


بهینه سازی کد (Code Optimization) در طراحی کامپایلر – راهنمای جامع
بهینهسازی کد یکی از تکنیکهای تبدیل برنامه است که در آن تلاش میشود تا با کاهش مصارف (CPU یا حافظه) کد را بهینه ساخته و سرعت اجرا را بالا برد. در بهینهسازی، سازههای برنامهنویسی عمومی سطح بالا با کدهای برنامهنویسی سطح پایین که کارایی بالا دارند جایگزین میشوند. فرایند بهینهسازی کد باید از این سه قاعده پیروی کند:




- کد خروجی نمیبایست به هیچ وجهی معنای برنامه را تغییر دهد.
- بهینهسازی باید باعث افزایش سرعت برنامه و در صورت امکان کاهش مصارف منابع از سوی برنامه شود.
- بهینهسازی باید خودش سریع باشد و در فرایند کلی کامپایل تأخیر ایجاد نکند.
تلاش در جهت بهینهسازی کد میتواند در مراحل مختلف فرایند کامپایل کردن انجام گیرد:
- در آغاز کاربران میتوانند کد را تغییر دهند یا بازآرایی کنند و یا از الگوریتمهای بهتری برای نوشتن کد بهره بگیرند.
- پس از ایجاد کد میانی، کامپایلر میتواند کد میانی را طوری تغییر دهد که با بهبود محاسبات و حلقهها، کد را بهبود بخشید.
- هنگام ایجاد کد برای ماشین مقصد، کامپایلر میتواند از سلسلهمراتب حافظه و ثباتهای CPU به منظور بهینهسازی کمک بگیرد.
بهینهسازی را به طور کلی میتوان به دو نوع تقسیم کرد: وابسته به ماشین و مستقل از ماشین.
بهینهسازی مستقل از ماشین
کامپایلر در این روش بهینهسازی کد میانی را میگیرد و آن را به بخشی از کد تبدیل میکند که شامل هیچ ثبات CPU یا موقعیت مطلق حافظه نیست.
برای نمونه:
do
{
item = 10;
value = value + item;
} while(value<100);
این کد شامل انتساب ثباتهای آیتم شناسه است که به صورت زیر بهینهسازی میشود:
Item = 10;
do
{
value = value + item;
} while(value<100);
بدین ترتیب نه تنها چرخههای CPU بهینهسازی میشوند؛ بلکه میتوانند از سوی پردازنده نیز مورد استفاده قرار گیرند.
بهینهسازی وابسته به ماشین
بهینهسازی وابسته به ماشین پس از این که کد مقصد تولید شد و هنگامی که کد بر اساس معماری ماشین مقصد تبدیل میشود صورت میپذیرد. در این روش از ثباتهای CPU و احتمالاً ارجاعهای مطلق حافظه به جای ارجاعهای نسبی استفاده میشود. بهینهسازهای وابسته به ماشین تلاش میکنند تا از بیشترین مزیت سلسلهمراتب حافظه استفاده کنند.
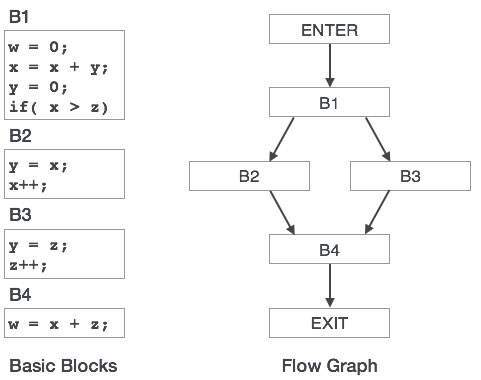
بلوکهای پایه
کدهای منبع به طور عمومی چند دستورالعمل دارند که همواره انتظار میرود پشت سر هم باشند و به عنوان بلوکهای پایهای کد محسوب میشوند. در میان این بلوکهای پایهای هیچ عبارت پرش (jump) وجود ندارد، یعنی هنگامی که دستورالعمل اجرا میشود همه دستورالعملها در یک بلوک پایه به ترتیبی که نوشته شدهاند و بدون از دست دادن کنترل گردش برنامه اجرا میشوند. یک برنامه میتواند سازههای مختلفی به صورت بلوکهای پایه داشته باشد مانند عبارتهای شرطی IF-THEN-ELSE، SWITCH-CASE و حلقههایی مانند DO-WHILE, FOR, و REPEAT-UNTIL و مواردی از این دست.
شناسایی بلوکهای پایه
ما میتوانیم از الگوریتم زیر برای یافتن بلوکهای پایه در یک برنامه استفاده کنیم:
- عبارتهای هدر جستجو برای همه بلوکهای پایه از جایی که بلوک پایه آغاز میشود.
- عبارت نخست یک برنامه
- عبارتهایی که هر گونه انشعاب را نشان میدهند (شرطی/غیرشرطی)
- عبارتهایی که پس از عبارت شرطی میآیند.
- عبارتهای هدر و عبارتهای پس از آن که یک بلوک پایه تشکیل میدهند.
- یک بلوک پایه شامل هیچ عبارت هدر از هیچ بلوک پایه نباشد.
بلوکهای پایه مفاهیمی مهم هم از نظر تولید کد و هم از نقطهنظر بهینهسازی کد محسوب میشوند.

بلوکهای پایه نقشی مهم در شناسایی متغیرهایی که بیش از یک بار در یک بلوک پایه منفرد استفاده میشوند دارند. اگر هر متغیری بیش از یک بار استفاده شود، حافظه ثبات تخصیص یافته به آن لازم نیست تا زمان پایان اجرا خالی شود.
گراف کنترل گردش
بلوکهای پایه در یک برنامه میتوانند به وسیله گرافهای گردش کنترل نمایش یابند. یک گراف کنترل گردش چگونگی گردش کنترل در میان بلوکهای متفاوت را نشان میدهد. این ابزاری مفید برای کمک به بهینهسازی است و از طریق شناسایی مکانهای حلقههای ناخواسته در برنامه به بهینهسازی کد کمک میکند.
بهینهسازی حلقه
اغلب برنامهها به صورت یک حلقه در سیستم اجرا میشوند. برای این که در چرخههای CPU و حافظه صرفهجویی کنیم، لازم است که حلقهها بهینهسازی شوند. حلقهها میتوانند با تکنیکهای زیر بهینهسازی شوند:
- کد نامتغیر – یک بخش از کد که در حلقه قرار دارد و مقدار یکسانی را در هر بار تکرار محاسبه میکند به نام کد نامتغیر حلقه نامیده میشود. این کد را میتوان به جای تکرار محاسبات، از حلقه خارج ساخت و تنها یک بار آن را محاسبه کرد.
- تحلیل القایی – یک متغیر در صورتی متغیر القایی نامیده میشود که مقدار آن درون حلقه بر اساس مقدار نامتغیر حلقه تغییر یابد.
- کاهش مصرف – برخی عبارتها هستند که چرخههای CPU، زمان و حافظه زیادی مصرف میکنند. این عبارتها باید بدون این که خروجی عبارت به مخاطره بیفتد، با عبارتهای کمهزینهتر جایگزین شوند. برای نمونه ضرب (x * 2) بر حسب چرخههای CPU نسبت به (X << 1) پر هزینه است در حالی که نتیجه یکسانی ارائه میکند.
حذف کد مُرده
منظور از کد مرده یک یا چند عبارت کد است که شرایط زیر را دارد:
- هرگز اجرا نمیشود یا غیر قابل دسترسی است
- و یا در صورت اجرا، خروجی آن هرگز مورد استفاده قرار نمیگیرد.
از این رو کد مرده هیچ نقشی در هیچ یک از عملیاتهای برنامه ندارد و بنابراین میتوان به سادگی آن را حذف کرد.
کد نیمه مرده
برخی عبارتهای کد وجود دارند که مقادیر محاسبه شده آنها تحت شرایط خاصی مورد استفاده قرار میگیرند. یعنی برخی اوقات این مقادیر استفاده میشوند و برخی اوقات استفاده نمیشوند. چنین کدهایی به نام کدهای نیمه مرده نامیده میشوند.
گراف گردش کنترل فوق بخشی از برنامه را نشان میدهد که در آن متغیر a برای انتساب به خروجی عبارت x* y استفاده میشود. فرض کنید که این مقدار انتساب یافته a هرگز درون حلقه استفاده نمیشود. بلافاصله پس از این که کنترل از حلقه خارج میشود، مقدار a به متغیر z انتساب مییابد که میتواند بعدتر در برنامه استفاده شود. نتیجه میگیریم که کد انتساب یافته a هرگز هیچ جای دیگری استفاده نمیشود و از این رو میتوان آن را حذف کرد.
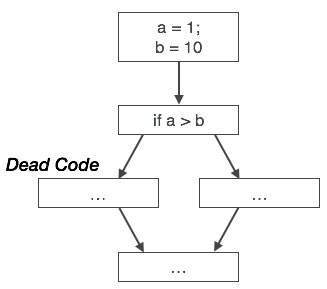
به طور مشابه تصویر فوق نشان میدهد که عبارت شرطی همواره نادرست است و بدان معنی است که کد نوشته شده برای حالت درست هرگز اجرا نمیشود و از این رو میتوان آن را حذف کرد.
افزونگی بخشی
عبارتهای دارای افزونگی عبارتهایی هستند که بیش از یک بار در مسیر موازی بدون هیچ تغییری در عملوندها محاسبه میشوند. اما عبارتهای دارای افزونگی بخشی در یک مسیر و بدون تغییری در عملوندها بیش از یک بار محاسبه میشوند.
برای مثال:


کد نامتغیر حلقه دارای افزونگی بخشی است و میتواند با استفاده از تکنیک جابجایی کد (code-motion) حذف شود. نمونه دیگر از کد دارای افزونگی بخشی به صورت زیر میتواند باشد:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;
ما فرض میکنیم که مقادیر عملوندها (y و z) از انتساب متغیر a به متغیر c تغییر نمییابند. در این جا اگر عبارت شرطی درست باشد در این صورت y OP z دو بار محاسبه شده است؛ در غیر این صوت یک بار محاسبه شده است. از جابجایی کد میتوان برای حذف این افزونگی استفاده کرد که در بخش زیر نمایش یافته است:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;
در این بخش چه شرط درست باشد و چه نادرست باشد y OP z تنها یک بار محاسبه خواهد شد. بدین ترتیب به انتهای سلسله مطالب راهنمای طراحی کامپایلر فرادرس میرسیم. هر گونه دیدگاه یا پیشنهاد خود را میتوانید در بخش نظرات در زیر این نوشته با ما و دیگر خوانندگان فرادرس در میان بگذارید.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز ملاحظه نمایید:
- آموزش طراحی کامپایلر
- مجموعه آموزشهای مهندسی نرم افزار
- آموزش گرامرها در طراحی کامپایلر
- کامپایلر، طراحی و معماری آن — به زبان ساده
- مجموعه آموزشهای علوم کامپیوتر
- آموزش طراحی کامپایلر (مرور و حل تست های کنکور کارشناسی ارشد)
==










