



مروری بر تجزیه و تحلیل دادههای صوتی با استفاده از آموزش عمیق




کار با علم اطلاعات را از کارهای ساده شروع کنید. سراغ پروژههای ساده مانند مسأله پیشبینی وام (Loan Prediction problem) یا پیشبینی فروش بزرگ مارت (Big Mart Sales Prediction) بروید. این مسائل دارای دادههای منظم ساختار یافته به فرمت جدولی هستند. به عبارت دیگر، شما سختترین بخش کار علم اطلاعات را مانند هلوی پوست کنده در دست خواهید داشت. این در حالی است که مجموعه دادهها در دنیای واقعی بسیار پیچیدهتر است.
ابتدا شما باید این مطلب را درک کنید، شما باید دادهها را از منابع مختلف جمعآوری و آنها را به یک فرمت آماده برای پردازش طبقهبندی کنید. این امر زمانی که دادهها در یک فرمت بدون ساختار مانند یک تصویر یا صدا باشد، بسیار پیچیدهتر میشود. در واقع برای اینکه دادهها برای تجزیه و تحلیل آماده شوند، شما باید دادههای صوتی/تصویری را به صورت استاندارد نشان دهید.
فراوانی دادههای بدون ساختار
جالب است که دادههای بدون ساختار نشاندهنده تحت استثمار قرار گرفتن فرصتها است. این به چگونگی برقراری ارتباط و تعامل با انسانها، نزدیکتر است. همچنین حاوی اطلاعات مفید و قدرتمندی است. به عنوان مثال، اگر شخصی صحبت کند؛ شما نه تنها آنچه را که او میگوید، بلکه احساسات شخص را نیز از صدای او تشخیص میدهید.
همچنین زبان بدن فرد میتواند ویژگیهای زیاد دیگری را در مورد یک فرد نشان دهد، چرا که عمل بسیار مؤثرتر از کلمات است! بنابراین به طور خلاصه، دادههای بدون ساختار پیچیده هستند اما با پردازش به آسانی میتوانید پاداش آن را دریافت کنید.
در این مقاله قصد داریم یک مرور کلی روی پردازش صوتی / صدا داشته باشیم و برای داشتن یک مقدمه عملی برای حل مسائل پردازش صوت، یک مطالعه موردی را نیز ارائه میکنیم.
منظور از دادههای صوتی چیست؟
شما همیشه به طور مستقیم یا غیرمستقیم، با صدا در تماس هستید. مغز شما به طور مداوم در حال پردازش و درک اطلاعات صوتی و دادن اطلاعات در مورد محیط به شما است. یک مثال ساده میتواند مکالمات شما با افراد باشد که بهصورت روزانه انجام میدهید. این صحبت برای ادامه بحث توسط شخصی دیگر مورد بحث قرار میگیرد. شما حتی هنگامی که در یک محیط ساکت فکر میکنید، تمایل دارید صداهای بسیار ظریف مانند صدای خشخش برگها یا صدای بارش باران را دریافت كنید. این گسترهی ارتباط شما با صدا است.
و اینکه آیا شما میتوانید صداهای شناور اطراف خود را برای انجام کاری سودمند به نحوی دریافت کنید؟ بله البته! دستگاههایی برای کمک به گرفتن این صداها ساخته شدهاند و میتوان آنها را با فرمتی قابل خواندن در رایانه نمایش داد. نمونههایی از این فرمتها عبارتند از:
- WAV (Waveform Audio File) format
- MP3 (MPEG-1 Audio Layer 3) format
- WMA (Windows Media Audio) format
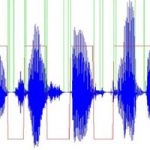
اگر شما به این فکر میکنید که صدا چه جوری به نظر میرسد، باید بدانید که چیزی نیست جز موجی شبیه فرمت داده که نوسان تغییر صدا با توجه به زمان است که میتواند به صورت تصویری زیر نمایش داده شود:

کاربردهای پردازش صوت
اگر چه ما گفتیم که دادههای صوتی میتوانند برای تجزیه و تحلیل مفید باشند اما کاربردهای بالقوه پردازش صوت چگونه میتواند باشد؟ در اینجا ما تعدادی از آنها را معرفی میکنیم:
- شاخصگذاری مجموعههای موسیقی با توجه به ویژگیهای صوتی آنها
- پیشنهاد موسیقی برای کانالهای رادیویی
- جستجویی مشابه برای فایلهای صوتی (ملقب به Shazam)
- پردازش و ترکیب گفتار - تولید صدای مصنوعی برای عوامل محاورهای
داده گردانی در دامنه صوتی
همانند تمام فرمتهای دادهای بدون ساختار، دادههای صوتی دارای دو مرحله پیش پردازش هستند که باید قبل از تجزیه و تحلیل پیگیری شوند. در اینجا ما بینش چرایی انجام آن را کسب خواهیم کرد.
گام نخست این است که دادهها را به طور عملی به فرمت قابل فهم برای ماشین بارگذاری کنیم. برای این، ما به سادگی مقادیر را بعد از هر گام زمانی خاص دریافت میکنیم؛ برای مثال در یک فایل صوتی 2 ثانیهای، مقادیر را در نیمثانیه استخراج میکنیم. این موضوع، نمونهبرداری از دادههای صوتی (sampling of audio data) نامیده میشود و نرخ آن، نرخ نمونهبرداری (sampling rate) نامیده میشود.
روش دیگری برای نمایش دادههای صوتی، تبدیل آن به یک نمایش متفاوت از دامنه دادهها، یعنی دامنه فرکانس (frequency domain) است. هنگامی که ما یک داده صوتی را به عنوان نمونه در نظر میگیریم، نیازمند نقاط دادهای بسیار زیادی برای نشان دادن کل دادهها هستیم و نرخ نمونهبرداری نیز باید تا حد ممکن زیاد باشد. از سوی دیگر، اگر ما اطلاعات صوتی را به صورت دامنه فرکانس نمایش دهیم، فضای محاسباتی بسیار کمتری مورد نیاز خواهد بود؛ برای درک بهتر، تصویر زیر را نگاه کنید:

در اینجا، ما یک سیگنال صوتی را به 3 سیگنال متفاوت خالص تفکیک میکنیم که اکنون میتوانند به عنوان سه مقدار منحصر به فرد در دامنه فرکانس نمایش داده شوند. البته چند راه دیگر برای نمایش دادههای صوتی، به عنوان مثال، با استفاده از MFCها (Mel-Frequency cepstrums) وجود دارد.
حال، گام بعدی این است که ویژگیهای این نمایشهای صوتی را استخراج کنیم تا الگوریتم ما بتواند بر روی این ویژگیها کار کند و کاری که برای آن منظور طراحی شده است را انجام دهد. در اینجا یک نمایش تصویری از دستهبندی ویژگیهای صوتی که میتوان آنها را استخراج کرد، آمده است.

پس از استخراج این ویژگیها برای تجزیه و تحلیل بیشتر به مدل یادگیری ماشین فرستاده میشوند.
بیایید چالش صداهای شهری را حل کنیم!
اجازه دهید ما یک مرور کلی عملی روی یک پروژه دنیای واقعی، با نام چالش صداهای شهری (Urban Sound challenge) داشته باشیم. این مسأله عملی با نیت آشنایی شما با پردازش صوتی در سناریوی طبقهبندی معمول ارائه میشود.
مجموعه داده حاوی 8732 صدای منتخب از صداهای شهری متعلق به 10 کلاس به صورت زیر است:
- تهویه هوا (air conditioner)
- بوق ماشین (car horn)
- بازی بچهها (children playing)
- پارس کردن سگ (dog bark)
- حفاری (drilling)
- ماشین درجا (engine idling)
- شلیک گلوله (gun shot)
- مته دستی مخصوص سوراخکردن سنگ (jackhammer)
- آژیر (siren)
- موسیقی خیابانی (street music)
این یک صدای منتخب از مجموعه دادهها است. برای پخش فایل در نوتبوک Jupyter، به سادگی میتوانید آن را در کد زیر دنبال کنید:
import IPython.display as ipd
ipd.Audio('../data/Train/2022.wav')
حالا اجازه دهید این صدا را در نوت بوک خود به عنوان آرایه numpy بارگذاری کنیم. برای این کار، از کتابخانه لیبروزا (librosa library) در پایتون (python) استفاده خواهیم کرد. برای نصب لیبروزا، تنها کافیست کد زیر را در خط فرمان تایپ کنید.
pip install librosaاکنون میتوانیم کد زیر را برای بارگیری دادهها اجرا کنیم.
data, sampling_rate = librosa.load('../data/Train/2022.wav')
وقتی دادهها را بارگذاری میکنید، به شما دو چیز میدهد: یک آرایه numpy از یک فایل صوتی و نرخ نمونهبرداری مربوطه که توسط آن استخراج میشود. اکنون برای نشان دادن آن به عنوان یک شکل موج (که در اصل همان است)، از کد زیر استفاده کنید.
% pylab inline import os import pandas as pd import librosa import glob plt.figure(figsize=(12, 4)) librosa.display.waveplot(data, sr=sampling_rate)
خروجی به شکل زیر است:

اکنون ما دادههایمان را به صورت بصری بررسی میکنیم تا ببینیم که آیا میتوان الگوهایی را در دادهها پیدا کرد.
Class: jackhammer

Class: drilling

Class: dog_barking

ما میتوانیم ببینیم که تشخیص تفاوت بین مته دستی و حفاری ممکن است دشوار باشد، اما تمایز بین پارس سگ و حفاری هنوز هم قابل تشخیص است. برای مشاهده بیشتر چنین مثالهایی، میتوانید از این کد استفاده کنید:
i = random.choice(train.index)
audio_name = train.ID[i]
path = os.path.join(data_dir, 'Train', str(audio_name) + '.wav')
print('Class: ', train.Class[i])
x, sr = librosa.load('../data/Train/' + str(train.ID[i]) + '.wav')
plt.figure(figsize=(12, 4))
librosa.display.waveplot(x, sr=sr)
انتراکت: اولین فرمان ما
ما در مسأله تشخیص سن ( Age detection problem)، برای دیدن توزیعهای کلاس و تنها پیشبینی کردن حداکثر رخداد تمام موارد آزمون در همان کلاس، روش مشابهی را به کار خواهیم برد. اجازه دهید توزیعهای این مسأله ببینیم:
train.Class.value_counts()
Out[10]: jackhammer 0.122907 engine_idling 0.114811 siren 0.111684 dog_bark 0.110396 air_conditioner 0.110396 children_playing 0.110396 street_music 0.110396 drilling 0.110396 car_horn 0.056302 gun_shot 0.042318
میبینیم که کلاس مته دستی مقدار بیشتری نسبت به سایر کلاسها دارد. بنابراین اجازه دهید اولین فرمان خود را با این ایده ایجاد کنیم:
test = pd.read_csv('../data/test.csv')
test['Class'] = 'jackhammer'
test.to_csv(‘sub01.csv’, index=False)
به نظر میرسد که این به عنوان یک معیار برای هر چالش ایده خوبی باشد، اما به نظر میرسد که برای این مسأله، کمی نادرست است. دلیل این امر این است که مجموعه دادهها خیلی نامتعادل نیستند.
ساختن مدلهای بهتر
حال اجازه دهید ببینیم چگونه میتوانیم مفاهیم آموخته شده در بالا را برای حل مسأله استفاده کنیم. ما مراحل زیر را برای حل مسأله دنبال خواهیم کرد:
مرحله 1: بارگذاری فایلهای صوتی
مرحله 2: استخراج ویژگیها از صدا
مرحله 3: تبدیل دادهها برای اینکه از مدل یادگیری عمیق ما عبور کنند
مرحله 4: اجرای یک مدل یادگیری عمیق و دریافت نتایج
در زیر کدی برای اجرای این مراحل آمده است:
بارگذاری فایلهای صوتی و استخراج ویژگیها
def parser(row):
# function to load files and extract features
file_name = os.path.join(os.path.abspath(data_dir), 'Train', str(row.ID) + '.wav')
# handle exception to check if there isn't a file which is corrupted
try:
# here kaiser_fast is a technique used for faster extraction
X, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
# we extract mfcc feature from data
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
except Exception as e:
print("Error encountered while parsing file: ", file)
return None, None
feature = mfccs
label = row.Class
return [feature, label]
temp = train.apply(parser, axis=1)
temp.columns = ['feature', 'label']
دادهها را برای ورود به مدل یادگیری عمیق تبدیل کنید.
from sklearn.preprocessing import LabelEncoder X = np.array(temp.feature.tolist()) y = np.array(temp.label.tolist()) lb = LabelEncoder() y = np_utils.to_categorical(lb.fit_transform(y))
اجرای یک مدل یادگیری عمیق و دریافت نتایج
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_labels = y.shape[1]
filter_size = 2
# build model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
اکنون اجازه دهید مدل خود را آموزش دهیم.
model.fit(X, y, batch_size=32, epochs=5, validation_data=(val_x, val_y))
این نتیجه گذراندن 5 دوره آموزشی می باشد:
Train on 5435 samples, validate on 1359 samples Epoch 1/10 5435/5435 [==============================] - 2s - loss: 12.0145 - acc: 0.1799 - val_loss: 8.3553 - val_acc: 0.2958 Epoch 2/10 5435/5435 [==============================] - 0s - loss: 7.6847 - acc: 0.2925 - val_loss: 2.1265 - val_acc: 0.5026 Epoch 3/10 5435/5435 [==============================] - 0s - loss: 2.5338 - acc: 0.3553 - val_loss: 1.7296 - val_acc: 0.5033 Epoch 4/10 5435/5435 [==============================] - 0s - loss: 1.8101 - acc: 0.4039 - val_loss: 1.4127 - val_acc: 0.6144 Epoch 5/10 5435/5435 [==============================] - 0s - loss: 1.5522 - acc: 0.4822 - val_loss: 1.2489 - val_acc: 0.6637
خوب به نظر میرسد، اما نمره میتواند به وضوح افزایش یابد.
گامهای بعدی برای اکتشاف
حال که ما یکی از کاربردهای ساده را دیدیم، قادر به تصور چند روش دیگر برای کمک به بهبود نمره هستیم.
- ما یک مدل شبکه عصبی ساده را برای مسأله به کار بردیم. گام ضروری بعدی ما شناخت نقاط شکست مدل و چرایی آن است. با این کار، ما میخواهیم درک خود را از شکستهای الگوریتم تفهیم کنیم تا زمانیکه یک مدل را ایجاد میکنیم، اشتباهات متفاوتی ایجاد نمیشود.
- ما میتوانیم مدلهای کارآمدتری که «مدلهای بهتر»نامیده می شود، مانند شبکههای عصبی کانولوشنی (convolutional neural networks) یا شبکههای عصبی بازگشنی (recurrent neural networks) ایجاد کنیم. ثابت شده است که این مدلها حل این مسائل را بسیار سادهتر میکنند.
- ما مفهوم تشدید اطلاعات (data augmentation) را لمس کردیم، اما ما آنها را در اینجا اعمال نکردیم. شما میتوانید آن را امتحان کنید تا ببینید که آیا برای مسأله کار میکند یا خیر.
در این مقاله، ما یک مرور کلی روی پردازش صوتی همراه با یک مطالعه موردی در مورد چالش صداهای شهری ارائه دادیم. همچنین مراحل اجرایی طرز برخورد با دادههای صوتی در پایتون با بسته لیبروزا را نشان دادیم. با دادن این مفاهیم ارزشمند به شما، امیدوارم بتوانید الگوریتمهای خود را برای چالش صداهای شهری امتحان کنید یا سعی کنید مسائل صوتی زندگی روزمره خود را حل کنید.
اگر تمایل به مطالعه بیشتر در این موضوع داشته باشید، شاید آموزش های زیر نیز برای شما مفید باشند:
- آموزش کاربردهای پردازش سیگنال های صدا و ارتعاشات
- آموزش پایهای پردازش صوت
- آموزش پردازش گفتار با متلب
**









بسیار مفید بود ممنونم ?