


تحلیل معنایی (Semantic Analysis) در طراحی کامپایلر – راهنمای جامع
در این نوشته شیوه ساخت یک درخت تجزیه از سوی تجزیهکننده را در فاز تحلیل معنایی بررسی میکنیم. درخت تجزیه سادهای که در این فاز ساخته شده است، به طور کلی برای یک کامپایلر کاربردی ندارد، چون هیچ اطلاعاتی در مورد شیوه ارزیابی درخت ندارد. محصولات گرامر مستقل از متن که قواعد زبان را تشکیل میدهند، شیوه تفسیر آنها را نشان نمیدهند.




برای نمونه
E → E + T
محصول CFG فوق، هیچ قاعده معنایی مرتبط مانند توکنها و یا ساختار نحوی ندارد. تحلیل معنایی به تفسیر نمادها، انواع آنها و روابط آنها با همدیگر کمک میکند. تحلیل معنایی تعیین میکند که آیا ساختار نحوی که در برنامه منبع ایجاد شده معنایی دارد یا نه.
CFG + semantic rules = Syntax Directed Definitions
برای نمونه
int a = “value”;
نمیتواند خطایی در فاز تحلیل واژهای و نحوی ایجاد کند، چون از نظر واژگانی و ساختاری صحیح است؛ اما میتواند یک خطای معنایی ایجاد کند، چون نوع انتساب فرق میکند. این قواعد از سوی گرامر زبان تعیین میشوند و در تحلیل معنایی مورد ارزیابی قرار میگیرند. وظایف زیر در فاز تحلیل معنایی اجرا میشوند:
- تحلیل دامنه
- بررسی نوع
- بررسی کرانهای آرایه
- خطاهای معنایی
برخی از خطاهای معنایی را که انتظار داریم تحلیلگر معنایی تشخیص دهد به صورت زیر هستند:
- عدم تطبیق نوع
- متغیر اعلان نشده
- استفاده نادرست از شناسه رزرو شده
- اعلان چندباره متغیر در دامنه
- عدم تطبیق پارامتر واقعی و رسمی
گرامر صفت
گرامر صفت نوع خاصی از گرامر مستقل از متن است که برخی اطلاعات (صفتهای) اضافی به یک یا چند مورد از غیر پایانیها الحاق میشوند تا اطلاعات حساس به متن را ارائه کنند. هر صفت، دامنه کاملاً تعریفشدهای از مقادیر مانند اعداد صحیح، اعشاری، کاراکتر، رشته و یا عبارت دارد.
گرامر صفت واسطهای برای ارائه تحلیل معناشناختی گرامر مستقل از متن است و به تعیین دستور زبان و معناشناسی یک زبان برنامهنویسی کمک میکند. گرامر صفت (وقتی به صورت یک درخت تجزیه نگریسته شود) میتواند مقادیر یا اطلاعات را در میان گرههای یک درخت جابجا کند.
مثال
E → E + T { E.value = E.value + T.value }
بخش راست CFG شامل قواعد معناشناختی است که شیوه تفسیر گرامر را تعیین میکنند. در این جا مقادیر غیر پایانی E و T به همدیگر اضافه شدهاند و نتیجه به غیر پایانی E کپی شده است.
صفتهای معناشناختی را میتوان در زمان تجزیه به مقادیرشان در دامنه انتساب داد و در زمان انتساب یا تعیین شرط مورد ارزیابی قرار داد. بر اساس روش دریافت مقادیر از سوی صفتها، میتوان آنها را به دو دسته کلی تقسیم کرد: صفتهای ترکیبی و صفتهای موروثی.
گرامر صفت (Synthesized attributes)
این صفتها مقادیرشان را از مقدار صفتهای گرههای فرزند خود میگیرند. برای نشان دادن این وضعیت ترکیب زیر را تصور کنید:
S → ABC
اگر S مقدار خود را از گرههای فرزندش (A,B,C) بگیرد، در این صورت گفته میشود که یک صفت ترکیبی است، چون مقادیر ABC در S ترکیب شدهاند.
در این مورد نیز همانند مثال قبلی E → E + T، گره والد E مقدار خود را از گره فرزندش میگیرد. صفتهای ترکیبی هرگز مقادیر خود را از گرههای والد یا هر گره همنیای دیگر نمیگیرند.
صفتهای موروثی (Inherited attributes)
برخلاف صفتهای ترکیبی، صفتهای موروثی میتوانند مقدارشان را از والد و/یا همنیاهای خود بگیرند. در ترکیب زیر
S → ABC
A میتواند مقدار خود را از هر یک از S، B و C بگیرد. B میتواند مقدار خود را از S، A و C بگیرد به طور مشابه C میتواند مقدار خود را از S، A و B بگیرد.
- بسط: منظور زمانی است که یک آیتم غیر پایانی بر اساس یک قاعده گرامری به صورت پایانی بسط مییابد.

- کاهش: زمانی است که یک پایانی بر اساس قواعد گرامری به غیر پایانی متناظر خود کاهش مییابد. درختهای نحوی به روش بالا به پایین و چپ به راست تجزیه میشوند. هر زمان که کاهش رخ میدهد، ما از قواعد معناشناختی متناظر استفاده میکنیم.
تحلیل معنایی از «ترجمههای جهتدار نحوی» (Syntax-Directed Definitions) یا به اختصار SDT برای اجرای وظایف فوق استفاده میکند.
تحلیلگر معنایی AST (درخت نحوی مجرد) را از مرحله قبلی (تحلیل نحوی) دریافت میکند.
تحلیلگر معنایی اطلاعات صفتی را به AST ملحق میکند و بدین ترتیب AST صفتی نامیده میشود.
صفتها مقدارهای دوتایی هستند: <نام صفت، مقدار صفت>
برای نمونه:
int value = 5; <type, “integer”> <presentvalue, “5”>
برای هر محصول، یک قاعده معناشناختی الحاق میشود.
SDT-های S-attributed
اگر یک SDT تنها از صفتهای ترکیبی استفاده کند به نام SDT S-attributed نامیده میشوند. این صفتها با استفاده از SDT-های S-attributed ارزیابی میشوند. اقدامهای معناشناختی چنین SDT-هایی پس از هر محصول (سمت راست) نوشته شدهاند.
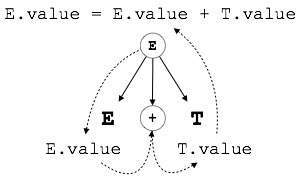
همان طور که در تصویر فوق میبینید SDT-های S-attributed در تجزیه پایین به بالا ارزیابی میشوند چون مقادیر گرههای والد به مقادیر گرههای فرزند وابسته هستند.
SDT-های L-Attributed
این شکل از SDT هم از صفتهای ترکیبی و هم موروثی استفاده میکند و تنها محدودیت آن این است که مقدر خود را از گره همنیای راست دریافت نمیکنند.
در SDT-های L-Attributed، یک غیر پایانی میتواند مقدار خود را از گرههای والد، فرزند و همنیای خود بگیرد. در محصول زیر
S → ABC
S میتواند مقادیر خود را از A، B و C بگیرد (ترکیبی). A میتواند تنها از S بگیرد. B میتواند مقدار خود را از S و A بگیرد. C میتواند از S، A و B مقدار بگیرد. هیچ آیتم غیر پایانی نمیتواند مقدار خود را از همنیای سمت راستش بگیرد.
صفتها در SDT-های L-Attributed به روش تجزیه عمق-نخست و چپ به راست ارزیابی میشوند.
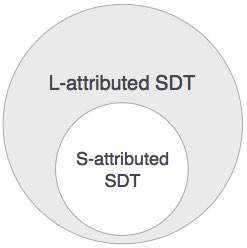
میتوان نتیجه گرفت که اگر یک تعریف S-attributed داشته باشیم در این صورت شامل L-Attributed نیز میشود، زیرا گرامرهای L-Attributed تعاریف S-attributed را احاطه کردهاند.
اگر این نوشته مورد توجه شما واقع شده، پیشنهاد میکنیم موارد زیر را نیز ملاحظه کنید:
- مجموعه آموزشهای دروس مهندسی کامپیوتر
- مجموعه آموزشهای ابزارهای مهندسی کامپیوتر
- آموزش طراحی کامپایلر
- انواع تجزیه — طراحی کامپایلر
- آموزش تجزیه انتقال (کاهش) در طراحی کامپایلر
- تحلیل واژهای (Lexical Analysis) در طراحی کامپایلر — راهنمای جامع
- آموزش گرامرها در طراحی کامپایلر
==










