



الگوریتم فازی C–Means در پایتون – راهنمای کاربردی
از اصول «منطق فازی» (Fuzzy Logic)، میتوان برای خوشهبندی دادههای چندبُعدی استفاده کرد. با استفاده از منطق فازی در دادهکاوی، به هر نمونه داده یک «عضویت» (Membership) برای هر «مرکز خوشه» (Cluster Center) تخصیص داده میشود که مقداری بین ۰ الی ۱۰۰ درصد دارد. این روش میتواند نسبت به خوشهبندیهای دارای «آستانه سخت» (Hard-Thresholded) سنتی که در آن هر نمونه یک برچسب مشخص دارد بسیار قدرتمندتر واقع شود. خوشهبندی با الگوریتم فازی C-Means که به آن فازی K-Means نیز گفته میشود، در پایتون با بهرهگیری از تابع skfuzzy.cmeans انجام میشود. خروجی این تابع میتواند برای دستهبندی دادههای جدید، مطابق با خوشههای محاسبه شده (که به آنها پیشبینی نیز گفته میشود)، با بهرهگیری از skfuzzy.cmeans_predict هدفگذاری مجدد شود و در واقع قابل استفاده برای دادههای جدید باشد.


تولید داده و راهاندازی
در این مثال، ابتدا ورودیهای لازم دریافت و سپس، «دادههای آزمون» (Test Data) برای کار تعریف میشوند.

الگوریتم فازی C-Means برای خوشهبندی
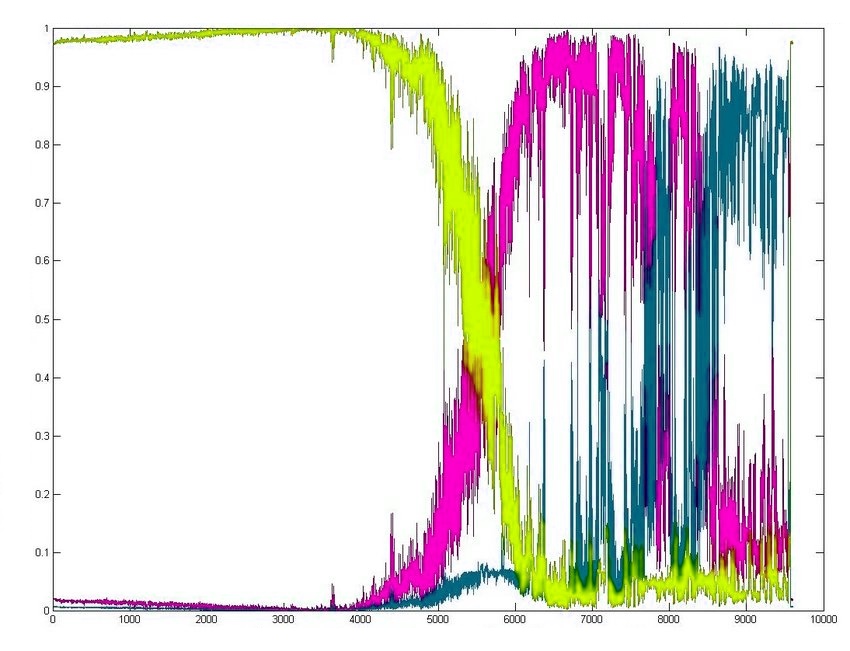
در بالا، دادههای تست مشاهده میشوند. به طور مشخص، سه ناحیه متمایز از هم وجود دارند. اما، اگر مشخص نباشد که چه تعداد خوشه باید وجود داشته باشد چه اقدامی باید انجام داد؟ اگر دادهها خیلی شفاف خوشهبندی نشوند (مرزهای دستهها مشخص نباشد) چه کار باید کرد؟

در ادامه، خوشهبندی چندین بار با تعداد خوشههای بین ۲ و ۹ تکرار میشود.

ضریب تقسیم فازی (FPC)
«ضریب تقسیم فازی» (Fuzzy Partition Coefficient)، در طیفی بین 0 و ۱ قرار میگیرد که در آن ۱ بهترین است. این سنجه به کاربر میگوید که دادهها به وسیله یک مدل چقدر شفاف توصیف شدهاند. سپس، مجموعه دادهها چندین بار با تعداد خوشههای بین ۲ تا ۹ خوشهبندی میشوند (در اینجا این آگاهی از پیش وجود داشت که تعداد خوشهها سه تا است). سپس، نتایج خوشهبندی نمایش داده میشود و نمودار ضریب تقسیم فازی رسم میشود.
هنگامی که مقدار FPC بیشینه شد، دادهها به بهترین شکل توصیف میشوند.

همانطور که مشهود است، تعداد ایدهآل مرکزها برابر با ۳ است. در این مثال کشف این موضوع خبر جدیدی نبود چون همانطور که پیشتر بیان شد، از قبل این آگاهی وجود داشت که تعداد خوشهها سه تا است. اما در حالت کلی، استفاده از FPC هنگامی که ساختار دادهها شفاف نیست، بسیار مفید محسوب میشود. توجه به این نکته لازم است که کار با دو مرکز خوشه آغاز میشود. خوشهبندی مجموعه داده با تنها یک مرکز خوشه یک راهکار بدیهی است و بر اساس تعریف FPC == 1 را باز میگرداند (در واقع تنها یک خوشه وجود دارد که همه دادهها به آن تعلق دارند).
دستهبندی دادههای جدید
اکنون که میتوان دادهها را خوشهبندی کرد، گام بعدی معمولا برازش نمونه دادههای جدید در مدل موجود است. به این کار پیشبینی گفته میشود و به مدل موجود و دادههای جدید برای دستهبندی نیاز دارد. برای دستهبندی دادههای جدید، نیاز به مدل موجود و دادههای جدید برای انجام دستهبندی است.

ساخت مدل
همانطور که پیشتر بیان شد، بهترین مدل دارای سه خوشه خروجی است. در ادامه، مدل سه خوشهای برای استفاده به منظور انجام خوشهبندی مجددا ساخته میشود، دادههای یونیفرم جدید تولید میشوند و پیشبینی میشود که هر نمونه داده جدید به کدام خوشه تعلق دارد.

پیشبینی
در نهایت، دادههایی که به صورت یکنواخت نمونهبرداری شدهاند تولید میشوند و خوشهبندی آنها با بهرهگیری از cmeans_predict انجام میشود. cmeans_predict در واقع آن را در یک مدل از پیش موجود ترکیب میکند.

کد کامل این کار را میتوان از زیر کپی و در فایل با فرمت py. ذخیرهسازی کرد.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش طراحی سیستمهای فازی عصبی یا ANFIS با استفاده از الگوریتمهای فرا ابتکاری و تکاملی
- مجموعه آموزشهای سیستمها و منطق فازی
- داده کاوی (Data Mining) — از صفر تا صد
- داده کاوی فازی چیست؟ — به زبان ساده
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
^^









سلام وقت بخیر
من یک سری داده گرد و غبار دارم که می خواهم با خوشه بندی فازی خوشه بندی انجام دهم ولی مشکل در کد نویسی دارم
لطفا مرا راهنمایی بفرمایید. باتشکر
با سلام و احترام؛
قسمتی از دوره آموزشی زیر به «خوشه بندی فازی و طراحی سیستم فازی مبتنی بر خوشه بندی» اختصاص پیدا کرده است که ممکن است در این مورد برای شما مفید باشد.
آموزش آورده شده در ادامه نیز دارای اطلاعات مفیدی در این رابطه است.
از همراهی شما با مجله فرادرس سپاسگزاریم و برای شما آرزوی موفقیت داریم.