



ضریب تغییرات و خطای نسبی – به زبان ساده
در آمار یکی از کارهایی که بیشتر اوقات صورت میگیرد، تخمین زدن است. معمولا میانگین نمونهای را به عنوان برآوردی از میانگین جامعه در نظر میگیریم. به این ترتیب پارامتر جامعه را بوسیله نمونه مشخص میکنیم. البته میدانیم که این کار همیشه با مقداری خطا همراه است که با توجه به نمونه گرفته شده، مقدار این خطا قابل اندازهگیری است. در نوشتارهای دیگری از مجله فرادرس با مفهوم ضریب تغییرات و خطای نسبی آشنا شدهاید. در اینجا هم میخواهیم بین این دو اصطلاح یک پیوند برقرار کنیم و مشخص کنیم آنچه که بوسیله ضریب تغییرات اندازهگیری میشود همان خطای نسبی مشاهدات برای برآورد میانگین است.

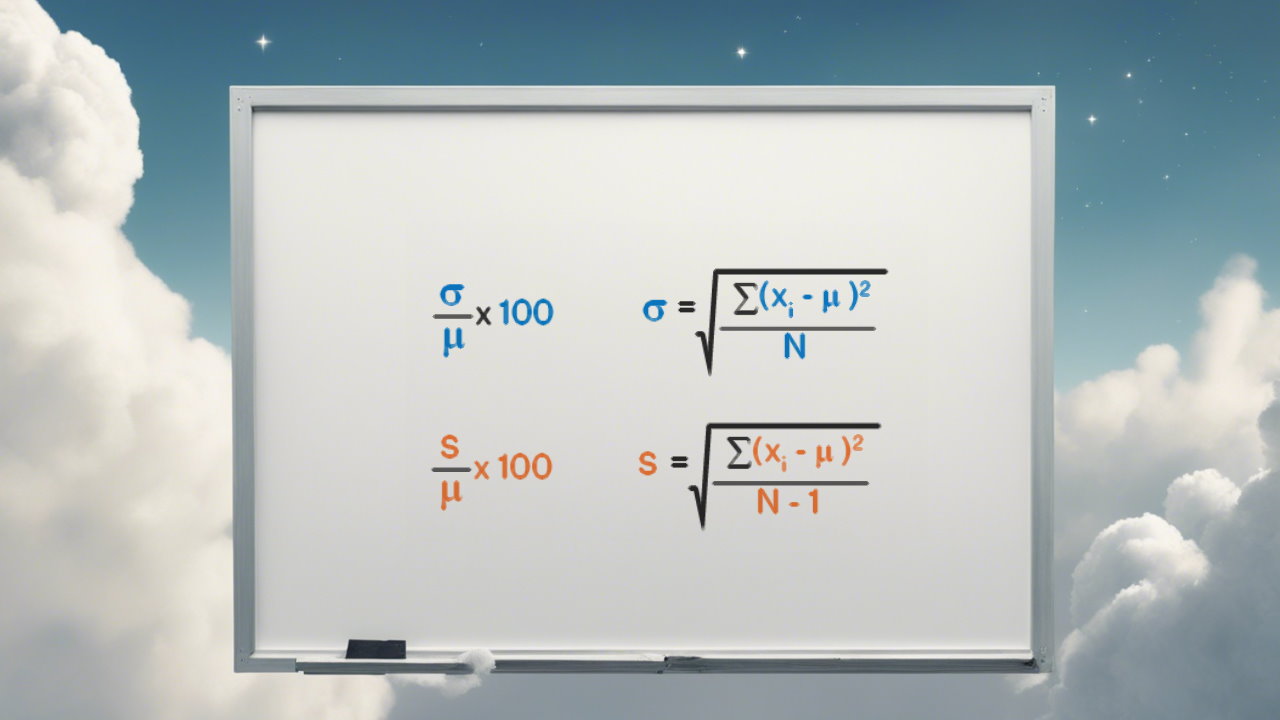


به منظور آشنایی بیشتر با مفاهیم و اصطلاحات به کار رفته در این نوشتار، بهتر است مطالب واریانس و اندازههای پراکندگی — به زبان ساده و خطای اندازه گیری — به زبان ساده را مطالعه کنید. همچنین خواندن نوشتارهای ضریب تغییرات در SPSS — راهنمای کاربردی و دقت و صحت اندازه گیری – به زبان ساده نیز خالی از لطف نیست.
ضریب تغییرات و خطای نسبی
یکی از شاخصهای آمار توصیفی که اغلب برای نمایش و مقایسه میزان پراکندگی بین دو جامعه یا دو متغیر به کار میرود، «ضریب تغییرات» (Coefficient of Variation) است. از آنجایی که کم بودن پراکندگی، نشانگر همگن بودن جامعه است، هر چه میزان ضریب تغییرات کمتر باشد، میانگین را معیار بهتری برای نقطه تمرکز مییابیم.
بنابراین در بین دو جامعه، آن که دارای ضریب تغییرات کمتری باشد، جامعه بهتری بوده، زیرا نتایج گرفته شده از شاخص میانگین، دقت بیشتری دارند. از آنجایی که ضریب تغییرات بوسیله یک نسبت از کمیتهای هم واحد، محاسبه و ساخته میشود، هیچ واحد اندازهگیری نداشته و به صورت درصدی مورد استفاده قرار میگیرد. همین موضوع نیز اهمیت استفاده از این شاخص را برای مقایسه بین جوامع مختلف، مشخص میکند.

از طرفی برای محاسبه یا تخمین خطا نیز روشهای گوناگونی وجود دارد. برای مثال میتوان به «خطای مطلق» (Absolute Error) و «خطای نسبی» (Relative Error) اشاره کرد که هر یک به شیوههای متفاوت، خطای یک تخمین برای یک مقدار مشخص را تعیین میکنند.

محاسبه ضریب تغییرات
معیارها و شاخصهای مختلفی برای اندازهگیری پراکندگی دادهها وجود دارد. برای مثال «دامنه تغییرات» (Range) یک معیار ساده بوده که حداکثر میزان پراکندگی را نشان میدهد. ولی به نظر میرسد بعضی خصوصیات و ويژگیهای خاصی که یک شاخص پراکندگی باید داشته باشد، در دامنه تغییرات وجود ندارد. چند نمونه از این خصوصیات در ادامه ذکر شدهاند.
- شاخص پراکندگی باید به کمک یک عدد، میزان پراکندگی را نمایش دهد.
- شاخص پراکندگی باید فاصله یا دوری دادهها را اندازهگیری کند.
- شاخص پراکندگی باید فاصله یا دوری را نسب به یک نقطه مرکزی محاسبه کند.
- شاخص پراکندگی باید با تغییر مقیاس دادهها تغییر نکند.
همانطور که میدانید، شاخصهای مختلفی برای اندازهگیری پراکندگی معرفی شدهاند. دامنه تغییرات، میانگین قدرمطلق فاصله از میانگین، میانگین قدرمطلق فاصله از میانه، واریانس (Variance)، انحراف معیار (Standard Deviation) و ضریب تغییرات در این گروه از شاخصهای آمار توصیفی (Descriptive Statistics) قرار گرفتهاند.
به غیر از دامنه تغییرات، بقیه شاخصها، نقطهای را به عنوان معیار تمرکز در نظر گرفته و پراکندگی را حول آن اندازهگیری میکنند ولی دامنه تغییرات حداکثر فاصله را محاسبه میکند. جدول ۱، به بررسی خصوصیات هر یک از این شاخصها پرداخته است.
جدول ۱: مقایسه ویژگیهای شاخصهای پراکندگی
| شاخص | فرمول محاسبات | پراکندگی نسبت به نقطه مرکزی | وابستگی به مقیاس دادهها |
| دامنه تغییرات - Range | ندارد | دارد | |
| میانگین قدر مطلق فاصله از میانگین- MAD | دارد - میانگین | دارد | |
| میانگین قدر مطلق فاصله از میانه- MADM | دارد - میانه | دارد | |
| واریانس- Variance | دارد - میانگین | دارد | |
| انحراف معیار - Standard Deviation | دارد - میانگین | دارد | |
| ضریب تغییرات- Coefficient of Variation | دارد- میانگین | ندارد |
همانطور که در جدول ۱ دیده میشود، به جز ضریب تغییرات، شاخصهای پراکندگی دیگر، به مقیاس اندازهگیری دادهها وابستگی دارند در نتیجه برای مقایسه معیار پراکندگی بین دو یا چند جامعه مناسب نیستند.
به یاد دارید که میانگین () و واریانس (Var)، همینطور انحراف معیار (SD) بوسیله رابطههای زیر محاسبه میشوند.
نکته: اغلب برای نمایش فرمول و رابطه محاسباتی ضریب تغییرات از علامت به عنوان میانگین و برای انحراف معیار استفاده میکنند. در نتیجه محاسبه ضریب تغییرات به شکل زیر خواهد بود.
رابطه ۱
محاسبه خطای نسبی
فرض کنید مقدار هدف تخمین باشد. به این منظور یک نمونه تصادفی در نظر گرفتهایم و میخواهیم بوسیله مشاهدات حاصل از آن، میانگین را تخمین بزنیم. هر یک از مقادیر مشاهده شده نسبت به مقدار واقعی که میانگین جامعه است، خطا یا اختلافی دارند.

گام اول برای محاسبه خطای نسبی، بدست آوردن خطای مطلق است. در نتیجه خطای مطلق برای هر یک از مشاهدات به صورت زیر محاسبه میشود. فرض کنید خطای مطلق را برای مشاهده ام به صورت مشخص کردهایم.
رابطه ۲
نکته: اغلب برای اندازهگیری خطا، از قدر مطلق فاصله استفاده میکنند زیرا جهت خطا مهم نبوده و فقط میزان خطا از اهمیت برخوردار است. ما این کار را در گام بعدی انجام خواهیم داد.
در گام دوم با تقسیم مقدار خطای مطلق بر مقدار هدف، خطای نسبی را بدست میآوریم. در اینجا خطای نسبی برای مشاهده ام را با نشان خواهیم داد.
رابطه ۳
گام سوم، نمایش مقدار مثبت این نسبت در رابطه ۳، است. با استفاده از قدر مطلق، میتوان این عمل را انجام داد. ولی به علت خاصی ما از تابع مربع یا توان ۲ استفاده میکنیم. در نتیجه خطای نسبی (با مقدار مثبت) را به صورت زیر محاسبه میکنیم.
رابطه ۴
تا اینجا، محاسبه صورت گرفته در رابطه ۴، همان خطای نسبی است که به توان ۲ رسیده است. ولی در قسمت بعدی نشان میدهیم که جذر این نسبت همان ضریب تغییرات است. بنابراین ضریب تغییرات و خطای نسبی هر دو ماهیت و شکل یکسانی دارند. به این ترتیب نشان میدهیم که ضریب تغییرات، میزان خطای نسبی مشاهدات برای میانگینشان است.
تفسیر ضریب تغییرات و خطای نسبی
در این قسمت رابطه ۴ را تبدیل به ضریب تغییرات معرفی شده در رابطه ۱ خواهیم کرد. طرف راست رابطه ۴ را در نظر بگیرید. با جایگزینی با مقداری که در رابطه ۲ معرفی شده، کار را ادامه میدهیم.
حال مخرج را به توان ۲ رسانده و جداگانه نمایش میدهیم.
از آنجا که محاسبه صورت گرفته، فقط برای یک مشاهده است با جمعبندی روی همه مشاهدات، یک عدد و شاخص برای کل نمونه تصادفی ایجاد میکنیم.
در انتها نیز از میانگینگیری برای جمعبندی استفاده میکنیم.
حال اگر از این عبارت جذر بگیریم، به مقدار خواهیم رسید.

در نتیجه ضریب تغییرات جذر، میانگین مربعات خطای نسبی مشاهدات برای میانگینشان خواهد بود. از طرفی میدانیم که خطای نسبی، به واحد اندازهگیری مقادیر وابسته نیست. به همین دلیل هم ضریب تغییرات به صورت درصدی و بدون حساسیت نسبت به واحد اندازهگیری است. همین ویژگی باعث میشود که برای مقایسه پراکندگی بین دو جامعه از این شاخص آماری استفاده شود.
خلاصه و جمعبندی
در این نوشتار روش محاسبه ضریب تغییرات و خطای نسبی مرور و نقاط مشترک آنها مشخص شد. به سادگی میتوان دید که ضریب تغییرات همان خطای نسبی مشاهدات برای برآورد میانگین است. بنابراین اگر میانگین را مبدا یا مرکز دادهها در نظر بگیریم، ضریب تغییرات، خطای نسبی را برای یک نمونه تصادفی به منظور برآورد میانگین نشان میدهد. مشخص است که فرمول محاسباتی ضریب تغییرات نیز همین موضوع را نشان داده و مشخص میکند به ازاء هر واحد تغییر در میانگین، به چه میزان یا نسبت واریانس یا انحراف معیار تغییر خواهند کرد.











سلام وقت بخیر
دکتر فرق بین relative devition با relative error چیه؟
در برخی از موارد ، انحراف معیار بیش از میانگین بوده و ضریب تغییرات بالای یک می شود. تفسیر این حالت چیست؟ آیا کافی است بگوئیم که با دادههای پرت و نرمال نبودن جامعه سروکار داریم؟
با سلام
جناب دکتر، CV داده هام خیلی بالا درآمده، حالا برای پایین آوردن cv چکار باید کنم؟
سلام داکتر صاحب شاخصهای پراکندگی وانحراف معیاری واریانس وضریب تغیرات وکاربرد آنها را بطور خلاصه اگر بیان کنید خوب میشود
سلام وقتتون بخیر
CV تا چه عددی قابل قبول هست؟
سلام و درود،
بزرگ بودن ضریب تغییرات نشان دهنده کوچک بودن میانگین از یک طرف و بزرگ بودن واریانس یا انحراف معیار است. این امر نشانگر آن است که داده ها همگن نیستند. البته لزومی به کم یا زیاد کردن مقدار cv نیست. این شاخص معمولا برای مقایسه به کار میرود و به تنهایی معنایی ندارد. بنابراین وقتی میگویید که cv زیاد است باید مشخص کنید که از چه چیزی بزرگتر است.
زمانی که میخواهید همگنی بین دو جامعه را مشخص کنید، cv کوچکتر جامعه همگن و یک شکل را نسبت به دیگری نشان میدهد.
بزرگ بودن cv گاهی ممکن است به معنی خوبی هم تفسیر شود. هر چه پراکندگی در یک جامعه مورد هدف یا آماری بزرگتر باشد، اطلاعات بیشتری نیز از مشاهدات دریافت خواهیم کرد. به این ترتیب نگران کوچکی یا بزرگی مقدار cv نباشید و آن را ملاکی برای مقایسه در نظر بگیرید.
از اینکه همراه مجله فرادرس بوده و مسائلتان را با ما در میان میگذارید بسیار سپاسگزاریم.
امیدوارم که در همه امور زندگی و تحصیلی موفق و پیروز باشید.