



حمله تخاصمی (Adversarial Attack) با مدل FGSM در پایتون – راهنمای کاربردی
بسیاری از افرادی که در حوزه «یادگیری ماشین» (Machine Learning | ML) فعالیت و پژوهش میکنند به خوبی آگاه هستند که برخی از مدلهای یادگیری ماشین چقدر عملکرد تاثیرگذاری دارند. پژوهشهایی که در این حوزه انجام میشود موجب شده تا مدلها سریعتر، صحیحتر و موثرتر از قبل بشوند. اگرچه، جنبهای از طراحی و آموزش مدل که اغلب نادیده گرفته میشود امنیت و استحکام مدل است. این موضوع به طور خاص هنگامی اهمیت پیدا میکند که یک متخاصم سعی در گول زدن مدل داشته باشد. این مساله ممکن است بسیاری از افراد را حیرت زده کند که اضافه کردن برخی اختلالات (آشفتگیهای) نامحسوس در تصاویر، میتواند کارایی مدل را به شدت متفاوت کند. با در نظر گرفتن این موضوع، در این راهنما مثالی پیرامون یک دستهبند متنی ارائه خواهد شد. در این مطلب، به طور خاص از یکی از اولین و متداولترین نوع حملات با عنوان «حمله علامت گرادیان سریع» (Fast Gradient Sign Attack | FCSA) برای گول زدن یک «دستهبند» (Classifier) از نوع MNIST استفاده خواهد شد. با مطالعه این راهنما و کسب شناخت از حمله تخاصمی (Adversarial Attack) با مدل FGSM در پایتون، آگاهی مخاطبان پیرامون آسیبپذیریهای امنیتی مدلهای یادگیری ماشین افزایش پیدا میکند و بینشی پیرامون یادگیری ماشین تخاصمی به دست میآورند.




مدل مخرب
دستههای گوناگونی از حملات تخاصمی وجود دارند. هر یک از این حملات دارای هدف و فرضی متفاوت بر اساس دانش مهاجم هستند. اگرچه، به طور کلی هدف کلاهبرداری اضافه کردن مقداری انحراف (آشفتگی) به دادههای ورودی به منظور انجام دستهبندی غلط توسط مدل روی آنها است. چندین نوع از فرضیات از دانش مهاجم پیرامون مدل وجود دارد که دو مورد از آنها «جعبه سفید» (white-box) و «جعبه سیاه» (black-box) هستند. یک حمله جعبه سفید فرض میکند که مهاجم دارای دانش و دسترسی کامل به مدل شامل معماری، ورودیها، خروجیها و وزنهای آن است.
در یک حمله جعبه سیاه، فرض بر این است که حمله کننده تنها دارای دسترسی به ورودیها و خروجیهای مدل است و هیچ چیز درباره معماری یا وزنهای مدل نمیداند. همچنین، انواع گوناگونی از اهداف نیز وجود دارد که از این جمله میتوان به دستهبندی غلط و دستهبندی غلط منبع/هدف اشاره کرد. در دستهبندی غلط هدف متخاصم فقط این است که دستهبندی خروجی غلط باشد، اما اهمیتی نمیدهد که دستهبندی جدید چیست. دستهبندی منبع/هدف، بدین معنا است که متخاصم میخواهد یک تصویر که در اصل از یک کلاس منبع خاص است را در یک کلاس هدف خاص (اشتباه) دستهبندی کند. در مثال ارائه شده در این مطلب، حمله FGSM که یک حمله جعبه سفید است و هدف دستهبندی غلط انجام میشود، پیادهسازی شده است. با این اطلاعات پیشزمینهای، اکنون میتوان پیرامون جزئیات حمله بحث کرد.
حمله علامت گرادیان سریع
یکی از محبوبترین نوع حملات تخاصمی تا به امروز «Fast Gradient Sign Attack | FGSM» است و توسط «ایان گودفِلو» (Ian Goodfellow) و همکاران در مقالهای با عنوان «تشریح و بهرهبرداری از مثالهای تخاصمی» (Explaining and Harnessing Adversarial Examples) ارائه شده است. این حمله به طور قابل توجهی قدرتمند و نوآورانه است. FGSM برای حمله به شبکههای عصبی با نفوذ به روش یادگیری آنها یعنی «گرادیان» (Gradients) طراحی شده است.
ایده این کار ساده است و به جای کار برای کمینه کردن «زیان» (Loss) با تنظیم وزنها بر پایه «گرادیان بازگشت به عقب» (backpropagated gradients)، حمله دادههای ورودی را با هدف بیشینهسازی زیان برپایه بازگشت به عقب مشابهی تنظیم میکند. به عبارت دیگر، حمله از گرادیان زیان w.r.t داده ورودی استفاده و سپس داده ورودی را برای بیشینه کردن زیان تنظیم میکند. پیش از آنکه کد لازم برای این کار ارائه شود، نگاهی به مثال معروف پاندا FGSM انداخته و نکاتی پیرامون آن بیان میشود.

با توجه به تصویر بالا، x تصویر ورودی اصلی است که به درستی به عنوان «Panda» شناسایی میشود، y برچسب حقیقت زمینهای برای x محسوب میشود و θ پارامترهای مدل را نشان میدهد. (J(θ,x,y هزینهای است که برای آموزش دادن شبکه مورد استفاده قرار میگیرد. حمله به منظور محاسبه (xJ(θ,x,y∇، گرادیان را بازگشت به عقب به دادههای ورودی میدهد. سپس، دادههای ورودی را با یک گام کوچک (ϵ یا 0.007 در تصویر) در جهتی که ((sign(∇xJ(θ,x,y) زیان را بیشینه میسازد تنظیم میکند. تصویر آaفته حاصل شده ′x است که توسط شبکه هدف به اشتباه به عنوان «میمون دراز دست» (gibbon) دستهبندی شده، در حالی که میتوان به وضوح دید که یک پاندا است. خوشبختانه اکنون دیگر مفاهیم نهفته در پس این راهنما واضح است، بنابراین میتوان مستقیم به سراغ پیادهسازی رفت.
پیادهسازی حمله تخاصمی (Adversarial Attack) با مدل FGSM
در این بخش، به پارامترهای ورودی پرداخته خواهد شد و سپس حمله با پایتون پیادهسازی و آزمونهایی اجرا میشود.
ورودیها
تنها سه ورودی برای این روش وجود دارد که به صورت زیر تعریف شدهاند:
اپسیلونها (epsilons): لیست مقادیر اپسیلون برای استفاده در اجرا است. اهمیت دارد که ۰ را در لیست نگاه داشت زیرا نشانگر کارایی مدل در مجموعه تست اصلی است. همچنین، به طور مستقیم انتظار اپسیلون بزرگتر و آشفتگیهای قابل توجهتری میرود، اما در عین حال انتظار میرود که حملات موثرتری باشند که بیشتر بتوانند صحت مدل را کاهش دهند. از آنجا که طیف دادهها در اینجا [0,1] است، هیچ مقدار اپسیلونی نباید از یک تجاوز کند.
pretrained_model: مسیری به مدل MNIST از پیشآموزش داده شده با pytorch/examples/mnist است. برای سادگی، میتوان مدل از پیش آموزش داده شده را از اینجا (+) دانلود کرد.
use_cuda: «پرچم دودویی» (boolean flag) برای استفاد از CUDA در صورت تمایل و در دسترس بودن است. شایان توجه است که GPU با CUDA در این راهنما امری الزامی نیست، زیرا CPU هم زمان اجرای زیادی ندارد.
مدل زیر حمله
همانطور که پیشتر بیان شد، مدل تحت حمله مشابه مدل MNIST موجود در pytorch/examples/mnist است. کاربر ممکن است مدل MNIST خودش را آموزش بدهد و ذخیره کند یا میتواند مدل آماده شده موجود را دانلود و استفاده کند. تعریف Net و «بارگذار داده آزمون» (test dataloader) در اینجا از مثال MNIST کپی شدهاند.
هدف این بخش تعریف مدل و بارگذار داده و سپس مقداردهی اولیه مدل و بارگذاری وزنهای از پیش تعریف شده است.
خروجی:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gz Extracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz Processing... Done! CUDA Available: True
حمله FGSM
اکنون، میتوان تابعی که مثالهای تخاصمی را با آشفته کردن دادههای اصلی میسازد تعریف کرد. تابع fgsm_attack سه ورودی را دریافت میکند. image همان تصویر سالم (x)، ورودی epsilon مقدار آشفتگی متناسب با پیکسل (ϵ)، و data_grad گرادیان زیان از زیان w.r.t تصویر ورودی ((xJ(θ,x,y∇) است. تابع در ادامه تصویر منحرف شده را به صورت زیر میسازد:
((perturbed_image=image+epsilon∗sign(data_grad)=x+ϵ∗sign(∇xJ(θ,x,y
در نهایت، به منظور نگهداری طیف اصلی دادهها، تصویر منحرف شده در دامنه [0,1] محدود شده است.
تابع تست
در نهایت، نتیجه مرکزی این راهنما از تابع test میآید. هر فراخوانی این تابع تست یک گام تست کامل را در مجموعه تست MNIST اجرا میکند و صحت نهایی را گزارش میدهد. اگرچه، شایان توجه است که این تابع نیز یک ورودی epsilon را دریافت میکند. این بدین دلیل به وقوع میپیوندد که تابع test صحت مدلی که تحت حمله متخاصم است را گزارش میکند. به طور مشخصتر باید گفت که برای هر نمونه در مجموعه تست، تابع گرادیان زیان w.r.t داده ورودی (data_grad) را محاسبه میکند، یک تصویر منحرف شده با (fgsm_attack (perturbed_data میسازد و سپس بررسی میکند که آیا مثال آشفته شده تخاصمی است. علاوه بر تست صحت مدل، تابع مثالهای تخاصمی موفقی را برای آنکه بعدا بصریسازی شوند ذخیره میکند و باز میگرداند.
اجرای حمله
آخرین بخش از پیادهسازی آن است که در واقع حمله اجرا شود. در اینجا، یک گام تست کامل برای هر مقدار اپسیلون در ورودی epsilons اجرا میشود. برای هر اپسیلون، صحت نهایی و برخی از مثالهای تخاصمی موفق برای ترسیم شدن در بخشهای آتی ذخیره میشوند.
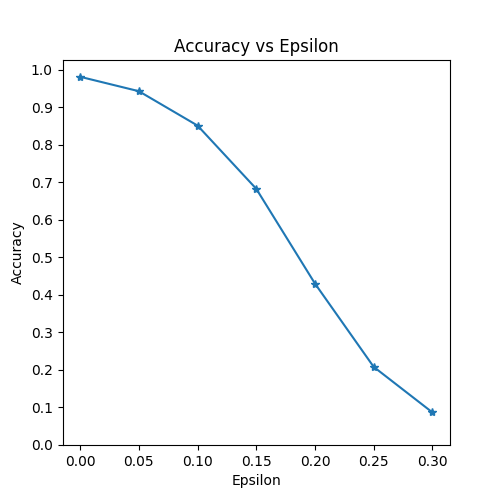
شایان توجه است که صحتهای پرینت شده چگونه با افزایش مقدار اپسیلونها، کاهش پیدا میکنند. حالت ϵ=0 که صحت تست اصلی را بدون حمله نشان میدهد نیز جالب توجه است.
خروجی:
Epsilon: 0 Test Accuracy = 9810 / 10000 = 0.981 Epsilon: 0.05 Test Accuracy = 9426 / 10000 = 0.9426 Epsilon: 0.1 Test Accuracy = 8510 / 10000 = 0.851 Epsilon: 0.15 Test Accuracy = 6826 / 10000 = 0.6826 Epsilon: 0.2 Test Accuracy = 4301 / 10000 = 0.4301 Epsilon: 0.25 Test Accuracy = 2082 / 10000 = 0.2082 Epsilon: 0.3 Test Accuracy = 869 / 10000 = 0.0869
نتایج
اولین نتیجه، نمودار «صحت» (accuracy) در مقایسه با «اپسیلون» (epsilon) است. همانطور که پیشتر اشاره شد، با افزایش اپسیلون، انتظار میرود که صحت مدل کاهش پیدا کند. این امر بدین دلیل است که هرچه اپسیلون بیشتر باشد این معنی را میدهد که گام بزرگتری در جهتی که زیان را بیشینه میکند برداشته شده است.
شایان توجه است که گرایش در این منحنی خطی نیست، حتی هنگامی که مقادیر اپسیلون فاصلهگذاری خطی شدهاند. برای مثال، صحت در ϵ=0.05 تنها حدود ٪۴ کمتر از ϵ=0 است، اما صحت در ϵ=0.2 به میزان ٪۲۵ کمتر از ϵ=0.15 است. همچنین، شایان توجه است که صحت مدل بر صحت تصادفی برای ۱۰ کلاس دستهبند بین ϵ=0.25 و ϵ=0.3 چیره میشود.

نمونه مثال تخاصمی
با توجه به مفهوم «no free lunch»، در این شرایط، با افزایش اپسیلون، صحت کل کاهش پیدا میکند، اما انحراف راحت تر قابل مشاهده میشود. در واقعیت، موازنهای بین کاهش صحت و آشفتگی وجود دارد که یک مهاجم باید آن را در نظر داشته باشد. در اینجا، مثالهایی از موفقیت نمونههای تخاصمی در هر مقدار اپسیلون ارائه شده است. هر سطر از نمودار یک مقدار اپسیلون متفاوت از خود نشان میدهد.
سطر اول مثالهای ϵ=0 هستند که تصوویر «پاک» اولیه را بدون هرگونه انحراف نشان میدهد. عنوان هر تصویر «original classification -> adversarial classification» را نشان میدهد. شایان توجه است که در همه شرایطها انسانها همچنان قادر به شناسایی دسته صحیح علارغم وجود نویز هستند.


کد منبع کامل FGSM در پایتون
کل زمان اجرای این اسکریپت: ۳ دقیقه و ۷.۳۳۳ ثانیه
گام بعدی
خوشبختانه این راهنما بینش خوبی از یادگیری ماشین تخاصمی فراهم میکند. جهتهای بالقوه زیادی وجود دارند که میتوان در ادامه به سمت آنها رفت. این نوع از حمله، شروعی بسیار مقدماتی برای پژوهشهای حملات تخاصمی است و از سوی دیگر، موضوعی که به آن پرداخته میشود چگونگی مقابله با این حملههای تخاصمی برای دفاع از یک مدل یادگیری ماشین در مقابل یک متخاصم است.

در کنفرانس NIPS 2017 یک رقابت حمله و دفاع برگزار شد و بسیاری از روشهای مورد استفاده در این رقابت در این مقاله (+) معرفی شدهاند. کار روی روشهای دفاع نیز منجر به ایده ساخت مدلهای یادگیری ماشین «مستحکم» (robust) به صورت کلی هم برای آشفتگی طبیعی و هم آشفتگی ناشی از حملات تخاصمی شده است.
دیگر جهتی که میتوان در آن گام برداشت، حملات تخاصمی و دفاع در برابر آنها در دامنههای گوناگون است. پژوهشهای تخاصمی به دامنه تصاویر محدود نشدهاند. برای مثال، این حمله (+) را روی مدلهای گفتار به متن (speech-to-text models) میتوان مشاهده کرد. برای یادگیری بیشتر، میتوان یکی دیگر از مدلهای رقابتهای NIPS 2017 را پیادهسازی و تفاوتهای آن با FGSM را مشاهده کرد. سپس از مدل در مقابل حملات دفاع کرد.
اگر نوشته بالا برای شما مفید بود، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش محاسباتی
- آموزش یادگیری عمیق (Deep learning)
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- فراگیری مفاهیم هوش مصنوعی — مجموعه مقالات جامع وبلاگ فرادرس
- دادهکاوی (Data Mining) — از صفر تا صد
- یادگیری عمیق (Deep Learning) با پایتون — به زبان ساده
^^








