



پایتون و مدلسازی زبان – راهنمای گامبهگام




«پیشبین کلمه بعدی» (Next Word Predictor)، که به آن «مدلسازی زبان» (Language Modeling) نیز گفته میشود، در واقع نرمافزاری است که پیشبینی میکند کلمه بعدی که کاربر تایپ خواهد کرد چیست. این کار یکی از وظایف پایهای در پردازش زبان طبیعی (NLP) است و کاربردهای بسیار زیادی دارد. این کاربردها حتی در زندگی روزمره نیز هنگام نوشتن پیام کوتاه یا ایمیل مورد استفاده قرار میگیرند.
Priya Dwivedi، دانشمند دادهای که مطالب خود را در وبسایت Toward Data Science منتشر میکند یک پیشبین کلمه بعدی با استفاده از کتابخانه پایتون «تنسورفلو» (Tensorflow) طراحی کرده است. در این مطلب چگونگی ساخت این پیشبین تشریح شده و با مطالعه آن مخاطبان میتوانند پیشبینهای اختصاصی خود را بسازند.
گام اول: دانلود دادهها و پیشپردازش
در ساخت این پیشبین، مجموعه داده text8 مورد استفاده قرار گرفته که بر اساس ویکیپدیای انگلیسی از ماه مارس سال ۲۰۰۶ ساخته شده است. این مجموعه داده بسیار بزرگ، ۱۶ میلیون کلمه را در بر میگیرد. بهمنظور ارزیابی و ساخت یک مدل پیشبینی کلمه، از یک زیر مجموعه تصادفی از دادهها با ۰.۵ میلیون کلمه استفاده شده است که ۲۶ هزار کلمه آن یکتا است. چنانکه در ادامه شرح داده خواهد شد، با افزایش تعداد کلمات یکتا، پیچیدگی مدل بیشتر میشود.

گام دوم: ساخت بردار واژه
در پردازش زبان طبیعی، یکی از وظایف اولیه، جایگزینی هر کلمه با بردار آن است که ارائه بهتری از معنای آن واژه را فراهم میکند. مدل ارائه شده در این مطلب، با استفاده از بردارهای Glove راهاندازی شده است که هر واژه را با یک بردار کلمه ۱۰۰ بُعدی جایگزین میسازد.
گام سوم: معماری مدل
برای ساخت این مدل، شبکه عصبی بازگشتی (Recurrent neural network - RNN) مورد استفاده قرار گرفته است. زیرا، هدف پیشبینی هر کلمه با نگاه کردن به کلماتی که پیش از آن استفاده شده به منظور حفظ یک وضعیت پنهان است که میتواند اطلاعات را از یک گام زمانی به دیگری منتقل کند.
نمودار زیر، ارائه بهتری از چگونگی عملکرد شبکه عصبی بازگشتی فراهم میکند.

شکل ۱: بصریسازی RNN از CS 224N
یک شبکه عصبی مصنوعی ساده، دارای ماتریسهای وزن WH و Embedding برای پنهانسازی ماتریسی است که در هر گام زمانی (time steps) به اشتراک گذاشته میشوند. هر وضعیت پنهان به صورت زیر محاسبه میشود.

و خروجی هر گام زمانی به صورت زیر وابسته به وضعیت پنهان است.

بنابراین، با استفاده از این معماری، شبکه عصبی بازگشتی به لحاظ «تئوری» قادر به استفاده از گذشته برای پیشبینی آینده خواهد بود. اگرچه، سادهترین نسخه این الگوریتم دارای مشکل حذف و انفجار شیب (vanishing and exploding gradients problem) است و بنابراین کمتر مورد استفاده قرار میگیرد. برای حل این مساله، در این مطلب از الگوریتم LSTM استفاده شده که از دروازهای برای بازگشت جریان گرادیانها در زمان و کاهش مشکل حذف آنها استفاده میکنند.
در اینجا، یک LSTM چند لایه با استفاده از تنسورفلو راهاندازی شده که دارای ۵۱۲ واحد در هر لایه و دو لایه LSTM است. ورودی LSTM، آخرین پنج کلمه استفاده شده توسط کاربر و هدف آن تشخیص کلمه بعدی است.
لایه نهایی در این مدل یک لایه softmax است که «درستنمایی» (likelihood) را برای هر کلمه پیشبینی میکند. همانطور که پیش از این نیز بیان شد، این مدل ۲۶ هزار واژه یکتا دارد، بنابراین این لایه یک طبقهبندی با ۲۶ هزار کلاس یکتا است. این بخش، دارای بالاترین هزینه محاسباتی در مدل و چالش اصلی در مدلسازی زبانی واژگان محسوب میشود.
آموزش مدل و خروجی
تابع هزینهای که در این مدل استفاده شده، sequence_loss و مدل برای ۱۲۰ دوره آموزش دیده است. هم هزینه آموزش و هم «سرگشتگی» (Perplexity) آن برای اندازهگیری پیشرفت آموزش مورد بررسی قرار گرفتند. سرگشتگی، یک متریک متداول است که برای سنجش کارایی یک مدل زبانی مورد استفاده قرار میگیرد. این متریک، در واقع احتمال معکوس یک مجموعه داده آزمون نرمال شده بهوسیله تعدادی از کلمات است. هرچه میزان سرگشتگی کمتر باشد، مدل نیز بهتر محسوب میشود. پس از آموزش دادن مدل ارائه شده برای ۱۲۰ دوره، مدل با سرگشتگی ۳۵ بهدست میآید.

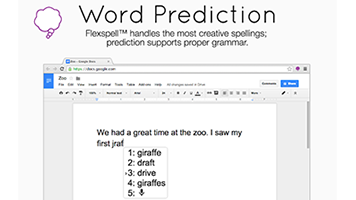
مدل روی چند پیشنهاد نمونه مورد آزمون قرار میگیرد. سه کلمه با احتمال بالاتر، خروجیهایی هستند که به کاربر نمایش داده میشوند تا از میان آنها انتخاب کند. چنانچه در تصویر زیر مشهود است، مدل با وجود آنکه تنها با ۲۶ هزار کلمه آموزش داده شده، به اندازه کافی خوب عمل میکند.

گامهای بعدی
- معماری مدل جایگزینی که بتواند روی حجم واژگان بیشتری کار کند قابل بررسی است. برخی از استراتژیهای قابل استفاده برای این کار در این مقاله آمدهاند.
- عمومیسازی بهتر مدل برای واژگان جدید یا کمیاب مانند اسامی غیر متداول. یکی از راهکارها، استفاده از مدل Pointer Sentinel Mixture است که جزئیات آن در این مقاله ارائه شده.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشود:
- فیلمهای آموزشی شبکههای عصبی مصنوعی در متلب
- شبکههای عصبی مصنوعی – از صفر تا صد
- آموزش یادگیری عمیق (Deep learning)
- آموزش برنامهنویسی یادگیری عمیق با پایتون (TensorFlow و Keras)
^^








بسیار خوب و کاربردی بود