


الگوریتم جستجوی محدوده در جاوا – از صفر تا صد
در این مقاله به بررسی مفهوم جستجو برای همسایگی در فضای دوبعدی میپردازیم. بدین ترتیب با الگوریتم جستجوی محدوده در جاوا و پیادهسازی آن آشنا خواهیم شد.



جستجوی تکبعدی چه فرقی با جستجوی دوبعدی دارد؟
به طوری که میدانیم «جستجوی دودویی» (binary search) الگوریتم کارآمدی برای یافتن تطبیق دقیق در یک لیست از آیتمها با استفاده از رویکرد «تقسیم و حل» (divide-and-conquer) محسوب میشود.
اینک یک مساحت دوبعدی را تصور کنید که هر آیتم به وسیله مختصات XY در یک صفحه نمایش مییابد. با این حال به جای تطبیق دقیق، فرض کنید که میخواهیم همسایگیهای یک نقطه مفروض را در یک صفحه بیابیم. روشن است که اگر بخواهیم نزدیکترین n مطابقت را پیدا کنیم، جستجوی دودویی عمل نخواهد کرد. دلیل این امر آن است که جستجوی دودویی میتواند دو آیتم را صرفاً در یک محور مقایسه کند، در حالی که باید بتوانیم آنها را در دو محور مقایسه کنیم. در بخش بعدی نگاهی به جایگزینهای ساختمان داده درخت دودویی خواهیم داشت.
Quadtree
«درخت چهارتایی» (Quadtree) یک ساختمان داده به صورت درخت فضایی است که در آن هر گره دقیقاً چهار فرزند دارد. هر فرزند میتواند یک نقطه یا یک لیست شامل چهار درخت چهارتایی فرعی باشد.
یک نقطه (Point) دادههایی را ذخیره میکند که برای نمونه شامل مختصات XY هستند. یک منطقه (Region) نماینده یک کران بسته است که درون آن میتوان یک نقطه را ذخیره کرد. از آن برای تعریف مساحت هر درخت چهارتایی استفاده میکنیم. برای درک بهتر به مثال زیر با 10 مختصات در ترتیب دلخواه توجه کنید:
(21,25), (55,53), (70,318), (98,302), (49,229), (135,229), (224,292), (206,321), (197,258), (245,238)
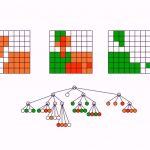
سه مقدار نخست به صوت نقاطی زیر گره ریشه مانند آنچه در تصویر اول دیده میشود، ذخیره خواهند شد.



گره ریشه در حال حاضر نمیتواند نقاط جدید بپذیرد، زیرا به ظرفیت بیشینه سه نقطه خود رسیده است. از این رو این منطقه گره ریشه را به چهار ربع مساوی تقسیم میکنیم.
هر کدام از این ربع ها میتوانند سه نقطه ذخیره کنند و علاوه بر آن شامل چهار ربع درون کران خود هستند. این کار میتواند به صورت بازگشتی انجام یابد که منجر به ایجاد یک درخت چهارتایی از ربعها میشود. در واقع نام ساختمان داده درخت چهارتایی نیز از همین واقعیت ناشی میشود.
در تصویر وسط در بخش قبلی، میبینیم که ربعها از گره ریشه ایجاد میشوند و چهار نقطه بعدی در این ربع ها ذخیره میشود. در نهایت تصویر پایین در بخش فوق، شیوه تقسیم مجدد ربع برای پذیرش نقاط بیشتری که در آن منطقه هستند را نشان میدهد و همزمان ربعهای دیگر همچنان نقاط جدید را قبول میکنند. اینک به بررسی شیوه پیادهسازی این الگوریتم در جاوا میپردازیم.
ساختمان داده
ابتدا یک ساختمان داده درخت چهارتایی ایجاد میکنیم.
به این منظور به سه کلاس دامنه نیاز داریم. ابتدا یک کلاس Point برای ذخیره مختصات XY میسازیم:
سپس یک کلاس Region میسازیم که کرانهای یک ربع را تعریف میکند:
در نهایت یک کلاس به نام QuadTree ایجاد میکنیم که دادهها را به صورت وهلههایی از Point و فرزندان را به صورت کلاسهای QuadTree ذخیره میکند:
برای وهلهسازی از شیء QuadTree مساحت آن را با استفاده از کلاس Region از طریق سازنده تعیین میکنیم.
الگوریتم
پیش از نوشتن منطق اصلی کد برای ذخیرهسازی دادهها، ابتدا چند متد کمکی میسازیم. این متدها در ادامه مفید واقع خواهند شد.
متدهای کمکی
ابتدا کلاس Region را ویرایش میکنیم. قبل از هر چیز یک متد به نام containsPoint داریم که در صورت افتادن یک نقطه درون یا بیرون مساحت یک منطقه آن را معلوم میسازد:
سپس یک متد به نام doesOverlap داریم که معلوم میسازد آیا یک منطقه مفروض با منطقه دیگر همپوشانی دارد یا نه:
در نهایت یک متد به نام getQuadrant ایجاد میکنیم که یک محدوده را به چهار ربع برابر تقسیم میکند و یکی از آنها را که تعیین شده بازگشت میدهد:
ذخیرهسازی دادهها
اکنون میتوانیم منطق خود را برای ذخیرهسازی دادهها بنویسیم. کار خود را با تعریف کردن متد جدیدی به نام addPoint روی کلاس QuadTree جهت افزودن یک نقطه جدید آغاز میکنیم. این متد در صورتی که یک نقطه با موفقیت اضافه شود، مقدار true بازگشت میدهد:
سپس منطق مدیریت نقطه را مینویسیم. ابتدا باید بررسی کنیم که آیا نقطه درون کرانهای یک وهله از QuadTree قرار دارد یا نه. همچنین باید مطمئن شویم که وهله QuadTree به ظرفیت بیشینه (MAX_POINTS) نقاط نرسیده باشد.
اگر هر دو شرط تأمین باشند، میتوانیم نقطه جدیدی اضافه کنیم:
از سوی دیگر، اگر به مقدار MAX_POINTS برسیم، باید نقطه جدیدی به یکی از ربعهای فرعی اضافه کنیم. به این منظور حلقهای روی فرزند لیست quadTrees تعریف میکنیم و همان متد addPoint را که روی افزودن موفقیتآمیز، مقدار true بازگشت داده فرامیخوانیم. سپس بیدرنگ از حلقه خارج میشویم چون یک نقطه باید دقیقاً به یک ربع اضافه شود. همه این منطق را میتوانیم درون یک متد کمکی کپسولهسازی کنیم:
علاوه بر آن یک متد کارآمد دیگر به نام createQuadrants برای تقسیم quadtree جاری به چهار quadtree فرعی میسازیم:
این متد را برای ایجاد درختهای چهارتایی تنها زمانی فراخوانی میکنیم که دیگر نتوانیم نقاط جدیدی اضافه کنیم. بدین ترتیب اطمینان مییابیم که این ساختمان داده استفاده بهینهای از فضای حافظه دارد. در نهایت متد addPoint به صورت زیر بهروزرسانی میشود:
جستجوی دادهها
اینک که ساختمان داده quadtree را برای ذخیرهسازی دادهها تعریف کردیم، میتوانیم به منطق اجرای جستجو فکر کنیم. از آنجا که ما به دنبال یافتن آیتمهای مجاور هستیم، میتوانیم searchRegion را به عنوان یک نقطه آغازین تعیین کنیم. سپس بررسی میکنیم که آیا با منطقه ریشه همپوشانی دارد یا نه. اگر چنین باشد، همه نقاط فرزند آن را به درون searchRegion قرار میگیرند اضافه میکنیم.
پس از منطقه ریشه وارد هر ربع میشویم و همین فرایند را تکرار میکنیم. این وضعیت تا زمانی که به انتهای درخت برسیم تکرار میشود. منطق فوق را به صورت یک متد بازگشتی در کلاس QuadTree مینویسیم:
تست کردن
اکنون الگوریتم را به دست آوردهایم و تلاش میکنیم آن را تست کنیم.
پر کردن دادهها
ابتدا درخت چهارتایی را با همان 10 مختصاتی که قبلاً استفاده کردیم، پر میکنیم:
جستجوی محدوده
سپس یک جستجوی محدوده در ناحیهای که از سوی مختصات کران پایین (200,200) و کران بالا (250,250) مشخص شده اجرا میکنیم:
با اجرای کد فوق، یک مختصات همسایگی درون ناحیه جستجو در اختیار ما قرار میگیرد:
[[245.0, 238.0]]
اگر ناحیه جستجوی متفاوتی بین مختصات (0,0) و (100,100) امتحان کنیم:
با اجرای کد فوق، دو مختصات مجاور برای ناحیه جستجوی تعیین شده بازگشت مییابد:
[[21.0, 25.0], [55.0, 53.0]]
مشاهده کردیم که بسته به اندازه ناحیه جستجو، میتوانیم صفر، یک یا چند نقطه به دست آوریم. بنابراین اگر نقطهای به ما داده شود و از ما خواسته شود که n نزدیکترین همسایگی را بیابیم، میتوانیم یک ناحیه جستجوی مناسب تعریف کنیم که نقطه مفروض در مرکز آن باشد. بدین ترتیب از روی همه نقطههای حاصل از عملیات جستجو، میتوانیم مسافت اقلیدسی بین نقاط مفروض را محاسبه کرده و آنها را برای یافتن نزدیکترین همسایگی مرتبسازی کنیم.
پیچیدگی زمانی
پیچیدگی زمانی یک کوئری محدوده برابر با O(n) است. دلیل آن این است که در سناریوی بدترین حالت، در صورتی که ناحیه جستجو برابر یا بزرگتر از ناحیه مقداردهی شده باشد، باید همه آیتمها پیمایش شوند.
سخن پایانی
در این مقاله ابتدا به بررسی مفهوم یک درخت چهارتایی به وسیله مقایسه آن با درخت دودویی پرداختیم. سپس شیوه استفاده مؤثر از آن برای ذخیرهسازی دادهها روی یک فضای دوبعدی را مشاهده کردیم. سپس شیوه ذخیرهسازی دادهها و اجرای یک جستجوی محدوده را بررسی کردیم. سورس کد این مقاله به همراه تستها در این ریپوی گیتهاب (+) در دسترس شما قرار دارد.

اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامهنویسی جاوا (Java)
- مجموعه آموزشهای برنامهنویسی
- گنجینه آموزش های جاوا (Java)
- ۱۰ مفهوم اصلی زبان جاوا که هر فرد مبتدی باید بداند
- پیاده سازی درخت دودویی در جاوا — راهنمای جامع
==










