

رسم نمودار داده ها در پایتون – راهنمای تخصصی
اغلب هنگامی که بخواهیم نمودارهای آماری را در پایتون رسم کنیم، از کتابخانه matplotlib استفاده میکنیم. در این نوشتار از کتابخانه plotly از pandas استفاده خواهیم کرد که قادر به ترسیم نمودارهای جذابتر و البته با امکانات بهتر و موثر از توابع matplotlib است. با استفاده از این کتابخانه میتوانید حتی با یک خط کد، نمودار زیبا و گویایی از دادهها ترسیم کنید. کدهای رسم نمودار با کد رسم شکل در پایتون تفاوت دارد.


اگر میخواهید با انواع نمودارها و نحوه نمایش دادهها آشنا شوید، بهتر است ابتدا مطلب نمایش و رسم نمودار برای دادهها — معرفی و کاربردها را مطالعه کرده باشید. البته برای ترسیم بعضی از نمودارهای مختلف آماری در زبان برنامه نویسی R به مطلب نمودار میلهای (Bar Chart) در R — راهنمای کاربردی و نمودار نقطهای (Scatter Plot) در R — راهنمای کاربردی مراجعه کنید. همچنین برای آشنایی با نحوه ترسیم نمودار جعبهای در پایتون خواندن مطلب نمودار جعبه ای (Boxplot) و رسم آن در پایتون – به زبان ساده نیز خالی از لطف نیست.
ترسیم و نمایش داده در پایتون
هر چند کتابخانههای مختلفی در پایتون برای ترسیم و رسم نمودار وجود دارد ولی شاید کتابخانه plotly یکی از بهترین ابزارهای برای رسم نمودار باشد. این کتابخانه توسط شرکت Plotly به صورت «متن-باز» (Open Source) تهیه شده و امکان ترسیم نمودارهای مختلفی را میسر میسازد.
برای اینکه در بتوانید Jupyter Notebook از این کتابخانه استفاده کنید، آن را با استفاده از دستور زیر نصب کنید. به این ترتیب محیطی مناسب با استفاده از cufflinks برای نمایش و تغییر نمودارها حاصل از کتابخانه plotly ایجاد خواهد شد.
1pip install cufflinks plotlyحال که محیط برای ترسیم نمودارها تهیه شد، بهتر است برای راهاندازی کتابخانه و فرخوانی توابع آن از کد زیر استفاده کنید.
1# Standard plotly imports
2import plotly.plotly as py
3import plotly.graph_objs as go
4from plotly.offline import iplot, init_notebook_mode
5# Using plotly + cufflinks in offline mode
6import cufflinks
7cufflinks.go_offline(connected=True)
8init_notebook_mode(connected=True)رسم نمودار فراوانی (Histograms) یک متغیره و نمودار جعبهای (Boxplot)
در مباحث آماری، یکی از مهمترین تکنیکها، مشخص کردن توزیع دادهها و نمایش فراوانی است. یکی از روشهای مرسوم برای انجام این کار، ترسیم نمودار فراوانی یا بافتنگار فراوانی است که البته به هیستوگرام (Histogram) نیز معروف است.

به کمک این نمودار، توزیع دادهها مشخص میشود و میتوانیم احتمال مشاهده هر مقدار یا فاصلهای از آنها را تشخیص دهیم. در ادامه با استفاده از یک کد ساده میخواهیم یک نمودار محاورهای از هیستوگرام ترسیم کنیم. منظور از نمودار محاورهای، استفاده از امکانات cufflinks است. با استفاده از این امکانات، میتوانید نمودار را زوم کنید تا قسمتی از آن قابل مشاهده باشد. با این کار مقیاسهای مربوط به محور افقی و عمودی به صورت فعال، تغییر خواهند کرد.
1df['claps'].iplot(kind='hist', xTitle='claps',
2 yTitle='count', title='Claps Distribution')خروجی به صورت زیر درخواهد آمد. امکاناتی که Cufflinks و تابع plotly در اختیارتان قرار میدهند به خوبی دیده میشود. مشخص است که به صورت پویا نمودار در حال تغییر است و هر قسمتی از آن با تغییر مقیاسها قابل مشاهده است. همانطور که دیده میشود امکاناتی نظیر زوم کردن و انتخاب بخشی از نمودار میتواند دید بهتری از دادهها به شما بدهد.
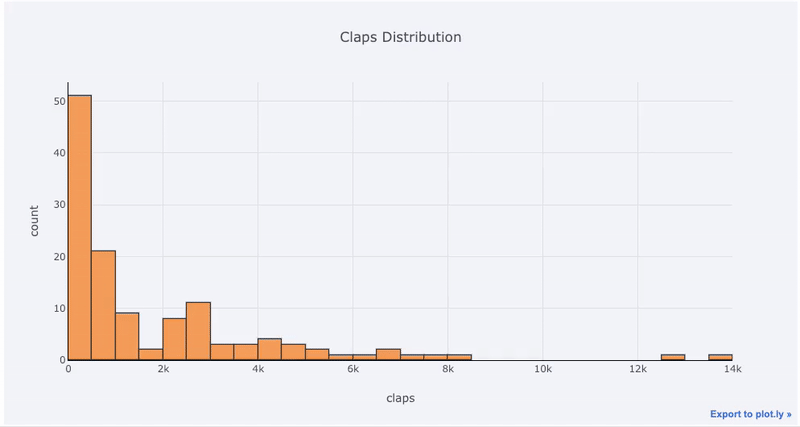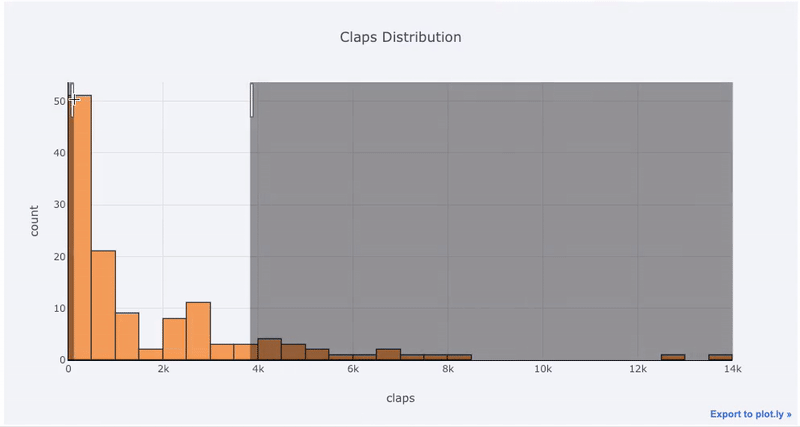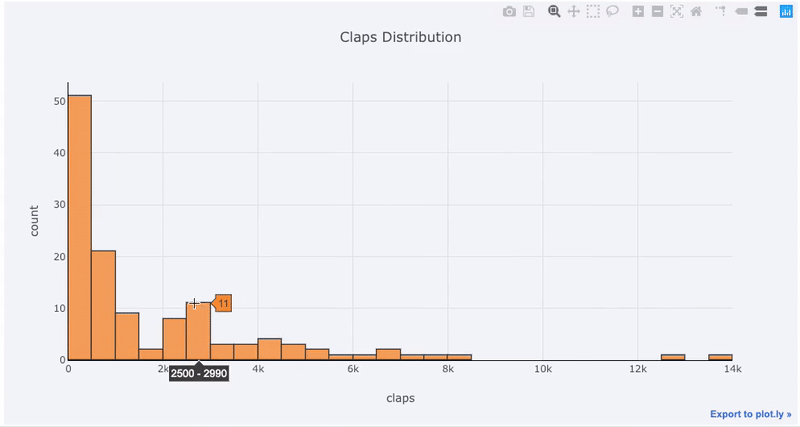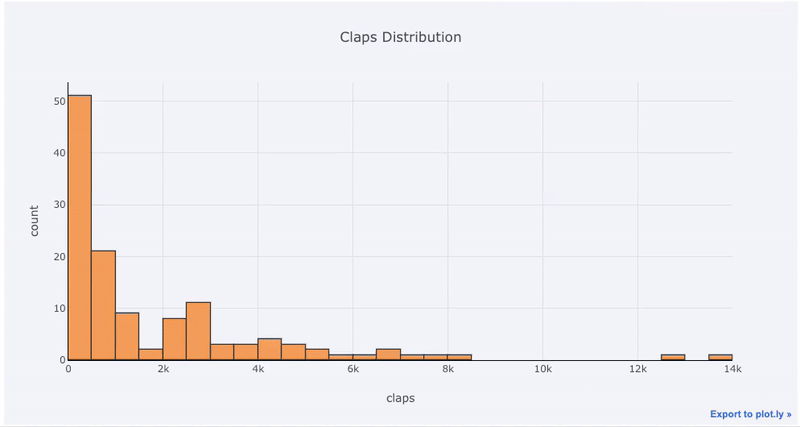
نکته: چارچوب داده (Dataframe) که در این مثال با نام df به کار رفته از مجموعه دادههای مربوط به مشخصات مقالاتی است که در چندین سایت مختلف منتشر شدهاند. نمونه فایل html آن از اینجا قابل دریافت است. به منظور استخراج این اطلاعات از داخل این فایل بهتر است از کد زیر در ترمینال پایتون استفاده کنید. توجه داشته باشید که نام فایل test.html است.
1from retrieval import get_data
2df = get_data(fname='test.html')نمودار فراوانی که در قسمت قبل مشاهده کردید، براساس یک متغیر ترسیم شده بود. اگر میخواهید نمودار فراوانی را برحسب چند متغیر ترسیم کنید بطوری که همه متغیرها براساس نقاط مشترک از محور افقی ترسیم شوند، از کد زیر استفاده کنید.
1df[['time_started', 'time_published']].iplot(
2 kind='hist',
3 histnorm='percent',
4 barmode='overlay',
5 xTitle='Time of Day',
6 yTitle='(%) of Articles',
7 title='Time Started and Time Published')همانطور که میبینید دو متغیر time_published و time_start در یک نمودار فراوانی که محور عمودی آن درصد فراوانی را نشان میدهد، نمایش داده شدهاند. محور افقی نیز بیانگر زمان یا ساعت روز است. به این ترتیب متوجه میشویم که بیشترین فراوانی برای شروع به نگارش مطالب در حدود ساعتهای ۹ صبح و شب است در حالیکه زمان انتشار، بیشترین فراوانی را در ساعت ۹ شب دارد. با کمی تغییر در کد و به کارگیری کتابخانه pandas، میتوانیم یک نمودار ستونی نیز ترسیم کنیم بطوری که هر یک از متغیرها در کنار یکدیگر ترسیم شوند.
1# Resample to monthly frequency and plot
2df2 = df[['view','reads','published_date']].\
3 set_index('published_date').\
4 resample('M').mean()
5df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
6 title='Monthly Average Views and Reads')خروجی برحسب اطلاعات df2 نموداری است که در ادامه قابل مشاهده است.

همانطور که دیده میشود، به کمک ابزارهای قدرتمندی که در کتابخانه pandas و ترکیب plotly با cufflinks وجود دارد، میتوان نمودار مناسبی، ترسیم کرد. حال به بررسی نحوه ترسیم یک نمودار جعبهای میپردازیم. برای این منظور باید ابتدا اطلاعات را به صورت یک «جدول محوری» (Pivot) درآورد، سپس با iplot آن را ترسیم کرد.
1df.pivot(columns='publication', values='fans').iplot(
2 kind='box',
3 yTitle='fans',
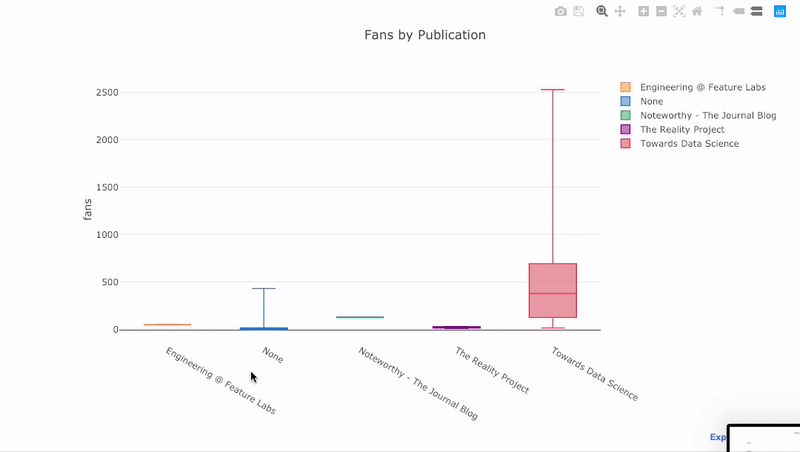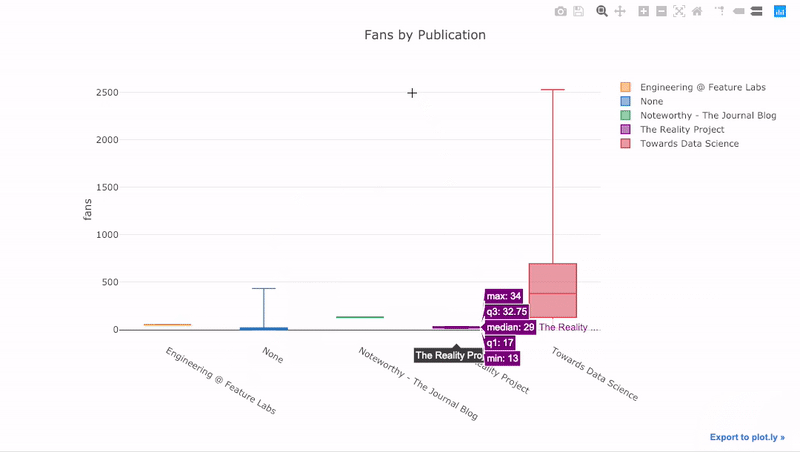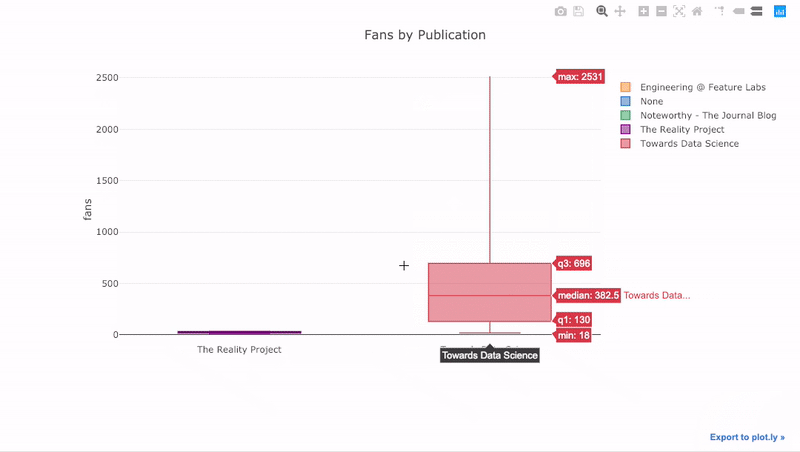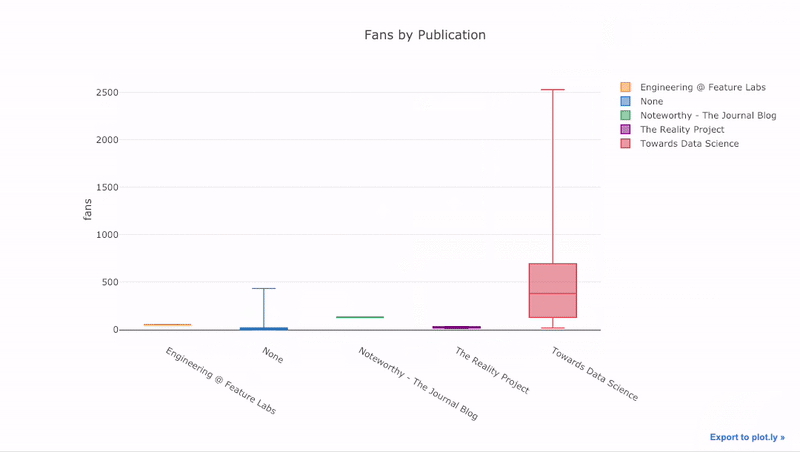
4 title='Fans Distribution by Publication')
نمودار زیر به بررسی هواداران (Fans) براساس سایت یا محل انتشار (Publication) پرداخته است.
نمودار پراکندگی (Scatter Plot)
در بیشتر تحلیلهای دو یا چند متغیره از «نمودار پراکندگی» (Scatter Plot) استفاده میشود. به این ترتیب میتوانیم رابطه بین تغییرات یک متغیر را نسبت به زمان یا متغیر دیگر مشخص کرده و نمایش دهیم. اگر متغیر مستقل را زمان در نظر بگیریم و تغییرات دادهها را نسبت به زمان بسنجیم، روش «سری زمانی» (Time Series) را در پیش گرفتهایم. گام ابتدایی در تحلیل سری زمانی، رسم نمودار پراکندگی است. خوشبختانه ترکیب Cufflinks و plotly امکانات خوبی برای نمایش دادههای سری زمانی دارد. در ادامه یک مجموعه داده سری زمانی به نام tds براساس دادههای df ایجاد کرده و با رسم نمودار پراکندگی به بررسی روند و تغییرات دادهها در بازه زمانی میپردازیم.
1Create a dataframe of Towards Data Science Articles
2tds = df[df['publication'] == 'Towards Data Science'].\
3 set_index('published_date')
4# Plot read time as a time series
5tds[['claps', 'fans', 'title']].iplot(
6 y='claps', mode='lines+markers', secondary_y = 'fans',
7 secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
8 text='title', title='Fans and Claps over Time')پس از اجرای این کد، نموداری برای بررسی تغییرات دادههای مربوط به هواداران و کلمات هر مقاله ترسیم شده که نشان میدهد هرچه تعداد کلمات کمتر باشد، تعداد هواداران یا علاقمندان آن مطلب بیشتر است.
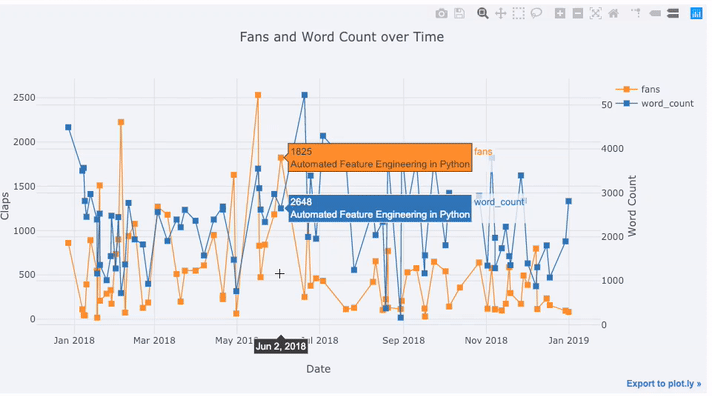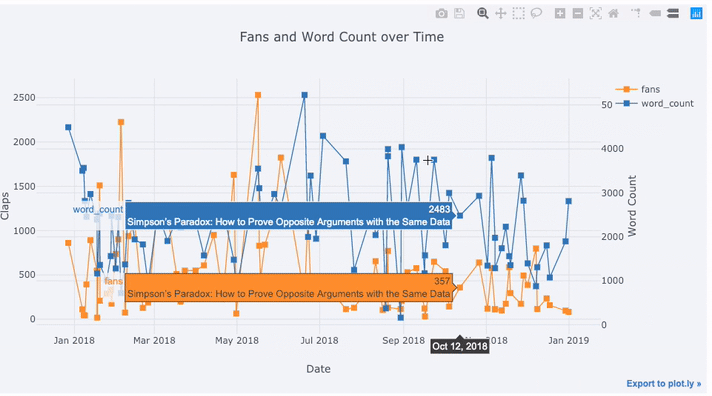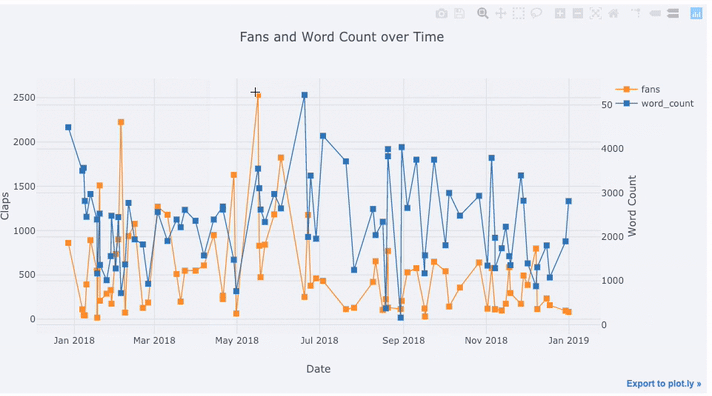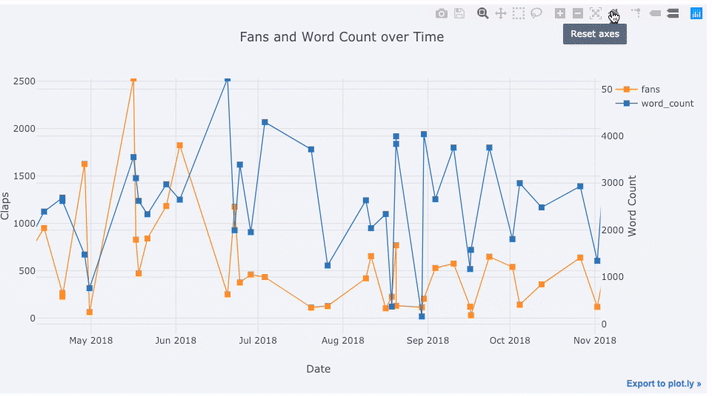
همانطور که میبینید به واسطه این کد، نمودار ترسیم شده دارای دو محور عمودی است زیرا دادهها مورد نظر دارای مقیاسهای اندازهگیری متفاوتی هستند. برای اینکه نمودار دارای عناوینی برای مقدارها باشد، میتوانید کدهای زیر را نیز اجرا کنید. محور عمودی سمت چپ مربوط به هواداران و محور عمودی سمت راست مربوط به کلمات هر مقاله است. محور افقی نیز تاریخی را مشخص میکند که مقاله منتشر شده است.
اگر میخواهید نمودار سری زمانی را فقط براساس تعداد کلمات ترسیم کنید، کافی است با کمی تغییر در کد، نقطهها را به صورت برچسبدار درآورده تا بیانگر تاریخ و تعداد کلمات هر مقاله باشد. محور عمودی در این حالت بیانگر تعداد کلمات بوده و محور افقی نیز تاریخ انتشار مقاله را نشان میدهد.
1tds_monthly_totals.iplot(
2 mode='lines+markers+text',
3 text=text,
4 y='word_count',
5 opacity=0.8,
6 xTitle='Date',
7 yTitle='Word Count',
8 title='Total Word Count by Month')همانطور که در نمودار مشاهده میکنید روند تغییرات تعداد کلمات مقالهها در ماههای مختلف نشانگر یک حرکت جهشی در ابتدای سال ۲۰۱۸ بوده ولی در ادامه روند تغییرات به کندی صورت گرفته یعنی تقریبا بیشتر مقالات در بازه سال ۲۰۱۸ تا ۲۰۱۹ دارای تغییرات کمی در کلمات هستند.

اگر میخواهید نمودار پراکندگی برای نمایش ارتباط بین زمان مطالعه و درصد مطالب خوانده شده براساس سایتهای منتشر کننده، ایجاد کنید بهتر است از کد زیر کمک بگیرید.
1df.iplot(
2 x='read_time',
3 y='read_ratio',
4 # Specify the category
5 categories='publication',
6 xTitle='Read Time',
7 yTitle='Reading Percent',
8 title='Reading Percent vs Read Ratio by Publication')خروجی به صورت زیر در خواهد آمد. در نمودار هر یک از سایتها با نقطههای مختلف رنگی نمایش داده شدهاند. محور افقی نیز زمان مطالعه و محور عمودی بیانگر درصد مقالاتی است که خوانده شدهاند. مشخص است که تعداد خوانندگان مطالبی که زمان کوتاهتری برای مطالعه احتیاج دارند بیشتر از تعداد افرادی است که مقالات طولانیتر را مطالعه کردهاند. به این ترتیب مشخص میشود که طول زمان مطالعه با تعداد خوانندگان رابطه معکوس دارد.
نکته: این نمودار، یک بررسی سری زمانی نیست بلکه رابطه بین زمان و درصد خوانندگان را بیان میکند. بنابراین میتوان این نمودار را به عنوان سنجش وابستگی بین دو متغیر زمان و درصد خوانندگان در نظر گرفت.

تا به اینجا مقیاس بندی محورها به طور خودکار صورت گرفت. در گام بعدی سعی میکنیم از محور لگاریتمی استفاده کنیم و مقیاس محور افقی را تغییر دهیم و البته قطر هر دایره را متناسب با یک متغیر عددی که در اینجا «نسبت خواندن» (read_ratio) نامیده میشود، تغییر دهیم.
1tds.iplot(
2 x='word_count',
3 y='reads',
4 size='read_ratio',
5 text=text,
6 mode='markers',
7 # Log xaxis
8 layout=dict(
9 xaxis=dict(type='log', title='Word Count'),
10 yaxis=dict(title='Reads'),
11 title='Reads vs Log Word Count Sized by Read Ratio'))همانطور که در نمودار ترسیم شده میبینید، محور افقی به صورت لگاریتمی ترسیم شده است. توجه دارید که این کار در قسمت layout تابع iplot صورت گرفته. هر چه قطر دایرهها بیشتر باشد، نسبت خوانندگان بیشتر است. باز هم میبینید که در مقالاتی که تعداد کلمات زیاد باشد، نسبت خوانندگان کم است.

همچنین امکان ترکیب pandas و plotly با cufflinks میتواند در رسم نمودار مفید باشد. در ادامه یک جدول محوری را به صورت یک نمودار در خواهیم آورد.
1df.pivot_table(
2 values='views', index='published_date',
3 columns='publication').cumsum().iplot(
4 mode='markers+lines',
5 size=8,
6 symbol=[1, 2, 3, 4, 5],
7 layout=dict(
8 xaxis=dict(title='Date'),
9 yaxis=dict(type='log', title='Total Views'),
10 title='Total Views over Time by Publication'))در نمودار زیر، مقایسه بین تعداد مقالات دیده شده در تاریخهای مختلف براساس پنج سایت صورت گرفته است. همانطور که دیده میشود از علامتهای مختلفی برای نمایش نقاط دادهای که مربوط به هر سایت است استفاده شده.

در ادامه به رسم نمودارهایی خواهیم پرداخت که ممکن است به طور معمول ترسیم نشوند ولی میتوانند در تجزیه و تحلیل رفتار دادهها موثر بوده و البته در جلب بیننده نیز تاثیر گذار باشند. در این جا از تابع figure_factory کتابخانه plotly استفاده میکنیم تا بتوانیم پارامترهای مربوط به ترسیم نمودار را در یک خط وارد کنیم.
نمودار پراکندگی ماتریسی (Scatter Matrix)
اگر لازم باشد که رابطه زوجی بین چندین متغیر مورد بررسی قرار گیرد، بهترین روش نمایش استفاده از «نمودار ماتریس پراکندگی» (Scatter Matrix Plot) است. فرض کنید قرار است ارتباط بین متغیرهای claps, Publication, views, read_ratio و word-count مورد بررسی قرار گیرد. کد زیر به منظور ترسیم نمودار ماتریس پراکندگی برای این دادهها تهیه شده است.
1import plotly.figure_factory as ff
2figure = ff.create_scatterplotmatrix(
3 df[['claps', 'publication', 'views',
4 'read_ratio','word_count']],
5 diag='histogram',
6 index='publication')همانطور که خواهید دید، عناصر مربوط به قطر اصلی (diag) نمودار پراکندگی ماتریسی، هیستوگرام در نظر گرفته شده است. این کار با استفاده از پارامتر 'diag='histogram انجام شده است. با استفاده از 'index='publication مشخص میشود که راهنمای نمودار باید نام سایتها باشد.

روش دیگری که برای نمایش رابطه زوج متغیرها مناسب به نظر میرسد، رسم نمودار حرارتی (Heatmap) است. در ادامه به بررسی این نوع نمودار میپردازیم.
نمودار همبستگی حرارتی (Correlation Heatmap)
اطلاعاتی که در نمودار زیر رسم شده است، مقدار ضریب همبستگی بین موضوعات (tag) و مشخصات مربوط به مقالات است. همانطور که دیده میشود در کد زیر ابتدا از ضریب همبستگی محاسبه، سپس از مقدار آن برای هر زوج برای رسم نمودار استفاده شده است.
1corrs = df.corr()
2figure = ff.create_annotated_heatmap(
3 z=corrs.values,
4 x=list(corrs.columns),
5 y=list(corrs.index),
6 annotation_text=corrs.round(2).values,
7 showscale=True)البته در نمودار یک راهنمای حرارتی نیز وجود دارد که نشان میدهد میزان رابطهها با چه رنگی در نمودار ظاهر شده است. این کار بوسیله دستور showscale=True صورت گرفته است.

امکانات و روشهای ترسیم دادهها در نرمافزارهای محاسباتی روز به روز بهبود مییابد. در ادامه به منظور آشنایی با امکانات بینظیری که در plotly وجود دارد به نمایش نمودارهای مختلفی پرداختهایم که امکان ترسیم آنها با استفاده از این کتابخانه وجود دارد. به این ترتیب مشخص میشود که با کمی هوشمندی و ابتکار میتوانید نمودارهایی ترسیم کنید که بیشترین اطلاعات را برای بیننده ارائه میکنند. این امر باعث میشود از ترسیم و ایجاد جداول پیچیده یا نوشتههای طولانی کاسته شده و موثرتر و بهتر در کار خود تاثیرگذار باشید.





سخن پایانی
رسم نمودارهای گویا و روشن، یکی از تکنیکهای «تصویر سازی دادهها» (Data Visualization) است. با این کار میتوانید دید بهتری نسبت به رفتار دادهها داشته باشید و از تغییرات یا ربطهای که بین متغیرها و مقادیرشان وجود دارد آگاه شوید. این شیوه شاید سریعترین روش برای دریافت اینگونه اطلاعات باشد. بنابراین استفاده از ابزارهایی که از عهده این کار به خوبی برآیند، ضروری به نظر میرسد.
اگر مطلب بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:








با سلام
برای رسم نمودار دو ستون از یک فایل ورودی csv که یکی عدد و دیگری str باشه چکار باید کرد؟
تشکر
تم ژوپیتر را دارک انتخاب کردم و نمودار که کشیده میشه، رنگ اعداد محور x و y مشکی هست
چطور میتونم رنگ فونت محور ها تو نمودار را عوض کنم؟
سلام وقت شما بخیر
برای اینکه برنامه پلات شده رو بررسی کنیم نیازه که با یه خط روی نمودار بتونیم حرکت کنیم و مقادیر رو مخصوصا وقتی چند نمودار در یک نمودار داریم بتونیم ببینیمشون یا یه گوشه مقادیر چند نمودار رو برامون نشون بده
میشه آموزشی برای این موضوع قرار بدین
ممنون
درود بر شما
براي استخراج اطلاعات فايل test پيام زير نشون داده ميشه.
No module named ‘retrieval’
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
احتمالاً این مشکل به این دلیل به وجود آمده است که retrieval نصب نیست. شما میتوانید با استفاده از دستور زیر آن را نصب و مجدد بررسی کنید که آیا مشکل برطرف میشود یا خیر.
pip install retrieval
برای شما آرزوی سلامتی و موفقیت داریم.