



نمونه گیری گیبز (Gibbs Sampling) و کاربردهای آن – به زبان ساده
در نظریه آمار بیز و استنباط بیزی، یکی از تکنیکهای نمونهگیری به منظور استنباط پارامتر مجهول جامعه، «نمونه گیری گیبز» (Gibbs Sampling) است. نمونه گیری گیبز و کاربردهای آن در الگوریتم «زنجیره مارکف مونت کارلو» (MCMC) بسیار مشخص است بطوری که بوسیله آن، نمونهگیری به صورت دنبالهای از توزیعهای چند متغیره امکان پذیر شده و برآورد پارامتر جامعه صورت میگیرد.



زمانی که نمونهگیری از یک توزیع به راحتی امکان پذیر نیست، روش نمونه گیری گیبز، این امکان را فراهم میآورد که بوسیله دنبالهای از نمونهها براساس توزیع پیشین پارامتر جامعه، بتوانیم از توزیع پسین، نمونه استخراج کنیم. به این منظور به جای استفاده از «توزیع توام» (Joint Distribution) برای تولید داده، از «توزیع حاشیهای» (Marginal Distribution) و «توزیع شرطی» (Conditional Distribution) که نمونهگیری از آنها سادهتر است، استفاده میشود تا بتوانیم پارامتر مجهول جامعه را برآورد کنیم. البته استفاده از نمونه گیری گیبز برای محاسبه انتگرال به شیوه مونت کارلو درست به مانند شبیهسازی مونتکارلو نیز موثر است.
از نمونه گیری گیبز برای استنباط آماری بخصوص استنباط بیزی استفاده میشود. برعکس «الگوریتم قطعی» (Deterministic Algorithm) مانند الگوریتم EM، الگوریتم نمونه گیری گیبز یک «الگوریتم تصادفی» (Randomized Algorithm) است زیرا براساس اعداد و دنبالهای از نمونههای تصادفی عمل میکند.
نمونه گیری گیبز (Gibbs Sampling) و کاربردهای آن
شیوه و روش نمونه گیری گیبز به افتخار فعالیتها و کارهایی که دانشمند و فیزیکدان آمریکایی «جوسیا ویلارد گیبز» (Josiah Willard Gibbs) در حوزه مکانیک آماری انجام داده به این نام خوانده میشود. او اولین با واژه «مکانیک آماری» (Statistical Mechanic) را به کار برد و مفاهیم آن را در سال ۱۹۰۲ توسعه دارد. البته بعدها استنباط آماری توسط دو برادر به نامهای «استوارت» و «دونالد گمان» (Stuart - Donald Geman) در سال ۱۹۸۴ ایدههای او را بسط داده و به صورت یک شاخه از مکانیک مدرن معرفی کردند. به نظر میرسد این ایده تقریبا حدود ۸۰ سال بعد از در گذشت جوسیا گبیز بسط و مورد استفاده قرار گرفت.
نمونهگیری گیبز را در حالت ساده میتوان حالت خاصی از الگوریتم متروپولیس-هستنینگز (Metropolis-Hastings Algorithm) دانست. از کاربردهای مهم نمونهگیری گیبز میتوان به تهیه داده و نمونه از یک توزیع چند متغیره پیچیده و با شکل نامخشص براساس توزیع شرطی و توزیع حاشیهای نام برد. البته فرض بر این است که توزیع شرطی و توزیعهای حاشیهای مشخص و نحوه تهیه نمونه از آنها نسبت به توزیع توام ساده است. میتوان نشان داد که دنباله نمونههای ایجاد شده توسط الگوریتم نمونه گیری گیبز یک «زنجیره مارکف» (Markov Chain) ایجاد میکنند.
به کمک قضیه بیز میتوان نمونه گیری گیبز را به شکلی مرتبط با توزیع پسین در شبکه بیزی (Bayesian Network) دانست زیرا شبکههای بیزی به صورت مجموعهای از توزیعهای شرطی، مشخص و معرفی میشوند.

پیشزمینه ریاضیاتی
در این قسمت به بررسی مفاهیم اولیه و ریاضیاتی برای نمونه گیری گیبز خواهیم پرداخت. البته همانطور که قبلا اشاره شد، نمونه گیری گیبز به قضیه بیز و استفاده از آن برای پیدا کردن توزیع توام نمونه تصادفی برحسب توزیع شرطی و توزیع حاشیهای تکیه دارد. به این ترتیب برای مشخص شدن این ارتباط در این بخش به معرفی توزیع شرطی و توزیع حاشیهای و ارتباطشان با توزیع توام خواهیم پرداخت.
فرض کنید یک نمونه تصادفی به صورت از توزیعی که به پارامتر بُعدی وابسته است، تهیه شده است. از طرفی میدانیم توزیع پیشین برای بردار پارامتر به صورت است. معمولا اگر مقدار بزرگ باشد، محاسبه توزیع حاشیهای برای هر کار مشکلی خواهد بود، زیرا احتیاج به محاسبه یک انتگرال گانه داریم. راه جایگزین برای این کار، محاسبه توزیع حاشیهای براساس انجام گامهای متوالی زیر است. مشخص است که در اینجا بُعد مسئله یا تعداد پارامترها را نشان میدهد.
- یک اندیس تصادفی مثل را از بین اعداد ۱ تا انتخاب میکنیم. البته بعد خواهیم دید که بهتر است این اندیس از ۱ شروع شود. به این معنی که از اولین پارامتر شروع میکنیم.
- براساس احتمال حاصل از توزیع توام یک مقدار برای انتخاب میکنیم.
به این ترتیب با تکرار این کار میتوانیم تابع احتمال حاشیهای برای هر استخراج کنیم. این کار درست به مانند به کارگیری «زنجیره مارکف وارونپذیر» (Reversible Markov Chain) است.
نکته: یک زنجیره مارکف را وارونپذیر مینامند اگر رابطه زیر برقرار باشد.
رابطه بالا نشان میدهد که اگر زنجیره مارکف، یکنواخت در زمان باشد، احتمال تغییر حالت از به متناسب با تغییر حالت از به است. این نسبت براساس تابع احتمال مشخص میشود.
نمونه گیری گبیز (Gibbs Sampling)
فرض کنید احتیاج به یک نمونه تصادفی با اندازه به صورت از توزیع توام داریم. در نظر بگیرید که نمونه تصادفی در مرحله ام است. به این ترتیب گامهای تولید نمونه تصادفی در نمونهگیری گبیز به صورت زیر خواهد بود.

1- در اولین گام با مقدار اولیه و اختیاری برای آغاز میکنیم.
۲- در گام بعدی نمونه جدیدی به نام ایجاد خواهیم کرد. از آنجایی که یک بردار به صورت است، تابع احتمال برای انتخاب نمونه برای هر یک از مولفهها مثلا را بوسیله تابع توزیع شرطی آن مولفه برحسب دیگر مولفهها در نظر میگیریم. این احتمال یا توزیع شرطی را به صورت زیر نمایش میدهیم.
نکته: باید توجه داشت که ما از مقدار امین مولفه در نمونه ام استفاده کردهایم. از طرفی هم برای نمونهگیری نیز از مولفه اول کار را آغاز کردهایم. به اندیسهای بالا و پایین جملات اولیه و همچنین جملاتی که در آخر رابطه بالا دیده میشوند دقت کنید. نمونههای استفاده شده برای محاسبه احتمال شرطی برای مولفه شامل نمونه ام برحسب مولفه اول تا به همراه مولفههای تا نمونه ام است. این امر مرحلهای بودن و تکرار مراحل در نمونه گیری گبیز را به خوبی نشان میدهد. همچنین مشخص است که از بیشترین اطلاعات برای تعیین توزیع و یا تولید نمونه تصادفی در گام بعدی استفاده شده است. به این ترتیب برای نمونه ام مولفههای 1 تا تولید میشود.
۳- گام ۲ را به تعداد بار (تعداد نمونهها) تکرار میکنیم.
رابطه بین توزیع شرطی و توزیع توام
توزیع شرطی یک متغیر تصادفی برحسب متغیرهای دیگر به شکل زیر نوشته میشود.
مشخص است که صورت کسر شامل توزیع توام همه نمونههای تصادفی است. همچنین در مخرج کسر نیز توزیع توام بدون در نظر گرفتن نمونه نوشته شده است. به این ترتیب به نظر میرسد که توزیع شرطی یک نمونه تصادفی، متناسب با توزیع توام نمونه تصادفی است. پس مشخص است که توزیع شرطی متغیر تصادفی با توجه به صورت کسر فقط به توزیع توام نمونهها بستگی دارد که برای همه ها یکسان است. این امر نشان میدهد که میتوان توزیع توام را بر حسب توزیع شرطی یک نمونه تصادفی و توزیع توام بقیه نمونهها تولید کرد. مخرج کسر را عامل نرمالسازی مینامند. بنابراین میتوان یکی از کارهای زیر را انجام داد.
- اگر توزیع متغیر تصادفی گسسته باشد، توزیع احتمال نمونه تصادفی به ازائ همه حالتهای ممکن برای را محاسبه کرد.
- اگر توزیع متغیر تصادفی پیوسته و معلوم باشد، عامل نرمال سازی در محاسبه توزیع توام نیز معلوم خواهد بود.
- در حالتهایی غیر از دو وضعیت بالا، مقدار فاکتور نرمال سازی که باعث تبدیل تابع تولید شده به تابع چگالی است، را میتوان نادیده گرفت و براساس بقیه عوامل، توزیع توام را محاسبه کرد.
استنابط به کمک نمونهگیری گبیز
نمونه گیبز معمولا برای استنتاج آماری استفاده میشود. برای مثال میتوان از نمونهگیری گیبز برای برآورد پارامتر توزیع پواسن () که بیانگر متوسط تعداد افرادی است که احتمالا در یک فروشگاه خاص در یک روز خاص خرید میکنند استفاده کرد. ایده اصلی در این زمینه آن است که دادههای مشاهده شده و توزیع شرطی با یکدیگر آمیخته شده تا برای تولید نمونه تصادفی از توزیع توام به کار گرفته شوند. در هر بار تکرار فرآیند نمونه گیری گیبز، توزیع متغیرهای باقیمانده همان توزیع پیشین و شرطی شده برحسب مشاهدات است.
به این ترتیب نزدیکترین مقدار به پارامتر (مقداری با بیشترین فراوانی یا همان نما) میتواند به عنوان مقدار برآورد پارامتر در نظر گرفته شود. این درست به مانند برآورد حداکثر احتمال پسین در استنباط آماری برای پارامتر مجهول جامعه است. اگر از میانگین (امید ریاضی) مقدارهای حاصل از نمونههای تولید شده برای پارامتر مجهول در نمونهگیری گیبز استفاده کنیم، معادل برآوردگر بیز در مباحث استنباط بیزی است. به این ترتیب از اطلاعات اضافهای که دادههای قبلی به همراه دارند، استفاده کردهایم در حالیکه اگر از الگوریتم EM کمک بگیریم چنین امکانی برایمان وجود ندارد.
برای مثال یک توزیع تک نمایی (Unimodal) را در نظر بگیرید. معمولا در چنین توزیعی با شرط وجود تقارن، میانگین و نما (Mode) تقریبا با یکدیگر برابر هستند. ولی اگر میزان «چولگی» (Skewness) در یک جهت زیاد باشد، میانگین در جهت چولگی تمایل پیدا کرده و از نما دور میشود. به این ترتیب احتمال مشاهده مقادیر در جهت چولگی نسبت به حالت تقارن بیشتر میشود. گاهی اوقات میتوان با استفاده از نمونهگیری گیبز مقادیر مرتبط با یک مدل خطی (یعنی تغییرات رگرسیون خطی) را بررسی کرد. برای مثال، رگرسیون probit را میتوان برمبنای نمونهگیری گبیز برای تعیین احتمال انتخاب یک داده باینری (مثلا بله / خیر) به عنوان متغیر وابسته با متغیرهایی مستقل به همراه جمله خطا که توزیع آن نرمال در نظر گرفته شده است به کار برد.
اشکالات نمونهگیری گیبز
در دو حالت، ممکن است نمونهگیری گیبز به شکست منجر شود. اولین وضعیت، زمانی است که دادهها در محل یا مقدارهای خاصی، چگالتر (متمرکز) باشند و تشکیل توزیع احتمال به صورت جزیرههایی منفصل با میزان احتمال بالا را بدهند. برای مثال توزیعی را در نظر بگیرید که توسط یک بردار دو بعدی از مقدارهای دو دویی تشکیل شده است، بطوری که در نقطه و میزان جرم احتمال است و در بقیه نقاط یعنی و جرم احتمال صفر است. به این ترتیب نمونهگیری گیبز در بین دو نقطه با بیشترین جرم احتمال متوقف شده و هرگز نقاط دیگر از مقدارهای توزیع را تولید نخواهد کرد. این حالت بخصوص زمانی که دو مقدار یا مولفه از بردارها کاملا به یکدیگر وابسته باشند نیز رخ میدهد.
در حالت دوم، همه نقاط دارای احتمال مثبت هستند ولی یک نقطه با جرم احتمال زیاد وجود دارد. برای مثال فرض کنید که یک بردار ۱۰۰ مولفهای با مقدار مولفههایی برابر با صفر دارید که با احتمال رخ میدهند. به این ترتیب اگر نقاط دیگر دارای جرم احتمال یکسان باشند، میزان احتمال برای بردارهای دیگر برابر با رابطه زیر است.
به این ترتیب اگر لازم باشد که احتمال مشاهده بردار صفر را برآورد کنیم، کافی است ۱۰۰ تا ۱۰۰۰ داده تولید کرده و احتمال را برآورد کنیم. در حالیکه اگر بخواهیم برای بردارهایی دیگر میزان احتمال را برآورد کنیم احتیاج به حداقل یک نمونه به اندازه داریم که عملا هیچ رایانهای امکان محاسبات این چنینی را ندارد.
تولید نمونه از توزیع نرمال دو متغیره با روش نمونهگیری گیبز
فرض کنید میخواهیم از یک توزیع نرمال دو متغیره نمونه تولید کنیم. پارامترهای این توزیع را به صورت زیر در نظر میگیریم.
که بردار میانگین توزیع نامیده میشود و همچنین ماتریس زیر را هم در نظر بگیرید که ماتریس کوواریانس (ماتریس ضریب همبستگی) با میزان ضریب همبستگی 0.8 بین دو متغیر را نشان میدهد.

به نظر میرسد که این متغیر تصادفی دارای توزیع نرمال دو متغیره استاندارد است زیرا میانگینها صفر و واریانسها نیز برابر با ۱ هستند.
به منظور تهیه نمونه از این توزیع، از نمونهگیری گیبز استفاده میکنیم زیرا میدانیم توزیع شرطی و توزیع حاشیهای چنین متغیر تصادفی نیز نرمال تک متغیره خواهند بود و نمونهگیری از آن به سادگی امکانپذیر است. به این ترتیب توزیعهای شرطی یک بُعد برحسب بُعد دیگر را به صورت زیر نشان میدهیم.
که توزیع احتمال شرطی مولفه اول برحسب مولفه دوم را نشان میدهد. همچنین توزیع زیر احتمال شرطی مولفه دوم برحسب مولفه اول را به صورت زیر مشخص میکنیم.
در اینجا مشخص است که در گام ام از نمونه گام ام استفاده کردهایم. با استفاده از اطلاعاتی که از توزیع شرطی و نحوه محاسبه آن داریم میتوانیم، رابطههای زیر را مشخص کنیم. ابتدا توزیع شرطی متغیر را تعیین میکنیم.
به این ترتیب با معلوم بودن توزیع در گام ام توزیع را بدست میآوریم.
واضح است که هر دو توزیع شرطی، نرمال یک متغیره هستند. به میانگین و واریانس هر یک از توزیعها توجه کنید. مشخص است که برای مثال میانگین توزیع شرطی برحسب به صورت ترکیبی از میانگین توزیع بُعد اول و دوم و همچنین ضریب همبستگی و مقدار متغیر در بُعد دوم است. یعنی دادههای جمعآوری شده قبلی در بُعد دوم برای اصلاح میانگین متغیر تصادفی در بُعد اول در مرحله ام به کار رفته است. به این ترتیب امید ریاضی و واریانس توزیع نرمال در بُعد اول به صورت زیر خواهد بود.
به همین شکل نیز رابطهای مانند زیر را برای میانگین و واریانس شرطی بُعد دوم خواهیم داشت.
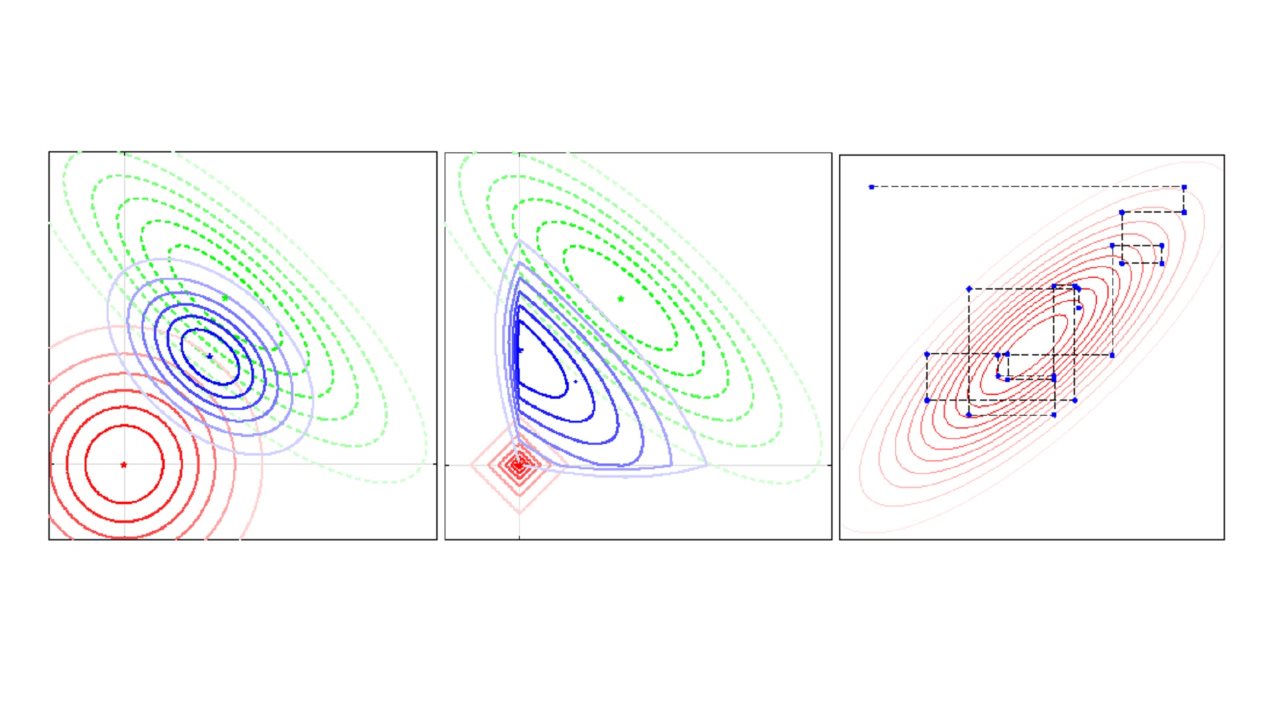
قطعه کدی که در ادامه مشاهده میکنید به زبان برنامهنویسی MATLAB نوشته شده و برای ایجاد نمونهای ۵۰۰۰ تایی از توزیع نرمال دو متغیره بوسیله نمونهگیری گبیز به کار میرود. در متغیر nSamples تعداد نمونهها مشخص شده همچنین بردار میانگین در mu و ضریب همبستگی نیز در (rho(1 و (rho(2 مشخص شدهاند تا بتوان ماتریس کوواریانس یا همبستگی را تشکیل داد. بازه تولید نمونهها نیز در گام اول از نقطه تا نقطه انتخاب شده است.
پس از اجرای این برنامه علاوه بر ایجاد نمونههای دو بعدی از این توزیع در متغیر نموداری نیز از این توزیع براساس نمونههای تولید شده ترسیم میشود. نقطههای حاصل از تولید این نمونهها در نمودار زیر با دایرههای قرمز رنگ مشخص شدهاند. در انتهای این برنامه برای پنجاه نقطه از نقاط تولید شده، مراحل جایگزینی و انتخاب در نمونه گیری گیبز به صورت خطوط سیاه رنگ دیده میشود.

نرمافزارهای تحلیلی با نمونهگیری گیبز
در زمینه استنباط و تحلیلهای بیزی نرمافزارهای مختلفی با تکیه بر نمونهگیری گیبز ایجاد و مورد استفاده قرار گرفته است. برای مثال WinBUGS و OpenBUGS براساس تحلیل بیزی و استفاده از نمونهگیری گیبز در زنجیره مارکف مونتکارلو، استنباط آماری و برآورد پارامترها را انجام میدهند. همچنین نرمافزار JAGS که اختصار عبارت (Just another Gibbs Sampler) به معنی یک «نمونه گیری گیبز دیگر» است، به عنوان یک برنامه متن باز برای تحلیلهای سلسله مراتبی بیزی با استفاده از زنجیره مارکف مونتکارلو قابل استفاده است.
از دیگر نرمافزارها در این زمینه میتوان به Church و PyMC3 که در پایتون قابل استفاده است، اشاره کرد. همچنین IA2RMS که مخفف (Independent Doubly Adaptive Rejection Metropolis Sampling) است، یک بسته برای متلب (Matlab) برای نمونهگیری براساس چگالیهای شرطی با تکیه بر نمونهگیری گیبز محسوب میشود.
اگر مطلب بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار و احتمالات
- آموزش مقدماتی آمار بیزی
- مجموعه آموزشهای برنامهنویسی R و نرم افزار RStudio
- دسته بند بیز ساده (Naive Bayes Classifiers) — مفاهیم اولیه و کاربردها
- یادگیری ماشین به زبان قضیه بیز، بی نظمی شانون و فلسفه
- احتمال پسین (Posterior Probability) و احتمال پیشین (Prior Probability) — به زبان ساده
^^











ببخشید اگر تابع توزیع چند متغیره( مثلا 5 متغیره) بخواهیم آن را چگونع میتوانیم تولید کنیم؟ و وابستگی ها را چگونه باید به دست اوریم.
سلام من میخام کد نویسی برای پواسون انجام بدم میشه راهنمایی کنید
سلام و درود به شما همراه مجله فرادرس،
کدهای مربوط به نمونهگیری گیبز در مطلب آماده است. کافی است توزیع نمونهای را به صورت توزیع پواسن درآورید. البته توجه داشته باشید که میانگین و واریانس در توزیع پواسن با یکدیگر برابر هستند.
همچنین میتوانید برای مشاهده کدهای بیشتر در حالت یک و دو بعدی به مطلب (+) مراجعه کنید.
از همراه شما با مجله فرادرس، سپاسگزار و مفتخریم.
پیروز و سربلند باشید.
متاسفانه کدی که گذاشتن اجرا نمیشه
سلام و درود
متاسفانه در کد یک اشکال تایپی وجود داشت که برطرف شد و میتوانید برنامه اصلاح شده را اجرا و نمودار مربوطه را بدست آورید.
از این که به مطالب مجله فرادرس توجه دارید، سپاسگزاریم.
شاد و تندرست و موفق باشید.