



بروز رفتارهای فوق هوشمند در تعاملات چند عامله – بررسی جامع
پژوهشهای انجام شده در زمینه «تعاملات چند عامله» (Multi-Agent Interactions) حاکی از آن است که عاملها در طی انجام یک بازی «قایمموشک» ساده، به تدریج روشهای پیچیدهتری برای استفاده از ابزارهای موجود در محیط کشف میکنند. در ادامه، به پژوهشی که اخیرا توسط دانشمندان «هوش مصنوعی» (Artificial Intelligence) و «یادگیری ماشین» (Machine Learning) در OpenAI انجام شده است، پرداخته میشود.




استفاده اضطراری از ابزارها در تعاملات چند عامله
در پژوهش انجام شده توسط دانشمندان OpenAI، عاملهای هوشمند در یک محیط ساده، بازی قایم موشک انجام میدهند. برای درک بهتر آنچه در ادامه بیان خواهد شد، ابتدا توضیحاتی در رابطه با محیط مذکور ارائه میشود. برای تولید این محیط، میتوان از کدهای آن که در گیتهاب پروژه [+] موجود است، استفاده کرد.
در محیط این بازی، دو دسته از عاملهای هوشمند وجود دارند. یک دسته که به رنگ آبی رنگ هستند و نقش بره را ایفا میکنند، در تلاش هستند تا از میدان دید گرگها فرار کنند و توسط آنها دیده نشوند. این برهها برای رسیدن به هدف مذکور، با یکدیگر همکاری میکنند.
دسته دوم عاملهای هوشمند موجود در این محیط، گرگها هستند. گرگها یا همان بازیکنان قرمز رنگ، در تلاش هستند تا برهها را پیدا کنند. این گرگها یک میدان دید مخروطی دارند که در ویدئو نیز قابل مشاهده است. اگر بره در این میدان دید قرار بگیرد، توسط گرگ مشاهده میشود. در این محیط، دیوارهایی قرار گرفته است و در میان آنها، فواصلی به عنوان راه عبور وجود دارد که به صورت تصادفی ایجاد شدهاند.
همچنین، جعبههای مکعبی و زرد رنگی وجود دارد که عاملها (چه گرگها و چه برهها) میتوانند آنها را تصاحب و استفاده کنند. در واقع، وقتی یک عامل این جعبه را لمس میکند، آن را از آن خود میکند. سپس، میتواند با قرار دادن آن در محل مناسب، برای رسیدن به هدف خود (هدف برای برهها فرار از دست گرگها و هدف گرگها، پیدا کردن برهها است) از آن استفاده کند. برای استفاده از این جعبهها، بازیکن جعبه را با حرکت دادن در محیط مناسب قرار داده و در آن موقعیت «قفل» (Lock) میکند. نکته شایان توجه این است که فقط و فقط، تیمی که جعبه را قفل کرده، میتواند قفل آن را باز کند. برهها از این جعبهها معمولا برای مسدود کردن مسیر عبور موجود در میان دیوارها و راه عبور و دید گرگها استفاده میکنند.
وسیله دیگری که در این محیط وجود دارد، سطحهای شیبدار (رَمپ | Ramp) هستند. گرگها از سطح شیبدار برای موجسواری و پرتاب خود استفاده میکنند. برهها در تلاش هستند تا این سطحهای شیبدار را در قسمتی از محیط که مسیر عبور گرگها به آن را با استفاده از جعبهها مسدود کردهاند پنهان کنند تا گرگها نتوانند از آنها استفاده کنند.
البته در ادامه مشخص میشود که عاملها به مرور زمان یاد میگیرد که از ابزارهای موجود در محیط، استفادههای پیچیدهتری کنند. برای مثال، گرگها، با پرش روی جعبهها تلاش میکنند تا برهها را شکار کنند (قرار گرفتن بره در میدان دید گرگ) و برهها سطحهای شیبدار را به بیرون از محیط بازی پرتاب میکنند تا گرگها نتوانند از آنها استفاده کنند. از دیگر رفتارهای جالب عاملهای هوشمند، فرار بیپایان برهها به بیرون از محیط بازی است. در ادامه، به طور دقیقتر به این موضوع پرداخته میشود.
در ابتدا، با آموزش دادن محیط بازی قایمموشک شبیهسازی شده، عاملها مجموعهای از ۶ «استراتژی» (Strategies) و استراتژیهای مقابله (Counterstrategies) متمایز را میآموزند. نکته جالب توجه آن است که پژوهشگران، خود حتی از اینکه محیط آنها از برخی از دیگر استراتژیها پشتیبانی میکند نیز آگاه نبودهاند. پیچیدگی «اضطراری خود نظارتی» (Self-Supervised Emergent) در این محیط ساده، حاکی از آن است که «سازگاری چندعامله» (Multi-Agent co-adaptation) ممکن است روزی منجر به ایجاد رفتارهای فوق پیچیده و هوشمند شود.
در محیط موجود، کاربران یک بازی قایمموشک تیمی انجام میدهند. در اینجا، بازیکنان آبی نقش برهها (افرادی که مخفی میشوند) را ایفا میکنند و بازیکنان قرمز، نقش گرگ (کسی که به دنبال برهها میگردد) را بازی میکنند. همانطور که پیش از این نیز بیان شد، در محیطی که ویدئوهای آن را مشاهده میکنید، برهها (آبیها) وظیفه دارند از میدان دید گرگها (قرمزها) اجتناب کنند.
اشیایی (جعبهها و سطحهای شیبدار) در این محیط به صورت پراکنده قرار دارند که گرگها و برهها میتوانند آنها را تصرف (بقاپند) و با قرار دادن و قفل کردن آنها در یک محل خاص، از آنها استفاده کنند. همچنین، اتاقهای ثابت و غیر قابل حرکت دادن نیز در محیط وجود دارند که به طور تصادفی ساخته شدهاند و عاملها (گرگها و برهها) باید یاد بگیرند که در آنها حرکت کنند.
پیش از آنکه بازی آغاز شود، برهها یک فاز آمادهسازی دارند. در این فاز، گرگها بیحرکت و در واقع ثابت شدهاند تا برهها این شانس را پیدا کنند که فرار کرده و یا محیط خود را تغییر بدهند.
عاملها میتوانند با وارد کردن نیرو به خودشان، در جهت محورهای y ،x و z حرکت (Move) کنند.
عاملها میتوانند اشیا را در میدان دید و در واقع، در یک ناحیه مخروطی که در ویدئو مشاهده میکنید، ببینند (See).
عاملها میتوانند فاصله تا اشیا، دیوارها و دیگر عاملها را «احساس» (Sense) کنند. آنها برای انجام این کار، از حسگرهای «لیدار» (Lidar) مانند استفاده میکنند.
عاملها میتوانند اشیای جلوی خودشان را «بگیرند» (Grab) و «حرکت» (Move) دهند.
عامل میتواند شی (جعبه) را در محل خود قفل (Lock) کند. فقط تیمی که یک شی را قفل کرده، میتواند قفل آن را باز کند.
هیچ انگیزه مشخصی برای تعامل عاملها با اشیا در محیط وجود ندارد. تنها نظارتی که داده شده مربوط به هدف بازی قایمموشک است. عاملها پاداش تیمی دریافت میکنند؛ برهها در صورتی که همه برهها قایم (پنهان) شوند ۱+ امتیاز پاداش میگیرند و اگر هر یک از برهها توسط گرگ مشاهده شد، ۱- امتیاز مجازات میشوند. برای محدود کردن رفتار عامل به یک فضای معقول، میتوان در صورت خروج عامل از فضای بازی آن را مجازات کرد. در طول فاز آمادهسازی، همه عاملها پاداش صفر دارند.
برنامه آموزشی خودکار و رفتار اضطراری
با آموزش دیدن عاملها در بازی قایمموشک برای اقدام علیه یکدیگر، ۶ استراتژی متمایز ظهور میکند. هر استراتژی جدید، فشاری که از قبل موجود نبوده است را برای عاملها میسازد تا به مرحله بعد پیشرفت کنند. شایان توجه است که هیچ انگیزه صریحی برای عامل، به منظور تعامل با اشیا یا اکتشاف آنها وجود ندارد.
استراتژیهای اضطراری که در ادامه نمایش داده شدهاند، نتیجه «برنامه آموزشی خودکار» (Auto Curriculum) استنتاج شده توسط رقابتهای چند عاملی و دینامیک ساده بازی قایمموشک است.
اضطرار در یک محیط ساده
ابتدا، استراتژیهای اضطراری یاد گرفته شده در یک محیط ساده با ۲ بره، ۲ گرگ، ۲ جعبه و ۱ سطح شیبدار (رَمپ)، و یک اتاق که بین دیوارهای آن ۱ یا ۲ در به طور تصادفی قرار گرفتهاند، مورد بررسی قرار میگیرد.
اپیزود ۰:
تصادفی: عاملها به طور تصادفی حرکت میکنند.
اپیزود ۰-۲/۶۹ میلیون
تعقیب: گرگها یاد میگیرند که برهها را تعقیب کنند.
اپیزود ۲/۶۹-۸/۶۲ میلیون
مسدود کردن درها: برهها یاد میگیرند که جعبهها را بگیرند و برای مسدود کردن درها، جعبهها را حرکت دهند.
اپیزود ۸/۶۲-۱۴/۵ میلیون
استفاده از سطح شیبدار: گرگها یاد میگیرند که از سطح شیبدار برای پریدن از موانع استفاده کنند.
اپیزود ۱۴/۵-۴۳/۴ میلیون
دفاع با سطح شیبدار: برهها یاد میگیرند که سطح شیبدار را به درون اتاق ببرند تا مانع از این شوند که گرگها از آنها استفاده کنند.
علاوه بر اینها، برهها یاد میگیرند که هماهنگی کنند چه کسی کدام یک از درها را مسدود کند و چه کسی، سطح شیبدار را بگیرد. در شرایطی که جعبهها از درها دور هستند، برهها به منظور مسدود کردن درها، جعبهها را به یکدیگر پاس میدهند.
اضطرار در محیط کامل
در ادامه، استراتژیهای اضطراری یاد گرفته شده در محیط با تصادفیسازیهای بیشتر، شامل ۱-۳ بره، ۱-۳ گرگ، ۳-۹ بلوک، ۲ سطح شیبدار و اتاقها و درهای تصادفی است. در این محیط کامل، عاملها از دو فاز استراتژی اضطراری بیشتر نیز، نسبت به محیط ساده قبلی، استفاده میکنند.
اپیزود ۰
تصادفی: عاملها به طور تصادفی حرکت میکنند.
اپیزود ۰-۲۲ میلیون
تعقیب: گرگها یاد میگیرند که برهها را تعقیب کنند.
اپیزود ۲۲-۸۸ میلیون
ساخت جانپناه: برهها یاد میگیرند که یک پناهگاه برای مخفی شدن بسازند.
اپیزود ۸۸-۱۱۵ میلیون
استفاده از سطح شیبدار: گرگها یاد میگیرند که از مانع بپرند.
اپیزود ۱۱۵-۳۸۸ میلیون
دفاع با سطح شیبدار: برهها یاد میگیرد که سطوح شیبدار را برای جلوگیری از اینکه گرگها از آنها استفاده کنند، قفل کنند.
اپیزود ۳۸۸-۴۵۸ میلیون
موجسواری با جعبه: گرگها یاد میگیرند جعبهها را نزدیک یک سطح شیبدار قفل شده بیاورند تا روی جعبه بپرند و سپس، از روی آن «موجسواری» و به پناهگاه برهها حمله کنند. موجسواری با جعبه، با توجه به مکانیزم تحریک عامل، امکانپذیر است؛ زیرا بر این اساس، عاملها یاد میگیرند که به خودشان صرف نظر از اینکه روی زمین هستند یا نه، نیرو وارد کنند.
اپیزود ۴۵۸-۴۸۱
دفاع در مقابل موجسواری: برهها میتوانند یاد بگیرند که همه سطحهای شیبدار و جعبهها را برای جلوگیری از موجسواری با جعبه، قفل کنند.
آموزش دادن عاملهای قایمموشک
در اینجا، از زیرساخت و الگوریتمهایی مشابه با آنچه که برای آموزش دادن OpenAI Five و Dactyl بهره گرفته شده بود، استفاده میشود. اگرچه، در محیط کنونی، هر عامل با استفاده از مشاهدات و وضعیت حافظه پنهان خود، به طور مستقل فعالیت میکند. عاملها از یک ارائه «موجودیت محور» (Entity-Centric) «حالت محور» (State-Based) از جهان استفاده میکنند که با توجه به اشیا و دیگر عاملها تغییرناپذیر است.
هر شی به صورت توکار قرار داده شده است و سپس، از طریق یک «بلوک خود توجه باقیمانده ماسک شده» (Masked Residual Self Attention Block) که مشابه با آنچه هستند که در مبدلها استفاده شده است، پاس داده میشوند. در این بلوکها، توجه بیشتر به اشیا است، نه زمان. اشیایی که در میدان دید نیستند و در مقابل عامل قرار دارند، به گونهای ماسک شدهاند که عامل هیچ اطلاعاتی از آنها ندارد.
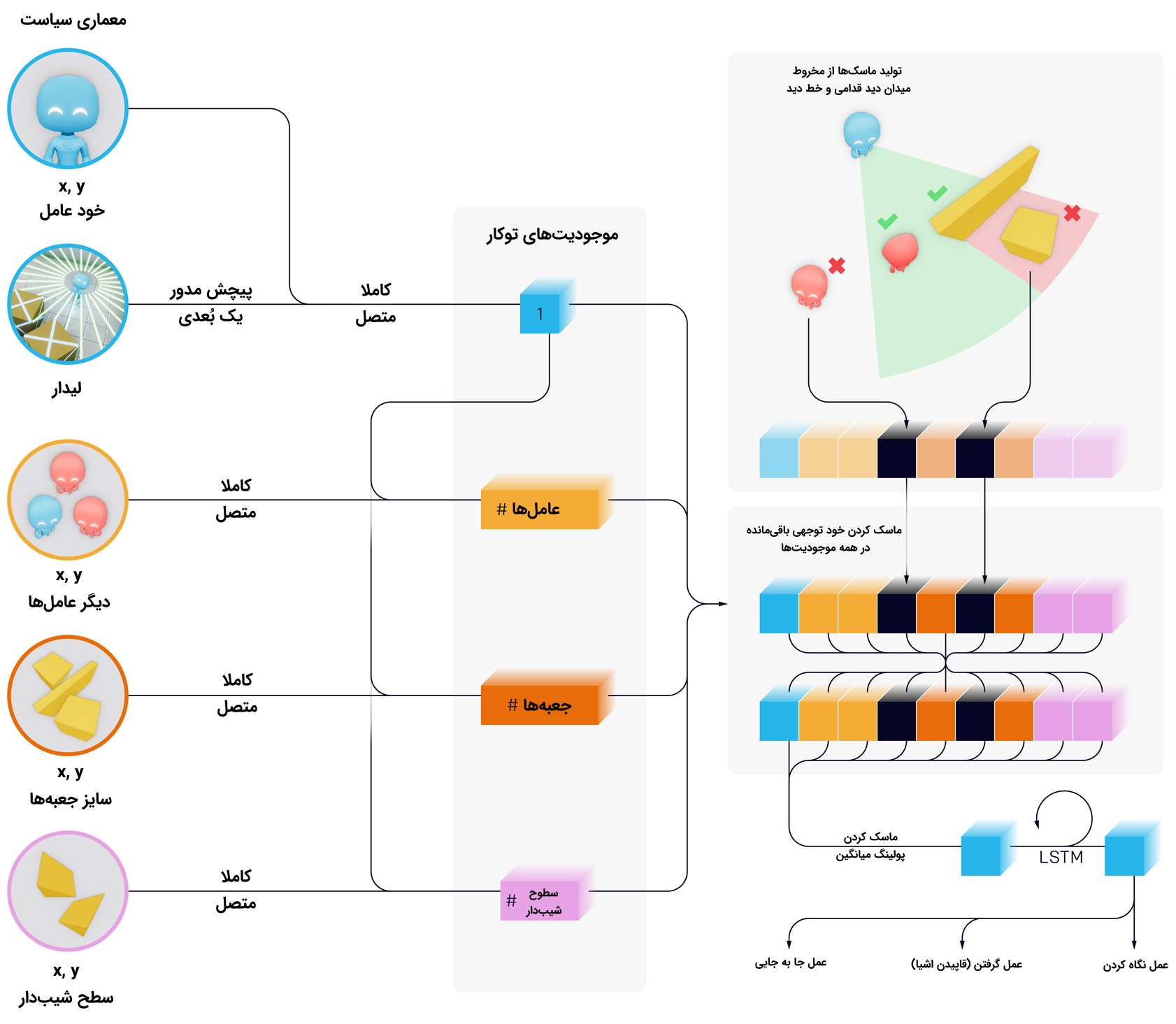
برای مشاهده تصویر در ابعاد بزرگتر، کلیک کنید.
سیاستهای عامل با «خود-نقشآفرینی» (Self-Play) و «بهینهسازی سیاست تقریبی» (Proximal Policy Optimization) آموزش داده میشوند. در طول بهینهسازی، عاملها میتوانند از اطلاعات ممتاز پیرامون اشیای مبهم و دیگر عاملها، در تابع ارزش خود استفاده کنند.
طی این پژوهش، کشف شده است که آموزش بزرگ مقیاس برای پیشرفت عامل در مراحل مختلف ظهور، حیاتی است. در زیر، زمان و تعداد اپیزودهایی که طول میکشد تا عامل به گام ۴ (دفاع با سطح شیبدار) برسد، برای سایزهای دسته گوناگون، ارائه شده است. در این میان، یک اندازه دسته افزایشی که سرعت بالایی را برای همگرایی ارائه میکند، کشف شده است؛ البته، کارایی نمونه را به اندازه خیلی زیاد و بیش از ۳۲k تحت تاثیر قرار نمیدهد. اگرچه، کاشف به عمل آمده است که اندازه دسته ۸k و 16k در تعداد دستههای تخصیص داده شده، هرگز به مرحله ۴ نرسیدهاند.
افزایش اندازه دسته، زمان همگرایی را سرعت میبخشد.

تذکر: اندازه دسته در تعداد بخشهای متناوب انتقال مورد استفاده در «پسانتشار» (Backpropagation) در طی زمان گزارش میشود که هر یک از آنها حاوی ۱۰ انتقال است؛ بدین معنا که یک سایز دسته ۶۴k گزارش شده، حاوی ۶۴۰k انتقال است.
رقابت چندعاملی در مقایسه با انگیزه ذاتی
در این پژوهش، شواهدی وجود دارد که نشان میدهد عاملها میتوانند استراتژیها و استراتژیهای مقابله پیچیده را از طریق یک برنامه آموزشی خودکار خود نظارت شده در قایم موشک یاد بگیرند. راهکار دیگر برای یادگیری مهارتها به صورت «نظارت نشده» (Unsupervised)، انگیزه ذاتی است که عاملها را تحریک میکند تا با سنجههای مختلف مانند خطای مدل یا شمارش حالات، به اکتشاف بپردازد.
اکتشاف شمارشمحور در محیطی اجرا میشود که در آن، عامل، تعداد دقیق حالتهایی که مشاهده کرده و تحریک شده است تا به حالتهای به ندرت مشاهده شده برود را حفظ میکند. انتخاب مدلسازی اولیه برای تنظیم در این تنظیمات، ارائه حالت است. برای مثال، در اولین خط مبنا، تنها یک موقعیت دوبعدی در حالت در نظر گرفته میشود، به طوری که عاملها تنها برای تعامل با جعبهها و تکان دادن آنها به یک موقعیت جدید تحریک میشوند. سپس، این مورد با سیاست مبتنی بر مقدار مقایسه میشود که حالت کامل داده شده به عاملی را که قایمموشک بازی میکند، میگیرد.
چند عامل
اکتشاف شمارشمحور با مشاهدات گزینشی
اکتشاف شمارشمحور با همه مشاهدات
همانطور که مشهود است، عاملها در قایمموشک با تمرکز بر کیفیت در حدود رفتارهای قابل تفسیر برای انسان، مانند ساخت جانپناه بیشتر، آموزش داده شدهاند؛ در حالی که عاملهایی که با انگیزه ذاتی آموزش داده شدهاند، اشیا را در اطراف به صورت ظاهرا غیر مستقیم حرکت میدهند. علاوه بر آن، هرچه پیچیدگی فضای حالت افزایش پیدا میکند، مشخص میشود که عاملها در روشهای انگیزشی ذاتی، تعاملات کمتر معناداری با اشیای موجود در محیط دارند. به همین دلیل، این باور به وجود آمده است که رقابتهای چندعاملی، روشهای مقیاسپذیرتری برای تولید مهارتهای مرتبط با انسانها در حالت «غیرنظارت شده» (Unsupervised) همگام با اینکه سایز و پیچیدگی محیط افزایش پیدا میکند، خواهند بود.
انتقال و تنظیم دقیق به عنوان ارزیابی
در بخش پیشین، رفتارهای یاد گرفته شده در قایمموشک با آنهایی که با انگیزه ذاتی یاد گرفته شدهاند، مقایسه شدند. اگرچه، هرچه مقیاس محیط افزایش پیدا میکند، سختی پیشرفت اندازهگیری کیفی نیز افزایش پیدا میکند.
پیگیری پاداش یک سنجه ارزیابی ناکافی در تنظیمات چندعامله است که میتواند در تعیین این که عامل به طور مداوم بهبود پیدا میکند یا به طور مساوی، نقشآفرین باشد. سنجههایی مانند ELO یا Trueskill میتوانند به طور قابل اطمینانتری اندازهگیری کنند که آیا کارایی مرتبط با نسخههای سیاست قبلی بهبود پیدا میکند یا دیگر سیاستها در جمعیت.
اگرچه، همچنان این سنجهها بینشی از اینکه کارایی به خاطر سازگاریهای جدید بهبود یافته است و یا به خاطر بهبود مهارتهای یادگرفته شده پیشین، ارائه نمیکند. در نهایت، با استفاده از آمارهای ویژه محیط مانند جا به جایی شی میتواند ابهامبرانگیز باشد (برای مثال، انتخاب پیگیری جا به جایی مطلق مشخص نمیکند که عاملها به کدام جهت جا به جا میشوند) و طراحی سنجههای موثر، دشوار و به اندازه مقیاس محیط پر هزینه خواهند شد.
پیشنهاد میشود که از آزمونهای هوشمندی ویژه دامنه که تواناییهایی که انتظار میرود عاملها به تدریج کسب کنند استفاده شود. انتقال کارایی در این تنظیمات میتواند به عنوان یک مقیاس کارایی برای ارائه کیفیت یا مهارت باشد و با پیشآموزش با اکتشاف مبتنی بر شمارش و همچنین، خط مبنای آموزش دیده از پایه، مقایسه میشود.

شمارش اشیا: عامل در یک محل میخ شده است و از آن خواسته میشود که پیشبینی کند چه تعداد از اشیا به راست یا چپ رفتهاند؛ بدین شکل، حافظه عامل و حس ماندگاری شی در آن تست میشود.

نگاه کردن و بازگرداندن: عامل باید جعبه را پیدا و آن را قفل کند، سپس به موقعیت اصلی خود بازگردد. این کار، حافظه بلند مدت عامل از موقعیت خود را میسنجد.

قفل دنبالهای: عامل باید جعبه ها را به ترتیبی که برای عامل نظارت نشده است، قفل کند. جعبهها تنها میتوانند به ترتیب صحیح قفل شوند، بنابراین عامل باید وضعیت جعبههایی که مشاهده کرده است را به خاطر بسپارد.

ساخت بلوپرینت: عامل باید جعبهها را به موقعیت هدف منتقل کند.

ساخت جانپناه: عامل باید یک جانپناه در اطراف استوانه بسازد.
با وجود آنکه عامل قایمموشک در بسیاری از وظایف انتقال، عملکرد بهتری دارد، کارایی یا زمان همگرایی را خیلی بهبود نمیبخشد. از مشاهده رفتار آن، این دانش حاصل میشود که مهارت نهفتهای برای جا به جایی اشیا در حالت دقیق برای ساخت جانپناه در بازی قایمباشک دارد؛ اگرچه، توانایی استفاده از این مهارت در دیگر زمینهها را هنگام آموزش دادن با تعداد کمتری از نمونهها ندارد.
دانشمندان بر این باورند که دلیل نتایج مختلط در «ارائه مهارت یادگیری عامل» ریشه دارد که البته این موارد آشفته هستند و تنظیم دقیق آنها دشوار است. با متنوعتر شدن محیطهای آینده و مهارتهایی که عاملها در بیشتر زمینهها الزام به یادگیری آنها دارند، به نظر میرسد که پژوهشگران شاهد ارائه مهارت عمومیتر و سیگنالهای موثرتری در این رویکرد ارزیابی باشند. علاوه بر آن، وظایف ارزیابی به عنوان راهی برای ارزیابی پیشرفت یادگیری در این محیط، متنباز شدهاند.
رفتارهای شگفت انگیز
پیش از این، نشان داده شد که عاملها میتوانند استفاده پیچیده از ابزارها را در شبیهساز فیزیکی با وفاداری بالا، یاد بگیرند. اگرچه، درسهای بیشتری در راه رسیدن به این نتایج یاد گرفته شده است.
ساختن محیطها کار سادهای نیست و اغلب شرایطی است که عامل یک راه برای بهرهبرداری از محیطی که پژوهشگر یا موتور فیزیکی به طور غیر عمدی ساخته است، پیدا میکند.
موج سواری روی جعبه: از آنجا که عامل با اعمال نیرو به خودش حرکت میکند، میتواند یک جعبه را هنگامی که در بالای آن قرار گرفته به مالکیت خود درآورد و روی آن به سمت محل برهها موجسواری کند.
فرار بیپایان: بدون افزودن پاداش منفی صریح برای عاملهایی که در ناحیه بازی سکونت دارند، در شرایط نادر، برهها یاد میگیرند که یک جعبه را بگیرند و تا بینهایت با آن بدوند.
بهرهبرداری از سطح شیبدار (برهها): یادگیری تقویتی در پیدا کردن مکانیکهای کوچک برای بهرهبرداری، فوقالعاده است. در این شرایط، برهها از فیزیک تماس سو استفاده میکنند و سطحهای شیبدار را از ناحیه بازی حذف میکنند.
بهرهبرداری از سطح شیبدار (گرگها): در این شرایط، گرگها یاد میگیرند که اگر با یک سطح شیبدار به سمت دیوار در گوشه راست بدوند، میتوانند خود را به بالا پرتاب کنند.
نگاه رو به جلو
شواهد بیشتری نیز فراهم شده است که نشان میدهد استراتژیها و مهارتهای مرتبط با انسان، پیچیدهتر از محیط و دینامیک چنین بازی هستند و میتوانند در نتیجه رقابتهای چندعاملی و الگوریتمهای یادگیری تقویتی استاندارد، ظاهر شوند.

این نتایج، موجب امیدواری از این میشود که در محیطهای بیپایان و متنوع، دینامیکهای چند عامله میتوانند منجر به رفتارهای انسانی فوقالعاده پیچیده و مرتبط شوند.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش دادهکاوی در متلب
- مجموعه آموزشهای هوش مصنوعی
- یادگیری تقویتی در پایتون — راهنمای کاربردی
- یادگیری تقویتی (Reinforcement Learning) — راهنمای ساده و کاربردی
- Q-Learning و یادگیری تقویتی — خودآموز سریع و جامع
- یادگیری تقویتی Active و Passive — راهنمای ساده
- یادگیری تقویتی (Reinforcement Learning) و پنج نکته کلیدی پیرامون آن — راهنمای کاربردی
^^








