



میانگین خطای مطلق چیست و چگونه محاسبه می شود؟ – به زبان ساده
«میانگین خطای مطلق» (Mean Absolute Error | MAE) معیاری است که برای ارزیابی عملکرد مدلهای رگرسیونی در یادگیری ماشین بهکار گرفته میشود. عمده کاربرد میانگین خطای مطلق در سنجش دقت پیشبینیها است. در محاسبه این معیار از تفاضل مطلقِ میان دادههای حقیقی و پیشبینی شده، میانگین گرفته میشود. بهطور معمول زمانی از MAE استفاده میشود که بخواهیم کیفیت پیشبینیها را نسبت به اندازه مطلق و نه اندازه نسبی آنها ارزیابی کنیم. در این مطلب از مجله فرادرس یاد میگیریم میانگین خطای مطلق چیست و همچنین چگونه محاسبه و پیادهسازی میشود.
- یاد میگیرید چگونه از MAE برای ارزیابی دقت مدل استفاده کنید.
- خواهید آموخت مراحل محاسبه MAE را با پایتون انجام دهید.
- میآموزید تفاوتهای MAE ،MSE و سایر معیارها را بررسی کنید.
- با نقش مدلهای رگرسیونی و شبکه عصبی MLP در یادگیری ماشین آشنا میشوید.
- یاد خواهید گرفت ویژگیهای مثبت و محدودیتهای MAE را درک کنید.
- خواهید توانست معیار مناسب برای ارزیابی مدل را انتخاب کنید.




در این مطلب ابتدا مقدمهای از مدلهای رگرسیونی و همچنین تعریفی از میانگین خطای مطلق ارائه میدهیم. سپس با نحوه محاسبه میانگین خطای مطلق در زبان برنامهنویسی پایتون آشنا میشویم و پس از شرح کاربرد این معیار ارزیابی، در انتهای این مطلب از مجله فرادرس به مقایسه میانگین خطای مطلق با سایر معیارهای ارزیابی میپردازیم.
مقدمه ای بر مدل های رگرسیونی
پیش از پاسخ دادن به پرسش میانگین خطای مطلق چیست و با توجه به پیوستگی که میان این دو مبحث وجود دارد، ابتدا پیشزمینهای از مدلهای رگرسیونی ارائه میدهیم. رگرسیون از جمله مورد استفادهترین تکنیکهای یادگیری ماشین «نظارت شده» است که با توجه به قابلیت تشخیص ارتباط میان دو یا چند متغیر، در زمینههای متنوعی از امور مالی گرفته تا «پیشبینی تقاضا» (Demand Forecasting) کاربرد دارد. برای آشنایی مقدماتی با مفهوم رگرسیون، میتوانید به فیلم آموزش درس رگرسیون ۱ فرادرس که لینک آن در ادامه آورده شده است مراجعه کنید:
بهمنظور درک بهتر، فرض کنید میخواهیم برای پیشبینی قیمت خانه بر اساس مساحت، یک مدل رگرسیون خطی طراحی کنیم. در نمودار این مسئله، محور افقی () بیانگر مساحت و محور عمودی () همان قیمت خانه است.

سپس خطی را بر نمونه دادهها برازش میکنیم که قادر به کشف رابطه خطی میان مساحت و قیمت خانه باشد. حالا میتوانیم هر خانهای که مساحت آن مشخص بوده را قیمتگذاری کنیم یا به بیان دیگر برای هر ، مقدار متناظری در محور پیشبینی شده است.

دقت داشته باشید که رابطه خطی بهدست آمده تنها یک تخمین است و برخی از نقاط داده با خط برازش شده فاصله دارند. یکی از دلایل استفاده پژوهشگران از MAE، مقاومت آن نسبت به نمونههای پرت یا Outliers است. با این حال این معیار نیز خالی از مشکل نبوده و پیدا کردن خطی با کمترین فاصله نسبت به مقادیر حقیقی چالشانگیز است. برای محاسبه میانگین خطای مطلق، باید هر کدام از مقادیر حقیقی را از مقدار پیشبینی شده متناظر کم کنیم. نتیجه یا همان «مقدار باقیمانده» (Residual)، نشاندهنده خطای مدل بهازای هر داده است.

اغلب معیارهای رگرسیونی بر اساس همین مقادیر باقیمانده از یکدیگر متمایز میشوند.
تعریف میانگین خطای مطلق چیست؟
پس از آشنایی با نحوه کارکرد مدلهای رگرسیونی، در این بخش یاد میگیریم میانگین خطای مطلق چیست و چگونه محاسبه میشود. همانطور که از نام آن نیز مشخص است، در میانگین خطای مطلق یا MAE از قدر مطلق خطاهای مدل میانگین گرفته میشود. فرمول محاسبه MAE به شرح زیر است:
هر یک از نمادهای استفاده شده در عبارت فوق را میتوان مانند زیر تعریف کرد:
- : تعداد کل نمونهها.
- : مقادیر پیشبینی شده.
- : مقادیر حقیقی.
برای محاسبه MAE، ابتدا باید قدر مطلق مقادیر باقیمانده را بهدست آوریم. از خطاها قدر مطلق میگیریم، چرا که نمیخواهیم مقادیر مثبت و منفی باعث خنثی شدن یکدیگر شوند. به عنوان مثال اگر دادهای با ۱۰+ و دیگری با ۱۰- واحد اختلاف از مقدار حقیقی پیشبینی شود، این خطاها طبق محاسبه: ، اثر یکدیگر را از بین میبرند. اما با قدر مطلق گرفتن از خطاها، دیگر چنین مشکلی وجود نخواهد داشت و نتیجه زیر حاصل میشود:

پس از محاسبه قدر مطلق مقادیر باقیمانده، آنها را با هم جمع و نتیجه را بر تعداد کل نمونهها تقسیم میکنیم. به این صورت، میانگین خطای مطلق برای مدل رگرسیونی بهدست میآید.
آموزش کاربردی رگرسیون خطی با فرادرس

رگرسیون خطی و شبکه عصبی MLP یا پرسپترون چندلایه دو رویکرد مهم در یادگیری ماشین هستند. رگرسیون خطی، نوعی روش اولیه و پایه برای مدلسازی رابطه میان متغیرها محسوب میشود. در حالی که شبکه عصبی MLP قادر به کشف الگوهای پیچیدهتر در دادهها است. تا اینجا میدانیم که میانگین خطای مطلق یا MAE یکی از معیارهای کلیدی در ارزیابی عملکرد مدلهای رگرسیونی است. این معیار، از قدر مطلقِ تفاضل بین مقادیر پیشبینی شده و حقیقی میانگین گرفته و نقش مهمی در تعیین دقت مدلها دارد.
امروزه یادگیری عملی این مفاهیم با استفاده از زبان برنامهنویسی پایتون، بسیار حائز اهمیت است. پایتون با کتابخانههایی چون Pandas، NumPy و Scikit-learn امکان پیادهسازی و ارزیابی مدلهای رگرسیونی را به شکلی کارآمد فراهم میکند. برای کسب مهارت در این زمینه، پلتفرم فرادرس دوره جامعی در قالب فیلمهای آموزشی تهیه و تولید کرده است که با مشاهده آن، نحوه استفاده از رگرسیون خطی و شبکه عصبی MLP را در یک مسئله کاربردی و با کمک زبان برنامهنویسی پایتون یاد میگیرید. برای انتقال به صفحه این آموزش بر روی لینک زیر کلیک کنید:
محاسبه میانگین خطای مطلق با پایتون
حالا که میدانیم میانگین خطای مطلق چیست و چگونه محاسبه میشود، در این بخش دو روش رایج را برای محاسبه MSE در مدلهای یادگیری ماشین و با بهرهگیری از زبان پایتون شرح میدهیم.

روش ۱: Scikit Learn
یکی از محبوبترین و همچنین کاربردیترین کتابخانهها در یادگیری ماشین، کتابخانه Scikit-learn نام دارد. در این کتابخانه تابع آمادهای برای محاسبه MAE تعریف شده است که در قطعه کد زیر نحوه استفاده از آن را برای مجموعه مقادیر حقیقی و پیشبینی شدهای که به ترتیب در متغیرهای actualو predictedذخیره شدهاند ملاحظه میکنید:
خروجی مانند زیر است:
1.8روش ۲: TensorFlow
هنگام کار کردن با مدلهای یادگیری عمیق از TensorFlow و کتابخانه سطح بالا آن یعنی Keras استفاده میشود. این کتابخانه نیز تابعی را برای محاسبه MAE در اختیار ما قرار میدهد که در ادامه بر روی مقادیر حقیقی و پیشبینی شدهای مشابه با روش قبل اعمال شده است:
خروجی به شرح زیر است:
1.8در مطلب زیر از مجله فرادرس بهطور کامل درباره کتابخانه TensorFlow و چگونگی نصب و اجرای آن توضیح دادهایم:
کاربرد میانگین خطای مطلق چیست؟
تا اینجا بهخوبی میدانیم میانگین خطای مطلق چیست و به چه شکل پیادهسازی میشود. معیاری که از تفاضل مطلقِ میان نمونههای حقیقی و پیشبینی شده میانگین میگیرد. هنگام محاسبه MAE برخلاف خطای میانگین مربعات یا MSE، همه دادهها وزن و اهمیت یکسانی داشته و توجه زیادی به نمونههای پرت نمیشود. در نتیجه معیار اندازهگیری متوازن است اما، دیگر تفاوتی میان خطاهای بزرگ و کوچک وجود ندارد. نکات مثبت و منفی که بسته به نوع مسئله خود باید در نظر داشته باشید.


«میانگین درصد خطای مطلق» (Mean Absolute Percentage Error | MAPE) از جمله دیگر میعارهای رایج برای سنجش دقت مدل است که معادل درصدی MAE بهحساب میآید. در واقع، MAPE و MAE به ترتیب معیارهایی نسبی و خطی برای اندازهگیری خطا هستند.
مقایسه میانگین خطای مطلق با سایر معیار های ارزیابی
هنگام استفاده از معیارهای ارزیابی، تنها اینکه بدانیم میانگین خطای مطلق چیست، کافی نبوده و باید دید کاملی از سایر معیارها و تفاوتهایشان با یکدیگر داشته باشیم. به همین خاطر سعی کردهایم تا در جدول زیر به مقایسه پنج مورد از متداولترین معیارهای ارزیابی بپردازیم:
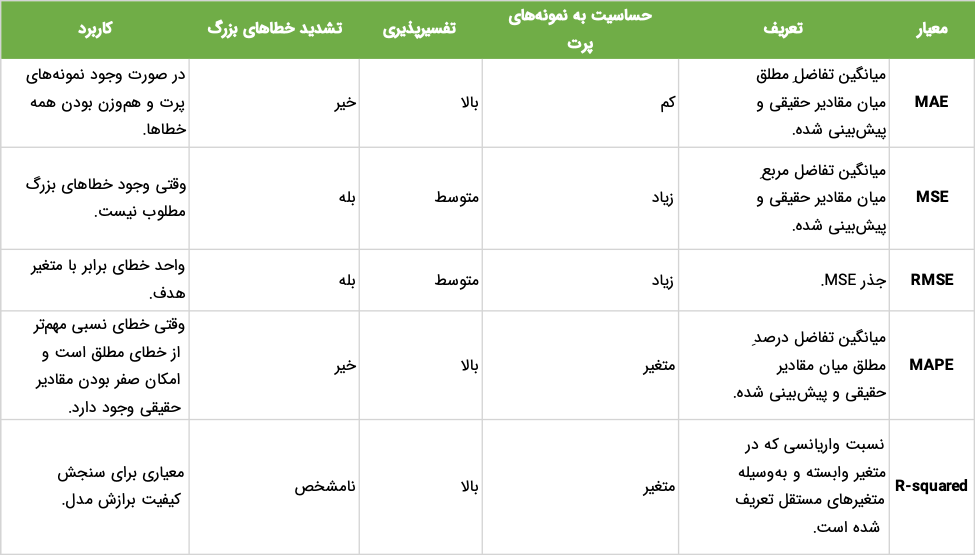
مفاهیم آماری مانند میانگین خطای مطلق، نه تنها برای ارزیابی عملکرد مدلها ضروری هستند، بلکه به ما کمک میکنند تا بینش عمیقتری نسبت به دادهها و الگوهای موجود در آنها بهدست آوریم. در داده کاوی، مفاهیم آماری به ما امکان میدهند تا روابط و الگوهای پنهان را در حجم عظیمی از دادهها کشف کنیم. از طرف دیگر، در یادگیری ماشین از این مفاهیم برای تنظیم و بهبود مدلها، مقایسه عملکرد الگوریتمهای مختلف و تصمیمگیری درباره بهترین رویکرد برای حل یک مسئله خاص استفاده میشود.
پیادهسازی این مفاهیم آماری با بهرهگیری از ابزاری مانند زبان برنامهنویسی پایتون، مهارتی ارزشمند برای هر متخصص داده است. اگر قصد دارید تا به شیوهای کاربردی بر مفاهیم آماری همچون MAE مسلط شوید، مشاهده فیلم آموزشی زیر را از وبسایت فرادرس به شما پیشنهاد میکنیم:
جمعبندی
با توجه به اهمیت مدلهای رگرسیونی در یادگیری ماشین، باید نه تنها از تفاوتهای عمده معیارهای ارزیابی مطلع باشید بلکه بدانید چگونه در مسائل و کاربردهای روزمره بهکار میروند. در این مطلب از مجله فرادرس به پرسش میانگین خطای مطلق چیست پاسخ دادیم و علاوهبر یادگیری نحوه محاسبه و پیادهسازی در زبان پایتون، با کاربرد و تفاوتهای آن نسبت به سایر معیارهای ارزیابی آشنا شدیم.







