



یادگیری تقویتی در پایتون – راهنمای کاربردی
«یادگیری تقویتی» (Reinforcement Learning)، یک شاخه از «یادگیری ماشین» (Machine Learning) است که در آن یک عامل میآموزد چگونه با انجام «اعمال» (Actions)، ساخت شهود و مشاهده نتایج در محیط رفتار کند. در این راهنما، چگونگی درک و طراحی یک مساله یادگیری تقویتی و حل آن با استفاده از «زبان برنامهنویسی پایتون» (Python Programming Language) تشریح شده است.




اخیرا، بشر شاهد رقابت کردن ماشینها با انسانها در بازیهای کامپیوتری به عنوان ربات در «بازیهای چند نفره» (Multiplayer Games) و یا رقیب در بازیهای «یک به یک» (one-on-one) مانند «دوتا۲» (Dota2)، «پابجی» (PUB-G) و «ماریو» (Mario) بوده است. «دیپمایند» (Deepmind) شرکت هوش مصنوعی است که هنگام انتشار خبر پیروزی برنامه AlphaGo که توسط آنها طراحی شده در مقابل قهرمان کره جنوبی تبار بازی Go در سال ۲۰۱۶ تاریخساز شد.
افرادی که به بازیهای کامپیوتری علاقمند هستند، احتمالا درباره رقابت OpenAI Five در بازی دوتا۲ شنیدهاند که طی آن ماشین در مقابل انسان بازی کرد و موفق شد طی چندین بازی، بازیکنان برتر Dota2 را شکست دهد.

بنابراین، سوال اساسی در این وهله این است که چرا نیاز به یادگیری تقویتی است؟ آیا از یادگیری تقویتی فقط برای بازیهای کامپیوتری استفاده میشود و یا این روشها قابل اعمال بر سناریوها و مسائل «جهان واقعی» (Real-world) نیز هستند؟ افرادی که برای اولین بار پیرامون یادگیری تقویتی به مطالعه میپردازند، قطعا از پاسخ این پرسش شگفت زده خواهند شد؛ زیرا پاسخ، فراتر از تصور آنها است. یادگیری تقویتی یکی از روشهایی است که از فناوریهای در حال رشد بهره میبرد و دارای کاربردهای گستردهای در زمینه «هوش مصنوعی» (Artificial Intelligence) است. در ادامه، برخی از کاربردهایی که میتوانند برای فراگیری مباحث یادگیری تقویتی انگیزهبخش باشند بیان شدهاند.
- خودرو خودران (Self-Driving Car)
- بازیهای کامپیوتری
- رباتیک
- سیستمهای توصیهگر (Recommendation Systems)
- تبلیغات و بازاریابی
یادگیری تقویتی چیست؟
پرسشی که در اینجا مطرح میشود آن است که چرا بحث یادگیری تقویتی در حالی مطرح شده که تعداد قابل توجهی از روشهای یادگیری ماشین از جمله «یادگیری عمیق» (Deep Learning) در دسترس هستند؟ در ادامه این مطلب، پاسخ مذکور بیان خواهد شد.
یادگیری تقویتی توسط «ریچ ساتِن» (Rich Sutton) و «اندرو بارتو» (Andrew Barto) (استاد راهنمای پایاننامه دکترای ریچ) ابداع شد. این روش شکل اولیه خود را از مدل اولیه ارائه شده در سال ۱۹۸۰ وامدار بود؛ اما آن شکل اولیه بعدها منسوخ شد. پس از آن، ریچ که به ماهیت یادگیری تقویتی امید داشت و بر این باور بود که به تدریج شناخته میشود به فعالیت در این حوزه ادامه داد.
یادگیری تقویتی از خودکارسازی با یادگیری از محیطی که در آن ارائه شده پشتیبانی میکند. این کار شبیه به شیوه عملکرد دیگر روشهای یادگیری ماشین و یادگیری عمیق است. هرچند استراتژی همه روشهای یادگیری ماشین با یکدیگر و با یادگیری تقویتی مشابه نیست، اما هر دو از خودکارسازی پشتیبانی میکنند. پس چرا یادگیری تقویتی ظهور کرد؟ یادگیری تقویتی شباهت زیادی به فرایند یادگیری طبیعی دارد، و در آن فرآیند/مدل بازخوردهایی پیرامون عملکرد خود دریافت میکند با این مضمون که آیا عملکرد خوبی داشته است یا خیر.
یادگیری تقویتی و دیگر روشهای یادگیری ماشین نیز فرآیندهای یادگیری هستند که بیشتر بر یافتن الگوها در دادههای موجود متمرکز شدهاند. از سوی دیگر، یادگیری تقویتی فرآیند آموختن و یادگیری را با روش آزمون و خطا انجام میدهد و به تدریج، به اقدام صحیح یا بهینه سراسری میرسد. دیگر مزیت قابل توجه یادگیری تقویتی آن است که نیازی به فراهم کردن کل مجموعه داده آموزش مانند آنچه در یادگیری نظارت شده است ندارد، بلکه چند تکه از آن برای مدل کافی محسوب میشوند.
درک یادگیری تقویتی
فرض میشود که فردی قصد آموزش دادن ترفندهای جدید به گربه خود را دارد، اما متاسفانه گربهها زبان انسان را متوجه نمیشوند، بنابراین نمیتوان به آنها گفت که قرار است چه چیزی به او آموزش داده شود و محتوای آموزش نیز به زبان انسانی قابل ارائه نیست.
بنابراین، فرد یک شرایط مشخص را برای گربه تقلید میکند و گربه سعی میکند تا به روشهای متنوعی در یک شرایط واحد واکنش نشان دهد. اگر گربه به شیوه شایستهای واکنش نشان داد، به عنوان پاداش به او شیر داده میشود. بنابراین، گربه دفعه بعدی که در شرایط مشابه قرار بگیرد اقدام مشابهی را حتی با هیجان بیشتر برای دریافت غذای بیشتر انجام میدهد. همچنین، اگر گربه به خوبی اقدام نکرد و با چهره عصبانی فرد مواجه شد، تلاش میکند که کاری که انجام داده را دیگر انجام ندهد و در واقع یاد نگیرد.

آنچه بیان شد چگونگی کار کردن روشهای یادگیری تقویتی است که در آن به ماشین چند ورودی و «عمل» (Action) داده میشود و سپس بر اساس خروجی دریافتی به او پاداش داده میشود. در یادگیری تقویتی، بیشینهسازی پاداش هدف نهایی به حساب میآید. در ادامه، چگونگی تفسیر مساله گربه به عنوان یک مساله یادگیری تقویتی بیان خواهد شد.
- گربه «عامل» (Agent) قرار گرفته در محیط است.
- «محیط» (Environment)، بسته به نوع چیزی که قرار است به گربه آموزش داده شود میتواند خانه یا فضای بازی باشد.
- شرایطی که گربه با آن مواجه میشود «حالت» (state) است. حالتها گاه مشابه هم هستند. در مثال بیان شده، گربه زیر تخت میخزد یا روی آن میدود. این موارد را میتوان به عنوان حالت تفسیر کرد.
- عامل با انجام اقداماتی برای تغییر یک حالت به دیگری، واکنش نشان میدهد.
- پس از تغییر در حالت، بسته به اقدامی که انجام میشود به عامل «پاداش» (reward) یا «مجازات» (penalty) داده میشود.
- «سیاست»، همان - استراتژی - انتخاب عمل برای پیدا کردن خروجی بهتر است.
اکنون که چیستی یادگیری تقویتی بیان شد، در ادامه به منشا و تکامل یادگیری تقویتی و «یادگیری تقویتی عمیق» (Deep Reinforcement Learning) پرداخته خواهد شد. همچنین، چگونگی حل مساله با استفاده از یادگیری تقویتی در مسائلی که «یادگیری نظارت شده» (Supervised Learning) و «نظارت نشده» (Unsupervised Learning) از حل آنها ناتوانند نیز بیان میشود. مساله بسیار جالبی که بیان آن در اینجا خالی از لطف نخواهد بود این است که که موتور جستوجوی گوگل با بهرهگیری از الگوریتمهای یادگیری تقویتی بهینهسازی شده است.
واژهشناسی یادگیری تقویتی
عامل و محیط نقش اساسی را در الگوریتم یادگیری تقویتی بازی میکند. محیط، همان «جهان» (world) محسوب میشود که عامل در آن زنده است. عامل همچنین یک سیگنال پاداش را از محیط دریافت میکند. این سیگنال عددی است که بیان میکند وضعیت کنونی جهان چقدر خوب یا بد است.

هدف عامل بیشینهسازی «پاداش تجمعی» (Cumulative Reward) است که به آن «بازده» (return) گفته میشود. پیش از آنکه اولین الگوریتم یادگیری تقویتی نوشته شود، نیاز به درک واژگان مهم مبحث یادگیری تقویتی و مفاهیم آنها است.
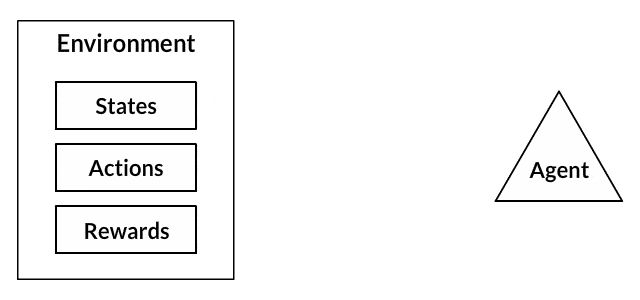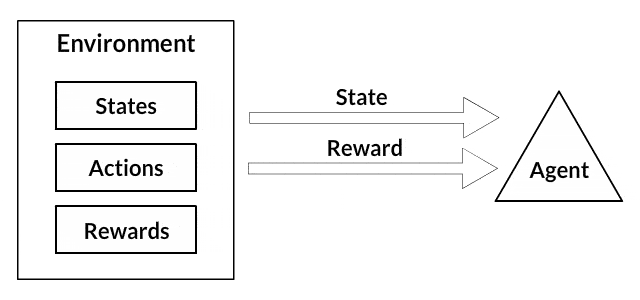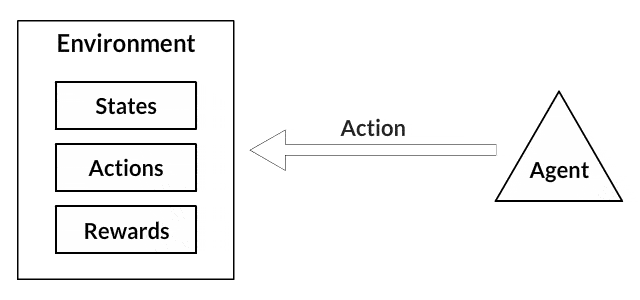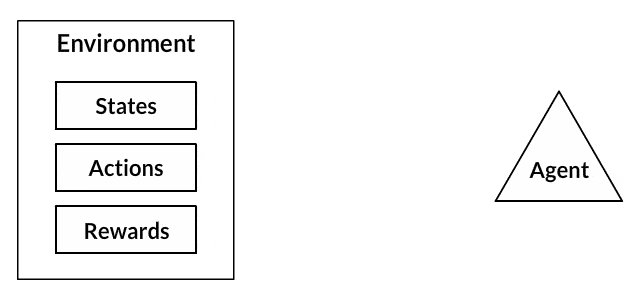
- حالتها (States): «حالت» یک توصیف کامل از محیط است. حالتها هیچ بخشی از اطلاعاتی که توسط جهان ارائه شده را پنهان نمیکنند. حالت میتواند یک «موقعیت» (Position)، «ثابت» (Constant) یا «پویا» باشد.
- عمل (Action): عمل معمولا بر پایه محیط است و محیطهای متفاوت منجر به اعمال متفاوتی میشوند. بنابراین، یک عمل معتبر برای عامل که در فضا ثبت شده، «فضای عمل» (Action Space) نامیده میشود. اعمال معمولا تعداد مشخصی دارند.
- محیط (Environment): محیط در واقع محلی است که عاملی در آن زندگی و تعامل میکند. برای انواع محیطها از پاداشها، سیاستها و دیگر موارد متفاوت استفاده میشود.
- پاداش و بازده (Reward and Return): تابع پاداش R یکی از مواردی است که همواره باید در یادگیری تقویتی مورد پیگیری قرار بگیرد. تابع پاداش نقش اساسی در تنظیم، بهینهسازی الگوریتم و متوقف کردن الگوریتم آموزش دارد. این امر بستگی به وضعیت کنونی، اقدامی که انجام شده و حالت بعدی جهان دارد.
- سیاستها (Policies): سیاست، قاعدهای است که توسط یک عامل برای انتخاب اقدام بعدی استفاده میشود. به این موارد مغز عامل گفته میشود.

اکنون که مفاهیم کلی یادگیری تقویتی بیان شدند، میتوان در ادامه از یادگیری تقویتی برای حل یک مساله با استفاده از الگوریتم یادگیری تقویتی استفاده کرد. بنابراین، نیاز به درک این موضوع است که چگونه میتوان یک مساله را ساخت و از مفاهیم یادگیری تقویتی برای حل آن استفاده کرد.
حل مساله تاکسی
مثالی که در اینجا طرح میشود «مساله تاکسی» است. فرض میشود که یک ناحیه آموزش برای تاکسی وجود دارد و تاکسی در آن میآموزد که چگونه مردم را از یک قسمت پارکینگ به چهار موقعیت مختلف (R,G,Y,B) حمل و نقل کند. پیش از ورود به مساله، نیاز به درک و راهاندازی محیطی است که در آن از پایتون استفاده خواهد شد. مطالعه مطلب «زبان برنامه نویسی پایتون (Python) — از صفر تا صد» به افرادی که در حال فراگیری پایتون هستند توصیه میشود.
میتوان محیط مساله تاکسی را با استفاده از OpenAi’s Gym که یکی از پرکاربردترین کتابخانهها برای حل مسائل یادگیری تقویتی است حل کرد. پیش از استفاده از این ابزار، نیاز به نصب gym روی ماشین است و برای انجام این کار نیاز به استفاده از «نصاب بسته پایتون» (Python Package Installer | PIP) وجود دارد. دستور لازم برای نصب gym در ادامه آمده است.
اکنون، میتوان مشاهده کرد که محیط چگونه همه مدلها را «رِندر» میکند و رابط برای این مساله در حال حاضر در gym پیکربندی شده و Taxi-V2 نامیده شده است. قطعه کد لازم برای رندر کردن محیط در ادامه مطلب ارائه شده است. چهار موقعیت وجود دارد (با حروف مختلف علامتگذاری شدهاند) و کار تاکسی برداشتن مسافران از یک موقعیت و پیاده کردن آنها در موقعیت دیگری است. ۲۰+ امتیاز برای پیادهسازی موفقیتآمیز و ۱ امتیاز منفی برای هر «گام زمانی» (time-step) محاسبه میشود. همچنین، ۱۰ امتیاز مجازات برای عمل سوار کردن و پیاده کردن غیر قانونی وجود دارد. خروجی رندر شده روی کامپیوتر به صورت زیر است.

env هسته OpenAi Gym است، که یک رابط محیط یکپارچه شده محسوب میشود. آنچه در ادامه آمده روشهای env هستند که بسیار مفید واقع خواهند شد:
- env.reset: محیط را بازنشانی میکند و یک حالت اولیه تصادفی را باز میگرداند.
- (env.step(action: متغیرهای زیر را باز میگرداند.
- observation: نشانگر مشاهدات در محیط است.
- reward: اگر یک عمل سودمند باشد، به عامل پاداش داده میشود.
- done: نشان میدهد که مسافر با موفقیت سوار و در محل مناسبی پیاده شده است. به این شرایط یک «اپیزود» (episode) گفته میشود.
- info: اطلاعات اضافی مانند کارایی و تاخیر به منظور انجام «اشکالزدایی» (Debugging) را فراهم میکند.
- env.render: یک فریم از محیط را رندر میکند (در بصریسازی محیط مفید است).
اکنون که محیط مشاهده شد، میتوان مساله را عمیقتر درک کرد. تاکسی تنها خودرو موجود در محوطه پارکینگ است. میتوان محیط را یک شبکه 5x5 در نظر گرفت، که حاصل آن ۲۵ موقعیت ممکن برای تاکسی است. این ۲۵ موقعیت بخشی از فضای حالت محسوب میشوند. باید توجه کرد که موقعیت کنونی تاکسی مختصات (۱ و ۳) است.
در محیط، چهار موقعیت ممکن وجود دارد که میتوان مسافران تاکسی را در آن پیاده کرد. این موقعیتها عبارتند از R ،G ،Y ،B یا [(۴,۳), (۴,۰), (۰,۴), (۰,۰)] در مختصات (سطر, ستون). هنگامی که برای - یک - مسافر اضافی وضعیت سوار بودن در تاکسی بررسی میشود، میتوان همه ترکیبات از موقعیت مسافران و موقعیتهای مقصد آنها که کل حالات برای محیط تاکسی هستند را دریافت کرد. چهار (۴) مقصد و پنج (۴+۱) «موقعیت مسافر» (Passenger Location) وجود دارد.
بنابراین، محیط تاکسی دارای در کل 5×5×5×4=500 حالت است. عامل با یکی از ۵۰۰ حالت مواجه میشود و عمل میکند. اقدام در این شرایط میتواند حرکت از یک جهت یا تصمیم برای سوار/پیاده کردن مسافرها باشد. به بیان دیگر، ۶ حالت ممکن وجود دارد: pickup ،drop ،north ،east ،southwes (این چهار موقعیت به سمتی هستند که تاکسی حرکت میکند). این فضای عمل است؛ یعنی مجموعهای از همه اعمال که عامل میتواند در یک حالت انجام دهد.
Reward Table: هنگامی که محیط یک تاکسی ساخته شد، یک جدول پاداشدهی اولیه وجود دارد که ساخته شده و نام آن p است. میتوان به این ماتریس به چشم ماتریسی نگاه کرد که حالات متعددی را به عنوان سطر و تعداد اعمال به عنوان ستون دارد، یعنی ماتریس states × actions. از آنجا که هر حالتی در این ماتریس وجود دارد، میتوان مقدار پیشفرض تخصیص داده شده به حالت نمایش را مشاهده کرد.
- این دیکشنری، دارای ساختار {[ (action: [(probability, nextstate, reward, done} است.
- ۵–۰ مطابق اقدامات (south، north، east، west، pickup و dropoff) است و تاکسی میتواند در حالت کنونی موجود در تصویر اقدام کند.
- done بدین منظور استفاده شده تا بگوید چه هنگامی به طور موفق مسافر را در محل صحیح پیاده کرده است.
برای حل مساله بدون هرگونه یادگیری تقویتی، میتوان حالت هدف را تنظیم و تعدادی فضای نمونه را انتخاب کرد و اگر با تعدادی تکرار به حالت هدفی که مفروض است برسد، میتوان آن را به عنوان بیشینه پاداش در نظر گرفت. در غیر این صورت، پاداش افزایش مییابد اگر نزدیک به حالت هدف باشد و مجازات افزایش مییابد اگر پاداش برای گام -۱۰ باشد که minimum است. اکنون، کد این مساله بدون استفاده از یادگیری تقویتی ارائه میشود.
از آنجا که جدول P برای پاداش پیشفرض در هر حالت وجود دارد، میتوان تلاش کرد که تاکسی با استفاده از آن گردش کند. در اینجا، یک حلقه بینهایت تا هنگامی که یک مسافر به مقصد برسد (یک اپیزود) یا به عبارت دیگر، هنگامی که پاداش دریافت شده ۲۰ باشد ساخته میشود. روش ()env.action_space.sample به طور خودکار یک عمل تصادفی را از مجموعهای از اعمال ممکن انتخاب میکند. در ادامه آنچه بیان شد در یک قطعه کد پیادهسازی شده است.
خروجی
مساله حل شد ولی خروجی بهینه نیست. البته این مساله هم وجود دارد که الگوریتم همیشه کار نمیکند. بنابراین، نیاز به داشتن عامل تعاملی مناسبی است که تعداد تکرارهایی که ماشین/الگوریتم در آن انجام میدهد بسیار کم باشد. در ادامه از الگوریتم Q-Learning برای حل این مساله استفاده خواهد شد.
مقدمهای بر Q-Learning
الگوریتم «Q-Learning» پر استفادهترین و پایهایترین الگوریتم یادگیری تقویتی است. این الگوریتم از پاداشهای محیط برای یادگیری بهترین عمل قابل انجام در یک حالت داده شده در طول زمان استفاده میکند. در پیادهسازی بالا، جدول پاداش «P» وجود دارد که عامل با توجه به آن یادگیری را انجام میدهد.
عامل با استفاده از جدول پاداش عمل بعدی را در صورت سودمند بودن انتخاب و در صورت سودمند نبودن از آن صرفنظر میکند و سپس مقدار جدیدی که Q-Value نامیده میشود را به روز رسانی میکند. جدول جدید ساخته شده Q-Table نامیده میشود و به ترکیبی که (عمل، حالت) (State, Action) نام دارد، نگاشت میشود. اگر Q-valueها بهتر باشند، پاداش بهینهسازی بیشتر میشود.
برای مثال، اگر تاکسی با حالتی مواجه شود که شامل مسافران در موقعیت کنونی باشد، این احتمال به شدت وجود دارد که Q-value برای سوار کردن مسافر در مقایسه با دیگر اعمال مانند dropoff یا north بیشتر باشد. Q-valueها با یک مقدار دلخواه مقداردهی اولیه میشوند و هنگامی که عامل خود را در معرض محیط قرار میدهد و پاداشهای مختلفی را با اجرای اعمال گوناگون دریافت میکند، Q-valueها با استفاده از معادله زیر به روز رسانی میشوند.

اکنون این پرسش مطرح میشود که چگونه میتوان این Q-Valueها را مقداردهی اولیه و به چه صورت محاسبه کرد. برای انجام این کار، Q-Valueها با ثابتهای دلخواه مقداردهی اولیه میشوند و سپس هنگامی که عامل در معرض محیط قرار گرفت، پاداشهای گوناگونی را با اجرای اعمال مختلف دریافت میکند. هنگامی که اعمال انجام شدند، Q-Valueها با معادله اجرا میشوند. در اینجا، «آلفا» (Alpha) و «گاما» (Gamma)، پارامترهای الگوریتم Q-learning هستند.
آلفا به عنوان نرخ یادگیری و گاما به عنوان فاکتور تنزیل/کاهش (discount factor) شناخته میشود. هر دو مقدار بین ۰ و ۱ و گاهی برابر با یک هستند. گاما میتواند صفر باشد، در حالیکه آلفا نمیتواند، زیرا «زیان» باید با نرخ یادگیری به روز رسانی شود. آلفا در اینجا نمایانگر همان چیزی است که در یادگیری «نظارت شده» (Supervised Learning) وجود دارد. گاما میزان اهمیتی که به پاداشهای آینده داده میشود را تعیین میکند. در زیر، این الگوریتم به صورت مختصر آمده است.
گام ۱: مقداردهی اولیه Q-Table با همه صفرها و Q-Valueها را با یک ثابت دلخواه انجام بده.
گام ۲: به عامل اجازه تعامل با محیط و کاوش در اعمال را بده. برای هر تغییر در این حالت، یکی از میان همه گزینههای ممکن برای حالت کنونی (s) را انتخاب کن.
گام ۳: در نتیجه عمل (a) به گام بعدی (S) حرکت کن.
گام ۴: برای همه اعمال ممکن از حالت (’S)، عملی با بالاترین Q-Value را انتخاب کن.
گام ۵: مقادیر Q-table را با استفاده از معادله به روز رسانی کن.
گام ۶: حالت بعدی را به عنوان حالت کنونی تغییر بده.
گام ۷: اگر حالت هدف رسید، تمام کن و فرآیند را تکرار کن.
کد کامل الگوریتم Q-Learning در پایتون
اکنون، همه مقادیر در متغیر q_table ذخیره خواهند شد. در حال حاضر مدل آموزش دیده و عامل میتواند مسافرها را به طور صحیحتری پیاده کند. افراد میتوانند با تمرین کردن برای حل این مساله و نوشتن کد بالا، یادگیری تقویتی را بهتر درک کنند و قادر به نوشتن کدها و انجام پیادهسازیهای دیگری برای مسائل جدید شوند.
دیگر روشهای یادگیری تقویتی
- «فرایندهای تصمیمگیری مارکوف» (Markov Decision Process) و «معادله بلمن» (Bellman Equation)
- برنامهنویسی پویا: یادگیری تقویتی مبتنی بر مدل، تکرار سیاست و تکرار مقدار
- «یادگیری Q عمیق» (Deep Q Learning)
- روشهای «سیاست گرادیان» (Policy Gradient)
- SARSA
کدهای این مطلب از این مسیر (+) در دسترس هستنند.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش محاسباتی
- آموزش یادگیری تقویتی با متلب
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای برنامهنویسی پایتون
- معرفی منابع جهت آموزش یادگیری عمیق (Deep Learning) — راهنمای کامل
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیس
^^








سلام. ممنون از پست خوبتون. در کد برنامه اول اسم تابع تعریف شده و لیست (frames) یک اسم مشترک دارن که بهتره اسم تابع با F بزرگ نوشته شود.
def Frames(frames):
همچنین در همون برنامه اول بهتر کتابخانه زیر آورده شود تا کد بدون خطا اجرا شود.
from IPython.display import clear_output