


پیچیدگی زمانی عملیات جاوا روی انواع ساختمان داده – به زبان ساده
در این مقاله در مورد عملکرد کلکسیونهای مختلف مربوط به API Collection جاوا صحبت میکنیم. زمانی که از کلکسیونها سخن میگوییم، معمولاً یاد ساختمانهای داده List ،Map و Set و پیادهسازیهای رایج آنها میافتیم. قبل از هر چیز، به مفهوم پیچیدگی O بزرگ برای عملیات رایج میپردازیم و سپس برخی اعداد واقعی از عملیات کلکسیون در زمان اجرا ارائه خواهیم کرد. بنابراین با ما همراه باشید تا پیچیدگی زمانی عملیات جاوا روی انواع ساختمان داده را به زبان ساده توضیح دهیم.

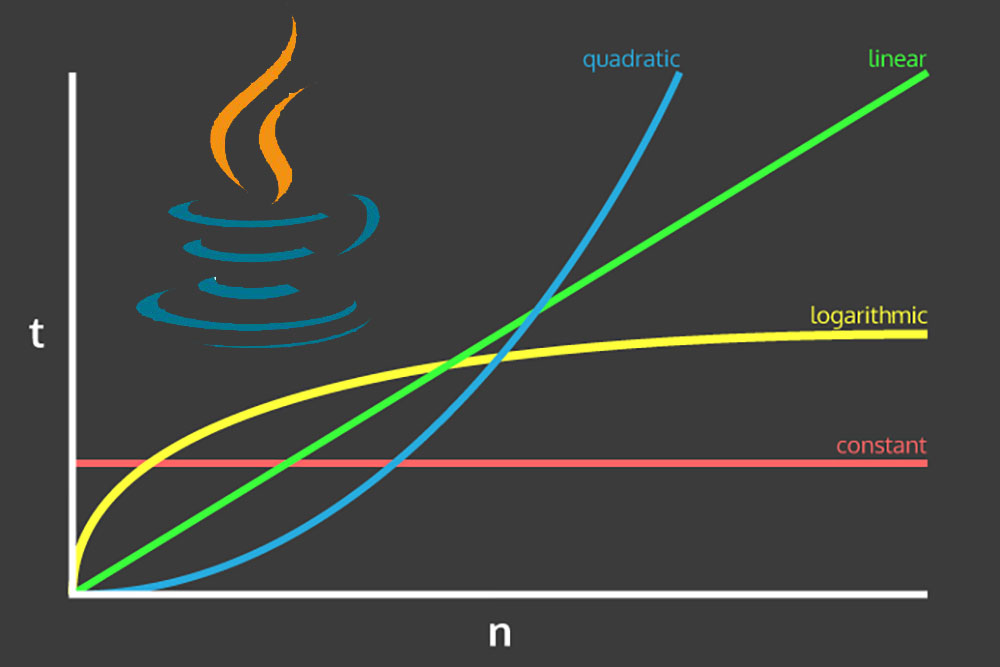


پیچیدگی زمانی
به طور معمول زمانی که از پیچیدگی صحبت میکنیم منظورمان نمادگذاری O بزرگ است. به بیان ساده این نمادگذاری میزان رشد مدت زمان مورد نیاز برای اجرای الگوریتم را در صورت افزایش اندازه ورودی مشخص میسازد.
برای یادگیری موارد بیشتر در مورد نمادگذاری O بزرگ پیشنهاد میکنیم از مطلب زیر بازدید نمایید:
ساختمان داده List
کار خود را با لیست ساده آغاز میکنیم که یک کلکسیون مرتب است. در ابن بخش به بررسی عملکرد پیادهسازیهای ArrayList, LinkedList و CopyOnWriteArrayList میپردازیم.
ArrayList
ArrayList در جاوا توسط یک آرایه پشتیبانی میشود. بدین ترتیب میتوانیم منطق درونی پیادهسازی آن را درک کنیم. بدین ترتیب ابتدا روی پیچیدگی زمانی عملیات رایج در سطح بالا متمرکز میشویم:
- add() – مدت زمان O(1) طول میکشد.
- (add(index, element – به طور میانگین در مدت زمان O(n) اجرا میشود.
- ()get – همواره دارای زمان ثابت O(1) است.
- remove() – با زمان خطی (O(n اجرا میشود. ما باید روی کل آرایه بچرخیم تا عنصری که شرایط حذف را دارد پیدا کنیم.
- indexOf() – این عملیات نیز دارای زمان اجرای خطی است. این عملیات روی کل آرایه میچرخد و هر عنصر را یک به یک بررسی میکند، بنابراین پیچیدگی زمانی این عملیات همواره O(n) است.
- contains() – پیادهسازی آن بر مبنای indexOf() است و از این رو زمان مورد نیاز آن نیز O(n) است.
CopyOnWriteArrayList
این پیادهسازی از اینترفیس List زمانی که مشغول کار با اپلیکیشنهای چند نخی هستیم بسیار مفید است، چون دارای ویژگی «ایمنی نخ» ((thread-safe است.
در ادامه عملکرد O بزرگ را برای CopyOnWriteArrayList میبینید:
- ()add – به مقداری اضافه کردهایم بستگی دارد و از این رو پیچیدگی آن O(n) است.
- ()get – عملیات با ثابت زمانی O(1) است.
- ()remove – مدت زمان O(n) طول میکشد.
- ()contains – به طور مشابه پیچیدگی آن O(n) است.
چنان که میبینید استفاده از کلکسیون به دلیل مشخصههای عملکردی متد add() بسیار پرهزینه است.
LinkedList
«لیست پیوندی» (LinkedList) یک ساختمان داده خطی است که شامل گرههایی برای نگهداری فیلدهای داده و ارجاعی به گرههای دیگر است. برای کسب اطلاعات بیشتر در مورد لیستهای پیوندی به لینک زیر مراجعه کنید:
در ادامه زمان تخمینی میانگین مورد نیاز برای اجرای برخی از عملیات ابتدایی را مشاهده میکنید:
- ()Add – درج در هر موقعیت از پیچیدگی زمانی (O(1 برخوردار است.
- ()Get – جستجو به دنبال عناصر، زمان (O(n طول میکشد.
- ()remove – حذف یک عنصر نیز به زمان (O(1 نیاز دارد، چون موقعیت عنصر ارائه شده است.
- ()contains – این عملیات دارای پیچیدگی زمانی خطی (O(n است.
گرم کردن JVM
اینک برای اثبات تئوری، کمی با دادههای واقعی کار میکنیم. به عبارت دقیقتر نتایج تست JMH یعنی Java Microbenchmark Harness را برای اغلب عملیات رایج کلکسیون ارائه میکنیم.
ابتدا پارامترهای اصلی تستهای بنچمارک را ارائه میکنیم:
سپس تعداد تکرارهای گرم کردن را روی 10 تعیین میکنیم. ضمناً میخواهیم زمان اجرای میانگین نتایج نمایش یافته را بر حسب میکروثانیه ببینیم.
تستهای بنچمارک
اینک زمان آن رسیده است که تستهای بنچمارک را اجرا کنیم. ابتدا با ArrayList آغاز میکنیم:
درون ArrayListBenchmark کلاس State را برای نگهداری از دادههای اولیه اضافه میکنیم.
در این بخش یک ArrayList از اشیای Employee میسازیم. پس از اقدام به مقداردهی آن با 100،000 آیتم درون متد ()setUp میکنیم. State@ نشان میدهد که تستهای Benchmark@ دسترسی کاملی به متغیرهای اعلانشده در همان نخ دارند.
در نهایت نوبت آن میرسد که تستهای بنچمارک را برای متدهای ()add() ،contains() ،indexOf() ،remove و ()get اضافه کنیم:
نتایج تست
همه نتایج بر حسب میکروثانیه ارائه شدهاند:
از روی نتایج فوق میفهمیم که متدهای ()testContains و ()testIndexOf تقریباً زمان اجرای یکسانی دارند. همچنین به وضوح میبینیم که تفاوت عظیمی بین نمرات متد ()testAdd و ()testGet از بقیه نتایج وجود دارد. افزودن یک عنصر باعث میشود که 2.296 میکروثانیه طول بکشد و دریافت آن نیز در طی زمان 0.007 میکروثانیه صورت میگیرد.
با این که زمان جستجو یا حذف یک عنصر تقریباً 700 میکروثانیه است، این اعداد اثباتی بر بخش نظری قبلی هستند که فهمیدیم پیچیدگی زمانی ()add و ()get به مقدار (O(1 و برای عملیات دیگر به مقدار (O(n است که در این مثال از n=10000 استفاده شده است.
به طور مشابه، میتوانیم همین تستها را برای کلکسیون CopyOnWriteArrayList بنویسیم. تنها چیزی که نیاز داریم جایگزینی ArrayList در employeeList با وهله CopyOnWriteArrayList است.
در ادامه نتایج بنچمارک را میبینید:
در این مورد نیز یک بار دیگر نتایج، تئوری را اثبات میکنند. چنان که میبینیم ()testGet به صورت میانگین در مدت زمان 0.006 میکروثانیه اجرا میشود و میتوانیم آن را O(1) تصور کنیم. در مقایسه با ArrayList نیز متوجه تفاوت زیادی بین نتایج متد ()testAdd میشویم. از آنجا که در اینجا پیچیدگی O(n) را برای متد ()add در برابر مقدار (O(1 برای ArrayList داریم.
به روشنی شاهد یک رشد خطی زمان هستیم، چون عملکرد عدد 878.166 را در مقایسه با 0.051 نمایش میدهد.
اینک نوبت به LinkedList میرسد:
از روی نمرات میتوان فهمید که افزودن و حذف عناصر در لیست پیوندی کاملاً سریع است. به علاوه یک شکاف عملکردی مهم بین عملیات add/remove و get/contains وجود دارد.
ساختمان داده Map
در جدیدترین نسخههای JDK شاهد بهبود عملکرد قابل توجهی برای پیادهسازیهای Map هستیم که شامل جایگزینی با ساختمان گره درخت متعادل متوازن در پیادهسازیهای درونی HashMap و LinkedHashMap میشود. این کار موجب کاهش زمان بدترین سناریوهای گشتن به دنبال عنصر از (O(n به O(log(n)) در زمان تصادم HashMap شده است.
با این حال در صورت پیادهسازی مناسب احتمال تصادم ()equals و ()hashcode بسیار پایین است.
لازمه به ذکر است که زمان بازیابی و ذخیرهسازی عناصر در HashMap به صورت (O(1 است.
تست کردن عملیات (O(1
اینک به بررسی مثالهای واقعی میپردازیم. ابتدا HashMap را بررسی میکنیم:
چنان که میبینیم اعداد ثابت میکنند که زمان ثابت O(1) برای اجرای متدهای فوق وجود دارد. اینک نمرات تست HashMap را با نمرات وهله دیگری از Map مقایسه میکنیم.
در مورد همه متدهای لیست شده برای HashMap ،LinkedHashMap ،IdentityHashMap ،WeakHashMap ،EnumMap و ConcurrentHashMap با زمان ثابت O(1) مواجه هستیم.
در ادامه نتایج نمرات باقیمانده تست را به شکل جدول مشاهده میکنید:
از روی اعداد خروجی میتوان تأیید کرد که ادعای پیچیدگی زمانی O(1) در این مورد صحیح است.
تست کردن عملیات O(log(n))
در مورد ساختمان درخت TreeMap و ConcurrentSkipListMap، عملیات ()put() ،get() ،remove و ()containsKey دارای پیچیدگی زمانی O(log(n)) است.
در این بخش میخواهیم مطمئن شویم که تستهای عملکردی ما تقریباً در زمان لگاریتمی اجرا میشوند. به همین جهت map-ها را به صورت پیوسته با n=1000, 10,000, 100,000, 1,000,000 آیتم مقداردهی میکنیم.
در این حالت به زمان کلی اجرا علاقهمند هستیم.
زمانی که n=1000 است، زمان کلی اجرا بر حسب میلیثانیه برابر با 00:03:17 است. در تعداد آیتم n=10,000 زمان تقریباً بدون تغییر و برابر با 00:03:18 میلیثانیه است. در تعداد n=100000، زمان اجرا به 00:03:30 افزایش مییابد. در نهایت زمانی که n = 1000000 میشود، زمان اجرا برابر با 00:05:27 میلیثانیه خواهد بود.
پس از مقایسه اعداد، زمان اجرای با تابع (log(n برای هر n، میتوان تأیید کرد که محاسبه هر دو تابع با هم مطابقت دارند.
ساختمان داده Set
به طور کلی Set یک کلکسیون با عناصر یکتا است. در این بخش قصد داریم پیادهسازی HashSet ،LinkedHashSet، EnumSet ،TreeSet ،CopyOnWriteArraySet و ConcurrentSkipListSet از اینترفیس Set را بررسی کنیم.
اینک مستقیماً به سراغ بررسی اعداد پیچیدگی زمانی میرویم. پیچیدگی زمانی برای عملیات ()add() ،remove و ()contains برای HashSet ،LinkedHashSet و EnumSet به صورت ثابت (O(1 است. این واقعیت به لطف پیادهسازی داخلی HashMap رخ داده است.
به طور مشابه پیچیدگی زمانی TreeSet برای عملیات لیست شده فوق به صورت ((O(log(n است. دلیل این امر به پیادهسازی TreeMap بازمیگردد. پیچیدگی زمانی برای ConcurrentSkipListSet نیز برابر با ((O(log(n است چون بر مبنای رد کردن ساختمان داده List طراحی شده است.
متدهای ()add() ،remove و ()contains برای CopyOnWriteArraySet دارای پیچیدگی زمانی میانگین (O(n است.
تست متدها
اینک به سراغ تستهای بنچمارک خود میرویم.
به علاوه پیکربندی بنچمارک را نیز همانند قبل و بدون تغییر بوده است.
مقایسه نتایج
در ادامه به مشاهده رفتار نمرات زمان اجرای HashSet و LinkedHashSet در هنگامی که n = 1000; 10,000; 100,000 آیتم است پرداختهایم.
در مورد HashSet نتایج به صورت زیر هستند:
به طور مشابه نتایج در مورد LinkedHashSet به صورت زیر هستند:
چنان که مشاهده میشود، نمرات برای همه عملیات تقریباً یکسان باقی مانده است. حتی هنگامی که آنها را با خروجیهای تست HashMap مقایسه میکنیم، همچنان یکسان به نظر میرسند.
در نتیجه تأیید میشود که همه متدهای تست شده در زمان ثابت (O(1 اجرا شدهاند.
سخن پایانی
در این مقاله پیچیدگی زمانی اغلب پیادهسازیهای ساختمانهای داده جاوا را مورد بررسی قرار دادیم. همچنین عملکرد زمان اجرای واقعی هر نوع از کلکسیون را از طریق تستهای بنچمارک JVM نشان دادیم. ضمناً عملکرد عملیات یکسان را در کلکسیونهای مختلف بررسی کردیم. در نتیجه اینک میتوانیم برای رفع نیازهای خود بهترین کلکسیون مناسب را انتخاب کنیم. همه کدهای مربوط به این مقاله را میتوانید در این ریپوی گیتهاب (+) ملاحظه کنید.

اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای جاوا (Java)
- گنجینه آموزش های جاوا (Java)
- مجموعه آموزشهای برنامهنویسی
- زبان برنامه نویسی جاوا (Java) — از صفر تا صد
- ۱۰ مفهوم اصلی زبان جاوا که هر فرد مبتدی باید بداند
==










