



تشخیص چهره در پایتون با OpenCV و Dlib – از صفر تا صد
در این راهنما با روش ایجاد و اجرای یک الگوریتم تشخیص چهره در پایتون با استفاده از OpenCV و Dlib آشنا میشویم. همچنین برخی قابلیتهای آنها را برای شناسایی همزمان چشمها و دهان روی چهرههای مختلف معرفی خواهیم کرد. در این مقاله روش پیادهسازی مقدماتی تشخیص چهره را به طور کامل توضیح میدهیم که شامل ابزارهای طبقهبندی آبشاری، پنجرههای HOG، و CNN-های یادگیری عمیق میشود.




برای مشاهده مخزن گیتهاب این مقاله به این لینک (+) مراجعه کنید.
مقدمه
ما در این مطلب از OpenCV استفاده خواهیم کرد که یک کتابخانه متنباز برای بینایی ماشین است و به زبان ++C/C نوشته شده است. این کتابخانه اینترفیسهایی در زبانهای ++C، پایتون و جاوا دارد. OpenCV از پلتفرمهای ویندوز، لینوکس، macOS ،iOS و اندروید پشتیبانی میکند. برخی از بخشهای کار نیازمند Dlib هستند که یک کیت ابزار ++C شامل الگوریتمهای یادگیری ماشین و ابزارهایی برای خلق نرمافزارهای پیچیده است.
پیشنیازهای تشخیص چهره در پایتون
نخستین مرحله برای شروع کار، نصب OpenCV و Dlib است.
به این منظور دستور زیر را وارد کنید:
pip install opencv-python pip install dlib
بسته به این که از کدام نسخه از پایتون استفاده میکنید، فایل در مسیرهای مختلفی نصب میشود. در مورد نسخهای که ما استفاده میکنیم، وضعیت به صورت زیر بوده است:
/usr/local/lib/python3.7/site-packages/cv2
اگر در نصب Dlib با مشکلاتی مواجه شدید به این مقاله (+) مراجعه کنید.
ایمپورت و مسیر مدلها
ما یک نتبوک ژوپیتر/فایل پایتون میسازیم و کار خود را با آن آغاز میکنیم:
import cv2 import matplotlib.pyplot as plt import dlib from imutils import face_utils font = cv2.FONT_HERSHEY_SIMPLEX
طبقهبندی آبشاری
ابتدا به بررسی طبقهبندی آبشاری میپردازیم.
نظریه
طبقهبندی آبشاری یا آبشارهای مشهور طبقهبندی ارتقا یافته به همراه ویژگیهای شِبه Haar (یا Haar-like feature) عمل میکنند و یک کاربرد خاص از «یادگیری گروهی» (ensemble learning) محسوب میشوند که boosting نام دارند. این ابزارها به طور عمده روی طبقهبندیهای Adaboost و دیگر مدلها مانند Real Adaboost ،Gentle Adaboost یا Logitboost تکیه دارند.
ابزارهای طبقهبندی آبشاری روی چند تصویر نمونه از یک موضوع آموزش میبینند. این تصاویر شامل سوژهای است که میخواهیم شناسایی کنیم. همچنین از تصاویر دیگر که شامل آن موضوع نیستند نیز استفاده میشود.
چگونه میتوان تشخیص داد که در تصویری چهره انسان وجود دارد یا نه؟ یک الگوریتم به نام فریمورک شناسایی شیء Viola–Jones وجود دارد که شامل همه مراحل مورد نیاز برای شناسایی زنده چهره است. این موارد شامل فهرست زیر میشوند:
- گزینش ویژگی Haar: ویژگیهایی هستند که از موجکهای Haar مشتق شدهاند.
- ایجاد تصویر یکپارچه
- آموزش Adaboost
- ابزارهای طبقهبندی آبشاری
اگر میخواهید مقاله اصلی Viola-Jones را ببینید، به این لینک (+) مراجعه کنید.
گزینش ویژگی Haar
برخی ویژگیهای مشترک وجود دارند که در همه چهرههای انسانی میتوان مشاهده کرد:
- یک منطقه شامل ناحیه چشمی که در مقایسه با گونهها تیرهتر است.
- رنگ روشنتر بینی در مقایسه با چشمها
- موقعیت خاص چشمها، دهان و بینی و ...
این خصوصیات به نام ویژگیهای Haar نامیده میشوند. فرایند استخراج ویژگی مانند زیر است:

در این مثال، نخستین ویژگی تفاوت بین شدت روشنایی بین ناحیه چشمها و منطقه گونههای فوقانی را اندازهگیری میکند. مقدار این ویژگی به وسیله جمع زدن پیکسلها در ناحیه سیاه فوقانی و تفریق آن از مقادیر پیکسلهای ناحیه سفید به دست میآید.

سپس این مستطیل را به عنوان یک کرنل کانولوشنی روی کل تصویر اعمال میکنیم. برای این که رویکرد جامعی داشته باشیم، باید همه ابعاد و موقعیتهای ممکن برای هر کرنل را اعمال کنیم. یک تصویر ساده 24 در 24 پیکسل، معمولاً منتهی به 160،000 ویژگی میشود که هر یک از جمع/تفریق کردن مقادیر پیکسلها به دست آمدهاند. بدین ترتیب امکان تشخیص چهره زنده از دست میرود. بنابراین سؤال این است که این فرایند چگونه عملیاتی میشود؟
زمانی که ناحیه مناسبی به وسیله یک مستطیل شناسایی میشود، اجرای پنجره روی نواحی مختلف چهره بیفایده خواهد بود. این کار به وسیله Adaboost صوت میگیرد.
ویژگیهای مستطیل با استفاده از مفهوم تصویر یکپارچه محاسبه میشوند که روشی بسیار سریعتر است. در مورد این روش در بخش بعدی بیشتر توضیح خواهیم داد.

چند نوع از مستطیلها وجود دارند که میتوان برای استخراج ویژگیهای Haar مورد استفاده قرار داد. این موارد شامل فهرست زیر هستند:
- ویژگی دو مستطیلی به تفاضل بین مجموع مقادیر پیکسلها درون نواحی مستطیلی میپردازد و به طور عمده برای تشخیص لبهها (در تصویر زیر a و b) استفاده میشود.
- ویژگی سه مستطیلی مجموع ناحیه درون محدوده مستطیلهای کناری را محاسبه میکند که از مجموع مستطیل میانی کسر میشوند و به طور عمده برای شناسایی خطوط (c و d) استفاده میشود.
- ویژگی چهار مستطیلی تفاضل بین جفتهای قطری مستطیلها (e) را محاسبه میکند.

اینک که ویژگیها گزینش شدهاند، آنها را با استفاده از طبقهبندی Adaboost روی مجموعهای از تصاویر آموزشی اعمال میکنیم. بدین ترتیب مجموعهای از طبقهبندیهای ضعیف با هم ترکیب میشود تا یک مدل گروهی دقیق را تشکیل دهند. با استفاده از 200 ویژگی (به جای 160،000 ویژگی اولیه) میزان دقتی برابر با 95% به دست میآید. ما در این نوشته از 6000 ویژگی استفاده کردهایم.
تصویر یکپارچه
محاسبه ویژگیهای مستطیلی به سبک کرنل کانولوشنی، ممکن است مدت زمان بسیار زیادی طول بکشد. به همین دلیل طراحان اولیه این روش Viola و Jones یک بازنمایی میانجی از تصویر را پیشنهاد کردهاند که آن را تصویر یکپارچه مینامند. نقش تصویر یکپارچه این است که امکان محاسبه مجموع هر مستطیلی را به سادگی با استفاده از تنها چهار ویژگی فراهم میکند.
فرض کنید میخواهیم ویژگیهای مستطیلی را در یک پیکسل مفروض با مختصات x و y محاسبه کنیم. سپس تصویر یکپارچه پیکسل را در مجموع پیکسلهای سمت بالا و سمت چپ پیکسل محاسبه میکنیم:

در فرمول فوق (ii(x،y تصویر یکپارچه و (i(x،y تصویر اصلی است.
زمانی که تصویر یکپارچه به صورت کامل محاسبه شد، یک رابطه بازگشتی وجود دارد که یک بار روی تصویر اصلی اعمال میشود. در واقع میتوانیم جفت روابط بازگشتی زیر را تعریف کنیم:

که (s(x،y مجموع ردیف تجمعی و s(x−1)=0، ii(−1،y)=0 است.
این رابطه چه فایدهای دارد؟ تصور کنید ناحیه D وجود دارد که در آن میخواهیم مجموع پیکسلها را محاسبه کنیم. ما سه ناحیه دیگر را نیز به صورت A ،B و C تعریف کردهایم.
- مقدار تصویر اصلی در نقطه 1 برابر با مجموعه پیکسلها در مستطیل A است.
- مقدار مربوطه در نقطه 2 برابر با A + B است.
- مقدار مربوطه در نقطه 3 برابر با A + C است.
- مقدار مربوطه در نقطه 4 برابر با A + B + C + D است.
از این رو مجموع پیکسلها در ناحیه D را میتوان با استفاده از فرمول زیر محاسبه کرد:
4+1−(2+3)
با استفاده از یک گذر میتوان مقدار درون یک مستطیل را با استفاده از تنها 4 ارجاع آرایهای محاسبه کرد:

باید بدانید که مستطیلها عملاً ویژگیهای کاملاً سادهای هستند، اما اهمیت زیادی در تشخیص چهره دارند. فیلترهای Steerable هنگامی که با مسائل پیچیده سر و کار داریم، انعطافپذیری بیشتری دارند.

یادگیری تابع طبقهبندی با استفاده از Adaboost
با فرض وجود یک مجموعه برچسب خورده از تصاویر آموزشی (مثبت یا منفی) Adaboost به صورت زیر مورد استفاده قرار میگیرد:
- یک مجموعه کوچک از ویژگیها را انتخاب کنید.
- الگوریتم طبقهبندی را آموزش دهید.
از آنجا که اغلب ویژگیها در میان 160،000 ویژگی نامرتبط تصور شدهاند؛ الگوریتم یادگیری ضعیف که با استفاده از مدل boosting ساختیم طوری طراحی شده است که ویژگی مستطیلی منفردی را انتخاب کند که مثالهای مثبت و منفی را به بهترین روش از هم جدا میکند.
طبقهبندی آبشاری
با این که فرایند توصیف شده فوق کاملاً کارآمد است، اما هنوز یک مشکل عمده بر سر راه آن پابرجا است. در یک تصویر اغلب بخشها را قسمتهای غیر از چهره تشکیل میدهند. دادن اهمیت یکسان به همه بخشهای چنین تصویری بیمعنی است، چون باید تمرکز عمده روی ناحیهای باشد که احتمال وجود چهره بیشتر است. Viola و Jones در روش خود به نرخ شناسایی بالایی دست یافتند و در عین حال زمان محاسبه را با استفاده از طبقهبندیهای آبشاری کاهش دادند.
ایده اصلی این بوده است که آن پنجرههای فرعی را که شامل چهره نیستند رد کنند و در عین حال مناطقی که چنین خصوصیتی را دارند حفظ نمایند. از آنجا که وظیفه ما شناسایی مناسب چهره بوده است، میخواهیم نرخ تشخیص منفی نادرست، یعنی موادی که شامل چهره بودهاند، اما چنین شناسایی نشدهاند را کاهش دهیم.
یک سری از طبقهبندیها روی هر پنجره فرعی اعمال میشوند. این طبقهبندیها درختهای تصمیم سادهای هستند:
- اگر طبقهبندی نخست مثبت باشد، به طبقهبندی دوم میرویم.
- اگر طبقهبندی دوم مثبت باشد، به طبقهبندی سوم میرویم.
- و همین طور تا آخر.
هر نتیجه منفی در یک نقطه، منتهی به رد پنجره فرعی میشود که احتمالاً شامل یک چهره است. طبقهبندی اول اغلب مثالهای منفی را با هزینه محاسباتی پایین کاهش میدهد و طبقهبندیهای بعدی مثالهای منفی بعدی را که هزینه بالاتری دارند با استفاده از توان محاسباتی بالاتر حذف میکنند.

طبقهبندیها با استفاده از Adaboost آموزش داده میشوند و حد آستانه طوری تعیین میشود که نرخ تشخیص نادرست کمینه شود. زمانی که چنین مدلی را آموزش میدهیم، متغیرها به صورت زیر هستند:
- تعداد مراحل طبقهبندی
- تعداد ویژگیها در هر مرحله
- حد آستانه در هر مرحله
خوشبختانه در OpenCV، کل مدل از قبل برای تشخیص چهره تعلیم یافته است.
ایمپورتها
مرحله بعدی این است که وزنهای از قبل آموزشیافته را مکانیابی کنیم. ما از مدلهای از پیش آموزشدیده برای تشخیص چهره، چشمها و دهان استفاده خواهیم کرد. بسته به این که از چه نسخهای از پایتون استفاده میکنید فایلهای مربوطه باید در چنین مکانهایی باشند:
/usr/local/lib/python3.7/site-packages/cv2/data
الگوریتمهای طبقهبندی آبشاری را به روش زیر اعلان میکنیم:
cascPath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml" eyePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_eye.xml" smilePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_smile.xml" faceCascade = cv2.CascadeClassifier(cascPath) eyeCascade = cv2.CascadeClassifier(eyePath) smileCascade = cv2.CascadeClassifier(smilePath)
تشخیص چهره روی یک تصویر
پیش از پیادهسازی یک الگوریتم تشخیص چهره واقعی، نسخه سادهای از آن را روی یک تصویر ساده به کار میگیریم. کار خود را با بارگذاری یک تصویر تست آغاز میکنیم:

سپس چهره را تشخیص داده و یک مستطیل پیرامون آن اضافه میکنیم:
در ادامه فهرستی از پارامترهای مشترک را برای تابع detectMultiScale مشاهده میکنید:
- scaleFactor: پارامتری است که میزان کاهش اندازه تصویر را در هر مقیاسبندی تصویر تعیین میکند.
- minNeighbors: این پارامتر تعداد همسایگیهای هر مستطیل نامزد که باید حفظ شوند را تعیین میکند.
- minSize: کمینه اندازه ممکن برای شیء است. شیءهای کوچکتر از آن نادیده گرفته میشوند.
- maxSize: بیشینه ممکن برای اندازه شیء است. شیءهای بزرگتر از آن نادیده گرفته میشوند.
در نهایت نتیجه نمایش پیدا میکند:

چنان که مشاهده میکنید، تشخیص چهره روی تصویر تست ما به خوبی عمل کرده است. در ادامه آن را به صورت عملکرد همزمان (آنی) تست میکنیم.
تشخیص چهره آنی
در این بخش پیادهسازی تشخیص چهره زنده را در پایتون بررسی خواهیم کرد. نخستین گام باز کردن دوربین و دریافت ویدئو است. سپس تصویر را به یک تصویر خاکستری تبدیل میکنیم. این کار برای کاهش ابعاد تصویر ورودی صورت میگیرد. در واقع به جای 2 نقطه برای هر پیکسل که با رنگهای قرمز، سبز و آبی توصیف میشوند، یک تبدیل خطی ساده استفاده میشود:

این وضعیت به صورت پیشفرض در OpenCV پیادهسازی شده است:
اینک از متغیر faceCascade که در بخش قبلی تعریف کردیم استفاده میکنیم. این متغیر شامل یک الگوریتم از پیش آموزشدیده است و آن را روی یک تصویر خاکستری اعمال میکنیم.
برای هر چهرهای که تشخیص داده شود، یک مستطیل پیرامون چهره ترسیم میشود:
در مورد هر دهان که تشخیص داده میشود نیز یک مستطیل پیرامون آن رسم میشود:
همچنین برای هر چشم شناسایی شده یک مستطیل در پیرامونش ترسیم میشود:
سپس تعداد کل چهرهها شمارش شده و تصویر نهایی نمایش پیدا میکند:
زمانی که میخواهیم از دوربین خارج شویم یک گزینه خروج نیز پیادهسازی میکنیم تا با ارسال حرف q فعال شود:
در نهایت هنگامی که همه کارها انجام یافت، دریافت ویدئو قطع میشود و همه پنجرهها بسته میشوند. البته بستن پنجرهها در سیستم Mac با برخی مشکلات مواجه میشود که ممکن است نیازمند توقف پردازش پایتون در Activity Manager باشد:
جمعبندی
کد کامل ما اینک به صورت زیر است:
نتایج
در ویدئوی کوتاه زیر عملکرد پیادهسازی تشخیص چهره ما را مشاهده میکنید:
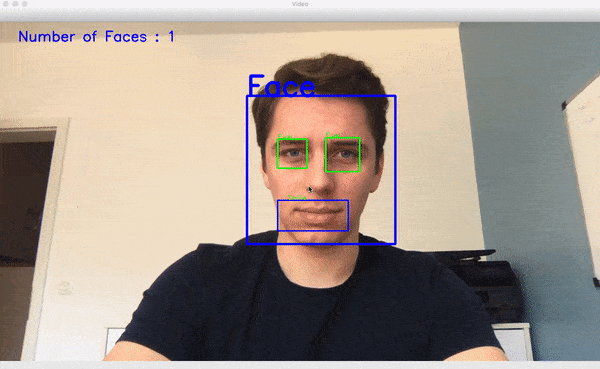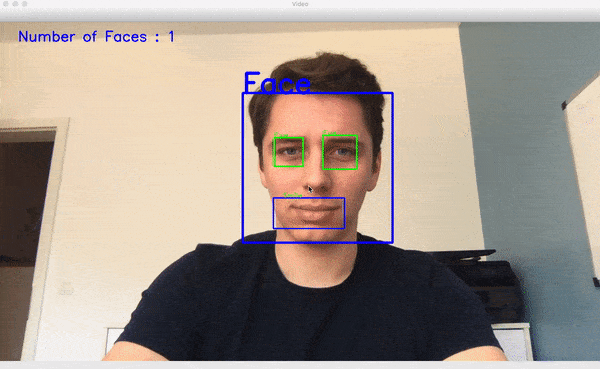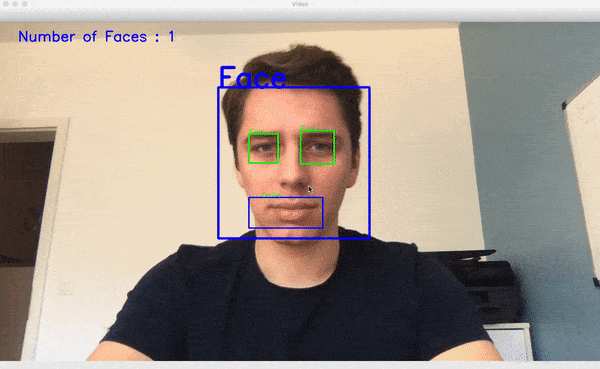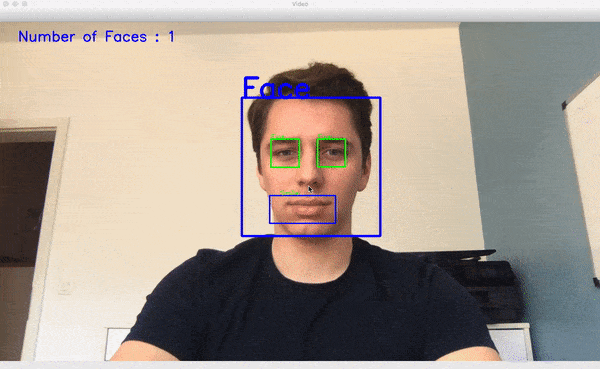
هیستوگرام گرادیانهای جهتدار (HOG) در Dlib
دومین پیادهسازی محبوب برای تشخیص چهره از سوی Dlib ارائه شده و از مفهومی به نام هیستوگرام گرادیانهای جهتدار (HOG) بهره میگیرد. در این بخش به پیادهسازی روش اصلی پیشنهاد شده در مقاله Dalal و Triggs (+) میپردازیم.
نظریه
ایدهای که در پشت HOG قرار دارد این است که میتوان ویژگیها را به صورت یک بردار استخراج کرد و آن را به یک الگوریتم طبقهبندی، برای مثال ماشین بردار پشتیبانی داد که ارزیابی کند آیا یک چهره (یا هر چیز دیگر که برای شناساییاش تعلیم دیده است) در آن ناحیه وجود دارد یا نه.
ویژگیهای استخراج شده، توزیعها (هیستوگرامها)-ی جهتگیری گرادیانها (یا گرادیانهای جهتدار) از تصویر هستند. گرادیانها عموماً در بخشهای لبه و گوشه، مقادیر بالایی دارند و بدین ترتیب به ما امکان میدهند که آن نواحی را تشخیص دهیم.
در مقاله اصلی، فرایند کار برای تشخیص بدن انسان به صورت زیر پیادهسازی شده است و زنجیره تشخیص به شرح زیر است:

پیشپردازش
قبل از هر چیز، تصاویر ورودی باید هماندازه باشند. از این رو برش و تغییر مقیاس لازم است. وصلههایی که ما در این مقاله استفاده میکنیم، دارای نسبت 1:2 هستند و از این رو ابعاد تصاویر ورودی باید برای نمونه 64 در 128 یا 100 در 200 باشد.
محاسبه تصاویر گرادیان
نخستین گام، محاسبه گرادیانهای افقی و عمودی تصویر از طریق بهکارگیری کرنلهای زیر است:

گرادیان یک تصویر عموماً اطلاعات غیرضروری را حذف میکند. گرادیان تصویری که در بخش فوق در نظر گرفتیم را میتوان در پایتون به صورت زیر به دست آورد:
شکل را به صورت زیر رسم میکنیم:

با این حال ما تصویر را پیشپردازش نکردهایم.
محاسبه HOG
در ادامه تصویر به سلولهای 8 در 8 تقسیم میشود تا یک بازنمایی فشرده ایجاد شود و HOG در برابر نویز مقاومت بیشتری بیابد. سپس HOG را برای هریک از این سلولها محاسبه میکنیم.
برای تخمین جهت گرادیان درون ناحیه، یک هیستوگرام میان 64 مقدار از جهتگیریهای گرادیان (8 در 8) میسازیم و بزرگی آنها (64 مقدار دیگر) درون هر ناحیه را نیز محاسبه میکنیم. دستههای هیستوگرام با زوایای گرادیان از 0 تا 180 درجه مرتبط هستند. در مجموع 9 دسته به صورت 0، 20، 40،... و 160 درجه وجود دارند.
کد فوق دو نوع اطلاعات را در اختیار ما قرار میدهد:
- جهت گرادیان
- بزرگی گرادیان
زمانی که HOG را میسازیم، 3 حالت فرعی وجود دارد:
- زاویه کمتر از 160 درجه باشد و در نیمه بین 2 طبقه قرار نگرفته باشد. در چنین مواردی، این زاویه در دسته مناسب HOG اضافه میشود.
- زاویه کمتر از 60 درجه باشد و دقیقاً بین دو طبقه قرار بگیرد. در چنین حالتی یک مشارکت برابر بین دو طبقه مجاور تصور کرده و بزرگی را به 2 بخش تقسیم میکنیم.

- زاویه بزرگتر از 160 درجه باشد. در چنین حالتهایی تصور میکنیم که آن پیکسل به صورت قائم بر 160 و تا 0 درجه مشارکت دارد.

HOG برای هر سلول 8 در 8 به صورت زیر به دست میآید:

نرمالسازی بلوک
در نهایت، یک بلوک 16 در 16 را میتوان برای نرمالسازی تصویر و برای مثال حذف تأثیر نوردهی اعمال کرد. این نتیجه به سادگی با تقسیم کردن هر مقدار HOG با اندازه 8 در 8 بر L2-norm مربوط به بلوک HOG 16 در 16 که شامل آن است صورت میگیرد. در واقع این یک بردار ساده با طول 9*4 = 36 است.
در نهایت همه بردارهای 36 در 1 در یک بردار بزرگ تجمیع میشوند و کار به پایان میرسد. بدین ترتیب بردار ویژگی به دست میآید و با استفاده از آن میتوان یک الگوریتم طبقهبندی SVM نرم (C=0.01) را آموزش داد.
تشخیص چهره روی یک تصویر
پیادهسازی این روش کاملاً سر راست است:
تشخیص چهره آنی
همانند روش قبلی، پیادهسازی آنی این الگوریتم نیز آسان است. ما یک نسخه سبکتر از آن را که تنها چهره را تشخیص میدهد را پیادهسازی کردهایم. Dlib شناسایی نقاط کلیدی چهره را نیز به صورت کاملاً ساده اجرا میکند که البته بررسی آن خارج از حیطه این مقاله است:
شبکه عصبی کانولوشنی در Dlib
آخرین روش که در این مقاله برای تشخیص چهره بررسی میکنیم مبتنی بر شبکههای عصبی کانولوشنی (CNN) است. برای پیادهسازی این روش از نتایج این مقاله (+) در مورد شناسایی شیء (Max-Margin (MMOD بهره جستهایم.
اندکی از نظریه روش
شبکههای عصبی کانولوشنی (CNN) شبکههای عصبی پیشخور (feed-forward) هستند که به طور عمده برای بینایی ماشین استفاده میشوند. این شبکهها یک پیش-آموزش خودکار را نیز همراه با بخش شبکه عصبی فشرده ارائه میکنند. CNN-ها انواع خاصی از شبکههای عصبی برای پردازش دادهها با فناوری شبه grid هستند. معماری CNN از کورتکس بینایی جانداران الهام گرفته است.
در رویکردهای قبلی، بخش عمدهای از کار مربوط به انتخاب فیلترها برای ایجاد ویژگیهایی جهت استخراج بیشینه ممکن اطلاعات از تصاویر بوده است. با ظهور یادگیری عمیق و ظرفیتهای محاسباتی بالاتر این کار اکنون به صورت خودکار صورت میگیرد. نام CNN از این واقعیت ناشی میشود که ورودی تصویر اولیه با یک مجموعه از فیلترها پیچش (convolve) مییابد. پارامتری که باید انتخاب کرد، تعداد فیلترهایی که باید اعمال شوند و ابعاد فیلترها است. بُعد فیلتر به نام طول stride نامیده میشود. مقادیر معمول برای این stride بین 2 و 5 هستند:
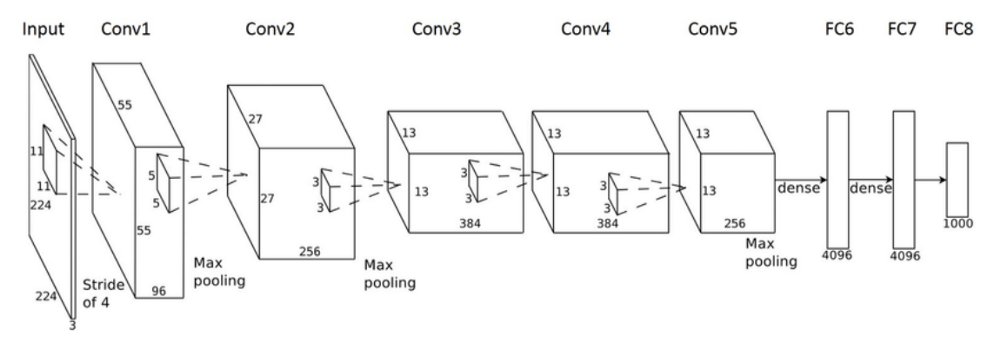
خروجی CNN در این مورد خاص یک طبقهبندی باینری است که در صورت وجود چهره مقدار 1 و در غیر این صورت مقدار 0 میگیرد.
تشخیص چهره روی یک تصویر
برخی اجزای این رویکرد در پیادهسازی تغییر مییابند. نخستین گام، دانلود کردن مدل از پیش آموزشدیده (+) است. وزنها را به پوشه خود منتقل و dnnDaceDetector را تعریف کنید:
dnnFaceDetector = dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat")
سپس مشابه روشی که تا به اینجا عمل کردیم پیش میرویم:

تشخیص چهره آنی
در نهایت نسخه آنی تشخیص چهره CNN را پیادهسازی خواهیم کرد:
کدام روش را باید انتخاب کرد؟
سؤال دشواری است و برای پاسخ به آن باید دو معیار مهم زیر را در نظر گرفت:
- زمان محاسبات
- دقت
اگر سرعت را معیار قرار دهیم، HoG سریعترین الگوریتم به نظر میرسد و سپس طبقهبندی آبشار Haar و CNN قرار دارند.
با این حال، CNN-ها و Dlib دقیقترین الگوریتمها هستند. HoG نیز عملکرد خوبی دارد، اما مشکلاتی در شناسایی چهرههای کوچک دارد. طبقهبندی HaarCascade نیز به خوبی HoG عمل میکند. اگر میخواهید تشخیص سریعی در ویدئوهای زنده خود داشته باشید پیشنهاد میکنیم از روش HoG استفاده کنید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش مصنوعی
- آموزش پروژه محور پردازش تصویر با OpenCV در ++C – تشخیص چهره
- مجموعه آموزشهای برنامهنویسی پایتون Python
- آموزش پایتون: مفاهیم OpenCV برای تشخیص چهره و حرکت — راهنمای مقدماتی
- یادگیری ماشین (Machine Learning) چیست؟ — راهنمای کامل
==








سلام من از ویندوز ده استفاده می کنم وقتی نی خوام dlibرو نصب کنم خطای میده مبنی به اینکه باید ویژوال استدیو رو نصب کنم این یعنی من حتما باید این برنامه رو نصب کنم یا راه حل دیگه ای داره ممنون میشم اگه راهنمایی کنید
با سلام. من هم همچین مشکلی داشتم.
به لینک زیر بروید و کتابخانه مطابق با ورژن پایتون نصب شده روی سیستمان نصب کنید.
https://github.com/sachadee/Dlib
البته الگوریتمی face detection که امروزه معمولا ازش استفاده میشه MTCNN هست که سه شبکه CNN داره که هم real-time هست و هم دقت بسیار بهتری در تشخیص صورت های کوچک نسبت به روش های بالا داره…