



تشخیص ناهنجاری در داده کاوی – با استفاده از زبان برنامهنویسی R
در مطلب «تشخیص ناهنجاری با استفاده از داده کاوی — بررسی موردی همراه با کدهای پایتون» به مفاهیم و روشهای تشخیص ناهنجاری پرداخته شد. همچنین، بررسی موردی جهت ساخت یک تشخیص دهنده ناهنجاری با استفاده از فیلتر پایین گذر و زبان برنامهنویسی پایتون انجام شد. در این قسمت، بحث تشخیص ناهنجاری با استفاده از زبان برنامهنویسی R مورد بررسی قرار خواهد گرفت.




از تشخیص ناهنجاری میتوان در زمینههای گوناگون مانند تشخیص نفوذ، تشخیص کلاهبرداری، سیستمهای سلامت و تشخیص گروهکها در شبکههای اجتماعی استفاده کرد. در زبان برنامهنویسی R به ناهنجاری، «دورافتادگی» نیز اطلاق میشود. در این زبان قابلیتهای متعددی برای تشخیص ناهنجاری وجود دارد که از آن جمله میتوان به موارد زیر اشاره کرد.
- آزمونهای آماری
- رویکردهای مبتنی بر عمق (Depth-based)
- رویکردهای مبتنی بر انحراف (Deviation-based)
- رویکردهای مبتنی بر فاصله (Distance-based)
- رویکردهای مبتنی بر چگالی (Density-based)
- رویکردهای ابعاد بالا (High-dimensional)
نمایش دورافتادگیها
زبان برنامهنویسی R دارای تابعی برای نمایش دورافتادگیها است. این تابع، «identify» نام داشته و در نمودار جعبهای (boxplot) قرار دارد. تابع boxplot، نمودار جعبهای یک مجموعه داده را همراه با خطوط (box-and-whisker) ترسیم میکند (نمودار زیر).
تابع identify روشی راحت و مناسب برای ایجاد نقاط در «نمودار نقطهای» (scatter plot) است. در زبان برنامهنویسی R، نمودار جعبهای نوعی از نمودار نقطهای محسوب میشود.

مثال 1
در این مثال، نیاز به ساخت ۱۰۰ عدد تصادفی و سپس ترسیم نقاط داده در جعبهها است. اولین نقطه ناهنجاری نیز به روش زیر کشف میشود.
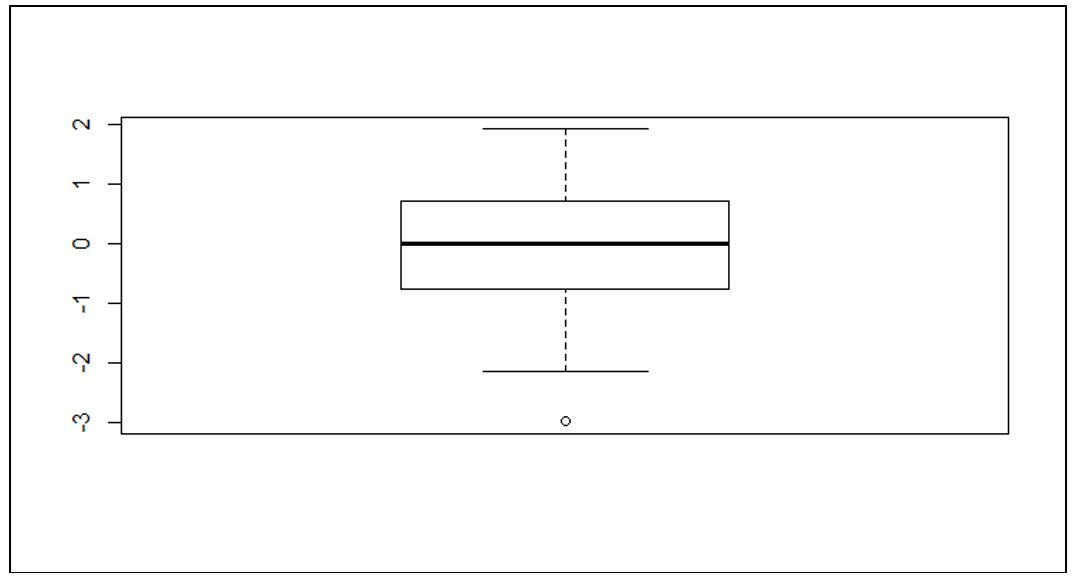

مثال 2
تابع boxplot ناهنجاریهای موجود در یک مجموعه داده را به طور خودکار محاسبه میکند. برای آزمودن این امر، ابتدا ۱۰۰ عدد تصادفی به شکل زیر ساخته میشود.
(توجه شود که این دادهها به طور تصادفی تولید میشود بنابراین افراد گوناگونی که در حال آزمایش راهکار ارائه شده هستند ممکن است نتایج متفاوتی دریافت کنند).
اکنون میتوان با استفاده از کد زیر، خلاصه اطلاعات مجموعه را مشاهده کرد.

اکنون میتوان ناهنجاریها را با استفاده از کد زیر نمایش داد.
[1] 2.420850 2.432033
کدی که در ادامه آمده، نمودار جعبهای مجموعه داده را رسم کرده و دورافتادگیها را برجسته میسازد.

میتوان نمودار جعبهای را برای مجموعه داده بیشتر شناخته شدهای ایجاد کرد و ناهنجاریهای موجود در آن را نمایش داد. این مجموعه داده مربوط به خودروها است.
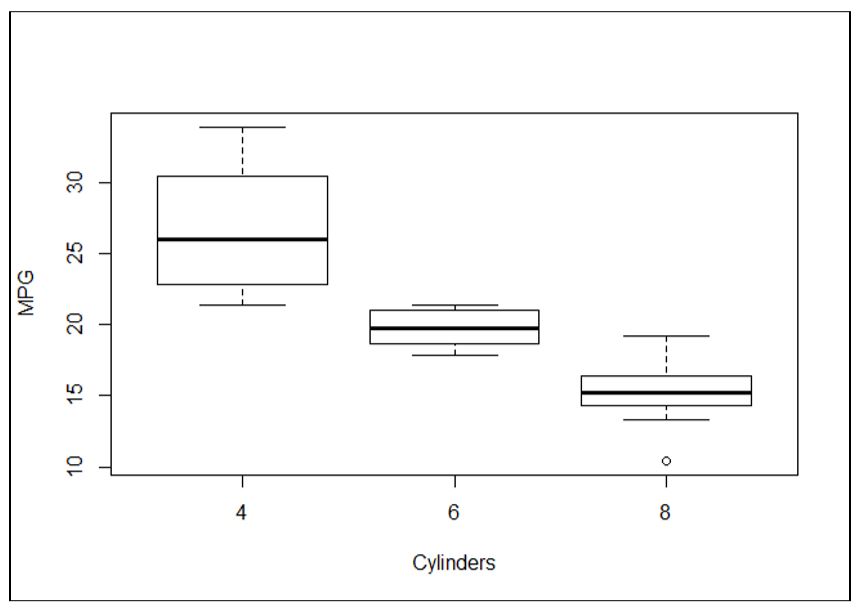

مثال ۳
همچنین میتوان از تشخیص ناهنجاری با استفاده از نمودار جعبهای برای مجموعههای دوبُعدی نیز استفاده کرد. لازم به ذکر است که مساله با استفاده از اتحاد ناهنجاریها در محورهای x و y و نه تقاطع آنها حل میشود.

نکته این مثال، چگونگی نمایش چنین نقاطی است. کد لازم برای انجام این کار در ادامه ارائه شده.
با وجود آنکه کد R ارائه شده در بالا، کار مورد نظر را انجام میدهد، اما به نظر میرسد نمودار صحیح نیست. دلیل این امر آن است که این مثال روی یک مجموعه داده واقعی پیادهسازی شده و بنابراین یک کارشناس دامنه باید تصمیم بگیرد که ناهنجاریها به درستی نمایش داده شدهاند یا خیر.

محاسبه ناهنجاریها
به دلیل وجود تنوع در دلایل ایجاد ناهنجاری، زبان برنامهنویسی R دارای مکانیزمی است که به کاربر کنترل کامل در این زمینه را میدهد. با استفاده از این مکانیزم میتوان تابعی نوشت که برای تصمیمسازی از آن استفاده کرد.
کاربرد
میتوان از تابع name برای کشف ناهنجاری به صورت زیر بهره برد.
پارامترهای موجود در این کد، مقادیری هستند که برای استفاده در تابع مورد نیاز است. خروجی این کد به صورت یک «دیتا فریم» (Data Frame) است.
مثال ۱
در این مثال از مجموعه داده معروف iris به صورت زیر استفاده شده است.
اگر تصمیمی مبنی بر این اتخاذ شود که یک نمونه داده هنگامی ناهنجار محسوب شود که اندازه کاسبرگ آن زیر ۴.۵ یا بالای ۷.۵ باشد، میتوان از تابعی مانند آنچه در زیر آمده استفاده کرد.
خروجی قطعه کد بالا، به صورت زیر خواهد بود.

این امر انعطاف لازم جهت ایجاد اصلاحات جزئی در معیارهای در نظر گرفته شده بهمنظور شناسایی ناهنجاری را با استفاده از مقادیر پارامتر متفاوت برای دستیابی به نتایج مورد انتظار میدهد.
نیاز به حذف ستون گونهها از دادههایی که پردازش روی آنها انجام میشود وجود دارد، زیرا این ستون بر خلاف دادههای آن که مقادیر عددی هستند، خود به صورت دستهای (Categorical) است.
اکنون میتوان دورافتادگیهای موجود در فریم را یافت.
scores <- lofactor(nospecies, k=3)
سپس، نگاهی به توزیع دادهها انداخته میشود.
نکته جالب توجه آن است که تقریبا نوعی برابری بین دادههای ناهنجار (چگالی ۴) وجود دارد.

اگر نوشته بالا برای شما مفید بود، آموزشهای زیر نیز به شما پیشنهاد میشوند:

- آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- آموزش تکمیلی برنامهنویسی R و نرمافزار RStudio
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیسی
^^







