



انواع الگوریتم های جستجو و Hash Table – راهنمای جامع
در این نوشته از مجموعه مطالب ساختمان داده انواع مختلف الگوریتمهای جستجو را معرفی میکنیم و با مفهومی به نام جدول hash آشنا میشویم. این الگوریتمها شامل الگوریتم جستجوی خطی، جستجوی باینری و جستجوی درونیابی است. در نهایت مفهوم جدول hash معرفی شده است. همه موارد فوق به همراه کدها و شیوه پیادهسازی در زبان C ارائه شدهاند.

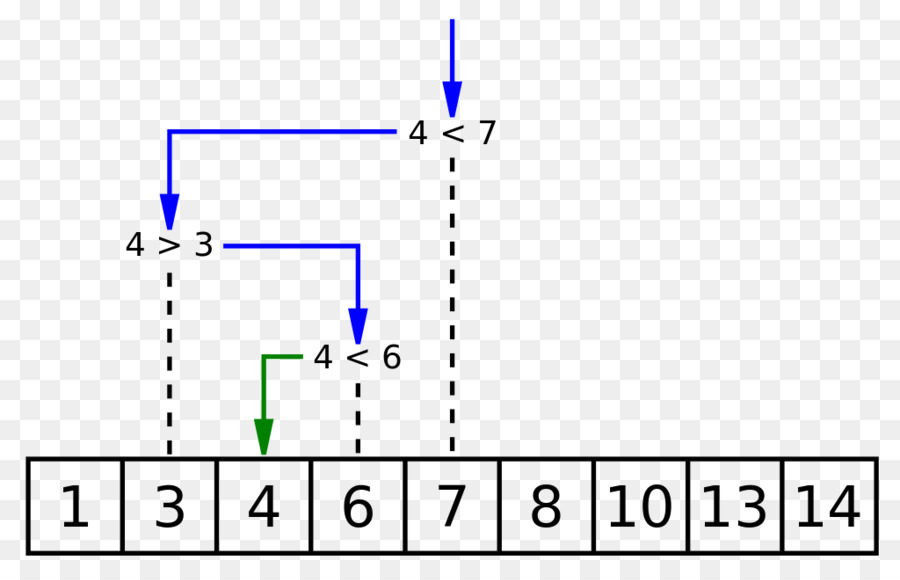


جستجوی خطی
جستجوی خطی یک الگوریتم جستجوی بسیار ساده است.
در این نوع جستجو، یک جستجوی ترتیبی بر روی تکتک آیتمها صورت میگیرد. هر آیتم بررسی میشود و در صورتی که مطابقتی مشاهده شود، این آیتم خاص بازگشت داده میشود، در غیر این صورت جستجو ادامه مییابد تا این که به انتهای مجموعه دادهها برسد.

الگوریتم
- جستجوی خطی (آرایه A، مقدار x)
- گام 1: متغیر i را برابر 1 قرار بده.
- گام 2: اگر i>n در این صورت به گام 7 برو.
- گام 3: اگر A[i] = x در این صورت به گام 6 برو
- گام 4: i را برابر با i + 1 قرار بده.
- گام 5: به گام 2 برو.
- گام 6: عنصر x را که در اندیس i قرار دارد یافته و به گام 8 برو.
- گام 7: پیام عدم یافته شدن را نمایش بده
- گام 8: خروج
شبه کد
procedure linear_search (list, value)
for each item in the list
if match item == value
return the item's location
end if
end for
end procedure
در ادامه پیادهسازی الگوریتم جستجوی خطی در زبان C به طور کامل ارائه شده است:
#include
#define MAX 20
// array of items on which linear search will be conducted.
int intArray[MAX] = {1,2,3,4,6,7,9,11,12,14,15,16,17,19,33,34,43,45,55,66};
void printline(int count) {
int i;
for(i = 0;i <count-1;i++) {
printf("=");
}
printf("=\n");
}
// this method makes a linear search.
int find(int data) {
int comparisons = 0;
int index = -1;
int i;
// navigate through all items
for(i = 0;i<MAX;i++) {
// count the comparisons made
comparisons++;
// if data found, break the loop
if(data == intArray[i]) {
index = i;
break;
}
}
printf("Total comparisons made: %d", comparisons);
return index;
}
void display() {
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++) {
printf("%d ",intArray[i]);
}
printf("]\n");
}
void main() {
printf("Input Array: ");
display();
printline(50);
//find location of 1
int location = find(55);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("Element not found.");
}
اگر کد فوق را کامپایل کرده و اجرا کنید، خروجی زیر را مشاهده میکنید:
خروجی
Input Array: [1 2 3 4 6 7 9 11 12 14 15 16 17 19 33 34 43 45 55 66] ================================================== Total comparisons made: 19 Element found at location: 19
الگوریتم جستجوی دودویی (binary)
جستجوی دودویی یک الگوریتم جستجوی سریع با پیچیدگی زمان اجرایی برابر با (O(log n است. این الگوریتم جستجو بر مبنای مفهوم «تقسیم و حل» عمل میکند. برای این که این الگوریتم به طرز صحیحی عمل کند. مجموعه دادهها باید به شکل مرتب باشند.

جستجوی باینری با مقایسه میانیترین آیتم مجموعه به دنبال یک آیتم خاص میگردد. اگر یک مطابقت رخ دهد در این صورت اندیس آیتم بازگردانده میشود. اگر آیتم میانی بزرگتر از آیتم مورد نظر باشد، در این صورت آیتم در آرایه فرعی سمت چپ آیتم میانی تکرار میشود. در غیر این صوت آیتم در آرایه فرعی سمت راست آیتم میانی صورت مورد جستجو قرار میگیرد. این فرایند بر روی آرایههای فرعی تا زمانی که اندازه آرایه فرعی برابر با صفر شود ادامه مییابد.
طرز کار جستجوی دودویی
برای این که بتوانیم از جستجوی دودویی استفاده کنیم، آرایه هدف باید مرتبسازی شده باشد. در ادامه فرایند جستجوی دودویی را یک مثال توضیح میدهیم. در ادامه آرایهای مرتب قرار دارد که فرض میکنیم میخواهیم موقعیت مقدار 31 را در آن با استفاده از جستجوی دودویی بیابیم.

ابتدا وسط آرایه را با استفاده از فرمول زیر تعیین میکنیم:
mid = low + (high - low) / 2
در این مثال، 0 + (9 - 0) / 2 = 4 (مقدار عدد صحیح 4.5) به عنوان میانه است. بنابراین 4 میانه آرایه است.

اینک مقداری را که در موقعیت 4 آرایه ذخیره شده است، با مقدار مورد جستجو یعنی 31 مقایسه میکنیم. درمییابیم که مقدار موجود در موقعیت 4 آرایه برابر با 27 است که مطابقت ندارد. از آنجا که مقدار مورد جستجو بزرگتر از 27 است و یک آرایه مرتب داریم، لذا میدانیم که مقدار مورد نظر باید در نیمه بالایی آرایه قرار داشته باشد.

اینک حد پایین جستجو را برابر با میانه + 1 قرار میدهیم و مقدار میانه جدید را مجدداً محاسبه میکنیم:
low = mid + 1 mid = low + (high - low) / 2
میانه جدید ما اینک برابر با 7 است و مقدار ذخیره شده در موقعیت 7 آرایه را با مقدار مورد نظر که 31 است مقایسه میکنیم.

مقدار ذخیره شده در موقعیت 7 مطابقت ندارد؛ اما این بار بزرگتر از مقدار مورد جستجو است. از این رو این مقدار باید در نیمه پایینی آرایه فرعی ما قرار داشته باشد.

بدین ترتیب مجدداً میانه را محاسبه میکنیم که این بار 5 است.

مقدار ذخیره شده در موقعیت 5 را با مقدار هدف مقایسه میکنیم. میبینیم که این بار این دو مقدار با هم مطابقت دارند.

نتیجه میگیریم که مقدار مورد جستجو در موقعیت 5 آرایه ذخیره شده است.
در جستجوی دودویی، در هر مرحله آرایه مورد جستجو نصف میشود و از این رو تعداد مقایسههای مورد نیاز بسیار کاهش مییابد.
شبه کد
شبه کد الگوریتمهای جستجوی دودویی به صورت زیر هستند:
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x set lowerBound = midPoint + 1 if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedure
در ادامه میتوانید پیادهسازی کامل الگوریتم جستجوی دودویی در زبان C را مشاهده کنید:
#include
#define MAX 20
// array of items on which linear search will be conducted.
int intArray[MAX] = {1,2,3,4,6,7,9,11,12,14,15,16,17,19,33,34,43,45,55,66};
void printline(int count) {
int i;
for(i = 0;i <count-1;i++) {
printf("=");
}
printf("=\n");
}
int find(int data) {
int lowerBound = 0;
int upperBound = MAX -1;
int midPoint = -1;
int comparisons = 0;
int index = -1;
while(lowerBound <= upperBound) {
printf("Comparison %d\n" , (comparisons +1) );
printf("lowerBound : %d, intArray[%d] = %d\n",lowerBound,lowerBound,
intArray[lowerBound]);
printf("upperBound : %d, intArray[%d] = %d\n",upperBound,upperBound,
intArray[upperBound]);
comparisons++;
// compute the mid point
// midPoint = (lowerBound + upperBound) / 2;
midPoint = lowerBound + (upperBound - lowerBound) / 2;
// data found
if(intArray[midPoint] == data) {
index = midPoint;
break;
} else {
// if data is larger
if(intArray[midPoint] < data) {
// data is in upper half
lowerBound = midPoint + 1;
}
// data is smaller
else {
// data is in lower half
upperBound = midPoint -1;
}
}
}
printf("Total comparisons made: %d" , comparisons);
return index;
}
void display() {
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++) {
printf("%d ",intArray[i]);
}
printf("]\n");
}
void main() {
printf("Input Array: ");
display();
printline(50);
//find location of 1
int location = find(55);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("\nElement not found.");
}
اگر کد فوق را کامپایل و اجرا کنید، خروجی زیر را به دست میآورید:
خروجی
Input Array: [1 2 3 4 6 7 9 11 12 14 15 16 17 19 33 34 43 45 55 66] ================================================== Comparison 1 lowerBound: 0, intArray[0] = 1 upperBound: 19, intArray[19] = 66 Comparison 2 lowerBound: 10, intArray[10] = 15 upperBound: 19, intArray[19] = 66 Comparison 3 lowerBound: 15, intArray[15] = 34 upperBound: 19, intArray[19] = 66 Comparison 4 lowerBound: 18, intArray[18] = 55 upperBound: 19, intArray[19] = 66 Total comparisons made: 4 Element found at location: 19
جستجوی درونیابی
جستجوی درونیابی یک روش بهبود یافته برای جستجوی دودویی محسوب میشود. این الگوریتم جستجو بر اساس کاوش موقعیت مقدار مورد نظر عمل میکند. برای این که این الگوریتم به درستی کار کند، مجموعه دادهها باید به شکل مرتب بوده و توزیع یکنواختی داشته باشند.
جستجوی دودویی مزیت زیادی در خصوص پیچیدگی زمانی نسبت به جستجوی خطی دارد. جستجوی خطی بدترین پیچیدگی (O(n را دارد، در حالی که جستجوی دودویی پیچیدگی زمانی آن به صورت زیر است:
O(log n)
مواردی وجود دارند که در آن موقعیت دادههای مورد جستجو ممکن است از قبل مشخص باشند. برای نمونه در مورد دفترچه راهنمای تلفن، اگر بخواهیم شماره تلفن فردی به نام Morphius را جستجو کنیم، هر دو الگوریتم جستجوی خطی و دودویی عملکرد کُندی خواهند داشت، در حالی که میتوانیم به طور مستقیم به فضایی از حافظه مراجعه کنیم که حرف M از آنجا شروع میشود.
موقعیتیابی در جستجوی دودویی
در جستجوی دودویی اگر داده مورد نظر یافت نشود، در این صورت باقی لیست به دو بخش کوچکتر و بزرگتر تقسیم میشود. سپس جستجو در یکی از دو نیمه جدید اجرا میشود:




حتی وقتی که دادهها مرتب باشند، جستجوی دودویی از مزیت کاوش موقعیت احتمالی دادههای مطلوب بهرهای نمیگیرد.


اگر مطابقتی رخ بدهد، در این صورت اندیس آیتم بازگشت داده میشود. برای افراز لیست به دو بخش باید از روش زیر استفاده کنیم:
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
که در آن:
- A یک لیست است.
- Lo پایینترین اندیس لیست است.
- Hi بالاترین اندیس لیست است
- A[n] مقدار ذخیره شده در اندیس n-ام لیست است.
اگر آیتم میانی بزرگتر از آیتم مورد جستجو باشد، در این صورت موقعیت کاوش مجدداً در آرایه فرعی سمت راست آیتم میانی تعیین میشود. در غیر این صورت آیتم در آرایه فرعی سمت چپ آیتم میانی جستجو میشود. این فرایند تا زمانی که اندازه آرایههای فرعی به صفر برسد، تداوم مییابد.
پیچیدگی زمان اجرای الگوریتم جستجوی درونیابی برابر با ((O(log (log n است که در مقایسه با (O(log n برای جستجوی دودویی بسیار بهینهتر است.
الگوریتم
از آنجا که این الگوریتم نسخه بهینهای از الگوریتم جستجوی دودویی موجود محسوب میشود، در این بخش گامهای جستجوی اندیس مقدار داده هدف با استفاده از کاوش موقعیت توضیح داده شده است:
- گام 1: جستجوی داده را از میانه لیست آغاز میکنیم.
- گام 2: اگر مطابقت وجود داشته باشد، اندیس آیتم بازگشت یافته و خارج میشویم.
- گام 3: اگر مطابق وجود نداشته باشد، موقعیت را کاوش میکنیم.
- گام 4: لیست را با استفاده از فرمول کاوش تقسیم میکنیم و میانه جدید را مییابیم.
- گام 5: اگر داده بزرگتر از میانه باشد، لیست فرعی بزرگتر را جستجو میکنیم.
- گام 6: اگر داده کوچکتر از میانه باشد، لیست فرعی کوچکتر را جستجو میکنیم.
- گام 7: تا زمانی که مطابقتی پیدا شود، این مراحل تکرار میشود.
شبه کد
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X Set Lo to Mid+1 else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End Procedure
در ادامه پیادهسازی کامل الگوریتم جستجوی درونیابی در زبان C ارائه شده است:
#include
#define MAX 10
// array of items on which linear search will be conducted.
int list[MAX] = { 10, 14, 19, 26, 27, 31, 33, 35, 42, 44 };
int find(int data) {
int lo = 0;
int hi = MAX - 1;
int mid = -1;
int comparisons = 1;
int index = -1;
while(lo <= hi) {
printf("\nComparison %d \n" , comparisons ) ;
printf("lo : %d, list[%d] = %d\n", lo, lo, list[lo]);
printf("hi : %d, list[%d] = %d\n", hi, hi, list[hi]);
comparisons++;
// probe the mid point
mid = lo + (((double)(hi - lo) / (list[hi] - list[lo])) * (data - list[lo]));
printf("mid = %d\n",mid);
// data found
if(list[mid] == data) {
index = mid;
break;
} else {
if(list[mid] < data) {
// if data is larger, data is in upper half
lo = mid + 1;
} else {
// if data is smaller, data is in lower half
hi = mid - 1;
}
}
}
printf("\nTotal comparisons made: %d", --comparisons);
return index;
}
int main() {
//find location of 33
int location = find(33);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("Element not found.");
return 0;
}
اگر کد فوق را کامپایل و اجرا کنیم، خروجی زیر به دست میآید:
خروجی
Comparison 1 lo: 0, list[0] = 10 hi: 9, list[9] = 44 mid = 6 Total comparisons made: 1 Element found at location: 7
جدول Hash
جدول Hash ساختار دادهای است که دادهها را به روشی مرتبط با هم ذخیرهسازی میکند. در یک جدول هَش، دادهها در قالب آرایهای ذخیره میشوند که در آن هر مقدار دادهای، مقدار اندیس آرایه منحصر به فرد خود را دارد. در این ساختار دادهای، اگر اندیس داده مطلوب را بدانیم، دسترسی به آن بسیار سریع خواهد بود.

از این رو این ساختار دادهای به ساختاری تبدیل میشود که در آن عملیاتهای درج و جستجو، صرف نظر از اندازه داده بسیار سریع اجرا میشوند. جدولهای هش از یک آرایه به عنوان واسطه ذخیرهسازی استفاده میکنند و از تکنیک هش برای ایجاد اندیسی استفاده میکنند که یک عنصر از طریق آن درج شده یا جستجو میشود.
هش کردن
هش کردن تکنیکی است که محدودهای از مقادیر کلید را به محدودهای از اندیسهای یک آرایه تبدیل میکند. ما از عملگر modulo برای گرفتن محدودهای از مقادیر کلیدی استفاده میکنیم. نمونهای از جدول هش به اندازه 20 را در نظر بگیرید که آیتمهای زیر باید در آن ذخیره شوند. آیتمها در قالب (کلید، مقدار) هستند.

- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| ردیف | کلید | هش | اندیس آرایه |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
کاوش خطی
همان طور که میبینید از تکنیک هش کردن میتوان برای ایجاد یک اندیس از قبل استفاده شده برای آرایه استفاده کرد. در چنین حالتی میتوانیم برای یافتن موقعیت خالی بعدی در آرایه به ترتیب به سلول های بعدی نگاه کنیم تا جایی که یک سلول خالی پیدا کنیم. این کار کاوش خطی نام دارد.
| ردیف | کلید | هش | اندازه آرایه | اندیس آرایه پس از کاوش |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
عملیاتهای ابتدایی
در ادامه عملیاتهای ابتدایی یک جدول هش ارائه شده است:
- جستجو (search): به دنبال یک عنصر در جدول هش میگردد.
- درج (Insert): عنصری را در جدول هش درج میکند.
- حذف (delete): عنصری را از جدول هش حذف میکند.
آیتم دادهای
منظور از آیتم دادهای نوعی ساختار است که حاوی یک کلید و مقداری داده است که بر مبنای آن چه که باید در یک جدول هش جستجو شود، ساخته میشود.
struct DataItem {
int data;
int key;
};
روش هش
روش هش برای محاسبه کد کلید برای آیتم دادهای استفاده میشود.
int hashCode(int key){
return key % SIZE;
}
عملیات جستجو
هر زمان که عنصری جستجو میشود، کد هش کلید، ارسال میشود و عنصر با استفاده از آن کد هش به عنوان اندیس آرایه پیدا میشود. اگر عنصری در کد هش محاسبه شده نباشد، از کاوش خطی برای رسیدن به عنصر استفاده میشود.
مثال
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
عملیات درج
هر زمان که لازم باشد عنصری در جدول هش درج شود، کد هش کلید ارسالی محاسبه شده و موقعیت اندیس با استفاده از کد هش به عنوان اندیس آرایه تعیین میشود. در صورتی که کد هش محاسبه شده در آرایه پیدا نشود، از روش کاوش خطی برای یافتن آن استفاده میشود.
مثال
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
عملیات حذف
هر زمان که بخواهیم عنصری را از یک جدول هش حذف کنیم، کد هش کلید ارسالی را محاسبه کرده و اندیس را با استفاده از کد هش به عنوان اندیس آرایه مییابیم. در مواردی که کد هش محاسبه شده در آرایه وجود نداشته باشد، از کاوش خطی برای یافتن موقعیت مورد نظر بهره گرفته میشود. زمانی که اندیس مربوطه پیدا شد، یک آیتم ساختگی در آن ذخیره میشود تا عملکرد جدول هش دست نخورده بماند.
مثال
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
در ادامه پیادهسازی کامل ساختار داده جدول هش در زبان C ارائه شده است:
#include
#include
#include
#include
#define SIZE 20
struct DataItem {
int data;
int key;
};
struct DataItem* hashArray[SIZE];
struct DataItem* dummyItem;
struct DataItem* item;
int hashCode(int key) {
return key % SIZE;
}
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void display() {
int i = 0;
for(i = 0; i<SIZE; i++) { if(hashArray[i] != NULL) printf(" (%d,%d)",hashArray[i]->key,hashArray[i]->data);
else
printf(" ~~ ");
}
printf("\n");
}
int main() {
dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem));
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
display();
item = search(37);
if(item != NULL) {
printf("Element found: %d\n", item->data);
} else {
printf("Element not found\n");
}
delete(item);
item = search(37);
if(item != NULL) {
printf("Element found: %d\n", item->data);
} else {
printf("Element not found\n");
}
}
اگر کد فوق را کامپایل کرده و اجرا کنید، خروجی زیر به دست میآید:
~~ (1,20) (2,70) (42,80) (4,25) ~~ ~~ ~~ ~~ ~~ ~~ ~~ (12,44) (13,78) (14,32) ~~ ~~ (17,11) (37,97) ~~ Element found: 97 Element not found
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز ملاحظه نمایید:
- آموزش مروری بر توابع Hash و خطر تصادم در آن ها
- مجموعه آموزش های پایگاه داده و سیستم های مدیریت اطلاعات
- درهمسازی (Hashing) در عصر یادگیری ماشین — معرفی جدیدترین تحولات این رشته
- آموزش درهم سازی در ساختمان داده
- مجموعه آموزشهای برنامهنویسی
- الگوریتم کروسکال چیست؟ – توضیح کراسکال به زبان ساده با مثال و کد
==










