دیتاست چیست؟ – آنچه باید درباره مجموعه داده ها بدانید

پیادهسازی و اجرای پروژههای مختلف «یادگیری ماشین» (Machine Learning)، از جمله بهترین تمرینها برای ارتقاء مهارتهای خود در زمینه علم داده است. شروع فعالیت در حوزه علم داده نیازمند آشنایی با داده یا همان Data میباشد. اجزای سازندهای که در موجودیت بزرگتری با عنوان دیتاست یا «مجموعهداده» (Dataset) ذخیره شده و بهرهبرداری از دادهها را برای ما ممکن میسازد. در واقع، دیتاست پایه و اساس هر نوع فرایند، تکنیک و مدلهایی است که توسعهدهندگان برای تفسیر کار خود از آن استفاده میکنند. بهطور معمول، دیتاست شامل تعداد زیادی نقاط داده است که در قالب یک جدول گروهبندی شدهاند. امروزه دیتاستها نقش مهمی در صنایع و همچنین مراکز آموزشی دارند که هدف آنها افزایش بهرهوری و آموزش نیروهای کارآمد است. در این مطلب از مجله فرادرس، یاد میگیریم دیتاست چیست و درک مناسبی از نحوه کارکرد انواع دادهها بهدست میآوریم.
در این مطلب، ابتدا به پرسش دیتاست چیست پاسخ میدهیم و پس از معرفی انواع دیتاستها، با نحوه تقسیم و ارزیابی دادهها آشنا میشویم. سپس شرحی از ویژگیهای مهم دیتاستها ارائه داده و با بررسی تعدادی از نمونههای کاربردی، روشهای ایجاد دیتاستها را یاد میگیریم. در انتهای این مطلب از مجله فرادرس، به معرفی برخی از رایجترین منابع دریافت دیتاستها میپردازیم و پس از بیان تفاوت سه مفهوم داده، پایگاه داده و مجموعهداده یا دیتاست، به چند مورد از پرسشهای متداول در این زمینه پاسخ میدهیم.
مجموعه داده یا دیتاست چیست؟
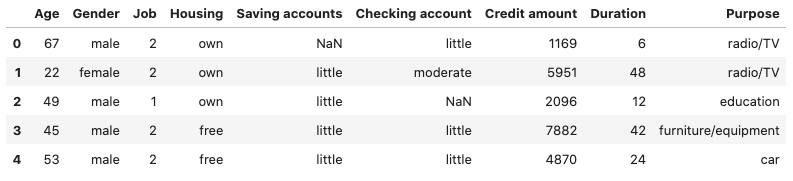
دیتاست مجموعهای از دادههای جمعآوری شده است که به پژوهشگران و توسعهدهندگان در حل مسئله کمک میکند. در هر دیتاست، سطرها نشاندهنده تعداد نمونههای داده و هر ستون بیانگر یکی از ویژگیهای مجموعهداده است. از دیتاستها برای تصمیمگیری آگاهانه و آموزش دادن الگوریتمها در کاربردهایی همچون یادگیری ماشین و کسبوکارها بسیار استفاده میشود. البته باید توجه داشت که هر دیتاست اندازه و پیچیدگی منحصربهفردی داشته و اغلب برای اطمینان حاصل کردن از کیفیت دادهها، ابتدا باید طی فرایندی با عنوان «پیشپردازش» (Preprocessing)، به اصطلاح پاکسازی شود. در تصویر زیر نمونهای از یک دیتاست را مشاهده میکنید:

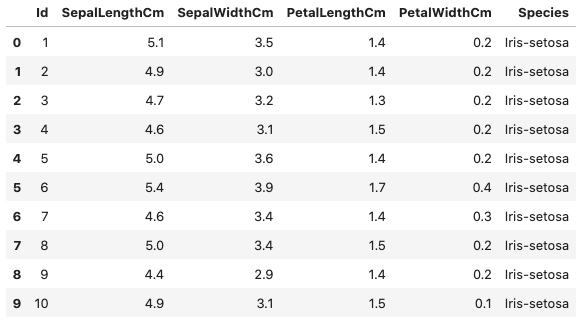
این دیتاست، یکی از مشهورترین مجموعهدادههای مورد استفاده در یادگیری ماشین است که بر اساس چند ویژگی، گونههای مختلف گیاه «زنبق» (Iris) را طبقهبندی کرده است. در طراحی و ساخت هر مدل یادگیری ماشین، ویژگیهای ورودی دیتاست نقش منابع یادگیری را داشته و خروجی پیشبینی شده با ویژگی خروجی دیتاست مقایسه میشود. در زیر، ویژگیهای ورودی و خروجی دیتاست Iris فهرست شده است:
- ویژگیهای ورودی: «طول کاسبرگ» (Sepal Length)، «عرض کاسبرگ» (Sepal Width)، طول گلبرگ (Petal Length) و «عرض گلبرگ» (Petal Width).
- ویژگی خروجی: «نوع گونه» (Species).
دیتاستها را میتوان در فرمتهایی مانند CSV یا «مقادیر جداشده با ویرگول» (Comma-separated Values)، جداول نرمافزار «مایکروسافت اِکسل» (Microsoft Excel)، JSON یا «نشانهگذاری اشیاء در جاوا اسکریپت» (JavaScript Object Notation) و فایلهای فشرده Zip ذخیره کرد.
انواع دیتاست چیست؟
در راستای پاسخ دادن به پرسش دیتاست چیست، آشنایی با انواع دیتاستها نیز ضرورت دارد. از جمله انواع مختلف دیتاستها میتوان به موارد زیر اشاره کرد:
- دیتاستهای «عددی» (Numerical): نمونه دادههای عددی مانند دما، رطوبت و امتیاز که قابلیت اعمال معادلات ریاضی بر آنها وجود دارد.
- دیتاستهای «طبقهبندی شده» (Categorical): این دیتاستها شامل دادههایی همچون رنگ، جنسیت، ورزش و شغل میشوند که میتوان آنها را در دسته یا گروههای مجزا طبقهبندی کرد.
- دیتاستهای «مبتنیبر وب» (Web-based): این نوع از دیتاستها از طریق ارسال درخواست HTTP و فراخوانی واسطهای برنامهنویسی کاربردی یا همان API، جمعآوری شده و در «تحلیل داده» (Data Analytics) مورد استفاده قرار میگیرند. ذخیرهسازی این دیتاستها اغلب با فرمت JSON صورت میگیرد.
- دیتاستهای «سری زمانی» (Time Series): متشکل از دادههایی مانند تغییرات جغرافیایی یک ناحیه که در بازه زمانی مشخصی جمعآوری شدهاند.

- دیتاستهای «مبتنیبر تصویر» (Image-based): اغلب از دیتاستهایی که شامل نمونههای تصویری هستند، در کاربردهای مقایسهای مانند تفاوت علائم چند نوع بیماری مختلف استفاده میشود.
- دیتاستهای «ترتیبی» (Ordered): دادههایی که بدون ترتیب ارزشی ندارند. مانند امتیازاتی که کاربران یک پلتفرم ویدئویی برای فیلمها ثبت کردهاند.
- دیتاستهای «بخشبندی شده» (Partitioned): متشکل از دادههایی که در چند گروه مجزا بخشبندی شدهاند.
- دیتاستهای «فایل محور» (File-based): دیتاستهایی که در قالب فایلهایی با پسوند csv، json یا xlsx ذخیره میشوند.
- دیتاستهای «دو متغیره» (Bivariate): در این قبیل از دیتاستها، دو کلاس یا ویژگی با یکدیگر «همبستگی» (Correlation) مستقیم دارند. به عنوان مثال، میان ویژگیهای وزن و قد ارتباط مستقیمی وجود دارد.
- دیتاستهای «چند متغیره» (Multivariate): همانطور که از نام آن پیداست، در دیتاستهای چند متغیره میان دو یا تعداد بیشتری از کلاسها همبستگی وجود دارد. به عنوان مثال، دو متغیر تعداد غیبت و نمرات کلاسی، در ارتباط مستقیم با معدل دانشآموز هستند.
تقسیم و ارزیابی دیتاست ها در یادگیری ماشین
کاربرد دیتاست تنها در فرایند آموزش خلاصه نمیشود. همزمان با بهکارگیری «مجموعه آموزشی» (Training Set) برای آموزش دادن مدل یادگیری ماشین، قسمت دیگری از دیتاست نیز با عنوان «مجموعه آزمایشی» (Testing Set)، در ارزیابی عملکرد مدل مورد استفاده قرار میگیرد.

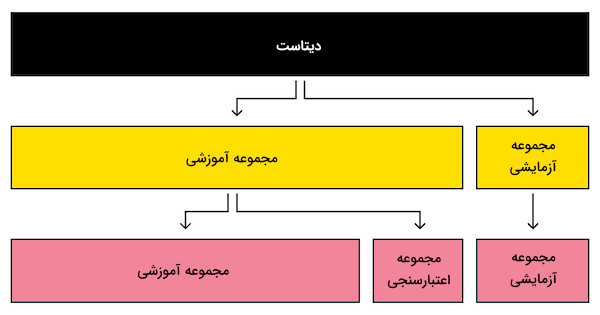
سپس در مرحلهای اختیاری و برای اجتناب از آموزش دیدن مدل با دادههای تکراری و در نتیجه ارائه پیشبینیهای «سوگیرانه» (Biased)، میتوان مجدد دیتاست را به بخش سومی با عنوان «مجموعه اعتبارسنجی» (Validation Set) تقسیم کرد.
چگونه کار کردن با دیتاست ها را یاد بگیریم؟

همچنین، اگر علاقه دارید پس از آشنایی با اصول و قواعد اولیه، آموختههای خود را به چالش کشیده و با استفاده از ابزارهایی مانند زبانهای برنامهنویسی پایتون و R، نحوه کار کردن با دیتاستها را از طریق پیادهسازی الگوریتمهای یادگیری ماشین فرا بگیرید، مشاهده فیلمهای آموزشی داده کاوی و یادگیری ماشین فرادرس را به شما پیشنهاد میکنیم:
ویژگی های یک دیتاست چیست؟
پس از آنکه یاد گرفتیم دیتاست چیست، در این بخش با مفهوم ویژگیهای یک دیتاست آشنا میشویم. وقتی صحبت از ویژگیهای دیتاست میشود، اغلب به ستونهای مجموعهداده اشاره داریم. ویژگیها مهمترین بخش از هر دیتاستی هستند؛ چرا که تمامی فرایند توسعه مدل و پیشبینی خروجی نهایی بر اساس همین ویژگیها انجام میشود. نوع داده و قابلیتهای هر ویژگی، نسبت به مجموعهداده و هدف مسئله متفاوت است. چند مورد از ویژگیهای رایج دیتاستها را در زیر فهرست کردهایم:


- ویژگیهای «عددی» (Numerical): ویژگیهایی مانند وزن و ارتفاع که هم میتوانند در بازهای پیوسته مانند اعداد اعشاری قرار داشته و هم مقادیر گسسته و صحیح را بپذیرند.
- ویژگیهای «طبقهبندی شده» (Categorical): این نوع از ویژگیها در چند کلاس یا گروه مجزا مانند جنسیت و انواع رنگها قابل جداسازی هستند.
- «فراداده» (Metadata): توصیفی جامع از دادهها که در دیتاستهای بزرگ کاربرد دارد. هنگام واگذاری وظیفه مدیریت و کار با مجموعهداده به فردی جدید، وجود چنین ویژگی باعث افزایش بهرهوری و صرفهجویی در زمان میشود.
- «اندازه دادهها» (Size of the Data): این ویژگی به تعداد نمونهها و همچنین ستونهای موجود در هر دیتاست اشاره دارد.
- «فرمت دادهها» (Formatting of Data): امروزه دیتاستها در فرمتهای متنوع و بهصورت آنلاین در دسترس همگان قرار دارند. از جمله رایجترین فرمتها، میتوان به مواردی همچون XML، CSV، JSON یا «زبان نشانهگذاری گسترشپذیر» (Extensible Markup Language)، جداول کتابخانه Pandas در زبان برنامهنویسی پایتون که با عنوان Dataframe شناخته میشوند و فایلهای نرمافزار اِکسل با پسوندهای xlsx یا xlsm اشاره کرد. بهطور معمول، مجموعهدادههای حجیم، بهویژه مواردی که شامل تصاویر میشوند را میتوان با فرمت فشرده شده Zip از اینترنت دریافت و سپس از حالت فشرده خارج کرد.
- «متغیر هدف» (Target Variable): ویژگی که مقادیر آن با خروجی مدل یادگیری ماشین مقایسه شده و نقش مهمی در فرایند آموزش دارد.
- «دادههای ورودی» (Data Entry): هر مقدار داده مجزایی که در دیتاست مشاهده میشود، یک داده ورودی است.
نمونه هایی از انواع دیتاست
در فضای اینترنت برای هر مسئله و کاربردی، بیش از هزاران دیتاست وجود دارد. برای دانلود چنین دیتاستهایی میتوانید به وبسایتهایی همچون Kaggle و UCI Machine Learning Repository مراجعه کنید. در ادامه این بخش، نگاهی به چند مورد از دیتاستهای مشهور و رایج در زمینه یادگیری ماشین میاندازیم.
۱. دیتاست شهر های ایالت تامیل نادو کشور هند
این دیتاست را میتوانید از سایت Kaggle با عنوان Tamilnadu Population و فرمت CSV دریافت کنید. در این دیتاست، تراکم جمعیت مناطق مختلف ایالت «تامیل نادو» (Tamil Nadu) هند اعلام شده است؛ ویژگی که آن را به گزینه مناسبی برای تحلیل داده و آموزش مدلهای یادگیری ماشین تبدیل میکند. بهطور معمول، از این نوع دیتاستها برای تکمیل اطلاعات میدانی استفاده میشود.

۲. دیتاست گونه های گیاه زنبق
از این دیتاست به عنوان یکی از رایجترین و همچنین سادهترین مجموعهدادهها برای آزمودن الگوریتمهای طبقهبندی، بهویژه از نوع «نظارت شده» (Supervised) یاد میشود. دیتاست گیاه زنبق یا Iris که پیشتر نیز به آن اشاره شد، از جمله مواردی است که بسیار مورد توجه افراد مبتدی برای انجام پروژههای یادگیری ماشین قرار دارد.
۳. دیتاست ریسک اعتباری افراد مقیم کشور آلمان
نمونهای از دیتاستهایی که در مدلهای یادگیری ماشین «نظارت نشده» (Unsupervised) کاربرد دارند. از جمله موارد کاربردی این دیتاست که با عنوان German Credit Risk شناخته میشود، گروهبندی و جداسازی افراد به اصطلاح خوشحساب، از کسانی است که امتیاز اعتباری پایینی دارند.
روش های ایجاد دیتاست
حالا که بهخوبی میدانید دیتاست چیست، در این بخش با دو مورد از روشهای کاربردی ایجاد و ساخت دیتاست آشنا میشویم. گاهی به دلایلی از جمله عدم دسترسی به نوع داده مدنظر، نمیتوان از دیتاستهای آماده موجود در اینترنت استفاده کرد و در نتیجه، نیاز است تا دیتاست جدیدی ایجاد کنیم. زبان برنامهنویسی پایتون به عنوان یکی از رایجترین ابزارهای یادگیری ماشین، این قابلیت را دارد تا با تولید دادههای تصادفی به اندازه دلخواه، در تحلیل داده بهکار گرفته شود. روش دیگر، بهرهگیری از ابزارهای «پرامپتنویسی» (Prompting) هوشمند نظیر «چتجیپیتی» (ChatGPT)، Perplexity AI یا «جمنای» (Gemini)، برای ساخت جداول و دیتاستهایی با دادههای تصادفی است. در ادامه این مطلب از مجله فرادرس، شرح دقیقتری از دو روش عنوان شده ارائه میدهیم. همچنین، برای تمرین پرامپتنویسی اصولی و دریافت نتایج دقیقتر از ابزارهای هوش مصنوعی، مشاهده فیلم آموزش چت با هوش مصنوعی در فرادرس را به شما پیشنهاد میکنیم:

۱. تولید داده با پایتون
برای آنکه بتوانیم از زبان برنامهنویسی پایتون برای ایجاد دیتاست استفاده کنیم، ابتدا باید دو کتابخانه NumPy و Pandas را نصب داشته باشیم. کتابخانه NumPy از طریق دستور زیر قابل نصب است:
pip install numpyهمچنین کتابخانه Pandas را نیز میتوانید مانند نمونه نصب کنید:
pip install pandasسپس و برای ساخت دیتاست مورد نظر، متغیرها و همچنین ویژگیها را تعریف کرده و در ادامه، مانند زیر، مقادیر هر کدام را بهصورت تصادفی انتخاب میکنیم:
1import pandas as pd
2import numpy as np
3import random as rd
4
5
6# Bussiness_type = ['Office_space','Restaurants','Textile_shop','Showrooms','grocery_shop']
7Bussiness_type = [1, 2, 3, 4, 5]
8# Demographics = ['Kids', 'Youth', 'Midde_aged', 'Senior']
9Demographics = [1, 2, 3, 4]
10# Accessibility = ['Bad', 'Fair', 'Good', 'Excellent']
11Accessibility = [1, 2, 3, 4]
12# Competition = ['low', 'medium', 'high']
13Competition = [1, 2, 3]
14Area = [250, 500, 750, 1000, 1500]
15Rent_per_month = ['5000', '75000', '95000', '10000', '13000', '17000', '20000']
16Gross_tax = [2.2, 3.4, 4.5, 5.6, 7.2, 10.2, 6.8, 9.3, 11, 13.4]
17labour_cost = [3500, 5000, 6500, 7500, 9000, 11000, 16000, 25000, 15000, 12500]
18location = ['San Diego', 'Miami', 'Seattle', 'LosAngeles', 'LasVegas', 'Idaho', 'Phoenix', 'New Orleans',
19 'WashingtionDC', 'Chicago', 'Boston', 'Philadelphia', 'New York', 'San Jose', 'Detroit', 'Dallas']
20# Location = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
21
22buss_type = []
23demo = []
24access = []
25comp = []
26area = []
27rpm = []
28gtax = []
29labour_cst = []
30loc = []
31
32# Net_profit is to be calculated
33
34for i in range(1000):
35 buss_type.append(rd.choice(Bussiness_type))
36 demo.append(rd.choice(Demographics))
37 access.append(rd.choice(Accessibility))
38 comp.append(rd.choice(Competition))
39 area.append(rd.choice(Area))
40 rpm.append(rd.choice(Rent_per_month))
41 gtax.append(rd.choice(Gross_tax))
42 labour_cst.append(rd.choice(labour_cost))
43 loc.append(rd.choice(location))
44
45
46dic_data = {'Business_type': buss_type, 'Demographics': demo, 'Accessibility': access, 'Competition': comp,
47 'Area(sq feet)': area, 'Rent_per_month': rpm, 'Gross_tax(%)': gtax, 'labour_cost(USD)': labour_cst, 'location': loc}
48frame_data = pd.DataFrame(dic_data)
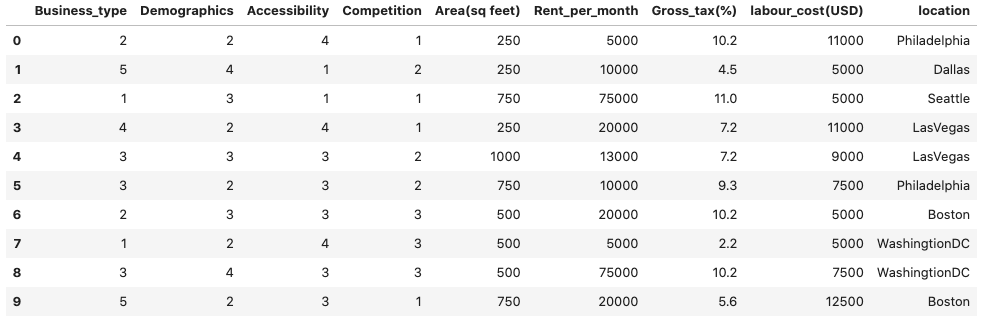
49frame_data.to_csv('autogen_data.csv')همانطور که در تصویر زیر یعنی خروجی اجرای قطعه کد بالا نیز مشاهده میکنید، دیتاست ایجاد شده با نام autogen_data.csv ، مجموعهدادهای است متشکل از اطلاعات انواع کسبوکارها با ستون یا همان ویژگیهای زیر:
- «نوع کسبوکار» (Business Type)
- «اطلاعات جمعیتی» (Demographics)
- «دسترسپذیری» (Accessibility)
- «رقابت» (Competition)
- «مساحت» (Area)
- «اجاره در ماه» (Rent Per Month)
- «مالیات بر درآمد» (Gross Tax)
- «هزینه نیروی کار» (Labour Cost)
- «موقعیت مکانی» (Location)
۲. ایجاد دیتاست با هوش مصنوعی
یکی دیگر از راههای ایجاد دیتاست، استفاده از ابزارهای «هوش مصنوعی مولد» (Generative Artificial Intelligence) مانند ChatGPT است. برای اینکار، ابتدا از ChatGPT میخواهیم تا با در اختیار داشتن اطلاعاتی از جمله تعداد نمونهها و نام ستونها، دیتاستی برای موقعیت تحصیلی دانشجویان تولید کند:

خروجی مانند تصویر زیر است:

با بهرهگیری از این روش، میتوان مقادیر داده بسیاری برای آموزش دادن مدلهای یادگیری ماشین تولید کرد.
معرفی منابع دریافت انواع دیتاست
در ادامه پاسخ دادن به پرسش دیتاست چیست، بهترین راه برای مسلط شدن بر مفاهیمی که تا اینجا مرور کردهایم، تحلیل و در نهایت طراحی الگوریتمهای یادگیری ماشین بر اساس دیتاستهای رایج و کاربردی است. پایگاههای داده فراوانی برای دریافت دیتاستها وجود دارد؛ اما منابعی که در این بخش معرفی میکنیم، در واقع نمونههایی بوده که از محبوبیت بیشتری در میان متخصصان و افراد حرفهای حوزه علم داده برخوردار هستند.
۱. Kaggle
از Kaggle «+» به عنوان یکی از محبوبترین پلتفرمهای علم داده یاد میشود. وبسایت Kaggle علاوهبر رقابتهای بهروز، فهرستی از آموزشهای مرتبط را در زمینههایی همچون یادگیری ماشین و هوش مصنوعی شامل میشود. مزیت بزرگ این پلتفرم در ارائه هزاران دیتاست کوچک و بزرگ بهصورت رایگان و با فرمت CSV است. بسیاری از دیتاستهای موجود در وبسایت Kaggle، مربوط به رقابتهایی هستند که در سابق به اتمام رسیده و حالا در اختیار عموم قرار گرفتهاند. از جمله این نمونهها، دیتاست «تایتانیک» (Titanic) است که به شما این امکان را میدهد تا با طراحی مدل یادگیری ماشین خود، مسافرانی که از حادثه جان سالم بهدر میبرند را پیشبینی کنید. در انتها نیز میتوانید نتایج خود را با دیگر کاربران به اشتراک بگذارید. پس اگر بهدنبال پلتفرمی برای یادگیری، تمرین و رقابت هستید، وبسایت Kaggle انتخاب مناسبی برای شروع است.
۲. Google Dataset Search
این پلتفرم در سال ۲۰۱۸ منتشر شد و نوآوری آن در ارائه دسترسی به دیتاستهای عمومی و رایگان برای همه خلاصه میشود. با استفاده از «موتور جستجوی دیتاست گوگل» (Google Dataset Search) «+»، حق انتخاب از میان گستره عظیمی از دیتاستها با موضوعات و فرمتهای مختلف مانند PDF، CSV، JPG و TXT به شما داده میشود. تنها کافیست وارد وبسایت شده و مانند جستجو معمولی، نام یا موضوعی که بهدنبال آن هستید را تایپ کنید. همزمان با تایپ کردن عنوان، گزینههای مشابهی نیز به شما پیشنهاد میشود که ممکن است زمینهساز پروژههای جدید و هیجانانگیزی برای شما باشند.
۳. GitHub
علاوهبر پشتیبانی از انواع پروژههای متنباز برنامهنویسی، پلتفرم GitHub «+»، هزاران دیتاست متنوع را نیز برای کارهایی همچون تحلیل داده شامل میشود. با استفاده از ابزارهای جستجو وبسایت GitHub، میتوان دیتاستهایی را با زبان و نوع داده متنوع انتخاب کرد. همچنین، این پلتفرم به شما اجازه میدهد تا نتیجه کار را با سایرین به اشتراک گذاشته و ارتباطات خود را در حوزه یادگیری ماشین و علم داده گسترش دهید.

۴. World Bank Open Data
وبسایت Word Bank Open Data «+»، یکی از کاملترین و متنوعترین منابع آماری و دیتاست به حساب میآید. شما میتوانید از این پلتفرم برای یافتن اطلاعات جمعیتی همچون اقتصاد، آموزش، وضعیت خدمات درمانی، سطح درآمد و جمعیت استفاده کنید. وبسایت World Bank Open Data، علاوهبر ارائه دیتاستهای با کیفیت و رایگان، ابزارهایی نیز برای «مصورسازی» (Visualization) دیتاستهای بزرگ در اختیار کاربران قرار میدهد.
۵. Data.world
همزمان با دسترسی به دیتاستهای رایگان، پلتفرم Data.world «+» امکان تجزیه و تحلیل مستقیم دادهها را نیز برای کاربران فراهم کرده است. تنها کافیست اکانت خود را به صورت رایگان ایجاده کرده تا بتوانید کار خود را بر روی سه پروژه رایگان شروع کنید. اگر به فضای ذخیرهسازی بیشتری نیز داشتید، میتوانید با پرداخت هزینهای، از سایر طرحهای وبسایت Data.world استفاده کنید. موتور جستجوی این پلتفرم ابزار کارآمدی برای پیدا کردن کلمات کلیدی، مخازن داده، سازمانها و حتی افراد فعال در حوزه علم داده است.
۶. DataHub
وبسایت DataHub «+»، در حقیقت پلتفرمی برای توزیع داده است که جستجو میان کلکسیون متنوعی از دیتاستها را برای کاربران ممکن ساخته است. در بخش وبلاگ این پلتفرم میتوانید از آخرین مقالات منتشر شده در حوزه علم داده مطلع شوید. نکتهای که وبسایت DataHub را متمایز میکند، وجود بخش مستندات برای آشنایی با نحوه استفاده از دیتاستها، همراه با آموزشهایی ارزشمند در زمینه مصورسازی و مدیریت آنلاین مجموعهدادههای بزرگ است.
۷. Humanitarian Data Exchange
اگر بهدنبال پلتفرمی برای دانلود، آپلود، اشتراکگذاری و استفاده از دادهها هستید، وبسایت Humanitarian Data Exchange «+» گزینه مناسبی برای شما است. در این پلتفرم میتوانید بر اساس معیارهایی همچون موقعیت مکانی و فرمت، دیتاستهای رایگان بسیاری پیدا کنید.
۸. FiveThirtyEight
این وبسایت کمی با سایر منابع تفاوت دارد. پلتفرمی منحصربهفرد که همراه با انتشار محتوای ورزشی، سیاسی و علمی، کد و دادههای استفاده شده در تولید آن محتوا را نیز به اشتراک میگذارد. تمامی دیتاستهای موجود در وبسایت FiveThirstyEight «+»، در اختیار عموم قرار داشته و میتوانید از وضعیت بهروزرسانی دادهها نیز اطمینان حاصل کنید.
۹. UCI Machine Learning Repository
به عنوان یکی دیگر از منابعی که بسیار در توسعه مدلهای یادگیری ماشین کاربرد دارد، میتوان به پلتفرم UCI Machine Learning Repository «+» اشاره کرد. شاید این پلتفرم به اندازه دیگر مراجع کامل نباشد، اما از جمله قدیمیترین کتابخانههای دریافت دیتاست بهشمار میرود؛ تا جایی که تاریخ قدیمیترین دیتاست موجود در این پلتفرم به سال ۱۹۸۷ بر میگردد. وبسایت UCI رابط کاربری سادهای دارد که با استفاده از آن میتوانید دیتاست مدنظر خود را پیدا کنید.

۱۰. Academic Torrents Data
اگر در حال تحصیل هستید یا مقالهای علمی در دست تالیف دارید، پلتفرم Academic Torrents Data «+»، مجموعه گوناگونی از دیتاستهای بزرگ استفاده شده در مقالات علمی را در اختیار شما قرار میدهد. به سادگی وارد وبسایت شده و با وارد کردن عنوان جستجو، دیتاست، مقاله و یا دوره آموزشی مورد نظر را پیدا کنید. همچنین میتوانید نتایج آزمایشات خود را با دیگران به اشتراک بگذارید.
تفاوت داده، پایگاه داده و دیتاست چیست؟
بهدلیل تشابه اسمی، بسیاری از جمله افراد مبتدی در فهم مفاهیم «داده» (Data)، «پایگاه داده» (Database) و دیتاست یا «مجموعهداده» (Dataset) با چالش روبهرو هستند. پس از آنکه یاد گرفتیم دیتاست چیست، در این بخش، شرح مختصری از سه مفهوم داده، پایگاه داده و مجموعهداده ارائه میدهیم.


داده
به هر موجودیتی مانند مقادیر «عددی» (Numerical) یا «طبقهبندی شده» (Categorical) که قابل شمارش یا جداسازی باشد، «داده» (Data) گفته میشود. با این حال، دادهها زمانی ارزشمند شده و قابل تجزیه و تحلیل هستند که با یکدیگر ترکیب شده و مجموعهای از دادهها را تشکیل دهند.
دیتاست یا مجموعه داده
هر دیتاست یا «مجموعه داده» (Dataset)، متشکل از دادههایی با نوع و همچنین ویژگیهای یکسان است. دیتاستها در توسعه مدلهای یادگیری ماشین، تحلیل داده و «مهندسی ویژگی» (Feature Engineering) کاربرد دارند و به دو دسته کلی «ساختارمند» (Structured) مانند وزن و قد و دادههای «بدون ساختار» (Unstructured) مانند فایلهای صوتی و تصویری تقیسم میشوند.
پایگاه داده
مجموع چند دیتاست را «پایگاه داده» (Database) گویند. یک پایگاه داده ممکن است شامل دیتاستهایی باشد که از نظر موضوعی هیچ ارتباطی با یکدیگر ندارند. از جمله انواع پایگاههای داده که برای پشتیبانی از دادههای ساختارمند و بدون ساختار طراحی شدهاند، میتوان به دو نوع «اِسکیواِل» (SQL) و NoSQL اشاره کرد. شما میتوانید با مطالعه عنوانی از مجله فرادرس که در ادامه لینک آن قرار داده شده است، تفاوتهای دو پایگاه داده SQL و NoSQL را یاد گرفته و با هر کدام بیشتر آشنا شوید:
در جدول زیر، خلاصهای از مقایسه سه مفهوم داده، مجموعهداده و پایگاه داده را ملاحظه میکنید.
| داده | مجموعهداده | پایگاه داده |
| شامل ویژگیها و اطلاعات خام است. | شامل ساختارهای داده مانند جداول و مجموعهها است. | متشکل از مجموعهدادههایی با فرمت یکسان است. |
| به تنهایی فاقد محتوا و نامرتب است. | دادهها در قالب چندین سطر و ستون سازماندهی میشوند. | دادهها در جداولی ذخیره شدهاند که ممکن است چندین بُعد داشته باشند. |
| دارای اطلاعات اولیهای بوده و پایه و اساس دیتاستها و همچنین پایگاههای داده را تشکیل میدهد. | دادهها را منظم ساخته و موجب استخراج اطلاعات مفیدی میشود. | متشکل از دادههای ساختارمند و مرتبط به یکدیگر است. |
| به دلیل فقدان ساختار، قابل تغییر نیست. | با استفاده از ابزارهایی مانند زبان برنامهنویسی پایتون، امکان ایجاد تغییر در آن وجود دارد. | از طریق مجموعهای از دستورات و کوئریهای پرسوجو، قابل تغییر است. |
| نیازمند پیشپردازش و تبدیل به موجودیتی قابل استفاده است. | در مواردی همچون تحلیل داده، مدلسازی و مصورسازی کاربرد دارد. | پردازش داده از طریق جابهجایی اطلاعات انجام میشود. |
سوالات متداول پیرامون دیتاست چیست؟
پس از آنکه یاد گرفتیم دیتاست چیست و با روش استفاده از انواع مختلف آن نیز آشنا شدیم، حال زمان خوبی است تا در این بخش از مطلب مجله فرادرس، به چند مورد از سوالات پرتکرار در این زمینه پاسخ دهیم.

مفهوم دیتاست چیست؟
مجموعهای سازماندهی شده از دادهها که با عنوان دیتاست شناخته میشود. عمده کاربرد دیتاستها در یادگیری ماشین، کسبوکار و امور مالی است؛ حوزههایی که برای توسعه و تصمیمگیری آگاهانه به چنین ابزاری نیاز دارند.
انواع دیتاست چیست؟
به عنوان چند نمونه رایج از انواع دیتاست، میتوان به موارد زیر اشاره کرد:
- دیتاستهای عددی
- دیتاستهای طبقهبندی شده
- دیتاستهای ترتیبی
- دیتاستهای بخشبندی شده
- دیتاستهای چند متغیره

دیتاستها چه ویژگیهایی دارند؟
هر دیتاست ویژگیهای منحصربهفردی دارد؛ از جمله:
- ویژگیهای طبقهبندی شده
- فراداده
- تعداد دادهها
- فرمت دادهها
- متغیر هدف
اهمیت دیتاست در یادگیری ماشین چیست؟
نقش دیتاست در شکل دادن به توانایی یادگیری مدلها و در نتیجه پیشبینی دقیقتر خروجی است. با استفاده از دیتاستها میتوانید مدل یادگیری ماشین خود را آموزش داده و همچنین معیاری برای ارزیابی دقت نهایی داشته باشید.
جمعبندی
شاید جمعآوری انواع دیتاستها کار آسانی بهنظر برسد و اینطور فکر کنید که باید بیشتر زمان و منابع خود را صرف ساخت مدل یادگیری ماشین کنید. با این حال، تجربه نشان میدهد که بهدلیل منابع محدود و نیاز به پردازش، بررسی و شناخت دادهها علاوهبر مهم بودن، بسیار زمانبر است. به همین دلیل، همانطور که در این مطلب از مجله فرادرس خواندیم، پاسخ دادن به پرسشهایی مانند دیتاست چیست و آشنایی با نحوه بهرهگیری از دادهها در یادگیری ماشین بسیار اهمیت دارد. در نهایت، دیتاستی ارزشمند و مفید است که هم به اندازه کافی جامع و هم از کیفیت بالا و استانداردی برخوردار باشد.