



جدول نماد (Symbol Table) در طراحی کامپایلر – راهنمای جامع
جدول نماد، ساختمان داده مهمی است که به وسیله کامپایلرها برای ذخیرهسازی اطلاعاتی در مورد رخداد گزارههای مختلف مانند نام متغیرها، نام تابعها، اشیا، کلاسها، رابطها و مواردی از این دست استفاده میشود. جدول نماد هم از سوی بخشهای تجزیهای و هم توسط بخشهای ترکیبی کامپایلر مورد استفاده قرار میگیرد.




یک جدول نماد بسته به زبان مورد استفاده برای مقاصد زیر استفاده میشود:
- ذخیرهسازی نامهای همه گزارهها دریک محل، به شکل ساختیافته
- تأیید این که متغیری اعلان شده است یا نه
- پیادهسازی بررسی نوع که تأیید میکند انتساب و عبارتها در کد منبع از نظر معناشناختی صحیح هستند
- تعیین دامنه نام (تحلیل دامنه)
یک جدول نماد به طور ساده جدولی است که میتواند خطی یا جدول هش (hash) باشد. این جدول همه نامها را به شکل زیر ذخیره میکند:
<symbol name, type, attribute>
برای نمونه اگر بخواهیم از یک جدول نماد برای ذخیرهسازی اطلاعاتی در مورد اعلانهای متغیرهای زیر استفاده کنیم:
<symbol name, type, attribute>
در این صورت باید هر مدخل را به صورت زیر ذخیره کنیم:
static int interest;
بند خصوصیت شامل مدخلهایی در ارتباط با نام است
<interest, int, static>
پیادهسازی
اگر یک کامپایلر بخواهد مقدار کمی از دادهها را مدیریت کند، در این صورت جدول نماد میتواند به عنوان یک لیست نامرتب پیادهسازی شود که کدنویسی آن آسان است؛ اما این روش تنها برای جداول کوچک مناسب است. یک جدول نماد را میتوان به یکی از روشهای زیر پیادهسازی کرد:
- لیست خطی (مرتب یا نامرتب)
- درخت جستجوی دودویی
- جدول هَش (جدول هَش)
در میان موارد فوق، جدولهای نماد به طور عمده به صورت جدولهای هش پیادهسازی میشوند که در آن نماد کد منبع خود به عنوان یک کلید برای تابع هش استفاده میشود و در آن منظور از مقدار بازگشتی اطلاعاتی در مورد آن نماد است.
عملیاتها
یک جدول نماد چه خطی و چه هَش باید عملیاتهای زیر را ارائه کرده باشد:
()Insert
این عملیات به طور عمده در فاز تحلیلی مورد استفاده قرار میگیرد، یعنی نیمه نخست فرایند کامپایل که توکنها شناسایی میشوند و نامها در جدول ذخیره میشوند. این عملیات برای افزودن اطلاعات در جدول نماد در مورد نامهای منحصر به فرد که در کد منبع حضور دارند استفاده میشود. قالب یا ساختاری که در آن نامها ذخیره میشوند به نوع کامپایلر بستگی دارد.
یک خصوصیت برای یک نماد در کد منبع معادل اطلاعاتی است که در مورد آن نماد وجود دارد. این اطلاعات شامل مقدار، وضعیت، دامنه و نوع نماد است. تابع ()insert نماد و خصوصیتهای آن را به صورت آرگومانهایی میگیرد و اطلاعات آن را در جدول نماد ذخیره میکند.
مثال
int a;
که از سوی کامپایلر به صورت زیر مورد پردازش قرار میگیرد:
insert(a, int);
()lookup
عملیات ()lookup برای جستجوی یک نام در جدول نماد برای تعیین موارد زیر استفاده میشود:
- آیا نمادی در جدول وجود دارد
- آیا نماد پیش از استفاده اعلان شده است
- آیا نام در دامنه خود استفاده شده است
- آیا نماد، مقداردهی اولیه شده است
- آیا نماد، چندین بار اعلان شده است
قالب تابع ()lookup بر اساس زبان برنامهنویسی متفاوت است. قالب اصلی مانند زیر است:
lookup(symbol)
این متد در صورتی که نماد وجود نداشته باشد، مقدار 0 (صفر) باز میگرداند. اگر نماد در جدول نماد وجود داشته باشد، در این صورت متد فوق خصوصیت ذخیره شده برای آن را باز میگرداند.
مدیریت دامنه (Scope)
یک کامپایلر دو نوع جدول نماد دارد: یک جدول نماد سراسری که میتواند از سوی همه روالها استفاده شود و یک جدول نماد دامنه که برای هر دامنه داخل برنامه ایجاد میشود.

برای تعیین دامنه یک نام، جدول نمادها به صورت ساختار سلسله مراتبی چیدمان یافته است که در مثال زیر بهتر مشخص شده است:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .
برنامه فوق را میتوان به روش ساختار سلسله مراتبی در جدول نماد زیر نمایش داد:
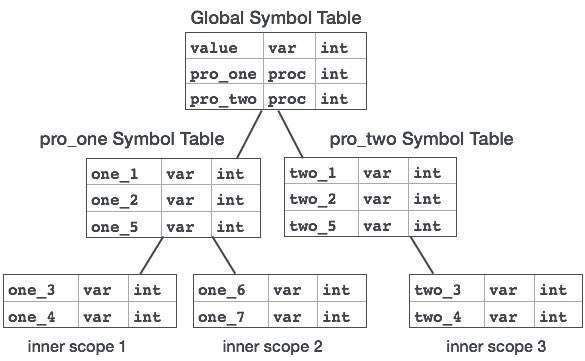
جدول نماد سراسری شامل نامهایی برای متغیرهای سراسری (مقدار int) و دو نام روال است که باید برای همه گرههای فرزند در تصویر فوق در دسترس باشند. نامهای ذکر شده در جدول pro-one (و همه جدولهای فرزندش) برای نمادهای pro-two و جدولهای فرزندشان در دسترس نیستند.
این ساختار سلسله مراتبی داده برای جدول نماد در تحلیلگر معنایی ذخیره میشود و هر زمان که لازم باشد موردی در جدول نماد جستجو شود، با استفاده از الگوریتم زیر این کار صورت میگیرد:
- ابتدا یک نماد در دامنه کنونی جستجو میشود یعنی جدول نماد کنونی؛
- اگر نامی یافت شد در این صورت جستجو پایان یافته است؛ اما در غیر این صورت جستجو در جدول نماد والدِ آن صورت میگیرد تا زمانی که ...
- یا نام پیدا شود و یا جدول نماد سراسری برای نام جستجو شود.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز ملاحظه کنید:
- مجموعه آموزشهای برنامهنویسی
- مجموعه آموزشهای دروس مهندسی کامپیوتر
- آموزش طراحی کامپایلر
- آموزش تجزیه انتقال (کاهش) در طراحی کامپایلر
- آموزش طراحی کامپایلر (مرور و حل تست های کنکور کارشناسی ارشد)
==










