Q-Learning و یادگیری تقویتی — خودآموز سریع و جامع

در قسمت اول از مجموعه مطالب یادگیری تقویتی با عنوان «یادگیری تقویتی (reinforcement learning) — راهنمای ساده و کاربردی»، به مفاهیم یادگیری، یادگیری ماشین، عامل هوشمند، یادگیری تقویتی، یادگیری تقویتی عمیق و رویکردهای گوناگون یادگیری تقویتی (ارزش محور، سیاست محور و مدل محور) پرداخته شد. Q-Learning یک الگوریتم یادگیری تقویتی ارزش محور است. در این قسمت به روش Q-Learning پرداخته خواهد شد و به سوالات زیر پاسخ داده میشود.
- Q-Learning چیست؟
- چگونه میتوان این الگوریتم را با استفاده از کتابخانه Numpy پیادهسازی کرد؟

مساله: شوالیه و پرنسس
شوالیهای باید پرنسس اسیر شده در یک قلعه که در تصویر زیر نشان داده شده را نجات دهد.

شوالیه میتواند در هر زمان به اندازه یک کاشی حرکت کند. دشمن توانایی حرکت ندارد، اما اگر شوالیه در خانهای که دشمن وجود دارد قرار بگیرد، کشته میشود. هدف آن است که شوالیه از سریعترین مسیر ممکن به قلعه برود. این مسیر را میتوان با استفاده از سیستم «امتیازدهی نقاط» (points scoring) ارزیابی کرد.
- شوالیه در هر گام ۱- امتیاز از دست میدهد (از دست دادن امتیازها در هر گام به عامل کمک میکند تا سریعتر باشد).
- اگر شوالیه یک دشمن را لمس کند، ۱۰۰- امتیاز از دست میدهد و اپیزود به پایان میرسد.
- اگر شوالیه در قلعه باشد، برنده شده و ۱۰۰+ امتیاز دریافت میکند.
پرسشی که در این وهله مطرح میشود این است که «چگونه میتوان عاملی ساخت که چنین کاری را انجام دهد؟». استراتژی اولی که میتوان اتخاذ کرد در ادامه مطرح شده است. فرض میشود که شوالیه تلاش میکند به هر کاشی برود و آن کاشی را رنگی کند. هر کاشی امن به رنگ سبز و هر کاشی ناامن قرمز رنگ میشود.

میتوان به عامل گفت که تنها به کاشیهای سبز رنگ برود. اما مساله این است که این کار واقعا مفید نیست. زیرا مشخص نیست که در صورت مجاور بودن کاشیها کدام یک بهترین است. بنابراین، عامل در تلاش برای رسیدن به قلعه در یک حلقه بینهایت قرار میگیرد.
معرفی Q-table
دومین استراتژی ممکن در ادامه بیان میشود. ساخت جدولی که در آن بیشینه پاداش آینده مورد انتظار برای هر عمل در هر حالت محاسبه شود. با بهرهگیری از این جدول، مشخص میشود که بهترین عمل ممکن برای هر حالت چیست. هر حالت (کاشی) دارای چهار عمل ممکن است. این چهار عمل، پایین، بالا، چپ و راست رفتن هستند.

به منظور انجام محاسبات، این شبکه به یک جدول تبدیل میشود. جدول ساخته شده، Q-table نامیده میشود (Q سرنام quality است و مربوط به عبارت quality of the action). ستونها چهار عمل (چپ، راست، بالا و پایین) هستند. سطرها حالتها هستند. مقدار هر سلول بیشینه پاداش آینده مورد انتظار برای حالت داده شده و عمل است.

هر امتیاز Q-table، پاداش آینده مورد انتظار بیشینهای است که شوالیه در صورت عمل کردن با بهترین سیاست داده شده، به آن دست مییابد. به این Q-table میتوان به صورت بازی «برگه تقلب» نگاه کرد. به لطف این جدول، شوالیه با نگاه کردن به بالاترین امتیاز در هر سطر برای هر حالت، میداند که بهترین عمل قابل انجام چیست. به نظر میرسد مساله قلعه حل شده است! اما اکنون چطور باید ارزش را برای هر جز Q-Table محاسبه کرد؟!
الگوریتم Q-learning: یادگیری تابع ارزش عمل
تابع ارزش عمل (یا Q-function) دو ورودی حالت و عمل را دریافت میکند. سپس، پاداش آینده مورد انتظار برای آن حالت و عمل را باز میگرداند.

میتوان تابع Q را به عنوان خوانندهای تصور کرد که جدول Q-table را برای یافتن سطر مرتبط به حالت و ستون تخصیص یافته به عمل شوالیه مرور میکند. سپس، ارزش Q را از سلول مطابق باز میگرداند. این «پاداش آینده مورد انتظار» است.

پیش از آنکه شوالیه در محیط جستوجو کند، Q-table مقادیر دلخواه مشابهی (اغلب اوقات ۰) را ارائه میکند. با جستوجوی شوالیه در محیط، Q-table تخمین بهتر و بهتری را با به روز رسانی بازگشتی (Q(s,a با استفاده از «معادله بلمن» (Bellman Equation) در اختیار قرار میدهد.
فرآیند الگوریتم Q-learning

شبه کد الگوریتم Q-Learning
- مقداردهی اولیه Q-valueها ((Q(s,a) با ارزشهای دلخواه برای همه جفتهای حالت-عمل
- برای زندگی یا تا هنگامی که یادگیری متوقف شود
- عمل (a) را در حالت (s) کنونی جهان بر اساس تخمین کنونی Q-value (یعنی (Q(s,a) انتخاب کن
- عمل (a) را انجام بده و حالت خروجی (’s) و پاداش (r) را مشاهده کن
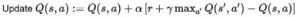

گام ۱: مقداردهی اولیه ارزشهای Q
Q-table با m ستون (m = تعداد اعمال) و n سطر (n = تعداد حالتها) ساخته شد. اکنون مقداردهی اولیه با «۰» انجام میشود.

گام ۲: برای زندگی (یا تا هنگامی که یادگیری متوقف شد)
گامهای ۳ تا ۵ هنگامی که به حداکثر تعداد اپیزودها (مشخص شده توسط کاربر) برسد یا به صورت دستی توسط کاربر متوقف شود، تکرار خواهند شد.
گام ۳: انتخاب یک عمل
انتخاب یک عمل a در وضعیت کنونی s برمبنای ارزش کنونی Q-value تخمین زده شده.
اما، اگر همه Q-valueها برابر با صفر باشند، شوالیه کدام عمل را در ابتدا انجام خواهد داد؟ توازن بین جستوجو و استخراج که در قسمت پیشین در رابطه با آن صحبت شد، اکنون حائز اهمیت میشود. ایده آن است که در آغاز، از «استراتژی حریصانه اپسیلون» (epsilon greedy strategy) استفاده شود.
- یک نرخ جستوجوی «اپسیلون» تعیین میشود که در آغاز برابر با یک قرار داده میشود. این، نرخ گامهایی است که شوالیه به طور تصادفی انجام میدهد. در آغاز، این مقدار باید بیشترین ارزش ممکن باشد، زیرا شوالیه هیچ چیز درباره ارزشهای موجود در Q-table نمیداند. این یعنی نیاز به جستوجوهای زیاد و انتخاب تصادفی اعمال توسط او است.
- یک عدد تصادفی تولید میشود. اگر این عدد بزرگتر از اپسیلون بود، استخراج انجام میشود (این یعنی از آنچه در حال حاضر مشخص است برای انتخاب بهترین عمل در هر گام استفاده میشود). در غیر این صورت، جستوجو صورت میپذیرد.
- ایده آن است که باید یک اپسیلون بزرگ در ابتدای راه آموزش Q-function وجود داشته باشد. سپس، به تدریج و پس از آنکه اطمینان عامل در تخمین Q-valueها افزایش یافت، مقدار آن کاهش پیدا کند.

گام ۴-۵: ارزیابی
انجام عمل a و مشاهده حالت خروجی s و پاداش r.
اکنون باید تابع (Q(s,a به روز رسانی شود. عمل a که در گام ۳ انتخاب شده بود انجام میشود و اجرای این عمل حالت s و پاداش r را در خروجی میدهد (همانطور که در فرآیند یادگیری تقویتی در قسمت اول این مطلب بیان شد). سپس، برای به روز رسانی (Q(s,a، از «معادله بلمن» (Bellman equation) استفاده میشود.

در اینجا، ایده به روز رسانی (Q(state, action، مانند آنچه در کد زیر بیان شده است.
1New Q value =
2 Current Q value +
3 lr * [Reward + discount_rate * (highest Q value between possible actions from the new state s’ ) — Current Q value ]اکنون فرآیند توضیح داده شده برای مثال موش و پنیر پیادهسازی میشود.

- یک پنیر = ۱+
- دو پنیر = ۲+
- کوه عظیمی از پنیر = ۱۰+ (پایان اپیزود)
- اگر موش، سم مرگ موش را بخورد = ۱۰- (پایان اپیزود)
گام ۱: انجام مقداردهی اولیه در Q-table

گام ۲: انتخاب یک عمل
از موقعیت آغاز، موش میتواند بین راست یا پایین یکی را انتخاب کند. دلیل این امر آن است که نرخ اپسیلون بزرگ موجود است (زیرا هنوز آگاهی درباره محیط برای موش وجود ندارد)، انتخاب تصادفی انجام میشود. برای مثال: حرکت به راست.


موش یک تکه پنیر پیدا کرد (۱+) و اکنون میتوان جدول Q-table را با آغاز از نقطه شروع و رفتن به راست، به روز رسانی کرد. این کار با استفاده از معادله بلمن انجام میشود.
گامهای ۴-۵: به روز رسانی Q-function


- ابتدا، تغییرات (ΔQ) در Q-value محاسبه میشود (آغاز، راست).
- سپس، مقدار اولیه Q به ΔQ (آغاز، راست) که با نرخ یادگیری چند برابر شده، اضافه میشود.
نرخ یادگیری به عنوان راهی که یک شبکه به سرعت مقدار پیشین را برای مقدار جدید رها کرده قابل تامل است. اگر نرخ یادگیری ۱ است، تخمین جدید، Q-value جدید خواهد بود.

بسیار عالی! اکنون اولین Q-value به روز رسانی شد.اکنون این کار دوباره و دوباره انجام میشود تا یادگیری متوقف شود.
پیادهسازی الگوریتم Q-learning
اکنون که نحوه کار الگوریتم مشخص شد، گام به گام به زبان پایتون، با استفاده از کتابخانه NumPy و در Jupyter notebook پیادهسازی میشود.
Q-Learning با FrozenLake
در ادامه، با بهرهگیری از الگوریتم Q-Learning، عاملی طراحی میشود که بازی FrozenLake را انجام میدهد. در بازی مذکور، هدف رفتن از نقطه آغاز (S) به حالت هدف (G) با قدم زدن روی کاشیهای یخ زده (F) و اجتناب از چالهها (H) است. اگرچه، یخ لغزنده است و بنابراین حرکت همیشه در جهتی که کاربر تمایل دارد انجام نمیشود.
گام ۰: ایمپورت کردن وابستگیها
از سه کتابخانه برای انجام این کار استفاده میشود که در ادامه بیان شدهاند.
- Numpy برای Qtable
- OpenAI Gym برای محیط FrozenLake
- Random برای تولید اعداد تصادفی
In [1]:
1import numpy as np
2import gym
3import randomگام ۱: ساخت محیط
- در این گام، محیط FrozenLake ساخته میشود.
- کتابخانه OpenAI Gym از محیطهای زیادی تشکیل شده که میتوان از آنها برای آموزش عامل استفاده کرد.
- در اینجا، محیط Frozen Lake برای آموزش عامل استفاده شده است.
In [2]:
1env = gym.make("FrozenLake-v0")گام ۲: ساخت Q-table و مقداردهی اولیه به آن
- اکنون، Q-table ساخته میشود تا تعداد سطرها (حالتها) و ستونهای موجود (اعمال) مشخص باشد. در حال حاضر باید سایز عمل (action_size) و سایز حالت (state_size) محاسبه شود.
- OpenAI Gym راهی برای انجام این کار فراهم میکند (env.action_space.n و env.observation_space.n).
In [3]:
1action_size = env.action_space.n
2state_size = env.observation_space.nIn [4]:
1qtable = np.zeros((state_size, action_size))
2print(qtable)
گام ۳: ساخت فراپارامترها
- در ادامه فراپامترها تعیین میشوند.
In [5]:
1total_episodes = 10000 # Total episodes
2learning_rate = 0.8 # Learning rate
3max_steps = 99 # Max steps per episode
4gamma = 0.95 # Discounting rate
5
6# Exploration parameters
7epsilon = 1.0 # Exploration rate
8max_epsilon = 1.0 # Exploration probability at start
9min_epsilon = 0.01 # Minimum exploration probability
10decay_rate = 0.01 # Exponential decay rate for exploration probگام ۴: الگوریتم Q learning
- اکنون، الگوریتم Q learning پیادهسازی میشود.
In [6]:
1# List of rewards
2rewards = []
3
4# 2 For life or until learning is stopped
5for episode in range(total_episodes):
6 # Reset the environment
7 state = env.reset()
8 step = 0
9 done = False
10 total_rewards = 0
11
12 for step in range(max_steps):
13 # 3. Choose an action a in the current world state (s)
14 ## First we randomize a number
15 exp_exp_tradeoff = random.uniform(0, 1)
16
17 ## If this number > greater than epsilon --> exploitation (taking the biggest Q value for this state)
18 if exp_exp_tradeoff > epsilon:
19 action = np.argmax(qtable[state,:])
20
21 # Else doing a random choice --> exploration
22 else:
23 action = env.action_space.sample()
24
25 # Take the action (a) and observe the outcome state(s') and reward (r)
26 new_state, reward, done, info = env.step(action)
27
28 # Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
29 # qtable[new_state,:] : all the actions we can take from new state
30 qtable[state, action] = qtable[state, action] + learning_rate * (reward + gamma * np.max(qtable[new_state, :]) - qtable[state, action])
31
32 total_rewards += reward
33
34 # Our new state is state
35 state = new_state
36
37 # If done (if we're dead) : finish episode
38 if done == True:
39 break
40
41 episode += 1
42 # Reduce epsilon (because we need less and less exploration)
43 epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
44 rewards.append(total_rewards)
45
46print ("Score over time: " + str(sum(rewards)/total_episodes))
47print(qtable)
گام ۵: استفاده از Q-table برای انجام بازی FrozenLake
- پس از ۱۰۰۰۰ اپیزود، Q-table به عنوان برگه تقلبی برای بازی FrozenLake در دسترس است.
- با اجرای این سلول، میتوان شاهد انجام بازی FrozenLake توسط عامل بود.
In [ ]:
1env.reset()
2
3for episode in range(5):
4 state = env.reset()
5 step = 0
6 done = False
7 print("****************************************************")
8 print("EPISODE ", episode)
9
10 for step in range(max_steps):
11 env.render()
12 # Take the action (index) that have the maximum expected future reward given that state
13 action = np.argmax(qtable[state,:])
14
15 new_state, reward, done, info = env.step(action)
16
17 if done:
18 break
19 state = new_state
20env.close()جمعبندی
- Q-learning یک الگوریتم یادگیری تقویتی ارزش محور است که برای پیدا کردن سیاست انتخاب عمل بهینه از تابع Q استفاده میکند.
- این الگوریتم، عمل مناسب انجام را بر مبنای تابع عمل-ارزش (action-value) ارزیابی میکند که ارزش قرار گرفتن در حالت قطعی و انجام یک عمل مشخص در آن حالت را به دست میدهد.
- هدف این الگوریتم بیشینهسازی تابع ارزش Q است (پاداش آینده مورد انتظار با توجه به یک حالت و عمل داده شده)
- جدول Q به عامل در پیدا کردن بهترین عمل برای حالت کمک میکند.
- بیشینهسازی پاداش مورد انتظار با انتخاب همه بهترین اعمال ممکن انجام میشود.
- Q سرنامی برای «quality» یک عمل مشخص در یک حالت مشخص است.
- تابع (Q(state, action، پاداش آینده مورد انتظار برای یک عمل در حالت تعیین شده را باز میگرداند.
- این تابع با استفاده از Q-learning قابل تخمین زدن است و به طور تکرار شونده (Q(s,a را با استفاده از معادله بلمن به روز رسانی میکند.
- پیش از آنکه محیط جستوجو شود، جدول Q مقادیر ثابت دلخواه را به دست میدهد، اما با آغاز جستوجوی عامل در محیط، Q تخمینهای بهتر و بهتری را ارائه میکند.
افرادی که تمایل به فراگیری مبحث یادگیری تقویتی دارند، علاوه بر مطالعه این مطالب، باید حتما اقدام به پیادهسازی و اصلاح کدهای ارائه شده در این مطلب کنند تا محتوای ارائه شده را به خوبی فرا بگیرند.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- آموزش یادگیری تقویتی با متلب
- مجموعه آموزشهای مهندسی کنترل
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای مهندسی برق
- مجموعه آموزشهای هوش محاسباتی
^^










فوق العاده عالی و روان توضیح دادید
ممنون