



تولید زبان طبیعی در پایتون – راهنمای جامع
به احتمال زیاد تا به حال، با اصطلاحاتی نظیر «پردازش زبان طبیعی» (Natural Language Processing)، «تحلیل متن» (Text Analysis) و «متنکاوی» (Text Mining) آشنا شدهاید. تمامی این اصطلاحات برای تعریف دستهای از الگوریتمهای حوزه «هوش مصنوعی» (Artificial Intelligence) و «یادگیری ماشین» (Machine Learning) استفاده میشوند که وظیفه آنها تحلیل، استخراج و مدلسازی اطلاعات مفید و بامعنی موجود در «دادههای متنی غیر ساخت یافته» (Unstructured Text Data) است.




اما شاید تا به حال با مفهوم «تولید زبان طبیعی» (Natural Language Generation) آشنا نشدهاید. به طور ساده، به فرآیند نرمافزاری «تبدیل خودکار» (Automatic Transform) دادههای خام یا «ساخت یافته» (Structured) به متون حاوی زبان طبیعی، تولید زبان طبیعی گفته میشود. اگر بخواهیم درک ملموستری از تولید زبان طبیعی داشته باشیم باشیم، میتوان این فرایند را متناظر با تبدیل ایده به نوشته یا سخن، توسط انسانها در نظر گرفت. فرایند تولید زبان طبیعی، نقطه مقابل «درک زبان طبیعی» (Natural Language Understanding) به حساب میآید.
در فرایند درک زبان طبیعی، سیستم کامپیوتری باید قادر باشد دادههای متنی ورودی به سیستم را پردازش و «ابهامزدایی» (Disambiguate) کند و از این طریق، زبان (یا مجموعهای از دستورالعملهای کامپیوتری) لازم برای تولید نمایش ماشینی آنها را تولید کند؛ در حالی که در تولید زبان طبیعی، کامپیوتر یا برنامه کامپیوتری باید قادر باشد دادههای «ماشینخوان» (Machine Readable) را به کلمات یا جملات حاوی زبان طبیعی تبدیل کند.
تفاوت دیگر میان سیستمهای درک و تولید زبان طبیعی، نامتقارن بودن مسائل قابل حل توسط این دسته از سیستمها است. در درک زبان طبیعی، سیستم باید بر خطا و ابهام موجود در دادههای حاوی زبانی طبیعی غلبه کند، اما در فرایند تولید زبان طبیعی، ایدهها و دادههایی که قرار است توسط زبان طبیعی بیان شوند، دقیق و ساخت یافته هستند.نیازمندی اصلی پیادهسازی یک سیستم تولید زبان طبیعی، «مالکیت» (Ownership) یا «دسترسی» (Access) به حجم عظیمی از دادههای خام یا ساخت یافته است. به عبارت دیگر، همیشه پای داده در میان است.
برای اینکه سیستم تولید زبان طبیعی قادر باشد تا روایت حاوی زبان طبیعی از دادهها تولید کند، لازم است تا قالب محتوای دادهها برای سیستم مشخص شود (از طریق تعریف «قالب» (Template) و یا «جریانهای کاری» مبتنی بر قاعده (Rule-based Workflow)). سپس دادههای ساخت یافته و قالب محتوایی آنها به سیستم وارد شده و دادههای حاوی زبان طبیعی، در خروجی تولید میشوند. سیستمهای تولید زبان طبیعی در وضعیت کنونی، بدون نظارت انسانی، قادر نیستند دادههای «غیر ساخت یافته» (Unstructured) را به متون نوشته شده به زبان طبیعی تبدیل کنند.
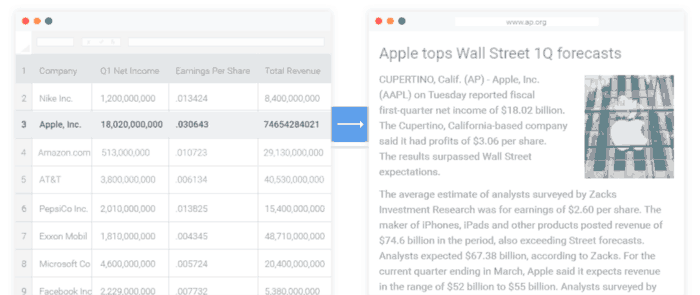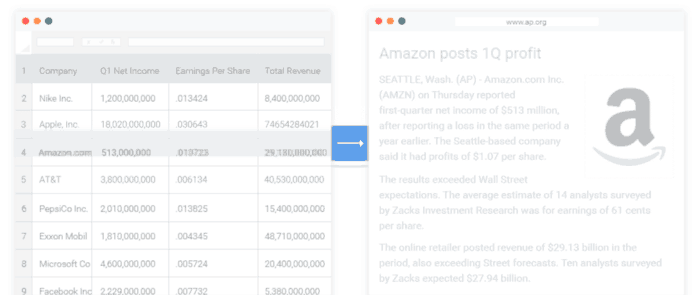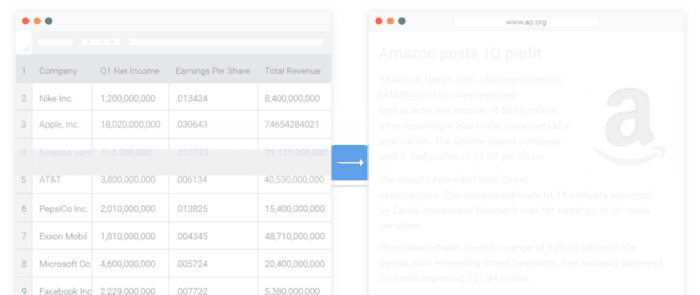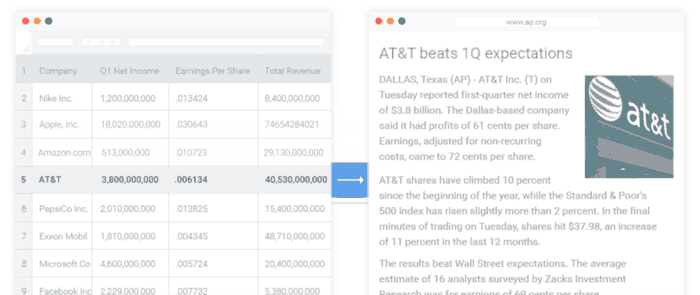
تولید زبان طبیعی و کاربردهای آن در صنعت
امروزه، بیشترین کاربرد چنین سیستمهایی در صنایع و شرکتهای تجاری است. به ویژه، در حالتی که صنایع و شرکتها نیاز داشته باشند، بدون صرف هزینه و وقت زیاد، دادههای سازمانی و غیر سازمانی مرتبط را در قالب گزارشات متنی خلاصهسازی کنند.
با این حال، دیگر کاربردهای مهم سیستمهای تولید زبان طبیعی عبارتند از:
- تولید تحلیلها در قالب نوشتاری جهت نمایش در داشبوردهای «هوش تجاری» (Business Intelligence)
- تولید خودکار گزارشات متنی منعکس کننده محتویات دادههای تجاری و تحلیل آنها
- «شخصیسازی» (Personalization) ارتباط با مشتریان از طریق ایمیل و پیامهای درون برنامهای
- تولید گزارشات مرتبط با وضعیت و شرایط «نگهداری» (Maintenance) دستگاههای «اینترنت اشیاء» (Internet of Things | IoT)
- به روز رسانی و خلاصهسازی «اسناد مالی» (Financial Portfolio) مشتریان
- تولید خودکار محتویات متنی مرتبط با توضیحات کالاهای تجاری یا دستهبندی آنها در وبسایتها یا پلتفرمهای «تجارت الکترونیک» (E-Commerce)
دادههای متنی (حاوی زبان طبیعی) تولید شده توسط سیستمهای تولید زبان طبیعی، باید به گونهای باشند که گویا توسط یک کاربر انسانی نوشته شدهاند. نگرش خاص موجود در دادههای متنی تولید شده، محتوا، زمینه موضوعی، شیوه نگارش و ساختارِ روایت خودکار و ماشینی ایجاد شده، بسته به مخاطب نهایی میتواند متفاوت باشد. خروجی نهایی چنین سیستمهایی توسط مفهومی به نام «طراحی روایت» (Narrative Design) تولید میشود.
مدلهای طراحی روایت، قالب و یا جریانهای کاری مبتنی بر قاعده هستند که توسط کاربر نهایی یا سازندههای سیستم تولید زبان طبیعی تعریف میشوند و وظیفه دارند دادههای ساختیافته را به روایتهای متنی حاوی زبان طبیعی تبدیل کنند.

مفاهیم تولید زبان طبیعی
با جستجو در رابطه با مدلهای تولید زبان طبیعی در سطح اینترنت، میتوان مطالبی را پیدا کرد که در آنها جزئیات مدلهای هوش مصنوعی و یادگیری ماشین ارائه شده است که قادرند پس از مشاهده فیلمهای سینمایی و یا خواندن کتاب، خروجیهای جدید و تا حدی مشابه آنها تولید کنند. اگر چه محتویات تولید شده توسط این سیستمها بیشتر برای خنداندن انسانها مفید است، با این حال، نمونههایی از سیستمهای تولید زبان طبیعی را نشان میدهند. در چند سال اخیر و با پیشرفتهای حاصل شده در حوزه هوش مصنوعی و سختافزارهای محاسباتی، استفاده از یادگیری ماشین برای تولید متن، تصویر و ویدئوهای بدیع بسیار رواج یافته است.
پیشرفتهای اخیر حاصل شده در حوزه «یادگیری عمیق» (Deep Learning) و سیستمهای مبتنی بر آن (نظیر مدل GPT-2 که توسط شرکت OpenAI توسعه داده شده است)، سبب شده است تا سیستمهای هوشمندی پدید آیند که قادرند با استفاده از حجم عظیمی از نمونههای آموزشی، دادههای متنی بسیار واقعگرایانهای تولید کنند. در این مطلب، برخی از روشهای مبتنی بر یادگیری ماشین برای تولید زبان طبیعی معرفی میشوند و کدهای لازم برای تولید «دادههای متنی تقلبی» (Fake Text Data) در زبان برنامهنویسی پایتون نمایش داده خواهند شد.
مفاهیم و روشهای ابتدایی در تولید زبان طبیعی
به جای استفاده از روشهای پیشرفته تولید زبان طبیعی (نظیر یادگیری عمیق)، در این مطلب سعی شده است تا یکی از تکنیکهای شناخته شده و بسیار سر راست جهت تولید زبان طبیعی معرفی شود. این روش، از یک سو درک مفهوم تولید زبان طبیعی را برای کاربران و مخاطبان این مطلب تسهیل میکند و از سوی دیگر، پیادهسازی آن (به عنوان نقطه شروعِ مطالعه سیستمهای تولید زبان طبیعی) در زبان برنامهنویسی پایتون ساده و سر راست است. یکی از روشهای معروف و شناخته شده در تولید متن زبان طبیعی، روش «زنجیرههای مارکوف» (Markov Chains) است. این روش، در عین سادگی پیادهسازی، در تولید زبان طبیعی بسیار قدرتمند ظاهر میشود.
روشهای زنجیره مارکوف، فرایندهایی «تصادفی» (Stochastic) هستند که تنها با داشتن «رویداد قبلی» (Previous Event) در دنبالهای از رویدادها، قادر به توصیف رویداد بعدی خواهند بود. مزیت چنین مشخصهای در مدل زنجیرههای مارکوف، در زمان پیشبینی رویداد بعدی مشخص میشود؛ بدین معنی که سیستم برای پیشبینی رویداد یا وضعیت بعدی، لازم نیست از مجموعه تمامی رویدادها یا وضعیتهای پیشین خود آگاهی داشته باشد. زمانی که از مدل زنجیرههای مارکوف برای تولید زبان طبیعی استفاده میشود، منظور از وضعیت پیشین، کلمه قبلی، 2 کلمه قبلی (Bigram) و یا 3 کلمه قبلی (Trigram) در متن زبان طبیعی تولید شده است.به چنین دنبالههایی از کلمات در پردازش زبان طبیعی، N-gram گفته میشود.
در مدلهای تولید زبان طبیعی، از N کلمه قبلی برای تولید (یا پیشبینی) کلمه بعدی ممکن در دنباله کلمات استفاده میشود. یک مدل زنجیره مارکوف، از طریق روشهای «وزندهی احتمالی» ( Probabilistic Weighting)، وضعیت بعدی سیستم را مشخص میکند. با این حال، اگر در هنگام تولید زبان طبیعی، از روش وزندهی احتمالی برای پیشبینی کلمه بعدی در دنباله کلمات استفاده کنیم، روشی حاصل خواهد شد که در آن روش انتخاب کلمات و ساختار کلمات، بسیار «قطعی» (Deterministic) به نظر خواهند رسید. به عبارت دیگر، متون زبان طبیعی تولید شده، بسیار مصنوعی به نظر خواهند آمد.
برای رفع چنین نقیصهای میتوان تغییراتی در روش وزندهی احتمالی پدید آورد. با این حال، بهترین راه غلبه بر این مشکل، معرفی فاکتورهای «تصادفی» (Random) در هنگام پیشبینی وضعیت بعدی سیستم است که سبب تولید جملات زبان طبیعی به مراتب واقعگرایانهتر و بدیعتر میشود.

تولید مدل زبانی
تولید «مدل زبانی» (Language Model) بسیار ساده است. ابتدا نیاز است مجموعهای از دادههای متنی نمونه (Corpus)، برای تولید مدل زبانی جمعآوری شوند. این مجموعه میتواند حاوی انواع مختلفی از دادههای متنی حاوی زبان طبیعی نظیر کتاب، مطالب وبسایتها، پستهای شبکههای اجتماعی و سایر موارد باشد.
در این مطلب، تعدادی از سخنرانیهای منتشر شده از رؤسای جمهور ایالات متحده آمریکا، برای ساختن مدل زبانی مورد استفاده قرار گرفتهاند. پس از جمعآوری دادههای متنی مورد نیاز برای تولید مدل زبانی، لازم است مراحل زیر دنبال شوند تا سیستم قادر به تولید متون زبان طبیعی باشد. علاوه بر مراحل زیر، توکن (#END#) نیز به مدل زبانی تعریف شده اضافه میشود تا «وضعیت پایانی» (Ending State) در هر کدام از متنهای سخنرانی جمعآوری شده مشخص شود.
- جداسازی واحدهای زبانی موجود در دادههای متنی جمعآوری شده (Tokenization)
- مرحله اختیاری: انجام هر نوع فرایند پیشپردازشی مورد نیاز کاربر (در این مطلب، برای تولید زبان طبیعی از روشهای پیشپردازشی استفاده نشده است.)
- تولید مدل زبانی N-gram از توکنهای پردازش شده
- ایجاد یک «نگاشت» (Mapping) از مدل N-gram به کلمات محتمل بعدی (کلمات بعدی در دنباله، پیشبینی میشوند.)
برای اینکه درک بهتری از نحوه تولید مدل زبانی، برای کاربران و مخاطبان این مطلب ایجاد شود، مثال بسیار سادهای در ادامه آورده شده است. فرض کنید که یک داده متنی ساده به شکل (.The dog jumped over the moon. The dog is funny) به سیستم داده شود. با استفاده از فرایند تولید مدل (مراحل بالا)، مدل زبانی و نگاشتهای N-gram زیر تولید خواهند شد:
(The, dog) -> [jumped, is] (dog, jumped) -> [over] (jumped, over) -> [the] (over, the) -> [moon.] (dog, is) -> [funny.] (is, funny) -> [#END#]
به محض اینکه مراحل تولید نگاشتهای N-gram با موفقیت به پایان رسید، از مدل زبانی تولید شده برای تولید دادههای متنی جدید استفاده میشود. برای تولید دادههای متنی جدید کافی است تا یک «نقطه آغازین» (Starting Point) برای مدل انتخاب شود. برای انتخاب نقطه آغازین، به دو شیوه میتوان عمل کرد:
- تعریف یک نقطه آغازین جهت تولید داده متنی نظیر عبارت (The dog)، توسط کاربر
- انتخاب نقطه آغازین تصادفی، از میان تمامی عبارات N-gram تولید شده
به محض اینکه نقطه آغازین جهت تولید داده متنی برای مدل زبانی تعریف شود، کلمه (وضعیت) بعدی بهطور تصادفی، از میان لیست کلمات محتمل بعدی انتخاب میشود. سپس، عبارت N-gram بعدی، در متن تولید شده مشخص و وضعیت (کلمه) بعدی بهطور تصادفی و با توجه به عبارت N-gram مشخص شده، از میان لیست کلمات محتمل بعدی انتخاب میشود. این رویه، تا پایان فرایند تولید متن حاوی زبان طبیعی ادامه خواهد داشت.
مدل زنجیره مارکوف در پایتون
تا به اینجا با مفهوم مدل زبانی و چگونگی تولید یک مدل زبانی ساده، با استفاده از روش زنجیره مارکوف آشنا شدیم. در ادامه، قطعه کد لازم برای آموزش مدل مارکوف و تولید متن حاوی زبان طبیعی در زبان برنامهنویسی پایتون نمایش داده شده است.
در ادامه نگاه دقیقتری به کدهای نمایش داده شده و توابع پیادهسازی شده در آن خواهیم انداخت. این قطعه کد، از دو تابع اصلی تشکیل شده است؛ یک تابع برای یادگیری مدل مارکوف و تابع دیگر، برای تولید متن زبان طبیعی. تابع یادگیری، مدل مارکوف لازم را برای تولید متن زبان طبیعی، با استفاده از لیستی متشکل از N توکن و عبارت N-gram تولید میکند.
نحوه کار این روش برای تولید زبان طبیعی بدین صورت است که در حلقه ابتدایی تابع، تمامی توکنهای موجود در دادههای متنی جمعآوری شده پردازش و یک «دایره لغات» (Dictionary) متشکل از تمامی عبارات N-gram (کلمات مجاور یکدیگر در مجموعه دادههای متنی) ساخته میشود. سپس، وقتی که حلقه تابع به عبارت N-gram آخر میرسد، عملیات تابع متوقف میشود و عبارات N-gram آخر به توکن (#END#) نگاشت میشود. توکن (#END#) پایانی برای سیستم تولید زبان طبیعی مشخص میکند که به انتهای سند رسیده است؛ یعنی، وضعیت نهایی مدل مارکوف پیشنهادی توسط توکن (#END#) مشخص میشود. نمونهای از نگاشت عبارات N-gram آخر به توکن (#END#) در ادامه آمده است.
(be, happy) -> [#END#]
یکی از محدودیتهای مدل تولید زبان طبیعی پیشنهادی در این مطلب این است که تمامی دادههای موجود در مجموعه دادههای متنی، با یکدیگر در یک لیست ترکیب میشوند؛ در نتیجه، تنها یک وضعیت نهایی (توکن #END#) در مدل مارکوف تعریف میشود. یکی از بخشهای قابل بهبود در مدل تولید زبان طبیعی پیشنهادی، قرار دادن وضعیت نهایی (توکن #END#) در انتهای هر کدام از اسناد پردازش شده در سیستم است. همچنین، میتوان از وضعیت نهایی (توکن #END#) برای مشخص کردن انتهای جملات در اسناد متنی استفاده کرد. در چنین حالتی، سیستم به شکل بهتری قادر به تولید جملات زبان طبیعی خواهد بود. علاوه بر این، در صورت قرار دادن وضعیت نهایی (توکن #END#) در پایان هر جمله، سیستم تولید زبان طبیعی قادر خواهد بود تا به شکل بهتری، زمان شروع یک جمله جدید را تشخیص دهد. در مرحله بعد، تابع پیادهسازی شده برای تولید متن زبان طبیعی مورد بررسی قرار میگیرد.
تابع پیادهسازی شده برای تولید متن زبان طبیعی، دو آرگومان را بهعنوان ورودی دریافت میکند؛ اندازه عبارت N-gram و اندازه بیشینه برای تعداد توکنهای موجود در متن زبان طبیعی تولید شده. همچنین پارامتری به نام seed در این تابع وجود دارد. در صورتی که مقدار پارامتر seed برابر با None باشد، سیستم به طور خودکار و کاملا تصادفی، یک عبارت N-gram را از میان تمامی عبارات N-gram ممکن که روی آنها آموزش دیده است، به عنوان نقطه آغازین انتخاب میکند. در هر تکرار از این تابع، با توجه به عبارت N-gram قبلی (وضعیت پیشین)، کلمه بعدی (وضعیت بعدی) برای «گذار» (Transition) انتخاب میشود. این کار تا زمانی ادامه پیدا میکند که در یکی از تکرارها، مدل به وضعیت نهایی (توکن #END#) برسد و یا شرط اندازه بیشینه برای تعداد توکنهای موجود در متن تولید شده ارضا شود.
در ادامه، یک نمونه متن زبان طبیعی تولید شده با استفاده از توابع بالا نمایش داده میشود. در این مثال، مدل زنجیره مارکوف، روی مدل زبانی Bigram آموزش دیده است.
Us from carrying out even the dishonest media report the facts! my hit was on the 1st of december, 1847, being the great reviews & will win on the front lines of freedom. we are now saying you will never forget the rigged system that is what we do at a 15 year high. i can perceive no good reason why the civil and religious freedom we enjoy and by the secretary of war would be 0.0 ratings if not.
همان طور که مشاهده میشود، متن تولید شده ساختار تقریبا مناسبی دارد ولی تصادفی بود آن کاملا مشهود است. در ادامه، یک نمونه دیگر از متن زبان طبیعی تولید شده نمایش داده شده است. در این مثال، مدل زنجیره مارکوف، روی مدل زبانی Trigram آموزش دیده است.
Was $7,842,306.90, and during the seven months under the act of the 3d of march last i caused an order to be issued to our military occupation during the war, and may have calculated to gain much by protracting it, and, indeed, that we might ultimately abandon it altogether without insisting on any indemnity, territorial or otherwise. whatever may be the least trusted name in news if they continue to cover me inaccurately and with a group, it’s going to be open, and the land will be left in better shape than it is right now. is that right? better shape. (applause.) we declined to certify the terrible one-sided iran nuclear deal. that was a horrible deal. (applause.) whoever heard you give $150 billion to a nation
متن دوم، ساختار بهتری نسبت به متن اول دارد ولی با بررسی دقیقتر جملات تولید شده میتوان دریافت که مدل آموزش دیده، جملات و عبارات موجود در دادههای متنی جمعآوری شده را بهطور تصادفی انتخاب و در کنار یکدیگر قرار میدهد. در واقعیت، تا زمانی که حجم عظیمی از دادهها برای آموزش مدل زنجیره مارکوف در اختیار نباشد، به محض استفاده از مدلهای زبانی Trigram و بالاتر، شاهد بروز چنین رفتاری در سیستم تولید زبان طبیعی خواهیم بود. این نقیصه، یکی از بزرگترین مشکلات مدل زنجیره مارکوف است.
زنجیره مارکوف با مدل زبانی Bigram، اگر چه تصادفیتر به نظر میآید، ولی با هر بار اجرای آن، خروجیهای به مراتب جدیدتر و متمایزتری نسبت به زنجیره مارکوف با مدل زبانی Trigram تولید میکند. نکته مهمی که باید در مورد سیستمهای تولید زبان طبیعی به خاطر داشته باشید این است که هر چقدر مجموعه دادههای متنی جمعآوری شده برای آموزش مدل زنجیره مارکوف جامعتر باشند، جملات و متن زبان طبیعی تولید شده، ساختار بهتری خواهند داشت.
مدل زنجیره مارکوف توزیع شده با استفاده از بسته Spark
فرض کنید به جای مجموعهای از سخنرانیهای منتشر شده از رؤسای جمهور ایالات متحده آمریکا، مجموعهای متشکل از پیامهای آرشیو شده در شبکههای اجتماعی در دسترس باشند. کدهای ارائه شده برای مدلسازی و تولید زبان طبیعی از روی دادههای متنی، در صورتی که حجم حافظهای و توان پردازشی کافی برای تحلیل آنها موجود باشد، به احتمال زیاد قادر به پردازش این حجم از داده خواهد بود ولی «مقیاسپذیری» (Scalability) به شدت ضعیفی خواهند داشت. در چنین حالتی، بهتر است که از بسته نرمافزاری Apache Spark و قابلیتهای محاسبات توزیعشده آن، جهت ساخت و ذخیره مدل زنجیره مارکوف استفاده شود. در ادامه، کدهای پیادهسازی مدل زنجیره مارکوف با استفاده از Apache Spark توضیح و نمایش داده شده است.

بزرگترین مشکل پیادهسازی مدل زنجیره مارکوف با استفاده از Apache Spark، چگونگی تولید مدل N-gram، تولید ساختاری شبیه به دایره لغات برای ذخیره عبارات N-gram و پرس و جو در آنها است. خوشبختانه، بسته Apache Spark قابلیتی برای استخراج ویژگیهای N-gram از اسناد متنی دارد. این قابلیت در بسته Apache Spark، یک شیء از «فریم دادهای» (Dataframe) بسته Spark و اسناد متنی پردازش شده (Tokenized) را به عنوان آرگومان ورودی دریافت میکند و عبارات N-gram موجود در دادههای متنی را، به عنوان خروجی تولید میکند.
با استفاده از بسته Apache Spark، میتوان تابعی برای تولید نگاشت (Mapping) از مدل N-gram به کلمات (مجاور) محتمل بعدی ایجاد کرد. هدف این تابع این است که به ازاء هر کدام از اسناد پردازش شده، لیستی از «چندتاییها» (Tuples) به شکل [(ngram, adjacent term)] تولید کند.
در نهایت، عبارات N-gram در اسناد مختلف با یکدیگر ترکیب میشوند و دوتاییهای جدید به شکل [(ngram, adjacent term list)] تولید میشوند. نکته مهمی که در این بخش وجود دارد این است که کلمات تکراری زیادی در لیست «کلمات مجاور» (Adjacent Term) هر عبارات N-gram ظاهر خواهند شد. از کلمات تکراری موجود در لیست، به عنوان «وزن» (Weight) کلمات در هنگام انتخاب کلمه بعدی (وضعیت بعدی) استفاده میشود.
در ادامه، کدهای پیادهسازی مدل زنجیره مارکوف با استفاده از Apache Spark نمایش داده شده است.
کدهای پیادهسازی مدل زنجیره مارکوف با استفاده از Apache Spark، خروجی مشابه با کدهای مرحله قبل تولید میکنند؛ با این تفاوت که مقیاسپذیری بسیار بهتری نسبت به کدهای مرحله قبل دارند.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای داده کاوی و یادگیری ماشین
- آموزش اصول و روشهای داده کاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- متنکاوی (Text Mining) — به زبان ساده
- روشهای متنکاوی — راهنمای کاربردی
- پیادهسازی سیستمهای توصیهگر در پایتون — از صفر تا صد
- پیادهسازی سیستم تشخیص و ردیابی خودرو در پایتون — راهنمای جامع
^^








درود بر شما. جای چنین مطالب آموزشی در کشور بسیار خالیست.