



رگرسیون چندکی در پایتون – راهنمای کاربردی
«رگرسیون چندکی» (Quantile Regression)، یکی از روشهای رگرسیون است که بخصوص در اقتصاد سنجی به کار گرفته میشود. همانطور که در دیگر نوشتارهای فرادرس با موضوع رگرسیون گفته شد، معمولا برای برآورد پارامترهای مدل رگرسیون خطی، از کمینه سازی خطای مدل به روشهای مختلف استفاده میشود. در روش OLS شیوه مدلسازی معادله خط رگرسیونی به صورت برآورد میانگین یا امید ریاضی شرطی «متغیر پاسخ» (Response Variable) به شرط مشاهدات «متغیرهای پیشگو» (Predictor Variables) که گاهی متغیرهای مستقل نیز نامیده میشوند، صورت میگیرد.



در رگرسیون چندکی، به جای محاسبه میانگین شرطی متغیر پاسخ، از میانه یا چندکهای شرطی متغیر پاسخ استفاده میشود.
به هر حال رگرسیون چندکی نیز یک حالت توسعه یافته از رگرسیون خطی است و زمانی که شرایط اجرای رگرسیون خطی وجود نداشته باشد، میتوان از رگرسیون چندکی استفاده کرد.
برای آگاهی در زمینه محاسباتی رگرسیون خطی یک و چند متغیره بهتر است مطالب رگرسیون خطی — مفهوم و محاسبات به زبان ساده و رگرسیون خطی چندگانه (Multiple Linear Regression) — به زبان ساده را بخوانید. البته خواندن مطلب تحلیل واریانس (Anova) — مفاهیم و کاربردها نیز خالی از لطف نیست.
رگرسیون چندکی (Quantile Regression)
زمانی که توابع شرطی چندکهای متغیر پاسخ مورد نیاز باشد، روش رگرسیون چندکی مناسب است. یکی از مزایای استفاده از رگرسیون چندکی نسبت به روش «معمول رگرسیون کمترین مربعات» (OLS)، پایداری در مقابل مقدارهای پرت (Outliers) یا دورافتاده است.
شکل و شیوه محاسبات رگرسیون چندکی با روشهای معمول رگرسیونی کاملا متفاوت است. در روش رگرسیون معمولی (OLS) با استفاده از ضرب داخلی، به یک زیر فضا میرسیم و در عمل به کمک جبرخطی قادر به برآورد پارامترهای مدل رگرسیون خطی خواهیم شد. در حالیکه در رگرسیون چندکی چنین ساختاری وجود ندارد و روش حل مانند روشهای برنامه ریزی خطی (روش سیمپلکس) است.
این روش توسط «راجر ویلیام کونکر» (Roger Willima Koenker) دانشمند آمریکایی در رشته اقتصاد سنجی در سال 1978 معرفی شد. او بعدها در سال ۲۰۰۵ کتاب Quantile Regression را در انتشارات کمبریج منتشر کرد که باعث شهرت و همهگیر شدن این روش رگرسیونی شد.

قبل از آنکه رگرسیون چندکی را مورد بررسی قرار دهیم، باید در مورد چندکها و خصوصیاتشان اطلاعات بیشتری داشته باشیم.
چندکها (Quantiles)
فرض کنید یک متغیر تصادفی با تابع توزیع تجمعی است. چندک ام متغیر به صورت زیر تعریف میشود.
در اینجا مقداری بین 0 و ۱ در نظر گرفته میشود. به این ترتیب مشخص است که مثلا منظور از چندک 0.1، کوچکترین مقدار از مقادیر است که مقدار تابع توزیع تجمعی بزرگتر از 0.1 است. برای پیدا کردن چندک ام از روشی که در ادامه معرفی میشود استفاده خواهیم کرد. «تابع زیان» (Loss Function) را به صورت زیر در نظر میگیریم.
منظور از تابع نشانگر (Indicator Function) است. به این معنی که مقدار این تابع برای مقدارهای کوچکتر از صفر برابر با ۱ و برای بقیه مقدارها، صفر است. به این ترتیب برای پیدا کردن چندک، از کمینهسازی امید ریاضی نسبت به استفاده میکنیم. بنابراین خواهیم داشت.
با استفاده از مشتقگیری و با فرض اینکه جواب برای کمینهسازی همان (چندک ام) باشد، میتوانیم بنویسیم.
در نتیجه با توجه به پاسخ معادله بالا، خواهیم داشت:
و در نتیجه مشخص است که:
به این ترتیب میتوانیم چندک ام را مطابق با روشی که برمبنای کمینهسازی تابع زیان بیان شد بیابیم زیرا این رابطه بیانگر همان رابطه است.
مثال
فرض کنید متغیر تصادفی گسسته مقدارهای را با احتمالات یکسان اختیار میکند. میخواهیم میانه این متغیر تصادفی را پیدا کنیم. در این حالت داریم . از آنجایی که تابع احتمال یکنواخت و گسسته در نظر گرفته شده، احتمال رخداد هر یک از مقدارهای متغیر تصادفی برابر با است.
مقدار مورد انتظار (امید ریاضی) تابع زیان به صورت زیر در خواهد آمد.
$$\large L(u)=\frac{(\tau-1)}{9}\sum_{y_{i}<u}(y_{i}-u)+\frac{\tau}{9}\sum_{y_{i}\geq u}(y_{i}-u)\\ \large =\frac{0.5}{9}\left(-\sum_{y_{i}<u}(y_{i}-u)+\sum_{y_{i}\geq u}(y_{i}-u)\right)$$
اگر در نظر گرفته شود، مقدار تقریبا برابر با رابطه زیر برابر خواهد بود.
اگر فرض کنیم که مقدار هر بار یک واحد افزایش مییابد، آنگاه مقدار امید ریاضی تابع زیان برای مقدارهای کمتر از ۴ به میزان واحد کاهش خواهد یافت. در زمانی که باشد مقدار بوسیله رابطه زیر محاسبه میشود.
جدول زیر به بررسی مقدارهای برحسب مقدارهای مختلف پرداخته است. به این ترتیب مشخص است که میانه همان خواهد بود زیرا کمینه مقدار تابع در این نقطه حاصل میشود.
| 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
| 36 | 29 | 24 | 21 | 20 | 21 | 24 | 29 | 36 | Expected Loss |
چندک شرطی و رگرسیون چندکی
با مفهومی که از چندک و تابع زیان درک کردیم، حالا میتوانیم به چندک شرطی و رگرسیون چندکی بپردازیم. فرض کنید چندک شرطی نسبت به متغیر را به صورت نشان دادهایم. به کمک این رابطه رگرسیون یا مدل خطی رگرسیون چندکی را به شکل زیر بیان میکنیم.
به منظور برآورد پارامترهای این مدل خطی کافی است که تابع زیان معرفی شده را برحسب کمینه کنیم. بیان ریاضی این مسئله را به صورت زیر مینویسیم.
$$\large {\displaystyle \beta _{\tau }={\underset {\beta \in \mathbb {R} ^{k}}{\mbox{arg min}}}E(\rho _{\tau }(Y-X\beta ))}$$
حال این معادله منجر به برآورد پارامترهای به صورت زیر خواهد شد.
$$\large {\displaystyle {\hat {\beta _{\tau }}}={\underset {\beta \in \mathbb {R} ^{k}}{\mbox{arg min}}}\sum _{i=1}^{n}(\rho _{\tau }(Y_{i}-X_{i}\beta ))}$$
این مسئله کمینهسازی را به روش برنامهریزی خطی میتوان حل کرد. فرض کنید نمادهای زیر در نظر گرفته شدهاند.
با این نمادها در حقیقت تابع هدف در رگرسیون چندکی به شکل زیر قابل نوشتن است.
برای حل این مسئله میتوان از «روش سیمپلکس» (Simplex Method) یا «روش نقاط داخلی» (Interior Point Method) استفاده کرد.
اجرای رگرسیون چندکی در پایتون
به منظور انجام محاسبات رگرسیون چندکی در پایتون باید از کتابخانه statsmodels و تابع QuantReg استفاده کنید. به همین منظور کتابخانهها و ملزومات مربوط به استفاده از رگرسیون چندکی در پایتون در قطعه کدی که در ادامه قابل مشاهده است، قرار گرفته است.

توجه داشته باشید که در کدهای زیر منظور از quantile همان مقدار در فرمولها و روابط بالا است.
در این بین از مجموعه داده Engel در کتابخانه statsmodels استفاده شده است. همانطور که خط آخر نشان میدهد، سطرهای اول مربوط به این مجموعه داده، با اجرای کد نمایش داده میشود. در ادامه بعضی از این مشاهدات قابل رویت هستند. مشخص است که این مجموعه داده مربوط به میزان درآمد و هزینه خوراک خانوار است.
اگر مقدار برابر با 0.5 در نظر گرفته شود، به رگرسیون چندکی، «مدل کمترین قدرمطلق خطا» (Least Absolute Deviation) نیز میگویند به این ترتیب در کد زیر مقدار q که نشاندهنده مرتبه چندک است برابر با 0.5 در نظر گرفته شده است.
مشخص است که ابتدا مدل توسط تابع smf.quantreg تولید شده و سپس با کمک mod.fit پارامترهای مدل برای q=0.5 برازش شدهاند. خروجی این دستورات به صورت زیر خواهد بود.

به منظور نمایش نتایج حاصل از رگرسیون چندکی، ابتدا باید دادهها را آماده کنیم که امکان نمایش آنها در نمودار وجود داشته باشد. کدی که در ادامه مشاهده میکنید به این منظور تهیه شده است.
در این برنامه برای راحتی و جداسازی نتایج حاصل از رگرسیون چندکی و رگرسیون معمولی، محاسبات مربوط به رگرسیون چندکی را در یک دیتافریم پانادس (Pandas DataFrame) و نتایج حاصل از رگرسیون معمولی (OLS) را در ساختار دادهای دیکشنری (dictionary) قرار دادهایم. اجرای این کد نتایج را به صورت زیر نمایش خواهد داد.

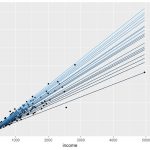
درصدها برای چندکها از 0.05 تا 0.95 مشخص شدهاند. البته به نظر میرسد که در کد، دامنه درصد برای چندکها از 0.05 تا 0.96 است ولی از آنجایی که میزان افزایش برای آنها 0.1 در نظر گرفته شده، هیچگاه به مقدار 0.96 نخواهیم رسید در نتیجه حداکثر مقدار برای در دامنه 0.05 تا 0.95 است. به این ترتیب صدک ۵ تا صدک ۹۵ ملاک ایجاد چندکها خواهد بود. البته فاصله بین چندکها ۱۰٪ است. در خروجی، مقدار a عرض از مبدا و b شیب خط چندک مربوطه است. در نمودارهایی که بوسیله کد زیر ترسیم میشود ۱۰ نقطه اول بوسیله رگرسیون چندکی و همچنین رگرسیون خطی معمولی ترسیم و مقایسه میشوند.
نمودار ترسیم شده به بررسی رابطه میزان درآمد و میزان سرانه خوراک پرداخته است. البته مشخص است که خطوط منقطع همان رگرسیون چندکی (Quantile Regression) و خط قرمز رنگ نیز رگرسیون خطی ساده (OLS) است. نقاط نیز به صورت دایرههای آبی رنگ در نمودار دیده میشوند.

در ادامه به بررسی ضرایب مدل رگرسیونی چندکی میپردازیم. برای برآورد هر یک از چندکها یک فاصله اطمینان ۹۵٪ نیز در نظر گرفتهایم. در نمودار زیر ۱۰ چندک (از چندک q=0.05 تا q=0.95) را ترسیم کردهایم.
همانطور که در نمودار خواهید دید، میانگین برآورد پارامترها در روش OLS ثابت است در حالیکه در روش رگرسیون چندکی، شیب خطها متفاوت است و در مثال ما برای چندکهای پایین شیب زیاد و برای چندکهای بالایی شیب کاهش مییابد. در بیشتر مواقع، نمودار ضرایب رگرسیون چندکی خارج از فاصله اطمینان برای ضرایب رگرسیونی OLS قرار میگیرند. خط مشکی در نمودار زیر نمایانگر ضرایب رگرسیون چندکی است و خط قرمز نیز میانگین ضریب رگرسیون OLS است. خط-نقطهها نیز بیانگر فاصلههای اطمینان برای هر دو گروه برآوردگرها هستند.

کاملا مشخص است که فاصله اطمینان برای ضرایب رگرسیون معمولی، ثابت است در حالیکه فاصله اطمینان برای ضرایب رگرسیون چندکی تابعی از درصد چندک است و با تغییر آن، طول فاصله اطمینان تغییر مییابد.
اگر علاقهمند به یادگیری مباحث مشابه مطلب بالا هستید، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزش های SPSS
- آموزش همبستگی و رگرسیون خطی در SPSS
- مجموعه آموزشهای نرمافزارهای آماری
- آموزش یادگیری ماشین
- رگرسیون خطی — مفهوم و محاسبات به زبان ساده
^^










