


استخراج داده از اسناد Word با پایتون – از صفر تا صد


در این نوشته به بررسی جزییات استخراج داده و اطلاعات از اسناد ورد به صورت محلی میپردازیم. از آنجا که بسیاری از شرکتها و مدیران مختلف از مجموعه نرمافزارهای اداری مایکروسافت استفاده میکنند، مطالبی که در این نوشته ارائه شدهاند، برای هر فردی که با دادههای انتقالی در قالبهای doc. یا docx. مواجه میشود مفید خواهند بود. پیش نیاز مطالعه این نوشته نیز آن است که پایتون را روی سیستم خود نصب کرده باشید. اگر روی سیستم خود مجوزهای مدیریتی ندارید، میتوانید اقدم به نصب پایتون آناکوندا (Anaconda) روی سیستم عامل ویندوزی خود بکنید.


نتبوک مربوط به این نوشته را میتوانید در این آدرس (+) مشاهده کنید.
ما در این مطلب از مزیت ساختار XML هر سند ورد استفاده میکنیم. سپس از کتابخانه regex برای یافتن هر URL در متن سند و در نهایت افزودن URL ها به یک فهرست استفاده میکنیم که برای اجرای حلقههای for بسیار مطلوب است.
#specific to extracting information from word documents import os import zipfile #other tools useful in extracting the information from our document import re #to pretty print our xml: import xml.dom.minidom
- کتابخانه os (+) امکان ناوبری و یافتن فایلهای مرتبط روی سیستم عامل را فراهم میسازد.
- کتابخانه Zipfile (+) امکان استخراج xml از فایل رها را میدهد.
- کتابخانه xml.dom.minidom (+) برای تجزیه کد xml است.
ابتدا باید کد خود را طوری بنویسیم که فایلها را از مکانی که ذخیره شدهاند بخواند. برای انجام این کار به جای استفاده از ویندوز اکسپلورر از کتابخانه OS پایتون استفاده میکنیم. با این که اطلاع از مسیر دقیق یک فایل باعث میشود نیازی به کتابخانه os نداشته باشیم؛ اما این کتابخانه در ادامه برای ایجاد فهرستی از اسناد ذخیره شده در پوشه مقصد مورد استفاده قرار میگیرد. داشتن فهرستی از اسناد ذخیره شده در یک پوشه در مواردی که قرار است از یک حلقه for برای استخراج اطلاعات از همه اسناد ورد ذخیره شده در پوشه استفاده کنیم، مفید خواهد بود.
برای دیدن فهرستی از فایلها در دایرکتوری جاری از یک نقطه در مسیر فایل os استفاده میکنیم:
os.listdir('.')
برای دیدن فهرستی از فایلها در دایرکتوری بالاتر از مکان جاری باید از نقطههای دوگانه استفاده کنیم:
os.listdir('..')
زمانی که مشخص شد فایلها کجا ذخیره شدهاند، میتوانیم فایل پیدا شده در مسیر فایل را به یک نوع فایل zipfile.ZipFile تبدیل کنیم که مناسب مقاصد ما است.
فرمت فایل ZIP یک فرمت بایگانی رایج و یک استاندارد فشردهسازی است.
document = zipfile.ZipFile('../docs/TESU CBE 29 Employee Job Description Evaluation - Final Approved.docx')
#document will be the filetype zipfile.ZipFile
اینک متد ()read. در کلاس zipfile نیازمند آرگومان نام است که از نام فایل یا مسیر فایل متفاوت است.
ZipFile.read(name, pwd=None)
برای دیدن نامهای ممکن میتوان از شیء ()name. استفاده کرد:
document.namelist()

در نتبوک ژوپیتر مربوط به این مقاله چند مورد از این نامها بررسی شدهاند. نام دارای متن سند ورد به صورت «word/document.xml» است.

میتوان از خصوصیت pretty print برای کمک به شناسایی الگوها در XML برای استخراج دادهها استفاده کرد. از این خصوصیت میتوان استفاده کرد و الگوهای ساختاری هر URL را در متن سند ورد یافت. اگر از قبل با الگوی ساختاری استخراج دادههایتان آشنا هستید، ممکن است اصولاً نیازی به pretty print نداشته باشید.
در مثال فوق مشخص شد که کاراکترهای http> و < پیرامون هر لینک موجود در سند متنی وجود دارند.

به منظور اجرای هدف این مقاله که گردآوری لینکها است، باید هر آن چه که بین دو عبارت فوق قرار دارد را گردآوری کنیم. این کار به کمک کتابخانه regex صورت میگیرد. ما میل داریم که عبارت HTTP بماند؛ اما علامتهای < و > مطلوب ما نیستند. این تغییرات در آیتمهای لیست با استفاده از برش دادن رشتهها و «خلاصهسازی لیست» (List Comprehension) صورت میگیرند.
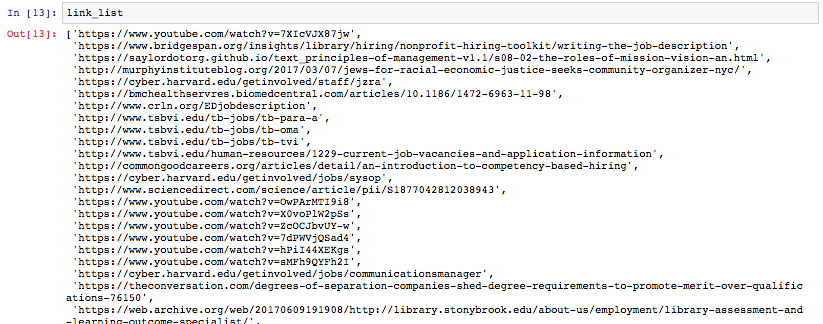
link_list = re.findall('http.*?\<',xml_str)[1:]
link_list = [x[:-1] for x in link_list]

برای دیدن نتبوک ژوپیتر این نوشته به این آدرس (+) مراجعه کنید. البته توجه داشته باشید که روشهای دیگری نیز مانند کتابخانههای ocx2txt و docx برای استخراج متن و اطلاعات از اسناد ورد وجود دارند، که با کمی تحقیق بیشتر میتوانید مشاهده کنید.
اگر این مطلب برایتان مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامه نویسی پایتون
- آموزشهای مجموعه نرمافزاری آفیس
- کتابخانه NumPy پایتون - راهنمای جامع
- زبان برنامه نویسی پایتون (Python) - از صفر تا صد
- پایتون و استخراج اطلاعات از گزارشها با RegEx Library
==









{kind=link}
{kind=link}
{kind=link}