



پیش بینی آلودگی هوا با شبکه عصبی بازگشتی و پایتون – راهنمای کاربردی
در این مطلب، پیشبینی آلودگی هوا با بهرهگیری از «شبکه عصبی بازگشتی» (Recurrent Neural Network) انجام میشود. موضوع بحث، پیشبینی آلودگی هوا در بلژیک و به طور مشخصتر، آلودگی هوای ایجاد شده بر اثر «گوگرد دیاکسید» (SO2) است. دادههای مورد استفاده در این مطلب از این لینک قابل دانلود هستند.




فایل زیپ، شامل فایلهای مجزا برای سطوح گوناگون آلودگی و تراکم هوا میشود. اولین رقم، شماره شناسه آلودگی به شکلی که در «واژگان» (vocabulary) (+) تعریف شده را نشان میدهد. فایل مورد استفاده در این راهنما «BE_1_2013–2015_aggregated_timeseries.csv» است. این فایل مربوط به آلودگی SO2 در بلژیک است، اما امکان یافتن دادههای مشابه برای دیگر کشورهای اروپایی نیز وجود دارد. توضیحات فیلدهای موجود در فایل CSV در صفحه اصلی انتشار دادهها (+) موجود است.
راهاندازی پروژه
بارگذاری دادهها
کاوش در دادهها
در ادامه از pandas_profiling برای وارسی دادهها استفاده میشود.
خروجی این کد به منظور اجتناب از پر شدن مطلب با جداول در اینجا آورده نشده، ولیکن علاقمندان میتوانند با انجام مراحل گام به گام بیان شده، کد را در سیستم خود اجرا و خروجی آن را دریافت کنند. pandas_profiling اطلاعات زیر را در اختیار قرار میدهد.
- شش متغیر ثابت وجود دارد. میتوان آنها را از مجموعه داده حذف کرد.
- هیچ مقدار «ناموجودی» (missing values) وجود ندارد، بنابراین نیازی به اعمال «جانهی» (Imputation) نیست.
- AirPollutionLevel دارای چندین صفر است، اما این موضوع میتواند کاملا طیبعی باشد. از سوی دیگر، این متغیرها دارای مقادیر ویژهای هستند که ممکن است ناشی از ثبت غلط اطلاعات آلودگی هوا باشد.
- ۵۳ مورد AirQualityStations وجود دارد که احتمالا مشابه با SamplingPoints هستند. AirQualityStationEoICode به سادگی کد کوتاهتری برای AirQualityStation است، بنابراین متغیرها قابل حذف هستند.
- سه مقدار برای AirQualityNetwork وجود دارد («والونی» (Wallonia)، «فلاندرز» (Flanders)، «بروسل» (Brussels)). بسیاری از سنجهها از فلاندرز میآیند.
- DataAggregationProcess: اغلب سطرها دارای دادههایی هستند که به عنوان میانگین متعلق به ۲۴ ساعت از یک شبانهروز (P1D) محسوب میشوند. در پروژه تعریف شده برای این مطلب، تنها از مقدار P1D استفاده خواهد شد.
- DataCapture: تناسب زمان سنجههای معتبر مربوط به کل زمان اندازهگیری شده (پوشش زمانی) در دوره میانگین، به عنوان درصد بیان شده است. تقریبا همه سطرها دارای حدود ٪۱۰۰ زمان اندازهگیری معتبر هستند. برخی از سطرها یک DataCapture دارند که اندکی کمتر از ٪۱۰۰ است.
- DataCoverage: تناسب سنجههای معتبر در فر آیند تجمیع در دوره میانگین به صورت درصد بیان شده است. در این مجموعه داده، دارای حداقل ٪۷۵ است. مطابق با تعریف این متغیر، مقادیر زیر ٪۷۵ نباید در ارزیابی کیفیت هوا در نظر گرفته شوند و این موضوع، چرایی اینکه این سطرها در مجموعه داده نشان داده نشدهاند را تشریح میکند.
- TimeCoverage: به شدت همبسته با DataCoverage است و از دادهها حذف خواهد شد.
- UnitOfAirPollutionLevel: تعداد ۴۲۳ سطر دارای یک واحد از count هستند. برای داشتن یک متغیر هدف ثابت رکوردها با این نوع واحد حذف خواهند شد.
- DateTimeBegin و DateTimeEnd: هیستوگرام جزئیات کافی را در اینجا فراهم نمیکند و این مورد نیازمند تحلیلهای بیشتری است.
DateTimeBegin و DateTimeEnd
هیستوگرام در pandas_profiling روزهای گوناگون را به ازای هر bin ترکیب کرده است. اکنون بررسی میشود که این متغیرها در سطح روزانه چگونه عمل میکنند.
چندین سطح تجمیع به ازای تاریخ
- DatetimeBegin: تعداد زیادی از رکوردها در اول ژانویه ۲۰۱۳، ۲۰۱۴، ۲۰۱۵ و اول اکتبر ۲۰۱۳ و ۲۰۱۴
- DatetimeEnd: تعداد زیادی از رکوردها در اول ژانویه ۲۰۱۴، ۲۰۱۵، ۲۰۱۶ و اول آپریل ۲۰۱۴ و ۲۰۱۵
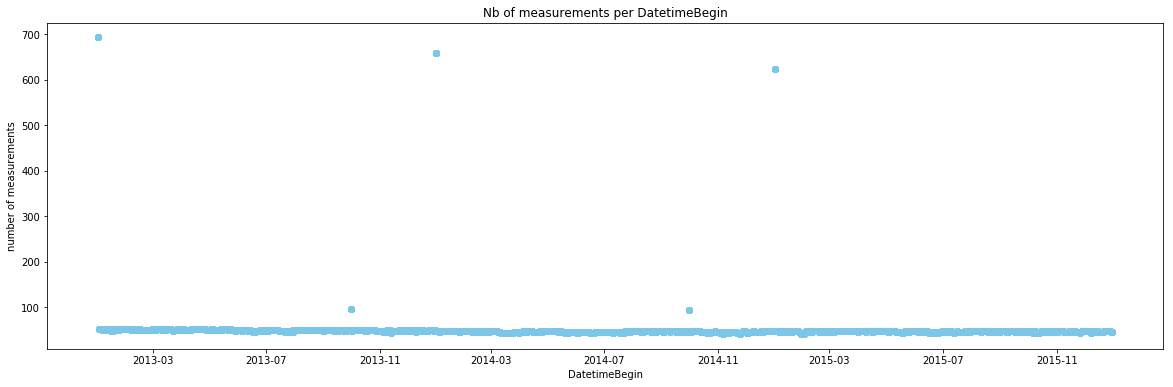
«دورافتادگیها» (outliers) در تعداد رکوردها مربوط به سطوح تجمیع چندگانه (DataAggregationProcess) هستند. مقادیر در DataAggregationProcess در این تاریخها بازه زمانی بین DatetimeBegin و DatetimeEnd را نشان میدهند. برای مثال، اول ژانویه ۲۰۱۳ تاریخ شروع دوره اندازهگیری یکساله است و تا تاریخ اول ژانویه ۲۰۱۴ ادامه دارد. از آنجا که در اینجا سطح تجمیع روزانه جالب توجه به حساب میآید، فیلتر کردن دیگر سطوح تجمیع فیلتر، این مساله را حل میکند. همچنین، میتوان DatetimeEnd را به همان دلیل حذف کرد.
گامهای زمانی ناموجود در سطح تجمیع روزانه
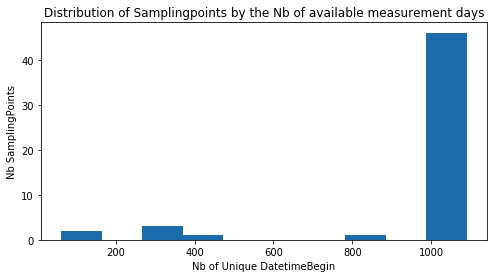
همانطور که در زیر مشهود است، همه SamplingPoints دارای داده برای DatetimeBegin در یک برهه سه ساله نیستند. این روزها بیشترین احتمال را دارند که در آنها متغیر DataCoverage زیر ٪۷۵ باشد. بنابراین، در این روزها هیچ اندازهگیری مناسب معتبری وجود ندارد.

در ادامه این مطلب، از سنجههای روزهای پیشین برای پیشبینی آلودگی در روز فعلی استفاده میشود. برای داشتن گامهای زمانی با اندازههای مشابه، نیاز به درج سطرهایی برای DatetimeBegin در هر SamplingPoint است. دادههای اندازهگیریهای روز بعد با دادههای معتبر درج میشوند. همچنین، SamplingPoints دارای تعداد زیادی گام زمانی ناموجود حذف میشوند. اکنون، تعداد دلخواهی گام زمانی - که در اینجا ۱۰۰۰ تا انتخاب شده - به عنوان حداقل گامهای زمانی مورد نیاز دریافت میشوند.

آمادهسازی دادهها
در ادامه فرآیند آمادهسازی دادهها مورد بررسی قرار میگیرد.
پاکسازی دادهها
بر پایه کاوش انجام شده روی دادهها، اقدامات زیر برای پاکسازی دادهها انجام میشود.
- تنها حفظ رکوردهای DataAggregationProcess با P1D
- حذف رکوردهایی با UnitOfAirPollutionLevel برابر با count
- حذف متغیرهای یگانی و دیگر متغیرهای دارای افزونگی
- حذف SamplingPoints که دارای کمتر از ۱۰۰۰ روز اندازهگیری است.
قرار دادن سطرها برای گامهای زمانی ناموجود
برای هر SamplingPoint، در ابتدا یک سطر (خالی) برای مواردی که DatetimeBegin وجود ندارد، درج میشود. این امر میتواند با ساخت یک multi-index کامل با همه SamplingPoints و بیش از محدوده بین کمینه و بیشینه DatetimeBegin انجام شود. سپس، reindex سطرهای ناموجود را با NaN برای سطرها درج میکند.
همچنین، از bfill استفاده و مقادیر ناموجود سطر بعد با دادههای معتبر جایگذاری میشود. روش bfill روی یک شی groupby به منظور محدود کردن کار پر کردن مجدد سطرهایی از هر SamplingPoint اعمال میشود. بدین شکل از مقادیر یک SamplingPoint برای پر کردن مقادیر ناموجود استفاده نمیشود. یک samplepoint برای تست اینکه این عملیات به درستی عمل کرده یا خیر، به صورت SPO-BETR223_00001_100 برای 2013–01–29 است.
مدیریت چندین سری زمانی
اکنون، مجموعه داده پاکسازی شده و فاقد هرگونه مقدار از دست رفته موجود است. یک جنبه که این مجموعه دادهها را خاص میسازد آن است که داده برای چندین «نقطه نمونه» (samplingpoints) موجود است. بنابراین، چندین سری زمانی وجود دارد.

یک راه برای کار با این مجموعه داده، ساخت متغیرهای مجازی برای کار با samplingpointها و استفاده از همه رکوردها برای آموزش دادن مدل است. راهکار دیگر، ساخت مدلی جداگانه به ازای هر samplingpoint است. در این راهنما این کار بعدا انجام میشود. اگرچه، در اینجا کار محدود به انجام این مورد تنها برای یک samplingpoint میشود. اما، منطق مشابهی نیز قابل اعمال بر هر samplingpoint است.
جداسازی مجموعههای «آموزش» (train)، «آزمون» (test) و «اعتبارسنجی» (validation)
در ادامه، مجموعه داده آزمون (Test) به منظور ارزیابی «کارایی» (Performance) مدل جداسازی میشود. مجموعه داده آزمون (تست) در طول فاز «آموزش» (Training) مورد استفاده قرار نمیگیرد.
- مجموعه آموزش: دادهها تا تاریخ جولای ۲۰۱۴
- مجموعه اعتبارسنجی: ۶ ماه بین جولای ۲۰۱۴ و ژانویه ۲۰۱۵
- مجموعه تست: دادههای ۲۰۱۵
مقیاسدهی
ذخیرهسازی مجموعه داده پالایش شده
با ذخیرهسازی مجموعه داده پردازش شده، نیازی به انجام مجدد «پیشپردازش» (Preprocessing) در هر بار اجرای مجدد نوتبوک نیست.
مدلسازی با شبکه عصبی بازگشتی
ابتدا، مجموعه دادههای پالایش شده خوانده میشوند. سپس، تابعی برای ترسیم نمودار هزینه آموزش و اعتبارسنجی مدلهای گوناگونی که ساخته خواهند شد، ایجاد میشود.
آمادهسازی دادهها با TimeseriesGenerator
- TimeseriesGenerator در کتابخانه «کِرَس» (TimeseriesGenerator) در ساخت دادهها به فرمت صحیح برای مدلسازی کمک میکند.
- length: تعداد گامهای زمانی در دنباله تولید شده به حساب میآید. در اینجا یک عدد دلخواه از n_lag گام زمانی مورد استفاده قرار میگیرد. در حقیقت، n_lag وابسته به این است که پیشبینیها چگونه مورد استفاده قرار میگیرند. حالتی مفروض است که دولت بلژیک میتواند اقدامات خاصی را برای کاهش آلودگی SO2 حول محور یک samplingpoint انجام دهد (برای مثال، ممنوعیت ورود خودروهای دیزلی در شهر برای مدت زمان مشخصی). همچنین، فرض شود که دولت به ۱۴ روز زمان پیش از انجام اقدامات اصلاحی برای موثر واقع شدن نیاز دارد. بنابراین، در این شرایط قرار دادن n_lag برابر با ۱۴ میتواند اقدامی به جا باشد.
- sampling_rate: تعداد گامهای زمانی بین گامهای زمانی پی در پی در دنباله تولید شده است. در اینجا قصد حفظ کردن همه گامهای زمانی وجود دارد، بنابراین مقدار آن روی مقدار پیشفرض ۱ قرار میگیرد.
- stride: این پارامتر میزان همپوشانی توالیهای تولید شده را تحت تاثیر قرار میدهد. از آنجا که دادههای زیادی وجود ندارد، مقدار آن روی میزان پیشفرض ۱ قرار میگیرد. این یعنی دو توالی که یکی پس از دیگری تولید شده با همه گامهای زمانی به جز یکی همپوشانی دارند.
- batch_size: تعداد توالیهای تولید شده در هر دسته است.
شبکههای عصبی بازگشتی
شبکههای عصبی سنتی فاقد حافظه هستند. در نتیجه، ورودی قبلی را هنگام پردازش ورودی کنونی به حساب نمیآورند. در مجموعه دادههای متوالی، مانند سریهای زمانی، اطلاعات گام زمانی پیشین معمولا به پیشبینی چیزی در گام کنونی مربوط است. بنابراین، «حالت» (State) پیرامون گام زمانی پیشین باید نگهداری شود.
در این مثال، آلودگی هوا در زمان ممکن است تحت تاثیر آلودگی هوا در گامهای زمانی پیشین قرار بگیرد. بنابراین نیاز به در نظر گرفتن آن است. «شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN) دارای یک حلقه داخلی هستند که با بهرهگیری از آن وضعیت گامهای زمانی پیشین را نگهداری میکنند. وضعیت هنگامی که یک دنباله جدید مورد پردازش قرار گرفت، بازنشانی میشود.
در مثال مطرح شده در این مطلب، از SimpleRNN در کتابخانه کرس استفاده شده است. همچنین، یک فراخوانی مجدد EarlyStopping برای متوقف کردن آموزش هنگامی که ۱۰ دوره بدون هرگونه بهبودی در هزینه اعتبارسنجی وجود دارد تعیین میشود. ModelCheckpoint این امکان را فراهم میکند تا وزنهای بهترین مدلها ذخیرهسازی شوند. همچنان نیاز است که معماری مدل به طور جداگانهای حفظ شود.

حافظه طولانی کوتاه مدت
یک شبکه عصبی بازگشتی (RNN) دارای حافظه کوتاه مدت است. بنابراین در به خاطر آوری اطلاعات چند گام قبل با مشکل مواجه میشود. این اتفاق زمانی به وقوع میپیوندد که دنبالهها خیلی طولانی هستند. در حقیقت، این موضوع به دلیل «مساله حذف گرادیان» (Vanishing gradient problem) به وقوع میپیوندد. گرادیان مقادیری هستند که وزنهای یک شبکه عصبی را به روز رسانی میکنند.

هنگامی که گامهای زمانی زیادی در RNN وجود دارد، گرادیان برای اولین لایه بسیار کوچک خواهد شد. در نتیجه، به روز رسانی وزنهای اولین لایه ناچیز است. این یعنی RNN قادر به یادگیری آنچه در لایههای اولیه بوده نیست. بنابراین، نیاز به راهکاری برای حفظ اطلاعات اولین لایهها به لایههای بعدی است. LSTMها برای در نظر گرفتن وابستگیهای بلند مدت گزینههای مناسبتری هستند.
یک مدل LSTM ساده

مدل Stacked LSTM
در این مدل، چندین لایه LSTM انباشته میشوند. بدین شکل، مدل دیگر انتزاعات از دادههای ورودی را در طول زمان فرا میگیرد. به عبارت دیگر، دادههای ورودی در مقیاسهای زمانی دیگر ارائه میشوند.
برای انجام این کار در کِرَس، نیاز به تعیین پارامتر return_sequences در لایه LSTM پیش از لایه LSTM دیگر است.

ارزیابی کارایی
بر اساس حداقل هزینههای اعتبارسنجی، به نظر میرسد SimpleRNN عملکردی بهتر از مدل STM دارد، اگرچه سنجهها به یکدیگر نزدیک هستند. با متد evaluate_generator میتوان مدل را روی دادههای تست (تولید کننده) ارزیابی کرد.
ابتدا، معماری مدل از فایلهای JSON و بهترین وزنهای مدل بارگذاری میشود.
- هزینه روی دادههای تست برای simple_rnn برابر است با: 0.01638169982337905
- هزینه روی دادههای تست برای simple_lstm برابر است با: 0.015934137431135205
- هزینه روی دادههای تست برای stacked_lstm برابر است با: 0.015420083056716116
نتیجهگیری
در این مطلب، از شبکههای عصبی بازگشتی و دو معماری متفاوت برای LSTM استفاده شد. بهترین کارایی از stacked LSTM دارای تعداد کمی لایه پنهان حاصل شده است.

قطعا جزئیاتی وجود دارد که ارزش پژوهشهای بیشتر را دارند و انجام آنها میتواند کارایی مدل را بهبود ببخشد، برخی از این موارد در ادامه بیان شدهاند.
- استفاده از دادههای ساعتی (فایل CSV دیگری در وبسایت EEA وجود دارد) و آزمودن دیگر استراتژیهای نمونهگیری به جز دادههای روزانه
- استفاده از دادههایی پیرامون دیگر آلایندهها به عنوان ویژگیهایی برای پیشبینی آلودگی SO۲. شاید در این راستا بتوان از دیگر آلایندههای مرتبط با SO۲ نیز استفاده کرد.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای برنامه نویسی پایتون (Python)
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^








این سطر اشتباه است
valid_data_gen = TimeseriesGenerator(train, train, length=n_lag, sampling_rate=1, stride=1, batch_size = 1)
جای valid کلمه train نوشتی
با سلام و وقت بخیر خدمت شما همراه گرامی؛
نکتهای که اشاره کردید درست است. اگر بخواهیم مجموعهای جدا برای اعتبارسنجی داشته باشیم، باید از دادههایی متفاوت در TimeseriesGenerator دوم استفاده کنیم.
با توجه به نکته شما، خطای موجود در مطلب اصلاح شد.
با آرزوی موفقیت برای شما و سپاس از همراهیتان با مجله فرادرس
سلام و خسته نباشید.فایل پیوست باز نمیشه
سلام، وقت شما بخیر؛
تشکر از بابت گزارش این موضوع، آدرس فایل پیوست بازبینی و اصلاح شده است.
از اینکه با مجله فرادرس همراه هستید از شما سپاسگزاریم.
با سلام! آیا این کدها کامپیال و اجرا شده اند یا فقط ترجمه متن و کپی از سایت اصلی هستند؟
سلام ببخشید لینکی که برای دانلود داده ها قرار دادید باز نمیشه لطفا بررسی کنید ممنون
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزارم. لینک فایل اصلاح شد و در حال حاضر، امکان دانلود فراهم شده است.
سپاسگزارم.
بسیار مفید و آموزنده.
نامدار باشید