



تحلیل واژهای (Lexical Analysis) در طراحی کامپایلر – راهنمای جامع
تحلیل واژهای نخستین فاز یک کامپایلر است. این فاز نسخه اصلاحشدهای از کد منبع را از پیش پردازندههای زبان برنامهنویسی میگیرد که به شکل جملاتی نوشته شدهاند. تحلیلگر واژهای، این ساختارها را با حذف کاراکترهای فاصله یا توضیحات در کد منبع تجزیه میکند.




اگر تحلیلگر واژهای دریابد که یک توکن نامعتبر است، یک خطا تولید میکند: تحلیلگر واژهای ارتباط نزدیکی با تحلیلگر نحوی دارد. این تحلیلگر کاراکترها را از کد منبع دریافت میکند، توکنهای معتبر را بررسی کرده و دادهها را در صورت تقاضا به تحلیلگر ساختاری میفرستد.
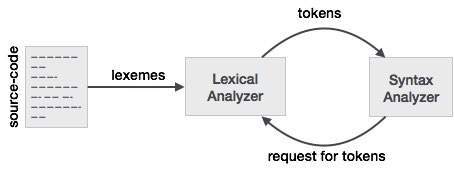
توکنها
تکواژهها یک توالی از کاراکترها (الفبایی-عددی) در یک توکن هستند. برخی قواعد از پیش تعریف شده برای هر تکواژه هستند که باید از یک توکن معتبر شناسایی شوند. این قواعد همانند قواعد گرامری بر اساس یک الگو تعریف میشوند. یک الگو توضیح میدهد که یک توکن چه چیزی میتواند باشد و این الگوها به وسیله عبارتهای منظم تعریف میشوند.
در زبان برنامهنویسی، کلیدواژهها، ثابتها، شناسهها، رشتهها، اعداد، عملگرها و نمادهای سجاوندی را میتوان به صورت توکن در نظر گرفت. برای نمونه در زبان C خط اعلان متغیر به صورت زیر است:
int value = 100;
که شامل توکنهای زیر است:
int (keyword), value (identifier), = (operator), 100 (constant) and; (symbol).
مشخصات توکنها
در ادامه به بررسی کاربرد نظریه زبان در این زمینه میپردازیم:
الفبا
به هر مجموعه متناهی از نمادها الفبا گفته میشود، برای نمونه {0 و 1} یک مجموعه از الفبای باینری است، {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} مجموعهای از الفبای هگزادسیمال و {a-z, A-Z} مجموعهی از الفبای زبان انگلیسی است.
رشتهها
هر توالی متناهی از الفباها به نام رشته خوانده میشود. طول رشته تعداد کل رخدادهای الفباها است، برای مثال، طول رشته faradars برابر با 8 و به صورت faradars| = 8| نمایش مییابد. رشتهای که هیچ الفبایی نداشته باشد، یعنی طول رشته صفر باشد، به نام رشته خالی نامیده میشود و با ε (اپسیلون) نمایش مییابد.
نمادهای خاص
یک زبان معمولی سطح بالا شامل نمادهای زیر است:
| نماد حسابی | جمع(+), تفریق(-), همنهشتی(%),ضرب(*), تقسیم(/) |
| سجاوندی | Comma(,), Semicolon(;), Dot(.), Arrow(->) |
| انتساب | = |
| انتساب خاص | +=, /=, *=, -= |
| مقایسه | ==, !=, <, <=, >, >= |
| پیش پردازنده | # |
| تعیین کننده مکان | & |
| منطقی | &, &&, |, ||, ! |
| عمگلر شیفت | >>, >>>, <<, <<< |
زبان
زبان به صورت مجموعهای متناهی از رشتهها بر روی مجموعهای متناهی از الفبا در نظر گرفته میشود. زبان رایانهای به صورت مجموعهای متناهی تصور میشود و از لحاظ ریاضی عملیاتهای مجموعه میتوانند بر روی آنها اجرا شوند. زبانهای متناهی را میتوان به عنوان ابزاری برای عبارتهای منظم توصیف کرد.
قاعده تطبیق بلندترین
هنگامی که تحلیلگر واژهای، کد منبع را میخواند، کد را حرف به حرف اسکن میکند و هنگامی که با یک کاراکتر فاصله، یا نماد عملگر مواجه میشود، تصمیم میگیرد که یک کلمه کامل شده است یا نه.
مثال
int intvalue;
هنگامی که دو تکواژه اسکن میشوند تا وقتی int تمام نشده است، اسکنر نمیتواند تعیین کند که آیا این کلیدواژه int است یا حروف اولیه شناسه مقدار int است.
قاعده تطبیق بلندترین، تعیین میکند که تکواژه اسکن شده باید بر اساس بلندترین مورد مطابقت، در میان همه توکنهای موجود تعیین شود.
تحلیلگر واژهای همچنین از «اولویت قاعده» پیروی میکند. بر این مبنا مشخص میشود که یک واژه رزرو شده مانند کلیدواژه در یک زبان نسبت به ورودی کاربر اولویت دارد. یعنی اگر تحلیلگر واژهای یک تکواژه بیاید که با یک واژه رزرو شده تطبیق داشته باشد باید یک خطا تولید کند یا نه.
عبارتهای منظم
تحلیلگر واژهای باید تنها یک مجموعه متناهی از رشته/توکن/تکواژههای معتبر را اسکن و شناسایی بکند که به زبان مورد بررسی تعلق دارند. این تحلیلگر به دنبال الگوهایی میگردد که توسط قواعد زبان تعریف میشوند.
عبارتهای منظم از طریق تعریف کردن یک الگو برای رشتههای متناهی از نمادها، توانایی بیان زبانهای متناهی را دارند. گرامر که از طریق عبارتهای منظم تعریف میشود به نام گرامر منظم تعریف میشود. زبانی که از طریق گرامر منظم تعریف میشود نیز به نام زبان منظم نامیده میشود.
عبارتهای منظم نمادگذاری مهمی برای تبیین الگوها هستند. هر الگو با یک مجموعه از رشتهها مطابقت دارد و از این رو عبارتهای منظم به صورت نامهایی برای یک مجموعه از رشتهها استفاده میشوند. توکنهای زبان برنامهنویسی را میتوان به صورت زبانهای منظم توصیف کرد. خصوصیات عبارتهای منظم نمونه از تعریف بازگشتی است. زبانهای منظم درک آسانی دارند و پیادهسازی آنها کارآمد است.
چند قاعده جبری وجود دارند که عبارتهای منظم از آنها تبعیت میکنند و از آنها میتوان برای تبدیل عبارتهای منظم به شکلهای معادل استفاده کرد.
عملیاتها
عملیاتهای مختلفی روی یک زبان صورت میگیرد:
- اتحاد دو زبان L و M به صورت زیر نوشته میشود:
L U M = {s | s is in L or s is in M}
- الحاق دو زبان L و M به صورت زیر نوشته میشوند:
LM = {st | s is in L and t is in M}
- بستار کلین (Kleene Closure) برای یک زبان L به صورت زیر نوشته میشود:
L* = L صفر یا تعدادی از رخدادهای زبان
نمادگذاری
اگر r و s عبارتهای منظمی باشند که زبانهای (L(r و (L(s را نشان میدهند در این صورت:
- اتحاد: (r)|(s) یک عبارت منظم است که (L(r) U L(s را نشان میدهد.
- الحاق: (r)(s) عبارت منظمی است که (L(r)L(s را نشان میدهد.
- بستار کلین: *(r) یک عبارت منظم است که *((L(r) را نشان میدهد.
- (r) یک عبارت منظم است که (L(r را نشان میدهد.
تقدم و شرکتپذیری
- *، الحاق (.) و | (خط عمودی) از سمت چپ شرکتپذیر هستند.
- * بالاترین تقدم را دارد
- الحاق (.) دومین درجه از تقدم را دارد.
- | (خط عمودی) پایینترین تقدم را در میان همه نمادها دارد.
نمایش توکنهای معتبر یک زبان در عبارت منظم
اگر x یک عبارت منظم باشد، در این صورت:
- *X به معنی رخداد صفر یا تعداد بیشتری از x است.
- یعنی میتواند این عبارت را تولید کند: { e, x, xx, xxx, xxxx, … }
- +X به معنی یک یا چند مورد رخداد x است:
- یعنی میتواند { x, xx, xxx, xxxx … } یا *x.x را تولید کند.
- ?X به معنی حداکثر رخداد یک مورد x است.
- یعنی میتواند {x} یا {e} را تولید کند.
- [a-z] حروف الفبای کوچک در زبان انگلیسی هستند
- [A-Z] حروف الفبای بزرگ در زبان انگلیسی هستند.
- [0-9] همه ارقام طبیعی مورد استفاده در ریاضی هستند.
نمایش رخداد نمادها با استفاده از عبارتهای منظم
- حرف = [a – z] یا [A – Z]
- رقم = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 یا [0-9]
- علامت = [+ | -]
نمایش توکنهای زبان با استفاده از عبارتهای منظم
- دهدهی :
(sign)?(digit)+
- شناسه
(letter)(letter | digit)*
تنها مسئلهای که در مورد تحلیلگر واژهای باقی مانده است، شیوه تأیید اعتبارسنجی عبارتهای منظم مورد استفاده برای تعیین الگوهای کلیدواژههای یک زبان است. یک راهحل کاملاً پذیرفتهشده در این مورد استفاده از اتوماتا برای اعتبارسنجی است.
اتوماتای متناهی
اتوماتای متناهی یک ماشین حالت است که رشتهای از نمادها را به عنوان ورودی میگیرد و حالت خود را بر همین مبنا تغییر میدهد. اتوماتای متناهی یک شناسه برای عبارتهای منظم محسوب میشود. زمانی که رشته یک عبارت منظم وارد اتوماتای متناهی میشود، این ماشین حالت خود را برای هر کلمه تغییر میدهد. اگر رشته ورودی با موفقیت پردازش شود و اتوماتا به وضعیت نهایی برسد، پذیرفته میشود، یعنی گفته میشود که رشته ورودی توکن معتبری از زبان مورد بررسی است.
مدل ریاضیاتی اتوماتای متناهی شامل موارد زیر است:
- مجموعهای متناهی از حالتها (Q)
- مجموعهای متناهی از نمادهای ورودی (Σ)
- یک حالت آغازین (q0)
- مجموعهای از حالتهای نهایی (qf)
- تابع انتقال (δ)
تابع انتقال (δ)، مجموعه متناهی از حالتها (Q) را به مجموعه متناهی از نمادهای ورودی (Σ) نگاشت میکند، یعنی: Q × Σ ➔ Q
ساخت اتوماتای متناهی
فرض کنید (L(r یک زبان منظم باشد که برحسب برخی اتوماتاهای متناهی (FA) شناسایی میشود.
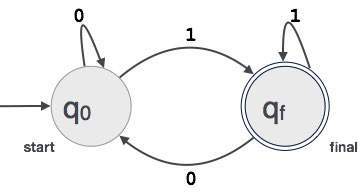
حالتها: حالتهای FA به وسیله دایرههایی نمایش مییابند. نام حالتها درون دایرهها نوشته میشوند.
- حالت آغازین: حالتی است که اتوماتا کار خود را از آنجا شروع میکند و به نام حالت اولیه نیز نامیده میشود. حالت آغازین فلشی دارد که به سمت داخل آن اشاره میکند.
- حالتهای میانی: همه حالتهای میانی دستکم دو فلش دارند که یکی به سمت داخل و دیگری به سمت خارج آن اشاره میکند.
- حالت نهایی: اگر رشته ورودی با موفقیت تجزیه شود، انتظار میرود که اتوماتا به این وضعیت برسد. حالت نهایی با دو دایره نشان داده میشود. به طور معمول تعداد فردی از فلشها به سمت داخل این حالت و تعداد زوجی از فلشها به سمت بیرون آن اشاره میکنند. تعداد فلشهای فرد یک عدد از فلشهای زوج بیشتر است یعنی فلشهای فرد = فلشهای زوج + 1
- انتقال: انتقال از یک حالت به حالت دیگر زمانی رخ میدهد که یک نماد مطلوب در ورودی پیدا شود. در زمان انتقال، اتوماتا میتواند به حالت بعدی برود یا در همان حالت بماند. حرکت از یک حالت به حالت دیگر به صورت فلش جهتدار نمایش مییابد که فلشها به حالت مقصد اشاره میکنند. اگر اتوماتا در همان حالت بماند یک فلش ترسیم میشود که از حالت خارج شده و به خود آن اشاره میکند.
مثال: فرض کنید FA هر مقدار باینری سه رقمی که به رقم 1 منتهی میشود را بپذیرید.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز ملاحظه کنید:
- آموزش طراحی کامپایلر
- بررسی مهمترین پروتکلهای زبان برنامهنویسی کلوژر (Clojure)
- ابزارهای مهندسی کامپیوتر
- ساختار داده و الگوریتم ها — راهنمای مقدماتی
- مجموعه آموزشهای علوم کامپیوتر
- آموزش گرامرها در طراحی کامپایلر
==











درسته. اما خب اصول کامپایلر که در کتاب کامپایلر خونده بودم، این بود که هر مرحله خطای خودشو داره. لکسر، پارسر و معنایی. و اصولا و منطقا هم همینه که وقتی کار لکسر شناسایی توکن معنی داره پس اگر توکنی مجاز و معنی دار نباشه پس خطا بده و برنامه متوقف بشه. و این قضیه در مورد زبان های به اصطلاح کامپایلری صدق میکنه. اما زبانی مثل پایتون که مفسری هست اما ابتدا کامپایل میشه و بعد بایت کدی که تولید میشه توسط ماشین مجازی یا مفسر خط به خط ترجمه و اجرا میشه خب بعضی چیز ها فرق داره. مثلا تو زبان های کامپایلری مثل سی شارپ یه تحلیلگر معنایی قبل کامپایل داریم که خطاهایی مثل متتغیر تعریف نشده رو میگیره و درکل خطاهای زیادی در زمان کامپایل گرفته میشه. اما در پایتون ما اگر کد مشکل سینتکس نداشته باشه کامپایل میشه و اکثر خطاها زمان اجرا گرفته میشه مثل خطای متغیر تعریف نشده که تو پایتون ران تایمه. پس یا اینکه تحلیلگر معنایی اینجا وجود نداره یا اینکه وظایف دیگه ای مربوط به سینتکس انجام میده یا در زمان اجرا وجود داره و.. ولی به هر حال متفاوته. به خاطر همین میگم این قضیه هم ممکنه فرق داشته باشه. الن این موضوع تحقیق ما هست ولی متاسفانه من ب هنتیجه ای نرسیدم که آیا تو بسته مفسری پایتون در مرحله لکسینگ ما خطای توکن غلط خواهیم داشت و برنامه متوقف خواهد شد یا خیر؟
سلام و وقت بخیر آقای نوروزی؛
در پاسخ به سوال شما باید اشاره کنم که بیشک وظیفه لکسر چه در زبانهای کامپایلی و چه تفسیری، شناسایی توکنهای غیر مجاز است. با این توضیح پاسخ سوال شما در آخر توضیحتان مثبت است. در نهایت پیشنهاد میکنم به عنوان بهترین مرجع برای بررسی لکسر پایتون، از داکیومنت اصلی این زبان بهره بگیرید.
از توجه شما متشکرم.
سلام استاد.
اگر توکن غیر مجاز در کد وجود داشته باشه در کدام مرحله خطای سینتکس مربوط به توکن شناسایی ایجاد میشه؟ lexing یا
parsing
بعضی جاها نوشته چون کار لکسر جدا کردن توکن های معنی دار و مجاز زبان هست، تو این مرحله خطا میده
بعضی جاها زدن توکن بی معنی به عنوان ناشناخته در نظر گرفته میشه و به مرحله بعد پارسینگ منتقل میشه و اونجا خطا گرفته میشه
سلام و وقت بخیر آقای نوروزی عزیز؛
در خصوص این سوال باید گفت که وقتی در مورد تقسیم وظایف بین لکسر و پارسر صحبت میکنیم، تقریبا همه چیز به جزئیات پیادهسازی وابسته است. به طور کلی وظیفه لکسر تجزیه توکنهای معنیدار و وظیفه پارسر ترکیب کردن آنها است. به این ترتیب توکنهای بیمعنی یا غیر معتبر هر چه در مراحل ابتدایی این زنجیره شناسایی شوند، بهینهتر است، اما در برخی سناریوها ممکن است تقویت بیش از حد لکسر موجب شود که تا حدودی وظایف پارسر را قبول کند و در واقع ماهیت وجودی پارسر زیر سوال برود. به طور کلی بسته به جزئیات پیادهسازی ممکن است ما برخی موارد غیر معتبر را در فاز لکسینگ و برخی را در فاز پارسینگ رد کنیم، اما در نهایت لکسر به تنهایی امکان رد کردن همه توکنهای غیر مجاز را نخواهد داشت.
از توجه شما سپاسگزاریم.