


ویژگی های مدرن ++C که باید بدانید – راهنمای کاربردی
زبان برنامهنویسی ++C در طی زمان تکامل زیادی یافته است. البته این تکامل در طی یک شب رخ نداده است. زمانی بود که ++C فاقد دینامیسم بود، اما اینک آن وضعیت دیگر وجود ندارد. همه چیز از زمانی که کمیته استانداردسازی ++C تصمیم گرفت اوضاع را تغییر دهد آغاز شد. این زبان برنامهنویسی از سال 2011 به صورت یک زبان دینامیک و مداوماً در حال تکامل ظاهر شده است و با معرفی ویژگی های مدرن ++C به زبانی تبدیل شده که افراد زیادی به آن دل بستهاند.




البته نباید تصور کنید که این زبان برنامهنویسی آسانتر شده است. ++C همچنان اگر نگوییم دشوارترین زبان برنامهنویسی است، دستکم یکی از دشوارترینها محسوب میشود که استفاده گستردهای دارد، اما ++C در نسخههای اخیر نسبت به نسخههای قدیمی، کاربرپسندتر شده است. در این مقاله قصد داریم برخی از ویژگیهای جدید (از نسخه 11++C به بعد که البته شاید همچنان قدیمی محسوب شود) را بررسی کنیم که هر توسعهدهندهای باید بداند.
کلیدواژه auto
هنگامی که 11++C در ابتدا کلیدواژه auto را معرفی کرد، موجب گشایش زیادی در این زبان شد. ایده auto این بود که کامپایلر ++C به جای این که شما را مجبور کند هر بار نوع داده خود را اعلان کنید، بتواند نوع دادههای شما را در زمان کامپایل کردن تشخیص دهد. بدین ترتیب داشتن انواع دادهای مانند زیر کار را بسیار راحتتر میکند:

به خط پنجم نگاه کنید. شما نمیتوانید چیزی را بدون استفاده از initializer اعلان کنید. این وضعیت در عمل مفید است. خط 5 اجازه نمیدهد کامپایلر بداند داده از چه نوعی است.
سیر تکامل auto
در ابتدا auto چیزی محدود بود. سپس در نسخههای بعدی این زبان، توان زیادی به آن داده شد.

در خط 7 و 8 از مقداردهی براکت دار استفاده کردهایم. این نیز یکی از ویژگیهایی است که در نسخه 11++C اضافه شده است. به خاطر داشته باشید که در صورت استفاده از auto باید روشی باشد که کامپایلر با استفاده از آن بتواند نوع داده را استنتاج کند. اینک سؤال مفید این است که اگر کد زیر را بنویسیم چه اتفاقی میافتد؟
آیا نتیجه اجرای کد فوق یک خطای کامپایل یا یک بردار است؟ در واقع 11++C مفهومی به شکل زیر معرفی کرده است:
این لیست با مقداردهی داخل براکت، در صورت اعلان شدن با auto به عنوان یک کانتینر سبک تلقی میشود. در نهایت همان طور که قبلاً اشاره کردیم، استنتاج نوع از سوی کامپایلر میتواند در مواردی که ساختمان داده پیچیدهای وجود دارد کاملاً مفید باشد:

در کد فوق خط 25 را بررسی کنید. عبارت auto [v1،v2] = itr.second به صورت لفظی یک ویژگی جدید در ++C محسوب میشود. نام این ویژگی «اتصال ساختیافته» (structured binding) است. در نسخههای قبلی این زبان باید هر متغیر به صورت مستقل استخراج میشد، اما اتصال ساختیافته این کار را آسانتر ساخته است.
به علاوه اگر خواسته باشید دادهها را با استفاده از ارجاع به دست آورید، کافی است نمادی به صورت زیر اضافه کنید:
عبارت لامبدا
در نسخه 11++C عبارتهای لامبدا معرفی شدند که چیزی مانند «تابعهای بینام» (anonymous functions) در جاوا اسکریپت هستند. عبارتهای لامبدا اشیای تابع هستند که فاقد نام هستند و متغیرها را روی دامنههای مختلف بر اساس نوعی ساختار منسجم به دست میآورند. همچنین میتوان آنها را به متغیر انتساب داد.
لامبداها در صورتی که قرار باشد کار سریع و کوچکی درون کد انجام شود؛ اما نوشتن یک تابع کامل مجزا برای آن وقتگیر باشد، بسیار مفید خواهند بود. استفاده رایج دیگر از این عبارتها به صورت تابعهای مقایسه است.

مثال فوق حرفهای زیادی برای گفتن دارد.
ابتدا توجه کنید که چگونه مقداردهی براکتی بار زیادی را از عهده شما بر میدارد. سپس ژنریکهای ()begin و ()end وجود دارند که آنها نیز جزء قابلیتهای اضافه شده در 11++C هستند. پس از آن تابع لامبدا به عنوان یک مقایسه کننده برای دادهها آمده است. پارامترهای تابع لامبدا به صورت auto تعریف میشوند که در نسخه 14++C اضافه شده است. تا پیش از این نسخه نمیتوانستیم از auto برای پارامترهای تابع استفاده کنیم.
توضیح براکتها
دقت کنید که چگونه عبارتهای لامبدا با یک براکت مربعی [] آغاز میشوند. بدین ترتیب دامنه لامبدا یعنی میزان نفوذی که روی متغیرها و اشیای محلی دارد تعریف میشود.
به طور خلاصه این وضعیت در ++C مدرن به شرح زیر است:
- [] – هیچ چیز دریافت نمیشود. بنابراین نمیتوانید از هیچ متغیر محلی با دامنه خارج از عبارت لامبدا استفاده کنید. در این حالت تنها میتوان از پارامترها استفاده کرد.
- [=] – شیءهای محلی (متغیرها و پارامترهای محلی) در دامنه به وسیله مقدار دریافت میشوند. میتوان از آنها استفاده کرد، اما امکان تغییر دادن آنها وجود ندارد.
- [&] – اشارهگر this به صورت «با مقدار» دریافت میشود.
- [this] - اشارهگر this با مقدار دریافت میشود.
- [a، &b] – شیء a با مقدار و شیء b با ارجاع دریافت میشود.
بدین ترتیب اگر بخواهیم دادهها را در داخل تابع لامبدا به نوعی قالب دیگر تبدیل کنیم، میتوانیم با بهرهگیری از دامنهبندی از لامبدا استفاده کنیم. برای نمونه:

در مثال فوق اگر متغیرهای محلی را با مقدار یعنی به صورت [factor] در عبارت لامبدا دریافت کنیم، نمیتوانیم factor را در 5 تغییر دهیم. زیرا چنین اجازهای نداریم.
در نهایت توجه کنید که ما val را به صورت با ارجاع دریافت میکنیم. این امر تضمین میکند که هر تغییری درون تابع لامبدا اتفاق بیفتد، در عمل موجب تغییر vector خواهد شد.
گزارههای init درون if و switch
یکی دیگر از ویژگیهای جذاب ++C هفده گزارههای init است. به مثال زیر توجه کنید:

به ظاهر اینک میتوانیم متغیرها را درون بلوک if/switch مقداردهی کرده و شرطها را بررسی کنیم. این وضعیت برای حفظ انسجام و تمیزی کد بسیار حائز اهمیت است. شکل کلی به صورت زیر است:
اجرای وظیفه فوق در زمان کامپایل با constexpr
تصور کنید نوعی عبارت برای ارزیابی دارید و مقدار آن از زمان مقداردهی اولیه به بعد تغییر نخواهد یافت. بدین ترتیب میتوان مقدار را از پیش محاسبه کرد و سپس به عنوان یک ماکرو از آن استفاده کرد. روش دیگر این است که از ویژگی constexpr که در ++C یازده ارائه شده است بهره گرفت.
برنامهنویسان علاقهمند هستند که محیط زمان اجرای برنامه را تا حد امکان سبک کنند. بنابراین اگر عملیاتی وجود داشته باشد که کامپایلر میتواند انجام دهد و بار را از عهده زمان اجرا بردارد موجب بهبود زمان اجرای برنامه خواهد شد.

کد فوق نمونه بسیار رایجی از constexpr است.
از آنجا که ما تابع محاسبه فیبوناچی را به صورت constexpr اعلان کردهایم، کامپایلر (fib(20 را از قبل در زمان کامپایل محاسبه میکند. بنابراین پس از کامپایل کردن میتواند خط زیر را:
با خط زیر جایگزین کند:
توجه کنید که آرگومان ارسالی یک مقدار const است. این یکی از نکات مهم تابعهای اعلانشده با constexpr است. آرگومانهای ارسالی باید constexpr یا const باشند؛ در غیر این صورت تابع به صورت یک تابع نرمال رفتار میکند که در زمان کامپایل هیچ محاسبه قبلی صورت نمیگیرد.
متغیرها نیز میتوانند constexpr باشند. در چنین حالتی چنان که میتوان حدس زد، این متغیرها باید در زمان کامپایل ارزیابی شوند. در غیر این صورت ممکن است با خطای کامپایل مواجه شوید.
نکته جالب این است که بعدتر و در نسخه C++17 به صورت constexpr-if و constexpr-lambda نیز معرفی شدند.
چندتاییها
چندتایی با tuple دقیقاً همانند pair مجموعهای از مقادیر با اندازه ثابت از انواع دادههای مختلف است.
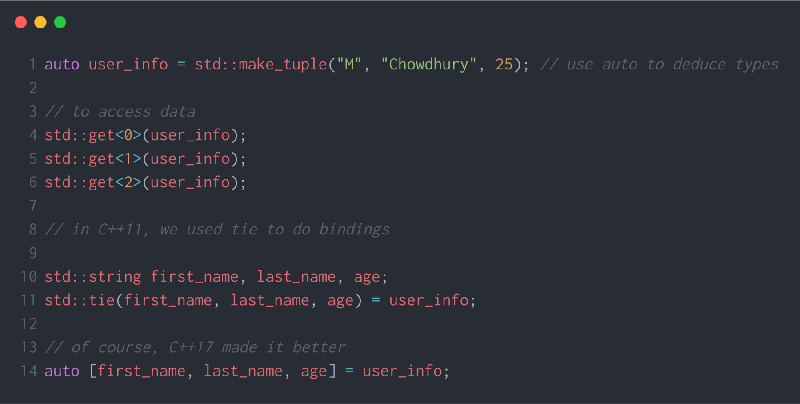
برخی اوقات استفاده از std::array به جای tuple راحتتر است. array مشابه آرایه ساده C به همراه چند کارکرد دیگر است که در کتابخانه استاندارد ++C وجود دارند. این ساختمان داده در نسخه 11++C معرفی شده است.
استنتاج آرگومان قالب کلاس
چنان که میبینید نام ویژگی فوق کاملاً گویای کارکرد آن است. از نسخه 17++C این ایده مطرح شد که استنتاج آرگومان برای قالبهای کلاس استاندارد نیز اتفاق بیفتد. تا پیش از آن این امکان صرفاً برای قالبهای تابع میسر بود. در نتیجه امکان نوشتن کد زیر مهیا شد:
استنتاج به صورت ضمنی انجام مییابد. این وضعیت در مورد tuple بسیار کار را راحتتر میکند.
توجه داشته باشید که این ویژگی در صورتی که به طور کامل با قالبهای ++C آشنا نباشید، چندان به کار شما نخواهد آمد.
اشارهگرهای هوشمند
اشارهگرها میتوانند واقعاً دردسرساز باشند. به دلیل میزانی از آزادی که زبانهایی مانند ++C در اختیار برنامه نویسان قرار میدهند، در برخی موارد ممکن است موجب شوند که این برنامه نویسان به خود آسیب بزنند. و در اغلب موارد اشارهگرها موجب وارد آمدن این آسیب میشوند.
خوشبختانه در نسخه 11++C ایده اشارهگرهای هوشمند مطرح شد. این اشارهگرها نسبت به اشارهگرهای معمولی بسیار راحتتر هستند. اشارهگرهای هوشمند به برنامه نویسان کمک میکنند تا با آزاد کردن حافظه در موارد ممکن از بروز نشت حافظه جلوگیری کنند. همچنین امنیت exception را موجب میشوند.
ما میتوانستیم در این مقاله در مورد اشارهگرهای هوشمند توضیحهای زیادی بنویسیم، اما گویا جزییات مهم زیادی در مورد آنها وجود دارد که توضیح دادن همه آنها به یک مقاله جداگانه و اختصاصی نیاز دارد.
سخن پایانی
بدین ترتیب به پایان این مقاله میرسیم. به خاطر داشته باشید که ++C عملاً ویژگیهای بسیار جدیدی در نسخههای اخیر خود افزوده است. شما میتوانید این موارد را در صورتی که علاقهمند باشید مورد بررسی قرار دهید. برای نمونه این ریپازیتوری گیتهاب (+) موارد آموزشی نسبتاً جامعی را در این خصوص گردآوری کرده است.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامهنویسی
- آموزش پیشرفته C++ (شیگرایی در سیپلاسپلاس)
- آموزش برنامهنویسی C++
- آموزش ++C — راهنمای شروع یادگیری
- کپسولهسازی در ++C و C — به زبان ساده
==











مطالب و آموزشهاتون خیلی عالیه.