پیاده سازی اندیکاتور شاخص قدرت نسبی RSI در پایتون – راهنمای گام به گام
اندیکاتور شاخص قدرت نسبی (Relative Strength Index) که بهصورت کوتاه با نام RSI شناخته میشود، یکی از اولین اندیکاتورهایی است که در تحلیل تکنیکال با آن آشنا میشویم و در عین فراگیری، قدرت خوبی نیز در زمینههای مختلفی از خود نشان میدهد. برای آشنایی بیشتر با این اندیکاتور میتوانید به مطلب «آموزش اندیکاتور RSI – نحوه استفاده به زبان ساده» مراجعه کنید. در ادامه، به بررسی پیادهسازی اندیکاتور RSI در پایتون میپردازیم.


آشنایی با اندیکاتور RSI
اندیکاتور RSI، بهنوعی، بزرگی حرکات قیمت پایانی (Close) به سمت پایین و بالا را در L دوره گذشته محاسبه میکند و با مقایسه آنها با یکدیگر، به یک شاخص در خصوص موقعیت قیمت میرسد.
این اندیکاتور یک اسیلاتور است و بین 0 تا 100 نوسان میکند، درحالیکه مقادیر کمتر از 30 را بهعنوان نقاط «بیشفروش» (Oversold) و مقادیر بیشتر از 70 را به عنوان نقاط «بیشخرید» (Overbought) میشناسیم.
این اندیکاتور علاوه بر موارد گفته شده توانایی خوبی نیز در شناسایی «واگراییها» (Divergence) دارد و از این جهت نیز مهم است. بنابراین، یاد گرفتن روش کار و پیادهسازی آن، از جهات گوناگون میتواند به ما در تحلیل بازارها، ساخت استراتژیهای قدرتمند و ایجاد رباتهای معاملهگر کمک کند.
بدین منظور، ابتدا با روش محاسبه این اندیکاتور آشنا میشویم. اگر بازه زمانی از گام زمانی 1 شروع شود و تا T ادامه یابد، مجموعه قیمتهای پایانی را بهشکل زیر خواهیم داشت:
حال میتوانیم تغییرات قیمت را بین هر دو روز متوالی با فرمول زیر تعریف کنیم:
به این ترتیب، به سادگی میتوان متوجه شد که تغییرات قیمت تنها در بازه زمانی 2 تا T قابل محاسبه است:
در این بخش از محاسبه اندیکاتور، تغییرات قیمت را به دو سری جداگانه تقسیم میکنیم که اولی تحرکات به سمت بالا (Up Trend) و دومی تحرکات به سمت پایین (Down Trend) را ذخیره میکند. مقادیر این دو سری بهشکل زیر تعریف میشود:
- برای روزهای با افزایش قیمت، مقدار U برابر با تغییرات قیمت خواهد بود و مقدار D برابر با صفر خواهد بود.
- برای روزهای با کاهش قیمت، مقدار U برابر با صفر خواهد بود و مقدار D برابر با قرینه تغییرات قیمت خواهد بود.
بنابراین میتوان بهشکل زیر نوشت:
البته میتوان با استفاده از تابع max این روابط را به شکل زیر نیز بازنویسی کرد:
پس از محاسبه این دو سری، روی هر دو آنها یک «میانگین متحرک هموار» (Smoothed Moving Average) یا SMMA اعمال میکنیم. با تقسیم خروجی این دو میانگین متحرک، عدد جدیدی به نام «قدرت نسبی» (Relative Strength) یا SR یا «فاکتور قدرت نسبی» (Relative Strength Factor) یا RSF بهدست خواهد آمد:
این معیار میتواند عددی در بازه به خود بگیرید که از آن میتوانیم برای محاسبه شاخص قدرت نسبی استفاده کنیم:
به این ترتیب، مقدار نهایی اندیکاتور قابل محاسبه است. توجه داشته باشید که با قرار دادن اعداد مختلف در بازه بهجای RS میتوانیم به این نتیجه برسیم که RSI همواره در بازه قرار خواهد گرفت.
میانگین متحرک هموار چیست؟
این میانگین متحرک نوع خاصی از میانگین متحرک نمایی (Exponential Moving Average) یا EMA است. برای آشنایی با این میانگین متحرک و پیادهسازی آن میتوانید به مطلب «پیاده سازی میانگین متحرک نمایی در پایتون – راهنمای گام به گام» مراجعه کنید. برای میانگین متحرک نمایی ابتدا یک L تعریف و سپس یک ضریب به نام محاسبه میشود:
سپس، با استفاده از این ضریب مقدار میانگین متحرک محاسبه میشود:
در اغلب موارد، از تنظیمات استفاده میشود. اگر تنظیمات استفاده شود، یک نوع خاصی از میانگین متحرک نمایی بهنام میانگین متحرک هموار حاصل خواهد شد که واکنش آرامتری نسبت به میانگین متحرک نمایی دارد. بنابراین میتوان گفت:
به این ترتیب، برخی از مشکلات موجود در رابطه با تأخیر نیز حذف میشود.
پیاده سازی اندیکاتور RSI در پایتون
ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم:
این کتابخانهها، بهترتیب، برای موارد زیر استفاده خواهند شد:
- کار با آرایهها و محاسبات برداری
- 2. دریافت مجموعه داده مربوط به قیمت طلا
- رسم نمودارهای قیمت و اندیکاتور
تنظیمات زیر را نیز برای تغییر Style نمودارها اعمال میکنیم:
حال میتوانیم مجموعه داده مربوط به قیمت طلا را، از تاریخ 2020/01/01 تا 2022/01/01 دریافت کنیم:
برای بررسی اولیه مجموعه داده میتوانیم 5 سطر ابتدایی و 5 سطر انتهایی آن را نمایش دهیم:
که خواهیم داشت:
Open High Low Close Adj Close Volume Date 2019-12-31 143.309998 143.600006 142.800003 142.899994 142.899994 5313500 2020-01-02 143.860001 144.210007 143.399994 143.949997 143.949997 7733800 2020-01-03 145.750000 146.320007 145.399994 145.860001 145.860001 12272800 2020-01-06 148.440002 148.479996 146.949997 147.389999 147.389999 14403300 2020-01-07 147.570007 148.139999 147.429993 147.970001 147.970001 7978500 Open High Low Close Adj Close Volume Date 2021-12-27 168.960007 169.419998 168.779999 169.369995 169.369995 4760300 2021-12-28 169.330002 169.649994 168.619995 168.639999 168.639999 4541900 2021-12-29 167.360001 168.690002 167.279999 168.589996 168.589996 5889700 2021-12-30 168.429993 169.809998 168.369995 169.800003 169.800003 5426300 2021-12-31 170.529999 171.039993 170.039993 170.960007 170.960007 7039300
به این ترتیب، مشاهده میکنیم که مجموعه داده از تاریخ 2019/12/31 شروع و در تاریخ 2021/12/31 به اتمام رسیده است. برای پیادهسازی اندیکاتور شاخص قدرت نسبی، هم میتوانیم از امکانات کتابخانه Numpy و هم امکانات کتابخانه Pandas استفاده کنیم. ابتدا پیادهسازی به کمک Numpy را بررسی میکنیم. به همین دلیل، ستون مربوط به قیمت پایانی را بهشکل آرایه Numpy درمیآوریم:
حال میتوانیم یک آرایه دیگر نیز برای شماره روزها ایجاد کنیم:
توجه داشته باشید که تابع اعداد را در بازه start تا stop-step ایجاد میکند، بنابراین عدد C.size + 1 در این آرایه وجود نخواهد داشت. Size یکی از attributeهای آرایههای Numpy است که تعداد درایههای موجود در آرایه را نشان میدهد. برای دریافت اندازه بعد اول آرایهها میتوان از تابع len نیز استفاده کرد.
حال با کمک دو آرایه T و C میتوانیم یک نمودار نیمهلگاریتمی (Semi-logarithm) برای قیمت رسم کنیم:
پس از اجرای کد، نمودار زیر را خواهیم داشت.
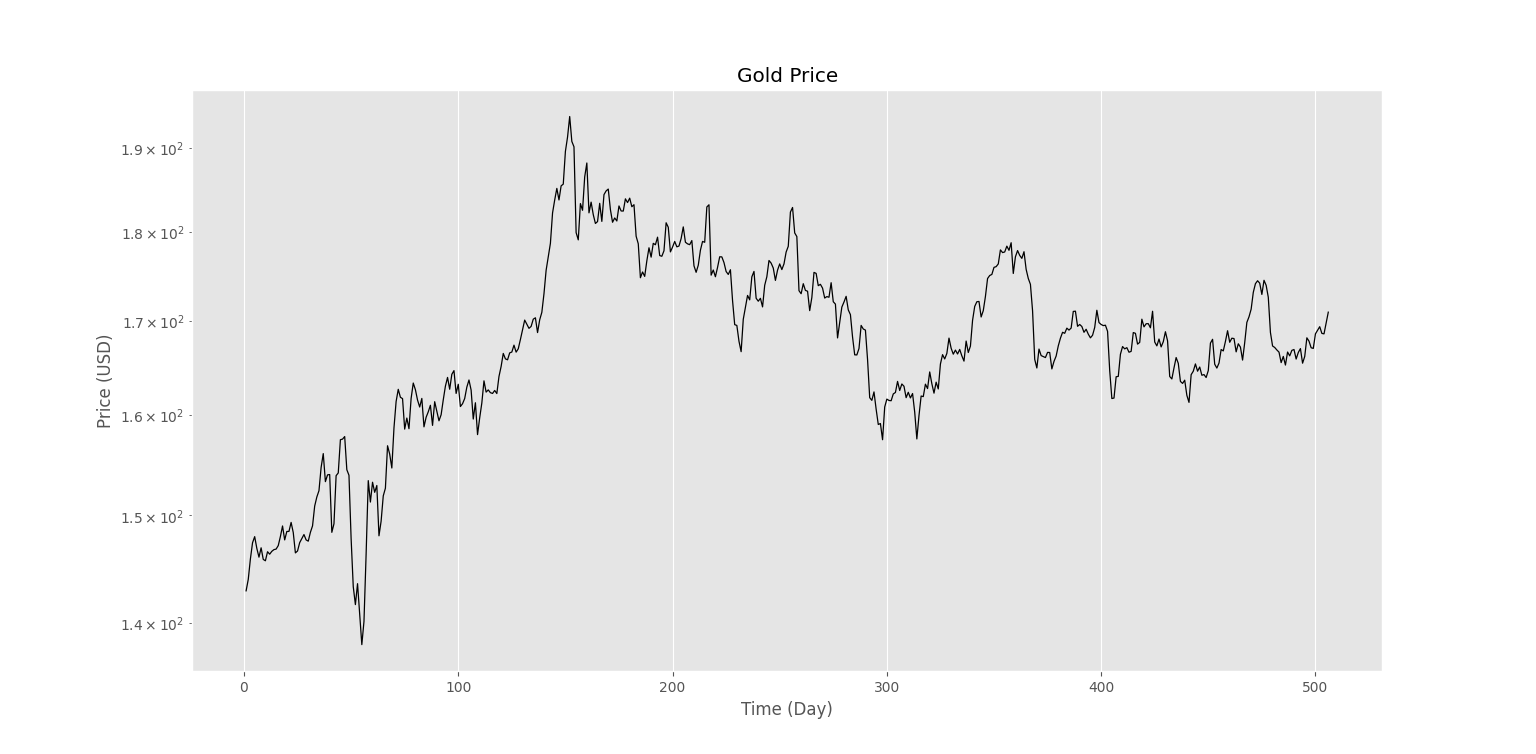
به این ترتیب، از صحت مجموعه داده اطمینان حاصل میکنیم. در نمودار قیمت برای برخی روزها سقف قیمت و رشد بسیار زیاد را مشاهده میکنیم. با توجه به روش محاسبه اندیکاتور شاخص قدرت نسبی، انتظار داریم که این نواحی به راحتی توسط آن شناسایی شود.
حال برای پیادهسازی اندیکاتور، یک تابع ایجاد میکنیم که در ورودی آرایه مربوط به قیمت پایانی و طول پنجره محاسبه اندیکاتور را دریافت میکند:
حال در اولین قدم، اندازه داده ورودی را محاسبه میکنیم:
حال میتوانیم تعداد روزهایی را محاسبه کنیم که تغییرات قیمت برای آنها موجود است:
حال دو آرایه با مقادیر برای U و D ایجاد میکنیم:
سپس نیاز داریم تا یک حلقه ایجاد کنیم و برای هر مقدار از تغییرات قیمت، تصمیمگیری کنیم:
در ابتدای حلقه، تغییرات قیمت را محاسبه میکنیم:
توجه داشته باشید که شمارش i از 0 شروع میشود بنابراین i-1 غیر قابلاستفاده است.
حال با یک شرط بررسی میکنیم تا اگر تغییرات قیمت مثبت بود، آن را به آرایه U اضافه کنیم:
در غیر این صورت نیز، قرینه تغییرات به آرایه D اضافه خواهد شد:
به این ترتیب، دو سری U و D در انتهای حلقه کامل خواهد بود. حال میتوانیم میانگین متحرک هموار را بر روی این دو سری اعمال کنیم:
توجه داشته باشید که ورودی r چون مقدار پیشفرض 1 را به خود میگیرد، برای تعیین مقداری غیر از آن، باید به شکل r=0 وارد شود.
به این ترتیب، سری RS قابل محاسبه خواهد بود:
در نهایت نیز RSI را محاسبه میکنیم و برمیگردانیم:
به این ترتیب، تابع RSI تکمیل میشود.

برای تابع EMA نیز از تابع زیر استفاده میکنیم:
توجه داشته باشید که میتوانیم خود تابع SMMA را به شکل جداگانه نیز تعریف کنیم:
این تابع مشابه قبلی است با این تفاوت که مقدار r برای آن متغیر نبوده و همواره 0 است. کد زیر نیز میتواند به عنوان جایگزین برای حالت قبلی استفاده شود:
نکته مهمی که وجود دارد، کاهش سرعت برنامه در صورت استفاده تودرتو از توابع است که باید در پروژههای بزرگ مورد توجه قرار گیرد. حال میتوانیم از تابع پیادهسازی شده استفاده کرده و اندیکاتور را محاسبه کنیم:
در نتیجه، اندیکاتور شاخص قدرت نسبی در طول پنجره 14 روزه محاسبه و برگردانده خواهد شد. برای نمایش نتایج، دو نمودار مربوط به قیمت و اندیکاتور را در کنار هم رسم میکنیم تا عملکرد آن را مشاهده کنیم:
توجه داشته باشید که در تابع plt.subplot 3 سطر و 1 ستون تعیین شده است، اما دو سطر اول برای نمودار قیمت در نظر گرفته شدهاند.
نکته مهم دیگری که باید به آن توجه کرد در خصوص طول آرایه rsi است. این آرایه طولی برابر با C و T ندارد، بنابراین نمیتوان از T بهعنوان مقادیر زمان استفاده کرد و حالت T[-rsi.size:] صحیح خواهد بود. پس از رسم نمودار فوق، نتیجه زیر حاصل میشود.
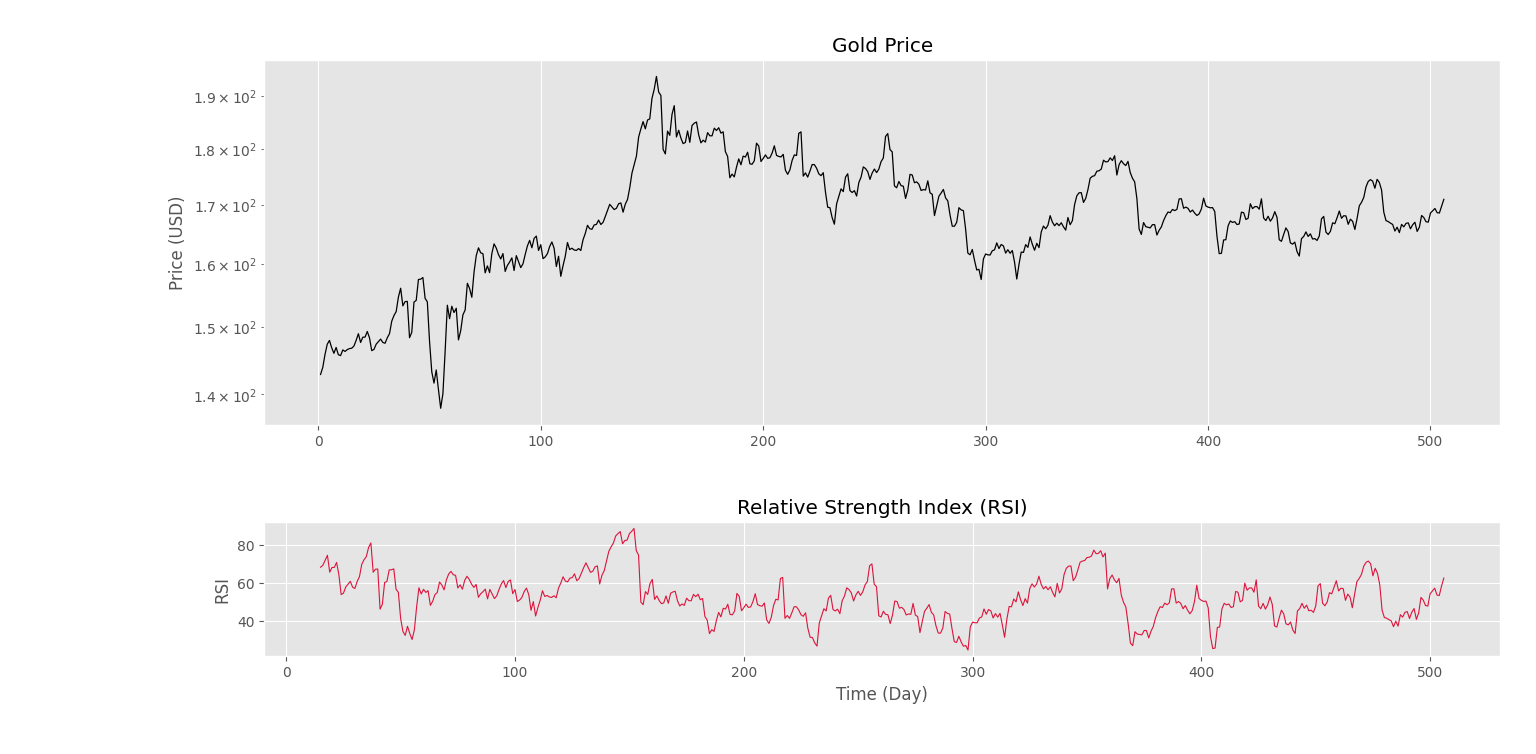
بنابراین، نمودار رسم میشود. مشکل دیگری که وجود دارد، بههمریختگی محور افقی دو نمودار به دلیل تفاوت در طول آن دو است. برای رفع این مشکل از plt.xlim استفاده میکنیم:
توجه داشته باشید که اضافه کردن این تکه کد به هر دو نمودار الزامی است. رعایت کردن یک حاشیه در سمت چپ و راست نیز برای مناسب بودن نمودار الزامی است. حال با اجرای برنامه نمودار شکل زیر ظاهر خواهد شد.
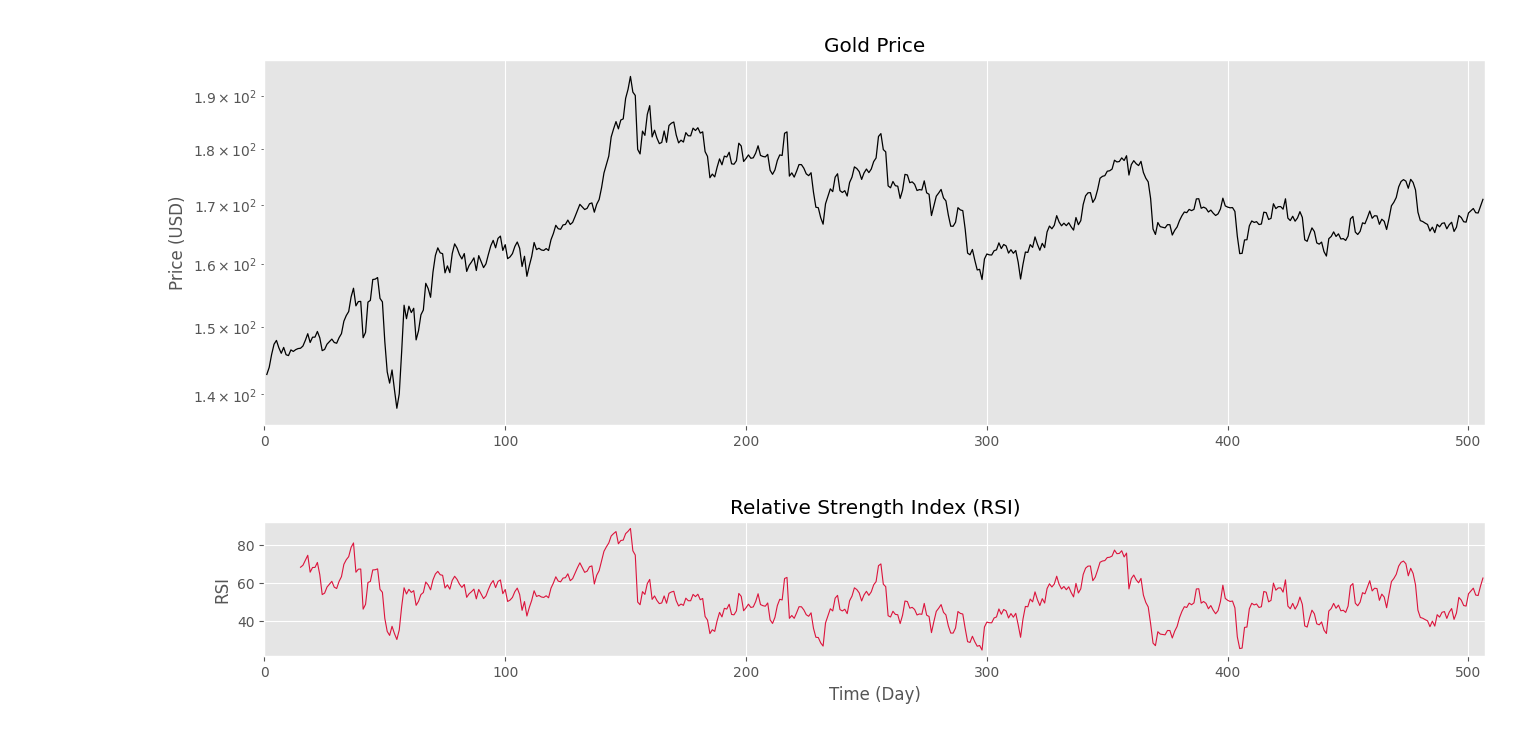
به این ترتیب، بههمریختگی محور افقی رفع میشود. حال میتوانیم نمودار پایینی را نیز بین 0 تا 100 محدود کنیم و دو خط 30 و 70 نیز به آن اضافه کنیم:
در نهایت، شکل نهایی نمودار حاصل خواهد شد.
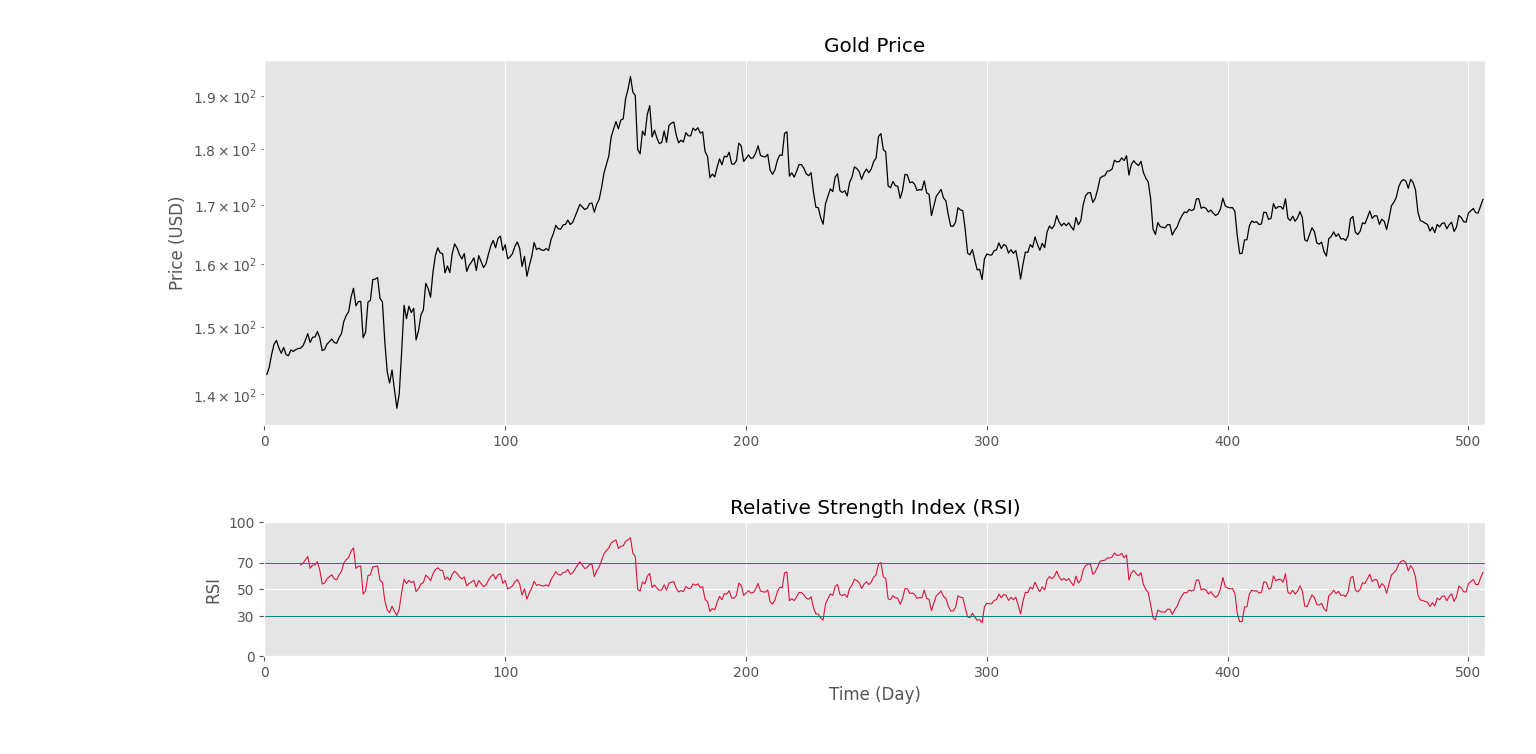
به این ترتیب، نمودار کامل میشود. حال میتوان بررسی کرد دید که اندیکاتور نقاط بیشخرید را در روزهای 40، 140 و 350 تشخیص داده است. برخی نقاط بیشفروش کوچک نیز شناسایی شدهاند که واکنش معاملهگران و بازگشت قیمت را شاهد بودهایم. بنابراین، اندیکاتور با استفاده از امکانات کتابخانه Numpy پیادهسازی و نتایج مصورسازی شدند.
حال قصد داریم اندیکاتور را به کمک کتابخانه Pandas پیادهسازی کنیم. برای این منظور فراخوانی زیر را نیز به موارد قبلی اضافه میکنیم:
ابتدا تابع را ایجاد و در ورودی دیتافریم و طول پنجره را دریافت میکنیم:
حال در اولین مرحله یک ستون برای تغییرات قیمت هر دو روز متوالی ایجاد میکنیم و با کمک متد diff آن را محاسبه میکنیم:
حال میتوانیم دو ستون U و D را به کمک متد apply محاسبه کنیم. به این منظور از توابع lambda پایتون استفاده میکنیم:
حال باید میانگین متحرک هموار را بر روی دو ستون اخیر اعمال کنیم. برای این منظور، میتوانیم از متد ewm استفاده کنیم و در نهایت میانگینگیری کنیم:
توجه داشته باشید که متد ewm به چندین شکل میتواند ورودی دریافت که یکی از آنها به کمک com است و به شکل زیر عمل میکند:
به این ترتیب، برای اینکه تنظیمات را داشته باشیم، باید مقدار com برابر با L-1 باشد. حال میتوانیم ستون RS را از نسبت دو ستون اخیر حساب کنیم:
در نهایت، میتوانیم خود اندیکاتور را محاسبه کنیم و پیادهسازی تابع به اتمام برسد:
حال میتوانیم تابع را روی دیتافریم اعمال کنیم:
پس از اجرای این بخش از کد، 7 ستون جدید به دیتافریم اضافه خواهد شد که تنها 1 ستون از آنها مورد نیاز است، برای بهینگی برنامه میتوانیم در انتهای تابع این ستونهای اضافه را حذف کنیم:
به این ترتیب، 6 ستون اضافه حذف خواهند شد. مشکل دیگری که در رابطه با این تابع وجود دارد، احتمال محاسبه چندین RSI است. برای مثال، اگر بخواهیم دو RSI با طولهای متفاوت ایجاد کنیم، تنها یکی از آنها را خواهیم داشت. برای رفع این مشکل، بهتر است نامگذاری هر ستون RSI را با طول آن تعیین کنیم تا مشکلی ایجاد نشود. برای این منظور، تابع را با اندکی تغییر به شکل زیر تغییر میدهیم:
به این ترتیب، هر RSI ستونی با نام اختصاصی برای خود خواهد داشت. حال میتوانیم پس از اعمال تابع بر روی دیتافریم، نمودار مربوط به اندیکاتور را رسم کنیم. به این منظور، کد قبلی را با اندکی تغییر به شکل زیر تغییر میدهیم:
در نهایت، خروجی به شکل زیر حاصل خواهد شد.
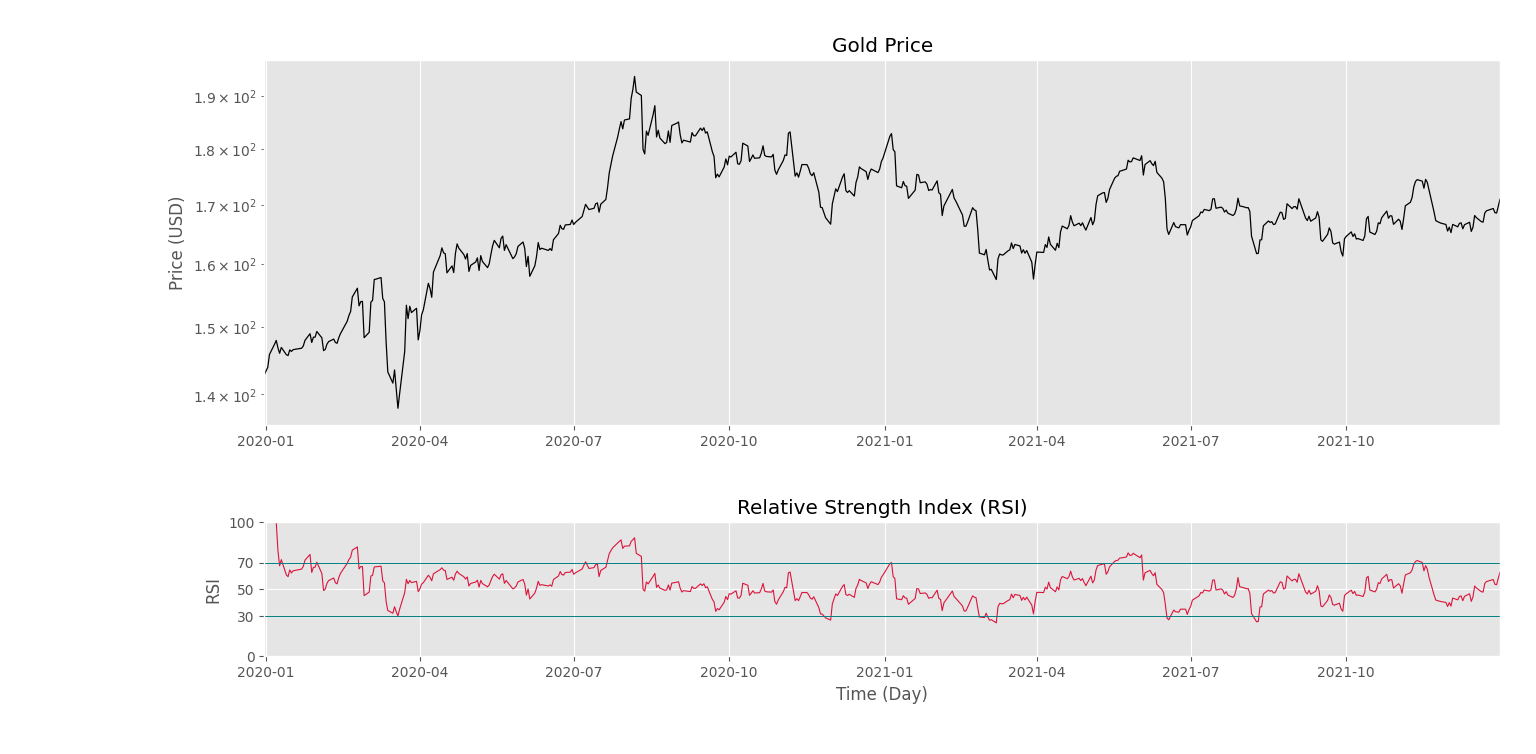
بنابراین، مشاهده میکنیم که نتیجه کاملاً مشابه پیادهسازی قبلی است. بنابراین هر دو کتابخانه امکاناتی برای اینگونه پیادهسازیها ارائه میکنند که هرکدام میتواند تحت شرایطی گزینه مناسبی باشد.

جمعبندی اندیکاتور RSI در پایتون
پیادهسازی اندیکاتور شاخص قدرت نسبی در اینجا به اتمام میرسد. برای مطالعه بیشتر میتوان موارد زیر را بررسی کرد:
- اگر به جای SMMA از EMA ساده در هموارسازی استفاده کنیم، چه تغییری حاصل خواهد شد؟ در یک نمودار این تغییرات را نشان دهید.
- چرا کتابخانه Pandas برای 13 روز اول اندیکاتور نیز مقدار میدهد ولی Numpy نمیتواند؟
- متد ewm را از سایت رسمی کتابخانه Pandas بررسی و انواع روشهای فراخوانی آن را مطالعه کنید.
- چگونه میتوان شاخص قدرت نسبی را به بازه محدود کرد؟
- اگر بخواهیم از این اندیکاتور برای ایجاد یک ربات معاملهگر ساده استفاده کنیم، چه استراتژیهای قابل استفاده خواهد بود؟
- ورودی inplace در متد drop چه فرآیندی را کنترل میکند؟
- سه خط smmaU, smmaD, RSI را در کنار هم رسم کنید بررسی کنید چه ارتباطی با هم دارند؟
- چگونه میتوان به کمک مقادیر smmaU، smmaD و قیمت پایانی میتوان شدت روند موجود در بازار را محاسبه کرد؟