



آموزش وب اسکرپینگ با پایتون – از صفر تا صد
«وب اسکرپینگ» (Web Scraping) یکی از فرایندهای خودکار برای جمعآوری اطلاعات وسیع از روی اینترنت محسوب میشود. اطلاعات موجود در صفحات وب و وبسایتها بهطور معمول سازماندهی نشدهاند و دارای نظم خاصی نیستند. برای ذخیره این نوع دادهها به شکل ساختیافتهتر، میتوانیم وب اسکریپنگ را به عنوان ابزاری سودمند مورد استفاده قرار دهیم. سرویسهای آنلاین، رابطهای برنامهنویسی اپلیکیشن یا همان API و کدهای سفارشی نوشتهشده، جزو راههایی هستند که برای وب اسکرپینگ وبسایتها میتوانیم بهکار ببریم. از سوی دیگر پایتون بهعنوان یکی از زبانهای برنامهنویسی پر طرفدار این روزا، به علت کدنویسی آسان، فراهم کردن کتابخانههای متعدد و کارآمد، کامیونیتی فعال و غیره انتخاب خوبی برای وب اسکرپینگ است. در این مطلب از مجله فرادرس قصد داریم تا به زبانی ساده و تا حد ممکن بهطور کامل، وب اسکرپینگ با پایتون را یاد بگیریم و همچنین نکات و ابزارهای متعددی را در این باره باهم مرور کنیم.
- میآموزید وب اسکرپینگ چیست و چه تفاوتی با وب کرالینگ دارد.
- یاد میگیرید چرا پایتون زبان مناسبی برای استخراج دادههای وب محسوب میشود.
- با ابزارها و کتابخانههای مهم وب اسکرپینگ در پایتون آشنا میشوید.
- میتوانید روشهای مختلف دریافت اطلاعات از صفحات وب را تشخیص دهید.
- دلایل و کاربرد استفاده از پروکسی در فرایند وب اسکرپینگ را میآموزید.
- با یک مثال عملی، شیوه اجرای وب اسکرپینگ در پایتون را تمرین میکنید.




احتمالاً پیش آمده است تا اطلاعاتی را از یک وبسایت کپی کرده و در جای دیگر الصاق - یا همان Paste - کرده باشید. در این هنگام هم در واقع عملی مشابه وب اسکرپینگ - اما بهصورت دستی - را روی آن بخش از صفحه وب انجام دادهاید. برعکس روند خستهکننده واکشی دادهها بهصورت دستی، وب اسکرپینگ از یادگیری ماشین و اتوماسیون هوشمند برای بازیابی هزاران، میلیونها یا حتی میلیاردها نقاط - یا مقادیر - دادهای استخراجی از مرز بیپایان دادههای وب استفاده میکند.
وب اسکرپینگ چیست؟
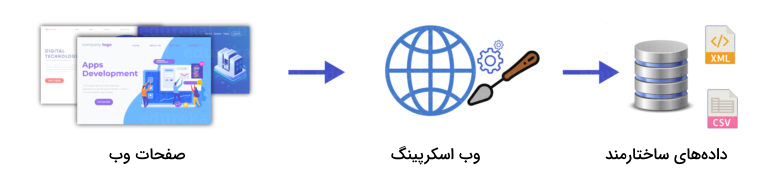
«وب اسکرپینگ» (Web Scraping) به فرایندی گفته میشود که در آن، دادههایی را بهوسیله یک ربات از وبسایت مورد نظر خارج میکنیم و در قالبی مناسب و قابلفهم ارائه میدهیم. یک «وب اسکرپر» (Web Scraper) کدهای HTML را از یک صفحه وب بیرون بیرون میکشد تا سپس، آنها را برای دستیابی به اطلاعات سودمند تجزیه کنیم.
به زبان ساده و بهطور خلاصه عملیات وب اسکرپینگ را میتوانیم «بیرون کشیدن دادهها از یک وبسایت» تعریف کنیم.
نقش پایتون در وب اسکرپینگ چیست؟
پایتون بهعنوان یکی از زبانهای برنامهنویسی محبوب و پر استفاده، جزو گزینههای مناسب برای انجام وب اسکرپینگ محسوب میشود. به دلیل اینکه کتابخانههای متعددی را برای مدیریت درخواستهای HTTP، تجزیه HTML و فریمورکهای مرورگر-محور برای گردآوری نسخههای رندر شده - و نمایش دادهشده - صفحات وب فراهم میکند.
فرایند وب اسکرپینگ برای تولید بینشها میتواند بهطور قابل توجهی سودمند باشد. برای دریافت دادههای وب، ۲ راه پیشِ رو داریم. اینکه خودمان با استفاده از ابزار وب اسکرپینگ این کار را انجام دهیم یا اینکه آن را به شرکتهایی برونسپاری کنیم که خدمات وب اسکرپینگ را ارائه میدهند.

چرا پایتون برای وب اسکرپینگ گزینه خوبی است؟
در ادامه، فهرستی از ویژگیهای زبان برنامه نویس پایتون را آوردهایم که نشان میدهد پایتون میتواند انتخاب خیلی خوبی به منظور وب اسکرپینگ باشد.
استفاده آسان: کدنویسی با زبان پایتون پیچیدگی زیادی ندارد. مانند برخی از زبانها نیاز به استفاده از براکتها و علامتهایی مانند نقطهویرگول نیست و در نتیجه کدهای تمیزتری خواهیم داشت که استفاده از آن را ساده میسازد.
مجموعه وسیعی از کتابخانهها: پایتون مجموعه گستردهای از کتابخانهها در زمینههای گوناگون را در اختیارمان قرار میدهد. Numpy ،Matlplotlib ،Pandas نمونههایی از کتابخانههای پرکاربرد پایتون هستند که سرویسها و متدهای مختلفی را برای برنامهنویسان فراهم میکنند. بههمین دلیل، زبان پایتون، انتخاب مناسبی برای انجام وب اسکرپینگ و اقدامات بیشتر روی دادههای بهدست آمده محسوب میشود.
«داینامیکتایپ بودن» (Dynamically typed): هنگام کدنویسی به زبان پایتون و تعریف متغیرها نیازی به تعیین نوع دادهها برای آنها نداریم و میتوانیم هر موقع که نیاز به متغیر داشتیم، بهطور مستقیم آنها را بهکار ببریم. این قضیه باعث صرفهجویی در زمان شده و کار را سریعتر پیش میبرد.
سینتکس قابل فهم: سینتکس پایتون و کدنویسی به این زبان ساده است چون شکل نوشتن دستورات پایتونی و خواندن آنها شباهت زیادی با مطالعه عبارات انگلیسی دارد. کدهای پایتون، صریح و روان و بهسادگی قابل خواندن هستند. تورفتگی موجود در کدهای آن نیز به کاربر در تشخیص محدودهها و بلوکهای مختلف کدها کمک میکند.
انجام وظایف بیشتر با حجم کد کمتر: با توجه به اینکه هدف وب اسکرپینگ، صرفهجویی در زمان است اگر بخواهیم زمان بیشتری را صرف کدنویسی کنیم دیگر به اندازه مدنظر سودمند نخواهد بود. در پایتون میتوانیم با نوشتن کدهای کوچکتر، کارهای بیشتری را انجام دهیم. در نتیجه، هنگام کدنویسی هم در زمان صرفهجویی خواهیم کرد.
کامیونیتی یا جامعه توسعهدهندگان: هنگام کدنویسی دور از انتظار نیست که با مشکلی مواجه شویم و در مسئلهای گیر کنیم. در این باره به لطف وجود کامیونیتی بزرگ و فعال پایتون جای نگرانی نیست و میتوانیم از آن کمک بگیریم.

برای وب اسکرپینگ با پایتون چه ابزارها و کتابخانه هایی وجود دارد؟
زبان برنامهنویسی پایتون ابزارهای مفیدی برای انجام وب اسکرپینگ دارد. برخی از مفیدترین کتابخانهها و فریمورکهای موجود در پایتون برای وب اسکریپت را در ادامه فهرست کردهایم.
- Requests
- BeautifulSoup
- Scrapy
- Selenium
- Urllib3
- Lxml

عملکرد وب اسکرپینگ چگونه است؟
در وب اسکرپینگ، محتوای صفحه وب بهوسیله درخواستهای HTTP استخراج شده، سپس منبع - همچون HTML ،JSON و غیره - به منظور بیرون کشیدن اطلاعات ارزشمند تجزیه میشود.
- درخواست محتوای یک صفحه وب ( requests )
- دانلود HTML
- تجزیه HTML ( BeautifulSoup )
- بیرون کشیدن عناصر از محتوای تجزیه شده

نصب کتابخانه های وب اسکرپینگ با پایتون
با استفاده از مدیر بسته pip، کتابخانههای وب اسکرپینگ با پایتون را نصب میکنیم. با اجرای دستوری که در ادامه آورده شده، نصب requests ،beautifulsoup ،urllib و scrapy را انجام میدهیم.
$ pip3 install requests urllib3 beautifulsoup4 scrapy lxml pyOpenSSLمثالی از وب اسکرپینگ با پایتون
سادهترین راهی که برای وب اسکرپینگ در پایتون میتوانیم انجام دهیم این است که صفحه وب مورد نظر را بهوسیله درخواستهای پایتون واکشی کنیم و توسط BeautifulSoup کدهای HTML صفحه را تجزیه کنیم. مثالی که در ادامه آوردهایم نحوه انجام این ۲ کار رانشان میدهد، پیش از اینکه به مثالهای پیچیدهتری برسیم.
استخراج HTML صفحه وب با Requests
نخستین گامی که برای وب اسکرپینگ در پایتون میبایست انجام دهیم این است که HTML صفحه مورد نظر را بیرون بکشیم. این کار را میتوان با درخواستهای HTTP یا اپلیکیشنهای مبتنی بر مرورگر انجام داد. در این مثال، ما درخواستهای پایتون را برای انجام یک درخواست HTTP بهکار میبریم و HTML صفحه وب را در پاسخ HTTP دریافت میکنیم.
خروجی کدهای گفته شده به صورت زیر خواهد بود.
تجزیه HTML با BeautifulSoup
گام دوم برای وب اسکرپینگ در پایتون این است که اطلاعات را از داکیومنت بیرون بکشیم. به این عمل «تجزیه» (Parsing) گفته میشود. در این مثال، ما از کتابخانه پایتون BeautifulSoup برای تجزیه کدهای HTML صفحهای استفاده میکنیم که در مرحله قبل - در پاسخ HTTP - بازگردانده شد.
خروجی این کدها به صورت زیر خواهد بود.
اکنون که با مقدمات اسکرپینگ یک صفحه وب آشنا شدیم، برخی از روشهایی قابل استفاده برای انجام وب اسکرپینگ را با هم مرور میکنیم.
درک CSS، HTML، جاوا اسکریپت و Xpath
پیش از شروع وب اسکرپینگ با پایتون، لازم است تا با برخی از مفاهیم پایهای CSS، HTML، جاوا اسکریپت و Xpath آشنایی داشته باشیم. با این دانش، میتوانیم از سورس کد و DOM برای خودکارسازی استخراج دادهها از وبسایت استفاده کنیم.
HTML برای وب اسکرپینگ
«زبان نشانهگذاری فرامتن» یا HTML یکی از زبانهای بنیادین برای ساخت صفحات وب بهشمار میرود. هنگامی که از مرورگر برای باز کردن یک صفحه وب استفاده میکنیم، بزرگترین هدف آن تفسیر فایلهای CSS ،HTML و جاوا اسکریپت و تبدیل آنها به وبسایتی کاربردی است. در ادامه نشان میدهیم که یک مرورگر چگونه کدهای HTML را نمایش میدهد.
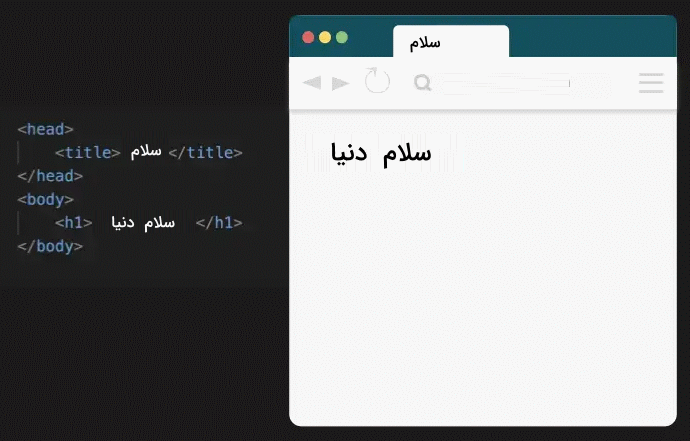
تگ <title> که عنوان صفحه را تعیین میکند در زبانه مرورگر قابل مشاهده است و تگ <h1> نیز متنی را به عنوان یک تیتر درجه اول نشان میدهد.
سند HTML شامل تگهایی است - محصور در علامتهای <> - که ساختار درختی صفحه وب را ارائه میدهند. تگهای HTML دارای قالب ساختار یافتهای هستند که میتوانیم آنها را برای استخراج اطلاعات از صفحه وب مورد استفاده قرار دهیم.
نحوه استفاده از تگ های HTML در وب اسکرپینگ با پایتون
برای بهکارگیری دادههای بهدست آمده از صفحه وب با تگهای HTML در پایتون، از متد .find('tag_name') کتابخانه BeautifulSoup استفاده میکنیم. این متد با تابع Find در پایتون تفاوت دارد. تابع Find در پایتون برای کار بر روی رشتهها تعریف شده است.
CSS برای وب اسکرپینگ
«شیوهنامه آبشاری» یا CSS در توسعه وب بهکار میرود، با هدف توصیف اینکه عناصر به چه صورتی روی صفحه نشان داده شوند. بهطور مثال، در CSS میتوانیم از دستور آورده شده در زیر برای اِعمال رنگ خاصی روی تمامی لینکها موجود در صفحه استفاده کنیم که دارای کلاسی بهنام myclass هستند .
سلکتورهای CSS قالب ساختارمند دیگری هستند که میتواند در وب اسکرپینگ برای مکانیابی و استخراج عناصر موجود در سند HTML مورد استفاده قرار گیرد.
در وب اسکریپنگ، این امکان نیز برایمان وجود دارد تا از سلکتورهای CSS که برای تغییر استایل صفحه استفاده شدهاند برای پیدا کردن هر عنصری از این سلکتور استفاده کنیم.

نحوه استفاده از سلکتورهای CSS در وب اسکرپینگ با پایتون
در پایتون، برای استخراج دادهها از یک سند HTML با استفاده از سلکتور CSS آن، از متدselect() کتابخانه BeautifulSoup استفاده میکنیم.
همچنین میتوانیم از متد.css() روی شی سلکتور scrapy استفاده کنیم.
XPath برای وب اسکرپینگ
XPath زبان پرس و جویی است که میتواند برای دسترسی به عناصر و خصوصیات گوناگون یک سند HTML یا XML مورد استفاده قرار بگیرد. عبارات XPath رشتههایی هستند که برای توصیف موقعیت یک عنصر (گره) یا عناصر متعدد درون سند HTML یا XML بهکار میروند.
XPath به ما امکان میدهد تا عناصر درون سند HTML را به دقت بیابیم. همچنین بهوسیله بیشتر ابزارهای وب اسکرپینگ نیز پشتیبانی میشود، که آن را به ابزاری بسیار ارزشمند برای وب اسکرپینگ تبدیل کرده است. بهطور مثال، xpath آورده شده در زیر، h1 را که درون عنصر body سند HTML است را پیدا میکند.
نحوه استفاده از XPath در وب اسکرپینگ با پایتون
برای تجزیه HTML صفحه وب با XPath در پایتون، از کتابخانه پایتونlxml استفاده میشود.
همچنین میتوانیم متد.xpath() در شی سلکتور scrapy را بهکار ببریم.
روش های انجام وب اسکرپینگ در پایتون
روشهای متعددی برای وب اسکرپینگ در پایتون وجود دارد. میتوانیم از یک زبان برنامهنویسی برای انجام درخواستهای HTTP استفاده کنیم. از مروگر وب بههمراه یک افزونه بهره بگیریم. اپلیکیشن مرورگر را مورد استفاده قرار دهیم. با یک اسپایدر وب یا «وب کرالر» (Web Crawler) کار کنیم.
- درخواستهای ساده HTTP - مانند کتابخانه requests .
- استفاده از مرورگر وب - مانند Selenium.
- بهکارگیری خزنده وب - همچون Scrapy.

وب اسکرپینگ با درخواست های HTTP در پایتون
میتوانیم درخواستهای HTTP در پایتون را به منظور ارتباط با سرور بهوسیله کتابخانهrequests در پایتون بهکار ببریم. تمام کاری که میبایست انجام دهیم این است که یک درخواست HTTP برای URL داده شده ارسال کنیم. سپس وبسرور، پاسخی را بههمراه محتوای صفحه بر میگرداند.
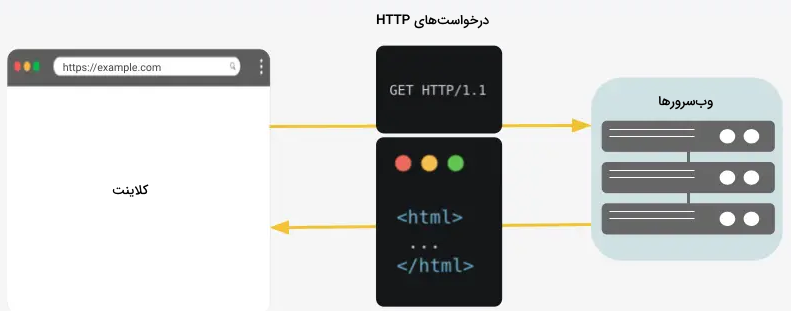
درخواستهای HTTP، امکان مشاهده نسخه رندر شده یا اجرایی صفحه وب - پس از اجرای جاوا اسکریپت - را برایمان فراهم نمیکنند. هنگامیکه برخی از محتوا پشت جاوا اسکریپت پنهان است - یعنی پس از اجرای جاوا اسکریپت نمایش داده میشوند - شاید بهتر باشد که از یک اپلیکیشن مرورگر برای گردآوری اطلاعات از وبسایت بهره بگیریم.
وب اسکرپینگ با مرورگر در پایتون
جمعآوری اطلاعات و محتوای وبسایت مورد نظرمان را میتوانیم با نصب اپلیکیشنی که مرورگرمان را بارگذاری میکند انجام دهیم. درست مانند زمانی که مرورگری مانند کروم را باز میکنیم. بدین ترتیب امکان تعامل با وبسایت بهوسیله پایتون برایمان فراهم میشود. این مورد زمانیکه نیازمند بارگذاری جاوا اسکریپت روی صفحه هستیم، هنگام افزودن اطلاعات لاگین یا خودکارسازی آزمایشات روی وبسایتمان بسیار مفید خواهد بود.
اپلیکیشنهای متعددی وجود دارند که به منظور اتوماسیون و وب اسکرپینگ مبتنی بر مرورگر میتوانند مورد استفاده قرار بگیرند. در ادامه برخی از آنها را فهرست کردهایم.
- «سلنیوم» (Selenium)
- Playwright
- Puppeteer
وب اسکرپینگ با خزنده وب در پایتون
«خزندههای وب» (Web crawlers) همچون Screaming Frog در واقع جزو ابزارهای وب اسکرپینگ محسوب میشوند. آنها قدرت بسیار بیشتری نسبت به وب اسکرپرهایی دارند که خودمان میسازیم. با استفاده از پایتون میتوانیم وب کرالر خودمان را بسازیم اما فراموش نکنید که این کار ممکن است بهسرعت پیچیده شود.
بهکارگیری راهکاری نظیر Scrapy میتواند ایجاد خزنده وب در پایتون را برایمان سادهتر سازد.

کتابخانه های وب اسکرپینگ در پایتون
زبان برنامهنویسی پایتون دارای مجموعه گسترده از کتابخانههایی است که میتوانند در وب اسکرپینگ مورد استفاده قرار گیرند. در ادامه، عناوین برخی از این کتابخانهها را فهرست کردهایم.
- Requests
- BeautifulSoup
- lxml
- Selenium
- Scrapy
- Requests-HTML
در بیشتر پروژههای وب اسکرپینگ تنها به تعداد معدودی از این کتابخانهها نیاز پیدا میکنیم. در ادامه، مثالهایی از راهاندازی کتابخانههای وب اسکرپینگ - از سادهترین تا پیچیدهترین پیادهسازی - را آوردهایم.
- استفاده از کتابخانهrequests پایتون بههمراه کتابخانه تجزیه نظیرBeautifulSoup یاlxml.
- بهکارگیری Requests-HTML با متدهای مربوط به تجزیه «داخلی» (Built-in) آن.
- استفاده ازSelenium بههمراه متدهای مربوط به تجزیه داخلی آن.
- ازScrapy با متدهای مربوط به تجزیه داخلی استفاده کنیم.
وب اسکرپینگ در پایتون با کتابخانه requests
برای انجام فرایند وب اسکرپینگ در پایتون، یکی از کتابخانههای مربوط به درخواست HTTP مثل requests را بههمراه یک کتابخانه پارسر - یا همان تجزیهکننده - مثلBeautifulSoup یا کتابخانهی مرورگر-محوری مثلSelenium بهکار میبریم.
بهطور کلی، تنها چیزی که نیاز داریم نصب پایتون و کتابخانهrequests است. برای این منظور دستور زیر را در خط فرمان، تایپ و اجرا میکنیم.
$ pip install requestsکدهایی که در ادامه آوردهایم را برای واکشی و دریافت یک صفحه وب اجرا میکنیم. خروجی این کدها شامل کدهای HTML مربوط به صفحه وب در قالب یونیکد و متن است.
وب اسکرپینگ در پایتون با کتابخانه BeautifulSoup
برای تجزیه کدهای HTML صفحه وب با استفاده از کتابخانه BeautifulSoup در پایتون، کتابخانه مربوطه را نصب میکنیم، با استفاده از یک کتابخانه درخواست HTTP، کدهای HTML را بازیابی کرده و HTML را با استفاده از کلاسBeautifulSoup() روی آن تجزیه میکنیم. این مراحل را در ادامه آوردهایم.
ابتدا، کتابخانه BeautifulSoup را نصب میکنیم.
$ pip3 install beautifulsoup4 سپس،bs4 را ایمپورت کرده و صفحه را با آن تجزیه میکنیم و از متدهای BeautifulSoup برای دریافت تگهای گوناگون HTML از صفحه استفاده میکنیم.
وب اسکرپینگ در پایتون با کتابخانه lxml
کتابخانهlxml یکی از کتابخانههای مربوط به تجزیه در پایتون است که میتواند برای بیرون کشیدن اطلاعات از HTML یا XML مورد استفاده قرار گیرد. کتابخانهlxml را میتوانیم بهعنوان جایگزینی برای کتابخانهBeautifulSoup بهکار ببریم.
برای استفاده از کتابخانهlxml در پایتون، صفحه مورد نظر را با کتابخانه مربوط به «درخواستها» (Requests) واکشی کرده و HTML آن را با متد html.fromstring() تجزیه میکنیم.
با استفاده از pip کتابخانهlxmlرا نصب میکنیم.
$ pip install lxmlنمایش متنی HTML را با متد fromstring() تجزیه میکنیم.
مزیت استفاده از lxml در مقایسه با BeautifulSoup این است که امکان استفاده از عبارات XPath را برای استخراج دادهها فراهم میکند.
وب اسکرپینگ در پایتون با کتابخانه requests-html
کتابخانهrequests-HTML یکی از کتابخانههای تجزیه HTML (پارسر HTML) در پایتون است که به ما امکان میدهد تا از سلکتور CSS و عبارات XPath به منظور بیرون کشیدن اطلاعات مورد نظر از یک صفحه وب، استفاده کنیم. این کتابخانه همچنین توانایی اجرای اسکریپتهای جاوا اسکریپت را نیز برایمان فراهم میکند.
برای گردآوری اطلاعات یک صفحه وب در پایتون با استفاده از کتابخانهrequests-HTML، ابتدا کتابخانههای مربوطه را نصب کرده و سپس با استفاده از کلاسHTMLSession() ، شی «نشست» (Session) را ایجاد میکنیم. حال میتوانیم درخواست GET را بهوسیله متد .get() انجام دهیم.
برای نصب کتابخانهها دستور زیر را تایپ و اجرا میکنیم.
pip install requests requests-HTML urlparse4جمعآوری اطلاعات از وبسایت در پایتون با استفاده از HTMLSession() قابل انجام است.
در صورت استفاده از ژوپیتر نوتبوک، بروز خطایی که در ادامه آوردهایم محتمل است. در اینگونه موارد از AsyncHTMLSession استفاده میکنیم.
RuntimeError: Cannot use HTMLSession within an existing event loop.وب اسکرپینگ در پایتون با کتابخانه selenium
برای بهکارگیری اپلیکیشن مرورگر وب برای وب اسکرپینگ در پایتون، وبدرایور و کتابخانه مربوطه را نصب میکنیم. سپس، از ماژول webdriver نمونهسازی کرده و با استفاده از متد get() ، مرورگر وب را برای صفحه وبی باز میکنیم که قصد بیرون کشیدن اطلاعاتی را از آن داریم.
کارکرد سلنیوم شامل بازکردن یک مرورگر و بارگذاری صفحه وب مورد نظر است. درست شبیه به کاری که هنگام مرور وب انجام میدهیم. در نتیجه، صفحه را اجرا میکند تا بتوانیم هر موردی که میخواهیم را از آن بیرون بکشیم. سلنیوم، اتوماسیون و خودکارسازی فعالیت مختلف در مرورگر را بهطور حیراتانگیزی انجام میدهد.
برای استفاده از سلنیوم با هدف انجام وب اسکرپینگ در پایتون، لازم است تا مواردی را با دستور زیر نصب کنیم.
$ pip3 install webdriver-manager Seleniumحال میتوانیم با اجرای کدهای آورده شده در ادامه، تگ تیتر سطح ۱ - یا h1 - این صفحه را برای نمونه، نمایش دهیم.
وب اسکرپینگ در پایتون با کتابخانه scrapy
برای اینکه بتوانیم اطلاعات مورد نظر را از صفحات وب را بهوسیله کتابخانه scrapy در پایتون استخراج کنیم. خزنده وب یا وب کراولر سفارشی خود را در پایتون میسازیم.
برای این منظور نیاز خواهیم داشت تا کتابخانههای مربوطه را نصب و از پوسته scrapy یا شی Selector() استفاده کنیم.

نخست، کتابخانههای لازم را با استفاده از دستور آورده شده در زیر نصب میکنیم.
$ pip3 install scrapy pyOpenSSL lxmlبا باز کردن ترمینال و اجرای دستور آورده شده در زیر، میتوانیم مروری سریع برای نمایش مواردی داشته باشیم که میتوان با scrapy انجام داد.
$ scrapy shellمیتوانیم دستورات زیر را امتحان کنیم.
همچنین میتوانیم از شی سلکتور Scrapy بههمراه requests برای استخراج اطلاعات از صفحه وب استفاده کنیم.
لزوم استفاده از پروکسی ها در وب اسکرپینگ با پایتون
وب اسکرپینگ با پایتون سرعت بسیار زیادی دارد و بار زیادی را به سرورهای میزبان تحمیل میکند. به همین دلیل، شرکتها سعی دارند تاحد ممکن، امکان فعالیت وب اسکرپینگ و رباتها را به منظور کاهش هزینهها، بلاک و مسدود کنند و مانع از کاهش سرعت تجربه کاربری خود شوند.
در برخی موارد، قابلیت کپچا را - برای تشخیص انسان از ربات - اضافه میکنند. در موارد دیگر User Agents-ها یا حتی یک آدرس IP را بهطور کامل مسدود میکنند. بههمین دلیل اگر بخواهیم وب اسکرپینگ را در مقیاس بزرگتری انجام دهیم اهمیت زیادی دارد تا IP-های چرخشی و پراکسیها را به کار ببریم.

برای اینکه بتوانیم از پراکسیها در پایتون استفاده کنیم، میتوانیم طبق روشهای گفته شده در ادامه، پراکسی خود را تهیه کنیم.
- پراکسیهای رایگانی را از وبسایتهایی مانند Proxyscrape پیدا کنیم، که تعداد زیادی از آنها در حال حاضر مسدود هستند.
- از سرویس های پولی استفاده کنیم که در ازای پرداخت هزینه، IP-های مورد نیازمان را فراهم میکنند.
پس از تهیه پراکسیها میتوانیم آنها را با درخواستهای پایتون بهوسیله ارسال یک دیکشنری به پارامتر Proxies درخواست get() بهکار ببریم.
موارد استفاده وب اسکرپینگ چیست؟
مواردی نظیر مقایسه قیمتها، جمعآوری آدرسهای ایمیل، دریافت دادهها از رسانههای اجتماعی، تحقیق و توسعه، آگهیهای استخدام و غیره را میتوان جزو کاربردهای وب اسکرپینگ دانست. در ادامه توضیحی در مورد هر یک فراهم کردهایم.

مقایسه قیمتها: سرویسهایی وجود دارند که به انجام وب اسکرپینگ برای دریافت دادههایی از فروشگاههای آنلاین میپردازند و این اطلاعات را برای مقایسه قیمت محصولات بهکار میبرند.
جمعآوری آدرسهای ایمیل: شرکتهای متعددی وجود دارند که از ایمیل بهعنوان ابزاری برای بازاریابی استفاده میکنند. این شرکتها با بهکارگیری وب اسکرپینگ، شناسه ایمیلها را جمعآوری کرده و برای ارسال ایمیلهای انبوه، مورد استفاده قرار میدهند.
دریافت دادهها از رسانههای اجتماعی: با بهکارگیری وب اسکریپت روی سایتهای رسانههای اجتماعی و دریافت اطلاعات از آنها میتوانیم بفهمیم که چه چیزی ترند - محبوب و پرطرفدار - شده است.

تحقیق و توسعه: وب اسکرپینگ را میتوان برای جمعآوری مجموعه بزرگی از دادههای آماری، عمومی، دما و غیره از وبسایتها بهکار برد. دادههای بهدست آمده را نیز تحلیل کرد و برای انجام ارزیابیها یا برای R&D یا تحقیق و توسعه بهکار برد.
آگهیهای استخدام: جزئیات مرتبط با موقعیتهای شغلی و مصاحبهها از وبسایتهای گوناگون جمعآوری شده و پس از آن در مکانی واحد فهرست شده تا به راحتی در دسترس کاربران باشد.
روشها و کاربردهای استخراج دادههای وب به همین موارد خلاصه نمیشود و در مواردی مانند آنچه در ادامه آورده شده نیز قابل استفاده است.
- اخبار و روزنامهنگاری
- نظارت بر سئو
- مدیریت ریسک و تحلیل رقبا
- بازاریابی دادهمحور
- پژوهشهای دانشگاهی
- خرید و فروش املاک و بسیاری موارد دیگر
فرق بین وب کرالینگ و وب اسکرپرپینگ در پایتون چیست؟
وب کرالر یا «خزنده وب» (Web Crawler) که بهطور معمول به آن اسپایدر هم گفته میشود، از ابزارهای هوش مصنوعی است که اینترنت را به منظور ایندکس کردن و جستجوی محتوا - بهوسیله دنبال کردن لینکها و کاوش - پیمایش میکند. در بسیاری از پروژهها، ابتدا وب یا وبسایت خاصی را Crawl کرده تا URL را پیدا کنیم. پس از آن، این URL-ها را به وب اسکرپر خود منتقل میکنیم.
در سویی دیگر، «اسکرپر» (Scraper) را داریم که ابزاری تخصصی است و به منظور واکشی دقیق و سریع دادهها از صفحات وب طراحی شده است. ابزارهای اسکرپینگ دادههای وب، با توجه به پروژه مورد نظر - به لحاظ طراحی و پیچیدگی - میتوانند بسیار متفاوت باشند. مهمترین بخش هر وب اسکرپر، سلکتورها هستند که برای یافتن دادههایی بهکار میروند که قصد استخراج آنها را ار فایل HTML داریم. بهطور معمول از XPath ،Regex، سلکتورهای CSS یا ترکیبی از این موارد استفاده میشود. دانستن فرق بین وب کرالر و وب اسکرپر به ما کمک میکند تا در پروژههای جمعآوری دادهها از وب، پیشتاز باشیم.
سوالات متداول
حال که با مفهوم وب اسکرپینگ و ابزارهای موجود برای این عملیات در پایتون آشنا شدیم و کدنویسی آن را با هم مرور کردیم نوبت به آن رسیده است که برخی از پرسشهای متداول مرتبط با وب اسکرپینگ را نیز در این قسمت مورد بررسی قرار دهیم.
چه ویژگیهایی پایتون را به گزینه مناسبی برای وب اسکرپینگ تبدیل میکند؟
فراهم کردن مجموعه گستردهای از کتابخانههای مرتبط، سهولت در استفاده، کدنویسی بهنسبت آسان، انجام کارهای بیشتر با حجم کدی کمتر، کامیونیتی فعال و داینامیکتایپ بودن را میتوان جزو ویژگیهایی دانست که وب اسکرپینگ در پایتون را به انتخاب مناسبی برای انجام این فرایند تبدیل میکند.
آیا وب اسکرپینگ در پایتون قانونی است؟
در مورد اینکه انجام عمل وب اسکرپینگ قانونی است یا خیر، میتوان گفت که تعدادی از وبسایتها این امکان را برای افراد فراهم میکنند و برخی دیگر اجازه جمعآوری دادهها از وبسایت خود را به ما نمیدهد. برای فهمیدن این مورد میبایست نگاهی به فایل robots.txt وبسایت مورد نظر بیندازیم. برا دسترسی به این فایل ، عبارت /robots.txt را به انتهای نشانی آن اضافه کنیم.
کتابخانههای پایتون برای وب اسکرپینگ کدام است؟
کتابخانههای متعددی برای این منظور وجود دارد اما Requests ،Scrapy و BeautifulSoup4 جزو محبوبترین آنها هستند.
جمعبندی
وب اسکرپینگ مهارت بسیار ارزشمندی است که در دنیای کنونی - با تولید حجم زیادی داده در هر ثانیه - میتوانیم کسب کنیم. دادهها همه جا هستند و اهمیت زیادی دارد تا قابلیت بیرون کشیدن راحت آنها را از منابع آنلاین بهدست آوریم.

گفتیم که وب اسکرپینگ رویهای است که طی آن با استفاده از رباتی نرمافزاری، دادههای موجود در وبسایت موردنظر را بیرون کشیده و در قالبی مناسب سازماندهی میکنیم. بدون استفاده از دانش وب اسکرپینگ، جمعآوری حجم زیادی از دادهها - برای تحیل، مصورسازی و انجام پیشبینیها - بسیار سخت خواهد بود.
بهطور کلی، این فرایند بهوسیله افراد و کسب و کارهایی مورد استفاده قرار میگیرد که میخواهند از دادهها و اطلاعات وب مورد دسترس عموم برای ایجاد نکات و بینشهای ارزشمند و همچنین تصمیمگیریهای هوشمندانهتر استفاده کنند.
با کتابخانههایی نظیر Requests و BeautifulSoup بهعنوان ابزارهایی برای وب اسکرپینگ نیز آشنا شدیم. بدون استفاده از این ابزارهای جمعآوری اطلاعات و بهجای آن، کپی و پِیست کردن دادهها بهصورت دستی از صفحات وبسایتها کار خستهکنندهای خواهد بود. کاری که میتواند با بهکارگیری قبلیتهای وب اسکرپینگ در کوتاهترین زمان ممکن انجام گیرد.







