



استفاده از Deep Q–learning در FIFA 2018 برای بهینه سازی ضربه آزاد
کیو-یادگیری عمیق (Deep Q-learning) نوعی از تکنیکهای یادگیری تقویتی است. در این نوشته از این تکنیک یادگیری تقویتی (Reinforcement Learning) در تنسورفلو (TensorFlow) به منظور بهینهسازی نواختن ضربههای آزاد استفاده شده است.





در این مقاله توضیح کوتاهی از مفهوم یادگیری تقویتی ارائه شده است و سپس چگونگی استفاده از آن در بازی فیفا 2018 بررسی شده است. یک چالش عمده در پیادهسازی این رویکرد این است که ما به کد بازی دسترسی نداریم و از این رو تنها میتوانیم از آنچه روی صفحه بازی میبینیم بهره بگیریم. به همین دلیل نمیتوان هوش مصنوعی را روی کل بازی تعلیم داد؛ اما برای پیادهسازی این تکنیک روی بازیهای مهارتی در حالت تمرین راهحلی یافتیم. در این نوشته تلاش کردهایم تا ربات بازیکن را با زدن ضربات آزاد از فاصله 30 یاردی تعلیم دهیم؛ اما شما میتوانید کد ارائه شده را برای تعلیم مهارتهای دیگر اصلاح کنید. ابتدا اجازه بدهید ببینیم یادگیری تقویتی چیست و چگونه میتوانیم مسئله ضربه آزاد خود را برای استفاده از این تکنیک فرمولبندی کنیم.
یادگیری تقویتی (و کیو-یادگیری عمیق) چیست؟
در یادگیری تقویتی برخلاف یادگیری نظارتشده لازم نیست دادههای آموزشی را به صورت دستی برچسب بزنیم. در عوض با محیط خود تعامل برقرار میکنیم و خروجی تعامل را مشاهده میکنیم. ما این فرایند را چندین بار تکرار میکنیم و نمونههایی از تجربههای مثبت و منفی به دست میآوریم که به عنوان دادههای آموزشی ما عمل میکنند. از این رو ما از روی تجربه کردن یاد میگیریم و نه تقلید.
فرض کنید محیط ما در حالت خاص s باشد و به محض اتخاذ اقدام a به حالت s’ برود. برای این اقدام خاص پاداش بیدرنگی که در محیط مشاهده میکنید به صورت r است. هر مجموعه از اقداماتی که از این اقدام پیروی کنند، پاداشهای بی درنگ خودشان را خواهند داشت، تا این که شما به دلیل بروز یک تجربه مثبت یا منفی خاص تعامل را متوقف کنید. اینها پاداشهای آتی نامیده میشوند. بنابراین برای حالت کنونی s تلاش میکنیم همه اقدامهای ممکن که پاداش بی درنگ + آتی بیشینه را به دست میدهد، تخمین بزنیم. این مقدار با (Q(s.a نشان داده و تابع کیو (Q) نامیده میشود. بدین ترتیب داریم:
Q(s,a) = r + γ * Q(s’,a’) Q(s,a) = r + γ * Q(s’,a’)
که پاداش نهایی را با اتخاذ اقدام a در حالت s نشان میدهد. در این جا γ عامل تخفیف است که برای عدم قطعیت در پیش بیتی آتی در نظر گرفته میشود و از این رو میخواهیم به حال، اندکی بیش از آینده اعتماد کنیم.
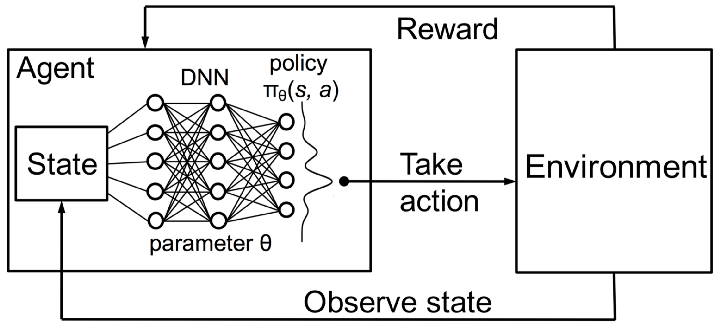
کیو-یادگیری عمیق (Deep Q-learning) نوعی از تکنیکهای یادگیری تقویتی است که در آن تابع Q به وسیله شبکه عصبی عمیق آموزش داده میشود. با توجه به این که حالت محیط به صورت یک ورودی برای این شبکه است، این تکنیک تلاش میکند تا پاداش نهایی مورد انتظار برای همه اقدامهای ممکن مانند یک مسئله رگرسیون را پیشبینی کند. اقدام دارای بالاترین مقدار کیو پیشبینیشده به عنوان اقدام منتخب ما در محیط انجام میگیرد. از این رو این تکنیک به نام کیو-یادگیری عمیق نامیده میشود.
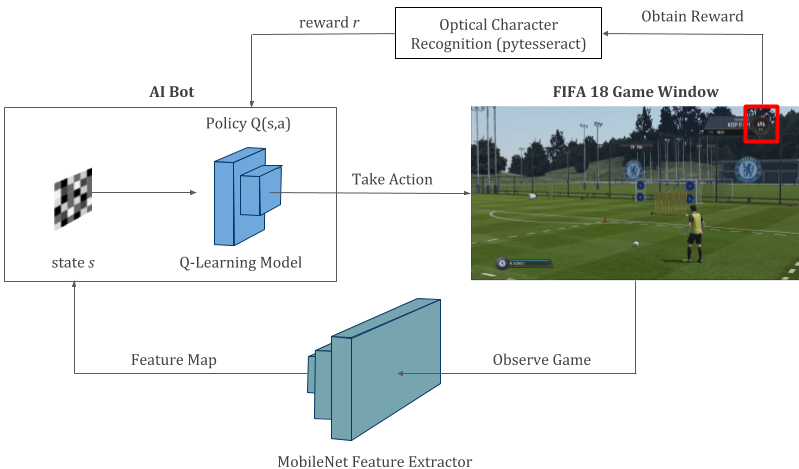
فرمولبندی ضربههای آزاد در FIFA به صورت یک مسئله کیو–یادگیری
- حالتها: تصاویر اسکرینشات بازی با استفاده از CNN (شبکه عصبی کانولوشنی) MobileNet با ارائه نگاشت ویژگی 128 بعدی مسطح شده (128-dimensional flattened feature map) مورد پردازش قرار گرفت.
- اقدامها: چهار اقدام ممکن که میتوانیم انجام دهیم به صورت shoot_low, shoot_high, move_left, move_right هستند.
- پاداش: اگر بعد از انجام شوت، امتیاز درون بازی بیش از 200 واحد افزایش یابد، یک هدف ثبت میکنیم و از این رو r=+1. اگر نتوانیم گل بزنیم، امتیاز همان r=-1 میماند. در نهایت r=0 برای اقدامهایی مانند حرکت به راست یا چپ است.
- سیاست: شبکه متراکم دولایهای که نگاشت ویژگی را به عنوان ورودی میگیرد و پاداش نهایی کلی را برای هر 4 اقدام محاسبه میکند.
توجه: اگر یک معیار عملکردی در حالت ضربه آزاد FIFA همانند آنچه در حالت تمرین دیدیم، وجود میداشت، شاید میتوانستیم این مسئله را برای کل بازی نیز فرمولبندی کنیم و خودمان را به ضربههای آزاد محدود نمیکردیم. بنابراین یا باید این شرایط برقرار باشد و یا به کدهای داخلی بازی دسترسی داشته باشیم که نداریم. در هر حال سعی میکنیم از آنچه داریم بیشترین استفاده را بکنیم.
نتایج
با این که ربات همه انواع مختلف ضربههای آزاد را تمرین نکرده بود، برخی موقعیتها را بسیار خوب یاد گرفت. این رباتِ بازیکن تقریباً در اغلب موارد، در صورت عدم وجود دیواره بازیکنان به هدف میزد؛ اما در صورت وجود چنین دیوارهای به تقلا میافتاد. ضمناً وقتی با موقعیتی مواجه میشد که به طور مکرر مشغول آموزش بود و نمیتوانست گل بزند، حرکات عجیب و غریبی انجام داد. با این حال با افزایش مراحل آموزش، این رفتار به طور میانگین رو به کاهش گذاشت.
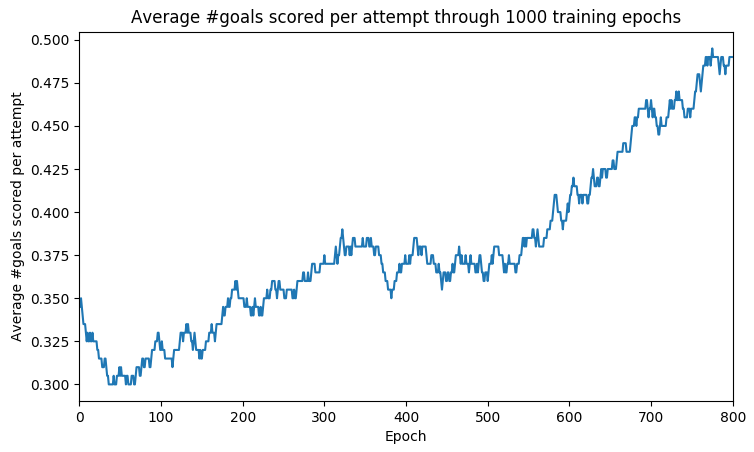
همان طور که در تصویر فوق مشخص است، نرخ امتیازهای گل پس از 1000 تکرار به طور میانگین از 30% به 50% افزایش یافته است. این بدان معنی است که این رباتتقریباً نیمی از ضربات آزاد خود را گل میکند. برای مقایسه باید گفت که بازیکن انسانی به طور معمول 75 تا 80% از این ضربهها را گل میکند. به این نکته توجه کنید که FIFA میل دارد با اندکی عدم قطعیت عمل کند و از این رو یادگیری بسیار دشوار است.


اگر میخواهید نتایج بیشتری را به صورت ویدئویی مشاهده کنید میتوانید به این کانال یوتیوب مراجعه کنید.
پیادهسازی کد
کد این تکنیک در پایتون و با استفاده از تنسورفلو (Keras) برای یادگیری عمیق و pytesseract برای OGR پیادهسازی شده است. در این لینک گیت کد برنامه به همراه دستورالعملهای مورد نیاز در توصیف ریپازیتوری ارائه شده است.
در ادامه کدهای اصلی به منظور درک این آموزش ارائه شده است؛ اما برای مشاهده کامل کد به لینک گیت فوق مراجعه کنید. در ادامه چهار بخش اصلی کد بررسی شده است.
1. تعامل با محیط بازی
ما هیچ API آماده نداریم که باعث شود به کد برنامه دسترسی داشته باشیم. بنابراین خودمان یک API میسازیم. ما از اسکرینشاتهای بازی برای مشاهده حالت استفاده میکنیم، فشردن دکمهها برای انجام اقدامها در محیط بازی شبیهسازیشده است و از شناسایی نوری کاراکتر (Optical Character Recognition) برای خواندن امتیاز ضربههای آزاد در بازی استفاده شده است. ما سه متد اصلی درکلاس FIFA خود داریم: ()observe(), act(), _get_reward و یک متد اضافی که ()is_over نام دارد برای بررسی این که شوت انجام یافته یا نه استفاده میشود.
class FIFA(object):
"""
This class acts as the intermediate "API" to the actual game. Double quotes API because we are not touching the
game's actual code. It interacts with the game simply using screen-grab (input) and keypress simulation (output)
using some clever python libraries.
"""
# Define actions that our agent can take and the corresponding keys to press for taking that action.
actions_display_name = ['shoot low', 'shoot high', 'move left', 'move right']
key_to_press = [spacebar, spacebar, leftarrow, rightarrow]
# Initialize reward that will act as feedback from our interactions with the game
self.reward = 0
def __init__(self):
# Create a CNN graph object that will process screenshot images of the game.
self.cnn_graph = CNN()
# Observe our game environment by taking screenshot of the game.
def observe(self):
# Get current state s from screen using screen-grab and narrow it down to the game window.
screen = grab_screen(region=None)
game_screen = screen[25:-40, 1921:]
# Process through CNN to get the feature map from the raw image. This will act as our current state s.
return self.cnn_graph.get_image_feature_map(game_screen)
# Press the appropriate key based on the action our agent decides to take.
def act(self, action):
# If we are shooting low (action=0) then press spacebar for just 0.05s for low power.
# In all other cases press the key for a longer time.
PressKey(key_to_press[action])
time.sleep(0.05) if action == 0 else time.sleep(0.2)
ReleaseKey(key_to_press[action])
# Wait until some time after taking action for the game's animation to complete.
# Taking a shot requires 5 seconds of animation, otherwise the game responds immediately.
time.sleep(5) if action in [0, 1] else time.sleep(1)
# Once our environment has reacted to our agent's actions, we fetch the reward
# and check if the game is over or not (ie, it is over once the shot been taken)
reward = self._get_reward(action)
game_over = self._is_over(action)
return self.observe(), reward, game_over
# Get feedback from the game - uses OCR on "performance meter" in the game's top right corner.
# We will assign +1 reward to a shot if it ends up in the net, a -1 reward if it misses the net
# and 0 reward for a left or right movement.
def _get_reward(self, action):
screen = grab_screen(region=None)
game_screen = screen[25:-40, 1921:]
# Narrow down to the reward meter at top right corner of game screen to get the feedback.
reward_meter = game_screen[85:130, 1650:1730]
i = Image.fromarray(reward_meter.astype('uint8'), 'RGB')
try:
# Use OCR to recognize the reward obtained after taking the action.
ocr_result = pt.image_to_string(i)
ingame_reward = int(''.join(c for c in ocr_result if c.isdigit()))
# Determine if the feedback is positive or not based on the reward observed.
# Also update our reward object with latest observed reward.
if ingame_reward - self.reward > 200:
# If ball goes into the net, our ingame performance meter increases by more than 200 points.
self.reward = ingame_reward
action_reward = 1
elif self._is_over(action):
# If ball has been shot but performance meter has not increased the score, ie, we missed the goal.
self.reward = ingame_reward
action_reward = -1
else:
# If ball hasn't been shot yet, we are only moving left or right.
self.reward = ingame_reward
action_reward = 0
except:
# Sometimes OCR fails, we will just assume we haven't scored in this scenario.
action_reward = -1 if self._is_over(action) else 0
return action_reward
def _is_over(self, action):
# Check if the ball is still there to be hit. If shoot action has been initiated,
# the game is considered over since you cannot influence it anymore.
return True if action in [0, 1] else False
2. گردآوری دادههای آموزشی
ما در سراسر فرایند آموزش، همه تجربیات و پاداشهای مشاهده شده را ذخیره کردیم. از این دادههای آموزشی برای مدل کیو-یادگیری استفاده شده است. بنابراین برای هر اقدامی که انجام میگیرد، تجربه <s, a, r, s’> را به همراه فلگ game_over ذخیره میکنیم. برچسب نهایی که مدل ما برای آموزش استفاده میکند، پاداش نهایی برای هر اقدام است که عدد حقیقی برای مسئله رگرسیون ما محسوب میشود.
class ExperienceReplay(object):
"""
During gameplay all the experiences < s, a, r, s’ > are stored in a replay memory.
In training, batches of randomly drawn experiences are used to generate the input and target for training.
"""
def __init__(self, max_memory=100000, discount=.9):
"""
Setup
max_memory: the maximum number of experiences we want to store
memory: a list of experiences
discount: the discount factor for future experience
In the memory the information whether the game ended at the state is stored seperately in a nested array
[...
[experience, game_over]
[experience, game_over]
...]
"""
self.max_memory = max_memory
self.memory = list()
self.discount = discount
def remember(self, states, game_over):
# Save a state to memory
self.memory.append([states, game_over])
# We don't want to store infinite memories, so if we have too many, we just delete the oldest one
if len(self.memory) > self.max_memory:
del self.memory[0]
def get_batch(self, model, batch_size=10):
# How many experiences do we have?
len_memory = len(self.memory)
# Calculate the number of actions that can possibly be taken in the game.
num_actions = model.output_shape[-1]
# Dimensions of our observed states, ie, the input to our model.
env_dim = self.memory[0][0][0].shape[1]
# We want to return an input and target vector with inputs from an observed state.
inputs = np.zeros((min(len_memory, batch_size), env_dim))
# ...and the target r + gamma * max Q(s’,a’)
# Note that our target is a matrix, with possible fields not only for the action taken but also
# for the other possible actions. The actions not take the same value as the prediction to not affect them
targets = np.zeros((inputs.shape[0], num_actions))
# We draw states to learn from randomly
for i, idx in enumerate(np.random.randint(0, len_memory,
size=inputs.shape[0])):
"""
Here we load one transition <s, a, r, s’> from memory
state_t: initial state s
action_t: action taken a
reward_t: reward earned r
state_tp1: the state that followed s’
"""
state_t, action_t, reward_t, state_tp1 = self.memory[idx][0]
# We also need to know whether the game ended at this state
game_over = self.memory[idx][1]
# add the state s to the input
inputs[i:i + 1] = state_t
# First we fill the target values with the predictions of the model.
# They will not be affected by training (since the training loss for them is 0)
targets[i] = model.predict(state_t)[0]
"""
If the game ended, the expected reward Q(s,a) should be the final reward r.
Otherwise the target value is r + gamma * max Q(s’,a’)
"""
# Here Q_sa is max_a'Q(s', a')
Q_sa = np.max(model.predict(state_tp1)[0])
# if the game ended, the reward is the final reward
if game_over: # if game_over is True
targets[i, action_t] = reward_t
else:
# r + gamma * max Q(s’,a’)
targets[i, action_t] = reward_t + self.discount * Q_sa
return inputs, targets
3. فرایند آموزش
اینک که میتوانیم با بازی تعامل کنیم و تعاملهای خود را در حافظه ذخیرهسازیم، شروع به آموزش دادن مدل کیو-یادگیری خود میکنیم. بدین منظور یک تعادل بین کشف (انجام یک اقدام تصادفی در بازی) و بهرهبرداری (انجام اقدم پیشبینیشده از سوی مدل) رعایت میکنیم. بدین ترتیب میتوانیم از روش آزمون و خطا برای به دست آوردن تجربیات مختلف در بازی استفاده کنیم.
پارامتر epsilon بدین منظور استفاده میشود که به عنوان یک عامل با کاهش نمایی برای ایجاد تعادل بین وجوه کشف و بهرهبرداری در مدل مورد استفاده قرار میگیرد. در آغاز، زمانی که هیچ نمیدانیم، میخواهیم کشف بیشتری داشته باشیم؛ اما وقتی تعداد تکرارها بالاتر میرود و دانستههایمان افزایش مییابد، میخواهیم بهرهبرداری بیشتری داشته باشیم و کشف را کاهش دهیم. بنابراین مقدار رو به کاهشی برای پارامتر epsion در نظر گرفتهایم.
در این راهنما به دلیل محدودیتهای زمانی و عملکردی، مدل را تنها برای 1000 تکرار آموزش دادیم؛ اما در آینده آن را به 5000 تکرار افزایش خواهیم داد.
# parameters
max_memory = 1000 # Maximum number of experiences we are storing
batch_size = 1 # Number of experiences we use for training per batch
exp_replay = ExperienceReplay(max_memory=max_memory)
# Train a model on the given game
def train(game, model, epochs, verbose=1):
num_actions = len(game.key_to_press) # 4 actions [shoot_low, shoot_high, left_arrow, right_arrow]
# Reseting the win counter
win_cnt = 0
# We want to keep track of the progress of the AI over time, so we save its win count history
# indicated by number of goals scored
win_hist = []
# Epochs is the number of games we play
for e in range(epochs):
loss = 0.
# epsilon for exploration - dependent inversely on the training epoch
epsilon = 4 / ((e + 1) ** (1 / 2))
game_over = False
# get current state s by observing our game environment
input_t = game.observe()
while not game_over:
# The learner is acting on the last observed game screen
# input_t is a vector containing representing the game screen
input_tm1 = input_t
# We choose our action from either exploration (random) or exploitation (model).
if np.random.rand() <= epsilon:
# Explore a random action
action = int(np.random.randint(0, num_actions, size=1))
else:
# Choose action from the model's prediction
# q contains the expected rewards for the actions
q = model.predict(input_tm1)
# We pick the action with the highest expected reward
action = np.argmax(q[0])
# apply action, get rewards r and new state s'
input_t, reward, game_over = game.act(action)
# If we managed to score a goal we add 1 to our win counter
if reward == 1:
win_cnt += 1
"""
The experiences < s, a, r, s’ > we make during gameplay are our training data.
Here we first save the last experience, and then load a batch of experiences to train our model
"""
# store experience
exp_replay.remember([input_tm1, action, reward, input_t], game_over)
# Load batch of experiences
inputs, targets = exp_replay.get_batch(model, batch_size=batch_size)
# train model on experiences
batch_loss = model.train_on_batch(inputs, targets)
loss += batch_loss
if verbose > 0:
print("Epoch {:03d}/{:03d} | Loss {:.4f} | Win count {}".format(e, epochs, loss, win_cnt))
# Track win history to later check if our model is improving at the game over time.
win_hist.append(win_cnt)
return win_hist
4. تعریف مدل و آغاز فرایند آموزش
در قلب فرایند کیو-یادگیری یک شبکه متراکم کاملاً متصل 2 لایه با فعالسازی ReLU قرار دارد. این شبکه نگاشت ویژگی 128 بعدی را به عنوان حالت ورودی میگیرد و 4 مقدار کیو برای هر اقدام ممکن در خروجی ارائه میدهد. اقدامی که دارای بیشترین مقدار کیو پیشبینیشده، اقدام مطلوب است که بر اساس سیاست شبکه برای حالت مفروض اتخاذ میشود.
# Number of games played in training. # Trained on 1000 epochs till now, but would ideally like to train for 5000 epochs at least. epochs = 1000 game = FIFA() # Our model's architecture parameters input_size = 128 # The input shape for model - this comes from the output shape of the CNN Mobilenet num_actions = len(game.key_to_press) hidden_size = 512 # Setting up the model with keras. model = Sequential() model.add(Dense(hidden_size, input_shape=(input_size,), activation='relu')) model.add(Dense(hidden_size, activation='relu')) model.add(Dense(num_actions)) model.compile(sgd(lr=.01), "mse") # Training the model hist = train(game, model, epoch, verbose=1)
این همان نقطه آغاز اجرای کد است؛ اما ابتدا باید اطمینان حاصل کنید که FIFA 18 در حالت پنجرهای در نمایشگر ثانویه اجرا شده است و حالت تمرین ضربه آزاد را در بخش بازیهای مهارتی در منوی shooting بارگذاری کردهاید. مطمئن شوید که کنترلهای بازی با کلیدهایی که در اسکریپت FiFa.py هارد کد کردهاید مطابقت دارند.
نتیجهگیری
در مجموع میتوان گفت که نتایج این تحقیق کاملاً رضایتبخش است، گرچه ربات بازیکن نتوانست به سطح عملکرد انسانی برسد. سوئیچ کردن از تکنیکهای یادگیری نظارتشده به تکنیکهای یادگیری تقویتی به کاهش زحمت گردآوری دادههای آموزشی کمک میکند. این تکنیک،. با دادن زمان کافی برای کشف، در مسائلی مانند یادگیری چگونگی اجرای بازیهای ساده بسیار خوب عمل میکند. با این حال به نظر میرسد که یادگیری تقویتی وقتی با موقعیتهای ناآشنای بیشمار مواجه میشود ناتوان است. این مسئله نشان میدهد که فرمولبندی چنین مسائلی به صورت مسئله رگرسیون نمیتواند اطلاعات را به خوبی فرمولبندیِ آن به صورت یک مسئله طبقهبندی کلاسیک در شرایط یادگیری نظارتشده، برونیابی کند.

شاید ترکیبی از هر دو این تکنیکهای یادگیری بتواند نقاط ضعف هر دو را برای این رویکردها پوشش دهد. احتمالاً این همان رویکردی است که باعث میشود بهترین نتایج را در ساخت هوش مصنوعی برای بازیها داشته باشیم. این مسئلهای است که تحقیقات آینده آن را مشخص خواهد کرد.
اگر این نوشته مورد توجه شما واقع شده، پیشنهاد میکنیم موارد زیر را نیز ملاحظه کنید:
- آموزش یادگیری تقویتی – Reinforcement Learning
- Q-Learning و یادگیری تقویتی — خودآموز سریع و جامع
- یادگیری تقویتی (Reinforcement Learning) — راهنمای ساده و کاربردی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- چارچوبی برای یادگیری تقویتی (Reinforcement Learning) توسط گوگل
- آموزش یادگیری عمیق (Deep learning)
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
==







