


وب اسکرپینگ (Web Scraping) چیست؟ – به زبان ساده


نرمافزارهای «وب اسکرپینگ» (Web Scraping) به طور خودکار اطلاعات و دادههایی را که معمولاً از طریق بازدید از یک وبسایت در مرورگر قابل دسترسی باشد، گردآوری میکنند. بدین ترتیب این نرمافزارها با اجرای ناشناس این کار میتوانند قابلیتهایی برای دادهکاوی، تحلیل داده، تحلیل آماری و موارد دیگر ایجاد کنند.


چرا وب اسکرپینگ مفید است؟
ما در روزگاری زندگی میکنیم که دسترسی به اطلاعات از هر زمان دیگری آسانتر شده است. زیرساختی که موجب شده شما بتوانید این مقاله را بخوانید باعث شده که افراد از هر زمان دیگری در طول تاریخ بشریت امکان بیشتری برای کسب دانش، ارائه نظر و دسترسی به اخبار داشته باشند.
در واقع مغز یک انسان اگر حتی با 100% ظرفیت خود کار کند، همچنان نمیتواند حتی یکهزارم دادههایی که روی اینترنت، صرفاً در ایالات متحده وجود دارد در خود جای دهد.
سیسکو (Cisco) در سال 2016 تخمین زده است که ترافیک روی اینترنت از یک زتابایت عبور کرده است. یک زتابایت برابر با 1،000،000،000،000،000،000،000 بایت است. یک زتابایت داده معادل این است که شرکت ارائه دهنده خدمات رسانهای «نتفلیکس» (Netflix) به مدت چهار هزار سال به پخش فیلم و سریال بپردازد. این وضعیت معادل آن است که مجموعه سریال «The Office» از ابتدا تا انتها بدون توقف 500 هزار بار پخش شود.
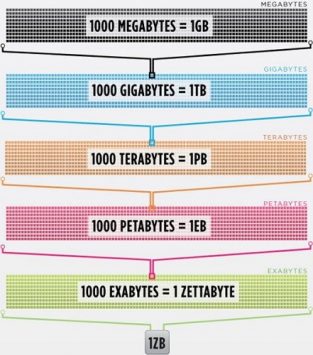

همه این دادهها و اطلاعات، حجم وحشتناکی را تشکیل میدهند. البته دقت کنید که ما در زندگی روزمره به همه این دادهها نیاز نداریم، اما رفته رفته دستگاههای بیشتری این اطلاعات را از سرورهایی در سراسر دنیا به سمت چشم و مغز ما گسیل میکنند.
از آنجا که ذهن و چشم ما عملاً نمیتوانند این همه اطلاعات را مدیریت کنند، وب اسکرپینگ به عنوان یک روش مفید برای گردآوری برنامهنویسی شده دادهها از اینترنت مطرح شده است. وب اسکرپینگ یک اصطلاح انتزاعی برای تعریف عمل استخراج دادهها از وبسایتها جهت ذخیرهسازی محلی آنها است.
هر نوع دادهای که در نظر داشته باشید، میتوان از طریق وب اسکرپینگ آن را جمعآوری کرد. فهرست فایلهای بنگاههای معاملات املاک، دادههای ورزشی، آدرسهای ایمیل کسب و کارها در منطقه مشخص، و حتی ترانههای یک هنرمند محبوب، امکان ذخیرهسازی همه این موارد با نوشتن یک اسکریپت کوچک وجود دارد.
مرورگر، چگونه دادهها را دریافت میکند؟
برای این که با طرز کار نرمافزارهای وب اسکرپینگ آشنا شویم، باید نخست طرز کار وب را بشناسیم. شما برای این که به وبسایت حاضر، آمده باشید یا باید آدرس https://www.blog.faradars.org را در مرورگر خود وارد کنید و یا این که روی یک لینک به این صفحه در هر کجای اینترنت کلیک کرده باشید. در هر حالت، مراحلی که در ادامه معرفی میشوند در مورد هر دو گزینه فوق صدق میکنند.
ابتدا مرورگر شما URL-ی که وارد کرده یا کلیک کردهاید را دریافت میکند و یک درخواست به سرور مربوطه ارسال میکند. سرور درخواست را پردازش کرده و یک پاسخ بازگشت میدهد.
پاسخ سرور شامل کد HTML، جاوا اسکریپت، CSS ،JSON و دادههای دیگر مورد نیاز است که به مرورگر امکان میدهد تا یک صفحه وب را برای بازدید شما ایجاد کند.
بازرسی عناصر وب
مرورگرهای مدرن در مورد فرایندی که در بخش فوق اشاره کردیم، برخی جزییات را در اختیار ما قرار میدهند. در مرورگر گوگل کروم روی ویندوز با زدن دکمههای Ctrl + Shift + I و یا راست کلیک و انتخاب گزینه Inspect، پنجرهای باز میشود که شبیه به تصویر زیر است:

یک فهرست برگهای از گزینهها در نوار فوقانی پنجره مشاهده میشود. برگهای که مورد علاقه ما است Network نام دارد. این برگه اطلاعاتی در مورد ترافیک HTTP به صورت زیر نمایش میدهد:

در بخش راست-پایین این برگه، اطلاعاتی در مورد درخواست HTTP مشاهده میشود. URL آن چیزی است که به دنبالش هستیم و method یک درخواست GET در HTTP است. «کد وضعیت» (Status Code) پاسخ بازگشتی برابر با 200 است که به این معنی است سرور درخواست را معتبر شمرده است. زیر کد وضعیت، آدرس ریموت را ملاحظه میکنید که آدرس IP عمومی سرور بلاگ فرادرس است.
در بخش بعدی جزییاتی در مورد پاسخها، فهرستبندی شده است. «هدر» (Header) پاسخ نه تنها شامل کد وضعیت؛ بلکه شامل نوع داده یا محتوایی است که پاسخ را تشکیل میدهد. در این حالت، ما شاهد «text/html» هستیم که دارای یک انکودینگ استاندارد است. بدین ترتیب مشخص میشود که پاسخ در واقع کد HTML است که برای رندر وبسایت استفاده میشود.

انواع دیگر پاسخها
علاوه بر HTML برای رندر صفحه وب، سرورها میتوانند اشیای دادهای را به عنوان پاسخ برای درخواست GET بازگشت دهند. یک API وبسایت معمولاً از این نوع مبادلهها استفاده میکند.
شما با بررسی برگه Network به روشی که توضیح دادیم، میتوانید ببینید که آیا این نوع مبادله صورت گرفته است یا نه. برای مثال زمانی که از وبسایت CrossFit Open Leaderboard (+) بازدید میکنیم، دادههای مورد نیاز برای پر کرد جدول امتیازات بارگذاری میشوند:

با کلیک کردن روی پاسخ، دادههای JSOM به جای کد HTML برای رندرینگ صفحه نمایش مییابد. دادهها در قالب JSON و به صورت یک سری از برچسبها و مقادیر هستند که به صورت لیست لایهبندی شدهای نمایش مییابند.

تجزیه دستی کد HTML یا بررسی هزاران جفت کلید/مقدار JSON تا حدودی کار دشواری است و در نگاه نخست ممکن است پیچیده به نظر بیاید، چون حجم اطلاعاتی که باید به صورت دستی کدگشایی شود بسیار زیاد است.
نرمافزارهای Web Scraping به کمک میآیند
اینک پیش از هر کاری باید بدانید که لازم نیست ما به صورت دستی کد HTML را کدگشایی کنیم. یک نرمافزار وب اسکرپینگ این وظایف دشوار را به جای شما انجام میدهد. فریمورکهای اسکرپینگ در زبانهای برنامهنویسی پایتون، جاوا اسکریپت، Node و دیگر زبانهای برنامهنویسی موجود هستند. یکی از سادهترین روشها برای شروع به اسکرپینگ استفاده از پایتون و Beautiful Soup است.
اسکرپینگ یک وبسایت با استفاده از پایتون
برای آغاز به کار اسکرپینگ با پایتون و BeautifulSoup تنها به چند خط کد نیاز داریم. در ادامه یک اسکریپت کوچک برای دریافت سورس یک وبسایت و ارزیابی آن از طریق پایتون و BeautifulSoup را مشاهده میکنید.
1from bs4 import BeautifulSoup
2import requests
3
4url = "http://www.athleticvolume.com/programming/"
5
6content = requests.get(url)
7soup = BeautifulSoup(content.text)
8
9print(soup)در کد فوق ما به طرز سادهای یک درخواست GET به یک URL ارسال میکنیم و سپس پاسخ را درون یک شیء قرار میدهیم. نمایش این شیء موجب مشاهده کد سورس HTML برای آن URL میشود. این فرایند شبیه آن است که گویی به صورت دستی به وبسایت مراجعه کرده و روی گزینه View Source کلیک کردهایم.
به طور خاص، این همان وبسایتی است که برنامه تمرینهای ورزشی را به صوت روزانه ارسال میکند؛ اما این کار تنها یک بار در طی روز صورت میگیرد. ما میتوانیم یک نرمافزار اسکرپینگ بسازیم که این تمرینها را هر روز دریافت کند و سپس آنها را به صورت یک فهرست جامع درآورد. برای مثال میتوانیم یک پایگاه داده متنی از تمرینها بسازیم که متعاقباً میتوان روی آن جستجو انجام داد.
معجزه BeaufiulSoup، توانایی آن برای جستجو در میان همه کدهای HTML با استفاده از تابع درونی ()findAll است. در این مورد خاص، وبسایت از تگهای «sqs-block-content» استفاده میکند و از این رو اسکریپت ما باید حلقهای روی همه این تگها اجرا کرده و مواردی که برای ما جالب هستند را بیابد.
به علاوه، چندین تگ <p> نیز در این بخش وجود دارند. اسکریپت میتواند همه متن این تگها را به یک متغیر محلی اضافه کند. بدین منظور باید یک حلقه ساده در اسکریپت تعریف کنیم:
1for div_class in soup.findAll('div', {'class': 'sqs-block-content'}):
2 recordThis = False
3 for p in div_class.findAll('p'):
4 if 'PROGRAM' in p.text.upper():
5 recordThis = True
6 if recordThis:
7 program += p.text
8 program += '\n'اینک ما یک نرمافزار وب اسکرپینگ داریم.
افزایش مقیاس وب اسکرپینگ
در این مرحله دو مسیر پیش روی شما برای ادامه کار قرار دارد. یک روش این است که به بررسی وب اسکرپینگ به کمک ابزارهای موجود بپردازید. برای نمونه نرمافزار Web Scraper (+) دویست هزار کاربر دارد و استفاده از آن آسان است. ضمناً Parse Hub (+) به کاربران امکان میدهد که دادههای اسکرپ شده را به شیتهای اکسل و گوگل اکسپورت کنند.
به علاوه Web Scraper یک افزونه کروم دارد که به بصریسازی شیوه ساخت یک وبسایت کمک میکند. نرمافزار OctoParse (+) نیز یک ابزار اسکرپینگ قدرتمند با رابط کاربری ساده است. در نهایت باید گفت که اینک شما با مبانی وب اسکرپینگ آشنایی دارد و میتوانید اسکریپت سادهای را که نوشتهاید به ابزاری برای crawl و اجرای موارد خواسته شده روی وبسایتهای مختلف تبدیل کنید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و داده کاوی
- مجموعه آموزشهای پایگاه داده و سیستم های مدیریت اطلاعات
- آموزش کار با پیش پردازش ها در یادگیری ماشین با پایتون (Python)
- آموزش اصول و روش های داده کاوی (Data Mining)
- وب اسکرپینگ (Web Scraping) با استفاده از R — راهنمای کاربردی
- وب اسکرپینگ (Web Scraping) با پایتون و کتابخانه Beautiful Soup — راهنمای جامع
- 1۰ کتابخانه پایتون علم داده — راهنمای کاربردی
==









سلام.خسته نباشید
مطلب web scraping بسیار مفید بود
من واقعا به کمک نویسنده این مطلب آقای میثملطفی نیاز دارم.کار پژوهشی انجام میدم بر اساس فرکانس پوشش خبری و احتیاج به اینطور تکنیکی دارم که به صورت محلی مطالب آرشیو الکترونیکی روزنامه ها و پایگاه های خبری رو از روی وب سایتشون جمع آوری کنه و بعد یه شمارش انجام بده و تحلیل آماری روش انجام بشه تا من به یک شاخص برسم.
لطفا اگر میتونید با من همکاری کنید به من ایمیل بزنید.خیلی به کمکتون احتیاج دارم.
با سلام
من میتونم به شما کمک کنم لطفا در صورت تمایل ایمیل بنده رو از میثم بگیرید تا انشاالله در خدمتتون باشم.
سلام دوست عزیز؛
من در چارچوب مقالات تا حد امکان و دانشم پاسخگوی سوالات شما هستم، اما متاسفانه امکان پذیرش چنین درخواستهایی برایم مقدور نیست. آرزوی موفقیت برای شما دارم.
با تشکر از توجه شما.