



توزیع لاپلاس (Laplace Distribution) – به زبان ساده
در میان توزیعها و متغیرهای تصادفی پیوسته، «توزیع لاپلاس» (Laplace Distribution) دارای کاربردهای زیادی است. در این نوشتار به بررسی این توزیع میپردازیم و در مورد خصوصیات آن بحث خواهیم کرد. از آنجایی که این توزیع برمبنای فاصله قدرمطلق خطاها (Absolute Difference) ساخته شده است، زمانی که میانه برآوردگر بهتری نسبت به میانگین برای نقطه مرکزی دادهها باشد، قادر است رفتار دادههای تصادفی را بهتر توصیف کند.



ضمناً بر حسب اینکه توزیع لاپلاس با توزیع نمایی در ارتباط است، خواندن مطلب متغیر تصادفی و توزیع نمایی — به زبان ساده ضروری به نظر میرسد. همچنین خواندن امید ریاضی (Mathematical Expectation) — مفاهیم و کاربردها نیز خالی از لطف نیست.
توزیع لاپلاس (Laplace Distribution)
توزیع لاپلاس را به قانون اول خطایهای لاپلاس نسبت میدهند. «پیر-سیمون لاپلاس» (Pierre-Simon Laplace) دانشمند و ریاضیدان فرانسوی قرن ۱۸، در پی تحقیقاتی که در مورد کاهش خطای برآوردها انجام میداد، این توزیع آماری را بررسی کرد. او در مقالهای که در سال 1774 منتشر کرد، نشان داده که فراوانی خطاها را میتوان به فرم یک تابع نمایی نشان داد. بعدها «جان کینس» (John Keynes) در سال 1901 نشان داد که توزیع لاپلاس، قدر مطلق خطا نسبت به نقطه میانه را کمینه میسازد.
به این توزیع، گاهی توزیع نمایی دوتایی (Double Exponential Distribution) گفته میشود. زیرا میتوان آن را به صورت دو تابع توزیع نمایی چسبیده به هم تصور کرد. نمودار تابع چگالی احتمال که در ادامه قابل مشاهده است، این موضوع را بهتر نشان میدهد.
تابع احتمال و توزیع تجمعی لاپلاس
اگر متغیر تصادفی دارای تابع چگالی احتمال به صورت زیر باشد، آن یک متغیر تصادفی با توزیع لاپلاس مینامند. در این صورت مینویسند: .
در این رابطه، را «پارامتر مکان» (Location Parameter) و را «پارامتر مقیاس» (Scale Parameter) مینامند.
نکته: اگر و باشد، توزیع لاپلاس از هر طرف (مجموعه مقادیر مثبت و منفی) شبیه دو توزیع نمایی با پارامتر و است.
تابع چگالی احتمال توزیع لاپلاس بسیار شبیه توزیع نرمال است. با این حال، اگر توزیع نرمال به صورت مربع اختلاف از میانگین بیان میشود، در توزیع لاپلاس، تراکم یا چگالی مقادیر به واسطه تفاوت قدر مطلق مقادیر حول میانه خواهد بود. در نتيجه توزيع لاپلاس با دمهای کشیدهتری نسبت به توزیع نرمال رسم میگردد.
در تصویر زیر تابع احتمال توزیع لاپلاس برای مقدارهای مختلف پارامترهایش دیده میشود.

در تصویر بالا دلیل نامگذاری این توزیع با توزیع نمایی دوتایی به وضوح دیده میشود. به نظر میرسد که در نقطه مرکزی یا پارامتر مکان، از سمت راست یک تابع نمایی منفی و در سمت چپ نیز یک تابع نمایی نمایی منفی دیگر رسم شده است. تابع توزیع تجمعی این توزیع احتمالی نیز به صورت زیر نوشته میشود.
$$\large F(x) = \int_{-\infty}^x \!\!f(u)\,\mathrm{d}u = \begin{cases} \frac12 \exp \left( \frac{x-\mu}{b} \right) & \mbox{if }x < \mu \\ \large 1-\frac12 \exp \left( -\frac{x-\mu}{b} \right) & \mbox{if }x \geq \mu \end{cases}$$
به همین ترتیب میتوان نمودار مربوط به تابع توزیع تجمعی این متغیر تصادفی را به صورت زیر ترسیم کرد.

امید ریاضی و واریانس توزیع لاپلاس
با توجه به شکل متقارن توزیع لاپلاس مشخص است که نما، میانه و میانگین در این توزیع برابر با پارامتر مکان () هستند. همچنین واریانس این متغیر تصادفی نیز خواهد بود.
نکته: این توزیع درست به مانند توزیع نرمال، کشیدگی یا چولگی ندارد. در نمودار مربوط به تابع احتمال این توزیع، تقارن در جهت افقی و عمودی به وضوح دیده میشود.
برآورد پارامترهای توزیع لاپلاس
یکی از مهمترین موضوعات در آمار و بخصوص توزیعهای آماری، برآوردگرها و شیوه محاسبه برآورد برای پارامترهای توزیعهای آماری است. در اینجا به معرفی برآوردگرهای حداکثر درستنمایی MLE یا (Maximum Likelihood Estimator) در توزیع لاپلاس میپردازیم. فرض کنید n مشاهده از توزیع لاپلاس به صورت موجود باشد. برآوردگرهای حداکثر درستنمایی برای پارامتر مکان و مقیاس به ترتیب به صورت میانه مشاهدات و میانگین قدرمطلق فاصله از میانه (AD) خواهند بود.
از آنجایی که در رابطه بالا مجموع قدر مطلقها به ازاء میانه حداکثر ممکن خواهد بود، این برآوردگرها حاصل شدهاند.
خصوصیات توزیع لاپلاس
فرض کنید که دارای توزیع لاپلاس با پارامترهای و است. در این صورت رابطههای زیر را خواهیم داشت.
- نیز دارای توزیع لاپلاس با پارامترهای و است.
- اگر باشد، آنگاه است.
- اگر و مستقل با توزیع نمایی با پارامتر باشند، آنگاه است.
- برای متغیر تصادفی با توزیع لاپلاس، دارای توزیع نمایی با پارامتر است.
- اگر دارای توزیع نرمال استاندارد باشند، آنگاه است.
- اگر و متغیرهای تصادفی با توزیع یکنواخت استاندارد باشند، آنگاه خواهیم داشت: است.
شبیهسازی مقدارهای توزیع لاپلاس
فرض کنید متغیر تصادفی یعنی دارای توزیع یکنواخت پیوسته در فاصله (۱/۲و۱/۲-) باشد.

آنگاه با استفاده از رابطه زیر میتوان مقادیری از توزیع لاپلاس را تولید کرد.
در اینجا منظور از همان تابع علامت است. به این معنی که اگر پارامتر این تابع مثبت باشد، مقدار این تابع برابر با ۱+ و در غیراینصورت مقدار آن نیز برابر با ۱- است. یعنی داریم.
کاربردهای توزیع لاپلاس
توزیع لاپلاس در تشخیص گفتار برای مدل سازی برمبنای ضریب DFT یا (Discrete Fourier transform) به کار گرفته شده است. همچنین از این توزیع برای فشردهسازی تصاویر به قالب JPEG نیز بهره گرفته میشود. ضمناً برای انجام رگرسیون خطی و برآورد پارامترهای مدل از کمینهسازی قدر مطلق خطای مدل نیز میتوان بهره برد. به همین ترتیب میتوان رگرسیون لاسو را به عنوان یک «روش رگرسیونی بیزی» (Bayesian Regression Method) برمبنای توزیع پیشین لاپلاس در نظر گرفت.
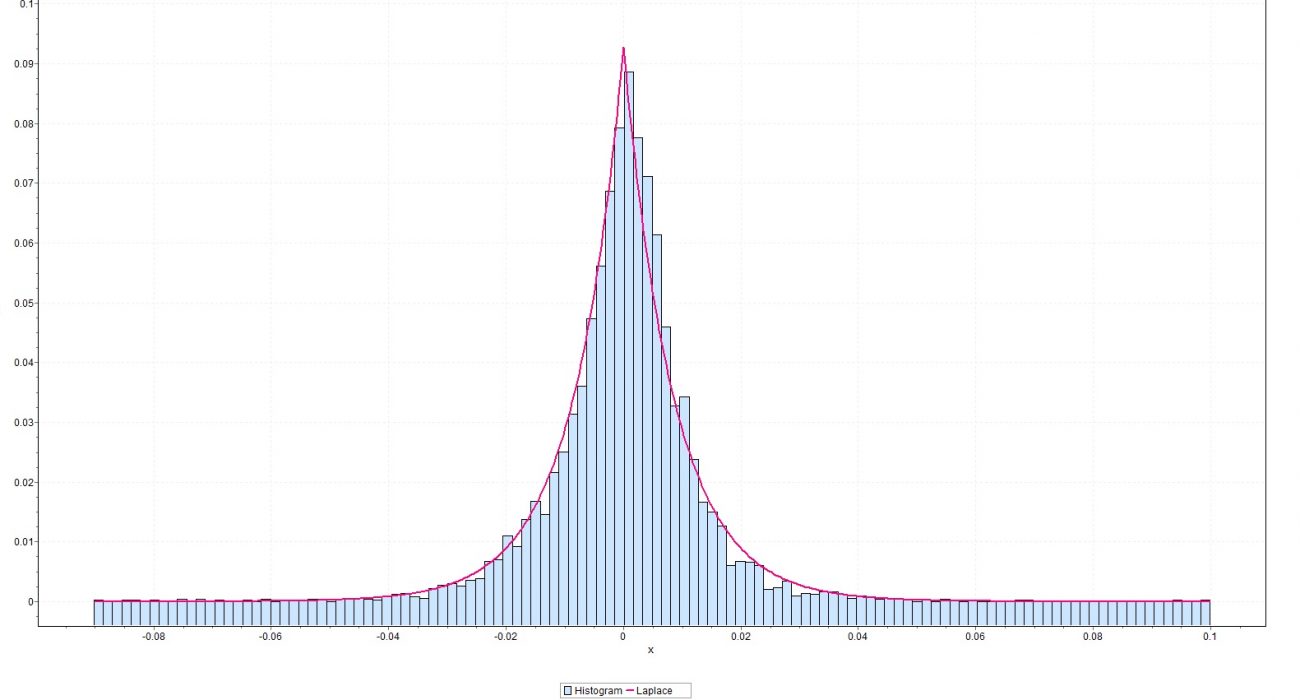
در آبخیزداری و علوم آب و آبشناسی، توزیع لاپلاس برای بیان پیشامدهایی با مقدارهای بسیار بزرگ (کرانگین)، به کار میرود. در تصویر زیر یک نمونه از برازش توزیع دادههای مربوط به میزان حداکثر بارش در روز، بوسیله توزیع لاپلاس دیده میشود.

اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای SPSS
- مجموعه آموزشهای نرمافزارهای آماری
- نامساوی چبیشف – کاربرد در توزیعهای غیرنرمال
- احتمال پسین (Posterior Probability) و احتمال پیشین (Prior Probability) — به زبان ساده
- تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده
^^










