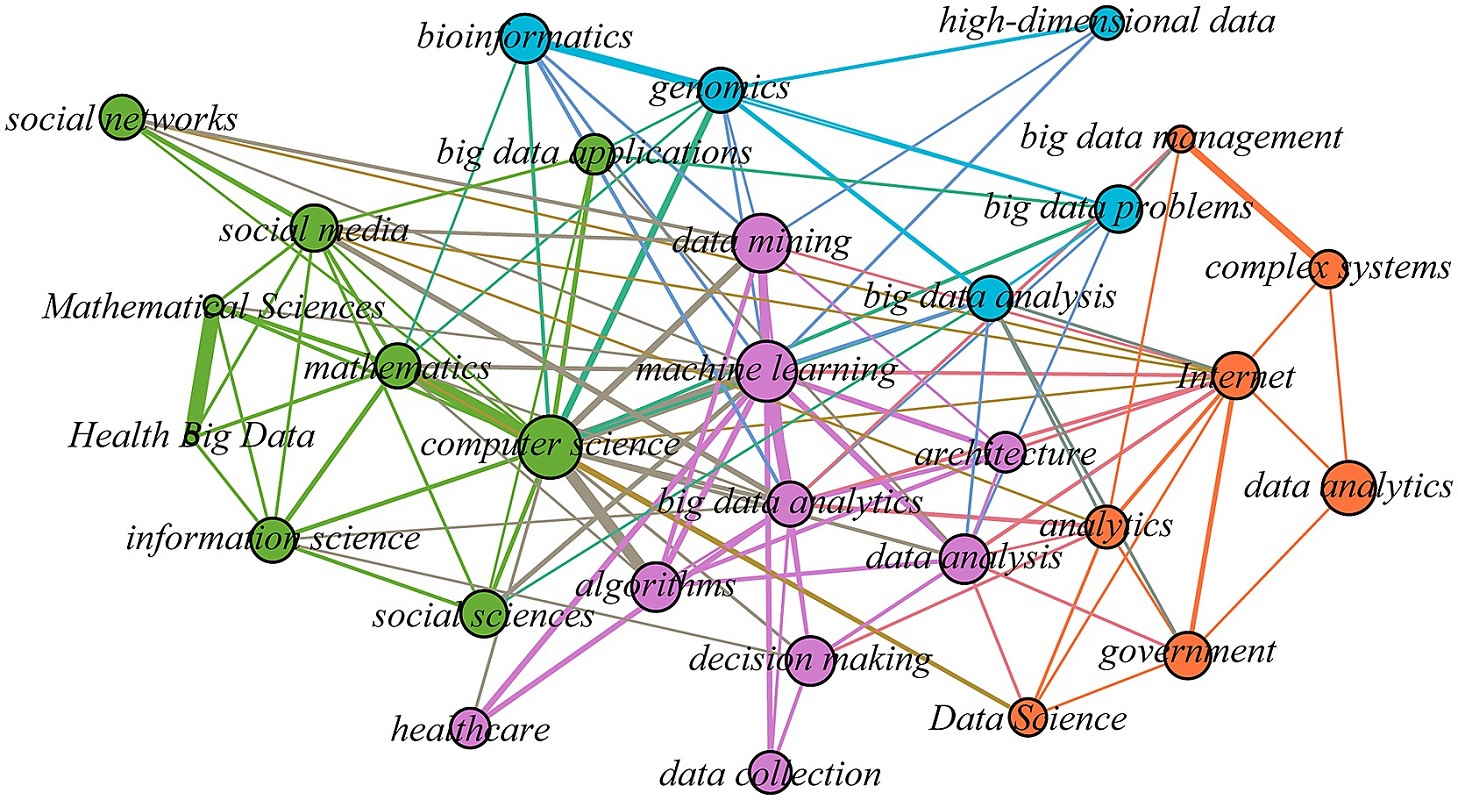


برای آشنایی بیشتر با مفاهیم به کار رفته در این نوشتار به مطالب آموزش رایانش ابری (Cloud Computing) — از صفر تا صد و تحلیل کلان داده (Big Data)، چالش ها و فناوری های مرتبط — راهنما به زبان ساده مراجعه کنید. همچنین خواندن پردازش کلان داده در پایتون — راهنمای جامع و ابزارهای تحلیل کلان داده (Big Data) — راهنمای کامل نیز خالی از لطف نیست.
آنالیز کلان داده و ساختار شبکه اجتماعی
داده های بزرگ یا «مِه داده» (Big data) زمینهای است که روشهای تجزیه و تحلیل، استخراج سیستماتیک اطلاعات و محاسبه روی حجم عظیمی از دادهها را میسر میکند. در اغلب موارد نمیتوان با نرم افزارهای کاربردی پردازش داده سنتی کلان داده (Big Data) را پردازش کرد. این گونه دادهها اگر به ساختار جدولی ثبت شوند، دارای ستونها (فیلدها) و سطرها (رکوردها) زیادی خواهند بود.
چالشهای آنالیز کلان داده شامل «دریافت دادهها» (capturing data)، «ذخیره داده ها» (data storage)، «تجزیه و تحلیل دادهها» (data analysis)، «جستجو» (search)، «به اشتراک گذاری» (sharing)، «انتقال» (transfer)، «مصورسازی» (Visualization)، «پرس و جو» (querying)، «به روزرسانی» (updating)، «حریم خصوصی اطلاعات و منبع داده» (information privacy) است.
کلان داده، در ابتدا به سه مفهوم در مورد اطلاعات متمرکز بود. حجم، تنوع و سرعت. به این معنی که روشهای تحلیل مه داده باید حجم زیاد اطلاعات که دارای تنوع بسیار هستند در زمان مناسب و سرعت زیاد، پردازش کند.
تجزیه و تحلیل کلان داده (مه داده) چالشهای زیادی را در موضوع «نمونهگیری» (Sampling) بوجود آورده است. در نمونهگیری به وسیله استخراج مشاهدات از جامعه آماری، اطلاعاتی در مورد کل جامعه استنباط میشد. ولی با توجه به ابزارهای مِه داده، شاید ضرورتی به نمونهگیری و روشهای آمار استنباط مبتنی بر نمونه وجود نداشته باشد. ضرورت نمونهگیری شاید به محدودیتهایی که محاسبات دستی یا استفاده از روشهای پردازش سنتی (قبل از ظهور مه داده) داشتند، مرتبط باشد.
به کارگیری مِه داده در تجارت
شرکت «ای بی» (eBay.com) که یک شرکت خرده فروشی آنلاین است، از دو انبار داده به حجمهای 7٫5 پتابایت و 40 پتابایت و همچنین یک خوشه 40 پتابایتی با معماری Hadoop برای جستجو، توصیههای مصرف کننده و تجارت استفاده میکند.
نکته: پتابایت برابر یک کادریلیون بایت، یا ۱۰۱۵ بایت است. پتابایت را به صورت PB نیز نشان میدهند.
آمازون (Amazon.com) هر روز میلیونها عملیات پشت سرهم و همچنین درخواستهای بیش از نیم میلیون فروشنده واسط را انجام میدهد. فناوری اصلی که آمازون را فعال نگه میدارد، مبتنی بر «سیستم عامل لینوکس» ( Linux OS) است و از سال 2005 آنها دارای سه پایگاه داده بزرگ لینوکس در جهان بودند که با ظرفیتهای 7٫8 ترابایت، 18٫5 ترابایت و 24٫7 ترابایت فعالیت میکنند.
نکته: ترابایت برابر یک بیلیون بایت، یا ۱۰۱۲ بایت است. ترابایت را به صورت TB نیز نشان میدهند.
شرکت «فیس بوک» (Facebook)، 50 میلیارد عکس را از پایگاه کاربران خود اداره و مدیریت میکند. از ژوئن 2017، فیس بوک ماهانه 2 میلیارد کاربر فعال دارد. «شرکت گوگل» (Google) در ماه اوت 2012 تقریباً 100 میلیارد جستجو در ماه را اجرا کرده است. این به معنی سه جستجو در روز برای هر نفر در جهان است. در طول بیماری همه گیر COVID-19، مه داده، به عنوان راهی برای به حداقل رساندن تأثیر بیماری به کار گرفته شد. کاربردهای قابل توجه مه داده شامل به حداقل رساندن شیوع ویروس، شناسایی موارد مشکوک و توسعه روشهای درمانی بود. دولتها از مه داده برای ردیابی افراد آلوده استفاده کردند تا میزان انتشار را به حداقل برسانند. در این بین میتوان به تلاشهای کشورهای شامل چین، تایوان و کره جنوبی اشاره کرد.
مِه داده در مقابل هوش تجاری
با رشد دانش در حوزههای مِه داده و «هوش تجاری» (Business Intelligence)، مفاهیم این دو اصطلاح به وضوح متفاوت شده و میتوان بین «مِه داده» و «هوش تجاری»، خطوط تفکیک را ترسیم میکند.
- هوش تجاری از ابزارهای ریاضی کاربردی و آمار توصیفی با دادههایی با تراکم اطلاعات بالا برای اندازه گیری موارد، تشخیص روندها و مدلسازی استفاده میکند.
- مه داده، از تجزیه و تحلیل ریاضی، بهینه سازی، آمار و مفاهیم استنباطی برای کشف قوانین (روشهای رگرسیون، روابط غیر خطی و اثرات علت و معلولی) از مجموعه زیادی از دادهها با تراکم اطلاعات کم بهره میبرد. به این ترتیب با استفاده از روابط و وابستگیها، امکان پیشبینی رفتار پدیدهها امکانپذیر میشود.
آنالیز کلان داده و تحلیل شبکههای اجتماعی
شبکه (Network) راهی برای نشان دادن اطلاعات است و با استفاده از روشهای ریاضی قابل درک و تجزیه و تحلیل است. شبکهها، گروهی از «گرهها» (Nodes) هستند که توسط «پیوند» (Link) یا «یال» (Edge) به هم متصل شدهاند و میتوانند نشانگر هدایت جهتدار از یک گره به گره دیگر یا بدون جهت (دو طرفه) در نظر گرفته شوند. از این جهت، یک شبکه به مانند یک «گراف» (Graph) قابل بررسی است. «صفحات وب» (Web Page) نمونههایی از شبکههای جهتدار هستند که صفحه وب نشان دهنده یک گره و «ابرپیوند» (Hyperlink) به عنوان یک یال است.
اغلب از شبکهها برای یافتن دقیق اجتماعات نیز استفاده میکنند. این گرهها راسهایی هستند که بصورت گروهی متصل هستند اما ارتباط کمی با گروههای دیگر دارند، این امر به مانند افرادی است که در شبکههای اجتماعی با علایق مشابه حضور داشته یا دانشمندانی را مشخص میکند که در یک زمینه علمی همکاری دارند. موضوع مورد توجه در این بین «متغیرهای» مربوط به این داده است که باید مورد مطالعه قرار گیرند، این کار ممکن است به بهبود دقت در شناسایی جوامع و «خوشهها» (Clusters) کمک کند. با گسترش «شبکههای اجتماعی» (Social Network)، موضوع کلان داده در بین کارشناسان داده» (Data Scientist) بیش از هر زمان دیگری اهمیت یافته است. در ادامه متن به مقالهای اشاره خواهیم کرد که در حوزه آنالیز کلان داده پرداخته و به کمک ساختار شبکه، اطلاعاتی را از مه داده استخراج میکند.
گروهها و اطلاعات گرهها
شناخت جوامع درون شبکه، ساختار آنها را روشن میکند و در عمل مزایای زیادی دارد. به عنوان مثال، مشخص است که افرادی که عضوی گروههای شبکه اجتماعی خاصی هستند، علایق مشابه دارند، بنابراین توصیهها یا پیشنهادات یکسانی را میتوان برایشان در نظر گرفت. با این کار با اعمال سیاست صحیح در مورد هر یک از آنها، درست به هدف زده و انتظارمان از آن سیاست برآورده میشود.
به طور گسترده، روشهای فعلی برای شناسایی جوامع درون مجموعه دادهها یا با استفاده از روشهای آماری با تکیه بر برنامههای رایانهای، یا مبتنی بر مدل، به صورت الگوریتمهایی انجام میشوند. یکی از این روشها، «مدل بلوک تصادفی» (stochastic block model) است که در اینجا قصد داریم به کمک آن شناخت جوامع درون ساختار شبکه را میسر کنیم.
در این مدل فرض شده است که گرههای درون جامعه هنگام تعامل با گرههای دیگر رفتار یکسانی دارند. به عنوان مثال، اگر افراد A و B به یک جامعه تعلق داشته باشند، هنگام برقراری ارتباط با هر شخص دیگری مثل C، رفتار مشابه از خود نشان میدهند. به یاد داشته باشید که شناخت جوامع درون شبکهها، ساختار آنها را روشن میکند و مزایای عملی مانند توصیههای بهتر در جستجوی وب را ارائه میدهد. به همین جهت تحلیل کلان داده و ساختار شبکه اهمیت پیدا کرده است.
در ساختار یک شبکه یا گراف، گرهها دارای خصوصیاتی هستند که میتوانند به تعیین ساختارهای جامعه در دادهها کمک کنند. به عنوان مثال، کاربران شبکههای اجتماعی، مشخصات کاربری خود را به گرهها متصل میکنند. همچنین در شبکههای علمی (مانند Research Gate) مقالات علمی ذکر شده حاوی اطلاعات نویسنده، کلمات کلیدی و خلاصه مقالات است. به این ترتیب هر گره شامل اطلاعاتی از نویسنده و مقاله علمی خواهند بود.
در نظر داشته باشید که این نوع اطلاعات و متغیرها، همراه با یالهای گرافها، از طریق دو رابطه متفاوت توصیف شده در شکل 1، این امکان را به ما میدهند که وجود جوامع یا گروههای مرتبط را بهتر استنباط کنیم.
همچنین در تصویر a، گره c یا «اطلاعات جامعه» (Community Information) به عنوان یک اصلاح کننده رابطه بین «ماتریس مشاهدات» (A) و X (به عنوان اطلاعات گرهها) را بهبود داده است. به بیان دیگر نقش مرتبط یا «ماتریس وابستگی» (Covariate) را بین دو ماتریس اطلاعاتی یا دو جامعه A و X ایفا کرده است و پُلی بین آنها محسوب میشود. همچنین در تصویر b ارتباط بین گره c و A به کمک ماتریس یا اطلاعات گره X تعدیل شده است.

رویکرد مجانبی برای آنالیز کلان داده و ساختار شبکه
از آنجایی که ساختار ماتریسهای A و X و همچنین بردار c مشخص نیست، متخصصین یا دانشمندان داده، معمولا به کمک دادهها، این بخشها را برآورد میکنند. در مقالهای (+) برای دو مثال مختلف این محاسبات صورت گرفته که در اینجا فقط به خروجیهای تولید شده، اشاره خواهیم داشت. شیوه محاسبه و تحلیل کلان داده در این مقاله براساس «ماتریس شبکه» (Network Matrix)، «ماتریس اتصالات» (Connections Matrix) یا یالها و ماتریس «خصوصیات گرهها» (Nodal Properties) صورت گرفته است. در اغلب موارد خصوصیات گرهها را به عنوان «ماتریس وابستگی» (Covariates) میشناسند.
نکته: ماتریس وابستگی (Covariate) زمانی به کار میرود که یک متغیر خارج از حیطه ارتباط بین متغیرها، معرفی میشود تا ارتباط بین متغیرهای اصلی واضحتر یا تعدیل شود.
با استفاده از «روشهای تکراری» (Iterative approach)، گروهها یا «جامعهها» (Communities) شناخته و تشخیص داده میشوند. به یاد دارید که جامعهها، گرههایی هستند که با یکدیگر یک گروه را تشکیل میدهند و شباهت زیادی با یکدیگر دارند. روشهای دیگر در این بین، اغلب مبتنی بر «تابع درستنمایی» (Likelihood-based) هستند که به نقاط اولیه بسیار حساس هستند. بنابراین شیوه مورد استفاده در این مقاله، سعی در رفع این مشکل داشته است. البته هدف ما در بازنویسی این مقاله، روند اجرا و بررسی محاسبات صورت گرفته نیست، بلکه نمایش کارکرد و نتایج حاصل از آنالیز کلان داده و ساختار شبکه است.
در راه حل ارائه شده، «نقاط اولیه خوش رفتار» (well-behaved initial values) مورد جستجو قرار گرفته و به کمک روشهای بهینهسازی ریاضی، جوامع تعیین میشوند. استفاده از این نقاط، عملکرد بهتری نسبت به نقاط تصادفی دارند. بهینهسازی ممکن است براساس بیشینه کردن شباهت بین گرهها یا کمینه کردن فاصله بین آنها صورت گیرد.
به کارگیری مدل شبکه برای شناخت جامعه
در این بخش به معرفی دو مثال در حوزه آنالیز کلان داده خواهیم پرداخت. مثال اول مربوط کارمندان یک شرکت است که از لحاظ میزان همکاری با یکدیگر مورد بررسی قرار گرفتهاند. فرض بر این است که متغیرهایی را برای اندازهگیری مشارکت کارکنان تعریف کردهایم و قرار است گروههای همکار را براساس این متغیرها، شناسایی نماییم.
در مثال دوم در مدارس آمریکا، «شبکه دوستی» (Friend Network) مورد بررسی قرار گرفته است. به این معنی که خصوصیات دانشآموزان تحلیل و شرایط دوستی بین آنها تجزیه و آنالیز خواهد شد. به این ترتیب میتوانیم گروههای همسان را در بین دانشآموزان مشخص کنیم.
شناخت گروههای کاری همسان در کارمندان
یک نمونه از تیم مورد بررسی متشکل از 77 کارمند است که در یک شرکت تولیدی کار میکنند. برای ایجاد یک شبکه، کارمندان را به عنوان گرههایی با پیوندهایی که یالهایش میزان تعامل آنها برای انجام کارشان است را در نظر بگیرید. هر یک از این پیوندها (یالها) دارای وزن نیز هستند. پس با یک گراف وزندار مواجه هستیم.
برای مثال اگر فرد A با فرد B در نظر گرفته شوند، وزن براساس تعداد تعامل آنها با یکدیگر در یک روز اندازهگیری میشود. وزنها را به صورت زیر نشان دادهایم.
۰: بدون تعامل، 1: به ندرت، 2: کم، 3: متوسط، 4: معمول، 5: زیاد و 6: خیلی زیاد.
این مجموعه داده دارای ویژگیهای دیگری در مورد هر کارمند مانند نژاد و سمت در سازمان نیز هست. دادهها نمایانگر یک «شبکه وزنی و جهتدار» (weighted directed network) است و باید برای مدلبندی به یک «شبکه باینری بدون جهت» (binary undirected network) تبدیل شود.

مدل نهایی از فراوانی ارتباطات استفاده کرده تا افرادی که اغلب با هم ارتباط برقرار نمیکنند را از بقیه جدا کند. موقعیت هر گره در تشخیص گروه یا جامعه در شبکه بسیار مهم است زیرا مکان یا نقاط پراکنده یا دورافتاده، متضمن تعامل کمتر آن کارمندان است. از این خاصیت برای آزمایش اثربخشی فرآیند استفاده شود. در طی مقاله یاد شده، مشخص میشود که با استفاده از خصوصیات گرهها، دقت تشخیص جامعه بهبود یافته و «برنامهریزی نیمه معین» (semi-definite programming) مانند روش مبتنی بر احتمال و تابع درستنمایی عمل میکند.
نکته: بهینهسازی نیمه معین، زمینهای نوظهور است که در حوزه تحقیق در عملیات و بهینهسازی ترکیبیاتی به کار گرفته میشود. تقریباً همهٔ مسائل برنامهریزی خطی را میتوان به صورت بهینهسازی نیمه معین، تعریف و حل کرد.

واضح است که در اینجا، ویژگیهای کارکنان، فقط تعداد تعامل آنها است. بنابراین برای هر گره دو مشخصه یکی سمت سازمانی و تعداد تعاملهای آن در نظر گرفته شده. بنابراین با یک مسئله تک متغیره مواجه هستیم. همانطور که در تصویر بالا به عنوان یک نمونه، مشاهده میکنید، خطوطی که پر رنگ هستند، ارتباط قویتر را نشان میدهند. گرهها (دایرهها) بزرگتر نیز سطح یا سِمَت سازمانی کارمند را نشان میدهد. همانطور که مشخص است، مدیران هر بخش بیشترین ارتباط را با کارکنان خود دارند. از طرفی ارتباطها نیز بدون جهت شدهاند.
نکته: در شبکههای واقعی، گره ها دارای خصوصیاتی هستند که میتوانند به تعیین ساختارهای جامعه در دادهها کمک کنند.
به عنوان یک نمونه دیگر به مسئله دانشآموزان میپردازیم. در این قسمت، ویژگیهای هر گره، بیش از یک متغیر بوده و مسئله به صورت چند متغیره خواهد بود.
در این مثال از «شبکه دوستان» در دبیرستان ایالات متحده استفاده شده است. اطلاعات مربوط در این مثال از مطالعه ملی در مورد بزرگسالی تا سلامت بزرگسالان استفاده شده که متشکل از 795 دانش آموز بین 9 تا 12 سال در دبیرستان و بین هفت تا هشت سال در دبستان گرفته شده است. دانشآموزان این مجموعه دارای چندین ویژگی یا متغیر مانند نمره (Grade)، «جنسیت» (Gender)، «قومیت» (Ethnicity) و «تعداد دوستان» (حداکثر ده اسم) بوده است. در جوامعی مانند این مثال، اطلاعات گرهها (مانند سن یا قومیت) اغلب میتوانند یک «حقیقت زمینهای» (Ground Truth) را برای شناخت جامعه، در اختیار قرار دهند. به این ترتیب براساس این واقعیت، انتظار داریم که کسانی که همنژاد هستند یا هم جنس یا در یک مقطع تحصیلی حضور دارند، بیشتر باب دوستی را با یکدیگر باز کنند.
در تصویر زیر، دو جامعه براساس رده تحصیلی یا متغیر School قابل مشاهده است. همانطور که میبینید گروه دبستان در سمت چپ و گروه دبیرستان در سمت راست قرار گرفتهاند. بیشترین تعامل درون هر یک از جوامع رخ داده و ارتبط بین این دو جامعه طبق شبکه ترسیم شده، ضعیف است.

توجه داشته باشید که در این حالت، این متغیرها به کار رفته است. گروه یا جامعه اول در سمت چپ و گروه یا جامعه دوم در سمت راست قرار گرفته است. البته بین این دو گروه ارتباطهای دوستی نیز برقرار است ولی تراکم آنها نسبت به درون گروه یا جامعهها کمتر است.
- M: دانشآموز مقطع دبستان
- H: دانشاموز مقطع دبیرستان
- B: سیاهپوست (آفریقایی) - نژاد
- W: سفید پوست (اروپایی) - نژاد
- H: سرخپوست (آمریکای شمالی) - نژاد
- O: زرد پوست (آسیایی) - نژاد
- Male: مذکر با نمایش به صورت مربع توپُر
- Female: مونث با نمایش به صورت دایره توپُر
در تصویری دیگر نتیجه تفکیک شبکه به دو جامعه (برحسب نژاد) را مشاهده میکنید. کلان داده و ساختار شبکه در این مثال به خوبی دیده میشود.

مشخص است که رنگین پوستان (زرد و سرخپوستان) در این بین محسوب نشدهاند و در بین دو جامعه سفید و سیاه پوستان پخش هستند. میتوان نشان داد که به این ترتیب ارتباط دوستی در بین سفید پوستان جداگانه از سیاهپوستان است و هر یک از این نژادها علاقمند به دوستیابی با همنژادهای خود هستند.
در بخش آخر نیز تفکیک جامعه به دو گروه براساس جنسیت (مذکر و مونث) روی داده. در تصویر زیر این دو جامعه را مشاهده میکنید. قرار است بوسیله آنالیز کلان داده به این پرسش پاسخ دهیم که آیا دوستیابی با همجنسها در بین دانشآموزان (چه در مقطع دبستان و چه دبیرستان) بیشتر رخ میدهد یا خیر.

همانطور که میبینید در طرف چپ تصویر، صرف نظر از نژاد و مقطع تحصیلی، دختران تشکیل یک جامعه و پسران نیز تشکیل جامعهای دیگر دادهاند. در این بین تشخیص یا تفکیک افراد در این دو گروه با خطای زیادی همراه خواهد بود. موارد زیادی دیده میشود که فرد با جنسیت مذکر با فرد دیگری با جنسیت مونث رابطه دوستی دارد و برعکس. بنابراین خطای این تفکیک بسیار زیاد است. این موضوع در آنالیز کلان داده چنین دادههایی اهمیت زیادی دارد.
خلاصه و جمعبندی
همانطور که در متن خواندید، استفاده از روشهای آنالیز کلان داده برای تجزیه و تحلیل شبکههای اجتماعی امری است که مورد استفاده قرار میگیرد. براساس خصوصیاتی که گرهها و همچنین یال های شبکه دارا هستند، امکان تعیین یا تفکیک جوامع یا گروههای همسان وجود دارد. با رسم نمودارهایی از شبکههای ایجاد شده براساس انتظارات و واقعیت، کارکرد تجزیه و آنالیز کلان داده (مه داده) مشخص شد. همانطور که امیدوار بودیم، گروههای همسان در شبکهها با استفاده از روشهای آنالیز کلان داده امکانپذیر است. کلان داده و ساختار شبکه اجتماعی یکی از مسائلی است که امروزه در بین دانشمندان داده، بسیار مورد توجه قرار دارد و تحقیقات بسیاری در این حوزه صورت میپذیرد.









