شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
داده های سانسور شده (Censored Data) در آمار – به زبان ساده
۱۹۹۵
۱۴۰۲/۰۳/۲
۴ دقیقه
PDF
آموزش متنی جامع
امکان دانلود نسخه PDF
در آمار، مهندسی، اقتصاد و تحقیقات پزشکی، منظور از «سانسور کردن» (Censoring)، ثبت و اندازهگیری بخشی از اطلاعات مربوط به مشاهدات یا متغیرها است. برای مثال فرض کنید که قرار است اثر یک دارو روی نرخ مرگ و میر اندازهگیری شود. گفتنی است که این دارو به گروهی از افراد داده شده و میدانیم که یکی از آنها در سن ۷۵ سالگی از بررسیهای پزشکی انصراف داده است. اگر این فرد از دادههای آزمایشگاهی خارج شود اطلاعاتی که توسط او تولید شده، از بین میرود. از آنجایی که میدانیم که در هنگام خروج از آزمایش پزشکی ۷۵ ساله بوده، میتوان این اطلاع را کسب کرد که سن مرگ او با توجه به مصرف دارو بیشتر از ۷۵ سال است. استفاده از داده های سانسور شده و اطلاعات حاصل از آنها در استنباط آماری و یا برآورد پارامترهای مربوط به متوسط سن فوت برای این گونه افراد باعث افزایش دقت برآوردها خواهد شد. از داده های سانسور شده بیشتر برای بررسی طول عمر در مباحث «قابلیت اعتماد» (Reliability) استفاده میشود؛ این مباحث به بررسی زمان خرابی یا طول عمر قطعات و دستگاهها میپردازند.
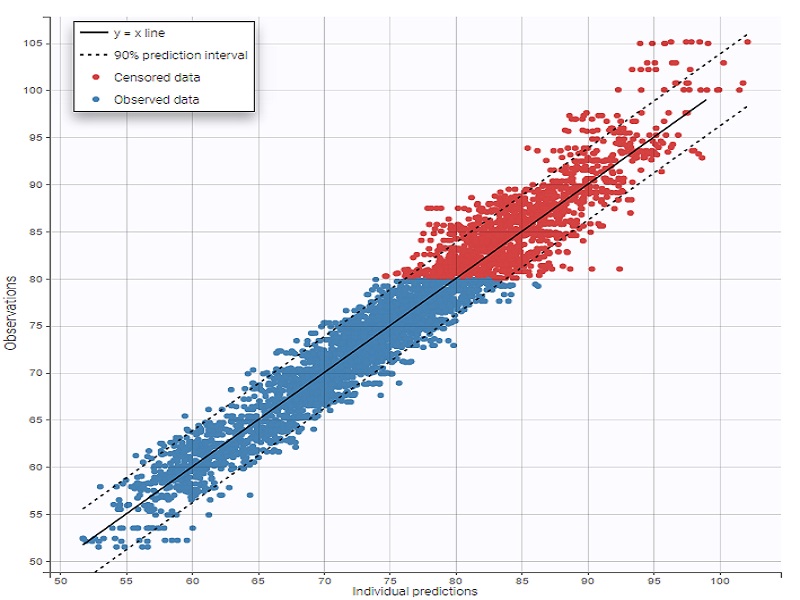
ممکن است مقدار اندازهگیری شده برای یک متغیر، خارج از محدوده قابل اندازهگیری برای آن باشد در نتیجه آن داده را سانسور میکنیم. چنین دادههایی را داده های سانسور شده مینامیم. برای مثال احتمال دارد یک ترازو برای اندازهگیری وزن به ۱۵۰ کیلوگرم محدود باشد. حال اگر فردی با وزن ۱۶۰ کیلوگرم در بررسی پزشکی وجود داشته باشد، امکان اندازهگیری وزن او وجود ندارد. با کنار گذاشتن این فرد اطلاعات مفیدی که ممکن است از او بدست آوریم را از بین بردهایم ولی داده سانسور شده به ما میگوید که وزن او از ۱۵۰ کیلوگرم بیشتر بوده.
در این جا باید تفاوت مهم بین دادههای ناموجود و یا «داده گمشده» (Missing Data) و «داده سانسور شده» (Censoring Data) را در نظر بگیریم. در دادههای گمشده، مقدار متغیر مشاهده نشده است و هیچ اطلاعاتی از حدود آن وجود ندارد در حالیکه در داده های سانسور شده که معمولا در طی زمان جمعآوری شده، ناموجود مقدار برای یک زمان به بعد، همراه اطلاعاتی است که محدوده یا کران پایین یا بالا برای مقداری سانسور شده را در خود دارد.
همچنین توجه داشته باشید که سانسور کردن به معنای «برش» (Truncation) دادهها نیست. زیرا برش دادن دادهها، عملی است که روی مقدارهای مشاهده شده به منظور محدود کردن آنها در یک فاصله صورت میپذیرد و اجازه ثبت مقدارهایی خارج از محدوده مورد نظر برای مشاهدات را نمیدهد. در حالیکه سانسور کردن به این معنی است که محقق اطلاع دارد که مقدار متغیر در یک محدوده یا فاصله قرار دارد و با توجه به این اطلاع مقداری را برای متغیر مورد نظر محدود میکند.
نکته: در بیشتر تحلیلهای مربوط به طول عمر، تابع توزیع متغیر تصادفی طول عمر را نمایی فرض میکنند.
انواع سانسور
با توجه به شیوه بررسی علمی و آماری، روشهای مختلفی برای سانسور کردن دادهها وجود دارد. توجه داشته باشید که اگر x متغیر طول عمر باشد، مجموعه مقادیر آن اعداد حقیقی مثبت هستند. در ادامه به معرفی بعضی از این روشها میپردازیم:
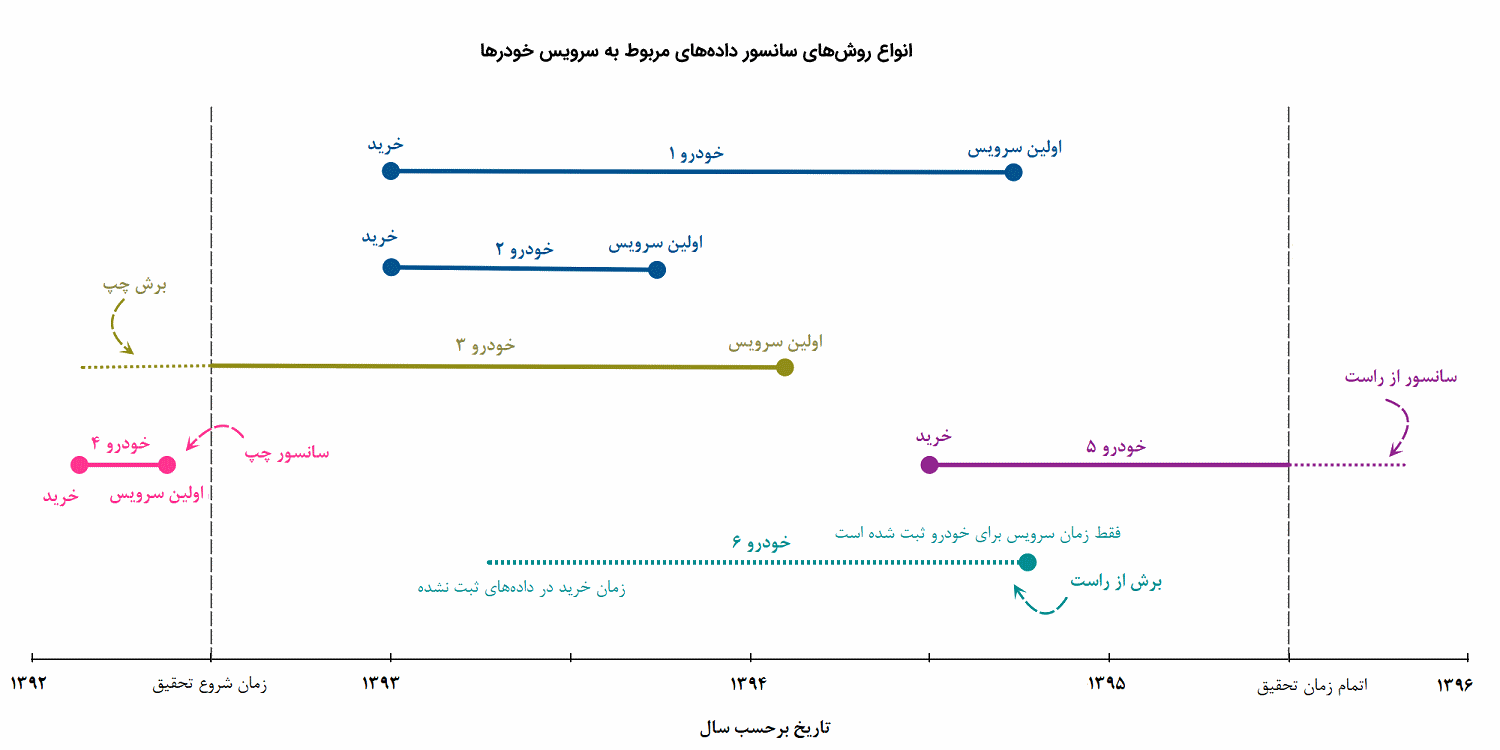
سانسور چپ: مقدار سانسور شده (x)، دارای کران بالا است. به این معنی که میدانیم از مثلا b کوچکتر است ولی مشخص نیست که اختلاف آن با b چقدر است (x).
سانسور راست: مقدار سانسور شده (x)، دارای کران پایین است. به این معنی که میدانیم از مثلا a بزرگتر است ولی مشخص نیست که اختلاف آن با a چقدر است (a).
سانسور دو طرفه: مقدار سانسور شده (x)، دارای کران پایین و بالا است. به این معنی که میدانیم از مثلا a بزرگتر و از b کوچکتر است ولی مشخص نیست که اختلاف آن با b یا a چقدر است (a≤x≤b).
دادههای سانسور شده از راست و چپ
سانسور نوع اول (Type I Censoring): فرض کنید در یک طرح تحقیقاتی باید چندین نمونه مورد بررسی و آزمایش قرار گیرند. ولی با توجه به اینکه بررسی این نمونهها زمانبر است، آزمایش را تا یک زمان مشخص متوقف کرده و از آن زمان به بعد بقیه نمونهها را از راست سانسور میکنیم.
سانسور نوع دوم (Type II Censoring): فرض کنید در یک طرح تحقیقاتی باید چندین نمونه مورد بررسی و آزمایش قرار گیرند. ولی با توجه به اینکه بررسی این نمونهها زمانبر است، آزمایش را تا زمانی که تعداد مشخصی از نتایج مورد نظر بدست آید ادامه میدهیم و بقیه نمونهها را از راست سانسور میکنیم.
سانسور تصادفی (Random, Non-informative Censoring): در این شیوه، زمان سانسور هر مشاهده مستقل از زمان معیوب شدن آن است.
همانطور که دیده میشود، سانسور چپ و راست حالت خاصی از سانسور دو طرفه هستند. سانسور چپ همان سانسور دو طرفه است اگر کران پایین را صفر در نظر بگیرم. همچنین سانسور راست نیز همان سانسور دو طرفه است اگر کران بالا را +∞ محسوب کنیم.
روشهای تحلیل و کاربردها
برای انجام تحلیل روی دادههای سانسور شده، روشهای خاصی وجود دارد. همینطور نرمافزارهای آماری زیادی که برمبنای قابلیت اعتماد و آنالیز بقا ایجاد شدهاند، امکان برآورد پارامترهای جامعه یا ایجاد فاصله اطمینان را میدهند. این کار برای دادههای سانسور شده به کمک تکنیک «حداکثر درستنمایی» (Maximum Likelihood) انجام میشود. یکی از قدیمیترین تحلیلها آماری روی دادههای سانسور شده، توسط «دانیل برنولی» (Daniel Bernoulli) در سال 1766 میلادی به منظور بررسی شیوع و میزان مرگ و میر بیماری آبله انجام گرفت. او با این کار میخواست میزان واگیری بیماری و اثربخشی واکسن آبله را نشان دهد.
همچنین در مباحت قابلیت اعتماد (Reliability)، معمولا آزمایشهایی صورت میگیرد تا در شرایطی مشخص زمان از بین رفتن یا وقوع خطا در یک مولفه (فوت فرد بیمار یا ایراد در قطعه صنعتی) اندازهگیری شود. گاهی در زمان تعیین شده برای انجام آزمایش، مولفه دچار شکست نمیشود. برای مثال ممکن است در طول یک روز راننده قطار هیچ خطایی نداشته باشد و یا دستگاه تولید منگنه در طول یک ساعت بدون تولید یک قطعه معیوب فعالیت کند. در چنین حالتهایی استفاده از دادههای سانسور شده یک ضرورت و اجبار است.
گاهی مهندسین برای تست خط تولید، آزمایشی را طراحی میکنند که مثلا بعد از گذشت یک زمان مشخص یا مشاهده تعداد خطاهای از قبل مشخص شده، آزمایش خاتمه یابد. در این حالت در زمان توقف آزمایش دادههای سانسور شده از راست ایجاد میشود. در بعضی از موارد ممکن است روی یک مولفه چندین بار آزمایش به صورت مکرر انجام گیرد. در این حالت چنین دادههایی هم شامل مقادیر مربوط به زمان شکست مولفههایی است که دچار خطا شدهاند و هم در برگیرنده مولفههایی است که در زمان اتمام آزمایش دچار خطا نشدهاند.
انجام آزمایشهای تکراری و دادههای سانسور شده
خلاصه
در این نوشتار با چند نوع روش سانسور و داده های سانسور شده آشنا شدیم و کاربردهای هر یک از آنها را فرا گرفتیم. همنطور که دیده شد، نوع سانسور در پیشبینی طول عمر بسیار موثر است. برای آگاهی بیشتر در زمینه انواع سانسورها و کاربردهای آنها میتوانید ویدئوی آموزش مقدماتی نظریه قابلیت اعتماد را مشاهده کنید.
اگر مطلب بالا برایتان مفید بوده است، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
«آرمان ریبد» دکتری آمار در شاخه آمار ریاضی دارد. از علاقمندیهای او، یادگیری ماشین، خوشهبندی و دادهکاوی است و در حال حاضر نوشتارهای مربوط به آمار و یادگیری ماشین را در مجله فرادرس تهیه میکند.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.





















سلام خسته نباشید
من طول عمر توزیع نمایی براساس داده های سانسور شده ی نوع ۱ رو میخواستم ؟