


بازیابی خطا در طراحی کامپایلر – راهنمای جامع
در بخشهای قبلی سلسله مطالب طراحی کامپایلر با انواع تجزیهکنندههای واژگانی و نحوی آشنا شدیم. یکی از وظایف تجزیهکننده کشف و گزارش وجود خطا در یک برنامه است. این انتشار از یک تجزیهکننده میرود که در مواردی که با خطایی در برنامه مواجه شد، بتواند آن را مدیریت کرده و به تجزیه ادامه ورودی بپردازد. غالباً انتظار میرود که یک تجزیهکننده خطاها را بررسی کند، اما واقعیت این است که خطاها در مراحل مختلف فرایند کامپایل رخ میدهند. انواع خطاهای مختلفی که در مراحل متفاوت کامپایل یک برنامه میتوانند وجود داشته باشند، به شرح زیر هستند:




- واژهای – نام برخی از شناسهها به صورت نادرستی تایپ شده باشد.
- نحوی – نقطهویرگول فراموش شده باشد یا این که یکی از پرانتزها درج نشده باشند.
- معنایی – انتساب مقدار کامل نشده باشد.
- منطقی – بخشی از کد قابل دسترسی نباشد و یا حلقه بیانتها وجود داشته باشد.
راهبردهای بازیابی خطا
چهار نوع راهبرد بازیابی خطا نیز وجود دارند که میتوان در تجزیهکننده برای مواجهه و رفع خطا پیادهسازی کرد.
حالت Panic
زمانی که تجزیهکننده در هر کجای یک عبارت با خطایی مواجه شود، با پردازش ورودی خطادار تا اولین جداکننده مانند یک نقطهویرگول، بقیه عبارت را نادیده میگیرد. این آسانترین راه بازیابی خطا محسوب میشود و از ورود تجزیهکننده به حلقههای بیانتها نیز جلوگیری میکند.
حالت Statement
زمانی که یک تجزیهکننده با خطایی مواجه میشود از اقدامهای اصلاحی استفاده میکند به طوری که بقیه ورودی عبارت به تجزیه کمک میکند تا به ادامه کار خود بپردازد. برای نمونه درج یک نقطهویرگول فراموش شده یا تعویض کامل با نقطهویرگول و غیره. طراحان تجزیهکننده باید مراقب باشند چون یک اصلاح نادرست میتواند منجر به ورود به یک حلقه بیانتها شود.
روش Error Production
طراحان کامپایلر با برخی خطاهای رایج که ممکن است در کد بروز یابند آشنا هستند. به علاوه طراحان میتوانند گرامر ارتقا یافتهای ایجاد کنند که از این خطاها استفاده میکنند و در صورت مواجهه با خطا، با سازههای خطایی که قبلاً ایجاد شده مقایسه میشوند.
روش Global Correction
در این روش تجزیهکننده برنامه مورد بررسی را به صورت یک کلیت در نظر میگیرد و تلاش میکند تا دریابد برنامه میخواهد چه کار کند و سعی میکند نزدیکترین مورد مطابق با آن را که عاری از خطا است، بیابد. زمانی که یک ورودی (عبارت) با خطا به صورت X وارد تجزیه کنده میشود، یک درخت تجزیه برای نزدیکترین عبارت عاری از خطای Y ایجاد میشود. بدین ترتیب تجزیهکننده تغییراتی جزئی در کد منبع ایجاد میکند؛ اما به دلیل پیچیدگی (زمانی و فضایی) این راهبرد تاکنون در عمل استفاده نشده است.
درختهای نحوی مجرد (AST)
تجزیه بازنماییهای درخت تجزیه از سوی کامپایلر کار آسانی نیست، چون این درختها شامل جزییاتی هستند که در اغلب موارد مورد نیاز نیستند. به عنوان مثال درخت تجزیه را در نظر بگیرید:

اگر به دقت به آن نگاه کنید درمییابید که گرههای برگ، تنها فرزندان گرههای والد خود هستند. این اطلاعات را میتوان پیش از ورود به فاز بعدی حذف کرد. با مخفی کردن اطلاعات اضافی، میتوانیم درختی به صورت زیر داشته باشیم:
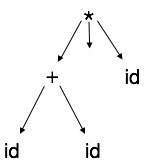
درخت مجرد به صورت زیر نمایش مییابد:
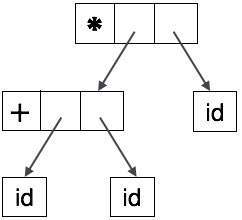
AST-ها ساختمانهای دادهای مهمی در کامپایلر محسوب میشوند که دارای کمترین اطلاعات غیرضروری هستند. AST-ها نسبت به درخت تجزیه بسیار فشردهتر هستند و کامپایلر با سهولت بیشتری آنها را مورد استفاده قرار میدهد.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز بررسی کنید:
- ابزارهای مهندسی کامپیوتر
- کامپایلر، طراحی و معماری آن — به زبان ساده
- آموزش طراحی کامپایلر
- آموزش گرامرها در طراحی کامپایلر
- دروس مهندسی کامپیوتر
- تجزیه پایین به بالا — طراحی کامپایلر
==










