



دسته بندی تصویری (Visual Binning) در SPSS – راهنمای کاربردی
همانطور که در نوشتارهای دیگر فرادرس خواندهاید، متغیرها و دادهها در SPSS به سه گروه «مقیاس» (Scale)، «ترتیبی» (Ordinal) و «اسمی» (Nominal) تقسیم میشوند. با استفاده از فرمان «دسته بندی تصویری» (Visual Binning) امکان تبدیل دادهها از نوع مقیاس به دادههای از نوع اسمی یا ترتیبی وجود دارد. برای انجام این کار روشهای مختلفی در فرمان Visual Binning در نظر گرفته شده است. در این نوشتار به بررسی این فرمان و تنظیمات و پارامترهای مورد نیاز برای اجرای آن میپردازیم. این فرمان در همه نسخههای SPSS قابل استفاده است.


برای آشنایی با انواع متغیرها بهتر است مطلب جامعه آماری — انواع داده و مقیاسهای آنها را بخوانید. از آنجایی که طبقهبندی کردن دادهها به ایجاد جدول فراوانی منجر میشود، خواندن مطلب جدول فراوانی برای دادههای کیفی و کمی — مثالهای کاربردی نیز ضروری به نظر میرسد. همچنین برای آشنایی با ویژگیهای جدید نسخه ۲۵ نرمافزار آماری SPSS خواندن مطلب امکانات جدید SPSS نسخه 2۵ که باید آنها را بدانید خالی از لطف نیست.
دسته بندی تصویری (Visual Binning)
حتما با متغیرهای عامل یا فاکتور آشنایی دارید. در نرمافزار SPSS، بعضی از تحلیلها باید براساس متغیر عامل یا متغیرهای طبقهای صورت بگیرد. بنابراین لازم است که در این موارد، یک متغیر از نوع مقیاس را به متغیری با ویژگی ترتیبی یا اسمی درآورد. برای مثال اگر بخواهیم یک نمودار برای مقایسه میانگین درآمد گروههای تحصیلی مختلف ایجاد کنیم، باید متغیر تحصیلات از نوع اسمی یا ترتیبی باشد. اغلب برای نشان دادن هر دو نوع متغیرهای اسمی و ترتیبی از عبارت متغیرهای طبقهای استفاده خواهیم کرد.
حتی برای ایجاد جدول فراوانی، باید متغیرهای کمی (مقیاس) را به دستههای مختلفی طبقهبندی کرد تا ردههای جدول فراوانی محدود و مناسب باشد. معمولا برای کارهای تحقیقاتی بهتر است که جدول فراوانی بین ۵ تا ۱۰ رده داشته باشد. اگر چنین جدول دارای ردههای بیشتر یا کمتری باشد، عملا خلاصهسازی دادهها که هدف ایجاد جدول فراوانی محقق نشده است.
از طرف دیگر اگر لازم است میزان رضایت شغلی (برحسب درصد) را با سطوح مختلف درآمدی بررسی کنیم، احتیاج است که متغیر درآمد به صورت طبقهای (Categorical) در بیاید. این کار را به کمک فرمان دستهبندی تصویری (Visual Binning) میتوان به راحتی انجام داد. در این نوشتار به کمک مجموعه داده نمونهای SPSS به نام DEMO.SAV مراحل انجام این کار را مرور خواهیم کرد و متغیر درآمد (income) را به صورت طبقهای درخواهیم آورد.
نکته: برچسب این متغیر به صورت Household income in thousands است. بنابراین اگر در پنجرههایی به جای income برچسب متغیر نمایش داده شود، منظور همان متغیر income است.
مسیر دسترسی به این فایل را در تصویر زیر ملاحظه میکنید.

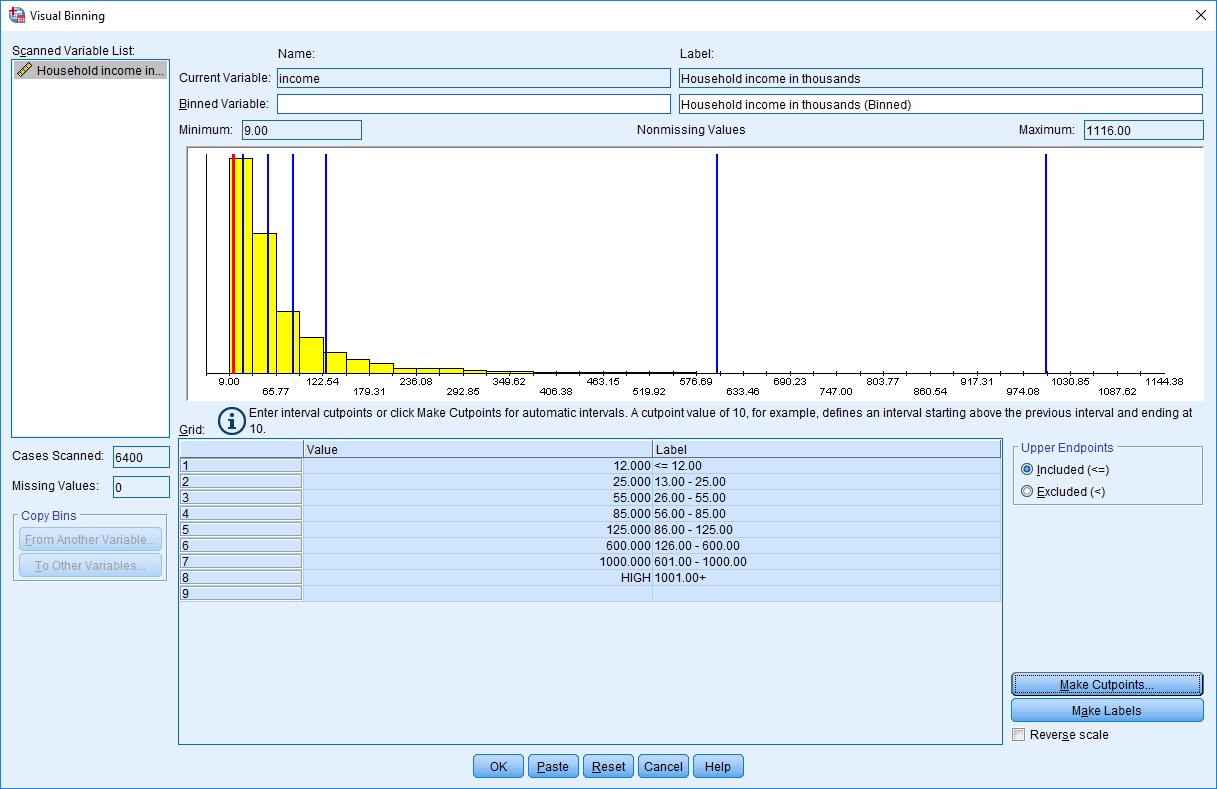
این فایل اطلاعاتی شامل 6400 مشاهده و 29 متغیر است. پس از باز کردن آن، صفحه نمایش مطابق تصویر زیر خواهد بود. متغیرها و مقدار آنها در سطرهای مختلف دیده میشود. در اینجا تمرکز بر روی متغیر income است که درآمد افراد برحسب هزار دلار در سال را نشان میدهد.

به منظور دسترسی به فرمان دستهبندی کردن دادهها به صورت تصویری، از فهرست Transform گزینه Visual Binning را انتخاب کنید. پنجرهای به شکل زیر ظاهر خواهد شد تا مشخص کنیم برای کدام متغیر باید این عمل صورت بگیرد. برای ایجاد دستهها، SPSS نیاز دارد بعضی از شاخصهای آماری را محاسبه کند. اگر دادهها حجیم باشند، محاسبه همه این شاخصها (مثل حداکثر، حداقل، میانگین و انحراف معیار) ممکن است زمانبر باشد، در نتیجه در پنجره Visual Binning با انتخاب گزینه Limit number of cases scanned to و تعیین مقدار مثلا ۱۰۰۰ به SPSS میگویید که از ۱۰۰۰ داده اول برای محاسبه این شاخصها استفاده کند.

با فشردن دکمه Continue وارد پنجره اصلی این فرمان خواهیم شد. در کادر Scanned Variable List اسامی متغیرهایی که باید تبدیل رویشان صورت بگیرد، مشاهده میشود. با انتخاب هر یک، شکل توزیع فراوانی به صورت یک بافتنگار فراوانی (Histogram) ظاهر میشود. همچنین حداکثر و حداقل مقادیر موجود در این متغیر در قسمتهای Minimum و Maximum قابل مشاهده است. در قسمت Cases Scanned تعداد مشاهدات مورد بررسی و در کادر Missing Values تعداد دادههای گمشده گزارش شدهاند.

پارامترهایی که باید در این پنجره تنظیم کنید، در جدول زیر معرفی شدهاند.
| پارامتر | عملکرد |
| Binned Variable (name) | نام متغیر جدید که از نوع طبقهای است |
| Binned Variable (label) | برچسب نام برای متغیر جدید |
| Value | تعیین نقاط برش (در حالت اولیه مقدار این گزینه HIGH به معنی بزرگترین مقدار است. |
| label | برچسب مقدار برای طبقه مورد نظر |
| Upper Endpoints --- Include (<=), Exclude (<) | انتخاب نقطه کران بالا فاصله در هر طبقه --- عدم انتخاب نقطه کران بالا فاصله در هر طبقه |
| Make Cutpoints... | ایجاد خودکار نقاط برش |
| Make Labels | ایجاد برچسبهای خودکار |
| Reverse scale | تعیین برچسبها به صورت معکوس (نزولی) |
اجرای دستهبندی تصویری توسط کاربر
دادههای فایل Demo.sav را در نظر بگیرید. فرض کنید بخواهیم دادههای مربوط به متغیر income را به طبقاتی مطابق جدول زیر تقسیم یا ردهبندی کنیم. در این مرحله تعیین کران برای طبقات یا ردهها توسط کاربر تعیین میشود. بنابراین نقاط برش (Cut points) به طور دلخواه، قابل تعیین است.

فقط باید توالی نقاط برش رعایت شود. البته اگر این ترتیب هنگام ورود رعایت نشود، SPSS به طور خودکار این ترتیب را اعمال خواهد کرد.
| شماره طبقه | کران پایین | کران بالا | برچسب |
| ۱ | از کمترین مقدار | 10 هزار دلار در سال | قشر ضعیف |
| ۲ | 11 هزار دلار در سال | 25 هزار دلار در سال | گروه متوسط |
| ۳ | 26 هزار دلار در سال | ۱۰۰ هزار دلار در سال | گروه درآمد مناسب |
| ۴ | 101 هزار دلار در سال | ۵۰۰ هزار دلار در سال | گروه ثروتمندان |
| ۵ | 501 هزار دلار در سال | بیشترین مقدار | گروه میلیاردرها |
مطابق جدول بالا، باید پنج رده تشکیل شود. برای ایجاد متغیر ردهبندی شده براساس اطلاعات این جدول در پنجره Visual Binning تنظیمات زیر را اجرا میکنیم. توجه داشته باشید که قرار است نتایج دادههای ردهبندی شده در متغیر income_group قرار گیرد.

کافی است که با طی کردن مراحل مطابق شمارههایی که در تصویر بالا دیده میشود، اقدام کنید. در مرحله شماره ۱، یک نام برای متغیر طبقهای جدید انتخاب کنید. باید توجه داشته باشید که در مرحله شماره ۲، ابتدا در سطر اول در ستون Value مقدار ۱۰ و در سطر دوم ۲۵ و ... را وارد کنید تا طبقهها معرفی شوند. در حقیقت این مقدارها تعیین کننده نقاط برش (Cut points) هستند. با استفاده از دکمه Make Labels نیز در مرحله شماره ۳، برچسبهایی به صورت خودکار در ستون Label قرار خواهند گرفت. با فشردن دکمه Ok پیغامی مبنی بر ایجاد یک متغیر جدید مشاهده خواهید کرد.

با مراجعه به پنجره ویرایشگر دادهها (Data Editor) در ستون آخر جدول اطلاعاتی متغیر group_income قابل مشاهده است.

نکته: با توجه به خطوطی که در نمودار فراوانی در پنجره Visual Binningایجاد شده، میتوانید ردهها را تغییر یا ایجاد کنید. کافی است خطوط را با روش کشیدن و رها کردن (Drag & Drop) جابجا کنید. خط قرمز رنگ در این نمودار نشان دهند رده فعال است به این معنی که در جدول مربوط به Grid آن رده انتخاب شده است.
اجرای دستهبندی تصویری محاسباتی
در این روش، نقاط برش توسط SPSS محاسبه میشود و کاربر فقط تعداد نقاط برش یا فاصله بین کرانهای هر رده را مشخص میکند. معمولا استفاده از این روش، نظم خاصی در ردهها یا طبقات ایجاد خواهد کرد. برای انجام این کار از داخل پنجره Visual Binning دکمه Make Cutpoints را بزنید. پنجرهای به صورت زیر ظاهر خواهد شد.

همانطور که در تصویر میبینید، سه روش برای ایجاد نقاط برش معرفی شدهاند.
طول ثابت برای طبقات یا ردهها (Equal Width Intervals)
در این حالت، با تعیین اولین نقطه برش و تعداد نقاط برش یا فاصله بین کرانهای طبقات، نقاط برش تعیین میشوند. برای مثال میتوان به کمک این انتخاب طبقاتی به صورت ۰-۱۰، ۱۱-۲۰، ۲۱-۳۰ و ... ایجاد کرد. مشخص است که طول هر رده در اینجا برابر با ۱۰ است. روش محاسباتی برای تعیین طول رده این حالت به صورت زیر خواهد بود.
مشخص است که در این محاسبات دامنه تغییرات (Range) بوسیله اندازهگیری فاصله بین بزرگترین (Maximum) و کوچکترین (Minimum) مقدار بدست آمده و در صورت کسر قرار دارد. در مخرج کسر نیز تعداد نقاط برش دیده میشود. نسبت این دو طول رده را محاسبه میکند.
به این ترتیب براساس اولین نقطه برش که در قسمت First Cutpoint Location مشخص میشود اولین گروه با کران پایین «کمترین مقدار» و کران بالای «اولین نقطه برش» ساخته میشود. طبقات بعدی نیز از «کران بالای رده قبلی+1» شروع شده و کران بالا نیز براساس افزودن مقدار «طول رده» یا همان Width به کران پایین معرفی میشود. پس از ورود این پارامترها، محل آخرین نقطه برش در قسمت Last Cutpoint Location محاسبه و نمایش داده میشود.
نکته: ممکن است لازم باشد به جای محاسبه طول ردهها (Width)، تعداد طبقات محاسبه شود. بنابراین کافی است ابتدا اولین نقطه برش و سپس طول ردهها را وارد کنید. به طور خودکار SPSS تعداد نقاط برش را محاسبه میکند.
فرض کنید که میخواهیم درآمد (income) را به ۱1 طبقه تقسیم کنیم بطوری که فاصله بین طبقات برابر با ۱۰ واحد باشد. تنظیمات این پنجره را مطابق با تصویر زیر-سمت چپ ایجاد میکنیم. با فشردن دکمه Apply به پنجره Visual Binning برگشته و اگر برچسبها را با دکمه Make Labels ایجاد کنید، طبقات مطابق تصویر زیر-سمت راست دیده خواهند شد.

نکته: باید در نظر بگیرید که تعداد طبقات همیشه یکی بیشتر از تعداد نقاط برش هستند. بنابراین برای ایجاد ۱۱ طبقه از ۱۰ نقطه برش استفاده کردهایم. مشخص است که آخرین نقطه برش نیز برابر با ۱۰۰۵.۴۰ بدست آمده است.
تعداد ثابت برای طبقات (Equal Percentiles Based on Scanned Cases)
اگر بخواهیم در هر طبقه، درصد ثابت یا یکسانی از دادهها قرار گیرند، این روش مناسب به نظر میرسد. بنابراین برای مثال اگر بخواهیم دادهها را براساس چارکها طبقهبندی کنیم، SPSS براساس دادهها چارکها، را محاسبه کرده و نقاط برش را طوری تعیین میکند که در هر طبقه ۲۵٪ از دادهها قرار گیرند. به این ترتیب اگر تعداد نقاط برش (Number of Cutpoints) را مقدار ۳ در نظر بگیریم، در حقیقت چارکها را مبنا قرار دادهایم و نقاط برش همان چارک اول و دوم و سوم خواهند بود. در این حالت بطور خودکار مقدار Width(%) برابر با ۲۵٪ محاسبه خواهد شد. برعکس میتوان مقدار درصدها یا همان Width(%) را مشخص کرد.آنگاه تعداد نقاط برش توسط SPSS بطور خودکار محاسبه خواهد شد.
نکته: محاسبه شاخصهایی مانند چارک، دهک و ... براساس دادههایی صورت میگیرد که در هنگام ورود به پنچره Visual Binning در قسمت Limit number of cases scanned to تعیین کردهاید.
در تصویر زیر فرض بر این است که میخواهیم جامعه را براساس دهکها ردهبندی کنیم. بنابراین تعداد نقاط برش را برابر با ۹ در نظر میگیریم، یا درصد Width را ۱۰ قرار میدهیم. همانطور که در تصویر سمت راست دیده میشود، ده رده یا طبقه ایجاد شدهاند.

نکته: پس از ایجاد متغیر طبقهای، متاسفانه نمیتوان روش ایجاد آن را با باز کردن مجدد پنجره Visual Binning مشاهده کرد. بنابراین همیشه ملاک و روش ایجاد متغیر طبقهای را یادداشت کنید تا نحوه محاسبات و شیوه ایجاد آن فراموش نشود.
فرض کنید نام این متغیر را percentile گذشتهایم. حال میخواهیم بر این اساس یک جدول فراوانی تشکیل دهیم تا مشخص شود آیا در هر رده تقریبا ۱۰ درصد دادهها قرار دارند یا خیر. از فهرست Analysis گزینه Descriptive Statistics و فرمان Frequency را اجرا میکنیم.

کافی است که از این متغیر برای ایجاد جدول فراوانی استفاده کنیم و نتیجه را مطابق تصویر زیر ایجاد کنیم. مشخص است که در هر رده یا طبقه، تقریبا درصد فراوانیها یکسان است. البته اختلاف از ۱۰٪ از آن جهت پیش آمده است که ممکن است یک مقدار از درآمد بیش از یکبار وجود داشته باشد و چون برای مثال مقدار ۲۰ به تعداد ۵ بار تکرار شده، درصد برای آن رده کمی بیش از ۱۰ درصد در نظر گرفته شده است. به همین ترتیب نیز ممکن است بعضی از ردهها دارای درصدی کمتر از ۱۰٪ باشند. ولی به هر حال مقادیر درصدها به ۱۰ نزدیک هستند.

تعیین نقاط برش برحسب میانگین و فاصله برحسب انحراف معیار از میانگین (Cutpoints at Means and Selected Standard Deviation Bases on Scanned Cases)
در این روش، با استفاده از میانگین، نقاط برش تعیین میشوند. فرض کنید میخواهید دادههای درآمد را برحسب اینکه سطح درآمدی چه میزان از میانگین فاصله دارند طبقهبندی کنید. در این حالت میزان فاصله از میانگین نیز برمبنای انحراف معیار اندازهگیری میشود. با انتخاب این روش، میتوانید ضرایب فاصله از میانگین را برابر با ۱، ۲ یا حداکثر ۳ انحراف معیار تعیین کنید. اگر همه گزینهها را انتخاب کنید دارای هفت نقطه برش خواهید شد که ۸ طبقه یا رده را تعیین خواهند کرد. اگر براساس متغیر طبقهای که به این ترتیب ایجاد کردهاید یک جدول فراوانی یا بافتنگار فراوانی (Histogram) بسازید، میتوانید مطابقت آن را با توزیع نرمال بسنجید زیرا در توزیع نرمال درصدی از دادهها که در این فاصلهها از میانگین قرار میگیرند مشخص است.
تنظیمات را در تصویر زیر سمت چپ و نتایج را در تصویر سمت راست میبینید.

همانطور که دیده میشود، ۸ رده ایجاد شده است. با توجه به اینکه ننتیجه این رده بندی در متغیر $$mean\ـand\ـstandard\ـdeviation$$
نکته: اسامی متغیرها نمیتواند با فاصله خالی (Space) همراه باشد بنابراین از «ـ» برای جداسازی قسمتهای مختلف نام متغیر استفاده کردهایم. همچنین توجه داشته باشید اگر از قبل در پنجره Visual Binning رده یا طبقهها را معرفی کرده باشید، با فشردن دکمه Apply طبقاتی که به روش خودکار ایجاد کردهاید، جایگزین ردههای قبلی خواهند شد.
برای ایجاد هیستوگرام کافی است از فهرست Analysis گزینه Descriptive Statistics و فرمان Frequency را اجرا کنیم. با انتخاب دکمه Chart نیز رسم نمودار هیستوگرام به همراه منحنی نرمال را درخواست میکنیم. با اجرای این مراحل برای متغیر مورد نظر، تنظیمات مطابق با تصویر زیر خواهد بود.

نتیجه مطابق تصویر زیر ظاهر خواهد شد. مشخص است که این نمودار با توزیع نرمال فاصله بسیار زیادی دارد. این امر نشان میدهد که توزیع درآمدی در جامعه به صورت نرمال توزیع نشده است و کاملا به سمت راست چولگی دارد.

اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای نرمافزارهای آماری
- مجموعه آموزشهای SPSS
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آزمون لون (Levene’s Test) برای برابری واریانس ها در SPSS — راهنمای کاربردی
- آزمون میانگین نمونه تکی در SPSS — راهنمای کاربردی
- داده های گمشده در SPSS — راهنمای کاربردی
^^











خیلی عاالی..واقعا ممنون