



اطلاع فیشر (Fisher Information) – مفاهیم و کاربردها
یکی از مباحثی که از دستاوردهای آمارشناس و ریاضیدان بزرگ «رونالد فیشر» (Ronald Fisher) محسوب میشود، «اطلاع فیشر» (Fisher Information) یا به اختصار «اطلاع» (Information) است. براساس این نظریه، میتوان مقدار اطلاعاتی را اندازهگیری کرد که یک نمونه تصادفی برای شناخت از پارامتر نامعلوم جامعه () در خود دارد. حتی میتوان به نوعی میزان «اطلاع فیشر» را حساسیت تابع درستنمایی نسبت به تغییرات پارامتر در نظر گرفت.

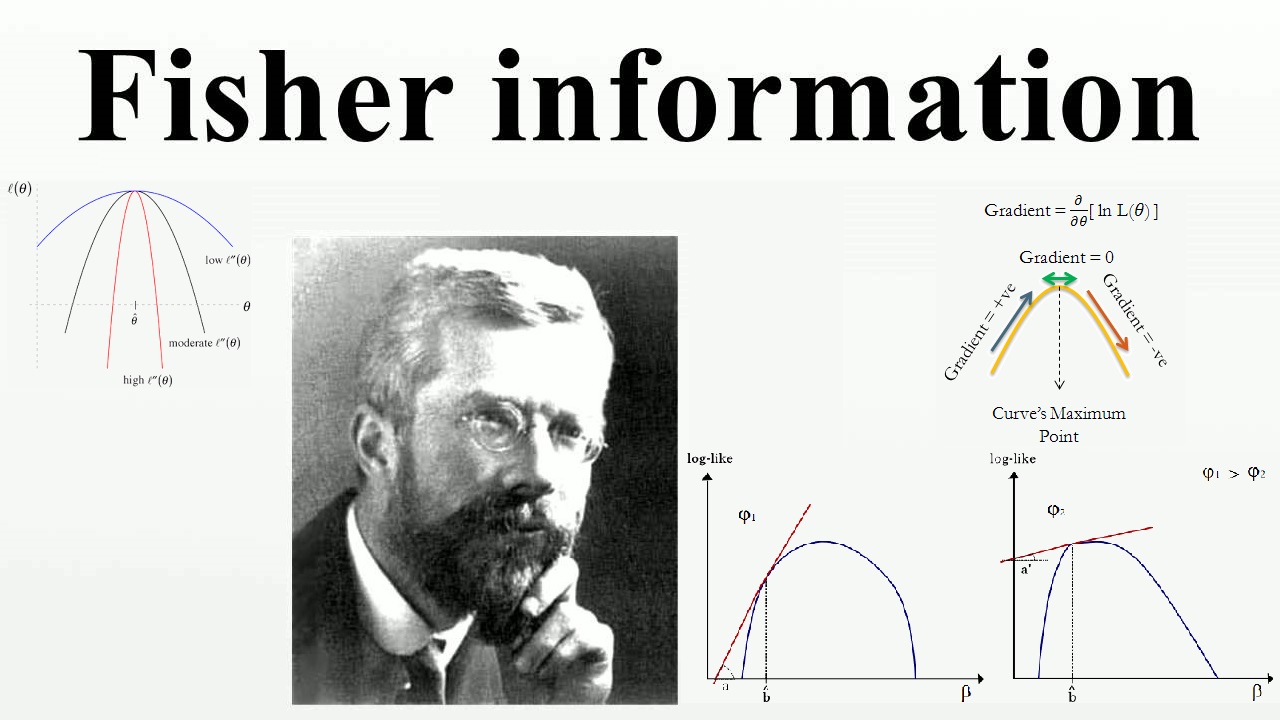


برای آشنایی با مباحث مطرح شده در این نوشتار، بهتر است مطالب تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده و امید ریاضی (Mathematical Expectation) — مفاهیم و کاربردها را مطالعه کنید. همچنین خواندن نوشتار متغیر تصادفی و توزیع برنولی — به زبان ساده و توزیع نرمال یک و چند متغیره — مفاهیم و کاربردها نیز خالی از لطف نیست.
اطلاع فیشر (Fisher Information)
مفهوم و نحوه محاسبه «اطلاع فیشر» توسط بسیاری از آمارشناسان از جمله «پیرسون» (Pearson) و «فیلون» (Filon) مورد بررسی و تحقیق قرار گرفت. ولی این آمارشناس آمریکایی «فیشر» (Fisher) بود که با ابداع «برآوردگر حداکثر درستنمایی» (Maximum Likelihood Estimator) و ارتباط دادن آن با اطلاع فیشر، در نظریه آمار دست به ابتکار زد. براساس اطلاع فیشر میتوان میزان اطلاعاتی را که مشاهدات یک متغیر تصادفی در مورد پارامتر نامعلوم جامعه در خود دارند، اندازهگیری کرد. فرض کنید تابع توزیع احتمال یا تابع چگالی احتمال برای متغیر متغیر تصادفی به صورت نشان داده شود. این تابع به نوعی احتمال مشاهده X را با معلوم بودن پارامتر محاسبه میکند.
حال اگر پارامتر جامعه را به صورت یک متغیر تصادفی در نظر بگیریم، این تابع چگالی به صورت یک تابع چگالی شرطی در خواهد آمد. در این حالت اگر مشاهدات، موجود فرض شوند، این تابع را یک «تابع درستنمایی» (Likelihood Function) محسوب میکنند. اگر این تابع براساس تغییرات به عنوان متغیر رسم شود و منحنی دارای یک قله (حداکثر مقدار) باشد، میتوان نتیجه گرفت که مشاهدات از مقادیر میتوانند برآوردگر خوبی برای پارامتر جامعه باشند. پس دادهها و مقادیر مشاهده شده از متغیر تصادفی دارای اطلاعات زیادی در مورد پارامتر جامعه هستند.
برعکس، اگر تابع درستنمایی به صورت گسترده و پهن باشد، میتوان نمونههای زیادی مانند داشت که برآوردگر مناسب برای پارامتر باشند، پس به نظر میرسد که اطلاع زیادی از پارامتر نخواهد داشت.
نکته: توجه داشته باشید که در اینجا فرض بر این است که مقادیر متغیر تصادفی مشاهده شدهاند و هدف تعیین تغییرات پارامتر است. برای اندازهگیری میزان تغییرات تابع درستنمایی نسبت به پارامتر نیز از مشتق تابع درستنمایی نسبت به پارامتر استفاده خواهیم کرد.

مفهوم اطلاع فیشر
با توجه به توضیحات قبلی، این طور به نظر میرسد که لازم است، واریانس تغییرات تابع درستنمایی (یا تابع یکنوای از آن) را برحسب نمونههای تصادفی، اندازهگیری کنیم. از طرفی میدانیم که تغییرات یک تابع نسبت به متغیر توسط مشتق آن تابع شناخته شده و تعیین میشود.
مشخص است که مقدار اطلاعاتی که نمونههای تصادفی در اختیارمان قرار میدهند، متفاوت است. در ادامه خواهیم دید که متوسط این تغییرات به ازای نمونههای مختلف (امید ریاضی مشتق تابع درستنمایی) برابر با صفر خواهد بود. پس باید مشخص کنیم که پراکندگی تغییرات تابع درستنمایی برای نمونههای مختلف چقدر است. به این ترتیب از واریانس به عنوان معیار مقایسه استفاده خواهیم کرد. همانطور که در نوشتار مربوط به امید ریاضی خواندهایم، میدانیم که برای پیدا کردن واریانس یک متغیر تصادفی باید از رابطه زیر کمک گرفت.
رابطه ۱
البته از آنجایی که در اکثر مواقع تابع درستنمایی به شکل نمایی نوشته شده است، استفاده از عملگر لگاریتم تاثیری در تعیین رفتار تابع درستنمایی نخواهد داشت. پس عمل مشتقگیری را بر روی لگاریتم تابع درستنمایی انجام خواهیم داد و سپس واریانس تابع حاصل را برحسب نمونههای تصادفی محاسبه میکنیم.
اغلب به مشتق لگاریتم تابع درستنمایی، «تابع امتیاز» (Score Function)، میگویند که حساسیت تابع درستنمایی را به پارامتر تعیین میکند. به این ترتیب مشخص است که واریانس تابع امتیاز، همان اطلاع فیشر خواهد بود.
با توجه به رابطه ۱ و مفهوم اطلاع فیشر خواهیم داشت:
برای شروع کار بهتر است اصطلاح شرایط نظم را شرح دهیم، زیرا اطلاع فیشر براساس «شرایط نظم» (Regularity Condition) راحتتر محاسبه میشود.
شرایط نظم (Regularity Condition)
همانطور که دیدید، برای سادهتر کردن و انجام محاسبات مربوط به اطلاع فیشر از شرایط نظم اسم برده شد. در این قسمت به معرفی شرایط نظم خواهیم پرداخت. این شرایط را مطابق فهرست زیر میشناسیم.
- پارامتر مجهول () یک فاصله باز از اعداد حقیقی است. ()
- مشتق تابع چگالی احتمال متغیر تصادفی وجود دارد.
- جابجایی بین عملگرهای مشتق و انتگرال امکانپذیر است.
- رابطه زیر برای هر نقطه از پارامتر برقرار است. به این معنی که گشتاور دوم مشتق تابع لگاریتم درستنمایی موجود بوده، مخالف صفر است.
محاسبه اطلاع فیشر در حالت یک متغیره
تحت «شرایط نظم» (Regularity Conditions) که معرفی شده است، میتوان نشان داد، امید ریاضی مشتق لگاریتم تابع درستنمایی نسبت به پارامتر براساس نمونه تصادفی صفر است. زیرا داریم:
در نتیجه جمله دوم از سمت راست رابطه ۱ صفر بوده و کافی است که فقط جمله اول را برای محاسبه واریانس بدست آوریم. این مقدار به عنوان اطلاع فیشر معروف است و بوسیله رابطه زیر محاسبه میشود.
البته باز هم تحت «شرایط نظم» و با فرض وجود مشتق دوم برای تابع درستنمایی میتوان شکل سادهتری برای محاسبه اطلاع فیشر نیز ایجاد کرد.
رابطه ۲
علت این امر آن است که براساس مشتق دوم لگاریتم تابع درستنمایی میتوان رابطههای زیر را نوشت:
باز هم تحت شرایط نظم، امید ریاضی جمله اول سمت راست تساوی برابر با صفر است. زیرا با توجه به مفهوم و خصوصیت تابع چگالی احتمال و امکان جابجایی مشتق و انتگرال طبقه شرایط نظم، مقدار انتگرال زیر برابر با ۱ شده و مشتق مقدار ثابت برابر با صفر است. به این ترتیب امید ریاضی اولین جمله سمت راست تساوی بالا برحسب نمونه تصادفی (توزیع متغیر تصادفی )، صفر خواهد بود.
در نتیجه کاملا مشخص است که با توجه به وجود شرایط نظم برای تابع چگالی متغیر تصادفی میتوان اطلاع فیشر را به شکل سادهتری، مطابق با رابطه ۲، نوشت.
در ادامه به بررسی یک مثال برای متغیر تصادفی گسسته برنولی میپردازیم. البته در این مورد توجه داشته باشید که دامنه تغییرات برای پارامتر این توزیع زیرمجموعهای از اعداد حقیقی است و با توجه به پیوستگی و مشتقپذیر بودن تابع درستنمایی یا چگالی احتمال برحسب پارامتر امکان جابجایی انتگرال و مشتق وجود دارد.
مثال ۱- اطلاع فیشر برای پارامتر توزیع برنولی
متغیر تصادفی برنولی را در نظر بگیرید. مشخص است که در این حال پارامتر احتمال موفقیت در نظر گرفته شده است. مقدارهای متغیر تصادفی نیز به صورت دو وضعیتی با ۰ برای شکست و ۱ برای موفقیت تعیین شده.
با توجه به متغیر تصادفی برنولی، میدانیم امید ریاضی آن برابر با پارامتر است. حال اطلاع فیشر برای پارامتر به صورت زیر نوشته خواهد شد.
اگر یک نمونه n تایی از این متغیر تصادفی وجود داشته باشد، اطلاع فیشر برای چنین نمونهای به صورت زیر در خواهد آمد.
رابطه ۳
همانطور که دیده میشود، این مقدار معکوس واریانس متغیر تصادفی برنولی با n بار تکرار است.
خاصیت زنجیرهای اطلاع فیشر
«اطلاع فیشر» برای دو متغیر تصادفی و را میتوان به دو بخش تفکیک کرد. به این تفکیک «خاصیت زنجیرهای» (Chain Rule) میگویند. فرض کنید که این دو متغیر تصادفی دارای توزیع توام باشند. آنگاه اطلاع فیشر این دو متغیر تصادفی به صورت زیر تفکیک می شود.
توجه داشته باشید که منظور از ، اطلاع فیشر نسبت به براساس تابع چگالی شرطی با معلوم بودن است.
اگر دو متغیر تصادفی و مستقل از یکدیگر باشند، رابطه به شکل سادهتری در خواهد آمد که در ادامه قابل مشاهده است.
مشخص است که اطلاع توام متغیرهای و به صورت جمع اطلاع فیشر هر یک نوشته شده است. بر همین اساس میتوان اطلاع فیشر یک نمونه تصادفی nتایی (مستقل و هم توزیع) را به صورت جمع اطلاع فیشر هر یک از اعضای نمونه نوشت. این خاصیت را برای محاسبه رابطه ۳ به کار بردهایم.
ارتباط با کران پایین کرامر-رائو (Cramér–Rao bound)
حداقل ممکن برای واریانس برآوردگر توسط «کران پایین کرامر-رائو» (Cramér–Rao bound) بیان میشود. به این ترتیب اگر واریانس برآوردگری به کران پایین کرامر-رائو برسد، دیگر نمیتوان آن را بهبود دارد و اگر کم بودن واریانس را ملاک انتخاب برآوردگر مناسب در نظر بگیریم، آن برآوردگری که واریانس آن برابر با کران پایین کرامر-رائو باشد، بهترین برآوردگر خواهد بود.
فرض کنید پارامتر جامعه و برآوردگر نااریب آن نیز باشد. اگر اطلاع فیشر برای این برآوردگر را با نشان دهیم، میتوان رابطه زیر را بین واریانس این برآوردگر و اطلاع فیشر نوشت.
به این ترتیب اگر واریانس برآوردگر یعنی را به معنی دقت برآوردگر در نظر بگیریم، کران پایین برای آن معکوس اطلاع فیشر خواهد بود.
نکته: در اینجا کران پایین کرامر-رائو را برای برآوردگرهای نااریب (Unbiased Estimator) نوشتهایم. برآوردگرهایی نااریبی که واریانسی برابر با کران پایین کرامر-رائو داشته باشند، برآوردگرهای نااریب با کمترین واریانس یکنواخت (UMVUE- Uniform Minimum Variance Unbiased Estimator) گفته میشوند.
آماره بسنده و اطلاع فیشر
براساس تعریف «آماره بسنده» (Sufficient Statistic) میدانیم، بیشترین اطلاعات در مورد پارامتر، توسط آماره بسنده ارائه میشود. فرض کنید که نمونه تصادفی باشد، مشخص است که این نمونه تصادفی بیشترین اطلاعات را در مورد پارامتر دارد. اگر آماره بسنده برای پارامتر به صورت نمایش داده شود، میزان اطلاعاتی که آماره بسنده در مورد پارامتر دارد برابر با نمونه تصادفی است.
اگر یک آماره بسنده برای پارامتر باشد، میتوان تابع چگالی احتمال برای متغیر تصادفی را به صورت زیر تجزیه کرد. این تجزیه به «معیار تفکیک نیمن» (Neyman's Factorization Criterion) مشهور است و به کمک آن میتوان آماره بسنده را شناسایی کرد.
در این رابطه، تابعی برحسب (آماره بسنده) و پارامتر بوده ولی تابع فقط به نمونه تصادفی بستگی دارد. حال براساس این تفکیک، اطلاع فیشر را محاسبه میکنیم. از آنجایی که به پارامتر بستگی ندارد، هنگام مشتقگیری از تابع درستنمایی حذف خواهد شد. در نتیجه خواهیم داشت:
به این ترتیب به کمک این تساوی مشخص میشود که اطلاع فیشر حاصل از نمونه تصادفی با آماره بسنده برابر است. پس اطلاع فیشر براساس آماره بسنده نااریب ، کران پایین برای واریانس هر برآوردگر نااریب دیگر مثل خواهد بود.
زیرا بین اطلاع فیشر هر یک از آنها رابطه زیر برقرار است:
ماتریس اطلاع فیشر (Fisher Information Matrix-FIM)
اگر توزیع آماری متغیر تصادفی دارای پارامتر باشد آنگاه بردار پارامتر به صورت نوشته شده و اطلاع فیشر برای این توزیع برحسب پارامتر، یک ماتریس خواهد بود.
در این حالت ماتریس اطلاع فیشر (Fisher Information Matrix-FIM) دارای عناصری به صورت زیر خواهد بود.
تحت شرایط خاص نظم، میتوان عناصر ماتریس فیشر را به شکل سادهتری درآورد تا محاسبات راحتتر صورت گیرد. رابطه زیر جملات یا عناصر ماتریس فیشر را بر اساس مشتق دوم نمایش میدهد.
با کمی دقت متوجه خواهید شد که این رابطه درست به مانند رابطه مربوط به متغیر تک بعدی نوشته شده است.
به این ترتیب میتوان «پارامترهای عمود برهم» (Orthogonal Parameters) را تعریف کرد. پارامترهای و را عمود بر هم گویند اگر عناصر سطر iام و ستون jام ماتریس اطلاع فیشر، صفر باشد. از آنجایی که صفر بودن این عناصر نشان دهنده مستقل بودن برآوردگرهای حداکثر درستنمایی این پارامترها است، به راحتی امکان بدست آوردن این برآوردگرها وجود دارد. به همین دلیل محققین به دنبال نشان دادن عمود بودن پارامترهای توزیع هستند تا بتوانند با شیوه «حداکثرسازی تابع درستنمایی» (Maximum Likelihood Method)، برآوردگرها را محاسبه کنند.
مثال ۲- اطلاع فیشر برای پارامترهای توزیع چند متغیره نرمال
ماتریس اطلاع فیشر برای «توزیع نرمال چند متغیره» دارای شکل خاصی است. در این مثال به محاسبه و بررسی این ماتریس میپردازیم. فرض کنید که متغیر تصادفی دارای توزیع نرمال چند متغیره باشد، یعنی داریم . در اینجا بردار میانگین و ماتریس واریانس-کوواریانس، برحسب پارامتر نوشته شدهاند. بنابراین ماتریس اطلاع فیشر (FIM) به صورت زیر در خواهد آمد.
که در آن منظور از ، ترانهاده بردار و نیز «اثر ماتریس» (Trace) است. یعنی:
و همچنین برای ماتریس واریانس-کوواریانس نیز خواهیم داشت.
نکته: اگر همه مولفههای ماتریس واریانس-کوواریانس برابر و بستگی به نداشته باشند، (یعنی داشته باشیم )، فرم اطلاع فیشر به صورت سادهتری در خواهد آمد. به رابطه زیر توجه کنید.
کاربردهای اطلاع فیشر
در «آمار بیز» (Bayesian Statistics) اگر هیچ اطلاع یا توزیعی پیشینی برای پارامتر نتوان در نظر گرفت، از توزیع «پیشین جفریز» (Jeffreys Prior) که برحسب اطلاع فیشر محاسبه میشود، استفاده میکنند. پیشین جفریز را به عنوان پیشین استاندارد یا پیشین «بدون اطلاع» (Non-informative) برای توزیعهای پیوسته در نظر میگیرند.
همچنین از اطلاع فیشر در تکنیکهای «یادگیری ماشین» (Machine Learning) مانند روش «تثبیت وزنهای الاستیک» (Elastic Weight Consolidation) که به اختصار EWC نامیده میشود، بهره میبرند.
در مسائل «طرح آزمایشات» (Experimental Design) از اطلاع فیشر استفاده میشود. زیرا برحسب نسبت واریانس برآوردگر و اطلاع فیشر، میتوان با حداقل کردن واریانس نسبت به حداکثر کردن اطلاع فیشر، برآوردگر مناسب را پیدا کرد. در آزمون همزمان والد نیز ماتریس اطلاع فیشر به کار رفته و در انجام محاسبات مربوط به این آزمون به کار گرفته میشود.
اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای SPSS
- آموزش آمار و احتمال مهندسی
- آزمایش تصادفی، پیشامد و تابع احتمال
- مجموعه آموزشهای نرمافزارهای آماری
- متغیر تصادفی و توزیع برنولی — به زبان ساده
- تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده
^^











با درود و خداقوت به جناب آرمان ری بد و تمام دست اندرکاران فرادرس
مطالب فرادرس همیشه مفید هستند
بویژه این مطلب که یک موضوع تخصصی در آمار است، به خوبی بیان شده است
امیدوارم شاهد گسترش دانش آمار، بویژه آمار کاربردی در کارشناسان و تصمیم سازان کشورمان باشیم
با تشکر از مطالب بسیار مفیدتان