یادگیری ماشین چیست؟ – به زبان ساده

مفاهیم «یادگیری ماشین» (Machine Learning) در بسیاری از حوزههای تخصصی مثل بازارهای مالی، بازاریابی، اتومبیلهای خودران، سیستمهای توصیهگر، چتباتها، شبکههای اجتماعی، بازیهای کامپیوتری، امنیت سایبری و بسیاری از موارد دیگر کاربرد دارد. یادگیری ماشین یا همان ماشین لرنینگ یکی از مهمترین زیرشاخههای هوش مصنوعی به حساب میآید و با توجه به پیشرفت سریع این حوزه، افراد بسیاری میخواهند بدانند یادگیری ماشین چیست. بنابراین، در این نوشتار قصد داریم به این موضوع بپردازیم که یادگیری ماشین چیست و سعی شده است تا حد امکان به همه نکات مهم و موضوعات کلیدی پیرامون آن نیز پرداخته شود.
یادگیری ماشین زیرشاخهای از «هوش مصنوعی» (Artificial Intelligence | AI) است که به طور کلی به عنوان توانایی ماشین برای تقلید از رفتار هوشمند انسان تعریف میشود. از سیستمهای هوش مصنوعی و یادگیری ماشین برای پیادهسازی کارکردهای پیچیده در حل بسیاری از مسائل استفاده میشود. هدف هوش مصنوعی و یادگیری ماشین ایجاد مدلهای کامپیوتری است که مانند انسان دارای «رفتار هوشمندانه» هستند. برای مثال، تشخیص الگو در تصاویر، درک و پردازش متن به زبان انسان یا انجام عملی را در دنیای فیزیکی، همگی از مواردی هستند که ميتوان آنها را به عنوان رفتار هوشمندانه در نظر گرفت.
یادگیری ماشین چیست؟
یادگیری ماشین شاخهای از هوش مصنوعی (AI) و علوم کامپیوتر به حساب میآید که تمرکز آن بر استفاده از دادهها و الگوریتمها برای تقلید از روش یادگیری انسانها و بهبود عملکرد خود در طول زمان با یادگیری بیشتر است. طی چند دهه گذشته، پیشرفتهای تکنولوژیکی در زمینه ذخیرهسازی و قدرت پردازش برخی از محصولات نوآورانه مبتنی بر یادگیری ماشین، مانند موتور توصیهگر، نتفلیکس و خودروهای خودران را ممکن ساخته است. یادگیری ماشین در دهه 1950 توسط آرتور ساموئل پیشگام هوش مصنوعی به این صورت تعریف شد:
«یادگیری ماشین، رشته مطالعاتی است که به کامپیوترها، بدون آنکه صریحاً برنامهنویسی شوند، قابلیت یادگیری را میدهد». اما در برخی موارد، نوشتن برنامهای که ماشین باید آن را اجرا کند، زمانبر یا غیرممکن است، در حالی که انسان میتواند این کار را به راحتی انجام دهد.

روشهای یادگیری ماشین در حوزه رو به رشد علم داده استفاده و کاربرد بسیاری دارند. الگوریتمهای یادگیری ماشین با استفاده از روشهای آماری، برای طبقهبندی یا پیشبینی و کشف بینشهای کلیدی در پروژههای «داده کاوی» (Data Mining) آموزش داده میشوند. به طور خلاصه، داده کاوی شامل یادگیری ماشین به همراه بانک اطلاعاتی است. بینشهای کسب شده، متعاقباً تصمیمگیری را در برنامهها و کسبوکارها هدایت میکنند و به طور ایدهآل بر معیارهای رشد سازمانها تأثیر میگذارند. با ادامه گسترش و رشد دادههای بزرگ، تقاضای بازار برای دانشمندان داده و مهندسان یادگیری ماشین به میزان زیادی افزایش یافته است؛ از این متخصصان خواسته میشود تا به شناسایی مرتبطترین چالشها و مسائل تجاری پرداخته و نسبت به حل آنها با استفاده از روشهای یادگیری ماشین اقدام کنند.
الگوریتمهای یادگیری ماشین معمولاً با استفاده از چارچوبهایی ایجاد میشوند که توسعه راهحل مسائل را تسریع میکنند. تفاوت بین ML (مخفف Machine Learning) و AI (مخفف Artificial Intelligence) اغلب به اشتباه درک میشود؛ در این خصوص باید گفت، در یادگیری ماشین، آموزش بر اساس مشاهدات گذشته انجام و پیشبینی مطلوب حاصل میشود، در حالی که هوش مصنوعی دلالت بر «عامل» دارد؛ این عامل هوشمند با محیط در تعامل است و در نتیجه از محیط یاد میگیرد و اقداماتی را انجام میدهد. اقدامات انجام شده توسط عامل هوشمند باید احتمال موفقیتآمیز بودن رسیدن به اهداف را به حداکثر برسانند.

الگوریتمهای یادگیری ماشین بر اساس «دادههای آموزشی» (Training Data) مدلسازی را انجام میدهند، به طوری که امکان پیشبینی یا تصمیمگیری بدون برنامهنویسی صریح ممکن شود. روشها و محاسبات آماری نقش بسیار مهمی در یادگیری ماشین دارند و با استفاده از این روشها مثلاً میتوان به کمک کامپیوتر پیشبینی انجام داد؛ البته یادگیری ماشین تنها به استفاده از روشهای آماری محدود نمیشود. بخش دیگری از یادگیری ماشین بر مطالعه «بهینهسازی ریاضیاتی» (Mathematical Optimization) متمرکز است و روشها، نظریات و حوزههای کاربردی در این زمینه را مورد بحث قرار میدهد.
چه اقداماتی باید پیش از شروع عملیات یادگیری ماشین انجام شود؟
در یادگیری ماشین برای آموزش مدل، از دادهها استفاده میشود. بنابراین قبل از بهکارگیری یادگیری ماشین بایستی عملیات زیر انجام گیرد.
- دادهها جمعآوری شوند: در مرحله نخست، دادهها شامل اعداد، عکس و متن مثل تراکنشهای بانکی، تصاویر افراد، اقلام خرید، دادههای سری زمانی، گزارشهای فروش و غیره از منابع مختلفی جمعآوری میشود. هر چقدر حجم دادههای جمعآوری شده بیشتر باشد، امکان آموزش بهتر برای مدل فراهم خواهد شد.
- دادهها پیش پردازش و پاکسازی شوند: دادههای جمعآوری شده احتمالا برای ورود به الگوریتمهای یادگیری ماشین مناسب نیستند، چرا که این دادهها حاوی نویز و یا فاقد مقدار هستند (که اصطلاحا به آن دادههای گم شده یا Missing Values گفته میشود). دادهها در این مرحله با روشهای از پیشتعریف شدهای، پاکسازی میشوند بهطوری که بتوان آنها را به عنوان دادههای آموزشی وارد الگوریتمهای یادگیری ماشین کرد.

نحوه پیاده سازی الگوریتم های یادگیری ماشین چگونه است؟
پس از پیش پردازش دادهها، برنامهنویسان یک مدل یادگیری ماشین را انتخاب و دادهها را وارد مدل انتخاب شده میکنند، به طوری که مدل خود را برای یافتن الگوها یا پیشبینی آموزش دهد. با گذشت زمان، فرد برنامهنویس میتواند مدل را اصلاح کند. مثلا با تغییر پارامترهای آن، مدل را به سمت نتایج دقیقتر سوق دهد. برخی از دادهها از مجموعه دادههای آموزشی جداسازی میشوند تا به عنوان دادههای ارزیابی برای آزمایش دقت عملکرد مدل مورد استفاده قرار بگیرند.
در مرحله تست یا همان ارزیابی، میزان دقت خروجی مدل یادگیری ماشین با دریافت ورودیهای جدید بررسی میشود. نتیجه مدلی است که میتواند در آینده با مجموعه دادههای مختلف مورد استفاده قرار گیرد. عملکرد یک سیستم یادگیری ماشین میتواند توصیفی، مبتنی بر پیشبینی یا تجویزی باشد.
- توصیفی، به این معنی که سیستم برای توضیح آنچه اتفاق افتاده است، از دادهها استفاده میکند.
- مبتنی بر پیشبینی، به این معنی که سیستم برای پیشبینی آنچه اتفاق خواهد افتاد، از دادهها استفاده میکند.
- تجویزی، به این معنی است که سیستم برای ارائه پیشنهاداتی در مورد اقداماتی که باید انجام گیرد، از دادهها استفاده میکند.

زیربخش های یادگیری ماشین کدامند ؟
یادگیری ماشین در حالت کلی به زیربخشهای مختلفی تقسیمبندی میشود اما مهمترین رویکردها در یادگیری ماشین، شامل موارد زیر میشوند:
- «یادگیری نظارت شده» (Supervised Learning)
- «یادگیری بدون نظارت» (Unsupervised Learning)
- «یادگیری نیمه نظارتی» (Semi-Supervised Learning)
- «یادگیری تقویتی» (Reinforcement Learning)
در ادامه به معرفی و شرح هر کدام از این موارد در زیربخشهایی جداگانه پرداخته شده است.
یادگیری با نظارت در یادگیری ماشین چیست ؟
در این روش مدلها با مجموعه دادههای برچسبگذاری شده آموزش داده میشوند و در طول زمان یاد خواهند گرفت و توسعه خواهند یافت. به عنوان مثال، یک الگوریتم با تصاویر سگها و تصاویر چیزهای دیگر، که همه این تصاویر توسط انسان برچسبگذاری شدهاند، آموزش داده میشود و در نتیجه قادر به بازشناسی و تشخیص تصویر سگ جدید خواهد بود و میتواند آن را از دیگر تصاویر متمایز سازد.
امروزه یادگیری ماشین با نظارت رایجترین روش مورد استفاده در یادگیری ماشین است. یادگیری با نظارت خود به زیربخشهایی تقسیمبندی میشود که در ادامه به مهمترین آنها اشاره شده است.
- «دستهبندی» (Classification) که مهمترین کاربردهای آن شامل «شناسایی هویت جعلی» (Fake Identity Recognition)، «دستهبندی تصاویر» (Image Classification)، «حفظ مشتریان» (Customer Retention)، «تشخیصهای پزشکی» (Medical Diagnoses) و غیره است
- «رگرسیون» (Regression) که از کاربردهای مهم آن میتوان به پیشبینی رشد جمعیت، پیشبینی بازار، پیشبینی وضعیت هوا و غیره اشاره کرد.

یادگیری بدون نظارت در یادگیری ماشین چیست ؟
این الگوریتمها به دنبال الگوهای موجود در دادههای بدون برچسب هستند. یادگیری ماشین بدون نظارت میتواند الگوها یا روندهای پنهان را پیدا کنند. برای مثال، یک برنامه یادگیری ماشینی بدون نظارت میتواند دادههای فروش آنلاین را بررسی کند و انواع مختلفی از مشتریان خریدار را شناسایی کند. یادگیری بدون نظارت خود به زیربخشهایی تقسیمبندی میشود که در ادامه به مهمترین آنها اشاره شده است.
- «خوشهبندی» (Clustering) که کاربردهای مهم آن در «سیستمهای توصیهگر» (Recommender Systems)، «بازاریابی هدفمند» (Targeted Marketing)، «بخشبندی مشتریان» (Customer Segmentation) و غیره است.
- «کاهش ابعاد» (Dimensionality Reduction) که کاربردهای مهم آن در «مصورسازی دادههای حجیم» (Big Data Visualization)، «فشردهسازی معنادار» (Significant Compression)، «کشف ساختار» (Structure Discovery)، «کاهش ویژگی» (Feature Reduction) و دیگر موارد است.
یادگیری نیمه نظارتی در ماشین لرنینگ چیست ؟
این الگو بین یادگیری بدون نظارت (بدون هیچ گونه داده آموزشی برچسب گذاری شده) و یادگیری نظارت شده (با دادههای آموزشی کاملاً برچسب گذاری شده) قرار دارد. برخی از نمونههای آموزشی فاقد برچسبهای آموزشی هستند، با این حال بسیاری از محققان یادگیری ماشین دریافتهاند که دادههای بدون برچسب، زمانی که همراه با تعداد کمی از دادههای برچسبگذاری شده استفاده شوند، بهبود قابل توجهی در دقت یادگیری ایجاد خواهد شد.

یادگیری تقویتی در یادگیری ماشین چیست ؟
در یادگیری تقویتی ماشینها از طریق آزمون و خطا و با ایجاد یک سیستم پاداش آموزش داده میشوند تا بهترین اقدام را انجام دهند. الگوریتم با مشخص کردن اینکه ماشین چه زمانی تصمیمات درستی گرفته است به آن کمک میکند در طول زمان یاد بگیرد و بهتر است چه اقداماتی را انجام دهد.

از یادگیری تقویتی در چه حوزه هایی استفاده می شود؟
یادگیری تقویتی در بسیاری از رشتهها و زمینههایی مورد مطالعه قرار میگیرد که در ادامه به برخی از آنها اشاره شده است.
- «نظریه بازی» (Game Theory)
- «نظریه کنترل» (Control Theory)
- «تحقیق در عملیات» (Operations Research)
- «نظریه اطلاعات» (Information Theory)
- «بهینهسازی مبتنی بر شبیهسازی» (Simulation-based optimization)
- «سیستمهای چند عاملی» (Multi-Agent Systems)
- «آمار» (Statistics)
- «الگوریتم ژنتیک» (GA | Genetic Algorithms)
در یادگیری ماشین، محیط معمولاً بر اساس «فرایند تصمیمگیری مارکوف» (MDP | Markov Decision Process) مشخص یا تعیین میشود. بسیاری از الگوریتمهای یادگیری تقویتی، از روشهای «برنامهریزی پویا» (Dynamic Programming) استفاده میکنند. الگوریتمهای یادگیری تقویتی فاقد یک مدل ریاضی دقیق MDP هستند و زمانی استفاده میشوند که بهکارگیری مدلهای دقیق ممکن نباشند. از دیگر کاربردهای الگوریتمهای یادگیری تقویتی، استفاده آن در وسایل نقلیه خودران و یادگیری بازی در مقابل حریف انسانی است.
در یادگیری ماشین روشهای دیگری نیز توسعه یافتهاند که در دستهبندیهای بیان شده جای نمیگیرند و همینطور روشهایی مثل «مدلسازی موضوعی» (Topic Modeling) و «فرا یادگیری» (Meta Learning) وجود دارند که همزمان میتوان آنها را در چندین زیرشاخه از یادگیری ماشینی قرار داد.
معرفی فیلم های آموزش یادگیری ماشین و داده کاوی

مجموعههای آموزشی فرادرس، دورههای ویدیویی هستند که یک موضوع آموزشی را از سطح مقدماتی تا پیشرفته و با در نظر گرفتن جوانب مختلف نظری و عملیاتی پوشش میدهد. یادگیری ماشین و مباحث وابسته به آن امروزه چه در پژوهش و چه در صنعت از مباحث پویا و مورد نیاز به حساب میآید. دورههای آموزش داده کاوی و یادگیری ماشین یکی از این مجموعههای آموزشی است که در پلتفرم فرادرس و برای رفع این نیاز منتشر شده است. این مجموعه شامل آموزش سرفصلهای دانشگاهی و همچنین آموزش برنامهنویسی با استفاده زبانهایی چون پایتون، متلب، سیشارپ و غیره به صورت عملیاتی و کاربردی با هدف آمادهسازی برای انجام پژوهش و یا ورود به بازار کار است. در تصویر بالا تنها چند نمونه از این آموزشها آورده شده است.
- برای شروع یادگیری داده کاوی و یادگیری ماشین و دسترسی به تمام دورههای این مجموعه + اینجا کلیک کنید.
روش های مهم و رایج مورد استفاده در یادگیری ماشین
در ادامه برخی دیگر از روشها و رویکردها در یادگیری ماشین را بیشتر مورد بررسی قرار میدهیم.
کاهش ابعاد در یادگیری ماشین چیست ؟
«کاهش بعد» (Dimension Reduction) فرآیندی است برای کاهش تعداد متغیرهای تصادفی مورد بررسی که به کمک آن مجموعهای از متغیرهای اصلی به دست میآید. روشهای کاهش ابعاد در حالت کلی عملیات «انتخاب ویژگی» (Feature Selection) یا استخراج ویژگی را پیادهسازی میکنند. یکی از روشهای رایج کاهش ابعاد، تحلیل مؤلفههای اصلی (Principal Component Analysis | PCA) است.
به طور نظری، PCA یک روش آماری است و کاهش ابعاد را با تبدیل خطی دادهها به یک سیستم مختصات جدید انجام میدهد. بسیاری از مطالعات از دو مولفه اصلی اول برای ترسیم دادهها در دو بعد و شناسایی مصور خوشهها استفاده میکنند. تحلیل مولفههای اصلی در بسیاری از زمینهها مانند ژنتیک جمعیت، «مطالعات میکروبیوم» (Microbiome Studies) و «علوم جوی» (Atmospheric Science) کاربرد دارد.

تشخیص ناهنجاری در یادگیری ماشین چیست ؟
در داده کاوی، «تشخیص ناهنجاری» (Anomaly Detection)، که به عنوان تشخیص «داده پرت» (Outlier Data) نیز شناخته میشود، شناسایی موارد، رویدادها یا مشاهداتی از مجموعه دادهها است که در الگوهای موجود جای نمیگیرند. به طور معمول، موارد ناهنجار نشان دهنده موضوعاتی مانند «کلاهبرداری بانکی» (Bank Fraud)، «نقص ساختاری» (Structural Defect)، «مشکلات پزشکی» (Medical Problems) یا «اشتباهات در یک متن» (Errors in a Text) است. ناهنجاریها بهعنوان موارد «پرت» (Outliers)، «بدیع» (Novelties)، «نویز» (Noise)، «انحرافات» (Deviations) و «استثنائات» (Exceptions) نیز شناخته میشوند.

در زمینه سوءاستفاده و «تشخیص نفوذ شبکه» (Network Intrusion Detection)، موارد مورد توجه اغلب کمیاب نیستند، بلکه موارد غیرمنتظرهای هستند که فعالیتی غیرعادی و متفاوت از خود نشان میدهند. چنین الگویی در تعریف آماری رایج از داده پرت قرار نمیگیرد.
بسیاری از روشهای تشخیص داده پرت (به ویژه، الگوریتمهای بدون نظارت) در تشخیص دادههای ناهنجار با شکست مواجه میشوند. البته الگوریتمهای تحلیل خوشه ممکن است بتوانند ریز خوشههای تشکیل شده توسط این الگوها را تشخیص دهند.
سه دسته کلی از روشهای تشخیص ناهنجاری وجود دارد که در ادامه به آنها اشاره شده است.
- روشهای تشخیص ناهنجاری بدون نظارت: ناهنجاریها در مجموعه دادههای آزمایشی بدون برچسب با این فرض شناسایی میشوند که اکثر نمونه دادهها نرمال هستند و نمونههایی جستجو میشوند که کمترین تناسب را با بقیه مجموعه دادهها دارند.
- روشهای تشخیص ناهنجاری نظارت شده: به مجموعه دادهای نیاز دارند که بهصورت «نرمال» و «غیر نرمال» برچسبگذاری شده است و شامل آموزش کلاسیفایر است.
- روشهای تشخیص ناهنجاری نیمه نظارت شده: مدلی را میسازند که نشاندهنده رفتار نرمال از یک مجموعه دادههای آموزشی نرمال است و سپس احتمال تولید یک نمونه تستی توسط مدل را آزمون میکند.
قوانین انجمنی در یادگیری ماشین چیست ؟
یادگیری قوانین انجمنی یک روش یادگیری ماشین مبتنی بر قانون، برای کشف روابط بین متغیرها در پایگاه دادههای بزرگ است. یادگیری ماشین مبتنی بر قانون، یک اصطلاح کلی برای هر روش یادگیری ماشین است که بهمنظور ذخیرهسازی، دستکاری یا اعمال دانش، «قوانین» را شناسایی میکند، یاد میگیرد یا تکامل میدهد. مشخصه اصلی یک الگوریتم یادگیری ماشین مبتنی بر قانون، شناسایی و استفاده از مجموعهای از قوانین رابطهای است که دانش کشف شده را نشان میدهد.
رویکردهای یادگیری ماشین مبتنی بر قانون شامل سه دسته «سیستمهای طبقهبندی کننده یادگیری» (Learning Classifier Systems)، «یادگیری قوانین انجمنی» (Association Rule learning) و «سیستمهای ایمنی مصنوعی» (Artificial Immune Systems) میشود. قوانین انجمنی، اولین بار، بر اساس مفهوم قوانین قوی، برای کشف نظم بین محصولات در دادههای تراکنش در مقیاس بزرگ که توسط دستگاههای POS در سوپرمارکتها ثبت شده بود، معرفی شد. مثلا قانون {پیاز، سیبزمینی}=>{گوشت}، بیانکننده این قانون است که اگر مشتری در سبد خرید خود سیبزمینی و پیاز را داشته باشد، احتمالا گوشت را نیز خرید خواهد کرد.

چنین اطلاعاتی میتواند به عنوان مبنایی برای تصمیمگیری در مورد فعالیتهای بازاریابی مانند قیمتگذاری تبلیغاتی یا جایگاهیابی محصول مورد استفاده قرار گیرد. قوانین انجمنی علاوه بر تجزیه و تحلیل سبد بازار، امروزه در زمینههایی مثل «کاوش استفاده از وب» (Web Usage Mining)، تشخیص نفوذ، «تولید پیوسته» (Continuous Production) و بیوانفورماتیک استفاده میشود. برخلاف «دنباله کاوی | کاوش الگوهای متوالی» (Sequential Mining)، یادگیری قوانین انجمنی معمولاً ترتیب اقلام را چه در یک تراکنش و چه در بین تراکنشها در نظر نمیگیرد.
سیستمهای طبقهبندیکننده یادگیری (LCS) خانوادهای از الگوریتمهای یادگیری ماشین مبتنی بر قانون هستند که برای انجام یادگیری نظارتشده، یادگیری تقویتی یا یادگیری بدون نظارت، یک مؤلفه اکتشافی، مثلا الگوریتم ژنتیک را با یک مؤلفه یادگیری ترکیب میکنند. آنها به دنبال شناسایی مجموعهای از قوانین وابسته به زمینه هستند که بهمنظور پیشبینی، دانش را به صورت «تکهای» (Piecewise) ذخیره میکنند و به کار میبرند.
پردازش زبان طبیعی
«پردازش زبان طبیعی» (Natural Language Processing | NLP) زمینهای از یادگیری ماشین است که در آن ماشینها یاد میگیرند که زبان طبیعی را همانطور که توسط انسانها صحبت و نوشته میشود، درک کنند. دادههای ورودی در این نوع الگوریتمها نه از نوع دادههای معمول ساختار یافته بلکه از نوع دادههای متنی و صوتی وابسته به زبان طبیعی است. پردازش زبان طبیعی به ماشینها اجازه میدهد تا زبان را بازشناسی کنند، آن را دریابند، به آن پاسخ دهند، متن جدیدی ایجاد کنند و قادر به ترجمه باشند. پردازش زبان طبیعی فناوریهای آشنا مانند چتباتها و دستیارهای دیجیتالی مانند سیری یا الکسا را امکانپذیر میسازد.
مدل در یادگیری ماشین چیست ؟
پیادهسازی یادگیری ماشین شامل ایجاد مدلی است که از دادههای آموزشی یاد میگیرد، سپس میتواند دادههای جدید را بهمنظور پیشبینی پردازش کند. انواع مختلفی از مدلها در سیستمهای یادگیری ماشین مورد استفاده و تحقیق قرار گرفتهاند که در ادامه به برخی از مهمترین آنها میپردازیم.

رگرسیون در یادگیری ماشین چیست ؟
رگرسیون روشی برای تعیین رابطه آماری بین یک متغیر وابسته و یک یا چند متغیر مستقل است. تغییرات متغیر مستقل با تغییرات متغیرهای مستقل مرتبط است. تحلیل رگرسیون طیف وسیعی از روشهای آماری را برای تخمین رابطه بین متغیرهای ورودی و ویژگیهای مرتبط با آنها در بر میگیرد.
رایجترین شکل رگرسیون، رگرسیون خطی است. رگرسیون خطی رابطه خطی بین متغیر وابسته و یک یا چند متغیر مستقل را با استفاده از بهترین خط مستقیم پیدا میکند. به طور کلی، یک مدل خطی به سادگی با محاسبه مجموع وزنی ویژگیهای ورودی، به اضافه ثابتی به نام ترم بایاس که به آن «عرض از مبدا» (Intercept) نیز گفته میشود، عمل پیشبینی را انجام میدهد. در این روش، متغیر وابسته پیوسته، متغیر(های) مستقل میتواند پیوسته یا گسسته باشد. از نظر ریاضی، میتوان معادله رگرسیون خطی را به صورت زیر بیان کرد.
$$y=theta_0+theta_1x_1+theta_2x_2+...+theta_nx_n$$
که در این معادله داریم:
- $$y$$ برابر با مقدار پیشبینی شده
- $$n$$ برابر با تعداد کل ویژگیهای ورودی
- $$x_i$$ برابر با ویژگی ورودی برای مقدار $$i^{th}$$
- $$theta_i$$ پارامترهای مدل
- $$theta_۰$$ برابر با بایاس
- $$theta_1\, theta_2\, … theta_n$$ برابر با ضرایب
هر ضریب نشان دهنده سهم متغیرهای ورودی در تعیین بهترین خط به حساب میآید و مانند یک دکمه تنظیمگر عمل میکند. ضریب با توجه به ویژگی ورودی مربوطه تغییر میکند و باعث تغییر در مقدار نهایی میشود.
بایاس، انحرافی است که به معادله خط $$y = mx$$ و برای پیشبینیهایی دقیقتر افزوده میشود. ما باید بایاس را تنظیم کنیم تا موقعیت خطی که میتواند برای دادههای مفروض مناسبتر باشد، بهینه شود.

شبکههای عصبی مصنوعی در یادگیری ماشین چیست ؟
«شبکههای عصبی مصنوعی» (Artificial Neural Networks) متشکل از نورونهای مصنوعی است که به طور مفهومی از نورونهای بیولوژیکی الهام گرفته شدهاند. نورونها معمولاً در چندین لایه سازماندهی میشوند. نورونهای یک لایه فقط به نورونهای لایههایی که بلافاصله قبل و بلافاصله بعد از آن لایه قرار دارد متصل میشوند. لایهای که دادهها را دریافت میکند لایه ورودی و لایهای که نتیجه نهایی را تولید میکند لایه خروجی نام دارد. لایههای مابین لایههای ورودی و خروجی، لایههای مخفی نامیده میشوند.
یادگیری شامل بهروزرسانی وزنها در شبکه برای برای بهبود دقت نتیجه است که این عملیات با در نظر گرفتن مشاهدات نمونه همراه است و با به حداقل رساندن خطاهای مشاهده شده انجام میشود. یادگیری زمانی همگرا میشود که بررسی مشاهدات اضافی به طور مفید، میزان خطا را کاهش نمیدهد. حتی پس از یادگیری، نرخ خطا معمولاً به صفر نمیرسد. اگر پس از یادگیری، میزان خطا بسیار بالا باشد، معمولاً شبکه باید دوباره طراحی شود.
یادگیری عملاً با تعریف یک تابع هزینه انجام میشود که به طور دورهای در طول یادگیری ارزیابی میشود و تا زمانی که خروجی آن رو به کاهش باشد، یادگیری ادامه خواهد داشت. هزینه یک آماره است که مقدار آن تقریب زده میشود. خروجیها به صورت عددی هستند، بنابراین وقتی خطا کم است، تفاوت بین خروجی و پاسخ صحیح کم خواهد بود. یادگیری تلاش میکند تا مجموع تفاوتهای مشاهدات را کاهش دهد.

ماشینهای بردار پشتیبان در یادگیری ماشین چیست ؟
«ماشین بردار پشتیبان» (Support Vector Machine) که به عنوان شبکه بردار پشتیبان نیز شناخته میشود، مجموعهای از روشهای یادگیری نظارت شده است که برای طبقهبندی و رگرسیون استفاده میشوند. یک الگوریتم آموزشی SVM یک طبقهبندیکننده خطی، باینری و غیر احتمالی است، اگرچه روشهایی برای استفاده از SVM در یک تنظیمات طبقهبندی احتمالی نیز وجود دارد. علاوه بر انجام طبقهبندی خطی، SVMها میتوانند به طور موثر یک طبقهبندی غیرخطی را با استفاده از آنچه که ترفند هسته نامیده میشود، انجام دهند، و به طور ضمنی ورودیهای خود را در فضاهای ویژگی با ابعاد بالا نگاشت میکنند.
SVM در مقایسه با الگوریتمهای جدیدتر مانند شبکههای عصبی، دو مزیت اصلی سرعت بالاتر و عملکرد بهتر با تعداد محدود نمونه را دارند. این باعث میشود که الگوریتم SVM برای مسائل طبقهبندی متن بسیار مناسب باشد، که در آن مجموعه دادهای با چند هزار نمونه برچسب گذاری شده معمول است. هدف الگوریتم ماشین بردار پشتیبان یافتن یک «ابر صفحه» (Hyperplane) در یک فضای N بعدی است که به طور جداگانه نقاط داده را طبقهبندی میکند. نزدیکترین نقاط داده در دو طرف ابر صفحه، بردارهای پشتیبان نامیده میشوند. بردارهای پشتیبان بر موقعیت و جهتگیری هایپرپلین تأثیر میگذارند و بنابراین به ساخت SVM کمک میکنند.
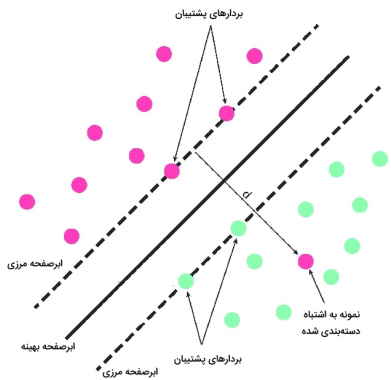
مزایای ماشین بردار پشتیبان
- هنگامی که یک حاشیه تفکیک قابل توجه بین کلاسها وجود داشته باشد، ماشین بردار پشتیبان یک الگوریتم برتر به حساب میآید.
- در فضاهای با ابعاد بالا، کارایی بیشتری دارد.
- در مواردی که تعداد ابعاد بزرگتر از تعداد نمونهها باشد موثر است.
درخت تصمیم در یادگیری ماشین چیست ؟
«درخت تصمیم» (Decision Tree) یک روش یادگیری ناپارامتریک با نظارت است که برای طبقهبندی و برای رگرسیون استفاده میشود. هدف ایجاد مدلی است که با یادگیری قوانین تصمیمگیری ساده استنتاج شده از ویژگیهای داده، ارزش متغیر هدف را پیشبینی کند. یک درخت را میتوان به عنوان یک تقریب ثابت «تکهای» (Piecewise) مشاهده کرد. هرچه درخت عمیقتر باشد، قوانین تصمیمگیری پیچیدهتر و مدل مناسبتر است.
درختی که در آن متغیر هدف میتواند مجموعهای از مقادیر گسسته بگیرد، درختان طبقهبندی نامیده میشوند. در این ساختارهای درختی، برگها نشاندهنده برچسبهای کلاس هستند و شاخهها نشاندهنده ترکیبی از ویژگیهایی هستند که به آن برچسبهای کلاس منتهی میشوند. درختهای تصمیمی که در آنها متغیر هدف میتواند مقادیر پیوسته (اعداد حقیقی) بگیرد، درختهای رگرسیون نامیده میشوند. در تجزیه و تحلیل تصمیم میتوان از درخت تصمیم برای نمایش مصور و صریح تصمیمات و تصمیمگیری استفاده کرد.
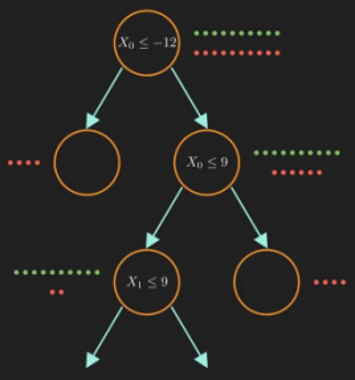
مزایای درخت تصمیم در ماشین لرنینگ
برخی از مزیتهایی که این رویکرد یادگیری ماشینی به همراه دارد در زیر فهرست شده است.
- درک و تفسیر آن ساده است. درختان را میتوان مصور ساخت.
- نیاز به آمادهسازی دادهها در این روش نسبت به دیگر الگوریتمها کم است. در سایر روشها اغلب نیاز به نرمالسازی دادهها وجود دارد، متغیرهای ساختگی باید ایجاد شوند و دادههای فاقد مقدار، حذف شوند.
- هزینه استفاده از درخت (برای پیشبینی دادهها) از نظر تعداد نقاط داده مورد استفاده برای آموزش درخت، لگاریتمی است.
- قادر به مدیریت دادههای عددی و رستهای است.
- درخت قادر به حل مسائل با چند خروجی است.
- از مدل جعبه سفید استفاده میکند. به این معنی که اگر یک موقعیت معین در یک مدل قابل مشاهده باشد، توضیح این شرط به راحتی با منطق بولی توضیح داده میشود. در مقابل، در مدل جعبه سیاه، مثل شبکه عصبی مصنوعی، تفسیر نتایج ممکن است دشوارتر باشد.
- امکان اعتبارسنجی مدل با استفاده از آزمونهای آماری وجود دارد. این امر باعث میشود که «قابلیت اطمینان» (Reliability) مدل در نظر گرفته شود.
- عملکرد خوبی دارد حتی اگر مفروضات آن تا حدی توسط مدل واقعی که دادهها از آن تولید شده اند نقض شود.
معایب درخت تصمیم در ماشین لرنینگ
در ادامه به برخی از ضعفهای درخت تصمیم اشاره شده است.
- درخت تصمیم ممکن است مدلهای بیش از حد پیچیدهای ایجاد کنند که مدل دادهها را به خوبی تعمیم نمیدهند. که به این اتفاق، «بیش برازش» (Overfitting) میگویند. مکانیسمهایی مانند هرس، تنظیم حداقل تعداد نمونه مورد نیاز در یک گره برگ یا تنظیم حداکثر عمق درخت برای جلوگیری از این مشکل ضروری است.
- درختهای تصمیم میتوانند ناپایدار باشند، زیرا تغییرات کوچک در دادهها ممکن است منجر به تولید درخت کاملاً متفاوتی شود. این مشکل با استفاده از درختهای «جمعی» (Ensemble) کاهش مییابد.
- در صورت تسلط برخی کلاسها، درخت تصمیم ممکن است دچار اریبی شود. بنابراین توصیه میشود قبل از برازش با درخت تصمیم، مجموعه داده را متعادل کنید.

شبکههای بیزین در یادگیری ماشین چیست ؟
یک «دستهبند نایو بیز» (Naive Bayes Classifier) که به آن «شبکه بیزی» (Bayesian Network) و «شبکه باور» (Belief Network) هم گفته میشود، یکی از روشهای یادگیری ماشین برای حل مسائلی است که دارای عدم قطعیت هستند. شبکه بیزی یک مدل گرافیکی احتمالی است که مجموعهای از متغیرها و وابستگیهای شرطی آنها را با استفاده از یک گراف غیرمدور جهتدار (DAG) نشان میدهد. شبکههای بیزی احتمالی هستند، زیرا این شبکهها از یک توزیع احتمال ساخته شدهاند و همچنین از نظریه احتمال برای پیشبینی و تشخیص ناهنجاری استفاده میکنند.
کاربردهای شبکه بیزین در دنیای واقعی ماهیت احتمالی دارند و در زمینههای مختلفی از جمله تشخیص ناهنجاری، تشخیص پزشکی، بینش خودکار، استدلال، پیشبینی «سریهای زمانی» (Time Series) و تصمیمگیری در شرایط عدم قطعیت استفاده میشوند. شبکه بیزی از دو بخش تشکیل شده است.
- گراف غیرمدور جهتدار
- جدول احتمالات مشروط
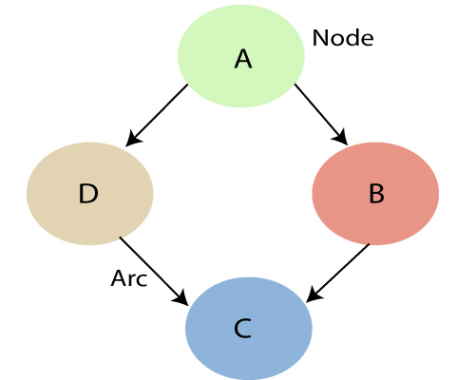
گراف شبکه بیزی از گرهها و یالهای جهتدار تشکیل شده است که به مفهوم هر یک در زیر اشاره شده است.
- گره: مربوط به متغیرهای تصادفی است و این متغیر میتواند پیوسته یا گسسته باشد.
- یال جهتدار: نشان دهنده رابطه علی یا احتمالات شرطی بین متغیرهای تصادفی است و گرهها را به هم متصل میکند. این پیوندها نشان میدهد که یک گره مستقیماً بر گره دیگر تأثیر میگذارد و اگر پیوند مستقیم وجود نداشته باشد به این معنی است که گرهها از یکدیگر مستقل هستند.
در گراف زیر C ،B ،A و D متغیرهای تصادفی هستند. مطابق با این گراف، گره A والد گره B به حساب میآیدو گره C مستقل از گره A است. هر گره در شبکه بیزی دارای توزیع احتمال شرطی (P(Xi | Parent(Xi) است که تأثیر والد را بر آن گره تعیین میکند. شبکه بیزی مبتنی بر «توزیع احتمال مشترک» (Joint Probability Distribution) و احتمال شرطی است.
الگوریتم ژنتیک در یادگیری ماشین
در علوم کامپیوتر و تحقیقات در عملیات، الگوریتم ژنتیک (GA) یک الگوریتم فراابتکاری الهام گرفته از فرآیند انتخاب طبیعی است که به کلاس بزرگتر «رایانش تکاملی» (Evolutionary Computation) تعلق دارد. الگوریتمهای ژنتیک معمولاً برای تولید راهحلهای با کیفیت بالا برای مسائل بهینهسازی و جستجو با تکیه بر عملگرهای الهامگرفتهشده از علوم زیستشناسی مانند آمیزش، جهش و انتخاب استفاده میشوند. برخی از نمونههای کاربردهای GA شامل بهینهسازی درختهای تصمیم برای عملکرد بهتر، حل پازل سودوکو، بهینهسازی فراپارامتر و غیره است.
در یک الگوریتم ژنتیک، جمعیتی از راهحلهای کاندید (به نام افراد، موجودات، ارگانیسمها یا فنوتیپها) برای یک مسئله بهینهسازی به سمت راهحلهای بهتر تکامل مییابند. هر راهحل کاندید دارای مجموعهای از خواص (کروموزومها یا ژنوتیپ آنها) است که میتواند جهشیافته و تغییر یابد. به طور سنتی، راهحلها به صورت باینری به صورت رشتههای 0 و 1 نمایش داده میشوند، اما رمزگذاریهای دیگر نیز امکانپذیر است.
تکامل معمولاً از جمعیتی از افراد بهطور تصادفی ایجاد میشود و یک فرآیند تکراری است. جمعیت در هر تکرار یک نسل نامیده میشود. در هر نسل، «برازش» (Fitness) هر فرد در جمعیت ارزیابی میشود. برازش معمولاً برابر با مقدار تابع هدف در مسئله بهینهسازی است. افراد با برازش بالاتر به طور تصادفی از جمعیت فعلی انتخاب میشوند و ژنوم هر فرد اصلاح میشود (بازترکیب میشود و احتمالاً به طور تصادفی جهش مییابد) تا نسل جدیدی تشکیل شود. سپس نسل جدیدی از راهحلهای کاندید در تکرار بعدی الگوریتم تولید میشود. یک الگوریتم ژنتیک معمولی شامل مولفههای زیر است.
- نمایش ژنتیکی دامنهای از راهحلها
- تابع برازش برای ارزیابی راهحلها
یک نمایش استاندارد از هر راهحل کاندید به صورت آرایهای از بیتها است (که مجموعه بیت یا رشته بیت نیز نامیده میشود). ویژگی اصلی مجموعه بیت که این نمایشهای ژنتیکی را ساده میسازد این است که قطعات آنها به دلیل اندازه ثابتشان به راحتی در یک راستا قرار میگیرند و در نتیجه عمل آمیزش را تسهیل میکند. الگوریتم ژنتیک، پس از این که نمایش ژنتیکی و تابع برازش تعریف شد، اقدام به مقداردهی اولیه راهحلها و سپس بهبود آن از طریق تکرار عملگرهای آمیزش، جهش، وارونگی و انتخاب میکند.
مقداردهی اولیه
اندازه جمعیت به ماهیت مسئله بستگی دارد، اما به طور معمول شامل صدها یا هزاران راهحل ممکن است. اغلب، جمعیت اولیه به طور تصادفی ایجاد میشود، و طیف وسیعی از راهحلهای ممکن (فضای جستجو) را ممکن میسازد. گاهی اوقات، راهحلها ممکن است در مناطقی که احتمالاً راهحلهای بهینه یافت میشوند، «بذر» شوند.
انتخاب
در طول هر نسل متوالی، بخشی از جمعیت موجود برای پرورش نسل جدید انتخاب میشود. راهحلها از طریق یک فرآیند مبتنی بر برازش انتخاب میشوند و در نتیجه راهحلهای با برازش بالاتر، با احتمال بالاتری انتخاب خواهند شد. روشهای انتخاب مختلفی وجود دارند که هر راهحل را ارزیابی میکنند و بهترین راهحلها را انتخاب میکنند. روشهای دیگری وجود دارند که فقط یک نمونه تصادفی از جامعه را رتبهبندی میکنند، زیرا روشهای اول ممکن است بسیار زمانبر باشند.
تابع برازش روی نمایش ژنتیکی تعریف میشود و کیفیت راهحل ارائه شده را اندازهگیری میکند. تابع برازش همیشه به مسئله وابسته است. برای مثال، در مسئله کوله پشتی میخواهیم ارزش کل اشیایی را که میتوان در یک کولهپشتی با ظرفیت ثابت قرار داد، به حداکثر رساند. نمایش یک راهحل ممکن است آرایهای از بیتها باشد، که در آن هر بیت یک شی متفاوت را نشان میدهد، و مقدار بیت (0 یا 1) نشان میدهد که آیا شی در کوله پشتی قرار گرفته است یا خیر.
هر نمایشی معتبر نیست، زیرا اندازه اشیاء ممکن است از ظرفیت کوله پشتی بیشتر باشد. برازش راهحل، مجموع ارزش تمامی اشیاء موجود در کوله پشتی است. در برخی مسائل، تعریف صریح برازش دشوار یا حتی غیرممکن است. در این موارد، ممکن است از شبیهسازی برای تعیین مقدار تابع برازش یک «فنوتیپ» (Phenotype) استفاده شود.
عملگرها در الگوریتم ژنتیک
گام بعدی، تولید نسل دوم با استفاده از راهحلهای انتخاب شده و به کمک عملگرهای ژنتیکی است. عملگرهای ژنتیکی شامل عملیات زیر میشود.
- «آمیزش» (Crossover)
- «جهش» (Mutation)
برای تولید هر راهحل جدید، نیاز به یک زوج «والد» داریم که این زوج، خود، در مرحله قبلی انتخاب شده بودند. با تولید یک راهحل «فرزند» که با استفاده از روشهای ترکیب و جهش ایجاد میشود. این روند تا زمانی که جمعیت جدیدی از راهحلها با اندازه مناسب تولید شود ادامه مییابد. اگرچه روشهای تولیدمثلی که مبتنی بر دو والد است، بیشتر «الهامگرفته از زیستشناسی» هستند، برخی تحقیقات نشان میدهند که بیش از دو «والد» کروموزومهای با کیفیتتری تولید میکنند.
این فرآیندها در نهایت منجر به نسل بعدی کروموزومها میشود که با نسل اولیه متفاوت است. به طور کلی، متوسط برازش با این روش برای جمعیت افزایش مییابد، زیرا از نسل اول، بهترین راهحلها با احتمال بالا، به همراه نسبت کمی از راهحلهای با برازش کمتر، انتخاب میشوند. این راهحلهایی که برازش کوچکتری دارند، تنوع ژنتیکی را در استخر ژنتیکی والدین و بنابراین تنوع ژنتیکی نسل بعدی فرزندان را تضمین میکنند.
شرط خاتمه یافتن
فرآیند تولید نسل جدید تا رسیدن به شرایط خاتمه تکرار میشود. مهمترین شرایط خاتمه در ادامه فهرست شده است.
- راهحلی به دست میآید که حداقل معیارها را برآورده میسازد.
- تکرار به تعداد معینی از نسلها رسیده باشد.
- هزینه، شامل زمان محاسبه یا بودجه تخصیص یافته، به آستانه تعریف شدهای رسیده باشد.
- برازش راهحل با بالاترین رتبه، به حدی رسیده است که تکرارهای متوالی، دیگر نتایج بهتری ایجاد نمیکند.
- ترکیبی از موارد فوق.
یادگیری عمیق چیست ؟
در یادگیری عمیق، یک مدل کامپیوتری یاد میگیرد که وظایف طبقهبندی را مستقیماً از روی تصاویر، متن یا صدا انجام دهد. مدلهای یادگیری عمیق میتوانند به دقت پیشرفتهای دست یابند، که گاهی اوقات از عملکرد سطح انسانی فراتر است. یادگیری عمیق با استفاده از مجموعه بزرگی از دادههای برچسبگذاری شده و معماریهای شبکه عصبی که حاوی لایههای زیادی هستند، آموزش داده میشوند. کاربردهای شبکههای عمیق از سال ۲۰۲۲ بهصورت قابلتوجهی فراگیر شده است.

آموزش مدل در یادگیری ماشین
به طور معمول، آموزش مدل به تعداد زیادی داده قابل اعتماد نیاز دارند تا مدلها پیشبینیهای دقیقی را انجام دهند. هنگام آموزش یک مدل یادگیری ماشین، مهندسان یادگیری ماشین باید نمونه بزرگ و معرف داده را هدف قرار داده و جمعآوری کنند. دادههای مجموعه آموزشی میتواند شامل دادههای متنی، تصویری، دادههای جمعآوریشده از حسگرها یا از تک تک کاربران یک سرویس باشد. مدلهای آموزشدیده که از دادههای «اریب» (Biased) یا ارزیابینشده به دست میآیند، میتوانند منجر به پیشبینیهای «منحرف» (Skewed) یا نامطلوب شوند. سوگیری الگوریتمی یک نتیجه بالقوه از آماده نبودن کامل دادهها برای آموزش است. اخلاق یادگیری ماشین در حال تبدیل شدن به یک زمینه مطالعه و یک بخش ضروری به ویژه در تیمهای مهندسی یادگیری ماشین است. بیش برازش چیزی است که هنگام آموزش یک مدل یادگیری ماشین باید مراقب آن بود. بیش برازش به این معنی است که دقت یادگیری در دادههای آموزشی بیش از حد بالا باشد. این دقت بالا ممکن است منجر به مدلهای پیچیدهای شود که در پیشبینی و در دادههای تست به خوبی عمل نمیکنند و دچار خطا میشوند.
ارزیابی مدل در یادگیری ماشین چیست ؟
طبقهبندی توسط مدلهای یادگیری ماشین را میتوان با روشهای تخمین دقت، مانند روش Holdout، که دادهها را به دو مجموعه آموزشی و تست تقسیم میکند اعتبارسنجی و عملکرد مدل آموزشی را ارزیابی کرد. در این روش معمولاً دو سوم دادهها به مجموعه آموزشی و یک سوم آنها به مجموعه تست تخصیص داده میشوند. در مجموعه تست، روش اعتبارسنجی K-fold به این صورت است که دادهها به طور تصادفی به k زیر مجموعه تقسیم میشوند. سپس k-1 زیرمجموعه از k زیرمجموعه موجود، به عنوان دادههای آموزشی و یک زیرمجموعه باقیمانده به عنوان دادههای تست در نظر گرفته میشود. علاوه بر روشهای Holdout و اعتبارسنجی متقاطع، میتوان از «خودگردانسازی» (Bootstrap) برای ارزیابی دقت مدل استفاده کرد که n نمونه را با جایگزینی از مجموعه داده نمونهبرداری میکند.
علاوه بر این، محققان اغلب «حساسیت» (Sensitivity) و «ویژگی» (Specificity) را به ترتیب به معنای «نرخ مثبت درست» (True Positive Rate | TPR) و «نرخ منفی درست» (True Negative Rate |TNR) گزارش میکنند. به طور مشابه، محققین گاهی اوقات نرخ مثبت اشتباه (False Positive Rate | FPR) و همچنین نرخ منفی اشتباه ( False Positive Rate | FNR) را گزارش میکنند. با این حال، این نرخها نسبتهایی هستند که صورت و مخرج خود را آشکار نمیکنند. «مشخصه عملیاتی کل» ( Total Operating Characteristic | TOC) یک روش موثر برای بیان توانایی تشخیصی مدل است. TOC صورت و مخرجهای نرخهای ذکر شده قبلی را نشان میدهد، بنابراین TOC اطلاعات بیشتری نسبت به «منحنی مشخصه عملکرد» (ROC) و ناحیه مرتبط ROC در زیر منحنی (AUC) ارائه میکند.
«ماتریس درهمریختگی» (Confusion Matrix) یک روش اندازهگیری عملکرد برای طبقهبندی یادگیری ماشینی است. این ماتریس در واقع یک جدول است که به شما کمک میکند تا عملکرد مدل طبقهبندی را در مجموعهای از دادههای آزمایشی بدانید.
کاربردهای یادگیری ماشین چیست ؟
دایره کاربردهای یادگیری ماشین به صورت فزاینده و بیش از پیش فراگیر شده است. در ادامه به برخی از مهمترین استفادههای یادگیری ماشین اشاره شده است.
سیستمهای توصیهگر
پیشنهادهای توصیه شده توسط موتورهای نتفلیکس، یوتیوب، اطلاعاتی که در فید فیسبوک ظاهر میشوند ، پیشنهاد توصیه خرید محصول توسط فروشگاههای آنلاین و بسیاری موارد دیگر توسط یادگیری ماشین توسعه داده شدهاند. الگوریتمها سعی میکنند ترجیحات ما را بیاموزند. آنها میخواهند یاد بگیرند که ما مثلاً در توییتر، چه توییتهایی را تمایل داریم ببینیم، در فیسبوک، چه تبلیغاتی، چه پستهایی یا محتوای لایکشدهای برای ما جالب توجه خواهد بود.
تحلیل تصویر و تشخیص اشیا
یادگیری ماشین میتواند تصاویر را برای کسب اطلاعات مختلف و به منظور شناسایی افراد و تفکیک آنها از یکدیگر تجزیه و تحلیل کند. هدف تشخیص اشیا این است که به ماشینها قدرت بدهد تا موجودیتهای تعریف شده را در یک تصویر یا ویدیوی زنده شناسایی کنند. تشخیص اشیاء اغلب با سایر روشهای بینایی کامپیوتر و «بینایی ماشین» (Machine Vision) ترکیب میشود تا برنامههای قویتری ایجاد کند. موارد استفاده تشخیص اشیاء اغلب اهدافی مانند مکانیابی، ردیابی، شمارش اشیا یا تشخیص ناهنجاریها و نقاط «پرت» (Outlier) در یک محیط دارند. دادههای تشخیص اشیا اطلاعات تجاری ارزشمندی را ارائه میدهد که به ذینفعان اجازه میدهد به رویدادها به صورت بلادرنگ پاسخ دهند.

تشخیص تقلب
ماشینها میتوانند الگوهای پرداخت، خرید و مخارج افراد را تحلیل کنند. مثل اینکه این افراد معمولاً در چه فروشگاهها یا مکانهایی خرید میکنند و یا اینکه چگونه خرج میکنند. یادگیری ماشین به کمک این الگوها، تراکنشهای تقلبی احتمالی، تلاشهای غیرقانونی برای ورود به یک سیستم، هرزنامهها و غیره را شناسایی میکند.
دستیارها و چتباتها
بسیاری از شرکتها در تلاش هستند تا رباتهای چت آنلاین را به خدمت بگیرند. به این وسیله مشتریان نه با انسانها بلکه با یک ماشین در تعامل خواهند بود. الگوریتمها بهکار رفته در این چتباتها از یادگیری ماشین و پردازش زبان طبیعی استفاده میکنند. این رباتها از سوابق مکالمات گذشته یاد میگیرند تا بتوانند پاسخهای مناسب را به مخاطبین ارائه دهند.
تصویربرداری و تشخیص پزشکی
برنامههای یادگیری ماشین را میتوان برای بررسی تصاویر پزشکی یا سایر اطلاعات و جستجوی نشانگرهای خاص بیماری آموزش داد، مانند ابزاری که میتواند خطر سرطان را بر اساس ماموگرافی پیشبینی کند.
ماشینهای خودران
بسیاری از فناوریهای بهکار رفته در خودروهای خودران مبتنی بر یادگیری ماشین و به ویژه یادگیری عمیق است.
چگونه کسب و کارها از یادگیری ماشین استفاده می کنند ؟
یادگیری ماشین هسته اصلی مدلهای کسب و کار برخی از شرکتها مانند الگوریتم پیشنهاددهنده نتفلیکس یا موتور جستجوی گوگل به حساب میآید. بسیاری شرکتهای دیگر با یادگیری ماشین درگیر هستند، اگرچه یادگیری ماشین جز اصلی مدل کسب و کارشان نیست. بسیاری از شرکتها در تلاشند تا تعیین کنند که چگونه به روشی سودمند از یادگیری ماشین استفاده کنند. در واقع یکی از چالشهایی که برای کسب و کارها مطرح هست این است که درک کنند چه مسائلی را میتوانند با ماشین لرنینگ حل کنند.
در مقاله ای در سال 2018، محققان MIT Initiative on the Digital Economy پرسشنامهای برای تعیین اینکه آیا مشاغل توسط یادگیری ماشین تسخیر خواهند شد یا خیر، طرح کردند. محققان دریافتند که هیچ شغلی توسط یادگیری ماشین دست نخورده نخواهد ماند، از طرفی، احتمالاً هیچ شغلی به طور کامل توسط آن تسخیر نخواهد شد. محققان دریافتند راه موفقیت در بهکارگیری یادگیری ماشین، سازماندهی مجدد مشاغل به وظایفی است که برخی از آنها توسط یادگیری ماشین انجام میشود و برخی دیگر به یک انسان نیاز دارند. برخی شرکتها در حال حاضر عملا از یادگیری ماشین و به روشهای مختلفی استفاده میکنند. در این قسمت به برخی مثالها، کاربردهای یادگیری ماشین در صنعت اشاره شده است.
نحوه به کارگیری یادگیری ماشین توسط کسب و کار ها
مدیران در تلاش هستند تا دریابند که یادگیری ماشین کجا و چگونه موجب ارزشآفرینی در سازمان آنها میشوند. برخی کاربرهای مختلف ماشین لرنینگ برای یک شرکت ممکن است مهم و حیاتی باشد اما این استفاده در شرکتی دیگر ارزشآفرین نباشد. کسب و کارها باید موارد استفاده تجاری مقتضی را که برای آنها مفید هستند، پیدا کنند. مثلا آمازون در بهکارگیری دستیارها و بلندگوهای صوتی موفق بوده است. این کاربری یادگیری ماشین مناسب کسب و کار آمازون است و احتمالاً در یک شرکت خودروسازی کارآمد نخواهد بود اما در عین حال شرکتهای خودروسازی ممکن است راهی برای استفاده از یادگیری ماشین در خط کارخانه پیدا کند که باعث صرفه جویی یا کسب درآمد زیادی شود.
همچنین بهتر است یادگیری ماشین به عنوان راهحلی برای جستجوی مشکلات در نظر گرفته نشود. برخی از شرکتها ممکن است تلاش کنند تا از یادگیری ماشین به عنوان ارتقادهنده برخی موارد استفاده قبلی کسب و کار استفاده کنند. کسب و کارها به جای اینکه در هنگام شروع بر فناوری تمرکز کنند، باید با توجه به یک مشکل تجاری یا نیاز مشتری، فعالیت تجاری خود را شروع کنند که میتواند با یادگیری ماشینی برآورده شود. داشتن درک پایه از یادگیری ماشینی مهم است، اما یافتن استفاده مناسب از یادگیری ماشینی در نهایت به افرادی بستگی دارد که تخصصهای متفاوتی دارند و با هم کار میکنند.
محدودیت ها در یادگیری ماشین چیست ؟
اگرچه یادگیری ماشین در برخی زمینهها تحول آفرین بوده است، اما در خیلی از موارد، برنامههای یادگیری ماشین در ارائه نتایج مورد انتظار شکست میخورند. دلایل این امر متعدد است که مهمترین آنها شامل موارد زیر میشود:
- «فقدان داده مناسب» (Lack of Suitable Data)
- «عدم دسترسی به دادهها» (Lack of Access to the Data)
- «سوگیری دادهها» (Data Bias)
- «مشکلات حریم خصوصی» (Privacy Problems)
- «الگوریتمهای نادرست انتخاب شده» (Badly Chosen Tasks and Algorithms)
- «ابزارها و افراد اشتباه» (Wrong Tools and People)
- «کمبود منابع» (Lack of Resources)
- «مشکلات ارزیابی» (Evaluation Problems)
در سال 2018، یک خودروی خودران از اوبر نتوانست یک عابر پیاده را شناسایی کند که منجر به تصادف و کشته شدن آن عابر شد. تلاشها برای استفاده از یادگیری ماشین در مراقبتهای بهداشتی با سیستم IBM Watson حتی پس از گذشت سالها و میلیاردها دلار سرمایهگذاری شکست خورد. یادگیری ماشین به عنوان یک استراتژی برای بهروزرسانی شواهد مربوط به بررسی و مرور سیستماتیک ادبیات فزاینده زیست پزشکی استفاده شده است. این رویکرد منجر به بهبود مجموعههای آموزشی شده است، اما هنوز محدودیت و حساسیت به یافتن پژوهشها وجود دارد
اریبی در یادگیری ماشین چیست ؟
ماشینها توسط انسانها آموزش داده میشوند و اریبی انسانی ممکن است الگوریتمها را تحت تاثیر قرار دهد. اگر اطلاعات اریب یا دادههایی که نابرابریهای موجود را منعکس میکنند به یک برنامه یادگیری ماشینی داده شود، برنامه یاد میگیرد که آن را تکرار کند و موجب توسعه این سوگیری میشود. رویکردهای یادگیری ماشینی میتوانند دچار اریبیهای مختلف داده شوند. هنگامی که یادگیری ماشین بر روی دادههای ساخته شده توسط انسان آموزش میبیند، احتمالاً سوگیریهای اساسی و ناخودآگاه موجود در جامعه را در بر دارد. یک سیستم یادگیری ماشین که به طور خاص بر روی مشتریان فعلی آموزش داده شده است ممکن است نتواند نیازهای گروههای مشتریان جدیدی را که در دادههای آموزشی نشان داده نشدهاند، پیشبینی کند.
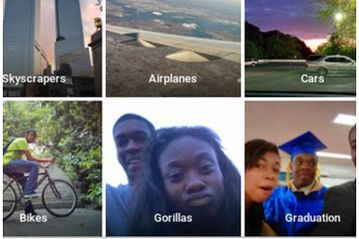
نشان داده شده است که مدلهای زبانی که از دادهها به دست میآیند، دارای سوگیریهای انسانی هستند، برای مثال سیستمهای یادگیری ماشین که برای ارزیابی ریسک جنایی استفاده میشوند علیه سیاهپوستان دچار اریبی بودهاند. مثال دیگر این که در سال 2015، عکسهای گوگل، اغلب افراد سیاهپوست را به عنوان گوریل برچسبگذاری میکردند و در سال 2018 هنوز این مشکل به خوبی حل نشده بود. طبق گزارشها، گوگل از راهحل حذف همه گوریلها از دادههای آموزشی استفاده میکرد و بنابراین قادر به شناسایی گوریلهای واقعی نبود.
مسائل مشابه با شناسایی افراد غیرسفیدپوست در بسیاری از سیستمهای دیگر مشاهده شده است. چتباتهایی که در مورد نحوه مکالمه افراد در توییتر آموزش دیدهاند، ممکن است دادههایی با زبان توهینآمیز و یا نژادپرستانه دریافت کنند. در سال 2016، مایکروسافت یک ربات چت را که یادگیری آن تحت توییتر بود، آزمایش کرد. نتایج این آزمون نشان داد که زبان به کار رفته، نژادپرستانه و جنسیتی است.
در برخی موارد، مدلهای یادگیری ماشین مشکلات اجتماعی را ایجاد یا تشدید میکنند. به عنوان مثال، فیس بوک از یادگیری ماشین به عنوان ابزاری برای نشان دادن تبلیغات و محتوایی که در کاربران ایجاد علاقه کرده و آنها را جذب میکند، استفاده کرده است. این اتفاق منجر به مدلهایی شده است که محتوای افراطی را به مردم نشان میدهد. محتوای آتشافروز، حزبی یا نادرست میتواند منجر به قطبی شدن و گسترش تئوریهای توطئه شود. برخی راهکارها برای اجتناب از اریبی در ماشین لرنینگ در زیر فهرست شده است.
- بررسی دقیق دادههای آموزشی
- قرار دادن حمایت سازمانی از هوش مصنوعی اخلاقی
- دریافت ورودی و دادهها از افراد با پیشینهها، تجربیات و سبکهای مختلف زندگی بههنگام طراحی سیستمهای هوش مصنوعی
به دلیل چنین چالشهایی، استفاده مؤثر از یادگیری ماشین در سایر حوزهها ممکن است صرفاً در طولانی مدت میسر شود. «عدالت» (Fairness) در یادگیری ماشین، به معنی کاهش اریبی در یادگیری ماشین و استفاده از آن به نفع انسان، به طور موکد توسط دانشمندان هوش مصنوعی مطرح میشود. این دانشمندان معتقدند که هیچ چیز مصنوعی در مورد هوش مصنوعی وجود ندارد و الگوهای موجود با الهام از مردم و توسط مردم ایجاد میشود و مهمتر این که، بر مردم تأثیر میگذارد.
توضیح پذیری در یادگیری ماشین چیست ؟
«یادگیری ماشین توضیحپذیر» (XML | Explainable Machine Learning) که با نامهای «هوش مصنوعی قابل توضیح» (XAI | Explainable AI) و هوش مصنوعی قابل تفسیر نیز شناخته میشود، عبارت است از توانایی شفافسازی در مورد آنچه که مدلهای یادگیری ماشین انجام میدهند. توضیحپذیری یادگیری ماشین کمک میکند تا انسانها تصمیمات یا پیشبینیهای انجام شده توسط هوش مصنوعی را درک کنند. این موضوع در تضاد با مفهوم «جعبه سیاه» در یادگیری ماشین است که در آن حتی طراحان مدل یادگیری نمیتوانند توضیح دهند که چرا یادگیری ماشین به یک تصمیم خاص رسیده است.
این موضوع از آن جهت اهمیت دارد که سیستمها ممکن است فریب بخورند و یا تضعیف شوند، یا فقط در انجام برخی وظایف که انسانها میتوانند به راحتی انجام دهند با شکست مواجه شوند. به عنوان مثال، تنظیم «فراداده» (Metadata) در تصاویر میتواند کامپیوترها را دچار اشتباه کند و یا با تغییر برخی تنظیمات، یک ماشین ممکن است تصویر یک سگ را به اشتباه به عنوان یک شترمرغ شناسایی کند.
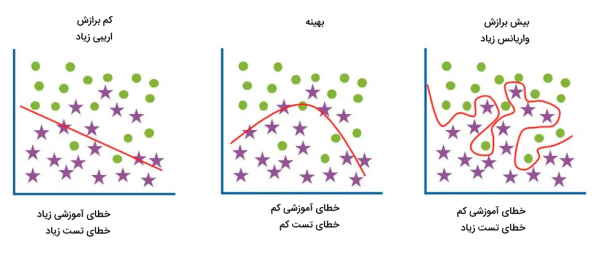
بیش برازش در یادگیری ماشین چیست؟
در مدلسازی ریاضی، بیشبرازش عبارت است از توسعه مدلی که بسیار نزدیک یا دقیقاً با مجموعهای از دادهها مطابقت دارد و بنابراین ممکن است با دادههای اضافی مطابقت نداشته باشد یا قادر نباشد مشاهدات آینده را بهطور قابل اعتماد پیشبینی کند. تعداد پارامترها در این مدل بیشتر از تعداد لازم است. برای کاهش احتمال رخداد بیش برازش، چندین راهکار وجود دارد که به برخی از آنها در زیر اشاره شده است.
- «مقایسه مدل» (Model Comparison)
- «اعتبارسنجی متقابل» (Cross Validation)
- «منظمسازی» ( Regularization)
- «توقف زودهنگام» (Early Stop)
- «هرس» (Pruning)
- «احتمال پیشین بیزی» (Bayesian Prior Probability)
- «حذف تصادفی» (Dropout)
روشهای فوق مبتنی بر رویکردهای زیر عمل میکنند.
- مدلهای بیش از حد پیچیده، جریمه میشوند.
- قابلیت تعمیمپذیری مدل با ارزیابی عملکرد مدل بر روی مجموعهای از دادهها به غیر از دادههای آموزشی، آزمون میشود.
قابلیت های یادگیری ماشین
یادگیری ماشین در تحلیل دادههای حجیم با مقیاس هزار یا میلیون رکورد، مثل دادههای به دست آمده از ضبط مکالمات با مشتریان، لاگ سنسورها، تراکنشهای خودپرداز و غیره، بسیار مناسب است. موفقیت برنامه مترجم گوگل به این دلیل موفق است که بر روی حجم وسیعی از اطلاعات وب و به زبانهای مختلف «آموزش» داده میشود.
در برخی موارد، یادگیری ماشین میتواند بینش به دست آورد یا در مواردی که انسانها قادر به تصمیمگیری نیستند، عمل تصمیمگیری را به صورت خودکار انجام دهد که در این شرایط داشتن یک الگوریتم، کارآمدتر و کمهزینهتر خواهد بود.
هر بار که شخصی در گوگل یک پرس و جو مینویسد، الگوریتم جستجوی گوگل در مقیاس و سرعتی بالا پاسخهای بالقوه را نمایش میهد. جستجوی اطلاعات کاری است که انسانها هم میتوانند انجام دهند، اما نه در مقیاس و سرعتی که مدلهای گوگل قادر به انجام آن هستند. این عمل، از نوع کارهایی نیست که باعث بیکاری انسانها شود. این عمل نمونه کاری است که اگر توسط انسانها انجام شود، از نظر اقتصادی منطقی نخواهد بود.
برخی سوالات پرتکرار در یادگیری ماشین
در این بخش به برخی از سوالات رایج و پرتکرار در خصوص یادگیری ماشین پاسخ داده میشود.
تفاوت داده کاوی و یادگیری ماشین چیست؟
داده کاوی در مورد کشف الگوها در مجموعه دادهها یا «به دست آوردن دانش و بینش» از دادهها است. میتوانیم الگوریتمهای یادگیری ماشین را بهعنوان یکی از ابزارهای دادهکاوی در نظر بگیریم. بیشتر رویکردهای داده کاوی مبتنی بر الگوریتمهای یادگیری ماشین هستند. شاید بتوان داده کاوی را به عنوان خط لولهای از مراحل و رویکردها در نظر گرفت و استفاده از الگوریتم یادگیری ماشین یکی از بخشهای این خط لوله است. به عبارت دیگر، داده کاوی «فقط» یادگیری ماشینی نیست. به عنوان مثال، مصورسازی یا خلاصه سازی داده نیز بخشی از داده کاوی است. یادگیری ماشین یک بخش و مجموعهای از روشها است که در داده کاوی استفاده میشود.
تفاوت یادگیری عمیق و یادگیری ماشین چیست ؟
برخی از مهمترین تفاوتها بین یادگیری ماشین و یادگیری عمیق در ادامه نام برده شده است.
- یادگیری ماشین از برخی الگوریتمها برای «تجزیه» (Parse) دادهها، یادگیری از آن دادهها و تصمیمگیری آگاهانه بر اساس آموختهها استفاده میکند.
- یادگیری عمیق زیر مجموعهای از یادگیری ماشین است که هوش مصنوعی را با بیشترین شباهت انسانی ممکن میسازد.
- یادگیری عمیق الگوریتمها را در لایههای یک «شبکه عصبی مصنوعی» ساختار میدهد به طوری که بتواند به تنهایی یاد بگیرد و تصمیمات هوشمندانه بگیرد.
الگوریتم دستهبند مناسب را در یک مسئله دستهبندی چگونه باید انتخاب کنیم؟
هیچ قانون ثابتی برای انتخاب یک الگوریتم در مسائل طبقهبندی وجود ندارد. اما راهکارهای زیر کمک میکند تا انتخاب بهتری داشته باشیم.
- اگر دقت دستهبند اهمیت ویژهای دارد، الگوریتمهای مختلف را آزمایش کنید و آنها را به کمک اعتبارسنجی متقابل ارزیابی کنید.
- اگر مجموعه داده آموزشی کوچک باشد، از مدلهایی استفاده کنید که دارای واریانس کم و اریبی بالا هستند.
- اگر مجموعه داده آموزشی بزرگ باشد، از مدلهایی استفاده کنید که واریانس بالا و اریبی کمی دارند.
در طبقهبندی نایو بیز، naive به چه مفهومی اشاره دارد؟
نایو در لغت به معنی «ساده لوح» است. این دستهبند مفروضاتی را مطرح میکند که ممکن است درست نباشد. الگوریتم فرض میکند با توجه به متغیر کلاس، وجود یک ویژگی از یک کلاس به وجود هیچ ویژگی دیگری مرتبط نیست. در واقع فرض میکند که ویژگیها کاملاً از هم مستقل هستند. به عنوان مثال، اگر میوهای قرمز رنگ و شکل گرد باشد، بدون توجه به سایر ویژگیها، ممکن است گیلاس در نظر گرفته شود. این فرض ممکن است درست نباشد، زیرا یک سیب نیز با این توضیحات مطابقت دارد.
جمعبندی
در این مقاله سعی شده است تا به سوال یادگیری ماشین چیست، پاسخ داده شود. پس از واکاوی مفاهیم هوش مصنوعی و یادگیری ماشین، به تقسیمبندی یادگیری ماشین و زیربخشهای آن و همچنین به مدلها و الگوریتمها پرداخته شده است. کاربردهای یادگیری ماشین به ویژه در صنعت مورد بحث قرار گرفته است و و در انتها به محدودیتها، سوگیریها و قابلیتهای یادگیری ماشین اشاره شده است. در بخش آخر این مطلب برخی سوالات رایج و پرتکرار مطرح شده و به آنها پاسخ داده شده است.










