نظارت (Monitoring) روی یک وب اپلیکیشن در محیط Production — راهنمای جامع

در بخشهای قبلی سلسله مباحث آمادهسازی اپلیکیشن وب برای محیط Production، با شیوه راهاندازی سرورها، تنظیم طرح بازیابی و پشتیبانگیری آشنا شدیم. در این مقاله نگاهی به بحث نظارت روی اپلیکیشن و بهبود آگاهیمان از وضعیت سرورها و سرویسها خواهیم داشت. نرمافزارهای نظارت مانند Nagios, Icinga, و Zabbix به شما مکان میدهند که داشبوردهایی ایجاد کنید و زمانی که متوجه شوند اپلیکیشن شما نیازمند توجه خاصی است به شما هشدار میدهند. هدف از این کار تشخیص سریع مشکلات سیستم و آغاز اصلاح آنها تا قبل از تشخیص آنها از سوی کاربران است.
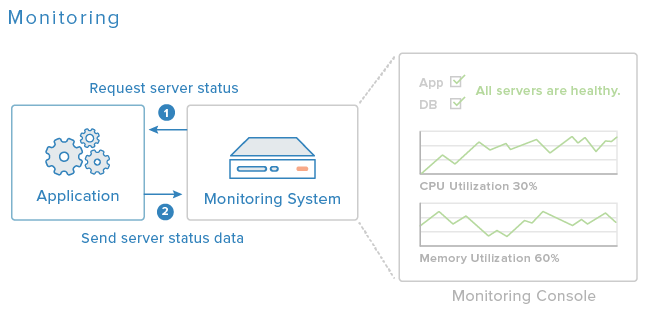
ما در این راهنما از Nagios 4 به عنوان نرمافزار نظارت استفاده خواهیم کرد و NRPE agent را روی سرورهایی که اپلیکیشن ما را تشکیل میدهند، نصب میکنیم.
ما میبایست برای هر سرور در مجموعه خود عامل نظارتی را نصب کنیم تا ببینیم آیا سرور روشن است و آیا پروسه اصلی آن (آپاچی، مایاسکیوال یا HAProxy) کار میکند یا نه. با این که این راهنمای نظارت بر اپلیکیشن راهنمای کاملی محسوب نمیشود، چون احتمالاً باید بررسیهای بیشتری که در این نوشته به آنها نمیپردازیم نیز انجام دهید؛ اما برای شروع بحث نظارت بر اپلیکیشنهای وب نقطه آغازین مناسبی محسوب میشود.
پیشنیازها
اگر میخواهید از طریق نام دامنه به داشبورد گزارشگیری خود وصل شوید بهتر است یک رکورد A زیردامنه خود، چیزی مانند «monitoring.example.com» ایجاد کنید که به آدرس IP عمومی سرور monitoring شما اشاره میکند. همچنین میتوانید از طریق آدرس IP عمومی سرور نظارت به داشبورد نظارتی دسترسی داشته باشید. بهتر است از پروتکل HTTPS برای این دسترسی استفاده کنید و دسترسی به آن را از طریق یک VPN محدود کنید.

نصب Nagios روی سرور نظارت
ابتدا باید Nagios 4 را روی سرور مخصوص نظارت خود نصب کنید. بدین منظور میتوانید از راهنمای «نصب Nagios 4 و نظارت روی سرورهای اوبونتو» استفاده کنید. اگر ترجیح میدهید میتوانید از Icinga که یک فورک Nagios است نیز استفاده کنید.
افزودن سرورها به Nagios
روی هر یک از سرورهای مجموعه خود (db1, app1, app2, and lb1) از بخش «نظارت روی یک میزبان اوبونتو با NRPE» در راهنمای نصب Nagios استفاده کرده و سرور را به فهرست نظارتی اضافه کنید. اطمینان حاصل کنید که نام میزبانی یا آدرس IP سرور monitoring شما به تنظیمات allowed_hosts در فایل پیکربندی NRPE اضافه شده است.
زمانی که همه میزبانها اضافه شدند، باید یک فایل برای هر سرور که میخواهید نظارت کنید، به صورت جداگانه بسازید: db1.cfg, app1.cfg, app2.cfg, و lb1.cfg. هر فایل باید شامل تعریف میزبان باشد که به نام میزبان و آدرس آن اشاره میکند (این آدرس میتواند نام میزبانی سرور یا آدرس IP آن باشد)
راهاندازی نظارت میزبان و سرویس
در ادامه فهرستی از مواردی که میتوان برای هر سرور مورد نظارت قرار داد را ارائه کردهایم. در مورد هر سرور، سرویسهای زیر را مورد نظارت قرار میدهیم:
- Ping
- SSH
- Current Load
- Current Users
- Disk Utilization
در ادامه تک تک این موارد را تنظیم میکنیم.
تعریف سرویسهای رایج
در راهنمای راهاندازی Nagios آن را طوری پیکربندی کردیم که به دنبال فایلهای cfg. در مسیر usr/local/nagios/etc/servers (یا /etc/icinga/objects/ برای Icinga) بگردد. برای این که همه چیز منظم و مرتب باشد یک فایل پیکربندی جدید Nagios برای سرویسهای رایج که میخواهیم مورد نظارت قرار دهیم ایجاد میکنیم و آن را «common.cfg» مینامیم. ابتدا فایل پیکربندی میزبان را باز میکنیم تا آن را ویرایش نماییم:
sudo vi /usr/local/nagios/etc/servers/common.cfg
تعریف سرویسهای زیر را به آن اضافه میکنیم و نام میزبانی هر یک از سرورها را که قبلاً در بخش تعریف میزبان ذکر کردیم، جایگزین میکنیم:
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description SSH
check_command check_ssh
notifications_enabled 0
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description Current Users
check_command check_nrpe!check_users
}
define service{
use generic-service
host_name db1,app1,app2,lb1
service_description Disk Utilization
check_command check_nrpe!check_hda1
}
فایل را ذخیره کرده و ببندید. اینک آماده هستیم تا سرویسهایی که خاص هر سرور هستند را تعریف کنیم. ابتدا از سرور پایگاه داده شروع میکنیم.
تعریف پروسه MySQL
تعریف کردن این پروسه دو بخش جداگانه برای سرور کلاینت دارد.
ایجاد دستور NRPE (روی کلاینت)
روی سرور پایگاه داده خود که db1 نام دارد، یک فایل جدید NRPE پیکربندی میکنیم. فایل پیکربندی NRPE جدید را که «commands.cfg» نام دارد باز کنید:
sudo vi /etc/nagios/nrpe.d/commands.cfg
تعریف دستور زیر را در آن وارد کنید:
command[check_mysqld]=/usr/lib/nagios/plugins/check_procs -c 1: -C mysqld
فایل را ذخیره کرده و خارج شوید. بدین ترتیب به NRPE اجازه میدهیم که پروسهای به نام mysqld را بررسی کرده و وضعیت بحرانی آن را در صورتی که کمتر از 1 پروسه با چنان نامی در اجرا بود، به ما گزارش دهد. پیکربندی NRPE را بارگذاری مجدد کنید:
sudo service nagios-nrpe-server reload
ایجاد تعریف سرویس (روی سرور)
اینک باید روی سرور Nagios که آن را monitoring نامیدهایم، یک سرویس جدید ایجاد کنیم که از NRPE برای اجرای دستور check_mysqld استفاده میکند.
فایلی که پیکربندی میزبان پایگاه داده در آن تعریف شده است، باز کنید. در مثال ما این فایل «db1.cfg» نام دارد:
sudo vi /usr/local/nagios/etc/servers/db1.cfg
در انتهای فایل تعریف سرویس را اضافه کنید (مطمئن شوید که مقدار host_name با نام میزبانی که تعریف کردهاید مطابقت دارد):
define service {
use generic-service
host_name db1
service_description Check MySQL Process
check_command check_nrpe!check_mysqld
}
فایل را ذخیره کرده و خارج شوید. بدین ترتیب Nagios برای استفاده از NRPE برای اجرای دستور check_mysqld روی سرو پایگاه داده پیکربندی میشود.
برای این که این تغییرات اعمال شوند باید Nagios را مجدداً بارگذاری کنید. با این حال ما قصد داریم ابتدا به بحث نظارت بر سرور آپاچی بپردازیم.
تعریف پروسه Apache
همانند بخش قبل این تعریف سرویس دو بخش کلاینت و سرور دارد.
ایجاد دستور NRPE (روی کلاینت)
در سرورهای اپلیکیشنتان که app1 و app2 نام دارند، یک دستور NRPE جدید ایجاد کنید. بدین منظور فایل پیکربندی NRPE را که «commands.cfg» نام دارد باز کنید:
sudo vi /etc/nagios/nrpe.d/commands.cfg
تعریف دستور زیر را به آن اضافه کنید:
command[check_apache2]=/usr/lib/nagios/plugins/check_procs -c 1: -w 3: -C apache2
فایل را ذخیره کرده و خارج شوید. بدین ترتیب به NRPE اجاره دادهایم که پروسهای به نام «apache2» را بررسی کرده و در مواردی که روی رایانه مربوطه هیچ پروسهای با این نام در حال اجرا نبود، یک وضعیت بحرانی و در صورتی که کمتر از سه پروسه با این نام در حال اجرا بود وضعیت هشدار را گزارش دهد.
بارگذاری مجدد پیکربندی NRPE:
sudo service nagios-nrpe-server reload
اطمینان حاصل کنید که این فرایند را روی هر تعداد سرور اپلیکیشن که دارید تکرار کردهاید.
ایجاد تعریف سرویس (روی سرور)
ما در این مرحله باید روی سرور Nagios که monitoring نام دارد یک سرویس جدید تعریف کنیم که از NRPE برای اجرای دستور check_apache2 کمک میگیرد. بدین منظور فایلی که میزبان اپلیکیشن را تعریف میکند باز کنید. در مثال ما این فایلها «app1.cfg» و «app2.cfg» نام دارند:
sudo vi /usr/local/nagios/etc/servers/app1.cfg
در انتهای فایل تعریف سرویس را اضافه کنید (مطمئن شوید که مقدار host_name با تعریف میزبان مطابقت دارد):
define service {
use generic-service
host_name app1
service_description Check Apache2 Process
check_command check_nrpe!check_apache2
}
فایل را ذخیره کرده و ببندید. بدین ترتیب Nagios طوری پیکربندی میشوند که دستور check_apache2 را روی سرورهای اپلیکیشن اجرا کند. اطمینان حاصل کنید که این فرایند را برای هر یک از سرورهای اپلیکیشن تکرار میکنید. برای این که این تغییرات اعمال شوند، باید Nagios بارگذاری کنید. با این حال ما در این مقاله به ادامه کار میپردازیم و نظارت بر پروسه HAProxy را نیز راهاندازی میکنیم.
تعریف پروسه HAProxy
همانند موارد قبل این مرحله دو بخش دارد: کلاینت و سرور.
ایجاد دستور NRPE (روی کلاینت)
روی سرور توزیع بار که lb1 نام دارد یک دستور جدید NRPE پیکربندی میکنیم. یک فایل پیکربندی جدید NRPE به نام «commands.cfg» باز کنید:
sudo vi /etc/nagios/nrpe.d/commands.cfg
تعریف دستور زیر را در آن اضافه کنید:
command[check_haproxy]=/usr/lib/nagios/plugins/check_procs -c 1: -C haproxy
فایل را ذخیره کرده و خارج شوید. بدین ترتیب به NRPE اجازه میدهیم که پروسهای به نام haproxy را بررسی کند و در مواردی که کمتر از 1 پروسه با این نام روی سرور در حال اجرا بود، وضعیت بحرانی را گزارش دهد. با دستور زیر پیکربندی NRPE را مجدداً بارگذاری کنید:
sudo service nagios-nrpe-server reload
اطمینان پیدا کنید که در صورت وجود سرورهای توزیع بار دیگر، این موارد را در مورد آنها نیز تکرار میکنید.
ایجاد تعریف سرویس (روی سرور)
در این مرحله روی سرور Nagios یا همان monitoring باید سرویس جدیدی تعریف کنیم که از NRPE برای اجرای دستور check_haproxy استفاده میکند. بدین منظور فایلی که نام میزبان سرور توزیع بار شما را تعریف میکند باز کنید. در این مثال فایل «lb1.cfg» نام دارد:
sudo vi /usr/local/nagios/etc/servers/lb1.cfg
در انتهای فایل تعریف زیر را اضافه کنید (اطمینان حاصل کنید که مقدار host_name با تعریف میزبان شما مطابقت دارد):
define service {
use generic-service
host_name lb1
service_description Check HAProxy Process
check_command check_nrpe!check_haproxy
}
بدین ترتیب Nagios طوری پیکربندی شده است که از NRPE برای اجرای دستور check_haproxy روی سرور توزیع بار استفاده کند. برای این که این تنظیمات اعمال شوند باید Nagios را مجدداً بارگذاری کنید.
بارگذاری مجدد پیکربندی Nagios
برای بارگذاری مجدد Nagios و پیادهسازی همه تغییراتی که روی پیکربندی آن ایجاد کردیم، باید دستور زیر را وارد کنید:
sudo service nagios reload
اگر هیچ خطای ساختاری در پیکربندی وجود نداشته باشد، کار ما پایان یافته است.
بررسی سرویسهای Nagios
در این مرحله باید مطمئن شویم که Nagios همه میزبانها و سرویسهایی که تعریف کردهایم را مورد نظارت قرار داده است. بدین منظور از طریق نام میزبانی یا آدرس IP عمومی Nagios (مانند http://monitoring.example.com/nagios/) به آن وصل شوید.
در منوی جانبی بر روی Services کلیک کنید. در این زمان به صفحهای میروید که شبیه زیر است:
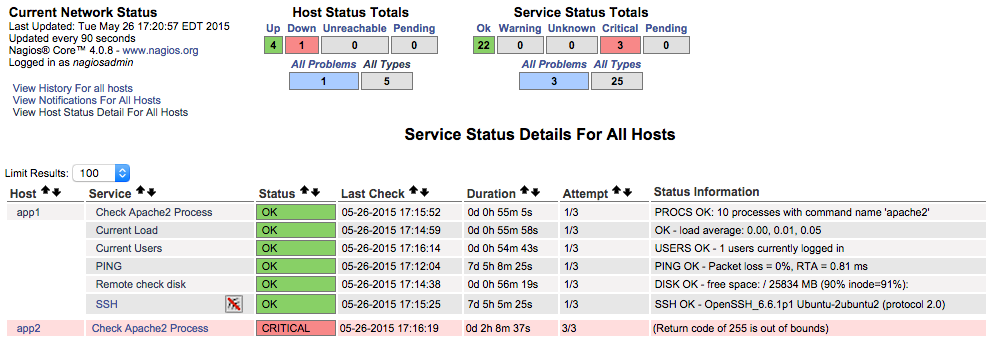
به طور معمول شما باید همه میزبانها و سرویسها را در وضعیت OK ببینید. در تصویر فوق میبینیم که در سرور app2 مشکلی وجود دارد، زیرا در طی آخرین بررسی وضعیت خاموش بوده است. اگر هر کدام از سرورهای شما در وضعیت OK نبودند، میتوانید آنها را اصلاح کنید. در مواردی که سرویسها همگی درست هستند، میتوانید پیکربندی Nagios را برای مشاهده خطاها بررسی کنید.
ملاحظات دیگر
مسلماً شما قصد دارید برای سرور نظارت خود نیز یک طرح بازیابی تهیه کنید و از فایلهای پیکربندی (/usr/local/nagios/etc) آن پشتیبان بگیرید. زمانی که پشتیبانگیری تنظیم شد، احتمالاً باید نظارت را برای سرویسهای دیگری مانند اطلاعرسانی ایمیلی نیز پیکربندی کنید.
سخن پایانی
اینک شما میتوانید وضعیت سرورها و سرویسها را با یک نگاه به داشبورد نظارتی خود ببینید. در صورت بروز هر گونه خرابی، سیستم نظارتی به شما کمک میکند که بفهمید کدام سرور یا سرویس به درستی کار نمیکند و بدین ترتیب زمان قطعی اپلیکیشن شما کاهش مییابد.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز ملاحظه کنید:
- مجموعه آموزشهای مهندسی نرم افزار
- طرح بازیابی (Recovery Plan) برای یک وب اپلیکیشن — راهنمای جامع
- ابزارها و راهکارهای مدیریت وبسایتها
- انتخاب پلتفرم مناسب برای ساخت اپلیکیشن — رایانه شخصی، وب، موبایل یا کراسپلتفرم
- نصب سرور باکولا (Bacula) روی اوبونتو ۱۴.۰۴ — از صفر تا صد
==